- Особенности программирования на GPU

Содержание
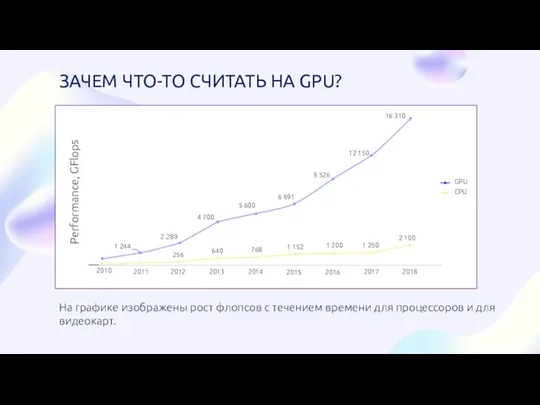
- 2. ЗАЧЕМ ЧТО-ТО СЧИТАТЬ НА GPU? На графике изображены рост флопсов с течением времени для процессоров и
- 3. CPU Core GPU Core АРХИТЕКТУРА GPU И ЕЕ СРАВНЕНИЕ С CPU Fetch/Decode Register ALU (Execute) Out-of-order
- 4. Ограничения на выполняемые алгоритмы при работе с GPU: Если мы выполняем расчет на GPU, то не
- 5. ПРИВЕДЕНИЕ КЛАССИЧЕСКИХ АЛГОРИТМОВ К SIMD-ПРЕДСТАВЛЕНИЮ
- 6. 4992 CUDA ядра 24 GB памяти 480 Gb/s — пропускная способность памяти Время выполнения агрегации на
- 7. Тест видеокарты Tesla k80 в облаке Amazon HtoD — передаем данные на видеокарту GPU Execution —
- 8. Время выполнения математических расчетов на GPU и CPU c матрицами размером 1000 x 60 в мс
- 9. Время выполнения математических расчетов на GPU и CPU c матрицами 10 000 x 60 в мс
- 10. Если вы размышляете об использовании GPU в своих проектах, то GPU, скорее всего, вам подойдет если:
- 12. Скачать презентацию
ЗАЧЕМ ЧТО-ТО СЧИТАТЬ НА GPU?
На графике изображены рост флопсов с течением
ЗАЧЕМ ЧТО-ТО СЧИТАТЬ НА GPU?
На графике изображены рост флопсов с течением

CPU Core
GPU Core
АРХИТЕКТУРА GPU И ЕЕ СРАВНЕНИЕ С CPU
Fetch/Decode
Register
ALU (Execute)
Out-of-order
control logic
Memory
pre-fetcher
Data
CPU Core
GPU Core
АРХИТЕКТУРА GPU И ЕЕ СРАВНЕНИЕ С CPU
Fetch/Decode
Register
ALU (Execute)
Out-of-order
control logic
Memory
pre-fetcher
Data

Ограничения на выполняемые алгоритмы при работе с GPU:
Если мы выполняем расчет
Ограничения на выполняемые алгоритмы при работе с GPU:
Если мы выполняем расчет

ПРИВЕДЕНИЕ КЛАССИЧЕСКИХ АЛГОРИТМОВ
К SIMD-ПРЕДСТАВЛЕНИЮ
ПРИВЕДЕНИЕ КЛАССИЧЕСКИХ АЛГОРИТМОВ
К SIMD-ПРЕДСТАВЛЕНИЮ
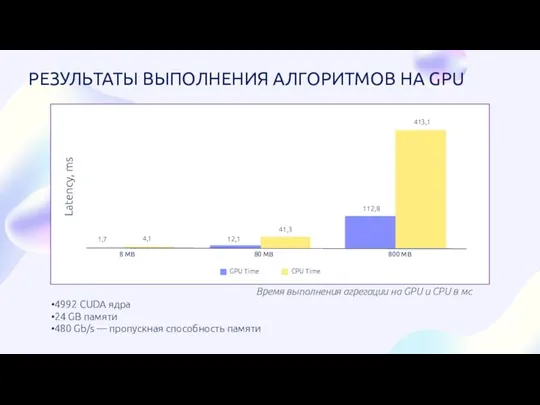
4992 CUDA ядра
24 GB памяти
480 Gb/s — пропускная способность памяти
Время выполнения
4992 CUDA ядра
24 GB памяти
480 Gb/s — пропускная способность памяти
Время выполнения
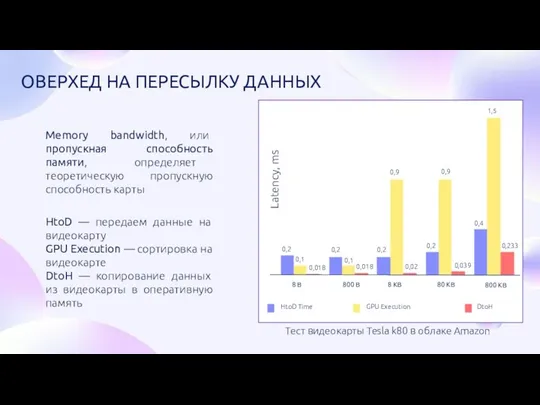
Тест видеокарты Tesla k80 в облаке Amazon
HtoD — передаем данные на
Тест видеокарты Tesla k80 в облаке Amazon
HtoD — передаем данные на
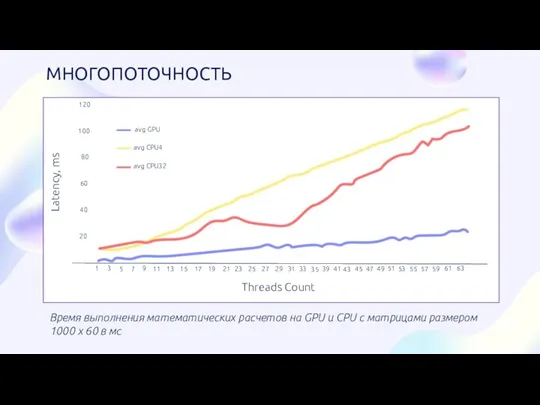
Время выполнения математических расчетов на GPU и CPU c матрицами размером
Время выполнения математических расчетов на GPU и CPU c матрицами размером
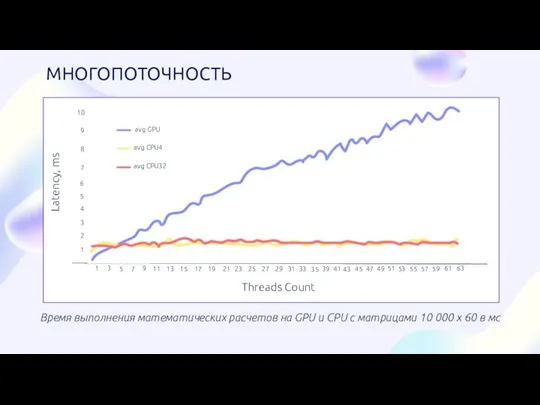
Время выполнения математических расчетов на GPU и CPU c матрицами 10
Время выполнения математических расчетов на GPU и CPU c матрицами 10

Если вы размышляете об использовании GPU в своих проектах, то GPU,
Если вы размышляете об использовании GPU в своих проектах, то GPU,
 Тексты в памяти компьютера
Тексты в памяти компьютера Операционные системы
Операционные системы Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации
Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации Библиографическое описание документа
Библиографическое описание документа Спільна діяльність у мережі інтернет
Спільна діяльність у мережі інтернет Компьютерные сети и их классификация
Компьютерные сети и их классификация PR on the Internet
PR on the Internet Drugs. Online store
Drugs. Online store Влияние СМИ на жизнь современного общества
Влияние СМИ на жизнь современного общества Построение модели данных
Построение модели данных Алгоритм и его формальное исполнение
Алгоритм и его формальное исполнение Повторення. Функції. Лекція 2
Повторення. Функції. Лекція 2 Вступ. Суть і основні елементи теорії надійності
Вступ. Суть і основні елементи теорії надійності Основы компьютерных сетей
Основы компьютерных сетей Техника безопасности при обслуживании информационных систем
Техника безопасности при обслуживании информационных систем Internet Explorer. История создания
Internet Explorer. История создания Абсолютные ссылки в электронных таблицах
Абсолютные ссылки в электронных таблицах Operating system. Applications
Operating system. Applications Факультативный курс Юные исследователи. Методика подготовки к защите исследовательско-проектной работы
Факультативный курс Юные исследователи. Методика подготовки к защите исследовательско-проектной работы Стандарт JPEG. Компрессия полутоновых и цветных изображений
Стандарт JPEG. Компрессия полутоновых и цветных изображений Information technologies in the professional sphere
Information technologies in the professional sphere презентация
презентация Перевод целых чисел из одной системы счисления в другую
Перевод целых чисел из одной системы счисления в другую Самостоятельная работа по программированию
Самостоятельная работа по программированию Adobe Illustrator: интерфейс программы
Adobe Illustrator: интерфейс программы Резервное копирование и архивирование
Резервное копирование и архивирование Понятие информации. Общая характеристика процессов сбора, передачи, обработки и накопления информации
Понятие информации. Общая характеристика процессов сбора, передачи, обработки и накопления информации Тестирование ПО. Основы тестирования
Тестирование ПО. Основы тестирования