- Методи та системи паралельного програмування

Содержание
- 2. Структура навчальної дисципліни 8. Структура навчальної дисципліни. Тематичний план лекційних та лабораторних занять Загальний обсяг 120
- 3. Література Основна: Таненбаум Э., Бос Х. Современные операционные системы. 4-е изд. — СПб.: Питер, 2015. —
- 4. Література Додаткова: Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. Учебное пособие. –
- 5. 1. Історія розвитку високопродуктивних обчислювальних систем. 2. Класифікація паралельних архітектур по Флінну 3. Основні елементи архітектури
- 6. Закон Мура — емпіричне— емпіричне спостереження, зроблене в 1965— емпіричне спостереження, зроблене в 1965 році (через
- 7. Паралельні обчислювальні системи Головне призначення паралельних систем – швидке розв’язання задач. Якщо технологія програмування не дозволяє
- 8. Методи паралельного програмування
- 9. Порівняння методів паралельного програмування
- 10. Історія розвитку високопродуктивних обчислювальних систем 70-ті роки ХХст. - Експериментальні розробки по створенню багатопроцесорних обчислювальних систем
- 11. Історія розвитку високопродуктивних обчислювальних систем 80-ті роки ХХст. Перші промислові зразки мультипроцесорних систем на базі векторно-конвеєрних
- 12. SMP і NUMA-архітектури (NonUniformMemoryAccess) - середнє між SMP і MPP. В NUMA-архітектурах пам'ять фізично розділена, але
- 13. Сучасний розвиток суперкомп'ютерних технологій 4 основні напрямки: векторно-конвеєрні суперкомп'ютери SMP системи MPP системи і Кластерні системи
- 14. Класифікація паралельних архітектур по Флінну запропонована Майклом Флінном в 1966 році і розширена в 1972 році
- 15. Класифікація паралельних архітектур по Флінну ОКОД - Обчислювальна система з одиночним потоком команд і одиночним потоком
- 16. Схема SISD - комп'ютера
- 17. Схема SIMD - комп'ютера з роздільною пам'яттю
- 18. Схема SIMD - комп'ютера з розподіленою пам'яттю
- 19. Схема MISD - комп'ютера Клас MISD включає в себе багатопроцесорні системи, де процесори обробляють множинні потоки
- 20. Схема MIMD - комп'ютера з роздільною пам'яттю
- 21. Схема MIMD - комп'ютера з розподіленою пам'яттю
- 22. Основні елементи архітектури високопродуктивних обчислювальних систем Конвеєри RISC-процесори Суперскалярні процесори Суперскалярні процесори із наддовгим командним словом
- 23. Конвеєри Ідея конвеєра полягає в тому, щоб складну операцію розбити на кілька більш простих, таких, які
- 24. RISC- та CISC- процесори В основі RISC-архітектури (RISC - Reduced Instruction Set Computer) процесора лежить ідея
- 25. Порівняння CISC і RISC процесорів
- 26. Суперскалярні процесори У них реалізована конвеєрна обробка і паралельне виконання команд. У звичайному конвеєрі паралельне виконання
- 27. Суперскалярні процесори із наддовгим командним словом Суперскалярні процесори зі наддовгим командним словом – VLIW (Very Long
- 29. Скачать презентацию

Структура навчальної дисципліни
8. Структура навчальної дисципліни. Тематичний план лекційних та лабораторних
Структура навчальної дисципліни
8. Структура навчальної дисципліни. Тематичний план лекційних та лабораторних

Література
Основна:
Таненбаум Э., Бос Х. Современные операционные системы. 4-е изд. —
Література
Основна:
Таненбаум Э., Бос Х. Современные операционные системы. 4-е изд. —

Література
Додаткова:
Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем.
Література
Додаткова:
Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем.

