- Основы современных операционных систем

Содержание
- 2. Взаимодействующие (cooperating) процессы Независимый процесс – не может влиять на исполнение других процессов и испытывать их
- 3. Виды процессов Подчиненный – зависит от процесса-родителя; уничтожается при его уничтожении; процесс-родитель должен ожидать завершения всех
- 4. Проблема “производитель-потребитель” (producer – consumer) Одна из парадигм взаимодействия процессов: процесс-производитель (producer) генерирует информацию, которая используется
- 5. Ограниченный буфер – реализация с помощью общей памяти Общие данные #define BUFFER_SIZE 10 typedef struct {
- 6. Ограниченный буфер: процесс-производитель item nextProduced; while (1) { while (((in + 1) % BUFFER_SIZE) == out)
- 7. Ограниченный буфер: процесс-потребитель item nextConsumed; while (1) { while (in == out) ; /* do nothing
- 8. Коммуникация процессов Механизм для коммуникации процессов и синхронизации их действий. Система сообщений – процессы взаимодействуют между
- 9. Если P и Q требуется взаимодействовать между собой, им необходимо: Установить связь (communication link) друг с
- 10. Реализация коммуникации процессов Как устанавливается связь? Можно ли установить связь более чем двух процессов? Сколько связей
- 11. Прямая связь (direct communication) Процессы именуют друг друга явно: send (P, message) – послать сообщение процессу
- 12. Косвенная связь (indirect communication) Сообщения направляются и получаются через почтовые ящики (порты) – mailboxes; ports Каждый
- 13. Косвенная связь Операции Создать новый почтовый ящик Отправить (принять) сообщение через почтовый ящик Удалить почтовый ящик
- 14. (C) В.О. Сафонов, 2010 Синхронизация при косвенной связи Передача сообщений может выполняться с блокировкой или без
- 15. Буферизация С коммуникационной линией связывается очередь сообщений, реализованная одним из трех способов: 1. Нулевая емкость –
- 16. Клиент-серверная взаимосвязь Сокеты (Sockets) Удаленные вызовы процедур (Remote Procedure Calls – RPC) Удаленные вызовы методов (Remote
- 17. Сокеты (Sockets) Впервые были реализованы в UNIX BSD 4.2 Сокет можно определить как отправную (конечную) точку
- 18. Взаимодействие с помощью сокетов
- 19. Удаленные вызовы процедур (RPC) RPC впервые предложен фирмой Sun и реализован в ОС Solaris Удаленный вызов
- 20. Исполнение RPC
- 21. (C) В.О. Сафонов, 2010 Удаленный вызов метода (RMI) - Java Remote Method Invocation (RMI) – механизм
- 22. Выстраивание параметров (marshaling)
- 23. Синхронизация процессов История Проблема критической секции Аппаратная поддержка синхронизации Семафоры Классические проблемы синхронизации Критические области Мониторы
- 24. История Совместный доступ к общим данным может привести к нарушению их целостности (inconsistency). Поддержание целостности общих
- 25. Ограниченный буфер: Представление Общие данные #define BUFFER_SIZE 10 typedef struct { . . . } item;
- 26. Ограниченный буфер: Производитель Процесс-производитель item nextProduced; while (1) { while (counter == BUFFER_SIZE) ; /* do
- 27. Ограниченный буфер: Потребитель Процесс-потребитель item nextConsumed; while (1) { while (counter == 0) ; /* do
- 28. Ограниченный буфер: Атомарность операций над counter Операторы counter++; counter--; должны быть выполнены атомарно (atomically). Атомарная операция
- 29. Ограниченный буфер: Реализация операций над counter Оператор “count++” может быть реализован на языке ассемблерного уровня как:
- 30. Ограниченный буфер: Совместное обращение (interleaving) Если и производитель, и потребитель пытаются обратиться к буферу совместно (одновременно),
- 31. Ограниченный буфер: Эффект interleaving Предположим, counter вначале равно 5. Исполнение процессов в совместном режиме (interleaving) приводит
- 32. Конкуренция за общие данные (race condition) Race condition: Ситуация, когда взаимодействующие процессы могут обращаться к общим
- 33. Проблема критической секции n процессов – каждый может обратиться к общим данным Каждый процесс имеет участок
- 34. Решение проблемы критической секции 1. Взаимное исключение. Если процесс Pi исполняет свою критическую секцию, то никакой
- 35. Решение проблемы критической секции 3. Ограниченное ожидание. Должно существовать ограничение на число раз, которое процессам разрешено
- 36. Первоначальные попытки решения проблемы Есть только два процесса, P0 и P1 Общая структура процесса Pi: do
- 37. Алгоритм 1 Общие переменные: int turn; первоначально turn = 0 turn == i процесс Pi
- 38. Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] = flag [1] = false. flag [i]
- 39. Алгоритм 3 Объединяет общие переменные алгоритмов 1 и 2. Процесс Pi : do { flag [i]:=
- 40. Алгоритм булочной (bakery algorithm) – L. Lamport Происхождение названия: реализована стратегия, подобная стратегии обслуживания клиентов в
