- Методология создания информационных систем

Содержание
- 2. Моделирование потоков данных (процессов) Модель системы определяется как иерархия диаграмм потоков данных (ДПД): описывают асинхронный процесс
- 3. Внешняя сущность (ВС). Материальный предмет или физич. лицо - источник или приемник информации (заказчики, персонал, поставщики,
- 4. Процесс. Преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс м. б.
- 5. Накопитель данных. Это абстрактное устройство для хранения информации, кот. м. в любой момент поместить в накопитель
- 6. Поток данных. Он определяет информацию, передаваемую через некот. соединение от источника к приемнику. Реальный поток данных
- 7. Построение иерархии диаграмм потоков данных (ДПД) Проектирование простых ИС: строится единственная контекстная диаграмма со звездообразной топологией
- 8. Иерархия контекстных диаграмм (КД) для сложных ИС. КД верхнего уровня содержит не единственный главный процесс, а
- 9. Детализация подсистем при помощи ДПД Каждый процесс на ДПД м. б. детализирован при помощи ДПД или
- 10. Мини-спецификация конечная вершина иерархии ДПД. Решение о завершении детализации процесса принимается аналитиком исходя из следующих критериев:
- 11. Переход к детализации процессов осуществляется после определения содержания всех потоков и накопителей данных, кот. описывается при
- 12. Верификация (проверка на полноту и согласованность) После построения законченной модели системы ее необходимо верифицировать. В полной
- 19. Методология функционального моделирования SADT Методология SADT разработана Дугласом Россом. На ее основе разработана известная методология IDEF0
- 20. Концепции методологии: — графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы отображает функцию в виде
- 21. Состав ФМ Модель состоит из диаграмм, фрагментов текстов и глоссария, имеющих ссылки друг на друга. Диаграммы
- 22. Особенность методологии SADT - постепенное введение все больших уровней детализации по мере создания диаграмм, отображающих модель.
- 24. Блок, представляющий систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных
- 25. Модель SADT - серия диаграмм с сопроводительной документацией, разбивающих сложный объект на составные части, кот. изображены
- 26. Неприсоединенные дуги соответствуют входам, управлениям и выходам родительского блока. Источник или получатель этих пограничных дуг м.
- 27. Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по времени) функции м. б. изображены с помощью дуг.
- 28. Механизмы (дуги с нижней стороны) показывают средства, с помощью кот. осуществляется выполнение функций. Механизм м. б.
- 29. Каждый блок на диаграмме имеет свой номер. Блок любой диаграммы м. б. далее описан диаграммой нижнего
- 30. Для того чтобы указать положение любой диаграммы или блока в иерархии, используются номера диаграмм. Например, А21
- 31. Функциональная модель Магазина с точки зрения покупателя
- 32. Диаграмма второго уровня функциональной модели магазина
- 42. Типы связей между функциями Одним из важных моментов при проектировании ИС с помощью методологии SADT является
- 43. Случайная связь — конкретная связь между функциями мала или полностью отсутствует. Пример: ситуация, когда имена данных
- 44. Логическая связь — данные и функции собираются вместе на диаграмме благодаря тому, что они попадают в
- 45. Коммуникационная связь — функции группируются благодаря тому, что они используют одни и те же входные данные
- 46. Последовательная связь — выход одной функции служит входными данными для следующей функции. Связь между элементами на
- 47. Моделирование данных. Основные понятия. Цель - обеспечение разработчика ИС концептуальной схемой БД в форме одной модели
- 48. Базовые понятия ERD: Сущность (Entity) — реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной
- 49. Связь - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - ассоциация между
- 50. Пример: Предметная область - компания по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом
- 51. Первый шаг моделирования - извлечение информации из интервью и выделение сущностей. Сущности м. б. идентифицированы с
- 52. Второй шаг моделирования - идентификация связей. Связь - ассоциация между сущностями, при кот., к. п., каждый
- 53. Например, связь продавца с контрактом м. б. выражена с. о.: — продавец м. получить вознаграждение за
- 54. Третий шаг моделирования - идентификация атрибутов. Атрибут м. б. либо обязательным, либо необязательным (рис.). Обязательность означает,
- 56. Скачать презентацию

Моделирование потоков данных (процессов)
Модель системы определяется как иерархия диаграмм потоков данных
Моделирование потоков данных (процессов)
Модель системы определяется как иерархия диаграмм потоков данных

Внешняя сущность (ВС).
Материальный предмет или физич. лицо - источник или
Внешняя сущность (ВС).
Материальный предмет или физич. лицо - источник или
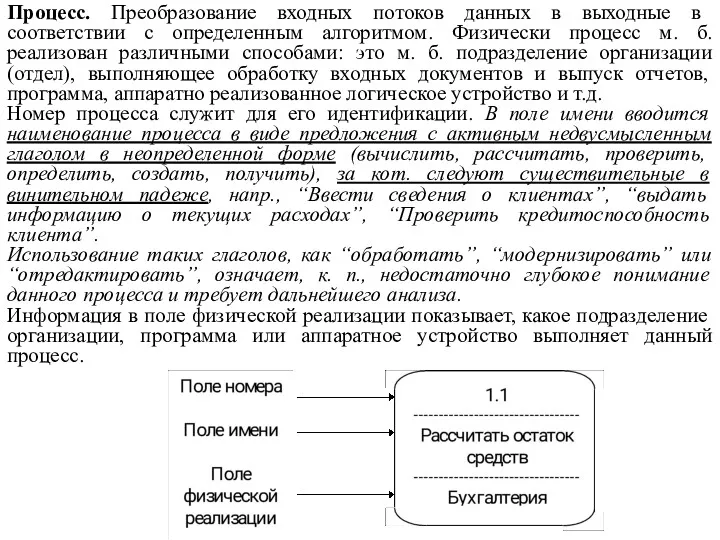
Процесс. Преобразование входных потоков данных в выходные в соответствии с определенным
Процесс. Преобразование входных потоков данных в выходные в соответствии с определенным