1. Історія розвитку високопродуктивних обчислювальних систем.
2. Класифікація паралельних архітектур по Флінну
3.
1. Історія розвитку високопродуктивних обчислювальних систем.
2. Класифікація паралельних архітектур по Флінну
3.

Закон Мура
— емпіричне— емпіричне спостереження, зроблене в 1965— емпіричне спостереження, зроблене
Закон Мура
— емпіричне— емпіричне спостереження, зроблене в 1965— емпіричне спостереження, зроблене

Паралельні обчислювальні системи
Головне призначення паралельних систем – швидке розв’язання задач. Якщо
Паралельні обчислювальні системи
Головне призначення паралельних систем – швидке розв’язання задач. Якщо
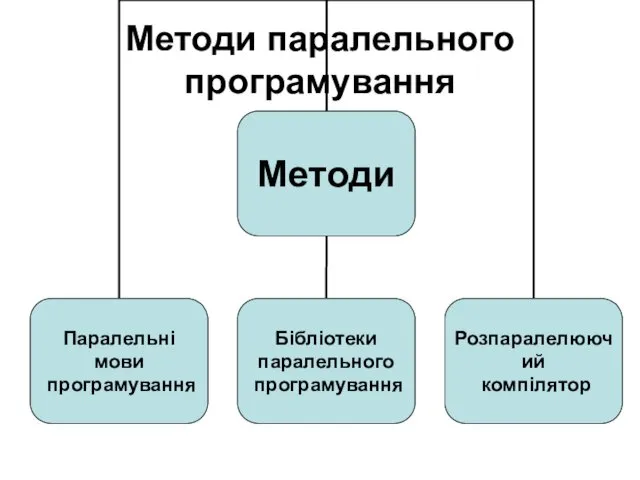
Методи паралельного програмування
Методи паралельного програмування
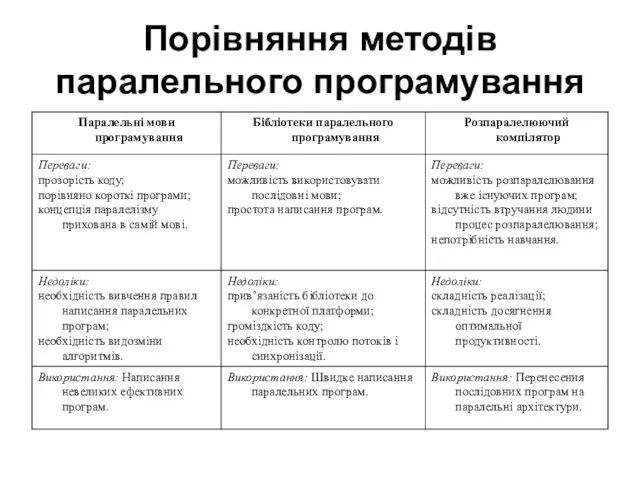
Порівняння методів паралельного програмування
Порівняння методів паралельного програмування

Історія розвитку високопродуктивних обчислювальних систем
70-ті роки ХХст.
- Експериментальні розробки по
Історія розвитку високопродуктивних обчислювальних систем
70-ті роки ХХст.
- Експериментальні розробки по

Історія розвитку високопродуктивних обчислювальних систем
80-ті роки ХХст.
Перші промислові зразки мультипроцесорних
Історія розвитку високопродуктивних обчислювальних систем
80-ті роки ХХст.
Перші промислові зразки мультипроцесорних
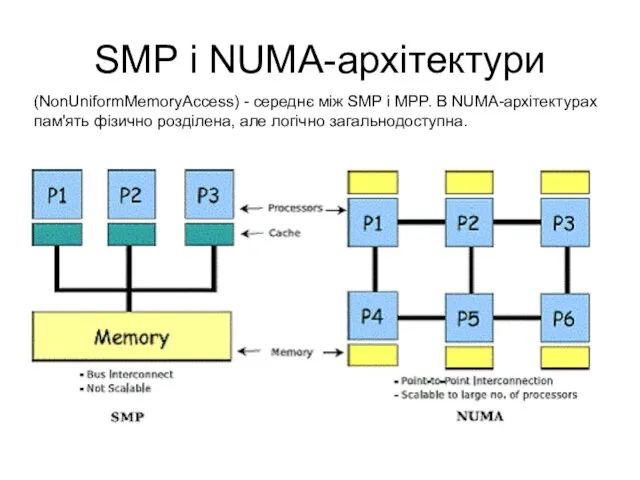
SMP і NUMA-архітектури
(NonUniformMemoryAccess) - середнє між SMP і MPP. В NUMA-архітектурах
SMP і NUMA-архітектури
(NonUniformMemoryAccess) - середнє між SMP і MPP. В NUMA-архітектурах