- 41. Алгоритм булочной do { choosing[i] = true; number[i] = max(number[0], number[1], …, number [n – 1])+1;
- 42. Аппаратная поддержка синхронизации Атомарная операция проверки и модификации значения переменной . boolean TestAndSet(boolean &target) { boolean
- 43. Взаимное исключение с помощью TestAndSet Общие данные: boolean lock = false; Процесс Pi do { while
- 44. Аппаратное решение для синхронизации Атомарная перестановка значений двух переменных. void Swap (boolean * a, boolean *
- 45. Взаимное исключение с помощью Swap Общие данные (инициализируемые false): boolean lock; boolean waiting[n]; Процесс Pi do
- 46. Общие семафоры – counting semaphores (по Э. Дейкстре) Семафоры Средство синхронизации, не требующее активного ожидания. (Общий)
- 47. Критическая секция для N процессов Общие данные: semaphore mutex; //initially mutex = 1 Процесс Pi: do
- 48. Реализация семафора Определяем семафор как структуру: typedef struct { int value; struct process *L; } semaphore;
- 49. Реализация Определим семафорные операции следующим образом: wait(S): S.value--; if (S.value добавить текущий процесс к S.L; block;
- 50. Семафоры как общее средство синхронизации Исполнить действие B в процессе Pj только после того, как действие
- 51. Два типа семафоров Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное Двоичный семафор (Binary semaphore)
- 52. (C) В.О. Сафонов, 2010 Вариант операции wait(S) для системных процессов (“Эльбрус”) Для системного процесса лишние прерывания
- 53. Реализация общего семафора S с помощью двоичных семафоров Структуры данных: binary-semaphore S1, S2; int C: Инициализация:
- 54. Реализация операций над семафором S Операция wait: wait(S1); C--; if (C signal(S1); wait(S2); } signal(S1); Операция
- 55. Классические задачи синхронизации Задача “ограниченный буфер” (Bounded-Buffer Problem) Задача “читатели-писатели” (Readers and Writers Problem) Задача “обедающие
- 56. (C) В.О. Сафонов, 2010 Задача “ограниченный буфер” Общие данные: semaphore full = n; semaphore empty =0;
- 57. Процесс-производитель ограниченного буфера do { … сгенерировать элемент в nextp … wait(empty); wait(mutex); … добавить nextp
- 58. Процесс-потребитель ограниченного буфера do { wait(full) wait(mutex); … взять (и удалить) элемент из буфера в nextc
- 59. Задача “читатели-писатели” Общие данные: semaphore mutex = 1; semaphore wrt = 1; int readcount = 0;
- 60. Процесс-писатель wait(wrt); … выполняется запись … signal(wrt);
- 61. Процесс-читатель wait(mutex); readcount++; if (readcount == 1) wait(rt); signal(mutex); … выполняется чтение … wait(mutex); readcount--; if
- 62. Задача “обедающие философы” Общие данные semaphore chopstick[5] = {1, 1, 1, 1, 1}; Первоначально все значения
- 63. Задача “обедающие философы” Философ i: do { wait(chopstick[i]); wait(chopstick[(i+1) % 5]); … dine … signal(chopstick[i]); signal(chopstick[(i+1)
- 64. Критические области (critical regions) Высокоуровневая конструкция для синхронизации Общая переменная v типа T, определяемая следующим образом:
- 65. (C) В.О. Сафонов, 2010 Пример: ограниченный буфер Общие данные: struct buffer { int pool[n]; int count,
- 66. Процесс-производитель Процесс-производитель добавляет nextp к общему буферу region buffer when (count
- 67. Процесс-потребитель Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc region buffer when (count >
- 68. Реализация оператора region x when B do S Свяжем с общей переменной x следующие переменные: semaphore
- 69. Реализация Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count и second-count. Алгоритм предполагает
- 70. Мониторы (C. A. R. Hoare) Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать доступ к абстрактному типу
- 71. monitor monitor-name { описания общих переменных procedure body P1 (…) { . . . } procedure
- 72. Мониторы: условные переменные Для реализации ожидания процесса внутри монитора, вводятся условные переменные: condition x, y; Условные
- 73. Схематическое представление монитора
- 74. Монитор с условными переменными
- 75. Пример: обедающие философы monitor dp { enum {thinking, hungry, eating} state[5]; condition self[5]; void pickup(int i)
- 76. Обедающие философы: реализация операций pickup и putdown void pickup(int i) { state[i] = hungry; test[i]; if
- 77. Обедающие философы: реализация операции test void test(int i) { if ( (state[(i + 4) % 5]
- 78. Реализация мониторов с помощью семафоров Переменные semaphore mutex; // (initially = 1) semaphore next; // (initially
- 79. Реализация мониторов Для каждой условной переменной x: semaphore x-sem; // (initially = 0) int x-count =
- 80. Реализация мониторов Реализация операции x.signal: if (x-count > 0) { next-count++; signal(x-sem); wait(next); next-count--; }
- 81. (C) В.О. Сафонов, 2010 Реализация мониторов Конструкция conditional-wait: x.wait(c); c – целое выражение, вычисляемое при исполнении
- 83. Скачать презентацию

