- Основные понятия баз данных. Лекция 1

Содержание
- 2. Тема 1. Введение в курс «Базы данных» Лекция 1
- 3. История возникновения баз данных Основные термины и определения Классификация СУБД Перспективы развития БД Вопросы лекции:
- 4. Веллинг Л., Томсон Л. MySQL. Учебное пособие: Пер. с англ. – М.: Издательский дом «Вильямс», 2005.
- 5. Дейт, К. Дж. Введение в системы баз данных. Вильямс, 2002. - 1071 с. Диго С.М. Базы
- 6. Кузнецов М.В. MySQL 5 / М. В. Кузнецов, И. В. Симдянов. – СПб.: БХВ-Петербург, 2010. –
- 7. Золотой фонд компьютерной литературы Дейт, К. Дж. Введение в системы баз данных 8-е издание.: Пер. с
- 8. Базы данных. Вводный курс. Кузнецов С. Д. URL: http://citforum.ru/database/advanced_intro. Интерактивный учебник по SQL. URL: http://www.sql-tutorial.ru. Национальный
- 9. Национальный Открытый Университет «ИНТУИТ». Назаров А. Введение в СУБД MySQL. URL: http://www.intuit.ru/studies/courses/111/111/info. Национальный Открытый Университет «ИНТУИТ».
- 10. Справочное руководство по MySQL. URL: http://www.mysql.ru/docs/man. Справочник по MySQL. URL: http://www.spravkaweb.ru/mysql. Справочник по языкам SQL Server.
- 11. История возникновения баз данных
- 12. Применение компьютерной техники Использование средств вычислительной техники в автоматических или автоматизированных информационных системах является одним из
- 13. Этапы развития БД. Этап 0. Файловые системы Магнитные диски впервые были реализованы в 1956 году в
- 14. Этапы развития БД. Этап 0. Файловые системы Магнитные диски впервые были реализованы в 1956 году в
- 15. Фа́йловая систе́ма — порядок, определяющий формат содержимого и способ физического хранения информации, которую принято группировать в
- 16. Недостатки применение файловых систем для хранения и обработки данных в информационных системах: Избыточность данных. Из-за дублирования
- 17. Этапы развития БД. Этап 1. Базы данных на больших ЭВМ 1960–1980 гг. Получаемые в результате библиотеки,
- 18. Этапы развития БД. Этап 1. Базы данных на больших ЭВМ 1960–1980 гг. На сегодняшний день история
- 19. IBM System/360
- 20. Этапы развития БД. Этап 2. Настольные (desktop) СУБД 1975 – 1995 гг. Звание первого персонального компьютера
- 21. Этапы развития БД. Этап 2. Настольные (desktop) СУБД 1975 – 1995 гг. Спрос на развитые удобные
- 22. Этапы развития БД. Этап 2. Настольные (desktop) СУБД 1975 – 1995 гг. Основанные на реляционном подходе
- 23. Главное ограничение при работе с настольными СУБД накладывалось монопольным доступом, поскольку первое время персональные компьютеры не
- 24. Этапы развития БД. Этап 3. Распределенные базы данных с 1985 по наст. вр. Третий этап развития
- 25. Эволюция архитектуры информационных систем 1-й этап. Монолитная архитектура (mainframe), когда и база данных, и приложения работали
- 26. РЕЗЮМЕ История развития баз данных насчитывает более 50 лет. Условно выделяют три этапа. При этом между
- 27. Основные термины и определения
- 28. Основные термины и определения База данных (БД) представляет собой совокупность специальным образом организованных данных, хранимых в
- 29. Основные термины и определения В части четвертой «Гражданского кодекса Российской Федерации» дается следующее определение базы данных:
- 30. Основные термины и определения Данные (data – факт) – это совокупность сведений, зафиксированных на определенном носителе
- 31. Система управления базами данных (СУБД) – это комплекс языковых и программных средств, предназначенный для создания, ведения
- 32. Система управления базами данных (СУБД) – это комплекс языковых и программных средств, предназначенный для создания, ведения
- 33. СУБД на рынке, прошлое и настоящее 15 лет назад - большая четверка коммерческих СУБД – Oracle,
- 34. Основные термины и определения Структурирование – это введение соглашений о способах представления данных. Создавая базу данных,
- 35. Основные термины и определения По степени структурированности выделяют следующие формы представления данных: неструктурированные структурированные слабоструктурированные К
- 36. Основные термины и определения Структурированные данные отражают отдельные факты предметной области. Структурированными называются данные, определенным образом
