- Объединение таблиц (SQL)

Содержание
- 2. Типы объединений Простое объединение таблиц (NATURAL JOIN): Условие USING; Условие ON. Самообъединение (SELF-JOIN); Объединение по равенству
- 3. Получение данных из нескольких таблиц EMPLOYEES DEPARTMENTS … …
- 4. CROSS JOIN возвращает декартовое пересечение таблиц. NATURAL JOIN соединяет две таблицы по одноименным столбцам, имеющим одинаковый
- 5. Использование одноименных столбцов в запросе Для одноименных столбцов таблиц необходимо использовать префиксы (имена таблиц или псевдонимы
- 6. Простое объединение таблиц NATURAL JOIN NATURAL JOIN основано на всех столбцах в двух таблицах, которые имеют
- 7. SELECT department_id, department_name, location_id, city FROM departments NATURAL JOIN locations ; Получение записей с NATURAL JOIN
- 8. Создание объединений с условием USING Если несколько столбцов имеют одинаковые имена, но типы данных не совпадают,
- 9. Использование USING EMPLOYEES DEPARTMENTS Внешний ключ Первичный ключ …
- 10. SELECT employee_id, last_name, location_id, department_id FROM employees JOIN departments USING (department_id) ; Получение результата с использованием
- 11. SELECT l.city, d.department_name FROM locations l JOIN departments d USING (location_id) WHERE d.location_id = 1400 –-
- 12. Создание объединений с условием ON NATURAL JOIN объединяет таблицы по всем одноименным столбцам. Если требуется объединить
- 13. SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id FROM employees e JOIN departments d ON (e.department_id = d.department_id);
- 14. SELECT employee_id, city, department_name FROM employees e JOIN departments d ON d.department_id = e.department_id JOIN locations
- 15. SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id FROM employees e JOIN departments d ON (e.department_id = d.department_id)
- 16. Самообъединение SELF-JOIN MANAGER_ID для Работника эквивалентно EMPLOYEE_ID для Начальника EMPLOYEES (Работник) EMPLOYEES (Начальник) … … Случай,
- 17. Самообъединение с условием ON SELECT worker.last_name emp, manager.last_name mgr FROM employees worker JOIN employees manager ON
- 18. Объединение по не равенству NONEQUIJOIN EMPLOYEES JOB_GRADES … Таблица JOB_GRADES определяет диапазон значений LOWEST_SAL и HIGHEST_SAL
- 19. SELECT e.last_name, e.salary, j.grade_level FROM employees e JOIN job_grades j ON e.salary BETWEEN j.lowest_sal AND j.highest_sal;
- 20. Получение записей при отсутствии значений в одной из таблиц EMPLOYEES DEPARTMENTS Нет сотрудников в отделе 190.
- 21. Внутреннее соединение и внешнее соединение В SQL:1999 объединение двух таблиц, возвращающее только совпадающие строки, называется внутренним
- 22. SELECT e.last_name, e.department_id, d.department_name FROM employees e LEFT OUTER JOIN departments d ON (e.department_id = d.department_id)
- 23. SELECT e.last_name, e.department_id, d.department_name FROM employees e RIGHT OUTER JOIN departments d ON (e.department_id = d.department_id)
- 24. SELECT e.last_name, d.department_id, d.department_name FROM employees e FULL OUTER JOIN departments d ON (e.department_id = d.department_id)
- 25. Декартово пересечение Декартово пересечение образуется когда: Условие объединения отсутствует; Условие объединения ошибочно; Необходимо все строки из
- 26. Декартово пересечение. Формирование. Декартово пересечение 20 x 8 = 160 строк EMPLOYEES (20 строк) DEPARTMENTS (8
- 27. SELECT last_name, department_name FROM employees CROSS JOIN departments ; Создание CROSS JOIN CROSS JOIN применяют для
- 28. Агрегация данных и групповые функции
- 29. Групповые функции Групповые функции позволяют обрабатывать набор строк для формирования одного результата. EMPLOYEES Значение максимальной зарплаты
- 30. Типы групповых функций Групповые функции
- 31. SELECT group_function(column), ... FROM table [WHERE condition] [ORDER BY column]; Групповые функции можно использовать в операторе
- 32. SELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary) FROM employees WHERE job_id LIKE '%REP%'; Использование функций AVG и SUM
- 33. SELECT MIN(hire_date), MAX(hire_date) FROM employees; Использование функций MIN и MAX Можно использовать функции MAX и MIN
- 34. Использование функции COUNT SELECT COUNT(commission_pct) FROM employees WHERE department_id=80; SELECT COUNT(*) FROM employees WHERE department_id =