Накопитель данных. Это абстрактное устройство для хранения информации, кот. м. в
Накопитель данных. Это абстрактное устройство для хранения информации, кот. м. в
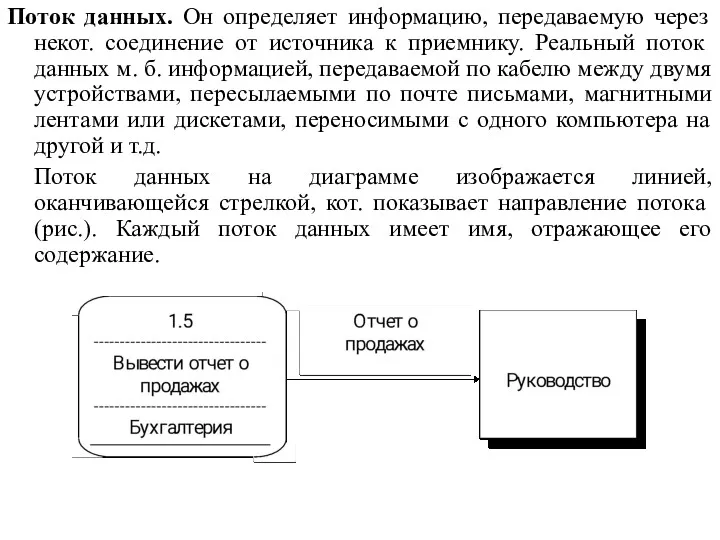
Поток данных. Он определяет информацию, передаваемую через некот. соединение от источника
Поток данных. Он определяет информацию, передаваемую через некот. соединение от источника

Построение иерархии диаграмм потоков данных (ДПД)
Проектирование простых ИС: строится единственная контекстная
Построение иерархии диаграмм потоков данных (ДПД)
Проектирование простых ИС: строится единственная контекстная

Иерархия контекстных диаграмм (КД) для сложных ИС.
КД верхнего уровня содержит
Иерархия контекстных диаграмм (КД) для сложных ИС.
КД верхнего уровня содержит

Детализация подсистем при помощи ДПД
Каждый процесс на ДПД м. б.
Детализация подсистем при помощи ДПД
Каждый процесс на ДПД м. б.

Мини-спецификация
конечная вершина иерархии ДПД.
Решение о завершении детализации процесса принимается
Мини-спецификация
конечная вершина иерархии ДПД.
Решение о завершении детализации процесса принимается

Переход к детализации процессов осуществляется после определения содержания всех потоков и
Переход к детализации процессов осуществляется после определения содержания всех потоков и

