- Параллельное программирование

Содержание
- 2. Существуют различные способы написания программ, (разделение условное) : Последовательное программирование с дальнейшим автоматическим распараллеливанием. Непосредственное формирование
- 3. Достижение параллелизма возможно только при выполнении следующих требований к архитектурным принципам построения вычислительной среды: независимость функционирования
- 4. Дополнительной формой обеспечения параллелизма может служить конвейерная реализация обрабатывающих устройств, при которой выполнение операций в устройствах
- 5. При конвейерной реализации параллелизм ограничен числом стадий В идеале времена работы каждой стадии должны быть одинаковыми
- 6. При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы выполнения независимых частей программы: многозадачный
- 7. параллельное выполнение, когда в один и тот же момент может выполняться несколько команд обработки данных. Такой
- 8. Классификация вычислительных систем Одним из наиболее распространенных способов классификации ЭВМ является систематика Флинна (Flynn, 1966 г.),
- 10. Мультипроцессоры Для дальнейшей систематики мультипроцессоров учитывается способ построения общей памяти. Первый возможный вариант – использование единой
- 11. Рис. 1. Архитектура многопроцессорных систем с общей (разделяемой) памятью: системы с однородным (а) и неоднородным (б)
- 12. Одной из основных проблем, которые возникают при организации параллельных вычислений на такого типа системах, является доступ
- 13. Наличие общих данных при параллельных вычислениях приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так,
- 14. Общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность
- 15. Мультикомпьютеры Мультикомпьютеры (многопроцессорные системы с к данным, располагаемым на других процессраспределенной памятью) уже не обеспечивают общего
- 16. Рис. 2. Архитектура многопроцессорных систем с распределенной памятью
- 17. Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для которых при помощи специальных аппаратно-программных
- 18. Применение кластеров может также в некоторой степени устранить проблемы, связанные с разработкой параллельных алгоритмов и программ,
- 19. Моделирование и анализ параллельных вычислений Для описания существующих информационных зависимостей в выбираемых алгоритмах решения задач может
- 20. Рис. 3. Пример вычислительной модели алгоритма в виде графа "операции – операнды"
- 21. Описание схемы параллельного выполнения алгоритма Операции алгоритма, между которыми нет пути в рамках выбранной схемы вычислений,
- 22. Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для параллельного выполнения вычислений необходимо задать
- 23. Определение времени выполнения параллельного алгоритма Вычислительная схема алгоритма G совместно с расписанием Hp может рассматриваться как
- 24. Уменьшение времени выполнения может быть обеспечено и путем подбора наилучшей вычислительной схемы Оценки Tp(G,Hp), Tp(G) и
- 25. Оценка T1 определяет время выполнения алгоритма при использовании одного процессора и представляет, тем самым, время выполнения
- 26. Теоретические положения, характеризующие свойства оценок времени выполнения параллельного алгоритма . Теорема 1. Минимально возможное время выполнения
- 27. Теорема 4. Для любого количества используемых процессоров справедлива следующая верхняя оценка для времени выполнения параллельного алгоритма