- 35. NULL значения в групповых функциях SELECT AVG(commission_pct) FROM employees; SELECT AVG(NVL(commission_pct, 0)) FROM employees; Строки, содержащие
- 36. Создание групп данных EMPLOYEES … Средняя заработная плата сотрудников по отделам В некоторых задачах необходимо применять
- 37. Создание групп данных Условие GROUP BY Для деления всех строк таблицы на группы используется условие GROUP
- 38. SELECT department_id, AVG(salary) FROM employees GROUP BY department_id ; Использование GROUP BY в операторе SELECT При
- 39. Использование GROUP BY в операторе SELECT Столбец, включенный в условие GROUP BY, может не присутствовать в
- 40. Группировка данных из нескольких столбцов EMPLOYEES Суммарная заработная плата сотрудников по занимаемым должностям внутри отдела …
- 41. SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id, job_id ORDER BY department_id; Использование условия
- 42. Ошибки при использовании групповых функций SELECT department_id, COUNT(last_name) FROM employees; SELECT department_id, job_id, COUNT(last_name) FROM employees
- 43. Ошибки при использовании групповых функций В предложение WHERE недопустимо использовать групповые функции для формирования ограничений на
- 44. Установка ограничений на группу выбираемых данных EMPLOYEES … Вывод №-ов отделов и максимальной заработной платы по
- 45. SELECT column, group_function FROM table [WHERE condition] [GROUP BY group_by_expression] [HAVING group_condition] [ORDER BY column]; Условие
- 46. SELECT department_id, MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary)>10000 ; Использование условия HAVING
- 47. SELECT job_id, SUM(salary) PAYROLL FROM employees WHERE job_id NOT LIKE '%REP%' GROUP BY job_id HAVING SUM(salary)
- 49. Скачать презентацию
 Презентация по информатике Создание комплексных текстовых документов
Презентация по информатике Создание комплексных текстовых документов Программирование на Python. Урок 10. Анимация и передвижение
Программирование на Python. Урок 10. Анимация и передвижение Абстрактные структуры данных. Списки
Абстрактные структуры данных. Списки Урок информатики в 4 классе на тему Элементный состав объекта.
Урок информатики в 4 классе на тему Элементный состав объекта. Решение задач на компьютере алгоритмизация и программирование
Решение задач на компьютере алгоритмизация и программирование Photo challenge: How to make and choose event photos for official Social Networks
Photo challenge: How to make and choose event photos for official Social Networks Языки програмирования
Языки програмирования Структура программы на языке С++
Структура программы на языке С++ Защита электронной почты
Защита электронной почты 可测试的电控系统. 软件的安装及使用
可测试的电控系统. 软件的安装及使用 VR, AR. История, технологии, применение
VR, AR. История, технологии, применение Специфика письменного общения в сети Интернет
Специфика письменного общения в сети Интернет Базы данных и SQL. Семинар 5
Базы данных и SQL. Семинар 5 Технические средства телекоммуникационных технологий
Технические средства телекоммуникационных технологий Личный кабинет застрахованного. Функционал личного кабинета
Личный кабинет застрахованного. Функционал личного кабинета QR-Коды. Их создание и применение
QR-Коды. Их создание и применение Создание мультимедийного тематического календаря на год с помощью программы Microsoft Power Point
Создание мультимедийного тематического календаря на год с помощью программы Microsoft Power Point Операции, операторы, операнды
Операции, операторы, операнды Обработка текстовой информации
Обработка текстовой информации Типы* языка Си. Лекция 3
Типы* языка Си. Лекция 3 Информационно-коммуникационные технологии. Лекция №13. Электронное обучение (с переводом на английский язык)
Информационно-коммуникационные технологии. Лекция №13. Электронное обучение (с переводом на английский язык) урок информатики по учебнику Плаксина М.А. тема Как управлять компьютером с помощью клавиатуры
урок информатики по учебнику Плаксина М.А. тема Как управлять компьютером с помощью клавиатуры Системное программное обеспечение
Системное программное обеспечение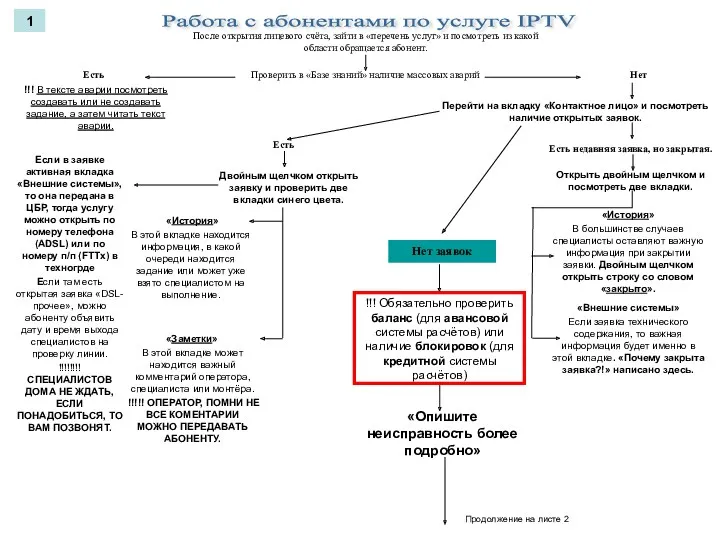 Алгоритм работы с IPTV
Алгоритм работы с IPTV Цветове в HTML
Цветове в HTML STL Algorithm
STL Algorithm Lms.synergy.ru - личный кабинет студента Университета Синергия
Lms.synergy.ru - личный кабинет студента Университета Синергия История развития вычислительной техники
История развития вычислительной техники