Верификация (проверка на полноту и согласованность)
После построения законченной модели системы
Верификация (проверка на полноту и согласованность)
После построения законченной модели системы
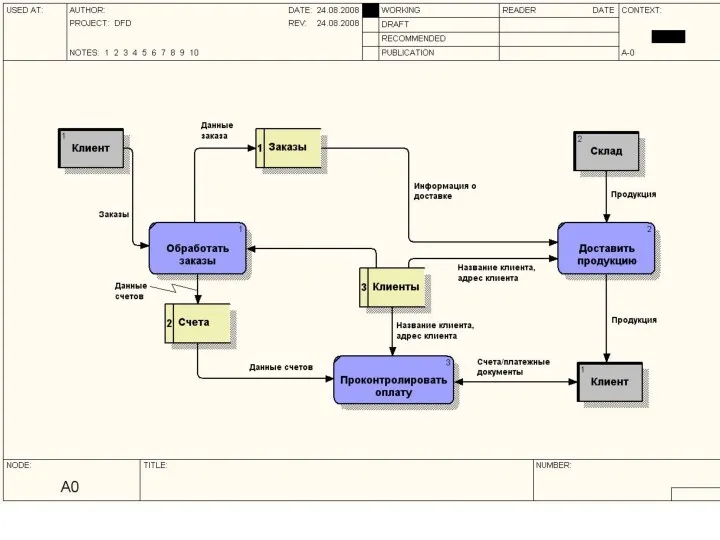
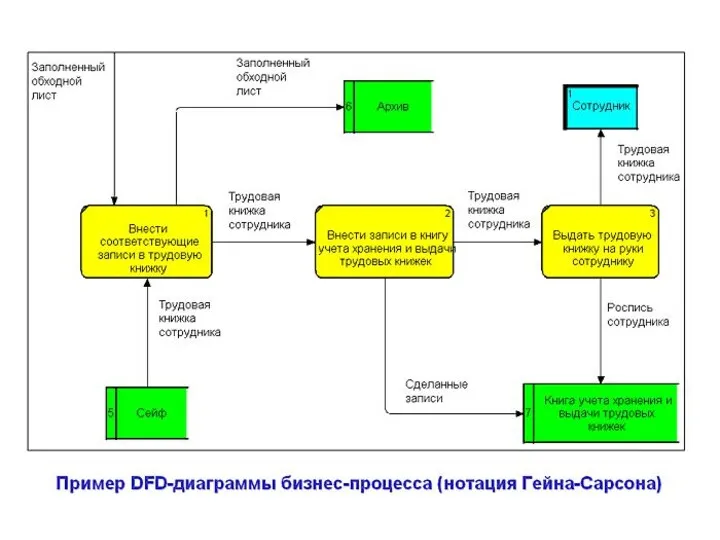
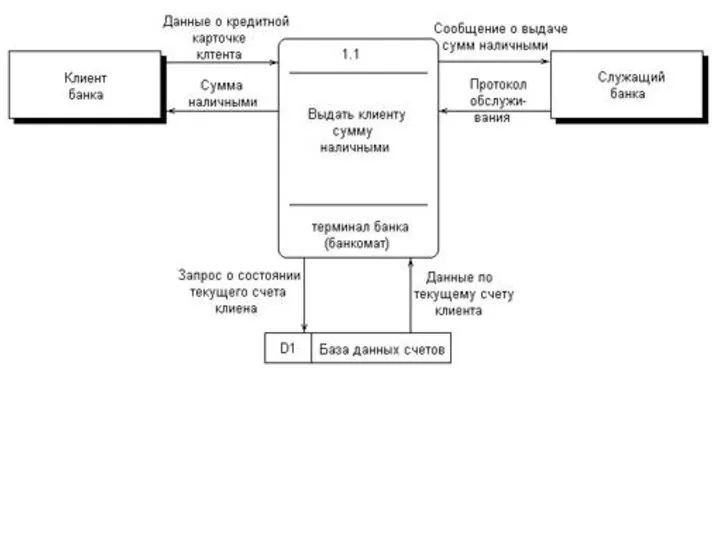
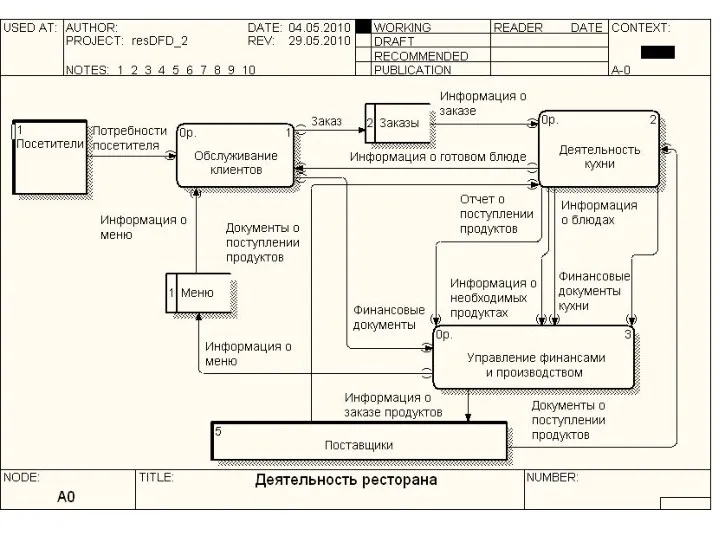
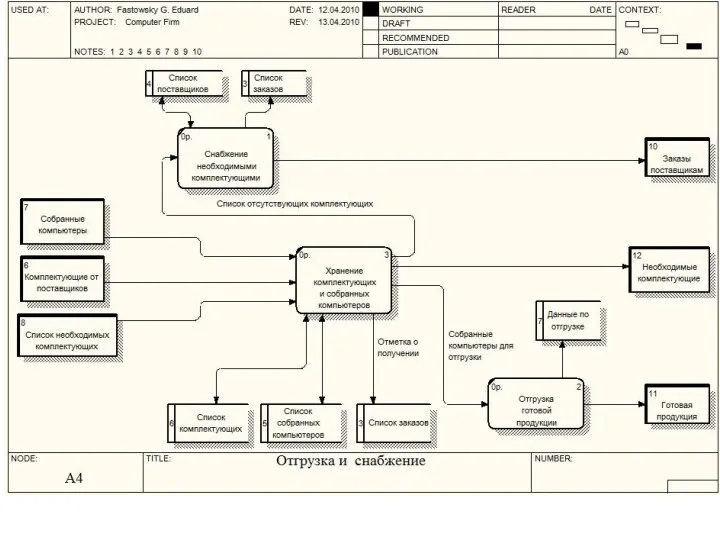
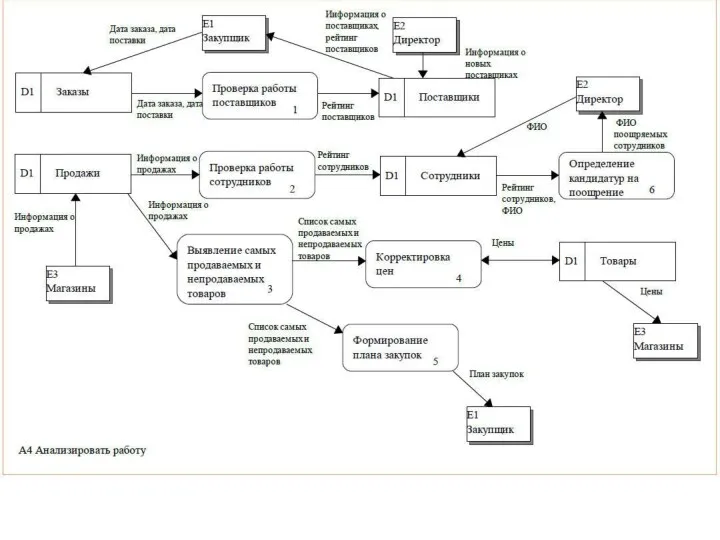

Методология функционального моделирования SADT
Методология SADT разработана Дугласом Россом.
На ее основе разработана
Методология функционального моделирования SADT
Методология SADT разработана Дугласом Россом.
На ее основе разработана