Взаимодействующие (cooperating) процессы
Независимый процесс – не может влиять на исполнение других
Взаимодействующие (cooperating) процессы
Независимый процесс – не может влиять на исполнение других

Виды процессов
Подчиненный – зависит от процесса-родителя; уничтожается при его уничтожении; процесс-родитель
Виды процессов
Подчиненный – зависит от процесса-родителя; уничтожается при его уничтожении; процесс-родитель

Проблема “производитель-потребитель”
(producer – consumer)
Одна из парадигм взаимодействия процессов: процесс-производитель (producer)
Проблема “производитель-потребитель”
(producer – consumer)
Одна из парадигм взаимодействия процессов: процесс-производитель (producer)

Ограниченный буфер – реализация с помощью общей памяти
Общие данные
#define BUFFER_SIZE 10
typedef
Ограниченный буфер – реализация с помощью общей памяти
Общие данные
#define BUFFER_SIZE 10
typedef

Ограниченный буфер: процесс-производитель
item nextProduced;
while (1) {
while (((in + 1) % BUFFER_SIZE)
Ограниченный буфер: процесс-производитель
item nextProduced;
while (1) {
while (((in + 1) % BUFFER_SIZE)

Ограниченный буфер: процесс-потребитель
item nextConsumed;
while (1) {
while (in == out)
; /* do
Ограниченный буфер: процесс-потребитель
item nextConsumed;
while (1) {
while (in == out)
; /* do

Коммуникация процессов
Механизм для коммуникации процессов и синхронизации их действий.
Система сообщений –
Коммуникация процессов
Механизм для коммуникации процессов и синхронизации их действий.
Система сообщений –

Если P и Q требуется взаимодействовать между собой, им необходимо:
Установить связь
Если P и Q требуется взаимодействовать между собой, им необходимо:
Установить связь

Реализация коммуникации процессов
Как устанавливается связь?
Можно ли установить связь более чем двух
Реализация коммуникации процессов
Как устанавливается связь?
Можно ли установить связь более чем двух

Прямая связь (direct communication)
Процессы именуют друг друга явно:
send (P, message) –
Прямая связь (direct communication)
Процессы именуют друг друга явно:
send (P, message) –

Косвенная связь (indirect communication)
Сообщения направляются и получаются через почтовые ящики (порты)
Косвенная связь (indirect communication)
Сообщения направляются и получаются через почтовые ящики (порты)

