- Основы программирования. Хеширование

Содержание
- 2. Хеширование Хеширование (хэширование) – это преобразование входного массива данных определенного типа и произвольной длины в выходную
- 3. Хеш-таблицы Хеш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она позволяет хранить пары
- 4. Области применения хеширования Базы данных Языковые процессоры (компиляторы, ассемблеры) – повышение скорости обработки таблицы идентификаторов Распределение
- 5. Прямая адресация U = {0, 1, …, m-1} – множество ключей T [0 .. m-1] –
- 6. Хеш-таблицы Недостатки прямой адресации: Пространство ключей U велико, хранение таблицы размера |U| непрактично |K| Требования к
- 7. Хеш-таблицы и коллизии Коллизия – ситуация, когда два ключа хешированы в одну и ту же ячейку
- 8. Коллизии Существует множество пар “ключ - значение”, дающих одинаковые хеш-коды. В этом случае возникает коллизия. Вероятность
- 9. Требования к хеш-функциям С точки зрения практического применения, хорошей является такая хеш-функция, которая удовлетворяет следующим условиям:
- 10. Методы создания хеш-функций: остатков от деления; функции середины квадрата; свертки; преобразования системы счисления.
- 11. Метод остатков от деления Остаток от деления целочисленного ключа Key на размерность массива HashTableSize: Key %
- 12. Метод остатков от деления. Пример Пусть ключом является символьная строка. Тогда хеш-код для нее – это
- 13. Функция середины квадрата преобразует значение ключа в число, возводит это число в квадрат, из полученного числа
- 14. Метод свертки Цифровое представление ключа разбивается на части, каждая из которых имеет длину, равную длине требуемого
- 15. Функция преобразования системы счисления Ключ, записанный как число в системе счисления с основанием P, интерпретируется как
- 16. МЕТОДЫ РАЗРЕШЕНИЯ КОЛЛИЗИЙ Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия между хеш-кодами и данными.
- 17. Открытое (внешнее) хеширование потенциальное множество (возможно, бесконечное) разбивается на конечное число классов; для B классов, пронумерованных
- 18. МЕТОД ЦЕПОЧЕК Технология сцепления элементов состоит в том, что элементы множества, которым соответствует одно и то
- 19. Разрешение коллизии при помощи цепочек (открытое хеширование) Chained_Hash_Insert( T, x) Вставить x в заголовок списка T
- 22. При предположении, что каждый элемент может попасть в любую позицию таблицы с равной вероятностью и независимо
- 30. Открытое хеширование (пример)
- 32. Скачать презентацию

Хеширование
Хеширование (хэширование) – это преобразование входного массива данных определенного типа и
Хеширование
Хеширование (хэширование) – это преобразование входного массива данных определенного типа и

Хеш-таблицы
Хеш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть
Хеш-таблицы
Хеш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть

Области применения хеширования
Базы данных
Языковые процессоры (компиляторы, ассемблеры) – повышение скорости обработки
Области применения хеширования
Базы данных
Языковые процессоры (компиляторы, ассемблеры) – повышение скорости обработки
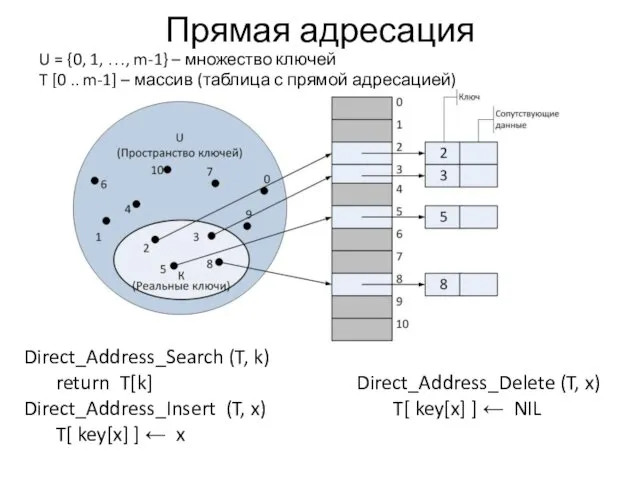
Прямая адресация
U = {0, 1, …, m-1} – множество ключей
T [0
Прямая адресация
U = {0, 1, …, m-1} – множество ключей
T [0