Сучасний розвиток суперкомп'ютерних технологій
4 основні напрямки:
векторно-конвеєрні суперкомп'ютери
SMP системи
MPP системи і
Кластерні
Сучасний розвиток суперкомп'ютерних технологій
4 основні напрямки:
векторно-конвеєрні суперкомп'ютери
SMP системи
MPP системи і
Кластерні
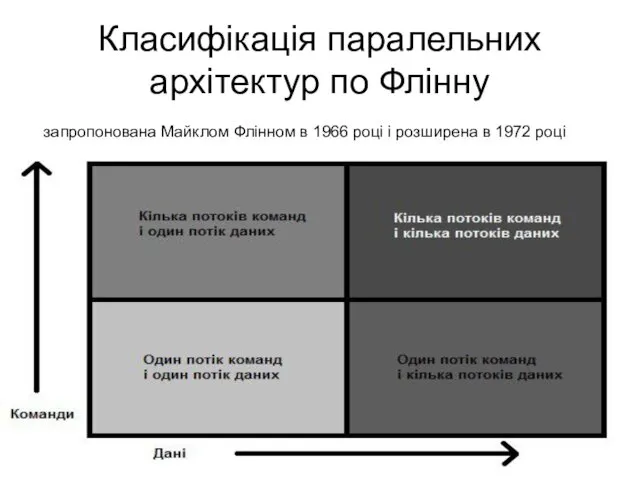
Класифікація паралельних архітектур по Флінну
запропонована Майклом Флінном в 1966 році і
Класифікація паралельних архітектур по Флінну
запропонована Майклом Флінном в 1966 році і

Класифікація паралельних архітектур по Флінну
ОКОД - Обчислювальна система з одиночним потоком
Класифікація паралельних архітектур по Флінну
ОКОД - Обчислювальна система з одиночним потоком
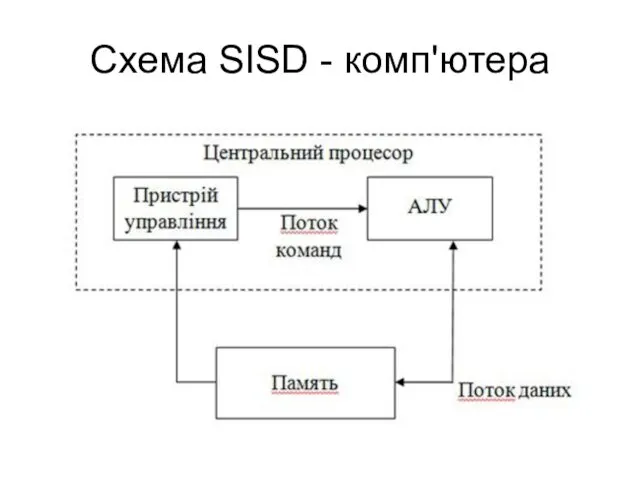
Схема SISD - комп'ютера
Схема SISD - комп'ютера
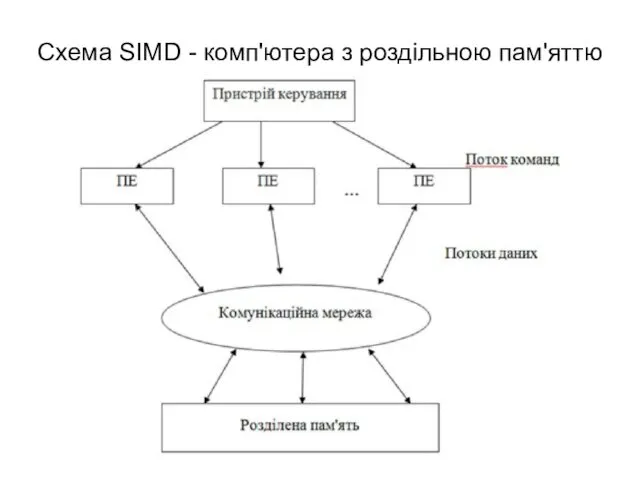
Схема SIMD - комп'ютера з роздільною пам'яттю
Схема SIMD - комп'ютера з роздільною пам'яттю
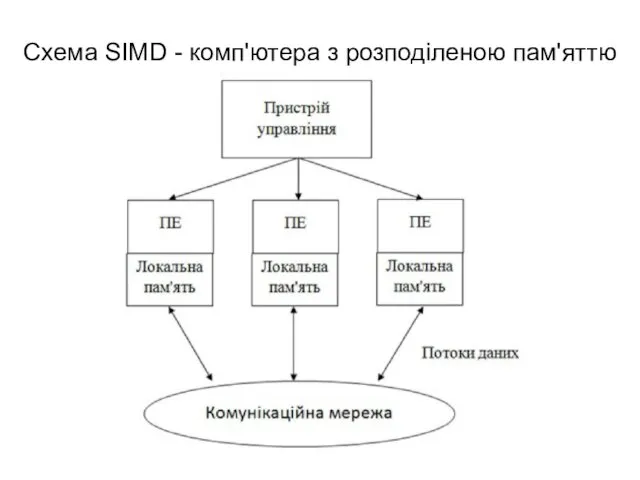
Схема SIMD - комп'ютера з розподіленою пам'яттю
Схема SIMD - комп'ютера з розподіленою пам'яттю
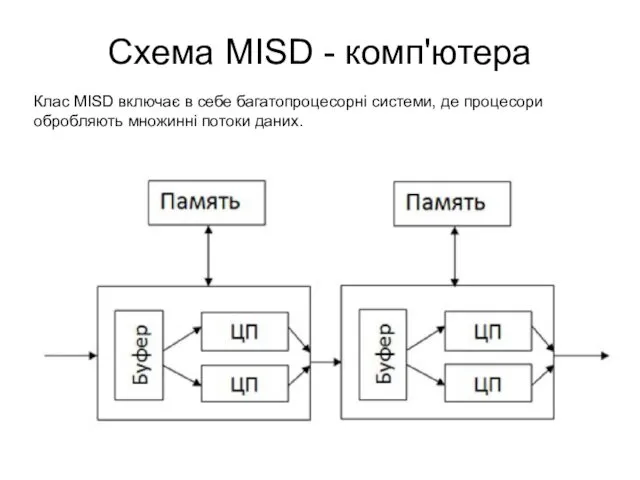
Схема MISD - комп'ютера
Клас MISD включає в себе багатопроцесорні системи, де
Схема MISD - комп'ютера
Клас MISD включає в себе багатопроцесорні системи, де
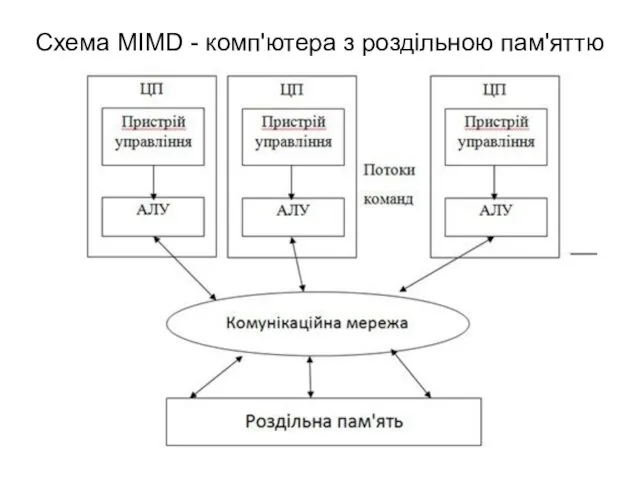
Схема MIMD - комп'ютера з роздільною пам'яттю
Схема MIMD - комп'ютера з роздільною пам'яттю
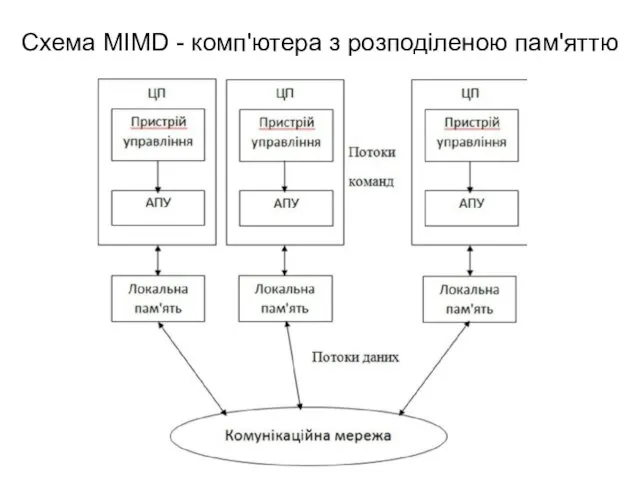
Схема MIMD - комп'ютера з розподіленою пам'яттю
Схема MIMD - комп'ютера з розподіленою пам'яттю

Основні елементи архітектури високопродуктивних обчислювальних систем
Конвеєри
RISC-процесори
Суперскалярні процесори
Суперскалярні процесори із наддовгим командним
Основні елементи архітектури високопродуктивних обчислювальних систем
Конвеєри
RISC-процесори
Суперскалярні процесори
Суперскалярні процесори із наддовгим командним
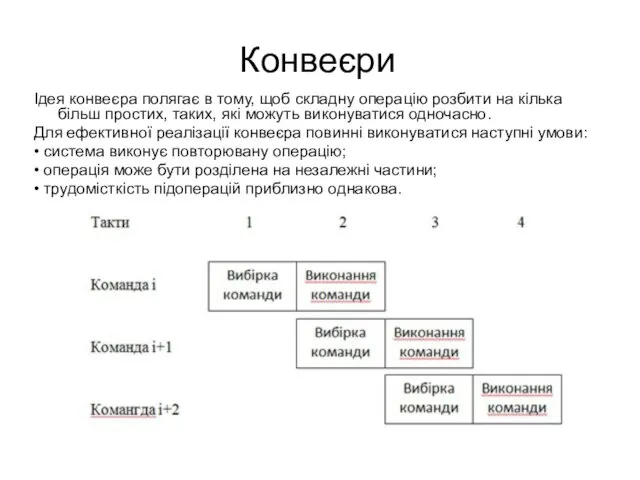
Конвеєри
Ідея конвеєра полягає в тому, щоб складну операцію розбити на кілька
Конвеєри
Ідея конвеєра полягає в тому, щоб складну операцію розбити на кілька