Косвенная связь
Операции
Создать новый почтовый ящик
Отправить (принять) сообщение через почтовый ящик
Удалить почтовый
Косвенная связь
Операции
Создать новый почтовый ящик
Отправить (принять) сообщение через почтовый ящик
Удалить почтовый

(C) В.О. Сафонов, 2010
Синхронизация при косвенной связи
Передача сообщений может выполняться с
(C) В.О. Сафонов, 2010
Синхронизация при косвенной связи
Передача сообщений может выполняться с

Буферизация
С коммуникационной линией связывается очередь сообщений, реализованная одним из трех способов:
1.
Буферизация
С коммуникационной линией связывается очередь сообщений, реализованная одним из трех способов:
1.

Клиент-серверная взаимосвязь
Сокеты (Sockets)
Удаленные вызовы процедур (Remote Procedure Calls – RPC)
Удаленные вызовы
Клиент-серверная взаимосвязь
Сокеты (Sockets)
Удаленные вызовы процедур (Remote Procedure Calls – RPC)
Удаленные вызовы

Сокеты (Sockets)
Впервые были реализованы в UNIX BSD 4.2
Сокет можно определить как
Сокеты (Sockets)
Впервые были реализованы в UNIX BSD 4.2
Сокет можно определить как
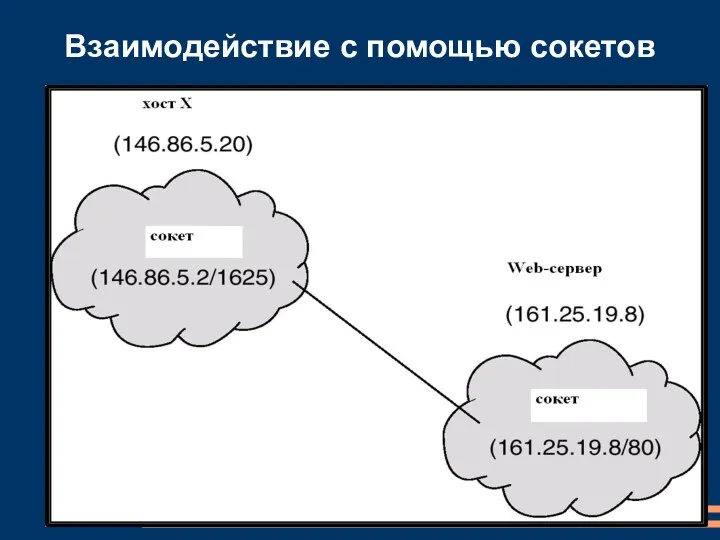
Взаимодействие с помощью сокетов
Взаимодействие с помощью сокетов