- 37. Основные термины и определения Одной из самых распространенных моделей хранения структурированных данных является таблица. В ней
- 38. Основные термины и определения Неструктурированные данные непригодны для обработки напрямую методами анализа данных, поэтому такие данные
- 39. Личное дело № 16493, Сергеев Петр Михайлович, дата рождения 1 января 1976 г.; Л/д № 16593,
- 40. Основные термины и определения Слабоструктурированные данные — это данные, для которых определены некоторые правила и форматы,
- 41. Основные термины и определения Целостность БД — соответствие имеющейся в базе данных информации её внутренней логике,
- 42. Классификация СУБД и БД
- 43. Классификация СУБД и БД По сфере возможного применения: универсальные Пример: МS Access, PostgreSQL. специализированные (проблемно-ориентированные) СУБД
- 44. Классификация СУБД По «мощности» СУБД делятся на: «Настольные» – невысокие требования к техническим средствам, ориентация на
- 45. Корпоративные СУБД, как правило, реализуют архитектуру клиент-сервер. Помимо хранения централизованной базы данных центральная машина – сервер
- 46. Классификация СУБД По характеру использования СУБД делятся на: Персональные. Обеспечивают возможность создания персональных БД и недорогих
- 47. Классификация СУБД По степени доступности БД выделяют: Общедоступные БД. Примеры: Банк документов на сайте Президента Российской
- 48. Классификация СУБД По способу доступа к БД выделяют: Файл-серверные СУБД. Примеры: Microsoft Access, Paradox, dBase, FoxPro,
- 49. Классификация СУБД В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском
- 50. Классификация СУБД Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно,
- 51. Классификация СУБД По форме представляемой информации выделяют фактографические, документальные, мультимедийные БД. фактографические БД, в которых хранится
- 52. Классификация СУБД По форме представляемой информации выделяют: документальные БД. Единицей хранения является какой-либо документ (например, текст
- 53. Классификация СУБД По типологии хранения – локальные и распределенные. По функциональному назначению (характеру решаемых задач и,
- 54. Классификация СУБД и БД По способу распространения: Commercial Software — коммерческие (с ограниченными лицензией возможностями на
- 55. По характеру преобладающей обработки информации: ОLTP (On-Line Transaction Processing) – системы оперативной обработки информации OLAP (On-Line
- 56. По используемой Модели данных Иерархические Сетевые Реляционные Объектно-ориентированные Объектно-реляционные NoSQL: “Ключ-значение” Документные Поколоночные (столбцовые) … Классификация
- 57. Перспективы развития баз данных
- 58. Технология In-Memory появилась в версии Oracle Database 12.1.0.2. Суть ее заключается в том, что рядом привычным
- 59. В обычном буферном кэше информация хранится по строкам. Вот пример — из четырехколоночной таблицы нужно извлечь
- 60. Технология SPARC принадлежит Oracle уже пять лет. За это время корпорация Oracle выпустила микропроцессоры SPARC ТЗ,
- 61. SPARC М7 - первый процессор, который полностью, начиная с идеологии и базового дизайна, разрабатывался Oracle и
- 62. Если сравнить параметры микропроцессора SPARC M7 с параметрами самого совершенного выпущенного ранее процессора SPARC T5, обнаружится,
- 63. Исторический революционный шаг, сделанный Oracle новым процессором, — это реализация программных функций непосредственно на кристалле. Это
- 64. Количество похищенных строк данных в мире за 2014 год, согласно отчету CSO Online Market Pulse, составило
- 65. Процессор SPARC М7 обладает уникальной функциональностью, позволяющей обеспечить прозрачное шифрование данных с использованием 15 наиболее известных
- 66. Системы на базе SPARC M7 предлагают также аппаратную поддержку безопасной миграции доменов. В процессе миграции виртуальная
- 67. Большинство вирусов для систем RISC/UNIX пытаются напрямую адресовать память за рамками отведенных им буферов, и используют
- 68. SQL in Silicon — обработка запросов к базе данных, реализованная непосредственно на процессоре. В процессоре SPARC
- 69. Максимальный результат, достигнутый на внутренних тестах Oracle, составил 170 млрд строк в секунду на процессорах SPARC
- 70. В результате аналитика на SPARC M7 работает более чем в восемь раз быстрее, чем на системной
- 72. Скачать презентацию