Хеш-таблицы
Недостатки прямой адресации:
Пространство ключей U велико, хранение таблицы размера |U| непрактично
|K|
Хеш-таблицы
Недостатки прямой адресации:
Пространство ключей U велико, хранение таблицы размера |U| непрактично
|K|
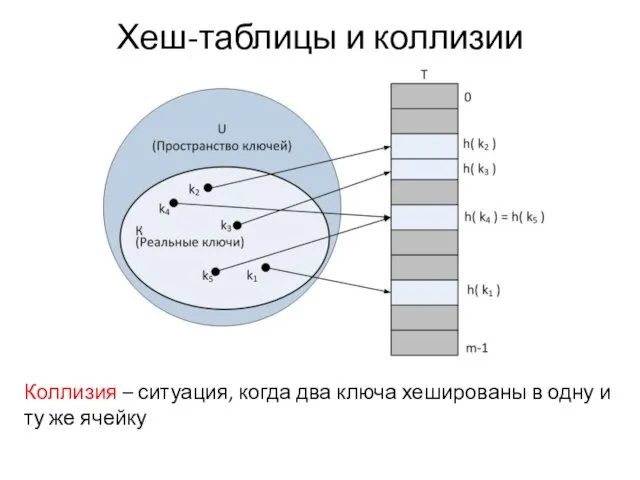
Хеш-таблицы и коллизии
Коллизия – ситуация, когда два ключа хешированы в одну
Хеш-таблицы и коллизии
Коллизия – ситуация, когда два ключа хешированы в одну

Коллизии
Существует множество пар “ключ - значение”, дающих одинаковые хеш-коды. В этом
Коллизии
Существует множество пар “ключ - значение”, дающих одинаковые хеш-коды. В этом

Требования к хеш-функциям
С точки зрения практического применения, хорошей является такая хеш-функция,
Требования к хеш-функциям
С точки зрения практического применения, хорошей является такая хеш-функция,

Методы создания хеш-функций:
остатков от деления;
функции середины квадрата;
свертки;
преобразования системы счисления.
Методы создания хеш-функций:
остатков от деления;
функции середины квадрата;
свертки;
преобразования системы счисления.

Метод остатков от деления
Остаток от деления целочисленного ключа Key на размерность
Метод остатков от деления
Остаток от деления целочисленного ключа Key на размерность

Метод остатков от деления. Пример
Пусть ключом является символьная строка.
Тогда хеш-код для
Метод остатков от деления. Пример
Пусть ключом является символьная строка.
Тогда хеш-код для

Функция середины квадрата
преобразует значение ключа в число,
возводит это число в квадрат,
из
Функция середины квадрата
преобразует значение ключа в число,
возводит это число в квадрат,
из

Метод свертки
Цифровое представление ключа разбивается на части, каждая из которых имеет
Метод свертки
Цифровое представление ключа разбивается на части, каждая из которых имеет

Функция преобразования системы счисления
Ключ, записанный как число в системе счисления с
Функция преобразования системы счисления
Ключ, записанный как число в системе счисления с

МЕТОДЫ РАЗРЕШЕНИЯ КОЛЛИЗИЙ
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия
МЕТОДЫ РАЗРЕШЕНИЯ КОЛЛИЗИЙ
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия

Открытое (внешнее) хеширование
потенциальное множество (возможно, бесконечное) разбивается на конечное число классов;
для
Открытое (внешнее) хеширование
потенциальное множество (возможно, бесконечное) разбивается на конечное число классов;
для

МЕТОД ЦЕПОЧЕК
Технология сцепления элементов состоит в том, что элементы множества, которым
МЕТОД ЦЕПОЧЕК
Технология сцепления элементов состоит в том, что элементы множества, которым
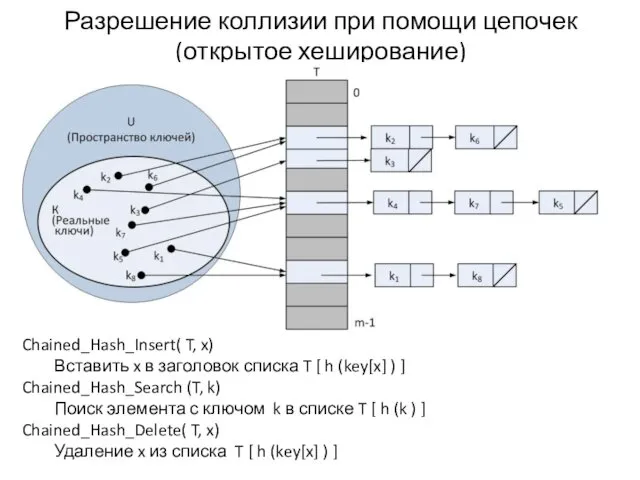
Разрешение коллизии при помощи цепочек (открытое хеширование)
Chained_Hash_Insert( T, x)
Вставить x в
Разрешение коллизии при помощи цепочек (открытое хеширование)
Chained_Hash_Insert( T, x)
Вставить x в
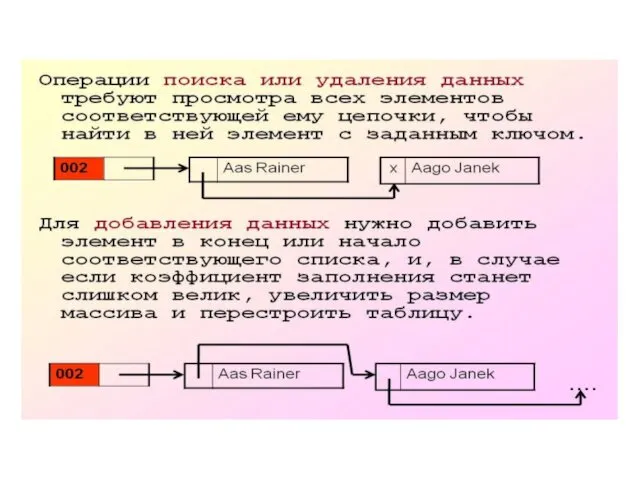