Удаленные вызовы процедур (RPC)
RPC впервые предложен фирмой Sun и реализован в
Удаленные вызовы процедур (RPC)
RPC впервые предложен фирмой Sun и реализован в
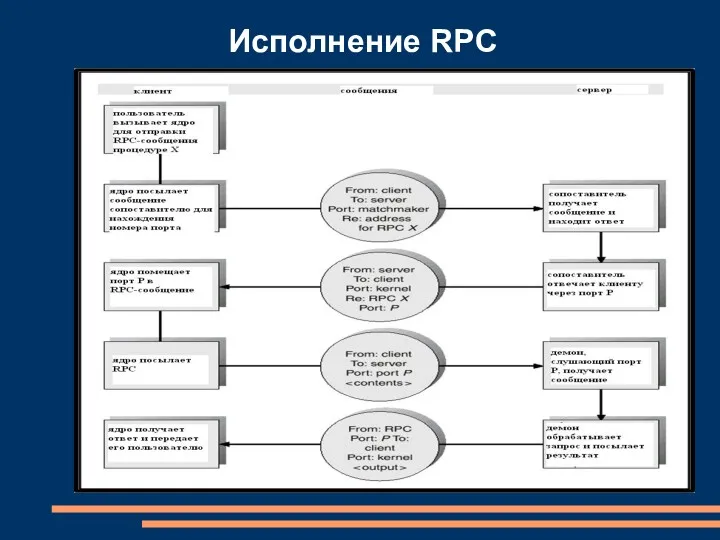
Исполнение RPC
Исполнение RPC
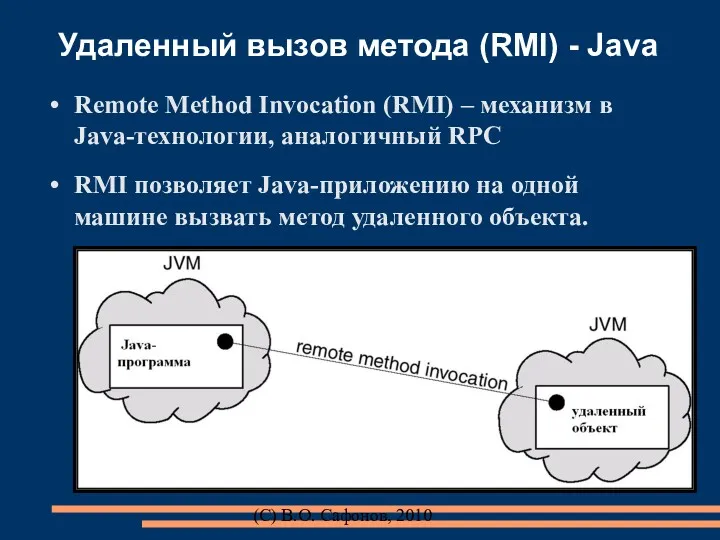
(C) В.О. Сафонов, 2010
Удаленный вызов метода (RMI) - Java
Remote Method Invocation
(C) В.О. Сафонов, 2010
Удаленный вызов метода (RMI) - Java
Remote Method Invocation
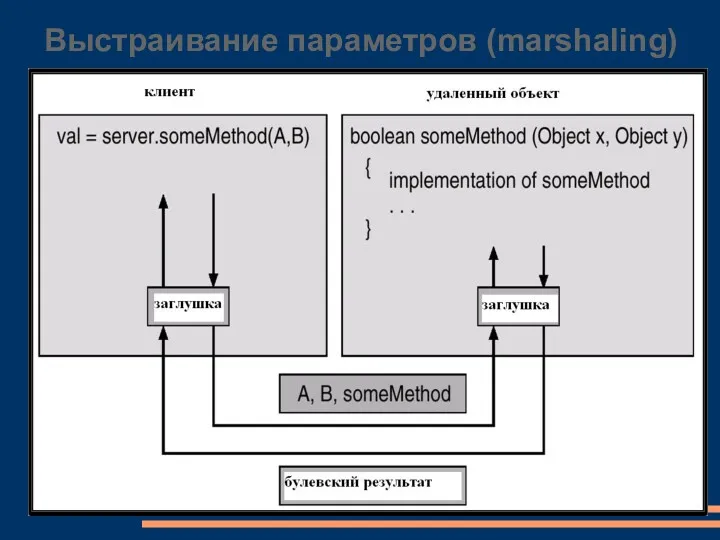
Выстраивание параметров (marshaling)
Выстраивание параметров (marshaling)

Синхронизация процессов
История
Проблема критической секции
Аппаратная поддержка синхронизации
Семафоры
Классические проблемы синхронизации
Критические области
Мониторы
Синхронизация в Solaris
Синхронизация процессов
История
Проблема критической секции
Аппаратная поддержка синхронизации
Семафоры
Классические проблемы синхронизации
Критические области
Мониторы
Синхронизация в Solaris

История
Совместный доступ к общим данным может привести к нарушению их целостности
История
Совместный доступ к общим данным может привести к нарушению их целостности

Ограниченный буфер: Представление
Общие данные
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item
Ограниченный буфер: Представление
Общие данные
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item

Ограниченный буфер: Производитель
Процесс-производитель
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE)
; /*
Ограниченный буфер: Производитель
Процесс-производитель
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE)
; /*

Ограниченный буфер: Потребитель
Процесс-потребитель
item nextConsumed;
while (1) {
while (counter == 0)
; /*
Ограниченный буфер: Потребитель
Процесс-потребитель
item nextConsumed;
while (1) {
while (counter == 0)
; /*

Ограниченный буфер:
Атомарность операций над counter
Операторы
counter++;
counter--;
должны быть выполнены атомарно (atomically).
Атомарная операция
Ограниченный буфер:
Атомарность операций над counter
Операторы
counter++;
counter--;
должны быть выполнены атомарно (atomically).
Атомарная операция