Тема 1. Введение в курс
«Базы данных»
Лекция 1
Тема 1. Введение в курс
«Базы данных»
Лекция 1

История возникновения баз данных
Основные термины и определения
Классификация СУБД
Перспективы развития БД
Вопросы лекции:
История возникновения баз данных
Основные термины и определения
Классификация СУБД
Перспективы развития БД
Вопросы лекции:

Веллинг Л., Томсон Л. MySQL. Учебное пособие: Пер. с англ. –
Веллинг Л., Томсон Л. MySQL. Учебное пособие: Пер. с англ. –

Дейт, К. Дж. Введение в системы баз данных. Вильямс, 2002. -
Дейт, К. Дж. Введение в системы баз данных. Вильямс, 2002. -

Кузнецов М.В. MySQL 5 / М. В. Кузнецов, И. В. Симдянов.
Кузнецов М.В. MySQL 5 / М. В. Кузнецов, И. В. Симдянов.

Золотой фонд компьютерной литературы
Дейт, К. Дж.
Введение в системы баз данных
8-е издание.:
Золотой фонд компьютерной литературы
Дейт, К. Дж.
Введение в системы баз данных
8-е издание.:

Базы данных. Вводный курс. Кузнецов С. Д. URL: http://citforum.ru/database/advanced_intro.
Интерактивный учебник по
Базы данных. Вводный курс. Кузнецов С. Д. URL: http://citforum.ru/database/advanced_intro.
Интерактивный учебник по

Национальный Открытый Университет «ИНТУИТ». Назаров А. Введение в СУБД MySQL. URL:
Национальный Открытый Университет «ИНТУИТ». Назаров А. Введение в СУБД MySQL. URL:

Справочное руководство по MySQL. URL: http://www.mysql.ru/docs/man.
Справочник по MySQL. URL: http://www.spravkaweb.ru/mysql.
Справочник по
Справочное руководство по MySQL. URL: http://www.mysql.ru/docs/man.
Справочник по MySQL. URL: http://www.spravkaweb.ru/mysql.
Справочник по

История возникновения баз данных
История возникновения баз данных
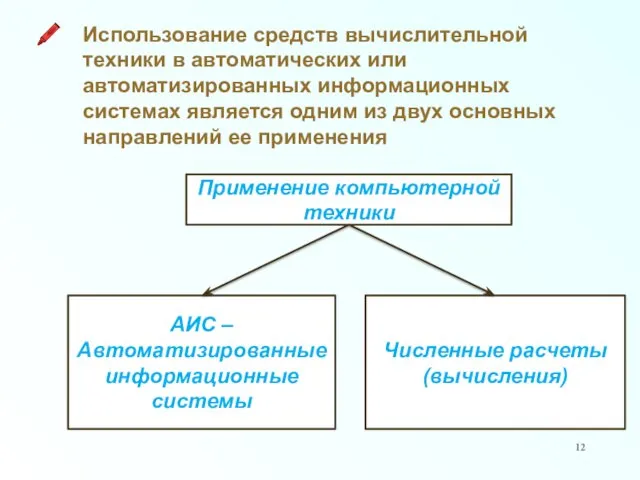
Применение компьютерной техники
Использование средств вычислительной техники в автоматических или автоматизированных информационных
Использование средств вычислительной техники в автоматических или автоматизированных информационных

Этапы развития БД.
Этап 0. Файловые системы
Магнитные диски впервые были реализованы
Этапы развития БД.
Этап 0. Файловые системы
Магнитные диски впервые были реализованы

Этапы развития БД.
Этап 0. Файловые системы
Магнитные диски впервые были реализованы
Этапы развития БД.
Этап 0. Файловые системы
Магнитные диски впервые были реализованы

Фа́йловая систе́ма — порядок, определяющий формат содержимого и способ физического хранения информации, которую