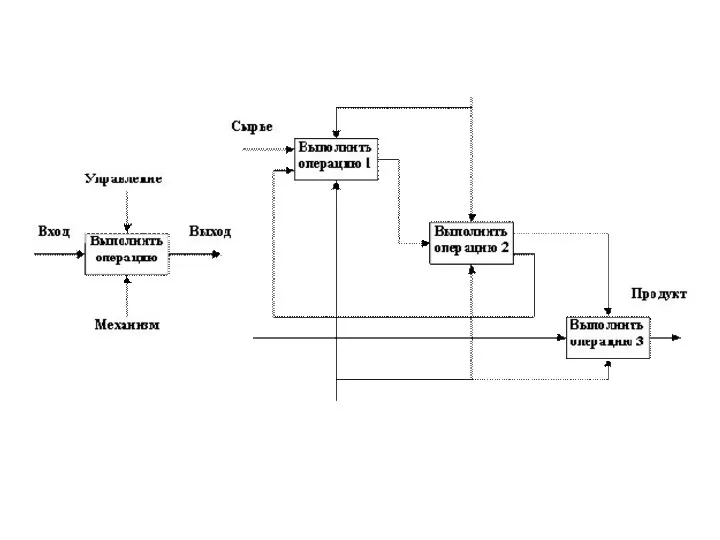
Концепции методологии:
— графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы
Концепции методологии:
— графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы
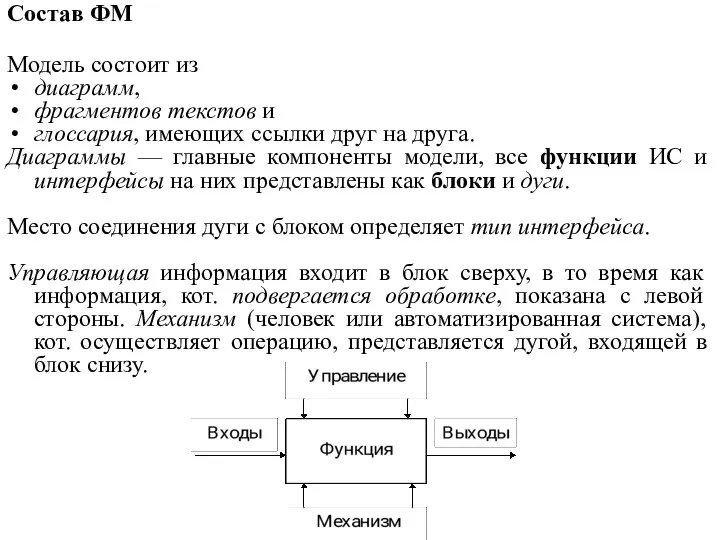
Состав ФМ
Модель состоит из
диаграмм,
фрагментов текстов и
глоссария, имеющих ссылки
Состав ФМ
Модель состоит из
диаграмм,
фрагментов текстов и
глоссария, имеющих ссылки

Особенность методологии SADT
- постепенное введение все больших уровней детализации по
Особенность методологии SADT
- постепенное введение все больших уровней детализации по
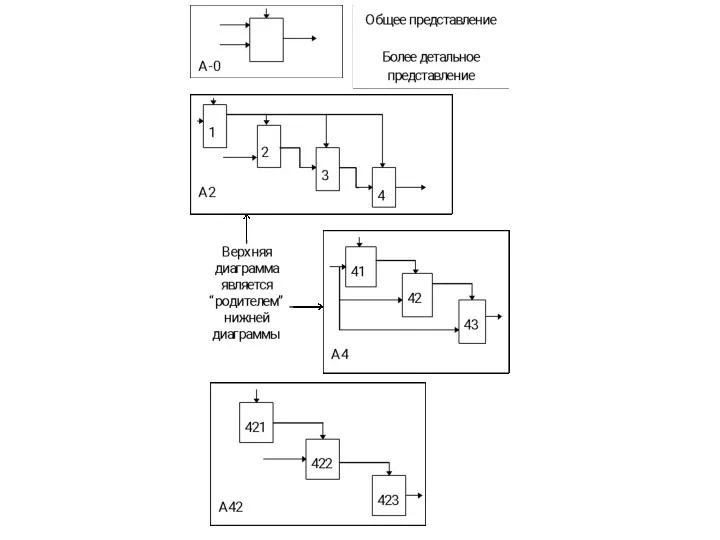

Блок, представляющий систему в качестве единого модуля, детализируется на другой диаграмме
Блок, представляющий систему в качестве единого модуля, детализируется на другой диаграмме