- 28. Приведенные утверждения позволяют дать следующие рекомендации по правилам формирования параллельных алгоритмов: при выборе вычислительной схемы алгоритма
- 29. Показатели эффективности параллельного алгоритма Ускорение ( speedup ), получаемое при использовании параллельного алгоритма для p процессоров,
- 30. Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p и Ep(n)=1. При практическом применении данных
- 31. Попытки повышения качества параллельных вычислений по одному из показателей (ускорению или эффективности) могут привести к ухудшению
- 32. При выборе надлежащего параллельного способа решения задачи может оказаться полезной оценка стоимости (cost) вычислений, определяемой как
- 33. Моделирование параллельных программ На стадии проектирования параллельный метод может быть представлен в виде графа "подзадачи –
- 34. Рис. 4. Модель параллельной программы в виде графа "процессы - каналы"
- 35. под процессом будем понимать выполняемую на процессоре программу, которая использует для своей работы часть локальной памяти
- 37. Модели жизненного цикла для разработки программных систем За десятилетия опыта построения программных систем был наработан ряд
- 38. Основное назначение моделей ЖЦ состоит в следующем: планирование и распределение работ между разработчиками и ресурсов, а
- 39. Процессы ЖЦ стандарта ISO/IEC 12207 При выборе схемы модели ЖЦ для конкретной предметной области, решаются вопросы
- 40. Рис. 1. Схема основных процессов ЖЦ ПС
- 41. Рис. 2. Схема вспомогательных процессов ЖЦ ПС
- 42. Являясь стандартом высокого уровня, он не задает детали того, как надо выполнять действия или задачи, составляющие
- 43. Процессы, включенные в модель ЖЦ, предназначены для реализации стандартных задач процессов ЖЦ и могут привлекать другие
- 44. Характеристики качества программных средств Международный стандарт ISO 9126:1-4 (1991г.), переиздан в 2002г. Метрики характеристик качества отражают:
- 45. Модель характеристик качества состоит из 6 базовых показателей: Функциональные возможности: пригодность для применения по назначению; корректность
- 46. 4. Применимость (практичность) ПП: понятность функций и сопроводительной документации; простота использования комплекса программ; простота изучения процесса
- 47. Характеристики, субхарактеристики и атрибуты качества ПП имеют 3 уровня детализации: Категорийно-описательные – это описательные характеристики функций,
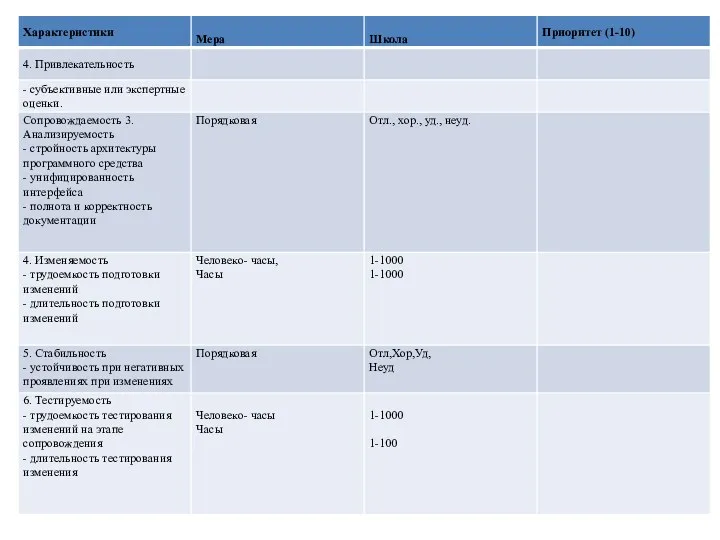
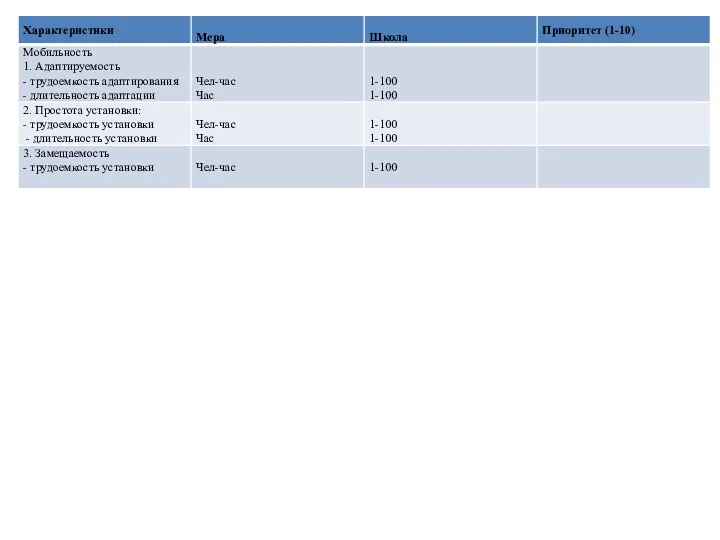
- 48. Основные количественные характеристики программных средств и их атрибуты
- 49. Основные качественные характеристики программных средств и их аттрибутов
- 52. Метод установления правильности программ при помощи строгих средств известен как верификация программ. В отличие от тестирования
- 53. К методам проверки правильности программ относятся: 1) методы доказательство правильности программ; 2) верификация и аттестация программ.
- 54. Метод Флойда и Наура основан на определении условий для входных и выходных данных и в выборе
- 55. Метод Хоара - это усовершенствованный метод Флойда, основанный на аксиоматическом описании семантики языка программирования исходных программ.
- 56. Таким образом, алгоритм доказательства правильности программы методом индуктивных высказываний представляется в следующем виде: 1) Построить структуру
- 57. Метод Маккарти состоит в структурной проверке функций, работающих над структурными типами данных, изменяет структуры данных и
- 59. Скачать презентацию