Недостатки применение файловых систем для хранения и обработки данных в информационных
Недостатки применение файловых систем для хранения и обработки данных в информационных

Этапы развития БД.
Этап 1. Базы данных на больших ЭВМ 1960–1980
Этапы развития БД.
Этап 1. Базы данных на больших ЭВМ 1960–1980

Этапы развития БД.
Этап 1. Базы данных на больших ЭВМ 1960–1980
Этапы развития БД.
Этап 1. Базы данных на больших ЭВМ 1960–1980

IBM System/360
IBM System/360

Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995
Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995

Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995
Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995

Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995
Этапы развития БД.
Этап 2. Настольные (desktop) СУБД 1975 – 1995

Главное ограничение при работе с настольными СУБД накладывалось монопольным доступом, поскольку
Главное ограничение при работе с настольными СУБД накладывалось монопольным доступом, поскольку

Этапы развития БД.
Этап 3. Распределенные базы данных с 1985 по
Этапы развития БД.
Этап 3. Распределенные базы данных с 1985 по
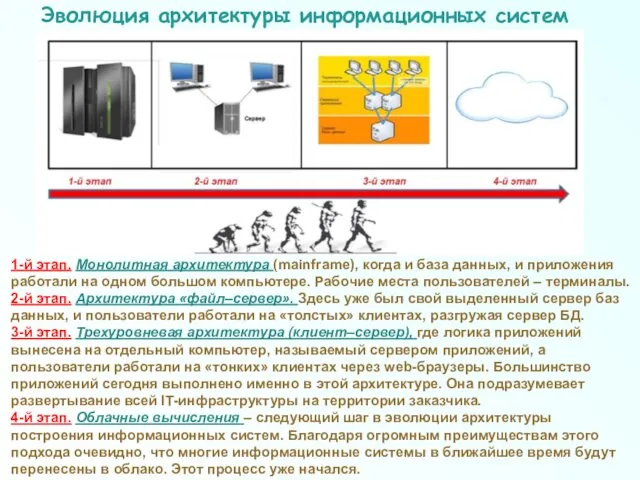
Эволюция архитектуры информационных систем
1-й этап. Монолитная архитектура (mainframe), когда и база
Эволюция архитектуры информационных систем
1-й этап. Монолитная архитектура (mainframe), когда и база

РЕЗЮМЕ
История развития баз данных насчитывает более 50 лет.
Условно выделяют три этапа.
РЕЗЮМЕ
История развития баз данных насчитывает более 50 лет.
Условно выделяют три этапа.

Основные термины и определения
Основные термины и определения

Основные термины и определения
База данных (БД) представляет собой совокупность специальным образом
Основные термины и определения
База данных (БД) представляет собой совокупность специальным образом

Основные термины и определения
В части четвертой «Гражданского кодекса Российской Федерации» дается
Основные термины и определения
В части четвертой «Гражданского кодекса Российской Федерации» дается

Основные термины и определения
Данные (data – факт) – это совокупность сведений,
Основные термины и определения
Данные (data – факт) – это совокупность сведений,
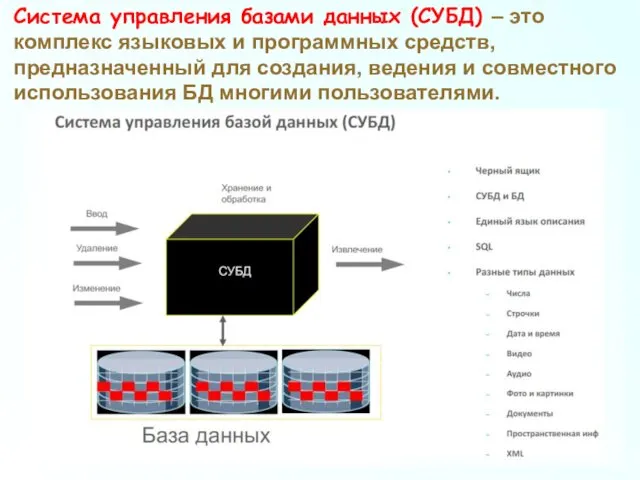
Система управления базами данных (СУБД) – это комплекс языковых и программных
Система управления базами данных (СУБД) – это комплекс языковых и программных