Модель SADT - серия диаграмм с сопроводительной документацией, разбивающих сложный объект
Модель SADT - серия диаграмм с сопроводительной документацией, разбивающих сложный объект
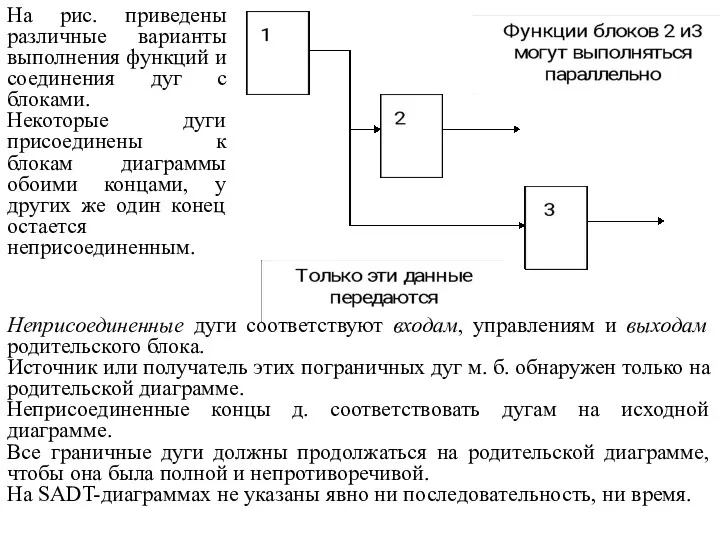
Неприсоединенные дуги соответствуют входам, управлениям и выходам родительского блока.
Источник или
Неприсоединенные дуги соответствуют входам, управлениям и выходам родительского блока.
Источник или
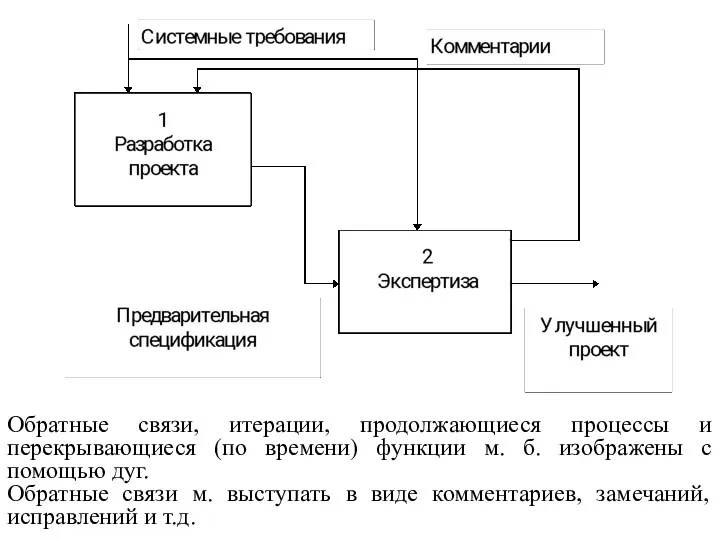
Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по времени) функции м.
Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по времени) функции м.
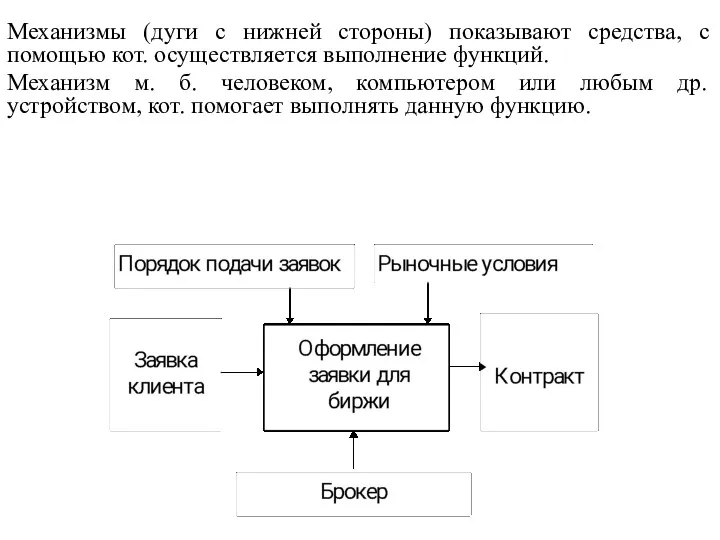
Механизмы (дуги с нижней стороны) показывают средства, с помощью кот. осуществляется
Механизмы (дуги с нижней стороны) показывают средства, с помощью кот. осуществляется
