- Лекція 13. Хеш таблиці

Содержание
- 2. Хеш-таблиця - це структура даних, яка впроваджує інтерфейс асоціативного масиву, а саме, вона дозволяє зберігати пари
- 3. Таблиці з прямою адресацією Припустимо, що застосуванню потрібна динамічна множина, кожний елемент якої має ключ з
- 4. Таблиці з прямою адресацією Комірка k вказує на елемент множини з ключем k. Якщо множина не
- 5. Динамічна множина із використанням таблиці з прямою адресацією
- 6. Процедури, які реалізують операції роботи з масивами. DirectAddressSearch(T, k) return T[k] DirectAddressInsert(T, x) T[key[x]] ← x
- 7. Хеш-таблиці У випадку прямої адресації елемент з ключем k зберігається у комірці k. При хешуванні цей
- 8. Використання хеш-функції для відображення ключів у комірки хеш-таблиці
- 9. Розв’язання колізій за допомогою ланцюгів Два ключа можуть мати одне й те саме хеш-значення. Так ситуація
- 10. Розв’язання колізій за допомогою ланцюгів
- 11. Словарні операції в хеш-таблиці із використанням ланцюгів ChainedHashInsert(T, x) Вставити x в заголовок списку T[h(key[x])] ChainedHashSearch(T,
- 12. T- хеш-таблиця з m комірками, в яких зберігаються n елементів. Коефіцієнт заповнення таблиці T як α
- 14. Хеш-функції
- 15. Хеш-функції Розглянемо наступні два методи побудови хеш-функцій: метод ділення та метод множення. Побудова хеш-функції методом ділення
- 16. Хеш-функції
- 17. Відкрита адресація При використанні методу відкритої адресації всі елементи зберігаються безпосередньо в хеш-таблиці, тобто кожний запис
- 18. Приклад
- 19. Приклад колізії int hash(char *str, int table_size) { int sum; /* Make sure a valid string
- 20. Приклад колізії
- 21. вирішення колізії за допомогою ланцюгів
- 22. Представлення структури hash-table на мові С typedef struct _list_t_ { char *str; struct _list_t_ *next; }
- 23. ініціалізація Хеш-таблиці hash_table_t *create_hash_table(int size) { hash_table_t *new_table; if (size /* Attempt to allocate memory for
- 24. Відкрита адресація В результаті хеш-функція стає наступною: h :U × {0,1,.. m −1 }-> {0,1,0..,m −1
- 25. Процедура додавання елементу до відкритої адресації HashInsert(T, k) 1 i ← 0 2 repeat j ←
- 26. Процедура пошуку ключа у відкритій адресації HashSearch(T, k) 1 i ← 0 2 repeat j ←
- 27. Рівномірне хешування Ми будемо виходити із припущення рівномірного хешування, тобто ми припускаємо, що для кожного ключа
- 28. Рівномірне хешування Для обчислення послідовності досліджень для відкритої адресації зазвичай використовуються три методи: лінійне дослідження, квадратичне
- 29. Лінійне хешування Нехай задана звичайна хеш-функція h′: U → {0, 1, …, m – 1}, яку
- 30. Квадратичне дослідження
- 31. Подвійне хешування
- 32. Для того щоб послідовність досліджень могла охопити всю таблицю, значення h2(k) повинно бути взаємно простим із
- 34. Скачать презентацию

Хеш-таблиця - це структура даних, яка впроваджує інтерфейс асоціативного масиву, а саме, вона дозволяє
Хеш-таблиця - це структура даних, яка впроваджує інтерфейс асоціативного масиву, а саме, вона дозволяє

Таблиці з прямою адресацією
Припустимо, що застосуванню потрібна динамічна множина, кожний
Таблиці з прямою адресацією
Припустимо, що застосуванню потрібна динамічна множина, кожний