Система управления базами данных (СУБД) – это комплекс языковых и программных
Система управления базами данных (СУБД) – это комплекс языковых и программных

СУБД на рынке, прошлое и настоящее
15 лет назад - большая четверка
СУБД на рынке, прошлое и настоящее
15 лет назад - большая четверка

Основные термины и определения
Структурирование – это введение соглашений о способах представления
Основные термины и определения
Структурирование – это введение соглашений о способах представления

Основные термины и определения
По степени структурированности выделяют следующие формы представления данных:
неструктурированные
Основные термины и определения
По степени структурированности выделяют следующие формы представления данных:
неструктурированные

Основные термины и определения
Структурированные данные отражают отдельные факты предметной области. Структурированными
Основные термины и определения
Структурированные данные отражают отдельные факты предметной области. Структурированными
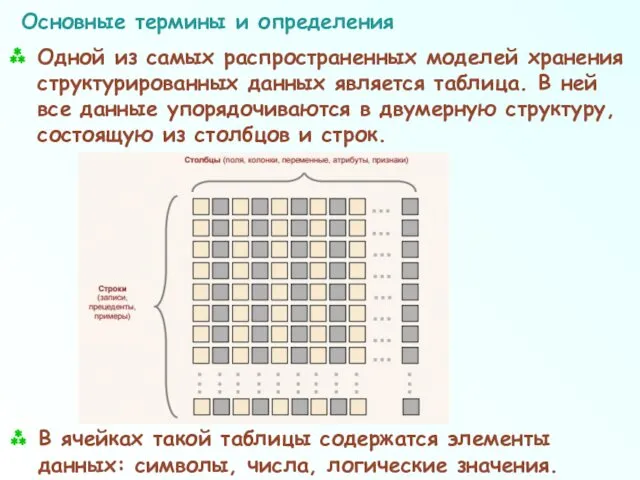
Основные термины и определения
Одной из самых распространенных моделей хранения структурированных данных
Основные термины и определения
Одной из самых распространенных моделей хранения структурированных данных

Основные термины и определения
Неструктурированные данные непригодны для обработки напрямую методами анализа
Основные термины и определения
Неструктурированные данные непригодны для обработки напрямую методами анализа
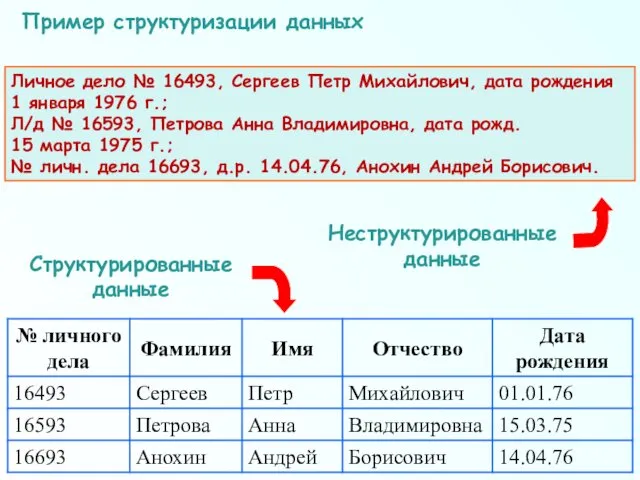
Личное дело № 16493, Сергеев Петр Михайлович, дата рождения
1 января
Личное дело № 16493, Сергеев Петр Михайлович, дата рождения 1 января

Основные термины и определения
Слабоструктурированные данные — это данные, для которых определены
Основные термины и определения
Слабоструктурированные данные — это данные, для которых определены

Основные термины и определения
Целостность БД — соответствие имеющейся в базе данных
Основные термины и определения
Целостность БД — соответствие имеющейся в базе данных

Классификация СУБД и БД
Классификация СУБД и БД

Классификация СУБД и БД
По сфере возможного применения:
универсальные
Пример: МS Access, PostgreSQL.
Классификация СУБД и БД
По сфере возможного применения:
универсальные
Пример: МS Access, PostgreSQL.