Существуют различные способы написания программ, (разделение условное) :
Последовательное программирование с дальнейшим
Существуют различные способы написания программ, (разделение условное) :
Последовательное программирование с дальнейшим

Достижение параллелизма возможно только при выполнении следующих требований к архитектурным принципам
Достижение параллелизма возможно только при выполнении следующих требований к архитектурным принципам

Дополнительной формой обеспечения параллелизма может служить конвейерная реализация обрабатывающих устройств, при

При конвейерной реализации параллелизм ограничен числом стадий
В идеале времена работы
При конвейерной реализации параллелизм ограничен числом стадий
В идеале времена работы

При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы
При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы

параллельное выполнение, когда в один и тот же момент может выполняться
параллельное выполнение, когда в один и тот же момент может выполняться

Классификация вычислительных систем
Одним из наиболее распространенных способов классификации ЭВМ является систематика
Классификация вычислительных систем
Одним из наиболее распространенных способов классификации ЭВМ является систематика
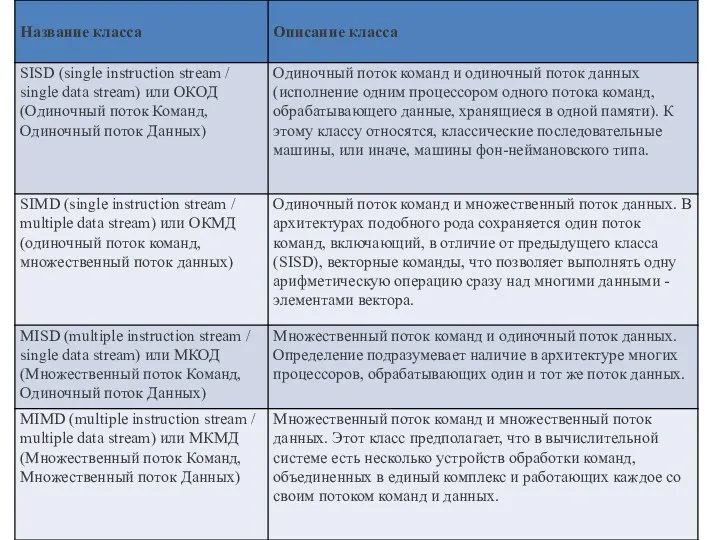

Мультипроцессоры
Для дальнейшей систематики мультипроцессоров учитывается способ построения общей памяти. Первый возможный
Мультипроцессоры
Для дальнейшей систематики мультипроцессоров учитывается способ построения общей памяти. Первый возможный
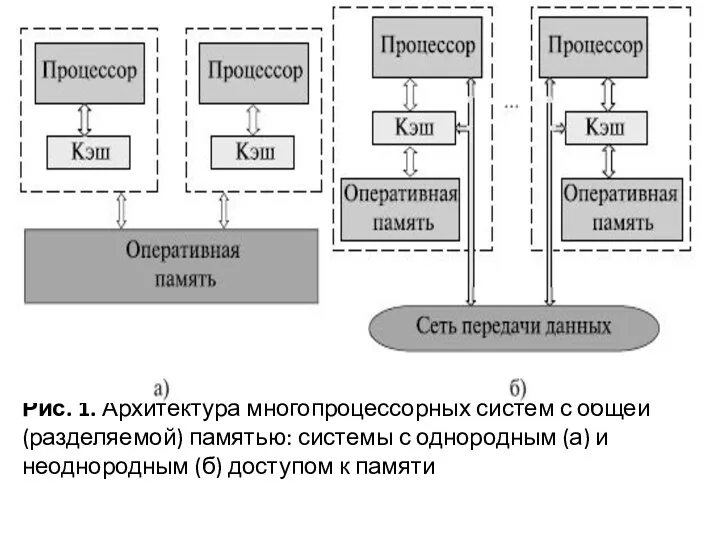
Рис. 1. Архитектура многопроцессорных систем с общей (разделяемой) памятью: системы с
Рис. 1. Архитектура многопроцессорных систем с общей (разделяемой) памятью: системы с