Таблиці з прямою адресацією
Комірка k вказує на елемент множини з
Таблиці з прямою адресацією
Комірка k вказує на елемент множини з
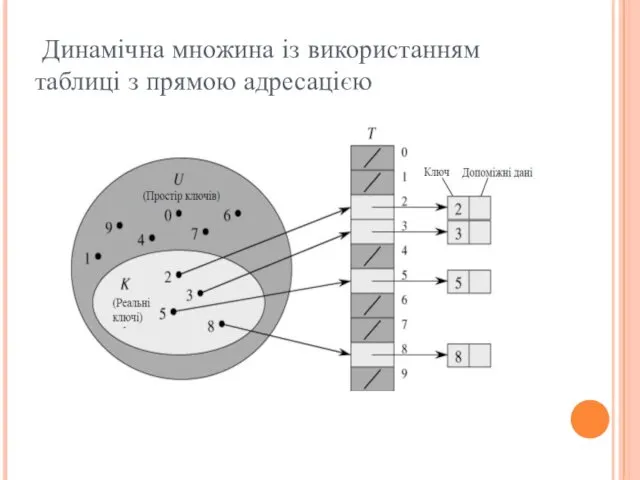
Динамічна множина із використанням таблиці з прямою адресацією
Динамічна множина із використанням таблиці з прямою адресацією

Процедури, які реалізують операції роботи з масивами.
DirectAddressSearch(T, k)
return T[k]
Процедури, які реалізують операції роботи з масивами.
DirectAddressSearch(T, k)
return T[k]

Хеш-таблиці
У випадку прямої адресації елемент з ключем k зберігається у
Хеш-таблиці
У випадку прямої адресації елемент з ключем k зберігається у
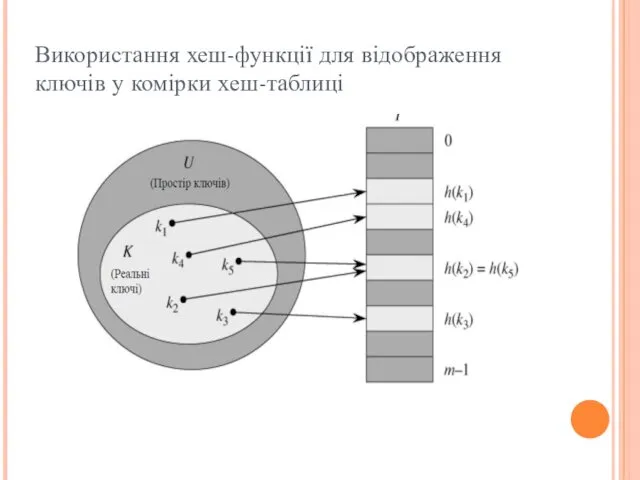
Використання хеш-функції для відображення ключів у комірки хеш-таблиці
Використання хеш-функції для відображення ключів у комірки хеш-таблиці

Розв’язання колізій за допомогою ланцюгів
Два ключа можуть мати одне й те
Розв’язання колізій за допомогою ланцюгів
Два ключа можуть мати одне й те
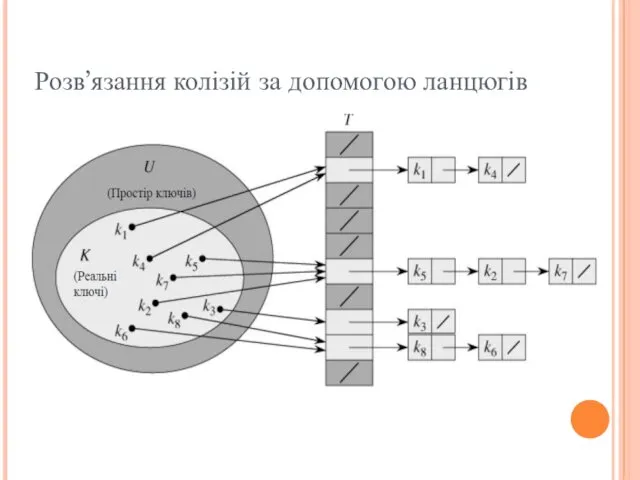
Розв’язання колізій за допомогою ланцюгів
Розв’язання колізій за допомогою ланцюгів

Словарні операції в хеш-таблиці із використанням ланцюгів
ChainedHashInsert(T, x)
Вставити x
Словарні операції в хеш-таблиці із використанням ланцюгів
ChainedHashInsert(T, x)
Вставити x

T- хеш-таблиця з m комірками, в яких зберігаються n елементів.
Коефіцієнт
T- хеш-таблиця з m комірками, в яких зберігаються n елементів.
Коефіцієнт


Хеш-функції
Хеш-функції

Хеш-функції
Розглянемо наступні два методи побудови хеш-функцій: метод ділення та метод множення.
Хеш-функції
Розглянемо наступні два методи побудови хеш-функцій: метод ділення та метод множення.