Классификация СУБД
По «мощности» СУБД делятся на:
«Настольные» – невысокие требования к
Классификация СУБД
По «мощности» СУБД делятся на:
«Настольные» – невысокие требования к
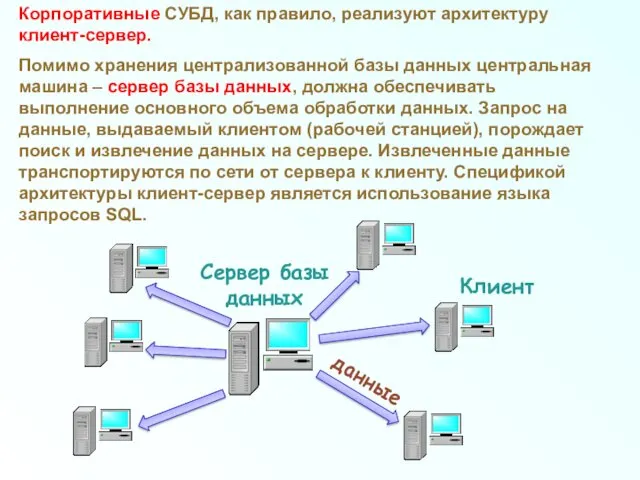
Корпоративные СУБД, как правило, реализуют архитектуру клиент-сервер.
Помимо хранения централизованной базы данных
Корпоративные СУБД, как правило, реализуют архитектуру клиент-сервер.
Помимо хранения централизованной базы данных

Классификация СУБД
По характеру использования СУБД делятся на:
Персональные. Обеспечивают возможность создания
Классификация СУБД
По характеру использования СУБД делятся на:
Персональные. Обеспечивают возможность создания

Классификация СУБД
По степени доступности БД выделяют:
Общедоступные БД.
Примеры: Банк документов
Классификация СУБД
По степени доступности БД выделяют:
Общедоступные БД.
Примеры: Банк документов

Классификация СУБД
По способу доступа к БД выделяют:
Файл-серверные СУБД.
Примеры: Microsoft
Классификация СУБД
По способу доступа к БД выделяют:
Файл-серверные СУБД.
Примеры: Microsoft

Классификация СУБД
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД
Классификация СУБД
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД

Классификация СУБД
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет
Классификация СУБД
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет

Классификация СУБД
По форме представляемой информации выделяют фактографические, документальные, мультимедийные БД.
фактографические
Классификация СУБД
По форме представляемой информации выделяют фактографические, документальные, мультимедийные БД.
фактографические

Классификация СУБД
По форме представляемой информации выделяют:
документальные БД. Единицей хранения является
Классификация СУБД
По форме представляемой информации выделяют:
документальные БД. Единицей хранения является

Классификация СУБД
По типологии хранения – локальные и распределенные.
По функциональному назначению (характеру
Классификация СУБД
По типологии хранения – локальные и распределенные.
По функциональному назначению (характеру

Классификация СУБД и БД
По способу распространения:
Commercial Software — коммерческие (с
Классификация СУБД и БД
По способу распространения:
Commercial Software — коммерческие (с
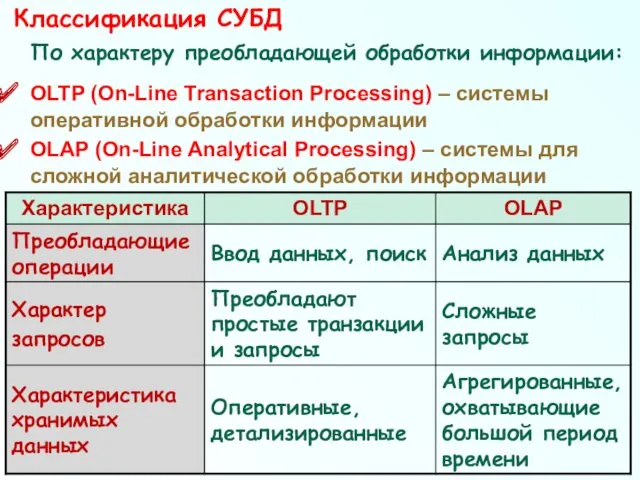
По характеру преобладающей обработки информации:
ОLTP (On-Line Transaction Processing) – системы
По характеру преобладающей обработки информации:
ОLTP (On-Line Transaction Processing) – системы