Ограниченный буфер:
Реализация операций над counter
Оператор “count++” может быть реализован на языке
Ограниченный буфер:
Реализация операций над counter
Оператор “count++” может быть реализован на языке

Ограниченный буфер:
Совместное обращение (interleaving)
Если и производитель, и потребитель пытаются обратиться к
Ограниченный буфер:
Совместное обращение (interleaving)
Если и производитель, и потребитель пытаются обратиться к

Ограниченный буфер: Эффект interleaving
Предположим, counter вначале равно 5. Исполнение процессов в
Ограниченный буфер: Эффект interleaving
Предположим, counter вначале равно 5. Исполнение процессов в

Конкуренция за общие данные (race condition)
Race condition: Ситуация, когда взаимодействующие процессы
Конкуренция за общие данные (race condition)
Race condition: Ситуация, когда взаимодействующие процессы

Проблема критической секции
n процессов – каждый может обратиться к общим данным
Каждый
Проблема критической секции
n процессов – каждый может обратиться к общим данным
Каждый

Решение проблемы критической секции
1. Взаимное исключение. Если процесс Pi исполняет свою
Решение проблемы критической секции
1. Взаимное исключение. Если процесс Pi исполняет свою

Решение проблемы критической секции
3. Ограниченное ожидание. Должно существовать ограничение на число раз,
Решение проблемы критической секции
3. Ограниченное ожидание. Должно существовать ограничение на число раз,

Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура
Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура

Алгоритм 1
Общие переменные:
int turn;
первоначально turn = 0
turn == i
Алгоритм 1
Общие переменные:
int turn;
первоначально turn = 0
turn == i
![Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167524/slide-37.jpg)
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag

Алгоритм 3
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi :
do {
flag
Алгоритм 3
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi :
do {
flag

Алгоритм булочной (bakery algorithm) – L. Lamport
Происхождение названия: реализована стратегия, подобная
Алгоритм булочной (bakery algorithm) – L. Lamport
Происхождение названия: реализована стратегия, подобная
![Алгоритм булочной do { choosing[i] = true; number[i] = max(number[0],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167524/slide-40.jpg)
Алгоритм булочной
do {
choosing[i] = true;
number[i] = max(number[0], number[1], …, number
Алгоритм булочной
do {
choosing[i] = true;
number[i] = max(number[0], number[1], …, number

Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
.
boolean TestAndSet(boolean &target)
Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
.
boolean TestAndSet(boolean &target)

Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do
Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do

Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
void Swap (boolean *
Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
void Swap (boolean *

Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс
Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс

Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафоры
Средство синхронизации, не
Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафоры
Средство синхронизации, не

Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =
Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =

Реализация семафора
Определяем семафор как структуру:
typedef struct {
int value;
struct process
Реализация семафора
Определяем семафор как структуру:
typedef struct {
int value;
struct process

Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить
Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить

Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только
Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только

Два типа семафоров
Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное
Два типа семафоров
Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное

(C) В.О. Сафонов, 2010
Вариант операции wait(S) для системных процессов (“Эльбрус”)
Для системного
(C) В.О. Сафонов, 2010
Вариант операции wait(S) для системных процессов (“Эльбрус”)
Для системного

Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int
Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int

Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция
Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция

Классические задачи синхронизации
Задача “ограниченный буфер” (Bounded-Buffer Problem)
Задача “читатели-писатели” (Readers and Writers
Классические задачи синхронизации
Задача “ограниченный буфер” (Bounded-Buffer Problem)
Задача “читатели-писатели” (Readers and Writers

(C) В.О. Сафонов, 2010
Задача “ограниченный буфер”
Общие данные:
semaphore full = n;
semaphore
(C) В.О. Сафонов, 2010
Задача “ограниченный буфер”
Общие данные:
semaphore full = n;
semaphore

Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp
Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp

Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера
Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера

Задача “читатели-писатели”
Общие данные:
semaphore mutex = 1;
semaphore wrt = 1;
int readcount =
Задача “читатели-писатели”
Общие данные:
semaphore mutex = 1;
semaphore wrt = 1;
int readcount =

Процесс-писатель
wait(wrt);
…
выполняется запись
…
signal(wrt);
Процесс-писатель
wait(wrt);
…
выполняется запись
…
signal(wrt);

Процесс-читатель
wait(mutex);
readcount++;
if (readcount == 1)
wait(rt);
signal(mutex);
…
выполняется чтение
…
wait(mutex);
readcount--;
if (readcount == 0)
Процесс-читатель
wait(mutex);
readcount++;
if (readcount == 1)
wait(rt);
signal(mutex);
…
выполняется чтение
…
wait(mutex);
readcount--;
if (readcount == 0)
![Задача “обедающие философы” Общие данные semaphore chopstick[5] = {1, 1,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167524/slide-61.jpg)
Задача “обедающие философы”
Общие данные
semaphore chopstick[5] = {1, 1, 1, 1,
Задача “обедающие философы”
Общие данные
semaphore chopstick[5] = {1, 1, 1, 1,
![Задача “обедающие философы” Философ i: do { wait(chopstick[i]); wait(chopstick[(i+1) %](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167524/slide-62.jpg)
Задача “обедающие философы”
Философ i:
do {
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
…
dine
…
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);
Задача “обедающие философы”
Философ i:
do {
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
…
dine
…
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);

Критические области (critical regions)
Высокоуровневая конструкция для синхронизации
Общая переменная v типа T,
Критические области (critical regions)
Высокоуровневая конструкция для синхронизации
Общая переменная v типа T,

(C) В.О. Сафонов, 2010
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count,
(C) В.О. Сафонов, 2010
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count,

Процесс-производитель
Процесс-производитель добавляет nextp к общему буферу
region buffer when (count < n)
Процесс-производитель
Процесс-производитель добавляет nextp к общему буферу
region buffer when (count < n)

Процесс-потребитель
Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc
region buffer
Процесс-потребитель
Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc
region buffer

Реализация оператора
region x when B do S
Свяжем с общей переменной
Реализация оператора
region x when B do S
Свяжем с общей переменной

Реализация
Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count
Реализация
Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count

Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать
Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать

monitor monitor-name
{
описания общих переменных
procedure body P1 (…) {
. . .
}
procedure body
monitor monitor-name
{
описания общих переменных
procedure body P1 (…) {
. . .
}
procedure body

Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
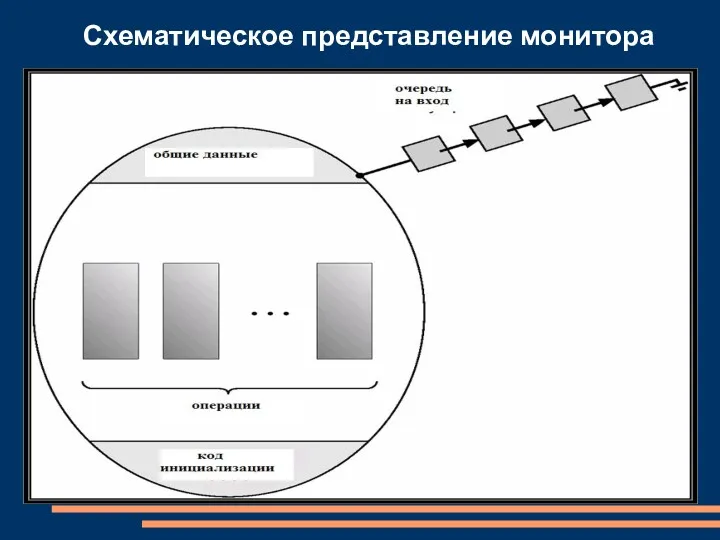
Схематическое представление монитора
Схематическое представление монитора
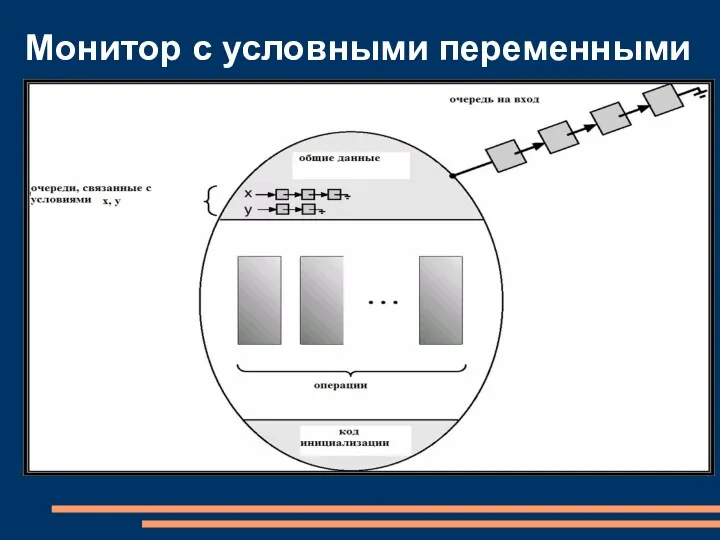
Монитор с условными переменными
Монитор с условными переменными

Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int
Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int

Обедающие философы:
реализация операций pickup и putdown
void pickup(int i) {
state[i] =
Обедающие философы:
реализация операций pickup и putdown
void pickup(int i) {
state[i] =

Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +
Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +

Реализация мониторов с помощью семафоров
Переменные
semaphore mutex; // (initially = 1)
semaphore
Реализация мониторов с помощью семафоров
Переменные
semaphore mutex; // (initially = 1)
semaphore

Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int
Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int

Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}
Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}

(C) В.О. Сафонов, 2010
Реализация мониторов
Конструкция conditional-wait: x.wait(c);
c – целое выражение, вычисляемое
(C) В.О. Сафонов, 2010
Реализация мониторов
Конструкция conditional-wait: x.wait(c);
c – целое выражение, вычисляемое
 Средства защиты информации
Средства защиты информации 3D принтеры: возможности и перспективы
3D принтеры: возможности и перспективы Тема: Базы данных
Тема: Базы данных CRM технологии 1С на службе бизнеса
CRM технологии 1С на службе бизнеса Методология IDEF0, ARIS
Методология IDEF0, ARIS Структура программы, оператор ввода-вывода
Структура программы, оператор ввода-вывода Способи комунікації в мережі. Модуль 2. Урок 2
Способи комунікації в мережі. Модуль 2. Урок 2 Архитектура вычислительных систем. Синхронизация процессов
Архитектура вычислительных систем. Синхронизация процессов Решение логических задач при подготовке к ЕГЭ
Решение логических задач при подготовке к ЕГЭ Компьютерные сети. § 44. Основные понятия. 10 класс
Компьютерные сети. § 44. Основные понятия. 10 класс Регистрация в Личном кабинете
Регистрация в Личном кабинете Introduction to Machine Learning. Algorithms
Introduction to Machine Learning. Algorithms БЭМ. Просто и доступно
БЭМ. Просто и доступно Тема 2. Каскадные таблицы стилей CSS
Тема 2. Каскадные таблицы стилей CSS Сервисное программное обеспечение
Сервисное программное обеспечение Электронные ресурсы ЦГАСО. Электронные ресурсы в помощь изучения семейной истории
Электронные ресурсы ЦГАСО. Электронные ресурсы в помощь изучения семейной истории Курс Основы HTML и CSS. Введение
Курс Основы HTML и CSS. Введение OSPF. Основы протокола
OSPF. Основы протокола Эффективная вёрстка в условиях крайнего Севера
Эффективная вёрстка в условиях крайнего Севера Инспекция программного кода на предмет соответствия стандартам кодирования
Инспекция программного кода на предмет соответствия стандартам кодирования Разработка программного модуля для автоматизации работы менеджера автостоянки
Разработка программного модуля для автоматизации работы менеджера автостоянки Троянские программы и защита от них
Троянские программы и защита от них Представление числовой информации с помощью систем счисления
Представление числовой информации с помощью систем счисления Использование Linux при программировании. Лекция 1. Общие сведения об Операционной системе Linux
Использование Linux при программировании. Лекция 1. Общие сведения об Операционной системе Linux Двоичное кодирование текстовой информации
Двоичное кодирование текстовой информации Библиотечно-библиографическая классификация (ББК)
Библиотечно-библиографическая классификация (ББК) Операционные системы. Определение и история
Операционные системы. Определение и история Разработка web-сайта рекламного агентства по созданию движущейся рекламы
Разработка web-сайта рекламного агентства по созданию движущейся рекламы