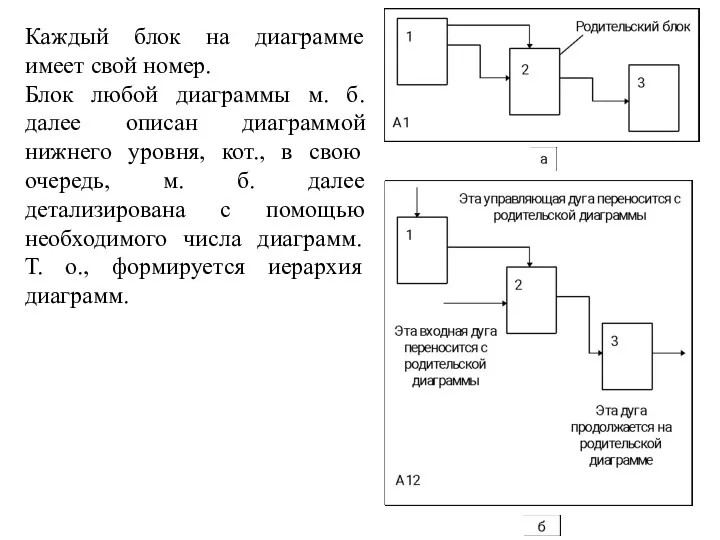
Каждый блок на диаграмме имеет свой номер.
Блок любой диаграммы м.
Каждый блок на диаграмме имеет свой номер.
Блок любой диаграммы м.
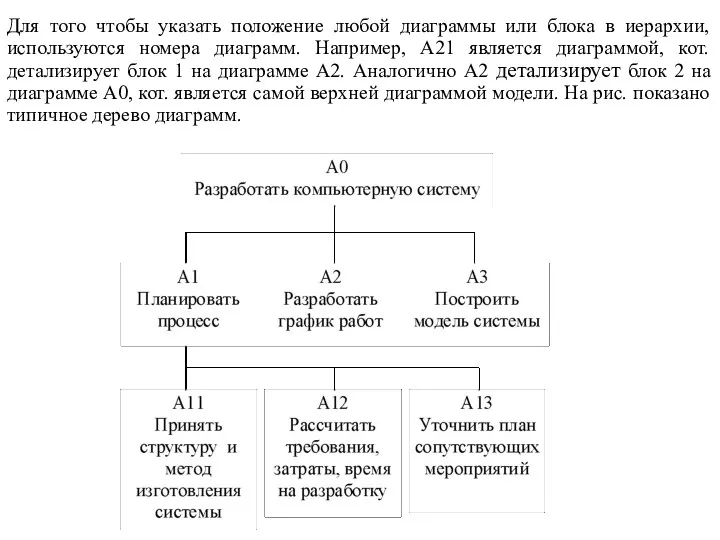
Для того чтобы указать положение любой диаграммы или блока в иерархии,
Для того чтобы указать положение любой диаграммы или блока в иерархии,
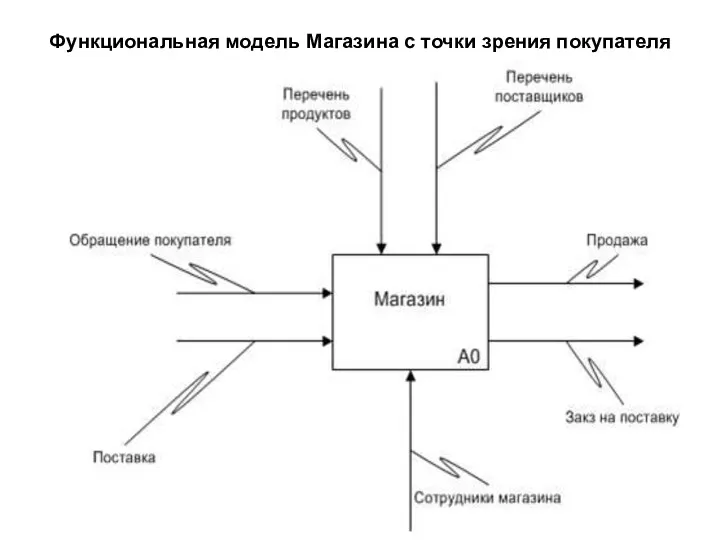
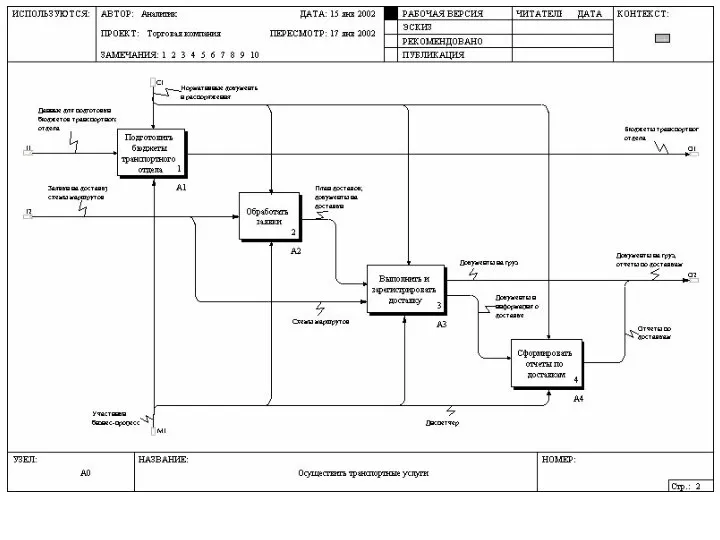
Функциональная модель Магазина с точки зрения покупателя
Функциональная модель Магазина с точки зрения покупателя
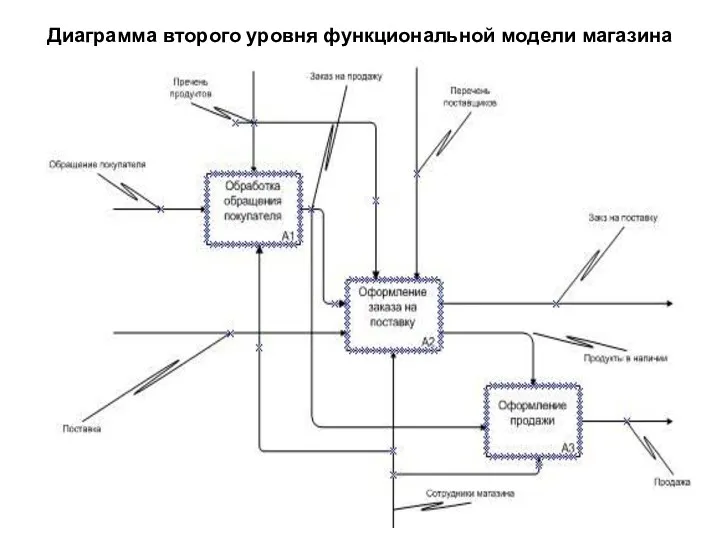
Диаграмма второго уровня функциональной модели магазина
Диаграмма второго уровня функциональной модели магазина
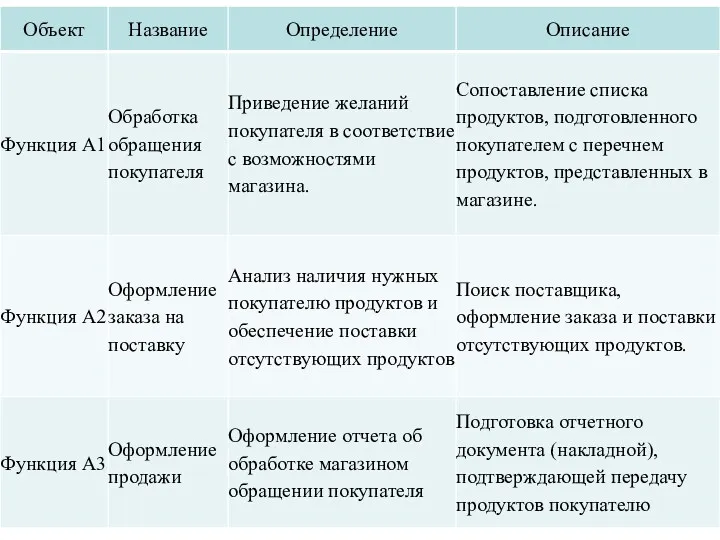
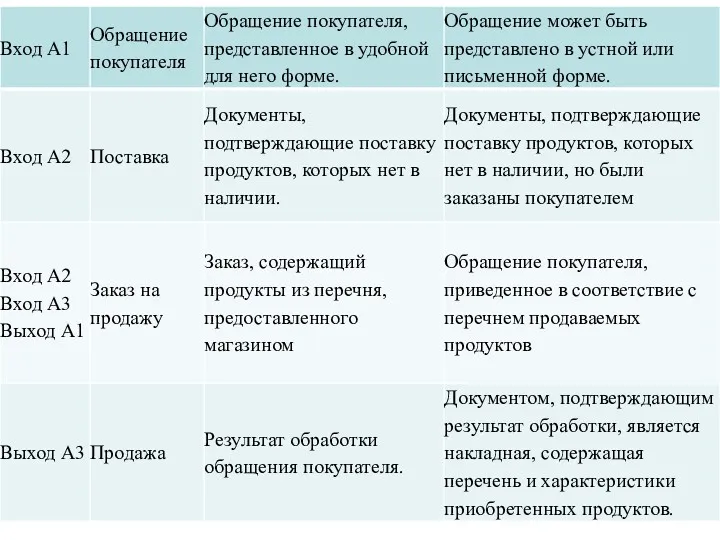



Типы связей между функциями
Одним из важных моментов при проектировании ИС с
Типы связей между функциями
Одним из важных моментов при проектировании ИС с
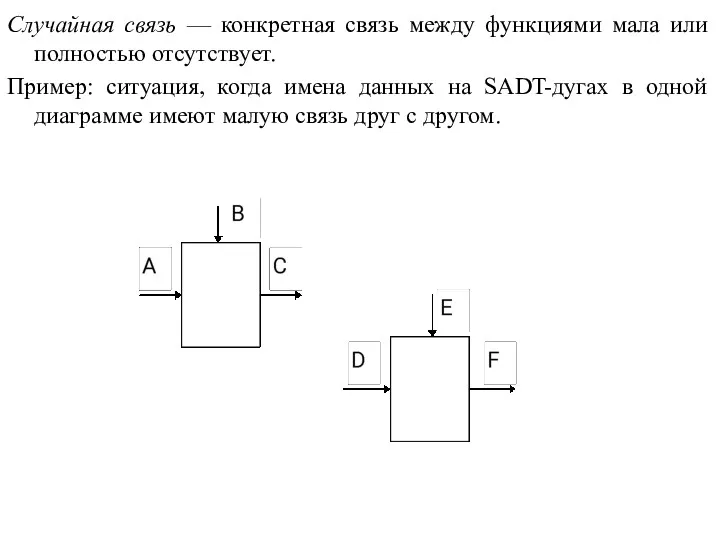
Случайная связь — конкретная связь между функциями мала или полностью отсутствует.
Случайная связь — конкретная связь между функциями мала или полностью отсутствует.
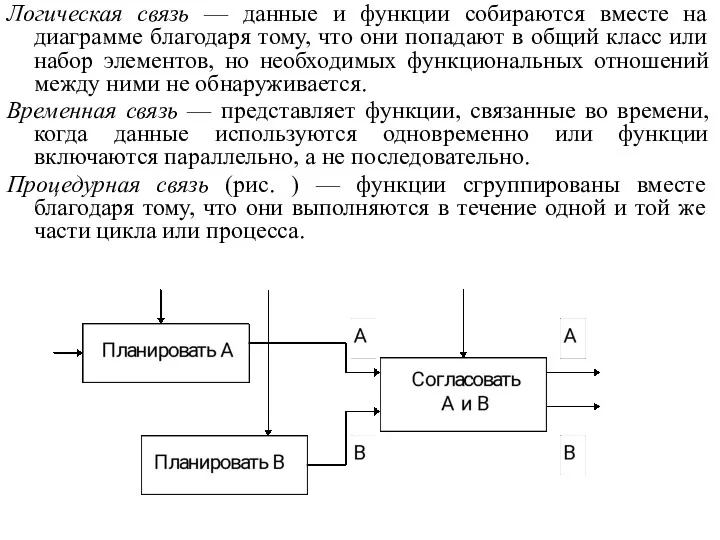
Логическая связь — данные и функции собираются вместе на диаграмме благодаря
Логическая связь — данные и функции собираются вместе на диаграмме благодаря
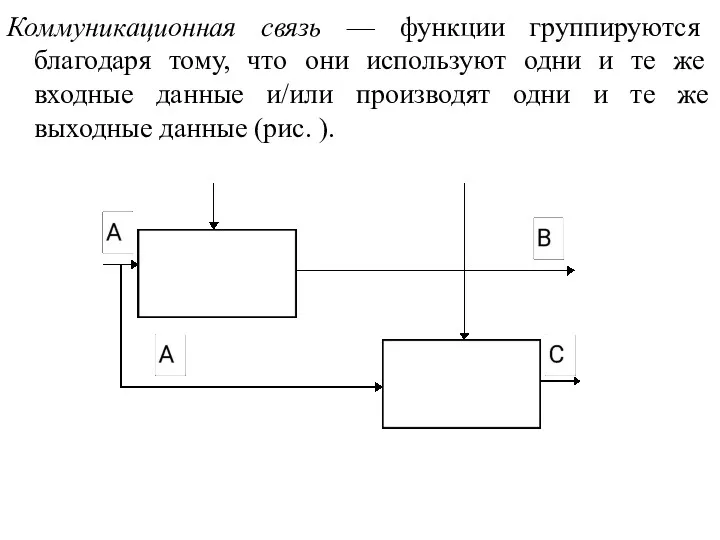
Коммуникационная связь — функции группируются благодаря тому, что они используют одни
Коммуникационная связь — функции группируются благодаря тому, что они используют одни
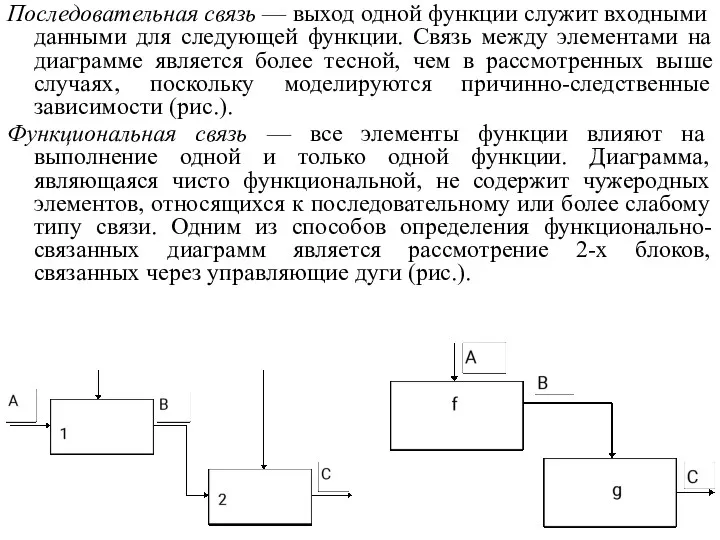
Последовательная связь — выход одной функции служит входными данными для следующей
Последовательная связь — выход одной функции служит входными данными для следующей