По используемой Модели данных
Иерархические
Сетевые
Реляционные
Объектно-ориентированные
Объектно-реляционные
NoSQL:
“Ключ-значение”
Документные
Поколоночные (столбцовые)
…
Классификация СУБД
По используемой Модели данных
Иерархические
Сетевые
Реляционные
Объектно-ориентированные
Объектно-реляционные
NoSQL:
“Ключ-значение”
Документные
Поколоночные (столбцовые)
…
Классификация СУБД

Перспективы развития
баз данных
Перспективы развития
баз данных
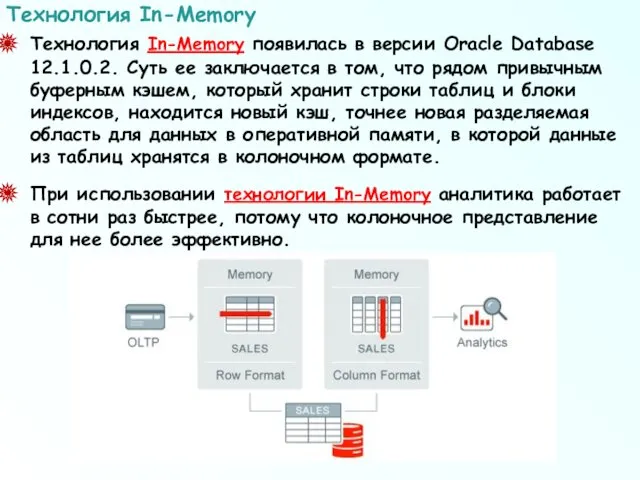
Технология In-Memory появилась в версии Oracle Database 12.1.0.2. Суть ее заключается
Технология In-Memory появилась в версии Oracle Database 12.1.0.2. Суть ее заключается

В обычном буферном кэше информация хранится по строкам.
Вот пример —
В обычном буферном кэше информация хранится по строкам. Вот пример —

Технология SPARC принадлежит Oracle уже пять лет. За это время корпорация
Технология SPARC принадлежит Oracle уже пять лет. За это время корпорация

SPARC М7 - первый процессор, который полностью, начиная с идеологии и
SPARC М7 - первый процессор, который полностью, начиная с идеологии и
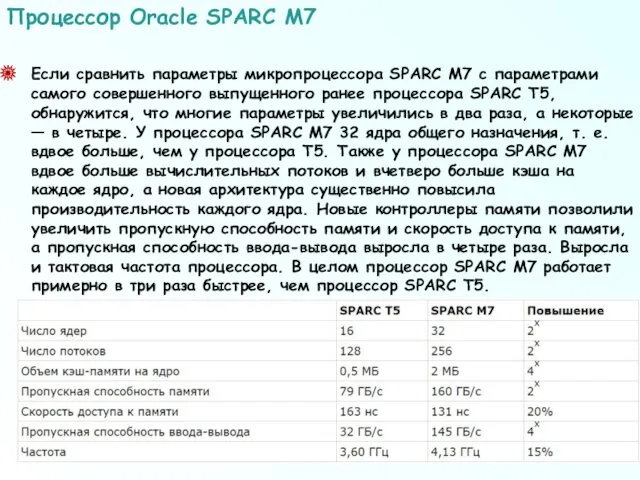
Если сравнить параметры микропроцессора SPARC M7 с параметрами самого совершенного выпущенного
Если сравнить параметры микропроцессора SPARC M7 с параметрами самого совершенного выпущенного

Исторический революционный шаг, сделанный Oracle новым процессором, — это реализация программных
Исторический революционный шаг, сделанный Oracle новым процессором, — это реализация программных