Одной из основных проблем, которые возникают при организации параллельных вычислений на
Одной из основных проблем, которые возникают при организации параллельных вычислений на

Наличие общих данных при параллельных вычислениях приводит к необходимости синхронизации взаимодействия
Наличие общих данных при параллельных вычислениях приводит к необходимости синхронизации взаимодействия

Общий доступ к данным может быть обеспечен и при физически распределенной
Общий доступ к данным может быть обеспечен и при физически распределенной

Мультикомпьютеры
Мультикомпьютеры (многопроцессорные системы с к данным, располагаемым на других процессраспределенной памятью)
Мультикомпьютеры
Мультикомпьютеры (многопроцессорные системы с к данным, располагаемым на других процессраспределенной памятью)

Рис. 2. Архитектура многопроцессорных систем с распределенной памятью
Рис. 2. Архитектура многопроцессорных систем с распределенной памятью

Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для
Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для

Применение кластеров может также в некоторой степени устранить проблемы, связанные с
Применение кластеров может также в некоторой степени устранить проблемы, связанные с

Моделирование и анализ параллельных вычислений
Для описания существующих информационных зависимостей в
Моделирование и анализ параллельных вычислений
Для описания существующих информационных зависимостей в
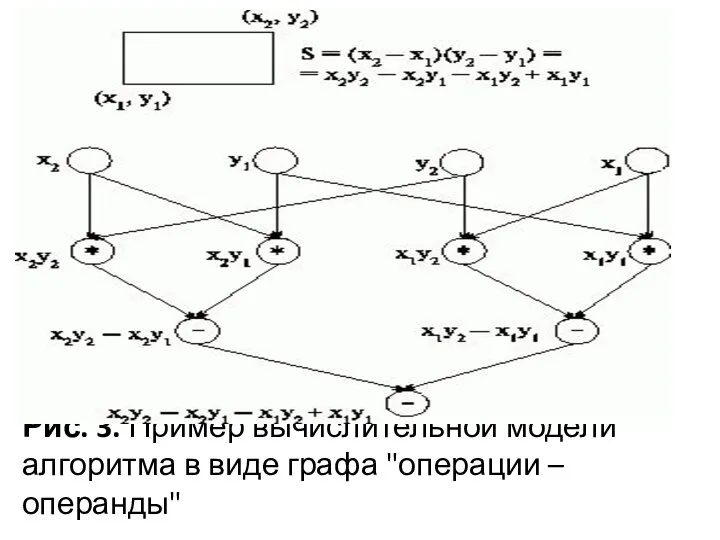
Рис. 3. Пример вычислительной модели алгоритма в виде графа "операции –
Рис. 3. Пример вычислительной модели алгоритма в виде графа "операции –

Описание схемы параллельного выполнения алгоритма
Операции алгоритма, между которыми нет пути в
Описание схемы параллельного выполнения алгоритма
Операции алгоритма, между которыми нет пути в

Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для
Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для

Определение времени выполнения параллельного алгоритма
Вычислительная схема алгоритма G совместно с расписанием
Определение времени выполнения параллельного алгоритма
Вычислительная схема алгоритма G совместно с расписанием

Уменьшение времени выполнения может быть обеспечено и путем подбора наилучшей вычислительной
Уменьшение времени выполнения может быть обеспечено и путем подбора наилучшей вычислительной

Оценка T1 определяет время выполнения алгоритма при использовании одного процессора и
Оценка T1 определяет время выполнения алгоритма при использовании одного процессора и

Теоретические положения, характеризующие свойства оценок времени выполнения параллельного алгоритма .
Теорема 1.
Теоретические положения, характеризующие свойства оценок времени выполнения параллельного алгоритма .
Теорема 1.

