- Сбор и подготовка данных

Содержание
- 2. Процесс анализа данных
- 3. Этапы процесса анализа данных , которые носят итеративный характер Спецификация требований к данным Сбор данных Обработка
- 4. Данные по виду Числовые характеризующие состояние какого-либо параметра изучаемого объекта. Наиболее часто такие данные бывают представлены
- 5. Пример В примере поля Age и Balance являются числовыми, а поля Job, Marital, Education и Housing
- 6. Источники данных В настоящее время в открытом доступе есть большое количество баз данных, содержащих самые разнообразные
- 7. Сбор данных процесс формирования структурированного набора данных в цифровой форме. В некоторых случаях процесс сбора данных
- 8. Особенности набора данных Для использования в системах анализа данные должны быть представлены в определенном, как правило,
- 9. Подготовка данных Для устранения отмеченных несоответствий могут быть применены следующие операции: структурирование – приведение данных к
- 10. Пример. Анкетные данные клиентов банка Для приведения этой выборки данных в «правильный» формат необходимо выполнить следующие
- 11. Пример. Обработанная выборка данных
- 12. РЕГРЕССИОННЫЙ АНАЛИЗ Предсказание значения зависимой переменной с помощью независимой переменной (независимых переменных) является задачей регрессионного анализа.
- 13. Схема применения регрессии
- 14. линейная функция гипотезы С учетом того, что наборы значений θ и x по сути являются векторами,
- 15. Виды регрессии В зависимости от характера функции гипотезы регрессию подразделяют на линейную и нелинейную. В зависимости
- 16. Пример регрессии с помощью линейной функции. Характеристики квартир Регрессия с помощью линейной функции
- 17. Функция штрафа Подбор параметров регрессионной функции обычно осуществляется по критерию минимума суммы квадратов отклонений: При этом
- 18. Оптимизационная задача В формулировке (3) задача нахождения параметров регрессионной функции является оптимизационной. Существует два основных подхода
- 19. Аналитическое решение Известно аналитическое решение задачи линейной регрессии в постановке (1): ? = (X T X
- 21. Вычисления в Microsoft Excel для умножения матриц используется функция МУМНОЖ, для транспонирования матриц – функция ТРАНСП,
- 22. Пример в Excel
- 23. Особенности Относительно низкая устойчивость к отдельным сочетаниям данных. Так, дублирование какой-либо строки в наборе данных приведет
- 24. Численное решение Для линейной регрессии задача в формулировке (1) имеет единственное решение, что позволяет без каких-либо
- 25. Шаги яисленного решения регрессионной задачи 1) подготовку данных; 2) задание функции гипотезы, в том числе начальных
- 26. Пример на основе данных о стоимости квартир Для удобства запишем выражение для функции гипотезы в следующей
- 27. Подготовка к численному решению Зададим функцию гипотезы и начальные значения коэффициентов функции гипотезы, зададим функцию штрафа
- 28. Поиск решения В настройках инструмента «Поиск решения» (MS Excel) зададим целевую ячейку, содержащую выражение для функции
- 29. Выбор функции гипотезы В случае парной̆ регрессии выбор функции гипотезы можно осуществлять визуально по соответствующему графику.
- 30. Решение с применением линейной̆ функции гипотезы и функции гипотезы
- 31. Регрессия при разных функциях гипотезы В терминологии Machine Learning ситуация, иллюстрируемая сплошной̆ линией̆, соответствующей̆ линейной̆ функции
- 32. Выбор функции регрессии 1 Разделение случайным образом исходной выборки данных на две части: обучающую, содержащую от
- 33. Заключение понятие регрессионного анализа, парной регрессии, множественной регрессии способы решения задачи регрессии. особенности решения регрессионной задачи
- 35. Скачать презентацию

Процесс анализа данных
Процесс анализа данных

Этапы процесса анализа данных , которые носят итеративный характер
Спецификация требований к
Этапы процесса анализа данных , которые носят итеративный характер
Спецификация требований к

Данные по виду
Числовые
характеризующие состояние какого-либо параметра изучаемого объекта. Наиболее
Данные по виду
Числовые
характеризующие состояние какого-либо параметра изучаемого объекта. Наиболее

Пример
В примере поля Age и Balance являются числовыми, а поля Job,
Пример
В примере поля Age и Balance являются числовыми, а поля Job,

Источники данных
В настоящее время в открытом доступе есть большое количество
Источники данных
В настоящее время в открытом доступе есть большое количество

Сбор данных
процесс формирования структурированного набора данных в цифровой форме. В
Сбор данных
процесс формирования структурированного набора данных в цифровой форме. В

Особенности набора данных
Для использования в системах анализа данные должны быть
Особенности набора данных
Для использования в системах анализа данные должны быть

Подготовка данных
Для устранения отмеченных несоответствий могут быть применены следующие операции:
Подготовка данных
Для устранения отмеченных несоответствий могут быть применены следующие операции:

Пример. Анкетные данные клиентов банка
Для приведения этой выборки данных в
Пример. Анкетные данные клиентов банка
Для приведения этой выборки данных в
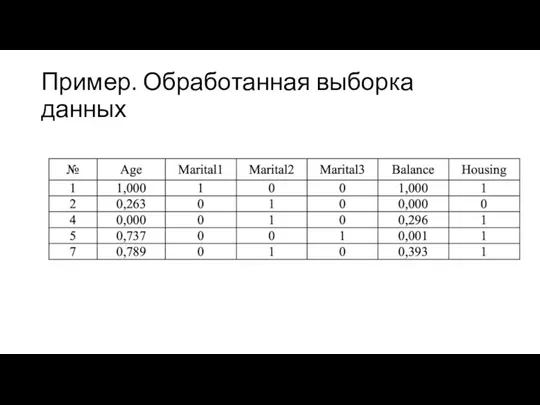
Пример. Обработанная выборка данных
Пример. Обработанная выборка данных

РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание значения зависимой переменной с помощью независимой переменной (независимых
РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание значения зависимой переменной с помощью независимой переменной (независимых
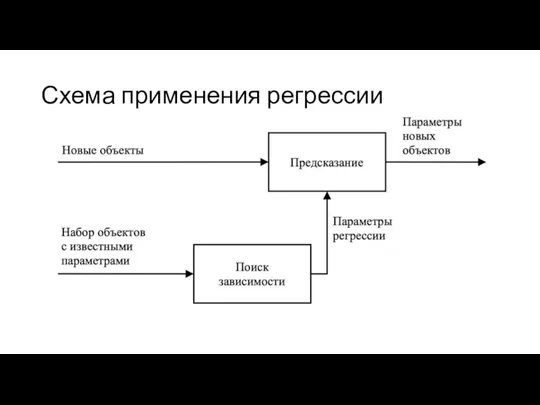
Схема применения регрессии
Схема применения регрессии

линейная функция гипотезы
С учетом того, что наборы значений θ и
линейная функция гипотезы
С учетом того, что наборы значений θ и

Виды регрессии
В зависимости от характера функции гипотезы регрессию подразделяют на линейную
Виды регрессии
В зависимости от характера функции гипотезы регрессию подразделяют на линейную

Пример регрессии с помощью линейной функции. Характеристики квартир
Регрессия с помощью
Пример регрессии с помощью линейной функции. Характеристики квартир
Регрессия с помощью

Функция штрафа
Подбор параметров регрессионной функции обычно осуществляется по критерию минимума
Функция штрафа
Подбор параметров регрессионной функции обычно осуществляется по критерию минимума

Оптимизационная задача
В формулировке (3) задача нахождения параметров регрессионной функции является оптимизационной.
Оптимизационная задача
В формулировке (3) задача нахождения параметров регрессионной функции является оптимизационной.

Аналитическое решение
Известно аналитическое решение задачи линейной регрессии в постановке (1):
Аналитическое решение
Известно аналитическое решение задачи линейной регрессии в постановке (1):

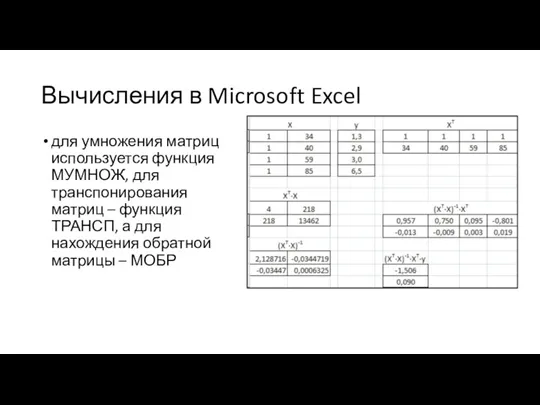
Вычисления в Microsoft Excel
для умножения матриц используется функция МУМНОЖ, для транспонирования
Вычисления в Microsoft Excel
для умножения матриц используется функция МУМНОЖ, для транспонирования

Пример в Excel
Пример в Excel

Особенности
Относительно низкая устойчивость к отдельным сочетаниям данных. Так, дублирование какой-либо строки
Особенности
Относительно низкая устойчивость к отдельным сочетаниям данных. Так, дублирование какой-либо строки

Численное решение
Для линейной регрессии задача в формулировке (1) имеет единственное
Численное решение
Для линейной регрессии задача в формулировке (1) имеет единственное

Шаги яисленного решения регрессионной задачи
1) подготовку данных;
2) задание функции
Шаги яисленного решения регрессионной задачи
1) подготовку данных;
2) задание функции

Пример на основе данных о стоимости квартир
Для удобства запишем выражение для
Пример на основе данных о стоимости квартир
Для удобства запишем выражение для

Подготовка к численному решению
Зададим функцию гипотезы и начальные значения коэффициентов
Подготовка к численному решению
Зададим функцию гипотезы и начальные значения коэффициентов
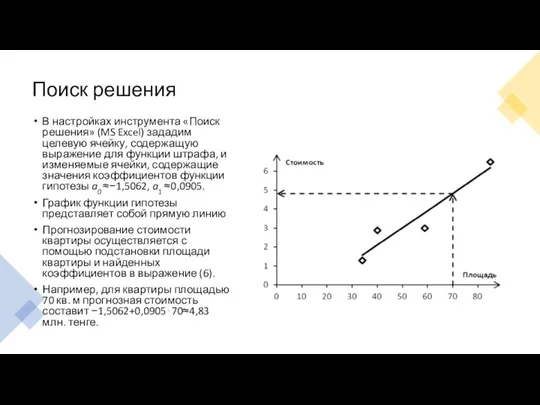
Поиск решения
В настройках инструмента «Поиск решения» (MS Excel) зададим целевую ячейку,
Поиск решения
В настройках инструмента «Поиск решения» (MS Excel) зададим целевую ячейку,

Выбор функции гипотезы
В случае парной̆ регрессии выбор функции гипотезы можно
Выбор функции гипотезы
В случае парной̆ регрессии выбор функции гипотезы можно

Решение с применением линейной̆ функции гипотезы и функции гипотезы
Решение с применением линейной̆ функции гипотезы и функции гипотезы
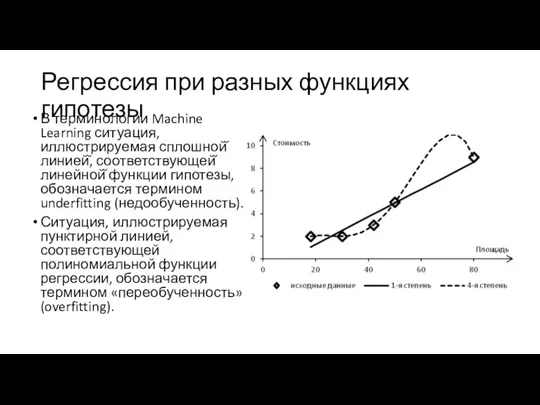
Регрессия при разных функциях гипотезы
В терминологии Machine Learning ситуация, иллюстрируемая
Регрессия при разных функциях гипотезы
В терминологии Machine Learning ситуация, иллюстрируемая

Выбор функции регрессии
1 Разделение случайным образом исходной выборки данных на
Выбор функции регрессии
1 Разделение случайным образом исходной выборки данных на

Заключение
понятие регрессионного анализа, парной регрессии, множественной регрессии
способы решения задачи регрессии.
особенности решения
Заключение
понятие регрессионного анализа, парной регрессии, множественной регрессии
способы решения задачи регрессии.
особенности решения
 Разработка рекомендаций по оценке безопасности информационных систем
Разработка рекомендаций по оценке безопасности информационных систем Принципы работы в сети. Исключения
Принципы работы в сети. Исключения Частотные методы улучшения изображений. Лекция 3
Частотные методы улучшения изображений. Лекция 3 Программы Microsoft Office: PowerPoint 2010, Word 2010
Программы Microsoft Office: PowerPoint 2010, Word 2010 Стандартизация сетей. Модель OSI
Стандартизация сетей. Модель OSI Пример слайда. Sydney Opera House is Australia’s
Пример слайда. Sydney Opera House is Australia’s История технологий шифрования
История технологий шифрования Основные команды ассемблера
Основные команды ассемблера Вкладені цикли. Покрокове введення та виведення даних. Лекція №8
Вкладені цикли. Покрокове введення та виведення даних. Лекція №8 Media & newspapers
Media & newspapers Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes
Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes Российское движение школьников. Информационно-медийное направление
Российское движение школьников. Информационно-медийное направление Интернет-коммуникации. Автоматизация
Интернет-коммуникации. Автоматизация Графический метод решения уравнений в Excel
Графический метод решения уравнений в Excel Электронный листок нетрудоспособности на территории Ленинградской области
Электронный листок нетрудоспособности на территории Ленинградской области Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2)
Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2) История серии видеоигр: Crysis, Wolfenstein, Dead Space
История серии видеоигр: Crysis, Wolfenstein, Dead Space Блогеры вместо СМИ
Блогеры вместо СМИ Путешествие по сказкам. Блок-схема. 6 класс
Путешествие по сказкам. Блок-схема. 6 класс Массивы. Строки. Пользовательские типы.(Тема 3)
Массивы. Строки. Пользовательские типы.(Тема 3) Интерактивная компьютерная графика
Интерактивная компьютерная графика Кодирование и шифрование данных
Кодирование и шифрование данных Мобильное рабочее место
Мобильное рабочее место Электронные таблицы. Программа MS Excel
Электронные таблицы. Программа MS Excel Візуальна система формування набору об’єктів нерухомості на карті
Візуальна система формування набору об’єктів нерухомості на карті Создание и форматирование таблиц в текстовом редакторе
Создание и форматирование таблиц в текстовом редакторе Текстовые редакторы. Урок 10
Текстовые редакторы. Урок 10 Создание веб-сайтов
Создание веб-сайтов