Моделирование данных. Основные понятия.
Цель - обеспечение разработчика ИС концептуальной схемой БД
Моделирование данных. Основные понятия.
Цель - обеспечение разработчика ИС концептуальной схемой БД

Базовые понятия ERD:
Сущность (Entity) — реальный либо воображаемый объект, имеющий существенное
Базовые понятия ERD:
Сущность (Entity) — реальный либо воображаемый объект, имеющий существенное

Связь - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной
Связь - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной

Пример: Предметная область - компания по торговле автомобилями.
Ниже приведены выдержки
Пример: Предметная область - компания по торговле автомобилями.
Ниже приведены выдержки
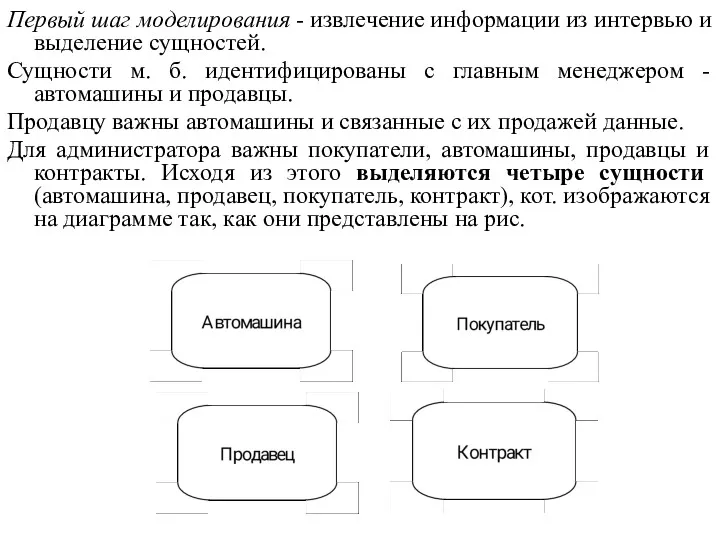
Первый шаг моделирования - извлечение информации из интервью и выделение сущностей.
Сущности
Первый шаг моделирования - извлечение информации из интервью и выделение сущностей.
Сущности

Второй шаг моделирования - идентификация связей.
Связь - ассоциация между сущностями, при
Второй шаг моделирования - идентификация связей.
Связь - ассоциация между сущностями, при
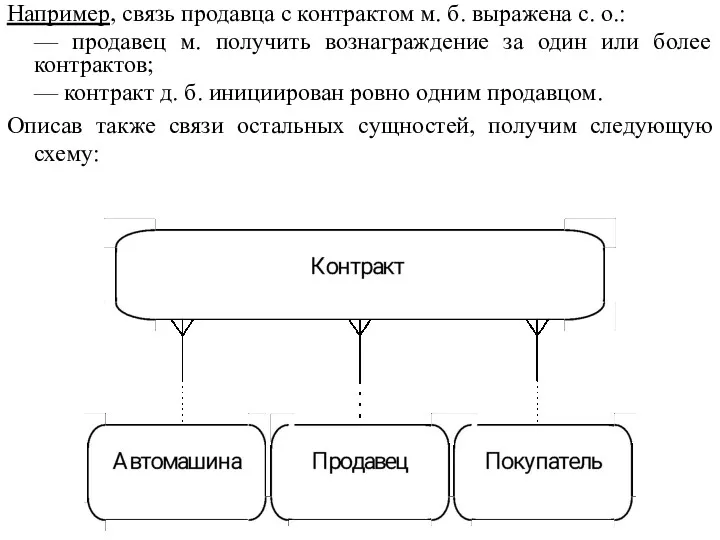
Например, связь продавца с контрактом м. б. выражена с. о.:
— продавец
Например, связь продавца с контрактом м. б. выражена с. о.:
— продавец

Третий шаг моделирования - идентификация атрибутов.
Атрибут м. б. либо обязательным, либо
Третий шаг моделирования - идентификация атрибутов.
Атрибут м. б. либо обязательным, либо
 Анализ размера рынка
Анализ размера рынка Качество управления системами
Качество управления системами Начинаем программировать на Pascsl
Начинаем программировать на Pascsl Создание Промо Сайта
Создание Промо Сайта Информационные технологии перевернувшие нашу жизнь
Информационные технологии перевернувшие нашу жизнь Программы для создания презентаций
Программы для создания презентаций Сетевая этика. Культура общения в сети. Основные понятия
Сетевая этика. Культура общения в сети. Основные понятия Умовні і циклічні конструкції JavaScript
Умовні і циклічні конструкції JavaScript Анимейт (ютубер, который делает смешные обзоры аниме с супер монтажом)
Анимейт (ютубер, который делает смешные обзоры аниме с супер монтажом) Роль школьной газеты в образовательном пространстве гимназии
Роль школьной газеты в образовательном пространстве гимназии Программное обеспечение компьютерной графики. Классификация программного обеспечения компьютерной графики
Программное обеспечение компьютерной графики. Классификация программного обеспечения компьютерной графики Вложенные (внутренние) классы. (Лекция 2.1)
Вложенные (внутренние) классы. (Лекция 2.1) Особенности объектной модели Java. (Лекция 5)
Особенности объектной модели Java. (Лекция 5) Разработка АИС Библиотека
Разработка АИС Библиотека JRE ортасының және Java SE платформасының салыстырмалы сипаттамасын орындау. Зертханалык жумыс
JRE ортасының және Java SE платформасының салыстырмалы сипаттамасын орындау. Зертханалык жумыс Этапы информационных революций. Поколения компьютеров
Этапы информационных революций. Поколения компьютеров Математические модели объектов проектирования
Математические модели объектов проектирования Повышение вовлеченности в Instagram
Повышение вовлеченности в Instagram Компьютер
Компьютер Логомиры. Кто такие черепашки?
Логомиры. Кто такие черепашки? Компьютерные сети (§44-50)
Компьютерные сети (§44-50) Преобразователи двоичного кода в двоично-десятичный код
Преобразователи двоичного кода в двоично-десятичный код Профессия программист
Профессия программист Acronis Backup 12.5. Современная система защиты данных для предприятий любого размера
Acronis Backup 12.5. Современная система защиты данных для предприятий любого размера Презентация Создание простых текстовых документов
Презентация Создание простых текстовых документов Подходы к конструированию тестов достижений
Подходы к конструированию тестов достижений Кіріспе. Java тілі туралы түсінік
Кіріспе. Java тілі туралы түсінік Количество информации
Количество информации