Теорема 4. Для любого количества используемых процессоров справедлива следующая верхняя оценка
Теорема 4. Для любого количества используемых процессоров справедлива следующая верхняя оценка

Приведенные утверждения позволяют дать следующие рекомендации по правилам формирования параллельных алгоритмов:
при
Приведенные утверждения позволяют дать следующие рекомендации по правилам формирования параллельных алгоритмов:
при

Показатели эффективности параллельного алгоритма
Ускорение ( speedup ), получаемое при использовании параллельного
Показатели эффективности параллельного алгоритма
Ускорение ( speedup ), получаемое при использовании параллельного

Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p и
Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p и

Попытки повышения качества параллельных вычислений по одному из показателей (ускорению или
Попытки повышения качества параллельных вычислений по одному из показателей (ускорению или

При выборе надлежащего параллельного способа решения задачи может оказаться полезной оценка
При выборе надлежащего параллельного способа решения задачи может оказаться полезной оценка

Моделирование параллельных программ
На стадии проектирования параллельный метод может быть представлен
Моделирование параллельных программ
На стадии проектирования параллельный метод может быть представлен
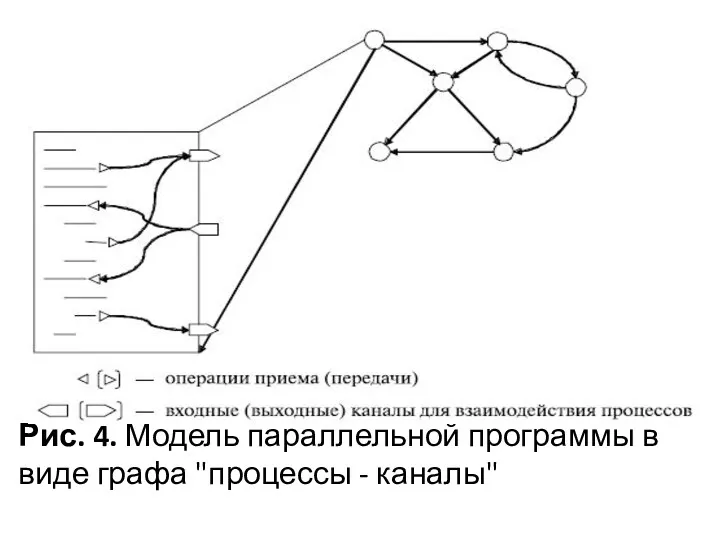
Рис. 4. Модель параллельной программы в виде графа "процессы - каналы"
Рис. 4. Модель параллельной программы в виде графа "процессы - каналы"

под процессом будем понимать выполняемую на процессоре программу, которая использует для
под процессом будем понимать выполняемую на процессоре программу, которая использует для


Модели жизненного цикла для разработки программных систем За десятилетия опыта построения программных
Модели жизненного цикла для разработки программных систем За десятилетия опыта построения программных

Основное назначение моделей ЖЦ состоит в следующем:
планирование и распределение работ между
Основное назначение моделей ЖЦ состоит в следующем:
планирование и распределение работ между

Процессы ЖЦ стандарта ISO/IEC 12207
При выборе схемы модели ЖЦ для конкретной
Процессы ЖЦ стандарта ISO/IEC 12207
При выборе схемы модели ЖЦ для конкретной
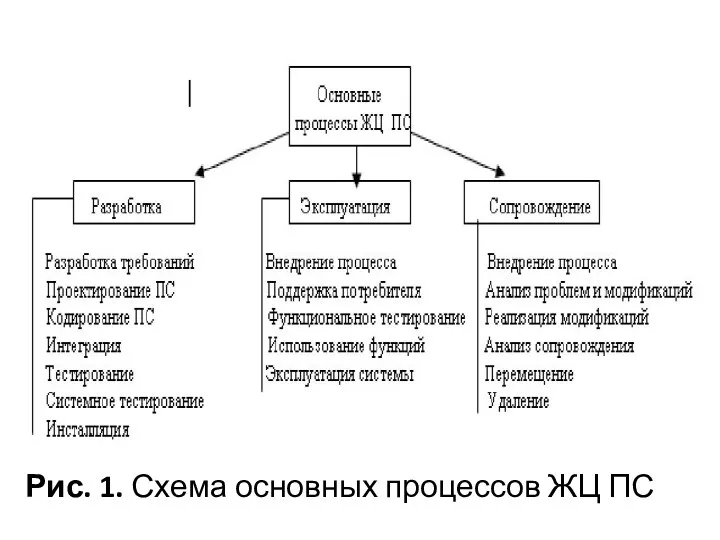
Рис. 1. Схема основных процессов ЖЦ ПС
Рис. 1. Схема основных процессов ЖЦ ПС
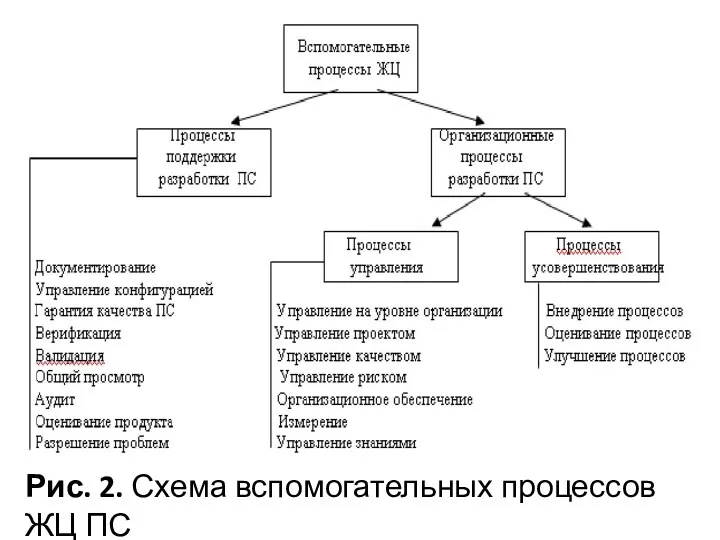
Рис. 2. Схема вспомогательных процессов ЖЦ ПС
Рис. 2. Схема вспомогательных процессов ЖЦ ПС