Хеш-функції
Хеш-функції

Відкрита адресація
При використанні методу відкритої адресації всі елементи зберігаються безпосередньо в
Відкрита адресація
При використанні методу відкритої адресації всі елементи зберігаються безпосередньо в

Приклад
Приклад

Приклад колізії
int hash(char *str, int table_size)
{
int sum;
/* Make sure a valid
Приклад колізії
int hash(char *str, int table_size)
{
int sum;
/* Make sure a valid
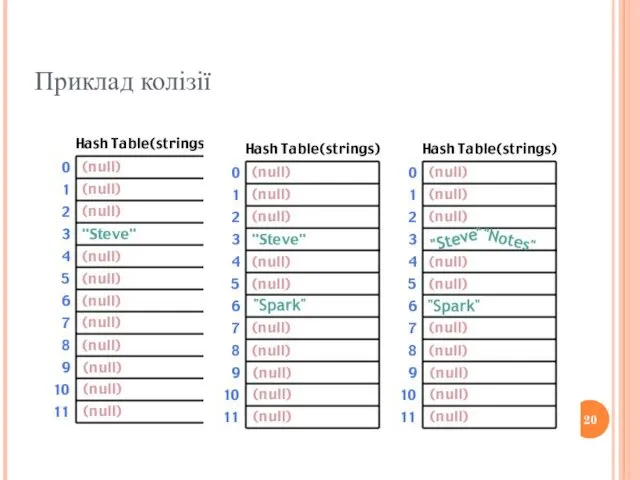
Приклад колізії
Приклад колізії

вирішення колізії за допомогою ланцюгів
вирішення колізії за допомогою ланцюгів

Представлення структури hash-table на мові С
typedef struct _list_t_ {
char *str;
Представлення структури hash-table на мові С
typedef struct _list_t_ {
char *str;

ініціалізація Хеш-таблиці
hash_table_t *create_hash_table(int size)
{
hash_table_t *new_table;
if (size<1) return NULL; /* invalid
ініціалізація Хеш-таблиці
hash_table_t *create_hash_table(int size)
{
hash_table_t *new_table;
if (size<1) return NULL; /* invalid

Відкрита адресація
В результаті хеш-функція стає наступною: h :U × {0,1,.. m
Відкрита адресація
В результаті хеш-функція стає наступною: h :U × {0,1,.. m

Процедура додавання елементу до відкритої адресації
HashInsert(T, k)
1 i ← 0
Процедура додавання елементу до відкритої адресації
HashInsert(T, k)
1 i ← 0

Процедура пошуку ключа у відкритій адресації
HashSearch(T, k)
1 i ← 0
Процедура пошуку ключа у відкритій адресації
HashSearch(T, k)
1 i ← 0

Рівномірне хешування
Ми будемо виходити із припущення рівномірного хешування, тобто ми припускаємо,
Рівномірне хешування
Ми будемо виходити із припущення рівномірного хешування, тобто ми припускаємо,

Рівномірне хешування
Для обчислення послідовності досліджень для відкритої адресації зазвичай використовуються три
Рівномірне хешування
Для обчислення послідовності досліджень для відкритої адресації зазвичай використовуються три

Лінійне хешування
Нехай задана звичайна хеш-функція h′: U → {0, 1, …,
Лінійне хешування
Нехай задана звичайна хеш-функція h′: U → {0, 1, …,