RISC- та CISC- процесори
В основі RISC-архітектури (RISC - Reduced Instruction Set
RISC- та CISC- процесори
В основі RISC-архітектури (RISC - Reduced Instruction Set
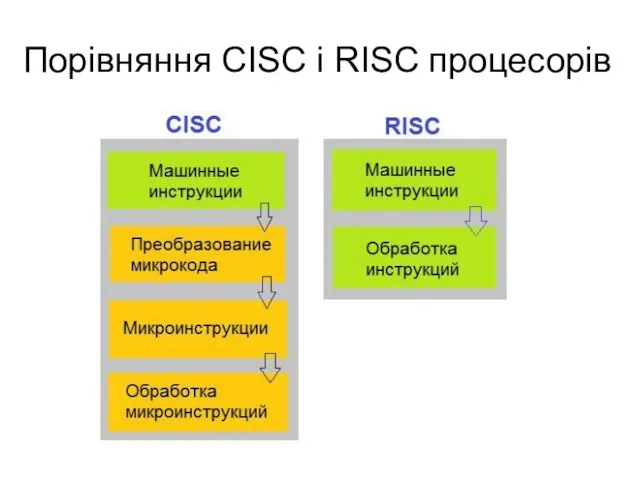
Порівняння CISC і RISC процесорів
Порівняння CISC і RISC процесорів

Суперскалярні процесори
У них реалізована конвеєрна обробка і паралельне виконання команд.
У
Суперскалярні процесори
У них реалізована конвеєрна обробка і паралельне виконання команд.
У

Суперскалярні процесори із наддовгим командним словом
Суперскалярні процесори зі наддовгим командним словом
Суперскалярні процесори із наддовгим командним словом
Суперскалярні процесори зі наддовгим командним словом
 Позиционные системы счисления
Позиционные системы счисления Локальные сети. Параметры сетей и их стандарты
Локальные сети. Параметры сетей и их стандарты Сбор и подготовка данных
Сбор и подготовка данных Современные накопители информации, используемые в вычислительной технике
Современные накопители информации, используемые в вычислительной технике Использование технологии веб-квест как средство развития познавательных и творческих способностей учащихся
Использование технологии веб-квест как средство развития познавательных и творческих способностей учащихся Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля
Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля Параллельное программирование. С++. Thread Support Library. Atomic Operations Library
Параллельное программирование. С++. Thread Support Library. Atomic Operations Library Функции в Excel
Функции в Excel Организация и средства информационных технологий обеспечения управленческой деятельности
Организация и средства информационных технологий обеспечения управленческой деятельности Поиск публикаций и показатели деятельности ученого в Web of Science
Поиск публикаций и показатели деятельности ученого в Web of Science Бездротові мережі
Бездротові мережі Занятие 1. Знакомство с программой Adobe Photoshop
Занятие 1. Знакомство с программой Adobe Photoshop Microsoft Visual Studio — линейка продуктов компании Microsoft
Microsoft Visual Studio — линейка продуктов компании Microsoft Операторы цикла
Операторы цикла Понятие об информации. Представление информации. Информационная деятельность человека.
Понятие об информации. Представление информации. Информационная деятельность человека. Автоматизоване створення запитів у базі даних
Автоматизоване створення запитів у базі даних Архітектура операційних систем
Архітектура операційних систем Windows System Programming
Windows System Programming Личный кабинет
Личный кабинет Мир станочника. Аддитивные технологии и 3D-сканирование
Мир станочника. Аддитивные технологии и 3D-сканирование Методы и средства защиты программ от компьютерных вирусов
Методы и средства защиты программ от компьютерных вирусов 46_Yaroslavskaya_Sasha
46_Yaroslavskaya_Sasha Локальные и глобальные сети ЭВМ. Защита информации в сетях. (Тема 6)
Локальные и глобальные сети ЭВМ. Защита информации в сетях. (Тема 6) Godseeker. Игра
Godseeker. Игра Рабочий стол. Управление компьютером с помощью мыши
Рабочий стол. Управление компьютером с помощью мыши Проектирование изделий из листового металла в NX
Проектирование изделий из листового металла в NX Эти люди изменили мир
Эти люди изменили мир Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование
Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование