- Параллельное программирование

Содержание
- 2. Литература: Методическое пособие А. С. Антонова «Введение в параллельные вычисления» Лекции по параллельным вычислениям: учеб. пособие
- 3. Распределенная система — это набор независимых компьютеров, представляющиеся их пользователям единой объединенной системой. Эндрю Таненбаум, Мартин
- 4. Закон Амдала 4
- 5. Параллельная обработка данных Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий, имеет две разновидности: конвейерность,
- 6. Классификация М. Флинна
- 7. Суперкомпьютеры Кластеры Grid-системы Некоторые примеры II-вычислительных систем
- 8. Суперкомпьютеры Суперкомпьютер МГУ «Ломоносов» Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим параметрам большинство существующих
- 9. Кластеры Кластер «TEdge-Mini» Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и способных работать
- 10. Grid-системы Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети и способных выполнять вычисления
- 11. Проблемы координации Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними и синхронизацию их работы.
- 12. «Гонка» данных Если несколько задач одновременно попытаются изменить некоторую общую область данных, а конечное значение данных
- 13. Бесконечная отсрочка Если одна или несколько задач ожидают сеанса связи до своего выполнения, то в случае,
- 14. Взаимоблокировка Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов,
- 15. Трудности организации связи Многие распространенные параллельные среды (например, кластеры) зачастую состоят из гетерогенных компьютерных сетей. Гетерогенные
- 16. Модели параллельных вычислений POSIX Threads - стандарт для нитей. Стандарт определяет API для создания и манипуляции
- 17. POSIX Threads POSIX определяет основной набор функций и структур данных, чтобы многопоточный код можно было легко
- 18. PVM (Parallel Virtual Machine) PVM представляет собой набор программных средств и библиотек, которые эмулируют общецелевые, гибкие
- 19. MPI (Message Passing Interface) Базовым механизмом связи между MPI процессами является передача и приём сообщений. Сообщение
- 20. OpenMP OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках которой для всех параллельных
- 21. CUDA (Compute Unified Device Architecture) Технология CUDA вводит ряд дополнительных расширений для языка C, которые необходимы
- 22. Использование моделей ПВ : При необходимости решения задач распределенных вычислений на базе SMP-систем (Symmetric Multiprocessing), в
- 23. Основные понятия Компиляция программы Модель параллельной программы Директивы и функции Выполнение программы Замер времени
- 24. OpenMP OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран.
- 25. Преимущества OpenMP 1. Разработчик не создает новую параллельную программу, а просто последовательно добавляет в текст последовательной
- 26. Модель параллельной программы OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках которой для
- 27. Компиляция программы Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP, с указанием соответствующего ключа
- 28. Использование OpenMP Заголовочный файл библиотеки называется omp.h: #include Директивы OpenMP для C/C++ в общем случае выглядят
- 29. Пример 1 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(){ SetConsoleCP(1251); SetConsoleOutputCP(1251); cout
- 30. Директивы и функции Формат директивы на Си/Си++: #pragma omp directive-name [опция[[,] опция]...] Ассоциированные с директивы OpenMP
- 31. Замер времени Функции для работы с системным таймером: omp_get_wtime() - возвращает в вызвавшей нити астрономическое время
- 33. Скачать презентацию

Литература:
Методическое пособие А. С. Антонова «Введение в параллельные вычисления»
Лекции по параллельным
Литература:
Методическое пособие А. С. Антонова «Введение в параллельные вычисления»
Лекции по параллельным

Распределенная система — это набор независимых компьютеров, представляющиеся их пользователям единой

Закон Амдала
4
Закон Амдала
4
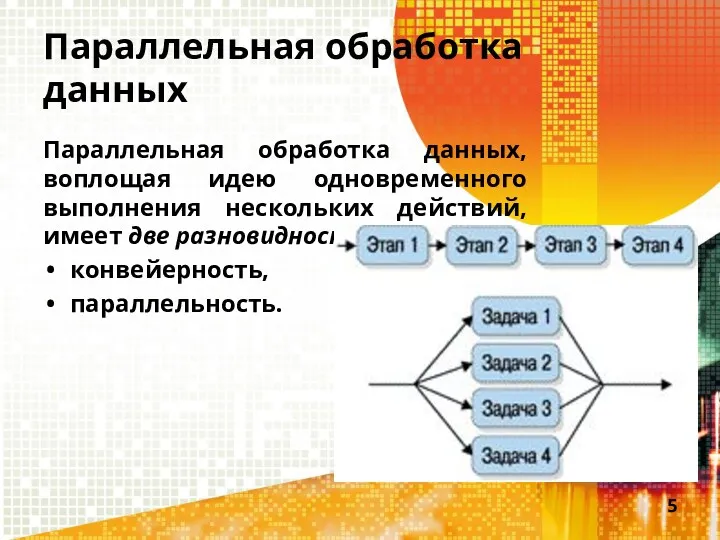
Параллельная обработка данных
Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий,
Параллельная обработка данных
Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий,
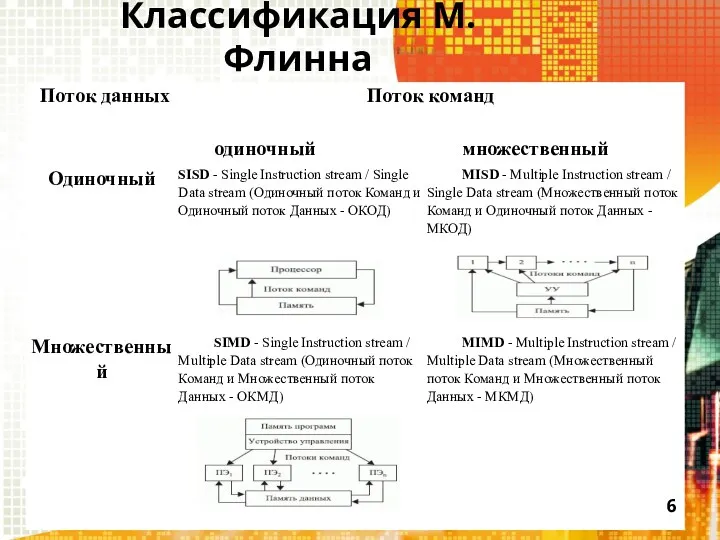
Классификация М. Флинна
Классификация М. Флинна

Суперкомпьютеры
Кластеры
Grid-системы
Некоторые примеры
II-вычислительных систем
Суперкомпьютеры
Кластеры
Grid-системы
Некоторые примеры
II-вычислительных систем

Суперкомпьютеры
Суперкомпьютер МГУ «Ломоносов»
Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим
Суперкомпьютеры
Суперкомпьютер МГУ «Ломоносов»
Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим

Кластеры
Кластер «TEdge-Mini»
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС)
Кластеры
Кластер «TEdge-Mini»
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС)

Grid-системы
Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети
Grid-системы
Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети

Проблемы координации
Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними
Проблемы координации
Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними

«Гонка» данных
Если несколько задач одновременно попытаются изменить некоторую общую область данных,
«Гонка» данных
Если несколько задач одновременно попытаются изменить некоторую общую область данных,

Бесконечная отсрочка
Если одна или несколько задач ожидают сеанса связи до своего
Бесконечная отсрочка
Если одна или несколько задач ожидают сеанса связи до своего
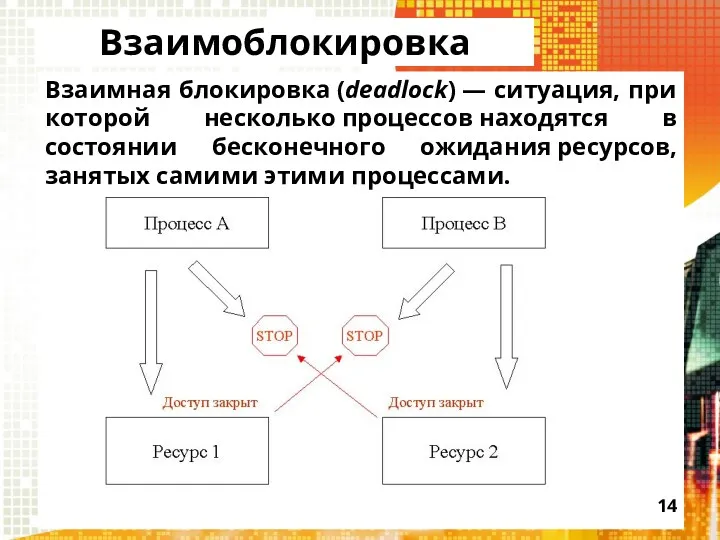
Взаимоблокировка
Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых
Взаимоблокировка
Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых

Трудности организации связи
Многие распространенные параллельные среды (например, кластеры) зачастую состоят из
Трудности организации связи
Многие распространенные параллельные среды (например, кластеры) зачастую состоят из

Модели параллельных вычислений
POSIX Threads - стандарт для нитей. Стандарт определяет
Модели параллельных вычислений
POSIX Threads - стандарт для нитей. Стандарт определяет

POSIX Threads
POSIX определяет основной набор функций и структур данных, чтобы
POSIX Threads
POSIX определяет основной набор функций и структур данных, чтобы

PVM (Parallel Virtual Machine)
PVM представляет собой набор программных средств и библиотек,
PVM (Parallel Virtual Machine)
PVM представляет собой набор программных средств и библиотек,

MPI (Message Passing Interface)
Базовым механизмом связи между MPI процессами является передача
MPI (Message Passing Interface)
Базовым механизмом связи между MPI процессами является передача

OpenMP
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках
OpenMP
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках

CUDA (Compute Unified Device Architecture)
Технология CUDA вводит ряд дополнительных расширений для
CUDA (Compute Unified Device Architecture)
Технология CUDA вводит ряд дополнительных расширений для

Использование моделей ПВ :
При необходимости решения задач распределенных вычислений на базе
Использование моделей ПВ :
При необходимости решения задач распределенных вычислений на базе

Основные понятия
Компиляция программы
Модель параллельной программы
Директивы и функции
Выполнение программы
Замер времени
Основные понятия
Компиляция программы
Модель параллельной программы
Директивы и функции
Выполнение программы
Замер времени

OpenMP
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Описывает совокупность директив компилятора, библиотечных процедур и переменных
OpenMP
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Описывает совокупность директив компилятора, библиотечных процедур и переменных

Преимущества OpenMP
1. Разработчик не создает новую параллельную программу, а просто
Преимущества OpenMP
1. Разработчик не создает новую параллельную программу, а просто

Модель параллельной программы
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования,
Модель параллельной программы
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования,
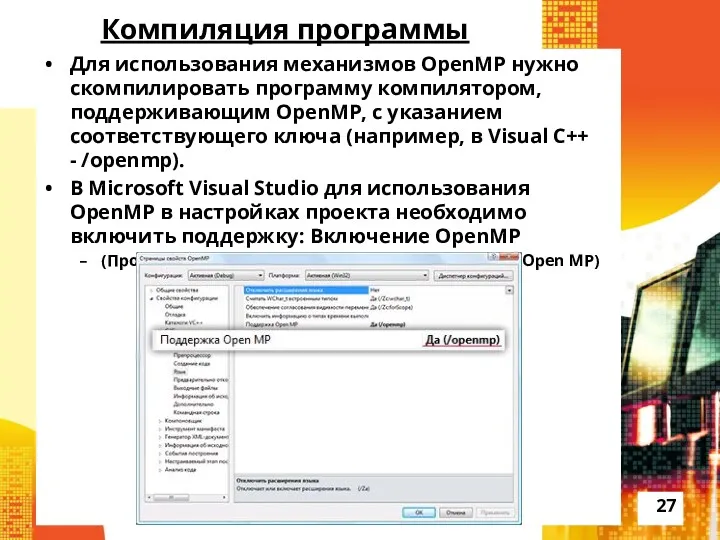
Компиляция программы
Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP,
Компиляция программы
Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP,

Использование OpenMP
Заголовочный файл библиотеки называется omp.h:
#include
Директивы OpenMP для C/C++
Использование OpenMP
Заголовочный файл библиотеки называется omp.h:
#include
Директивы OpenMP для C/C++

Пример 1
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 1
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Директивы и функции
Формат директивы на Си/Си++:
#pragma omp directive-name [опция[[,] опция]...]
Ассоциированные
Директивы и функции
Формат директивы на Си/Си++:
#pragma omp directive-name [опция[[,] опция]...]
Ассоциированные

Замер времени
Функции для работы с системным таймером:
omp_get_wtime() - возвращает в вызвавшей
Замер времени
Функции для работы с системным таймером:
omp_get_wtime() - возвращает в вызвавшей
 Интерфейсы (C#, Лекция 8)
Интерфейсы (C#, Лекция 8) Жанр и критерии отбора новостей
Жанр и критерии отбора новостей Учебный материал Перемещение и копирование файлов и папок.
Учебный материал Перемещение и копирование файлов и папок. Платформа Б. Распределенная блокчейн-платформа для хранения и обмена данными
Платформа Б. Распределенная блокчейн-платформа для хранения и обмена данными Использование информационных технологий в обработке текстов
Использование информационных технологий в обработке текстов Подписчик жинау
Подписчик жинау Алгебра логики
Алгебра логики Техники тест-дизайна. Планирование, оценка трудозатрат. Отчетность. Лекция 5
Техники тест-дизайна. Планирование, оценка трудозатрат. Отчетность. Лекция 5 SEO продвижение сайтов
SEO продвижение сайтов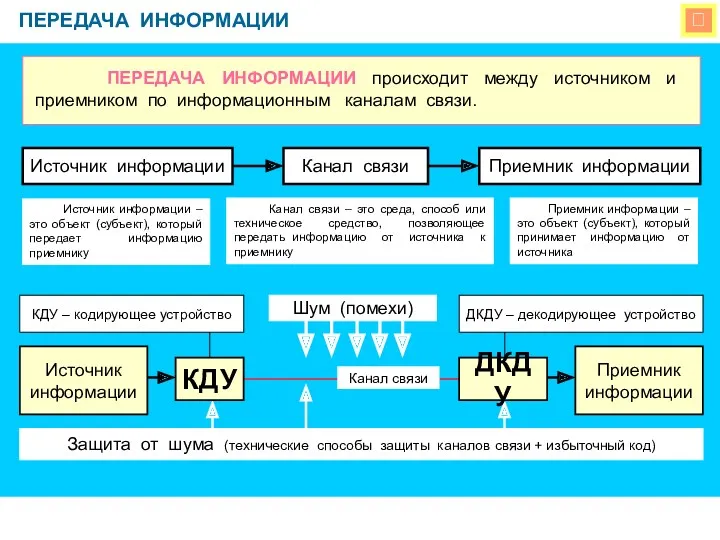 Передача информации. Виды информационных процессов
Передача информации. Виды информационных процессов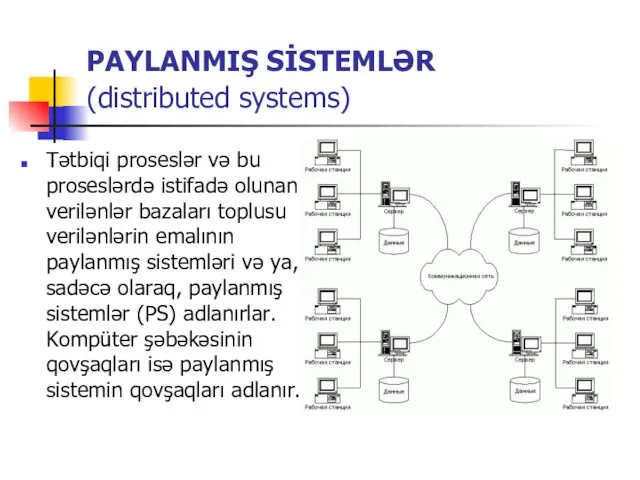 Paylanmiş si̇stemlər
Paylanmiş si̇stemlər Производственная технологическая практика. Учет запасных частей
Производственная технологическая практика. Учет запасных частей Искусственный интеллект. Самостоятельная работа
Искусственный интеллект. Самостоятельная работа Antivirus dasturiy vositalar: kompyuter viruslarining xarakteristikalari, viruslarni aniqlash va ulardan himoya qilish
Antivirus dasturiy vositalar: kompyuter viruslarining xarakteristikalari, viruslarni aniqlash va ulardan himoya qilish Архитектура ЭВМ. Операционные системы. Потоки исполнения - Thread
Архитектура ЭВМ. Операционные системы. Потоки исполнения - Thread Загальні поняття про архітектуру комп’ютерів
Загальні поняття про архітектуру комп’ютерів Кодирование и обработка числовой информации. Методическая разработка
Кодирование и обработка числовой информации. Методическая разработка Human-computer interaction
Human-computer interaction Проект Открытка в Scratch
Проект Открытка в Scratch ВКР: изучение функционирования предприятия путем внедрения информационных технологий
ВКР: изучение функционирования предприятия путем внедрения информационных технологий Создание игры с помощью программы PowerPoint
Создание игры с помощью программы PowerPoint Начальный курс Java. (8 занятий)
Начальный курс Java. (8 занятий) Ассемблер Atmel AVR
Ассемблер Atmel AVR Интерфейс пользователя, входной язык системы MathCAD, типы данных, ввод и редактирование данных. (Лекция 13)
Интерфейс пользователя, входной язык системы MathCAD, типы данных, ввод и редактирование данных. (Лекция 13) Этика сетевого общения
Этика сетевого общения Теория и средства передачи данных (Модуль 4. Сетевые технологии)
Теория и средства передачи данных (Модуль 4. Сетевые технологии) Управление памятью и указатели
Управление памятью и указатели Технические средства телекоммуникационных технологий
Технические средства телекоммуникационных технологий