Количество похищенных строк данных в мире за 2014 год, согласно отчету
Количество похищенных строк данных в мире за 2014 год, согласно отчету
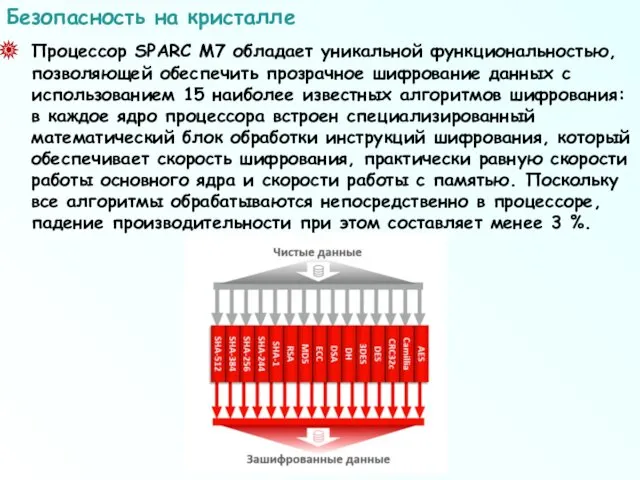
Процессор SPARC М7 обладает уникальной функциональностью, позволяющей обеспечить прозрачное шифрование данных
Процессор SPARC М7 обладает уникальной функциональностью, позволяющей обеспечить прозрачное шифрование данных

Системы на базе SPARC M7 предлагают также аппаратную поддержку безопасной миграции
Системы на базе SPARC M7 предлагают также аппаратную поддержку безопасной миграции

Большинство вирусов для систем RISC/UNIX пытаются напрямую адресовать память за рамками
Большинство вирусов для систем RISC/UNIX пытаются напрямую адресовать память за рамками

SQL in Silicon — обработка запросов к базе данных, реализованная непосредственно
SQL in Silicon — обработка запросов к базе данных, реализованная непосредственно

Максимальный результат, достигнутый на внутренних тестах Oracle, составил 170 млрд строк
Максимальный результат, достигнутый на внутренних тестах Oracle, составил 170 млрд строк

В результате аналитика на SPARC M7 работает более чем в восемь
В результате аналитика на SPARC M7 работает более чем в восемь
 Основы программирования на языке Python
Основы программирования на языке Python Ads-Residual is a company specialized in online advertising
Ads-Residual is a company specialized in online advertising Электронная таблица (табличный процессор)
Электронная таблица (табличный процессор) Цели и задачи введения в школу предмета Информатика
Цели и задачи введения в школу предмета Информатика Начальные сведения о языке Turbo Pascal
Начальные сведения о языке Turbo Pascal Операционные системы. Файловые системы (часть 1)
Операционные системы. Файловые системы (часть 1) Руководство пользователя для онлайн-курса ГПА
Руководство пользователя для онлайн-курса ГПА Функции в PHP
Функции в PHP Что такое компьютерная программа?
Что такое компьютерная программа? Середовище описання і виконання алгоритмів
Середовище описання і виконання алгоритмів Виртуальная реальность. Virtual reality
Виртуальная реальность. Virtual reality Высокоуровневые методы информатики и программирования. UML - язык моделирования и документирования сложных систем
Высокоуровневые методы информатики и программирования. UML - язык моделирования и документирования сложных систем Сервисы компании Такском
Сервисы компании Такском Шифрование и дешифрование матрицы с использованием ключа
Шифрование и дешифрование матрицы с использованием ключа Система контроля версий Git
Система контроля версий Git Створення, редагування та форматування символів, колонок, списків в текстовому документі. Недруковані знаки
Створення, редагування та форматування символів, колонок, списків в текстовому документі. Недруковані знаки Иллюстрированные правила игры. Twilight imperium 3rd edition
Иллюстрированные правила игры. Twilight imperium 3rd edition Безопасная дорога в интернет
Безопасная дорога в интернет Арифметические операции в позиционных системах счисления
Арифметические операции в позиционных системах счисления Копирайтинг 3.0. День 2
Копирайтинг 3.0. День 2 Личный кабинет студента Новосибирского государственного технического университета
Личный кабинет студента Новосибирского государственного технического университета Тематический библиографический список, как одна из форм библиографических пособий малых форм
Тематический библиографический список, как одна из форм библиографических пособий малых форм Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10
Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10 Вручение РПО (упрощенное вручение)
Вручение РПО (упрощенное вручение) Проектирование интерфейса пользователя
Проектирование интерфейса пользователя Хранилища данных. (Лекция 1)
Хранилища данных. (Лекция 1) Компьютерная анимация
Компьютерная анимация Виртуальный тур по университету СибГИУ
Виртуальный тур по университету СибГИУ