Являясь стандартом высокого уровня, он не задает детали того, как надо
Являясь стандартом высокого уровня, он не задает детали того, как надо

Процессы, включенные в модель ЖЦ, предназначены для реализации стандартных задач процессов
Процессы, включенные в модель ЖЦ, предназначены для реализации стандартных задач процессов

Характеристики качества программных средств
Международный стандарт ISO 9126:1-4 (1991г.), переиздан в
Характеристики качества программных средств
Международный стандарт ISO 9126:1-4 (1991г.), переиздан в

Модель характеристик качества состоит из 6 базовых показателей:
Функциональные возможности:
пригодность
Модель характеристик качества состоит из 6 базовых показателей:
Функциональные возможности:
пригодность

4. Применимость (практичность) ПП:
понятность функций и сопроводительной документации;
простота использования
4. Применимость (практичность) ПП:
понятность функций и сопроводительной документации;
простота использования

Характеристики, субхарактеристики и атрибуты качества ПП имеют 3 уровня детализации:
Категорийно-описательные
Характеристики, субхарактеристики и атрибуты качества ПП имеют 3 уровня детализации:
Категорийно-описательные
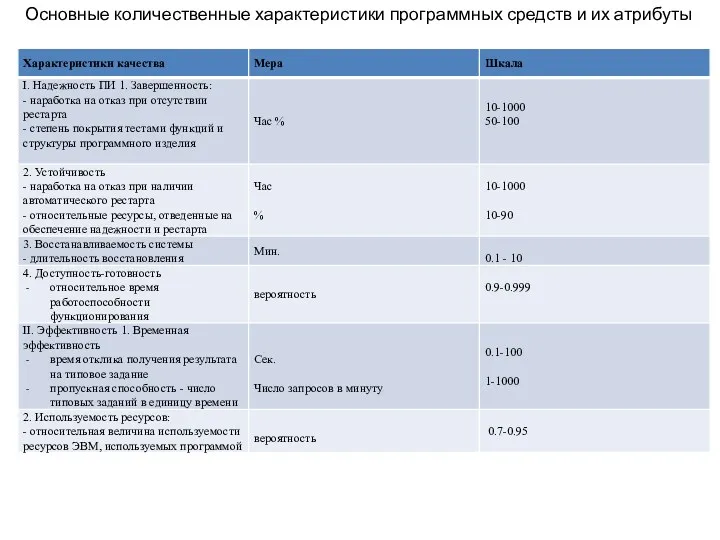
Основные количественные характеристики программных средств и их атрибуты
Основные количественные характеристики программных средств и их атрибуты
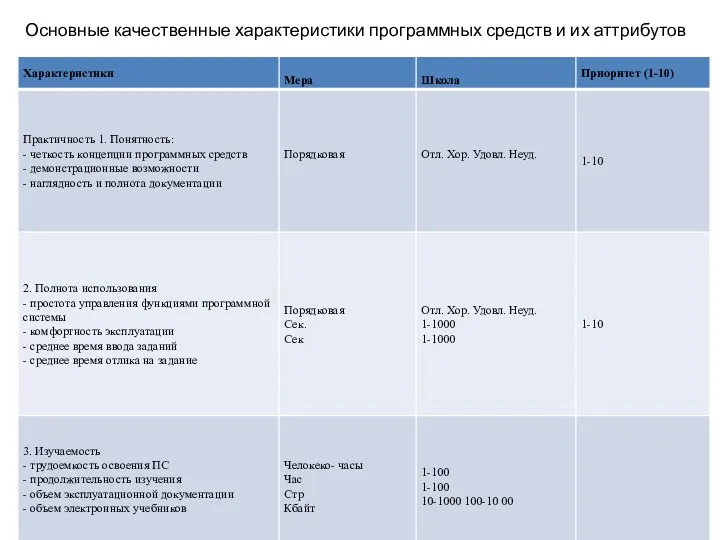
Основные качественные характеристики программных средств и их аттрибутов
Основные качественные характеристики программных средств и их аттрибутов

Метод установления правильности программ при помощи строгих средств известен как верификация
Метод установления правильности программ при помощи строгих средств известен как верификация

К методам проверки правильности программ относятся:
1) методы доказательство правильности программ;
2) верификация
К методам проверки правильности программ относятся:
1) методы доказательство правильности программ;
2) верификация

Метод Флойда и Наура основан на определении условий для входных и
Метод Флойда и Наура основан на определении условий для входных и

Метод Хоара - это усовершенствованный метод Флойда, основанный на аксиоматическом описании
Метод Хоара - это усовершенствованный метод Флойда, основанный на аксиоматическом описании

Таким образом, алгоритм доказательства правильности программы методом индуктивных высказываний представляется в
Таким образом, алгоритм доказательства правильности программы методом индуктивных высказываний представляется в

Метод Маккарти состоит в структурной проверке функций, работающих над структурными типами
Метод Маккарти состоит в структурной проверке функций, работающих над структурными типами
 Позиционные системы счисления
Позиционные системы счисления Локальные сети. Параметры сетей и их стандарты
Локальные сети. Параметры сетей и их стандарты Сбор и подготовка данных
Сбор и подготовка данных Современные накопители информации, используемые в вычислительной технике
Современные накопители информации, используемые в вычислительной технике Использование технологии веб-квест как средство развития познавательных и творческих способностей учащихся
Использование технологии веб-квест как средство развития познавательных и творческих способностей учащихся Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля
Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля Параллельное программирование. С++. Thread Support Library. Atomic Operations Library
Параллельное программирование. С++. Thread Support Library. Atomic Operations Library Функции в Excel
Функции в Excel Организация и средства информационных технологий обеспечения управленческой деятельности
Организация и средства информационных технологий обеспечения управленческой деятельности Поиск публикаций и показатели деятельности ученого в Web of Science
Поиск публикаций и показатели деятельности ученого в Web of Science Бездротові мережі
Бездротові мережі Занятие 1. Знакомство с программой Adobe Photoshop
Занятие 1. Знакомство с программой Adobe Photoshop Microsoft Visual Studio — линейка продуктов компании Microsoft
Microsoft Visual Studio — линейка продуктов компании Microsoft Операторы цикла
Операторы цикла Понятие об информации. Представление информации. Информационная деятельность человека.
Понятие об информации. Представление информации. Информационная деятельность человека. Автоматизоване створення запитів у базі даних
Автоматизоване створення запитів у базі даних Архітектура операційних систем
Архітектура операційних систем Windows System Programming
Windows System Programming Личный кабинет
Личный кабинет Мир станочника. Аддитивные технологии и 3D-сканирование
Мир станочника. Аддитивные технологии и 3D-сканирование Методы и средства защиты программ от компьютерных вирусов
Методы и средства защиты программ от компьютерных вирусов 46_Yaroslavskaya_Sasha
46_Yaroslavskaya_Sasha Локальные и глобальные сети ЭВМ. Защита информации в сетях. (Тема 6)
Локальные и глобальные сети ЭВМ. Защита информации в сетях. (Тема 6) Godseeker. Игра
Godseeker. Игра Рабочий стол. Управление компьютером с помощью мыши
Рабочий стол. Управление компьютером с помощью мыши Проектирование изделий из листового металла в NX
Проектирование изделий из листового металла в NX Эти люди изменили мир
Эти люди изменили мир Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование
Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование