- Параллельное программирование. Лекция 1

Содержание
- 2. Структура курса Лекции: 20 часов Лабораторные работы: 24часов Самостоятельная работа: 40 часов ИТОГ: Зачет
- 3. Темы Основные архитектуры параллельных вычислительных систем, их классификация Основные модели параллельного программирования Основы программирования с использованием
- 4. Литература Гергель В.П., Высокопроизводительные вычисления для многопроцессорных многоядерных систем М. : Изд-во Моск. ун-та [и др.],
- 5. Литература (библиотека) Введение в программирование для параллельных ЭВМ и кластеров Учебн. Пособие, Авт.-сост.: Кравчук В.В., Попов
- 6. Литература (internet) В.Н. Дацюк, А.А. Букатов, А.И. Жегуло Методическое пособие по курсу "Многопроцессорные системы и параллельное
- 7. Задачи «Большого вызова» Моделирование вселенной (а) (б) (в) Рис. 1. Изображение вселенной
- 8. Задачи «Большого вызова» Моделирование климата Рис. 2. Изображение воздушных потоков
- 9. Задачи «Большого вызова» Моделирование белков и др. химических объектов Рис. 3. Модели белков
- 10. Задачи «Большого вызова» Моделирование мозга (нейронные сети) ( Рис. 4. Нейронные сети
- 11. Задачи «Большого вызова» Расчеты сложных физических реакций Рис. 5. Сложные физические взаимодействия
- 12. Параллелизм Стратегическое направление развития вычислительной техники Основной путь повышения производительности компьютеров ASCI – Accelerated Strategic Computing
- 13. Пути достижения параллелизма Независимость функционирования отдельных устройств компьютеров Избыточность элементов вычислительной системы (использование специализированных устройств и
- 14. Сдерживающие факторы Высокая стоимость параллельных вычислительных систем (суперкомпьютеров) Необходимость обобщения последовательных программ Потери производительности при организации
- 15. Вперед к параллельному компьютеру
- 16. Симметричные мультипроцессорные системы SMP-системы Кэш CPU Память Кэш CPU Кэш CPU … Аппаратная поддержка когерентности кэшей
- 17. Укрупненно-распараллеленные системы (МРР-системы) … Высокоскоростная коммуникационная среда
- 18. Системы с неоднородным доступом к памяти (NUMA) cc-NUMA – cashe-coherent NUMA … Кэш CPU Память Кэш
- 19. Параллельные векторные системы PVP-системы Векторно-конвейерные процессоры: SMP - конфигурация MPP - конфигурация Модель программирования: Векторизация циклов
- 20. Кластерные системы
- 21. Классификация вычислительных систем Систематика Флинна (SISD и SIMD) SISD – Single Instruction, Single Data обычные последовательные
- 22. Классификация вычислительных систем Систематика Флинна (MISD и MIMD) MISD – Multiple Instruction, Single Data не существует
- 23. Классификация Дункана Синхронные Веторные SIMD Систолические Матричные С ассоциативной памятью MIMD С распределенной памятью С общей
- 24. Классификация Р. Хокни
- 25. Другие классификации Классификация В. Хендлера (t(C) = (k,d,w)) Классификация Л. Шнайдера (Iw(Ia)w(Iv) Iw(Ia)w(Iv))
- 26. TOP 10 Sites for November 2015
- 27. Сергей Королёв Общие характеристики: Общее число серверов/процессоров/вычислительных ядер: 165/332/1712; Общее число графических процессоров/ядер: 5/4216; Общая оперативная
- 28. Сергей Королёв Вычислительная часть 112 вычислительных блейд-серверов (2х Intel Xeon X5560, 12 Гб, 76/146Гб, InfiniBand DDR,
- 29. Сопроцессоры Intel Xeon Phi 61 ядро, 244 потока производительность 1,2 терафлопс. Векторные операции
- 31. Скачать презентацию

Структура курса
Лекции: 20 часов
Лабораторные работы: 24часов
Самостоятельная работа: 40 часов
ИТОГ: Зачет
Структура курса
Лекции: 20 часов
Лабораторные работы: 24часов
Самостоятельная работа: 40 часов
ИТОГ: Зачет

Темы
Основные архитектуры параллельных вычислительных систем, их классификация
Основные модели параллельного программирования
Основы
Темы
Основные архитектуры параллельных вычислительных систем, их классификация
Основные модели параллельного программирования
Основы

Литература
Гергель В.П., Высокопроизводительные вычисления для многопроцессорных многоядерных систем М. : Изд-во
Литература
Гергель В.П., Высокопроизводительные вычисления для многопроцессорных многоядерных систем М. : Изд-во

Литература (библиотека)
Введение в программирование для параллельных ЭВМ и кластеров
Учебн. Пособие, Авт.-сост.:
Литература (библиотека)
Введение в программирование для параллельных ЭВМ и кластеров Учебн. Пособие, Авт.-сост.:

Литература (internet)
В.Н. Дацюк, А.А. Букатов, А.И. Жегуло Методическое пособие по курсу
Литература (internet)
В.Н. Дацюк, А.А. Букатов, А.И. Жегуло Методическое пособие по курсу

Задачи «Большого вызова»
Моделирование вселенной
(а) (б) (в)
Рис. 1. Изображение вселенной
Задачи «Большого вызова»
Моделирование вселенной
(а) (б) (в)
Рис. 1. Изображение вселенной

Задачи «Большого вызова»
Моделирование климата
Рис. 2. Изображение воздушных потоков
Задачи «Большого вызова»
Моделирование климата
Рис. 2. Изображение воздушных потоков
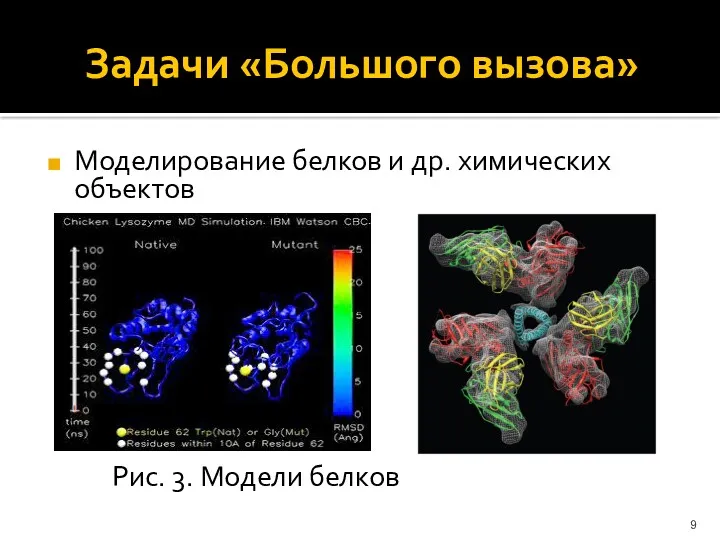
Задачи «Большого вызова»
Моделирование белков и др. химических объектов
Рис. 3. Модели белков
Задачи «Большого вызова»
Моделирование белков и др. химических объектов
Рис. 3. Модели белков
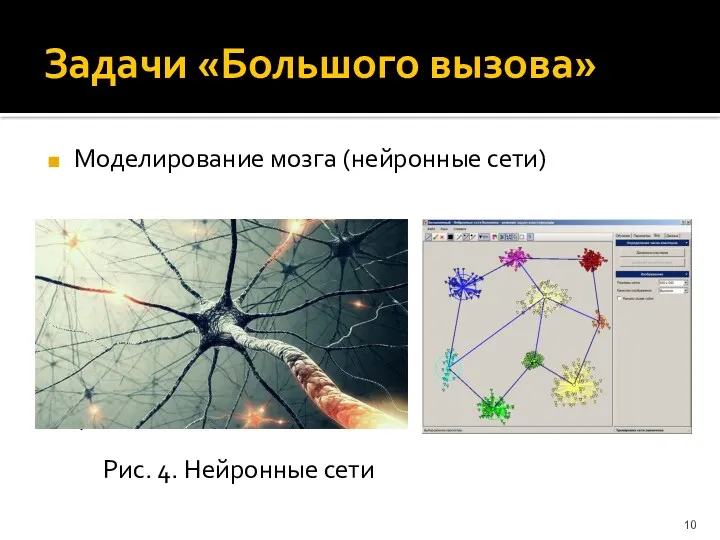
Задачи «Большого вызова»
Моделирование мозга (нейронные сети)
(
Рис. 4. Нейронные сети
Задачи «Большого вызова»
Моделирование мозга (нейронные сети)
(
Рис. 4. Нейронные сети

Задачи «Большого вызова»
Расчеты сложных физических реакций
Рис. 5. Сложные физические взаимодействия
Задачи «Большого вызова»
Расчеты сложных физических реакций
Рис. 5. Сложные физические взаимодействия

Параллелизм
Стратегическое направление развития вычислительной техники
Основной путь повышения производительности компьютеров
ASCI – Accelerated
Параллелизм
Стратегическое направление развития вычислительной техники
Основной путь повышения производительности компьютеров
ASCI – Accelerated

Пути достижения параллелизма
Независимость функционирования отдельных устройств компьютеров
Избыточность элементов вычислительной системы (использование
Пути достижения параллелизма
Независимость функционирования отдельных устройств компьютеров
Избыточность элементов вычислительной системы (использование

Сдерживающие факторы
Высокая стоимость параллельных вычислительных систем (суперкомпьютеров)
Необходимость обобщения последовательных программ
Потери производительности
Сдерживающие факторы
Высокая стоимость параллельных вычислительных систем (суперкомпьютеров)
Необходимость обобщения последовательных программ
Потери производительности
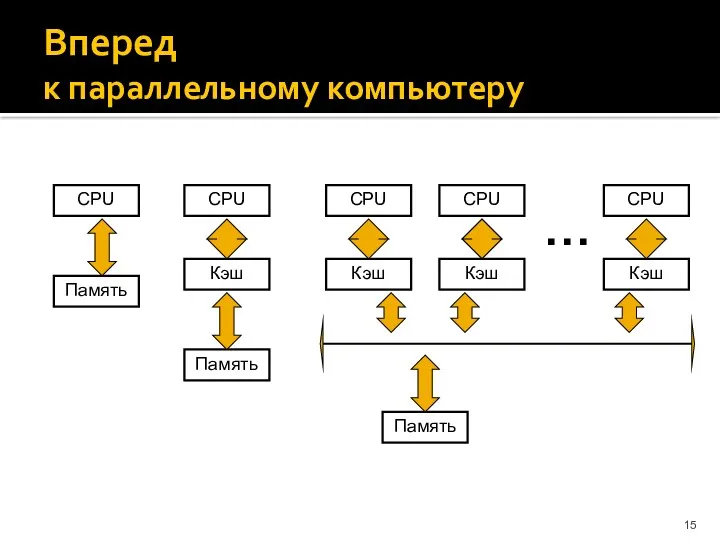
Вперед
к параллельному компьютеру
Вперед
к параллельному компьютеру
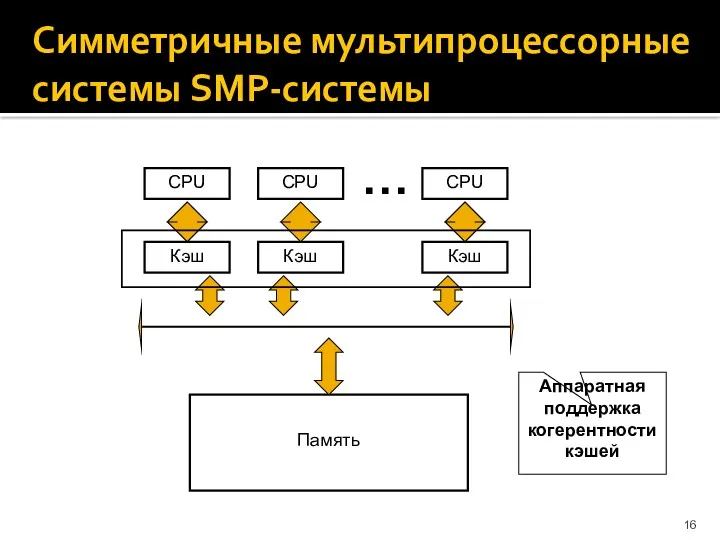
Симметричные мультипроцессорные системы SMP-системы
Кэш
CPU
Память
Кэш
CPU
Кэш
CPU
…
Аппаратная поддержка когерентности кэшей
Симметричные мультипроцессорные системы SMP-системы
Кэш
CPU
Память
Кэш
CPU
Кэш
CPU
…
Аппаратная поддержка когерентности кэшей
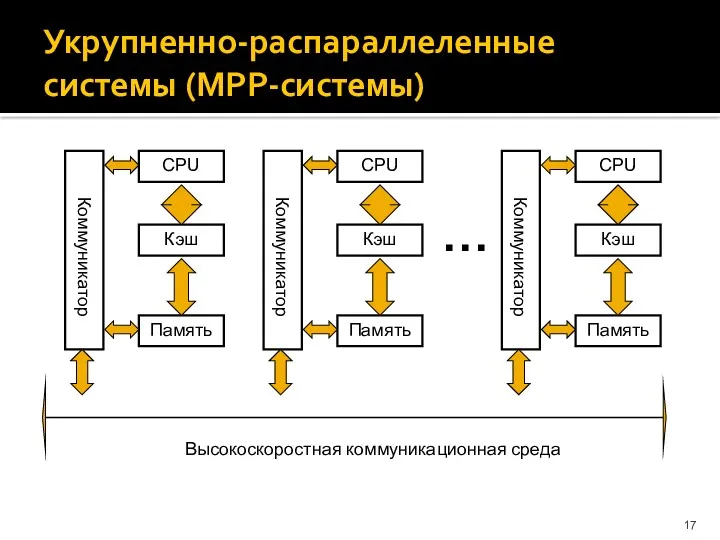
Укрупненно-распараллеленные системы (МРР-системы)
…
Высокоскоростная коммуникационная среда
Укрупненно-распараллеленные системы (МРР-системы)
…
Высокоскоростная коммуникационная среда
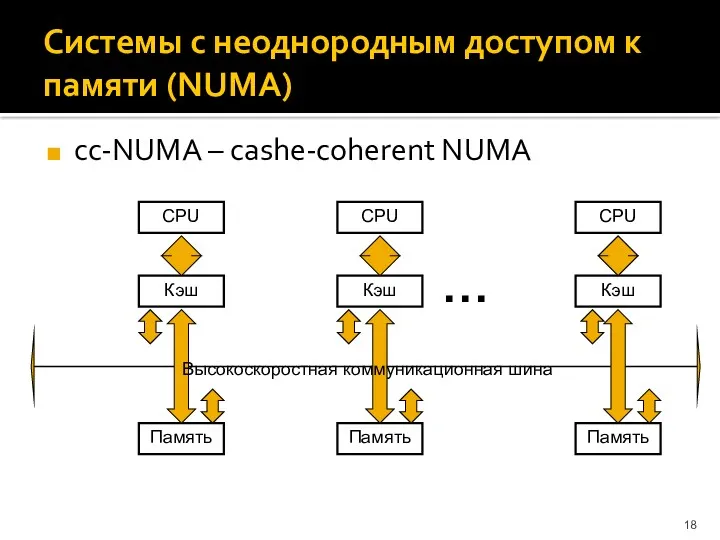
Системы с неоднородным доступом к памяти (NUMA)
cc-NUMA – cashe-coherent NUMA
…
Кэш
CPU
Память
Кэш
CPU
Память
Кэш
CPU
Память
Высокоскоростная коммуникационная
Системы с неоднородным доступом к памяти (NUMA)
cc-NUMA – cashe-coherent NUMA
…
Кэш
CPU
Память
Кэш
CPU
Память
Кэш
CPU
Память
Высокоскоростная коммуникационная

Параллельные векторные системы PVP-системы
Векторно-конвейерные процессоры:
SMP - конфигурация
MPP - конфигурация
Модель
Параллельные векторные системы PVP-системы
Векторно-конвейерные процессоры:
SMP - конфигурация
MPP - конфигурация
Модель
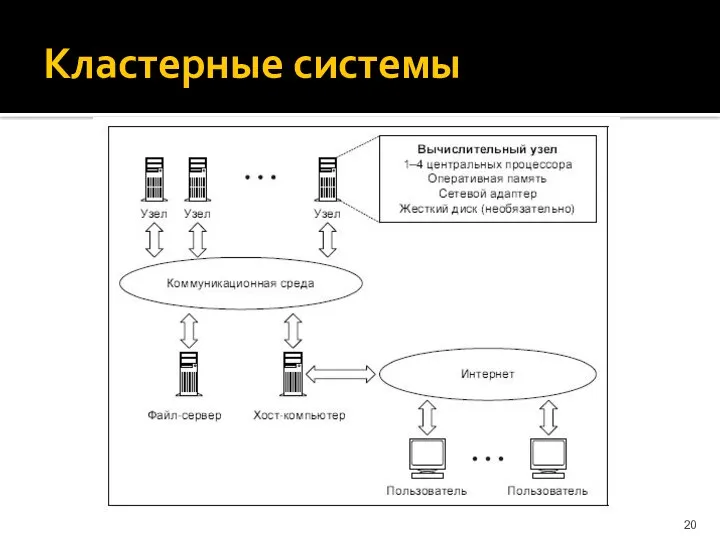
Кластерные системы
Кластерные системы
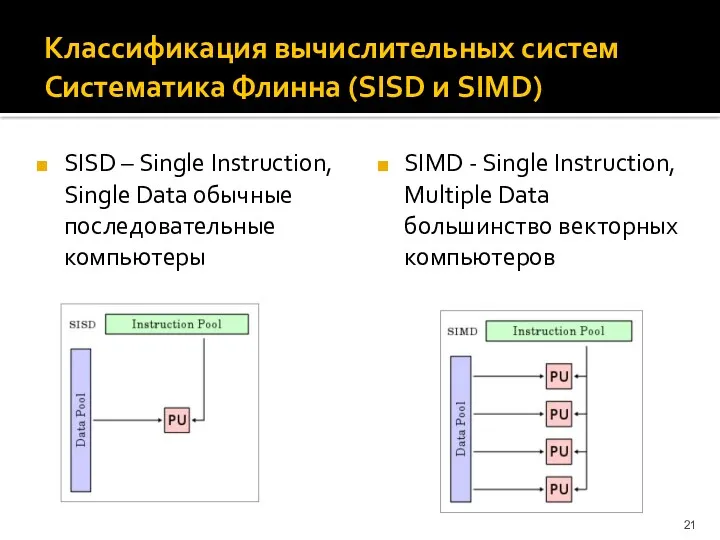
Классификация вычислительных систем
Систематика Флинна (SISD и SIMD)
SISD – Single Instruction, Single
Классификация вычислительных систем
Систематика Флинна (SISD и SIMD)
SISD – Single Instruction, Single
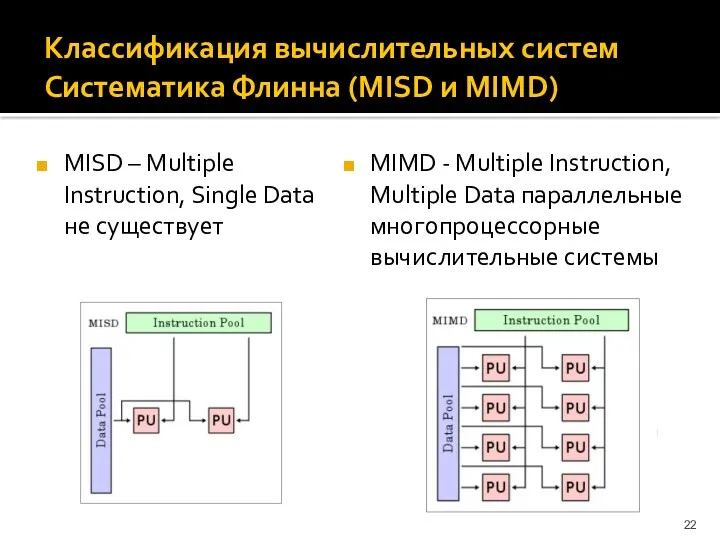
Классификация вычислительных систем
Систематика Флинна (MISD и MIMD)
MISD – Multiple Instruction, Single
Классификация вычислительных систем
Систематика Флинна (MISD и MIMD)
MISD – Multiple Instruction, Single
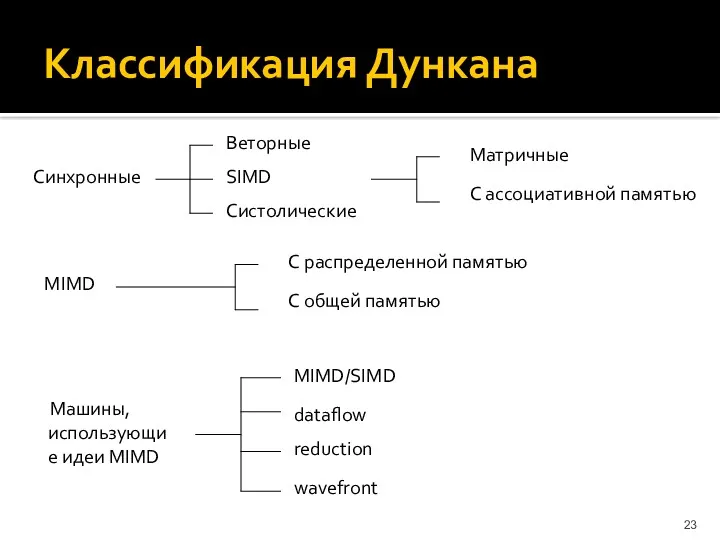
Классификация Дункана
Синхронные
Веторные
SIMD
Систолические
Матричные
С ассоциативной памятью
MIMD
С распределенной памятью
С общей памятью
Машины, использующие идеи MIMD
MIMD/SIMD
dataflow
reduction
wavefront
Классификация Дункана
Синхронные
Веторные
SIMD
Систолические
Матричные
С ассоциативной памятью
MIMD
С распределенной памятью
С общей памятью
Машины, использующие идеи MIMD
MIMD/SIMD
dataflow
reduction
wavefront
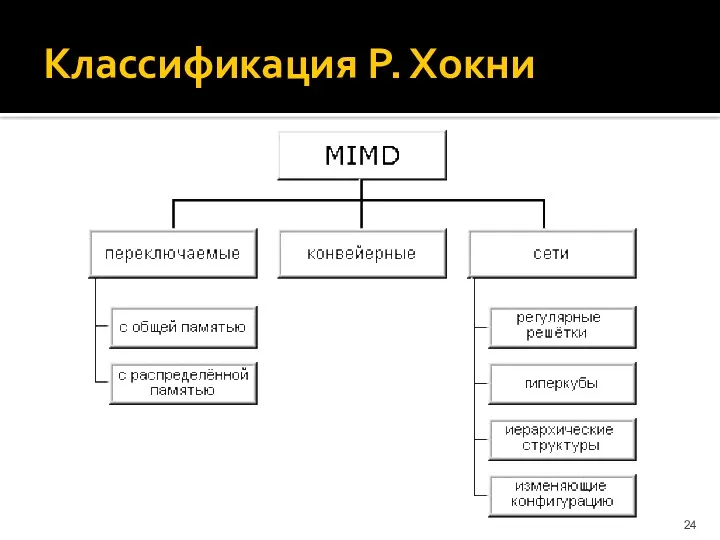
Классификация Р. Хокни
Классификация Р. Хокни

Другие классификации
Классификация В. Хендлера (t(C) = (k,d,w))
Классификация Л. Шнайдера (Iw(Ia)w(Iv) Iw(Ia)w(Iv))
Другие классификации
Классификация В. Хендлера (t(C) = (k,d,w))
Классификация Л. Шнайдера (Iw(Ia)w(Iv) Iw(Ia)w(Iv))
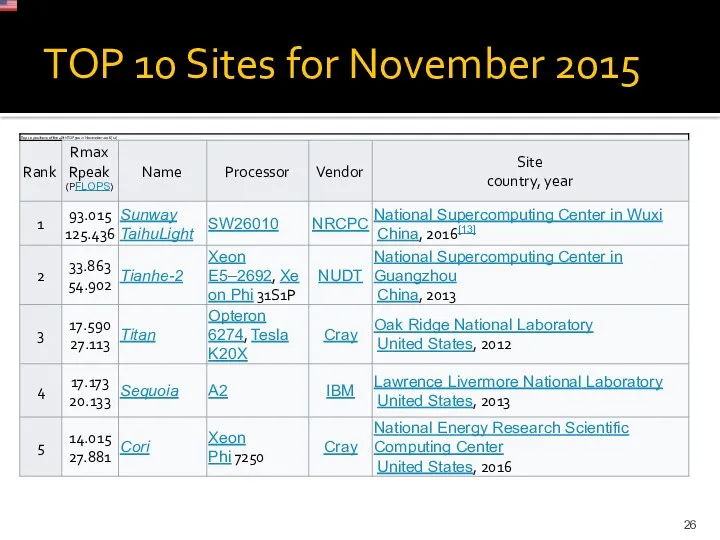
TOP 10 Sites for November 2015
TOP 10 Sites for November 2015