При предположении, что каждый элемент может попасть в любую позицию таблицы
При предположении, что каждый элемент может попасть в любую позицию таблицы







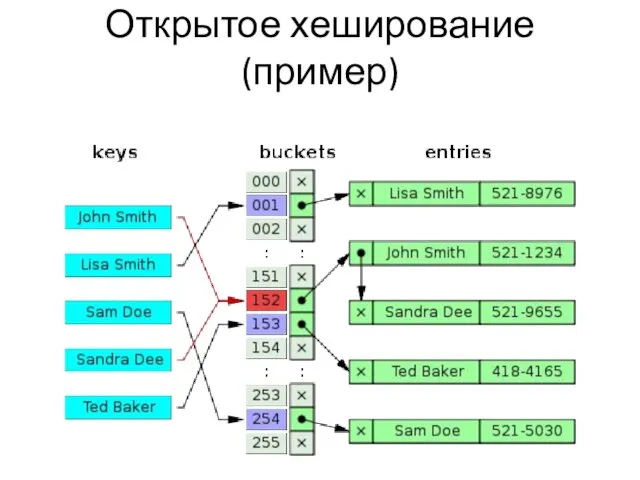
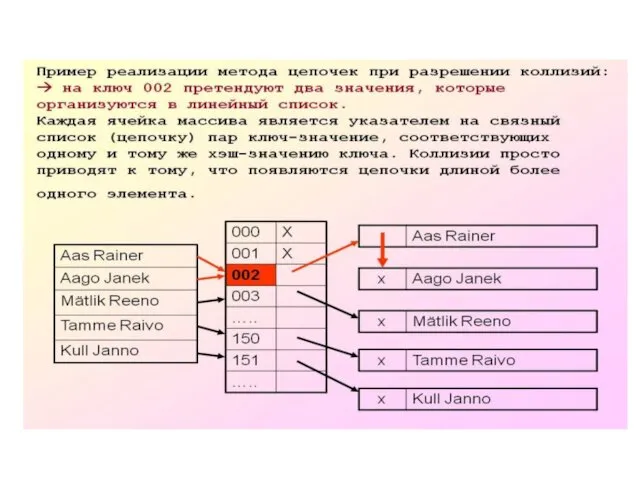
Открытое хеширование (пример)
Открытое хеширование (пример)
 Элементы алгебры логики. Математические основы информатики. Информатика. 8 класс
Элементы алгебры логики. Математические основы информатики. Информатика. 8 класс Комп’ютерна логіка (частина 1)
Комп’ютерна логіка (частина 1) Образовательный видео сервис
Образовательный видео сервис IBM Project Specific Training on bp account
IBM Project Specific Training on bp account The Culture app
The Culture app Информационная безопасность и её составляющие
Информационная безопасность и её составляющие Графический редактор PAINT
Графический редактор PAINT Модель Software Maintenance Maturity Model (SMMM)
Модель Software Maintenance Maturity Model (SMMM) Создание мини – сайта учителем
Создание мини – сайта учителем Синтаксис внешних объявлений. Верхний уровень грамматики языка С
Синтаксис внешних объявлений. Верхний уровень грамматики языка С Презентация урока по теме Форматирование документов
Презентация урока по теме Форматирование документов Уровень приложений
Уровень приложений Виртуальная и дополненная реальность
Виртуальная и дополненная реальность Нечеткая логика
Нечеткая логика Updated flow
Updated flow Службы сети интернет
Службы сети интернет Процедуры и функции ТР (Подпрограммы)
Процедуры и функции ТР (Подпрограммы) Научные открытия: от знания к ценностям. История счета и систем счисления. 6 класс
Научные открытия: от знания к ценностям. История счета и систем счисления. 6 класс Базы данных. Тестирование
Базы данных. Тестирование Сущность и виды электронных денег. Криптовалюты
Сущность и виды электронных денег. Криптовалюты Что такое обстановка, ее установка
Что такое обстановка, ее установка Таблиці, електронні таблиці. Табличний процесор, його призначення. Об'єкти електронної таблиці, їх властивості
Таблиці, електронні таблиці. Табличний процесор, його призначення. Об'єкти електронної таблиці, їх властивості Security. The goal
Security. The goal Множества и логика в задачах ЕГЭ по информатике
Множества и логика в задачах ЕГЭ по информатике Логические операторы if и switch. Язык С. Лекция 3
Логические операторы if и switch. Язык С. Лекция 3 EXCEL Встроенные функции
EXCEL Встроенные функции Среда Visual Basic. Основные понятия VB
Среда Visual Basic. Основные понятия VB Информатика. логика
Информатика. логика