Квадратичне дослідження
Квадратичне дослідження

Подвійне хешування
Подвійне хешування

Для того щоб послідовність досліджень могла охопити всю таблицю, значення h2(k)
Для того щоб послідовність досліджень могла охопити всю таблицю, значення h2(k)
 Базовый семинар: основы контекстной рекламы
Базовый семинар: основы контекстной рекламы Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій
Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій Документирование программного обеспечения
Документирование программного обеспечения Основы комбинаторики, размещения, перестановки, сочетания
Основы комбинаторики, размещения, перестановки, сочетания Работа с файлами в Pascal
Работа с файлами в Pascal Основные методы внедрения и анализа функционирования программного обеспечения и компьютерной системы
Основные методы внедрения и анализа функционирования программного обеспечения и компьютерной системы Конспект урока с презентацией
Конспект урока с презентацией Запись числа в различных системах счисления. ОГЭ - 4 (N10)
Запись числа в различных системах счисления. ОГЭ - 4 (N10) Курсовая работа
Курсовая работа The Internet
The Internet Вебинар 1
Вебинар 1 Графический редактор Adobe Photoshop. История создания
Графический редактор Adobe Photoshop. История создания Информационная культура
Информационная культура 1С:Предприятие 8. Такси и аренда автомобилей
1С:Предприятие 8. Такси и аренда автомобилей World Wide Web. История создания и современность
World Wide Web. История создания и современность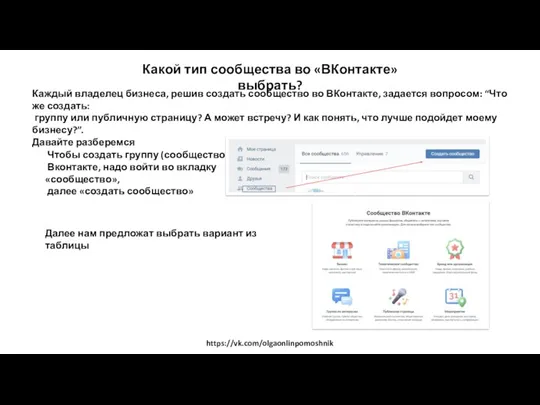 Сообщества во ВКонтакте
Сообщества во ВКонтакте Сортування та фільтрація даних
Сортування та фільтрація даних GSIS Инструкция пользователя (Для сервисного центра)
GSIS Инструкция пользователя (Для сервисного центра) Система счисления
Система счисления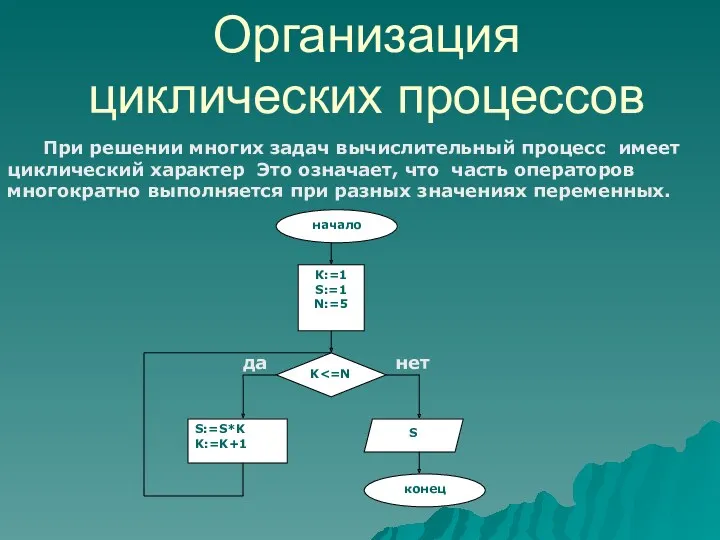 Урок по теме Организация циклических процессов
Урок по теме Организация циклических процессов Напрямки та інструменти веб-дизайну
Напрямки та інструменти веб-дизайну Ассистенты или чат - боты
Ассистенты или чат - боты Telegram. Характеристика
Telegram. Характеристика Cloud Computing For Everyone. Module 2. School Schedules
Cloud Computing For Everyone. Module 2. School Schedules Вводная презентация проекта Сердце - пламенный мотор
Вводная презентация проекта Сердце - пламенный мотор Регистр
Регистр Портал Работа в России
Портал Работа в России Архитектура ПК
Архитектура ПК