Сергей Королёв
Общие характеристики:
Общее число серверов/процессоров/вычислительных ядер: 165/332/1712;
Общее число графических процессоров/ядер: 5/4216;
Общая
Сергей Королёв
Общие характеристики:
Общее число серверов/процессоров/вычислительных ядер: 165/332/1712;
Общее число графических процессоров/ядер: 5/4216;
Общая

Сергей Королёв
Вычислительная часть
112 вычислительных блейд-серверов (2х Intel Xeon X5560, 12 Гб,
Сергей Королёв
Вычислительная часть
112 вычислительных блейд-серверов (2х Intel Xeon X5560, 12 Гб,

Сопроцессоры Intel Xeon Phi
61 ядро,
244 потока
производительность 1,2 терафлопс.
Векторные операции
Сопроцессоры Intel Xeon Phi
61 ядро,
244 потока
производительность 1,2 терафлопс.
Векторные операции
 Типы алгоритмов
Типы алгоритмов Интернет. Адресация в сети Интернет
Интернет. Адресация в сети Интернет Создание базы данных туристической фирмы
Создание базы данных туристической фирмы Электронный документооборот
Электронный документооборот Лекция 25. Пролог. Решение логических задач
Лекция 25. Пролог. Решение логических задач Как сделать портфолио
Как сделать портфолио Социальные сети
Социальные сети Операционная система Windows 2000. История создания
Операционная система Windows 2000. История создания Массивы
Массивы Event Notification in SIP SUBSCRIBE and NOTIFY and an example service
Event Notification in SIP SUBSCRIBE and NOTIFY and an example service Мережева безпека. Інструменти для аналізу трафіка
Мережева безпека. Інструменти для аналізу трафіка Функциональное программирование в реальной жизни
Функциональное программирование в реальной жизни E-mail
E-mail Двумерные массивы
Двумерные массивы Логическое программирование
Логическое программирование Ma’lumot modeli tushunchasi. Ierarxik (shajara) ma’lumot modeli
Ma’lumot modeli tushunchasi. Ierarxik (shajara) ma’lumot modeli Проект Перевод в Lazarus
Проект Перевод в Lazarus Процессор - основное устройство обработки информации
Процессор - основное устройство обработки информации разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON
разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON Разработка информационной системы автоматизации трейдинга
Разработка информационной системы автоматизации трейдинга Карта знань
Карта знань Презентация к уроку в 9 классе Системы оптического распознавания документов
Презентация к уроку в 9 классе Системы оптического распознавания документов Solaris - операционная система для архитектуры SPARC
Solaris - операционная система для архитектуры SPARC Логическая семиотика
Логическая семиотика Біометрична ідентифікація
Біометрична ідентифікація Подходы к понятию и измерению информации. Информационные объекты различных видов
Подходы к понятию и измерению информации. Информационные объекты различных видов Цифровая обработка сигналов
Цифровая обработка сигналов Фрагментация и персонификация контента в интернете
Фрагментация и персонификация контента в интернете