- Помехоустойчивое кодирование в системах телекоммуникаций (ПКСТ)

Содержание
- 2. Список литературы ОСНОВНАЯ 1. Макаров А.А., Прибылов В.П. Помехоустойчивое кодирование 2005г. 2. Макаров А.А.,Чернецкий Г.А. Корректирующие
- 3. Список литературы ДОПОЛНИТЕЛЬНАЯ: 1. Кларк Дж. и Кейн Дж. Кодирование с исправлением ошибок в системах цифровой
- 4. Историческая справка 1948г. К. Шеннон показал, что за счет кодирования передаваемой по каналу связи информации при
- 5. Историческая справка 1950г. Р. Хэмминг открыл класс кодов, исправляющий 1 ошибку в блоке длины 1960г. Р.
- 6. Основные практические приложения теории помехоустойчивого кодирования включают: Сотовая, транкинговая, пейджинговая и спутниковая связь; Сети передачи данных
- 7. ОЗУ ЭВМ (в режиме обнаружения или в режиме исправления); Шины данных ЭВМ (USB и др., высокая
- 8. Обобщенная структурная схема системы связи
- 9. Статистическое кодирование используется для уменьшения первичной избыточности передаваемой информации. Криптографическая защита используется для предотвращения несанкционированного доступа
- 10. Основная задача перемежителя состоит в перестановке элементов потока данных с выхода кодера помехоустойчивого кода таким образом,
- 11. Модулятор преобразует кодовые символы с выхода перемежителя в соответствующие аналоговые символы. Так как в канале связи
- 12. Декодер помехоустойчивого кода (второе решающее устройство) использует избыточность кодового слова для того, чтобы обнаружить или обнаружить
- 13. Дискретный канал связи Обобщенная структурная схема системы передачи дискретных сообщений (СПДС) Если входные и выходные сигналы
- 14. Математическая модель ДКС требует описания следующих параметров: 1) алфавитов входных и выходных сообщений (набор различных символов,
- 15. Диаграмма состояний и переходов для двоичного ДКС
- 16. S0, S1 – элементы алфавита источника; y0, y1 – элементы алфавита на выходе канала; q –
- 17. ДКС могут быть: 1) симметричными, когда переходные вероятности p(yi/Sj) одинаковы для всех i≠j и, соответственно, несимметричными
- 18. 3) без стирания, когда алфавиты на входе канала и выходе демодулятора совпадают, в канале со стиранием
- 19. Основные понятия и определения теории кодирования Избыточность кода , где n – количество элементов (символов) в
- 20. Скорость кода Чем больше избыточность кода, тем меньше скорость кода, и наоборот.
- 21. Расстояние Хэмминга между двумя кодовыми словами dij где xik , xjk – координаты слов Ai ,
- 22. Если код является двоичным, под расстоянием между парой кодовых слов понимается количество символов, в которых они
- 23. Пример Дано: А1=111, А2=100 Решение: d12 =(А1+А2)mod 2= 111 100 011, ∑"1"=2. Ответ: d12 = 2.
- 24. Таким образом, расстоянием Хэмминга между двумя двоичными последовательностями, называется число позиций, в которых они различны. Минимальное
- 25. Число ошибочных символов в принятом кодовом слове называется кратностью ошибки t, при длине кодового слова n
- 26. Для исправления ошибок кратности tи, требуется кодовое расстояние Это означает, что для исправления ошибок искаженное кодовое
- 27. В случае исправления tи ошибок и tq стираний (кратность стирания) кодовое расстояние d Спектр весов кода
- 28. Очевидно, что наилучшим как для исправления, так и для обнаружения ошибок будет код с наибольшим кодовым
- 29. Граница Хэмминга имеет вид: Граница Плоткина имеет вид:
- 30. Граница Хемминга утверждает, что не существует кодов с гарантированно исправляющих ошибки кратности , а граница Плоткина
- 31. Оптимальными обычно считаются такие коды, которые обеспечивают в заданном канале меньшую вероятность ошибки декодирования при одинаковой
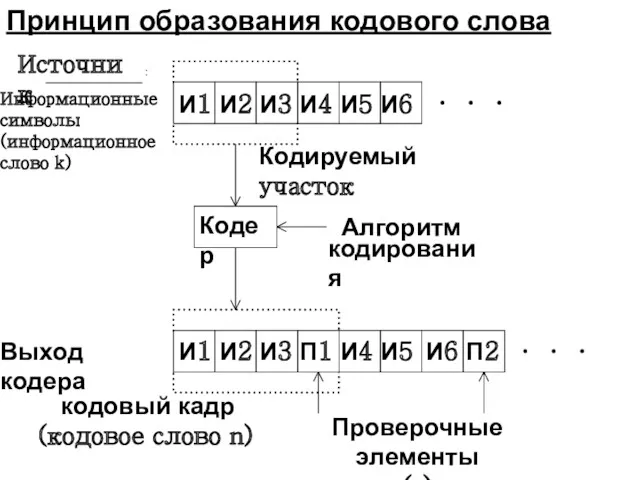
- 32. И1 И2 И3 И4 И5 И6 Источник : Информационные символы (информационное слово k) Кодируемый участок Кодер
- 33. Последовательность символов на выходе источника разбивается на блоки (кодовые слова или кодовые комбинации), содержащие одинаковое число
- 34. В общем случае для равномерного блочного кода с основанием m код имеет возможных кодовых слов. Используемые
- 35. Если в результате искажений в канале связи переданное кодовое слово превращается в одно из запрещенных слов
- 36. По сравнению с обнаружением исправление ошибок представляет собой более сложную операцию, поскольку в этом случае помимо
- 37. Каждое из этих подмножеств в декодере приемника приписывается одному из разрешенных кодовых слов. Если принятое кодовое
- 38. Если передаваемая (разрешенная) комбинация может в результате искажений с одинаковой вероятностью превратиться в любую из N
- 39. Коэффициент исправления кода, как доля исправленных ошибок, когда разрешенная комбинация с одинаковой вероятностью превращается в любую
- 40. Отношение , следовательно коэффициент исправления кода Ки всегда меньше коэффициента обнаружения, что является общим условием для
- 41. В общем случае передаваемая кодовая комбинация искажается случайным образом, что определяется случайным характером помех в канале
- 42. Вероятность необнаруживаемой ошибки при этом равна Коэффициент исправления кода где Pи – вероятность исправления ошибки в
- 43. Так как в канале связи возникают различного типа шумы, искажения и интерференция, то сигнал на входе
- 44. В соответствии с правилом жесткого решения сигнал на выходе демодулятора определен однозначно для каждого тактового интервала
- 45. Мягкое решение демодулятора может быть использовано для дальнейшего повышения помехоустойчивости приема (например, мягкого декодирования кодовых слов
- 46. Процесс декодирования можно представить в виде двух операций, в результате которых на выходе декодера получается оценка
- 47. Если , то информационные символы в кодовом слове имеют такой же вид, какой они имели на
- 48. Критерием, позволяющим минимизировать потери информации, является критерий максимального правдоподобия (МП). Правило решения по критерию МП можно
- 49. При этом обеспечивается минимум потерь информации, т.е. I( ↔Ai) - I( ↔Aj) > 0 для всех
- 50. где N – число кодовых слов данного кода; P(Ai, Aj) – совместная вероятность передачи кодового слова
- 51. Классификация корректирующих кодов Все коды делятся: Блочные - передаваемое сообщение делится на блоки. Процесс кодирования и
- 52. Разделимые – можно определить информационные и проверочные элементы. Неразделимые – этого сделать нельзя. Линейные – это
- 53. Все линейные коды делятся: Систематические (групповые)-если две комбинации принадлежат этой группе, то при сложении по модулю
- 54. Простейшие корректирующие коды Код с четным числом единиц Код с четным числом единиц является блочным кодом
- 55. Например, для к =2 00 → 000 01 → 011 10 → 101 11 → 110
- 56. Простейшие корректирующие коды Они только обнаруживают ошибку. 1) Код с проверкой на четность: Добавляем к информационным
- 57. Коэффициент обнаружения: Данный код обнаруживает ошибки нечетной кратности.
- 58. Избыточность: Данный код разделимый и блочный
- 59. 2) Код с постоянным весом: Вес- количество единиц кодовой комбинации. Рассмотрим код 3 к 4: 1001100
- 61. Избыточность: Код блочный неразделимый cистематический.
- 62. Обнаруживает все ошибки нечетной кратности и 50% ошибок вероятности четной кратности. Не обнаруживает ошибки четной кратности,
- 63. Инверсный код Кодовые слова инверсного корректирующего кода образуются повторением исходного кодового слова. Если число единиц в
- 64. Таблица кодирования а) а) в исходном кодовом слове четное число единиц, б) в исходном кодовом слове
- 65. Для обнаружения ошибок в кодовой комбинации, состоящей из n=r+k (в таблице n=10) производится две операции. Суммируются
- 66. Несовпадение хотя бы одной из пар сравниваемых кодовых элементов указывает на наличие ошибки в комбинации. Код
- 67. Энергетический выигрыш от кодирования Энергетический выигрыш от кодирования (ЭВК) указывает на улучшение качества системы связи от
- 68. где , – отношения сигнал/шум в сравниваемых системах связи при одинаковой вероятности ошибок на выходе; –
- 69. Для системы c кодом, исправляющим ошибки без переспроса, относительная скорость равна = k/n = R, т.е.
- 70. Если снять ограничения на длину кодового слова и полосу частот, то предельный выигрыш от помехоустойчивого кодирования
- 71. В тех случаях, когда непрерывный канал, включая модулятор и демодулятор, заданы, выигрыш от помехоустойчивого кодирования можно
- 72. Линейные двоичные блочные коды (групповые коды) Двоичный блочный код является линейным тогда и только тогда, когда
- 73. Кодовые слова такого кода содержат n символов; причем к символов – являются информационными, а остальные r
- 74. Так как разрешенные кодовые слова группового линейного кода образуют подгруппу относительно операции сложения по модулю два,
- 75. Для построения группового кода используют понятия: Производящая матрица и Проверочная матрица. Производящая матрица G кода (n,
- 76. = = = где к – количество столбцов в единичной подматрице, r – количество столбцов в
- 77. Символы могут быть найдены произвольно, однако должны выполняться условия: - вес каждой строки производящей матрицы ;
- 78. Для определения алгоритмов кодирования и декодирования некоторого группового линейного кода строится проверочная матрица H. Проверочная матрица
- 79. = = Эта матрица используется для составления проверочных уравнений.
- 80. Для построения группового (n, k) кода с заданными параметрами n и tи, и определения правил кодирования
- 81. Пример Построить групповой двоичный код, исправляющий одиночные ошибки tи=1, длина кодового слова n=7. Решение задачи будем
- 82. 2 этап: Определение количества проверочных элементов r производится согласно границе Хэмминга. , ; , , примем
- 83. 3 этап: Строим производящую матрицу G:
- 84. Проверочные символы записываем так, чтобы расстояния между кодовыми словами A1, A2, A3 и А4 и веса
- 86. Нулевое слово, хотя и не используется для передачи, также является разрешенным, так как оно определяется как
- 87. 5 этап: Проверка расстояний между разрешенными словами Эта проверка, в принципе, эквивалентна определению веса каждого разрешенного
- 88. 6 этап: Определение спектра весов N(w) и производящей функции T(z) кода. Подсчет количества одинаковых весов дает:
- 89. Производящая функция будет иметь вид: 7 этап: Формирование проверочной матрицы H. Для проверочной матрицы выбираем такие
- 90. Таким образом, все строки проверочной матрицы будут удовлетворять проверкам на четность: Операция кодирования, т.е. вычисление проверочных
- 91. Таким образом, если на вход кодера поступает последовательность вида {0110}, то на его выходе кодовое слово:
- 92. Вектор (s1,s2,s3) называется синдромом и зависит только от конфигурации ошибок: в этих суммах значения всех неискаженных
- 94. Таким образом, по значению синдрома декодер может определить, в какой позиции произошла ошибка, и исправить ее.
- 95. где s1, s2 и s3 – элементы синдрома ошибки, указывающие на факт наличия ошибки в случае
- 96. 3) Устанавливаем, что искажен тот символ, который входит только в 1-ю и 3-ю проверки, как видно,
- 97. Обобщенная структурная схема синдромного декодера группового линейного кода
- 98. Если оценка последовательности ошибок точна ( ), то оценка декодируемого кодового слова является переданным кодовым словом
- 99. В системах с обнаружением ошибок значение меньше по сравнению с аналогичным значением для систем с исправлением
- 100. Вероятность правильного приема кодового слова длины n в каналах с независимыми ошибками вероятности p определяется как
- 101. Соответственно, значение вероятности ошибки декодирования Без знания спектра весов кода вероятность обнаружения ошибок можно определить только
- 102. Тогда Режим исправления ошибок. Вероятность неверного декодирования в этом случае полностью определяется кратностью исправления ошибок кода
- 103. или, с учетом больших значений n, Зачастую необходимо оценивать помехоустойчивость устройства защиты от ошибок по эквивалентной
- 104. Число логических операций, необходимых для декодирования кодового слова длиной n (сложность декодера), обычно, увеличивается экспоненциально с
- 105. Пример Закодировать модифицированным кодом Хэмминга (7,4), d=3 комбинацию из четырех информационных символов {И1,И2,И3,И4}={1,0,0,1}. Определяем значения проверочных
- 106. Таким образом, передаваемое кодовое слово кода Хэмминга имеет вид {И4,И3,И2,П3,И1,П2,П1}={1,0,0,1,1,0,0}. Допустим, что в канале связи был
- 107. Записываем результат проверки в виде S3S2S1=011, что равно десятичному числу 3, которое указывает номер искаженного разряда,
- 108. Обнаруживающая способность кода Хэмминга может быть увеличена на единицу ( ) введением дополнительной проверки на четность.
- 109. а кодовое расстояние расширенного кода (8, 4) равно d=4. Однако следует отметить, что введение бита проверки
- 110. Для расширенного модифицированного кода Хэмминга кодовая последовательность имеет вид, представленный в таблице Распределение символов кодовой посылки
- 111. Циклическим кодом называется линейный блочный код (n,k), который характеризуется свойством цикличности, то есть сдвиг влево на
- 112. Множество кодовых слов циклического кода представляется совокупностью полиномов степени (n-1) и менее, делящихся на некоторый полином
- 113. Производящая матрица циклического кода определяется путем умножения g(x) степени (n-k) последовательно на . Проверочная матрица совершенного
- 114. Умножение и деление многочленов производится по обычным правилам алгебры, но с приведением подобных членов по модулю
- 116. Полином , полученный в результате деления ( ) на g(x), и будет первой строкой проверочной матрицы.
- 117. Проверочная матрица позволяет вычислить синдром ошибки в виде полинома степени (n-k-1) где B(x) − полином принятого
- 118. АЛГОРИТМ ПОЛУЧЕНИЯ РАЗРЕШЕННОЙ КОДОВОЙ КОМБИНАЦИИ ЦИКЛИЧЕСКОГО КОДА ИЗ КОМБИНАЦИИ ПРОСТОГО КОДА Пусть задан полином определяющий корректирующую
- 119. 1. Умножаем многочлен исходной кодовой комбинации : 2. Определяем проверочные разряды, дополняющие исходную информационную комбинацию до
- 120. Для обнаружения ошибок в принятой кодовой комбинации достаточно поделить ее на производящий полином. Если принятая комбинация
- 121. Пример. Пусть требуется закодировать комбинацию вида 1101, что соответствует Определяем число проверочных символов r=3. Из таблицы
- 122. Разделим полученное произведение на образующий полином g(x) В результате получим закодированное сообщение:
- 123. В полученной кодовой комбинации циклического кода информационные символы A(x)=1101, а проверочные 001. Закодированное сообщение делится на
- 124. Построение формирователя остатка циклического кода Структура устройства осуществляющего деление на полином полностью определяется видом этого полинома.
- 125. 1.Число ячеек памяти равно степени образующего полинома r. 2.Число сумматоров на единицу меньше веса кодирующей комбинации
- 126. Сумматоры ставят после каждой ячейки памяти, (начиная с нулевой) для которой существует НЕнулевой член полинома. Не
- 127. 4. В цепь обратной связи необходимо поставить ключ, обеспечивающий правильный ввод исходных элементов и вывод результатов
- 128. Рассмотрим работу этой схемы
- 129. 1. На первом этапе К1– замкнут, К2 – разомкнут. Идет одновременное заполнение регистров задержки и сдвига
- 130. Одновременно из РЗ на выход выталкивается задержанные информационные разряды. За 5 тактов (с 5 по 9
- 131. 3. К2 – размыкается, К1 – замыкается и вслед за информационными в линию уйдут элементы проверочной
- 132. Второй вариант построения кодера ЦК. Рассмотренный выше кодер очень наглядно отражает процесс деления двоичных чисел. Однако
- 134. За пять тактов в ячейках будет сформирован такой же остаток от деления, что и в рассмотренном
- 135. Далее вслед за информационными уходят проверочные из ячеек устройств деления. Но важно отключить обратную связь на
- 136. Окончательно структурная схема экономичного кодера выглядит так.
- 137. - На первом такте Кл.1 и Кл.3 замкнуты, информационные элементы проходят на выход кодера и одновременно
- 138. - на шестом такте ключи 1 и 3 размыкаются (разрываются обратная связь), а ключ 2 замыкается
- 139. Определение ошибочного разряда в ЦК. Пусть А(х)-многочлен, соответствующий переданной кодовой комбинации. Н(х)- многочлен, соответствующий принятой кодовой
- 140. При однократной ошибке Е(х) будет содержать только один единственный член, соответствующий ошибочному разряду. Остаток, полученный от
- 141. При этом ошибке в каждом разряде будет соответствовать свой остаток R(x) (он же синдром), а значит,
- 142. Алгоритм определения ошибки. Пусть имеем n-элементные комбинации (n = k + r) тогда: 1. Получаем остаток
- 143. 3. Сравниваем R0(x) и R(x). - Если они равны, то ошибка произошла в старшем разряде. Если
- 144. - Если они равны, то ошибки во втором разряде. - Если нет, то умножаем и повторяем
- 145. Пример декодирования комбинации ЦК. Положим, получена комбинация H(х)=111011010 Проанализируем её в соответствии с вышеприведенным алгоритмом. Реализуя
- 147. Разделим принятую комбинацию на образующий полином H(x) · x
- 148. 1110110100 10011 10011 111111 5-т 11101 10011 6-т 11100 10011 7-т 11111 10011 8-т 11000 10011
- 149. Полученный на 9-м такте остаток, как видим, не равен R0(x). Значит необходимо умножить принятую комбинацию на
- 150. В нашем случае это произойдет на 10 такте, при повышении степени на 1. Значит ошибки во
- 151. Декодер циклического с исправлением ошибки
- 152. Если ошибка в первом разряде, то остаток R0(x)=10101 появляется после девятого такта в ячейках ФПГ. Если
- 153. в пятом по старшинству то после 13го в шестом по старшинству то после 14го в седьмом
- 154. Если и этому моменту остаток в ФПГ=R0(x), то логическая 1 с выхода дешифратора поступит на второй
- 155. Действия над многочленами. При формировании комбинаций циклического кода часто используют операции сложения многочленов и деления одного
- 156. Рассмотрим операцию деления на следующем примере:
- 157. Деление выполняется, как обычно, только вычитание заменяется суммированием по модулю два. Отметим, что запись кодовой комбинации
- 158. Умножение многочленов производится по обычным правилам алгебры, но с приведением подобных членов по модулю 2. Например,
- 159. Выбор образующего полинома Рассмотрим вопрос выбора образующего полинома, который определяет корректирующие свойства циклического кода. В теории
- 160. Декодер Меггита Декодер Меггита представляет собой синдромный декодер, исправляющий одиночные ошибки. В нем хранится только один
- 161. Декодер Меггита для циклического кода (15,11)
- 162. Декодер работает следующим образом: кодовое слово (с ошибками или без них) в виде последовательности из 15
- 163. Ошибка обнаруживается, если хотя бы один элемент синдрома не равен нулю. Исправление ошибок производится в следующих
- 164. В пунктирном квадрате показана возможная модификация регистра синдрома, упрощающая реализацию схемы И. Для этого принимаемая последовательность
- 165. СВЕРТОЧНЫЕ КОДЫ Сверточными кодами являются древовидные коды, на которые накладываются дополнительные ограничения по линейности и постоянстве
- 166. или в виде полиномов a(х) = g(х) d(х), где ai – символы кода, gi-k – весовые
- 167. Эти полиномы могут быть объединены в матрицу где i=1...k0, j=1...n0, k0 и n0 − целые числа:
- 168. При использовании сверточных кодов поток данных разбивается на гораздо меньшие блоки длиной k символов, которые называются
- 169. Вместо длины кодового слова часто используется понятие «длина кодового ограничения» nа, которая показывает максимальное расстояние между
- 170. Входная последовательность из k информационных символов представляется вектором-строкой ; а кодовое слово на выходе кодера Операция
- 171. а вектор синдромов ошибки (синдромных полиномов) равен т.е. (n0 - k0)-мерный вектор-строка из полиномов, а B(x)
- 172. Как и блочные, сверточные коды могут быть систематическими и несистематическими и обозначаются как линейные сверточные (n,k)
- 173. Кодирование сверточных кодов производится аналогично блочным циклическим кодам с помощью регистров сдвига, у которых структура обратных
- 174. Кодеры сверточных кодов а) R=1/2 и б) R=2/3
- 175. Кодеры работают следующим образом. На вход регистра сдвига кодера (а) из 3 ячеек памяти подается двоичная
- 176. Матрица производящих полиномов кода R=2/3 (рисунок б) имеет вид Регистры сдвига 1 и 2 (число регистров
- 177. Переключатель Пвх разделяет входные информационные символы между регистрами, переключатель Пвых формирует кодовую последовательность на выходе кодера
- 179. Кодовое дерево строится таким образом, что информационному символу «0» соответствует перемещение на верхнюю ветвь (ребро) дерева,
- 180. Это обстоятельство определяется состоянием двух последних ячеек памяти регистра сдвига кодера (00,01,10,11); в общем случае число
- 181. Решетка сверточного кода представляет состояния кодера в виде четырех уровней, а ветви дерева являются ребрами решетки,
- 182. Если сверточный код является систематическим, то g1(x) = 1 (в верхней ветви кодера рисунка (а) отсутствует
- 183. Для кодера рис. (а) длина кодового ограничения равна 3. Эта величина означает, что поступивший на вход
- 184. Таким образом, действие одного информационного символа, поступившего на вход кодера, ограничено тремя тактовыми интервалами, т.е. от
- 185. Существует несколько способов описания связей между разрядами в регистре сдвига и сумматорами по модулю 2: 1.
- 186. Каждый вектор имеет составляющих из нулей и единиц (количество разрядов в регистре сдвига) и описывает связь
- 187. Единица (1) на i-й позиции вектора означает, что разряд с номером i связан с сумматором, а
- 188. Так, для кодера на рис.(а) число сумматоров n=2 и будет вектор связи для верхнего сумматора и
- 189. 2. Второй способ позволяет представить связи между разрядами регистра и сумматорами в виде набора из n
- 190. В зависимости от того, имеется ли связь между cоответствующими разрядами регистра сдвига и сумматором, в каждом
- 191. Для кодера рис.(а) полиноминальные генераторы будут иметь следующий вид: С помощью полиноминальных генераторов легко определить кодовые
- 192. Пусть, например, на вход кодера поступает последовательность информационных символов Этой последовательности соответствует полином Полином b(x), соответствующий
- 193. Сначала найдем произведения ,
- 194. (значения сумм в круглых скобках определяем по модулю 2).
- 195. Полином b(x), коэффициентами которого будут кодовые символы на выходе кодера, определим сложением и (здесь сложение не
- 196. Последовательность кодовых символов определяется двойными коэффициентами в круглых скобках полинома b(x), т.е. =11 10 01 10
- 197. Построение решетчатой диаграммы Решетчатая диаграмма также состоит из ребер и узлов. Все узлы решетки, расположенные вдоль
- 198. При построении решетки, как и для древовидной диаграммы, предполагается, что первоначально ячейки регистра сдвига кодера содержали
- 199. Если на вход кодера, находящегося в состоянии a=00, поступает информационный символ 0 или 1, то на
- 200. На 1-м уровне имеется два узла «a» и «b», из которых выходит 4 ребра. Из узла
- 201. На 3-м уровне наблюдается принципиальное отличие древовидной и решетчатой диаграмм. На древовидной на 3-м уровне расположено
- 202. Аналогично происходит и с другими узлами «b»,«c» и «d». На 4-м уровне на древовидной диаграмме отождествляются
- 203. Таким образом, в результате описанных отождествлений получается решетчатая диаграмма, на которой на любом уровне после 3-го
- 204. В рассматриваемом примере кодера Поэтому получаем
- 205. Алгоритм сверточного декодирования Витерби Пример декодирования по алгоритму Витерби R=1/2 Предположим, что передавалось нулевая кодовая последовательность
- 211. Из построенной диаграммы декодера видно, что от момента t1 до момента t6 выжил только один путь
- 213. Декодер принимает решение, что на интервале от t1 до t6 по каналу передавалась последовательность кодовых символов,
- 214. Алгоритм сверточного декодирования Витерби 1.При декодировании используются как решетчатая диаграмма кодера, так и решетчатая диаграмма декодера.
- 215. Эти расстояния пишут над соответствующими ребрами решетчатой диаграммы декодера. Обозначения на ребрах решетки декодера накапливаются декодером
- 216. 2. С помощью пометок (цифр) на ребрах решетчатой диаграммы декодера для момента времени ti определяются расстояния
- 217. Для каждого момента времени ti (где i >3) имеем четыре узла и в каждый узел приходят
- 218. Декодирование Витерби состоит в том, что из двух путей, приходящих в один узел, при продолжении операции
- 219. Отсекание одного из двух путей, сходящихся в узле решетки, гарантирует, что число продолжающихся путей будет равно
- 220. В результате использования алгоритма декодирования Витерби находится наиболее вероятный (с минимальным расстоянием Хэмминга) путь через решетку
- 221. Основные трудности при реализации алгоритма Витерби определяются тем, что сложность декодера экспоненциально растет с увеличением кодового
- 222. Декодирование по алгоритму Витерби кода R=2/3 оказывается существенно сложнее по сравнению с кодами R=1/2. В каждую
- 223. В общем случае для кодов R=k0/n0 требуется -ичное сравнение, что приводит к значительным усложнениям практической реализации
- 224. Например, для получения кода R=3/4 выкалывается каждый третий символ, сформированный кодером, и на выход поступают, соответственно,
- 225. Сверточные коды R=1/n0 строятся аналогично кодам R=1/2, но имеют большее кодовое расстояние и кодовое ограничение. В
- 226. В качестве дополнительного производящего полинома g3(x) может быть взят g1(x) или g2(x). Изменения алгоритма Витерби состоят
- 227. Последовательное декодирование В отличие от алгоритма Витерби при последовательном декодировании производится продолжение и обновление метрики только
- 228. Если решение о декодируемом символе, находящемся в начале пути, принять невозможно, то производится либо движение вперед,
- 229. Основное достоинство последовательного алгоритма заключается в том, что в среднем длина пути, достаточная для правильного декодирования
- 230. Недостатки определяются тем, что длина пути, приводящего к правильному декодированию, является случайной величиной. Это вызывает затруднения
- 231. В практике построения последовательных декодеров применяются два варианта алгоритма последовательного декодирования, позволяющих получить приемлемые для реализации
- 232. Декодер создает стек, состоящий из просмотренных ранее путей (могут иметь различную длину) и упорядочивает их в
- 233. Пример. Дано: передаваемая информационная последовательность I(x)=100, скорость кода R=1/2, na=3, производящие полиномы кода последовательность ошибок e(x)=010000.
- 234. Найти: оценку переданного слова с использованием стек-алгоритма декодирования сверточных кодов. Решение: переданная кодовая последовательность равна A(x)=110111.
- 235. Декодирование осуществляется за несколько шагов, где состояния представляют собой возможные состояния триггеров регистра кодера R1(x) и
- 236. Принятая последовательность: B=10.01.11 Стек «оценка информационной последовательности – метрика пути»: 0 – 1 1 – 1
- 237. B=10.01.11 1 – 1 00 – 2 01 – 2
- 238. B=10.01.11 10 – 1 00 – 2 01 – 2 11 – 3
- 239. B=10.01.11 100– 1 (декод.) 00 – 2 01 – 2 101 – 3 11 – 3
- 240. Выводы: Последовательное декодирование позволяет использовать большие значения длины кодового ограничения (на практике, 100>K>10), что повышает помехоустойчивость
- 241. Синдромное декодирование Синдромное декодирование сверточных кодов, в принципе, не отличается от синдромного декодирования циклических кодов. Вначале
- 242. Практически используются, в основном, два метода синдромного декодирования: декодирование с табличным поиском; пороговое декодирование.
- 243. Декодирование с табличным поиском заключается в том, что вычисленный синдром ошибки сравнивается с таблицей всевозможных синдромов
- 244. Применение: Сверточные коды с малым кодовым ограничением (na≤10÷20) и с малым энергетическим выигрышем (1÷2,5 дБ)
- 245. Пороговое декодирование возможно для определенного класса линейных кодов как блочных, так и сверточных, позволяющих получить так
- 246. Пороговое декодирование сверточных кодов Структурная схема порогового декодера
- 247. Последовательность символов канала bk после разделения на информационные buk и проверочные bpk поступает в регистр синдрома,
- 248. Исправление ошибки происходит в сумматоре по модулю два, на второй вход которого подаются информационные символы канала
- 249. КАСКАДНЫЕ КОДЫ Каскадные коды используются в практике передачи дискретных сигналов в качестве методов реализации кодов большой
- 250. Последовательные каскадные коды
- 251. Вторая ступень кодирования в последовательном каскадном кодеке формирует k2 строк, каждая из которых состоит из k1
- 252. К k2 информационным символам внешнего кода приписывается (n2-k2) проверочных символов, каждый из которых также состоит из
- 253. При этом следует иметь в виду, что кодовое слово кода 1-ой ступени может составлять только часть
- 254. В другом методе формирования каскадного кода (иногда называемого итеративным кодом) k2 информационных блоков, каждый из которых
- 255. Каждый ее столбец образует k2 символов, которые являются информационными символами кода (n2, k2) 2-ой ступени (внешнего
- 256. В результате и в том и другом случае образуется блок двоичных символов (матрица n1×n2) длиной n1⋅n2,
- 257. где aij − информационные символы, bij − проверочные символы
- 258. В качестве кодов 1-ой и 2-ой ступеней могут использоваться как блочные, так и сверточные коды. При
- 259. В качестве внешнего кода могут применяться как блочные (например, циклические), так и сверточные коды. Одним из
- 260. Вероятность ошибки на выходе декодера кодов РС в каналах с независимыми ошибками где t − кратность
- 261. Каскадное кодирование с внешним кодом РС (или сверточным кодом с итерационным декодированием) и внутренним сверточным кодом
- 262. Параллельные каскадные коды Параллельные каскадные коды с итерационным декодированием, обычно называют турбокодами. Турбокод может рассматриваться как
- 263. Турбокод образуется при параллельном каскадировании двух или более систематических кодов. Обычно используются два или три первичных
- 264. Структурная схема турбокодера
- 265. Блок данных u длиной k символов поступает сначала на вход турбокодера. Последовательность символов x0= u поступает
- 266. В этой схеме передаваемая информация совместно используется во всех компонентных кодерах. Каждый перемежитель преобразует структуру последовательности
- 267. Возможность исправления ошибок зависят не только от минимального кодового расстояния, но и от распределения весов кода,
- 268. Поэтому задачей перемежителя является преобразование входной последовательности таким образом, чтобы последовательности, приводящие к кодовым словам с
- 269. На выходах компонентных кодеров каждой из М ветвей образуются последовательности проверочных символов x1... xM. Поскольку информационные
- 270. Эта информационная последовательность x0 мультиплексируется с проверочными последовательностями x1... xM, образуя кодовое слово, которое подлежит передаче
- 271. Для повышения скорости кода применяют выкалывание (перфорацию) определенных проверочных символов выходной последовательности кодера. В типичном случае
- 272. Схема турбокодера с двумя одинаковыми кодерами
- 273. Операция выкалывания сводится к передаче в канал нечетных проверочных символов первого кодера и четных проверочных символов
- 274. Выкалывание позволяет устанавливать произвольное значение кодовой скорости и даже адаптировать параметры кодера к свойствам канала. Если
- 276. Декодирование турбокодов. В основе декодирования кодов, исправляющих ошибки, лежит сравнение вероятностных характеристик различных кодовых слов, а
- 277. Если имеется некоторое предварительное знание о принимаемом сигнале до его декодирования, то такая информация называется априорной
- 278. Структурная схема турбодекодера
- 279. Рассмотрим процесс декодирования для случая, когда кодирование осуществляется двухкомпонентным турбокодером. При этом в результате демультиплексирования на
- 280. После декодирования информационной и первой проверочной последовательностей получается начальная оценка информационной последовательности, которая может использоваться как
- 281. Такой подход требует, чтобы компонентный декодер мог использовать мягкое решение для входных данных ("мягкий" вход) и
- 282. КОДЫ БЧХ И РИДА-СОЛОМОНА Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их
- 283. Кодирующий многочлен g(x) для БЧХ-кода, длина кодовых слов n которого , строится так. Находится примитивный многочлен
- 284. Построенный кодирующий многочлен производит код с минимальным расстоянием между кодовыми словами, не меньшим d , и
- 285. Пример Построить код БЧХ при n=7 для исправления независимых ошибок кратности tи=1. Решение: 1) Для исправления
- 286. 3) Число проверочных символов ; . 4) Находим производящий полином, учитывая, что g(x)= , где i=1,
- 287. 5)Строим производящую матрицу, которая образуется добавлением n-k нулей к производящему полиному, записанному в виде двоичного числа;
- 288. 6)Суммируя по модулю два во всевозможных сочетаниях строки производящей матрицы, получим остальные 11 разрешенных кодовых слов
- 289. Также к ним применимы все методы, используемые для декодирования циклических кодов. Однако существуют гораздо лучшие алгоритмы,
- 290. Код Рида-Соломона является частным случаем БЧХ-кода. Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять
- 291. Построение недвоичных (q-ичных) кодов БЧХ мало отличается от построения двоичных кодов и сводится к определению производящего
- 292. Код Рида — Соломона, исправляющий t ошибок, требует 2t проверочных символов и с его помощью исправляются
- 293. Кодирование с помощью кода Рида — Соломона может быть реализовано двумя способами: систематическим и несистематическим. При
- 294. При систематическом кодировании к информационному блоку из k символов приписываются 2t проверочных символов, при вычислении каждого
- 295. При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного слова S длины k на
- 296. К исходному слову приписываются 2t нулей, получается полином . Этот полином делится на порождающий полином G,
- 297. Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия: - Вычисляет синдром ошибки -
- 298. Вычисление синдрома ошибки Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое слово на порождающий многочлен.
- 299. Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове. Нахождение корней На этом этапе
- 300. Определение характера ошибки и ее исправление По синдрому ошибки и найденным корням полинома с помощью алгоритма
- 302. Скачать презентацию

Список литературы
ОСНОВНАЯ
1. Макаров А.А., Прибылов В.П. Помехоустойчивое кодирование 2005г.
2. Макаров
Список литературы
ОСНОВНАЯ
1. Макаров А.А., Прибылов В.П. Помехоустойчивое кодирование 2005г.
2. Макаров

Список литературы
ДОПОЛНИТЕЛЬНАЯ:
1. Кларк Дж. и Кейн Дж. Кодирование с исправлением ошибок
Список литературы
ДОПОЛНИТЕЛЬНАЯ:
1. Кларк Дж. и Кейн Дж. Кодирование с исправлением ошибок

Историческая справка
1948г. К. Шеннон показал, что за счет кодирования передаваемой по
Историческая справка
1948г. К. Шеннон показал, что за счет кодирования передаваемой по

Историческая справка
1950г. Р. Хэмминг открыл класс кодов, исправляющий 1 ошибку в
Историческая справка
1950г. Р. Хэмминг открыл класс кодов, исправляющий 1 ошибку в

Основные практические приложения теории помехоустойчивого кодирования включают:
Сотовая, транкинговая, пейджинговая и спутниковая
Основные практические приложения теории помехоустойчивого кодирования включают:
Сотовая, транкинговая, пейджинговая и спутниковая

ОЗУ ЭВМ (в режиме обнаружения или в режиме исправления);
Шины данных ЭВМ
ОЗУ ЭВМ (в режиме обнаружения или в режиме исправления);
Шины данных ЭВМ
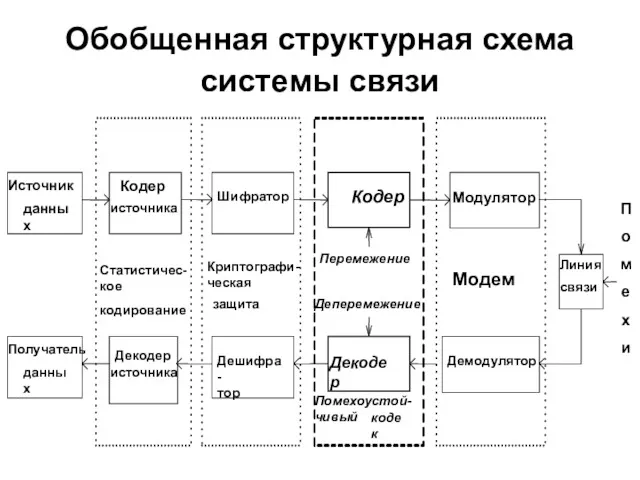
Обобщенная структурная схема системы связи
Обобщенная структурная схема системы связи

Статистическое кодирование используется для уменьшения первичной избыточности передаваемой информации.
Криптографическая защита
Статистическое кодирование используется для уменьшения первичной избыточности передаваемой информации.
Криптографическая защита

Основная задача перемежителя состоит в перестановке элементов потока данных с выхода
Основная задача перемежителя состоит в перестановке элементов потока данных с выхода

Модулятор преобразует кодовые символы с выхода перемежителя в соответствующие аналоговые символы.
Модулятор преобразует кодовые символы с выхода перемежителя в соответствующие аналоговые символы.

Декодер помехоустойчивого кода (второе решающее устройство) использует избыточность кодового слова для
Декодер помехоустойчивого кода (второе решающее устройство) использует избыточность кодового слова для
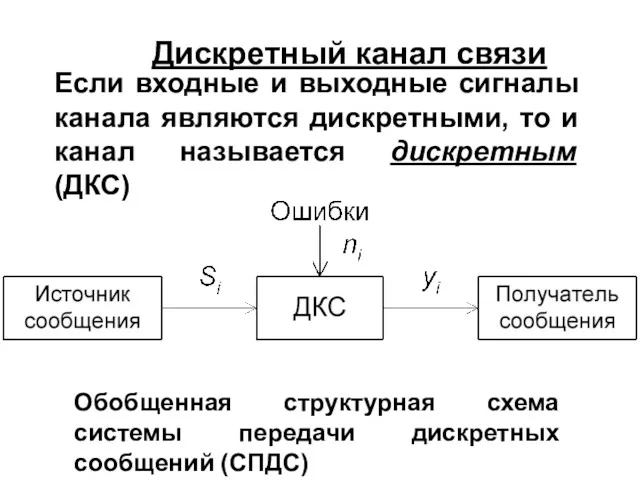
Дискретный канал связи
Обобщенная структурная схема системы передачи дискретных сообщений (СПДС)
Если
Дискретный канал связи
Обобщенная структурная схема системы передачи дискретных сообщений (СПДС)
Если

Математическая модель ДКС требует описания следующих параметров:
1) алфавитов входных и выходных
Математическая модель ДКС требует описания следующих параметров:
1) алфавитов входных и выходных
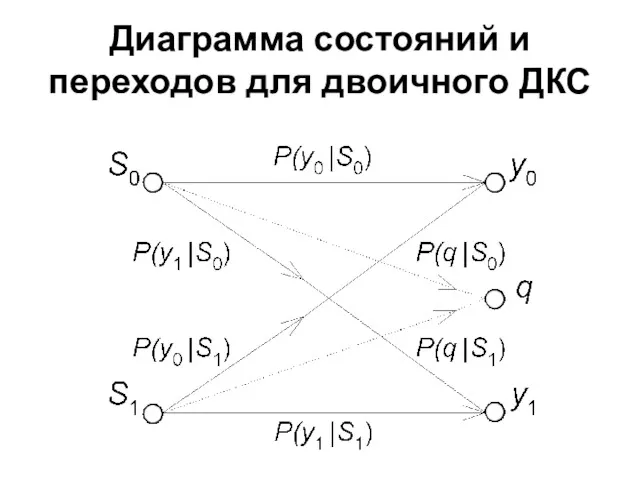
Диаграмма состояний и переходов для двоичного ДКС
Диаграмма состояний и переходов для двоичного ДКС

S0, S1 – элементы алфавита
источника;
y0, y1 – элементы алфавита на
S0, S1 – элементы алфавита
источника;
y0, y1 – элементы алфавита на

ДКС могут быть:
1) симметричными, когда переходные вероятности p(yi/Sj) одинаковы для
ДКС могут быть:
1) симметричными, когда переходные вероятности p(yi/Sj) одинаковы для

3) без стирания, когда алфавиты на входе канала и выходе
3) без стирания, когда алфавиты на входе канала и выходе

Основные понятия и определения теории кодирования
Избыточность кода
,
где n – количество элементов (символов)
Основные понятия и определения теории кодирования
Избыточность кода
,
где n – количество элементов (символов)

Скорость кода
Чем больше избыточность кода, тем меньше скорость кода, и наоборот.
Скорость кода
Чем больше избыточность кода, тем меньше скорость кода, и наоборот.

Расстояние Хэмминга между двумя кодовыми словами dij
где xik , xjk –
Расстояние Хэмминга между двумя кодовыми словами dij
где xik , xjk –

Если код является двоичным, под расстоянием между парой кодовых слов понимается
Если код является двоичным, под расстоянием между парой кодовых слов понимается

Пример
Дано: А1=111, А2=100
Решение: d12 =(А1+А2)mod 2=
111
100
011, ∑"1"=2.
Ответ: d12 =
Пример
Дано: А1=111, А2=100
Решение: d12 =(А1+А2)mod 2=
111
100
011, ∑"1"=2.
Ответ: d12 =

Таким образом, расстоянием Хэмминга между двумя двоичными последовательностями, называется число позиций,
Таким образом, расстоянием Хэмминга между двумя двоичными последовательностями, называется число позиций,

Число ошибочных символов в принятом кодовом слове называется
кратностью ошибки t, при

Для исправления ошибок кратности tи, требуется кодовое расстояние
Это означает, что
Для исправления ошибок кратности tи, требуется кодовое расстояние
Это означает, что

В случае исправления tи ошибок и tq стираний (кратность стирания) кодовое
В случае исправления tи ошибок и tq стираний (кратность стирания) кодовое

Очевидно, что наилучшим как для исправления, так и для обнаружения ошибок
Очевидно, что наилучшим как для исправления, так и для обнаружения ошибок
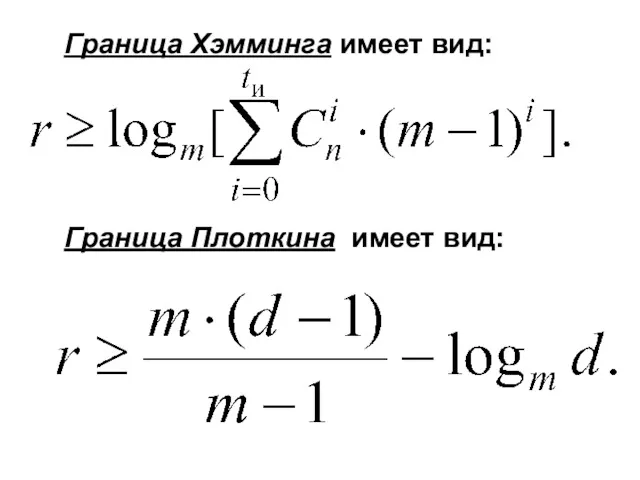
Граница Хэмминга имеет вид:
Граница Плоткина имеет вид:
Граница Хэмминга имеет вид:
Граница Плоткина имеет вид:

Граница Хемминга утверждает, что не существует кодов с
гарантированно исправляющих ошибки
Граница Хемминга утверждает, что не существует кодов с
гарантированно исправляющих ошибки

Оптимальными обычно считаются такие коды, которые обеспечивают в заданном канале меньшую
Оптимальными обычно считаются такие коды, которые обеспечивают в заданном канале меньшую
И1
И2
И3
И4
И5
И6
Источник
:
Информационные
символы (информационное
слово k)
Кодируемый
участок
Кодер
Алгоритм
кодирования
И1
И2
И3
И4
И5
И6
П1
П2
Проверочные элементы
(r)
Выход кодера
кодовый кадр
(кодовое слово n)
Принцип образования кодового
И1
И2
И3
И4
И5
И6
Источник
:
Информационные
символы (информационное
слово k)
Кодируемый
участок
Кодер
Алгоритм
кодирования
И1
И2
И3
И4
И5
И6
П1
П2
Проверочные элементы
(r)
Выход кодера
кодовый кадр
(кодовое слово n)
Принцип образования кодового

Последовательность символов на выходе источника разбивается на блоки (кодовые слова или
Последовательность символов на выходе источника разбивается на блоки (кодовые слова или

В общем случае для равномерного блочного кода с основанием m код
В общем случае для равномерного блочного кода с основанием m код

Если в результате искажений в канале связи переданное кодовое слово
Если в результате искажений в канале связи переданное кодовое слово

По сравнению с обнаружением исправление ошибок представляет собой более сложную операцию,
По сравнению с обнаружением исправление ошибок представляет собой более сложную операцию,

Каждое из этих подмножеств в декодере приемника приписывается одному из разрешенных
Каждое из этих подмножеств в декодере приемника приписывается одному из разрешенных

Если передаваемая (разрешенная) комбинация может в результате искажений с одинаковой вероятностью
Если передаваемая (разрешенная) комбинация может в результате искажений с одинаковой вероятностью

Коэффициент исправления кода, как доля исправленных ошибок, когда разрешенная комбинация с
Коэффициент исправления кода, как доля исправленных ошибок, когда разрешенная комбинация с

Отношение ,
следовательно коэффициент исправления кода Ки всегда меньше коэффициента обнаружения,
Отношение ,
следовательно коэффициент исправления кода Ки всегда меньше коэффициента обнаружения,

В общем случае передаваемая кодовая комбинация искажается случайным образом, что определяется
В общем случае передаваемая кодовая комбинация искажается случайным образом, что определяется

Вероятность необнаруживаемой ошибки при этом равна
Коэффициент исправления кода
где Pи – вероятность
Вероятность необнаруживаемой ошибки при этом равна
Коэффициент исправления кода
где Pи – вероятность

Так как в канале связи возникают различного типа шумы, искажения и
Так как в канале связи возникают различного типа шумы, искажения и

В соответствии с правилом жесткого решения сигнал на выходе демодулятора определен
В соответствии с правилом жесткого решения сигнал на выходе демодулятора определен

Мягкое решение демодулятора может быть использовано для дальнейшего повышения помехоустойчивости приема
Мягкое решение демодулятора может быть использовано для дальнейшего повышения помехоустойчивости приема

Процесс декодирования можно представить в виде двух операций,
в результате которых на
Процесс декодирования можно представить в виде двух операций, в результате которых на

Если , то информационные символы в кодовом слове имеют такой же
Если , то информационные символы в кодовом слове имеют такой же

Критерием, позволяющим минимизировать потери информации, является критерий максимального правдоподобия (МП). Правило
Критерием, позволяющим минимизировать потери информации, является критерий максимального правдоподобия (МП). Правило

При этом обеспечивается минимум потерь информации, т.е.
I( ↔Ai) - I( ↔Aj)
При этом обеспечивается минимум потерь информации, т.е.
I( ↔Ai) - I( ↔Aj)

где N – число кодовых слов данного кода; P(Ai, Aj) –
где N – число кодовых слов данного кода; P(Ai, Aj) –

Классификация корректирующих кодов
Все коды делятся:
Блочные - передаваемое сообщение делится на
Классификация корректирующих кодов
Все коды делятся:
Блочные - передаваемое сообщение делится на

Разделимые – можно определить информационные и проверочные элементы.
Неразделимые – этого сделать
Разделимые – можно определить информационные и проверочные элементы.
Неразделимые – этого сделать

Все линейные коды делятся:
Систематические (групповые)-если две комбинации принадлежат этой группе, то
Все линейные коды делятся:
Систематические (групповые)-если две комбинации принадлежат этой группе, то

Простейшие корректирующие коды
Код с четным числом единиц
Код с четным числом единиц
Простейшие корректирующие коды
Код с четным числом единиц
Код с четным числом единиц

Например, для к =2 00 → 000
01 → 011
10 → 101
11
Например, для к =2 00 → 000
01 → 011
10 → 101
11

Простейшие корректирующие коды
Они только обнаруживают ошибку.
1) Код с проверкой на четность:
Добавляем
Простейшие корректирующие коды
Они только обнаруживают ошибку.
1) Код с проверкой на четность:
Добавляем

Коэффициент обнаружения:
Данный код обнаруживает ошибки нечетной кратности.
Коэффициент обнаружения:
Данный код обнаруживает ошибки нечетной кратности.

Избыточность:
Данный код разделимый и блочный
Избыточность:
Данный код разделимый и блочный

2) Код с постоянным весом:
Вес- количество единиц кодовой комбинации.
Рассмотрим код 3
2) Код с постоянным весом:
Вес- количество единиц кодовой комбинации.
Рассмотрим код 3

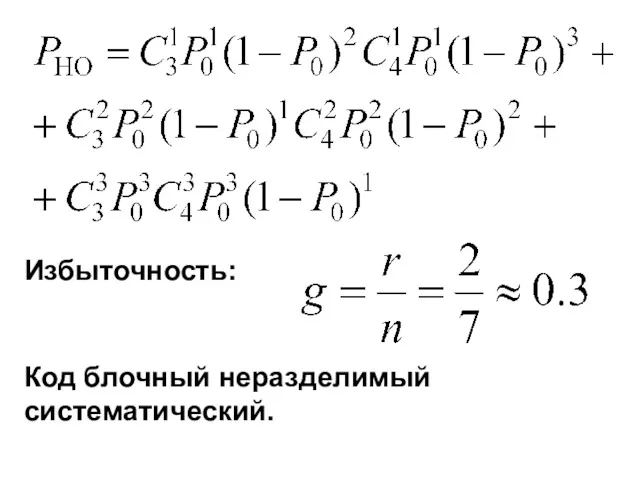
Избыточность:
Код блочный неразделимый cистематический.
Избыточность:
Код блочный неразделимый cистематический.

Обнаруживает все ошибки нечетной кратности и 50% ошибок вероятности четной кратности.
Обнаруживает все ошибки нечетной кратности и 50% ошибок вероятности четной кратности.

Инверсный код
Кодовые слова инверсного корректирующего кода образуются повторением исходного кодового слова.
Инверсный код
Кодовые слова инверсного корректирующего кода образуются повторением исходного кодового слова.
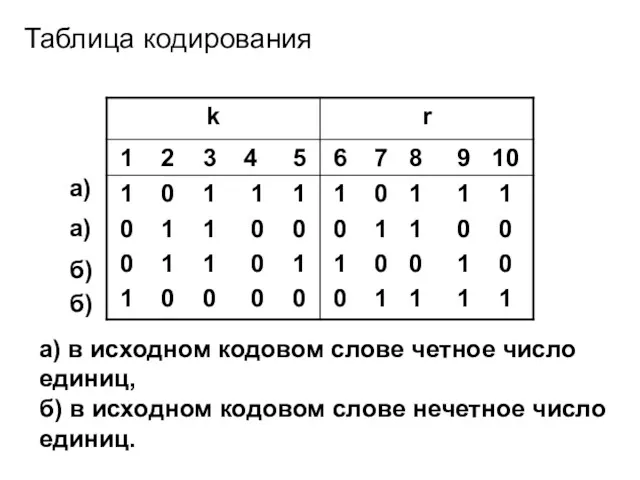
Таблица кодирования
а)
а) в исходном кодовом слове четное число единиц,
б) в
Таблица кодирования
а)
а) в исходном кодовом слове четное число единиц,
б) в

Для обнаружения ошибок в кодовой комбинации, состоящей из n=r+k (в таблице
Для обнаружения ошибок в кодовой комбинации, состоящей из n=r+k (в таблице

Несовпадение хотя бы одной из пар сравниваемых кодовых элементов указывает на
Несовпадение хотя бы одной из пар сравниваемых кодовых элементов указывает на

Энергетический выигрыш от кодирования
Энергетический выигрыш от кодирования (ЭВК) указывает на
Энергетический выигрыш от кодирования
Энергетический выигрыш от кодирования (ЭВК) указывает на

где , – отношения сигнал/шум в сравниваемых системах связи при одинаковой
где , – отношения сигнал/шум в сравниваемых системах связи при одинаковой

Для системы c кодом, исправляющим ошибки без переспроса, относительная скорость равна
Для системы c кодом, исправляющим ошибки без переспроса, относительная скорость равна

Если снять ограничения на длину кодового слова и полосу частот, то
Если снять ограничения на длину кодового слова и полосу частот, то

В тех случаях, когда непрерывный канал, включая модулятор и демодулятор, заданы,
В тех случаях, когда непрерывный канал, включая модулятор и демодулятор, заданы,

Линейные двоичные блочные коды
(групповые коды)
Двоичный блочный код является линейным
Линейные двоичные блочные коды
(групповые коды)
Двоичный блочный код является линейным

Кодовые слова такого кода содержат n символов; причем к символов –
Кодовые слова такого кода содержат n символов; причем к символов –

Так как разрешенные кодовые слова группового линейного кода образуют подгруппу относительно
Так как разрешенные кодовые слова группового линейного кода образуют подгруппу относительно

Для построения группового кода используют понятия: Производящая матрица и Проверочная матрица.
Для построения группового кода используют понятия: Производящая матрица и Проверочная матрица.

=
= =
где к – количество столбцов в единичной подматрице, r –
= =
где к – количество столбцов в единичной подматрице, r –

Символы могут быть найдены
произвольно, однако должны выполняться условия:
- вес каждой строки
Символы могут быть найдены
произвольно, однако должны выполняться условия:
- вес каждой строки

Для определения алгоритмов кодирования и декодирования некоторого группового линейного кода строится
Для определения алгоритмов кодирования и декодирования некоторого группового линейного кода строится

=
=
Эта матрица используется для составления проверочных уравнений.
=
=
Эта матрица используется для составления проверочных уравнений.

Для построения группового (n, k) кода с заданными параметрами n и
Для построения группового (n, k) кода с заданными параметрами n и

Пример
Построить групповой двоичный код, исправляющий одиночные ошибки tи=1, длина кодового
Пример
Построить групповой двоичный код, исправляющий одиночные ошибки tи=1, длина кодового

2 этап: Определение количества проверочных элементов r производится согласно границе Хэмминга.
,
2 этап: Определение количества проверочных элементов r производится согласно границе Хэмминга.
,

3 этап: Строим производящую матрицу G:

Проверочные символы записываем так, чтобы расстояния между кодовыми словами A1, A2,
Проверочные символы записываем так, чтобы расстояния между кодовыми словами A1, A2,


Нулевое слово, хотя и не используется для передачи, также является разрешенным,
Нулевое слово, хотя и не используется для передачи, также является разрешенным,

5 этап: Проверка расстояний между разрешенными словами
Эта проверка, в принципе,
5 этап: Проверка расстояний между разрешенными словами
Эта проверка, в принципе,
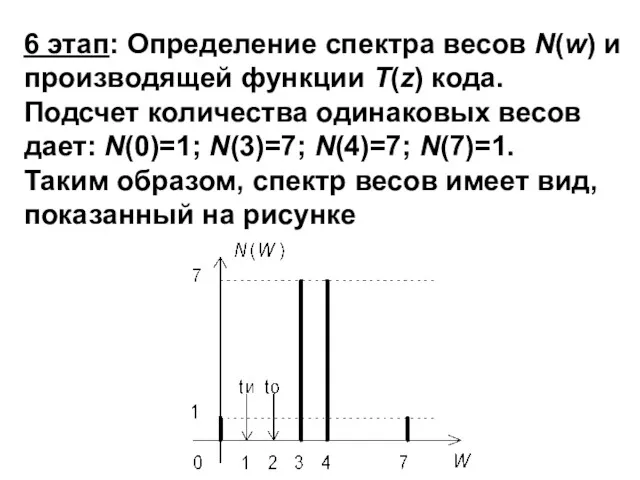
6 этап: Определение спектра весов N(w) и производящей функции T(z) кода.
Подсчет
6 этап: Определение спектра весов N(w) и производящей функции T(z) кода.
Подсчет

Производящая функция будет иметь вид:
7 этап: Формирование проверочной матрицы H.
Для проверочной
Производящая функция будет иметь вид:
7 этап: Формирование проверочной матрицы H.
Для проверочной

Таким образом, все строки проверочной матрицы будут удовлетворять проверкам на четность:
Операция
Таким образом, все строки проверочной матрицы будут удовлетворять проверкам на четность:
Операция

Таким образом, если на вход кодера поступает последовательность вида {0110}, то
Таким образом, если на вход кодера поступает последовательность вида {0110}, то

Вектор (s1,s2,s3) называется синдромом и зависит только от конфигурации ошибок: в
Вектор (s1,s2,s3) называется синдромом и зависит только от конфигурации ошибок: в
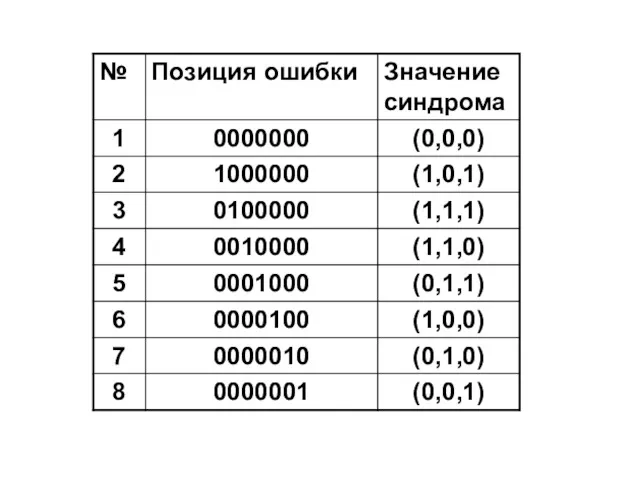

Таким образом, по значению синдрома декодер может определить, в какой позиции
Таким образом, по значению синдрома декодер может определить, в какой позиции

где s1, s2 и s3 – элементы синдрома ошибки, указывающие на
где s1, s2 и s3 – элементы синдрома ошибки, указывающие на

3) Устанавливаем, что искажен тот символ, который входит только в 1-ю
3) Устанавливаем, что искажен тот символ, который входит только в 1-ю
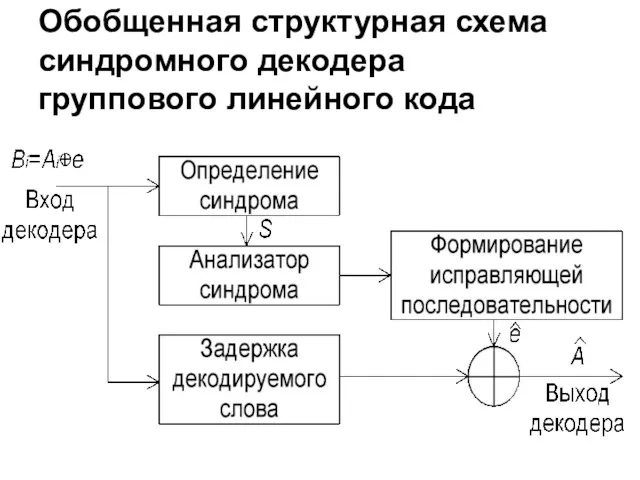
Обобщенная структурная схема синдромного декодера
группового линейного кода
Обобщенная структурная схема синдромного декодера
группового линейного кода

Если оценка последовательности ошибок точна ( ), то оценка декодируемого кодового
Если оценка последовательности ошибок точна ( ), то оценка декодируемого кодового

В системах с обнаружением ошибок значение меньше по сравнению с аналогичным
В системах с обнаружением ошибок значение меньше по сравнению с аналогичным

Вероятность правильного приема кодового слова длины n в каналах с независимыми
Вероятность правильного приема кодового слова длины n в каналах с независимыми

Соответственно, значение вероятности ошибки декодирования
Без знания спектра весов кода вероятность обнаружения
Соответственно, значение вероятности ошибки декодирования
Без знания спектра весов кода вероятность обнаружения

Тогда
Режим исправления ошибок.
Вероятность неверного декодирования в этом случае полностью определяется кратностью
Тогда
Режим исправления ошибок.
Вероятность неверного декодирования в этом случае полностью определяется кратностью

или, с учетом больших значений n,
Зачастую необходимо оценивать помехоустойчивость устройства защиты
или, с учетом больших значений n,
Зачастую необходимо оценивать помехоустойчивость устройства защиты

Число логических операций, необходимых для декодирования кодового слова длиной n (сложность
Число логических операций, необходимых для декодирования кодового слова длиной n (сложность

Пример
Закодировать модифицированным кодом Хэмминга (7,4), d=3 комбинацию из четырех информационных
Пример
Закодировать модифицированным кодом Хэмминга (7,4), d=3 комбинацию из четырех информационных

Таким образом, передаваемое кодовое слово кода Хэмминга имеет вид {И4,И3,И2,П3,И1,П2,П1}={1,0,0,1,1,0,0}.
Допустим,
Таким образом, передаваемое кодовое слово кода Хэмминга имеет вид {И4,И3,И2,П3,И1,П2,П1}={1,0,0,1,1,0,0}.
Допустим,

Записываем результат проверки в виде S3S2S1=011, что равно десятичному числу 3,
Записываем результат проверки в виде S3S2S1=011, что равно десятичному числу 3,

Обнаруживающая способность кода Хэмминга может быть увеличена на единицу ( )
Обнаруживающая способность кода Хэмминга может быть увеличена на единицу ( )

а кодовое расстояние расширенного кода (8, 4) равно d=4. Однако следует
а кодовое расстояние расширенного кода (8, 4) равно d=4. Однако следует

Для расширенного модифицированного кода Хэмминга кодовая последовательность имеет вид, представленный в
Для расширенного модифицированного кода Хэмминга кодовая последовательность имеет вид, представленный в

Циклическим кодом называется линейный блочный код (n,k), который характеризуется свойством цикличности,
Циклическим кодом называется линейный блочный код (n,k), который характеризуется свойством цикличности,

Множество кодовых слов циклического кода представляется совокупностью полиномов степени (n-1) и
Множество кодовых слов циклического кода представляется совокупностью полиномов степени (n-1) и

Производящая матрица циклического кода определяется путем умножения g(x) степени (n-k) последовательно
Производящая матрица циклического кода определяется путем умножения g(x) степени (n-k) последовательно

Умножение и деление многочленов производится по обычным правилам алгебры, но с
Умножение и деление многочленов производится по обычным правилам алгебры, но с


Полином , полученный в результате деления ( ) на g(x), и
Полином , полученный в результате деления ( ) на g(x), и

Проверочная матрица позволяет вычислить синдром ошибки в виде полинома степени (n-k-1)
где
Проверочная матрица позволяет вычислить синдром ошибки в виде полинома степени (n-k-1)
где

АЛГОРИТМ ПОЛУЧЕНИЯ РАЗРЕШЕННОЙ КОДОВОЙ КОМБИНАЦИИ ЦИКЛИЧЕСКОГО КОДА ИЗ КОМБИНАЦИИ ПРОСТОГО КОДА
Пусть
АЛГОРИТМ ПОЛУЧЕНИЯ РАЗРЕШЕННОЙ КОДОВОЙ КОМБИНАЦИИ ЦИКЛИЧЕСКОГО КОДА ИЗ КОМБИНАЦИИ ПРОСТОГО КОДА
Пусть

1. Умножаем многочлен исходной кодовой комбинации :
2. Определяем проверочные разряды, дополняющие
1. Умножаем многочлен исходной кодовой комбинации :
2. Определяем проверочные разряды, дополняющие

Для обнаружения ошибок в принятой кодовой комбинации достаточно поделить ее на
Для обнаружения ошибок в принятой кодовой комбинации достаточно поделить ее на

Пример. Пусть требуется закодировать комбинацию вида 1101, что соответствует
Определяем число проверочных
Пример. Пусть требуется закодировать комбинацию вида 1101, что соответствует
Определяем число проверочных

Разделим полученное произведение на образующий полином g(x)
В результате получим закодированное сообщение:
Разделим полученное произведение на образующий полином g(x)
В результате получим закодированное сообщение:

В полученной кодовой комбинации циклического кода информационные символы A(x)=1101, а проверочные
В полученной кодовой комбинации циклического кода информационные символы A(x)=1101, а проверочные

Построение формирователя остатка циклического кода
Структура устройства осуществляющего деление на полином полностью
Построение формирователя остатка циклического кода
Структура устройства осуществляющего деление на полином полностью

1.Число ячеек памяти равно степени образующего полинома r.
2.Число сумматоров на
1.Число ячеек памяти равно степени образующего полинома r.
2.Число сумматоров на
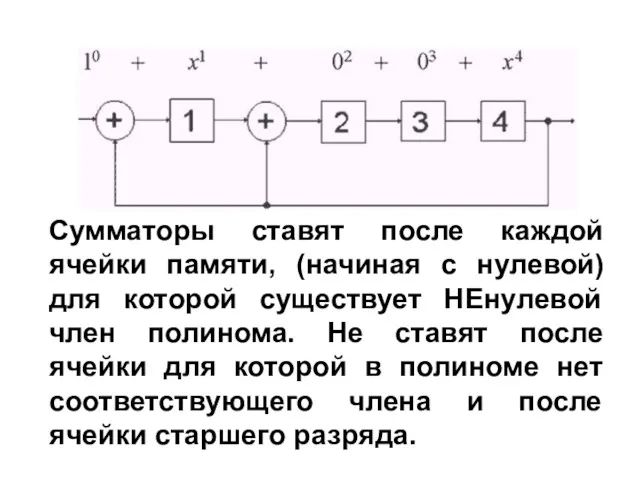
Сумматоры ставят после каждой ячейки памяти, (начиная с нулевой) для которой
Сумматоры ставят после каждой ячейки памяти, (начиная с нулевой) для которой

4. В цепь обратной связи необходимо поставить ключ, обеспечивающий правильный ввод
4. В цепь обратной связи необходимо поставить ключ, обеспечивающий правильный ввод
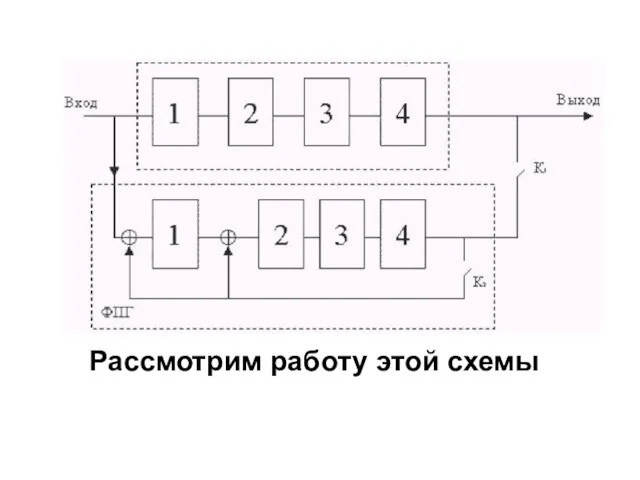
Рассмотрим работу этой схемы
Рассмотрим работу этой схемы

1. На первом этапе К1– замкнут, К2 – разомкнут. Идет одновременное
1. На первом этапе К1– замкнут, К2 – разомкнут. Идет одновременное

Одновременно из РЗ на выход выталкивается задержанные информационные разряды.
За 5 тактов
Одновременно из РЗ на выход выталкивается задержанные информационные разряды.
За 5 тактов

3. К2 – размыкается, К1 – замыкается и вслед за информационными
3. К2 – размыкается, К1 – замыкается и вслед за информационными

Второй вариант построения кодера ЦК.
Рассмотренный выше кодер очень наглядно отражает процесс
Второй вариант построения кодера ЦК.
Рассмотренный выше кодер очень наглядно отражает процесс


За пять тактов в ячейках будет сформирован такой же остаток от
За пять тактов в ячейках будет сформирован такой же остаток от

Далее вслед за информационными уходят проверочные из ячеек устройств деления.
Но важно
Далее вслед за информационными уходят проверочные из ячеек устройств деления.
Но важно
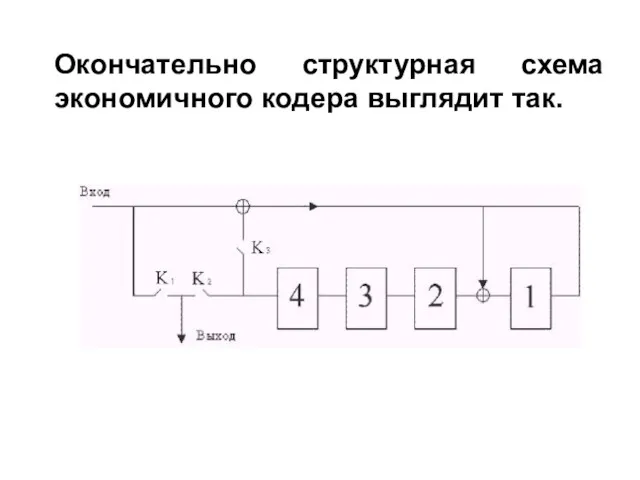
Окончательно структурная схема экономичного кодера выглядит так.
Окончательно структурная схема экономичного кодера выглядит так.

- На первом такте Кл.1 и Кл.3 замкнуты, информационные элементы проходят
- На первом такте Кл.1 и Кл.3 замкнуты, информационные элементы проходят

- на шестом такте ключи 1 и 3 размыкаются (разрываются обратная
- на шестом такте ключи 1 и 3 размыкаются (разрываются обратная

Определение ошибочного разряда в ЦК.
Пусть А(х)-многочлен, соответствующий переданной кодовой комбинации.
Н(х)- многочлен,
Определение ошибочного разряда в ЦК.
Пусть А(х)-многочлен, соответствующий переданной кодовой комбинации.
Н(х)- многочлен,

При однократной ошибке Е(х) будет содержать только один единственный член, соответствующий
При однократной ошибке Е(х) будет содержать только один единственный член, соответствующий

При этом ошибке в каждом разряде будет соответствовать свой остаток R(x)

Алгоритм определения ошибки.
Пусть имеем n-элементные комбинации (n = k + r)
Алгоритм определения ошибки.
Пусть имеем n-элементные комбинации (n = k + r)

3. Сравниваем R0(x) и R(x).
- Если они равны, то ошибка произошла
3. Сравниваем R0(x) и R(x).
- Если они равны, то ошибка произошла

- Если они равны, то ошибки во втором разряде.
- Если нет,
- Если они равны, то ошибки во втором разряде.
- Если нет,

Пример декодирования комбинации ЦК.
Положим, получена комбинация H(х)=111011010
Проанализируем её в соответствии с
Пример декодирования комбинации ЦК.
Положим, получена комбинация H(х)=111011010
Проанализируем её в соответствии с


Разделим принятую комбинацию на образующий полином H(x) · x
Разделим принятую комбинацию на образующий полином H(x) · x

1110110100 10011
10011 111111
5-т 11101
10011
6-т 11100
10011
7-т 11111
10011
8-т 11000
10011
9-т 10110 = R(x) R0(x)
10011
10-т
1110110100 10011
10011 111111
5-т 11101
10011
6-т 11100
10011
7-т 11111
10011
8-т 11000
10011
9-т 10110 = R(x) R0(x)
10011
10-т

Полученный на 9-м такте остаток, как видим, не равен R0(x). Значит
Полученный на 9-м такте остаток, как видим, не равен R0(x). Значит

В нашем случае это произойдет на 10 такте, при повышении степени
В нашем случае это произойдет на 10 такте, при повышении степени

Декодер циклического с исправлением
ошибки
Декодер циклического с исправлением
ошибки

Если ошибка в первом разряде, то остаток R0(x)=10101 появляется после девятого
Если ошибка в первом разряде, то остаток R0(x)=10101 появляется после девятого

в пятом по старшинству то после 13го
в шестом по старшинству
в пятом по старшинству то после 13го
в шестом по старшинству

Если и этому моменту остаток в ФПГ=R0(x), то логическая 1 с
Если и этому моменту остаток в ФПГ=R0(x), то логическая 1 с

Действия над многочленами.
При формировании комбинаций циклического кода часто используют операции сложения
Действия над многочленами.
При формировании комбинаций циклического кода часто используют операции сложения

Рассмотрим операцию деления на следующем примере:
Рассмотрим операцию деления на следующем примере:

Деление выполняется, как обычно, только вычитание заменяется суммированием по модулю два.
Отметим,
Деление выполняется, как обычно, только вычитание заменяется суммированием по модулю два.
Отметим,

Умножение многочленов производится по обычным правилам алгебры, но с приведением подобных
Умножение многочленов производится по обычным правилам алгебры, но с приведением подобных

Выбор образующего полинома
Рассмотрим вопрос выбора образующего полинома, который определяет корректирующие свойства
Выбор образующего полинома
Рассмотрим вопрос выбора образующего полинома, который определяет корректирующие свойства

Декодер Меггита
Декодер Меггита представляет собой синдромный декодер, исправляющий одиночные ошибки. В
Декодер Меггита
Декодер Меггита представляет собой синдромный декодер, исправляющий одиночные ошибки. В

Декодер Меггита для циклического кода (15,11)
Декодер Меггита для циклического кода (15,11)

Декодер работает следующим образом: кодовое слово (с ошибками или без них)
Декодер работает следующим образом: кодовое слово (с ошибками или без них)

Ошибка обнаруживается, если хотя бы один элемент синдрома не равен нулю.
Исправление
Ошибка обнаруживается, если хотя бы один элемент синдрома не равен нулю.
Исправление

В пунктирном квадрате показана возможная модификация регистра синдрома, упрощающая реализацию схемы
В пунктирном квадрате показана возможная модификация регистра синдрома, упрощающая реализацию схемы

СВЕРТОЧНЫЕ КОДЫ
Сверточными кодами являются древовидные коды, на которые накладываются
СВЕРТОЧНЫЕ КОДЫ
Сверточными кодами являются древовидные коды, на которые накладываются

или в виде полиномов a(х) = g(х) d(х),
где ai –
или в виде полиномов a(х) = g(х) d(х),
где ai –

Эти полиномы могут быть объединены в матрицу
где i=1...k0, j=1...n0, k0
Эти полиномы могут быть объединены в матрицу
где i=1...k0, j=1...n0, k0

При использовании сверточных кодов поток данных разбивается на гораздо меньшие блоки
При использовании сверточных кодов поток данных разбивается на гораздо меньшие блоки

Вместо длины кодового слова часто используется понятие «длина кодового ограничения» nа,
Вместо длины кодового слова часто используется понятие «длина кодового ограничения» nа,

Входная последовательность из k информационных символов представляется вектором-строкой
;
а кодовое
Входная последовательность из k информационных символов представляется вектором-строкой
;
а кодовое

а вектор синдромов ошибки (синдромных полиномов) равен
т.е. (n0 - k0)-мерный вектор-строка
а вектор синдромов ошибки (синдромных полиномов) равен
т.е. (n0 - k0)-мерный вектор-строка

Как и блочные, сверточные коды могут быть систематическими и несистематическими и
Как и блочные, сверточные коды могут быть систематическими и несистематическими и

Кодирование сверточных кодов производится аналогично блочным циклическим кодам с помощью регистров
Кодирование сверточных кодов производится аналогично блочным циклическим кодам с помощью регистров
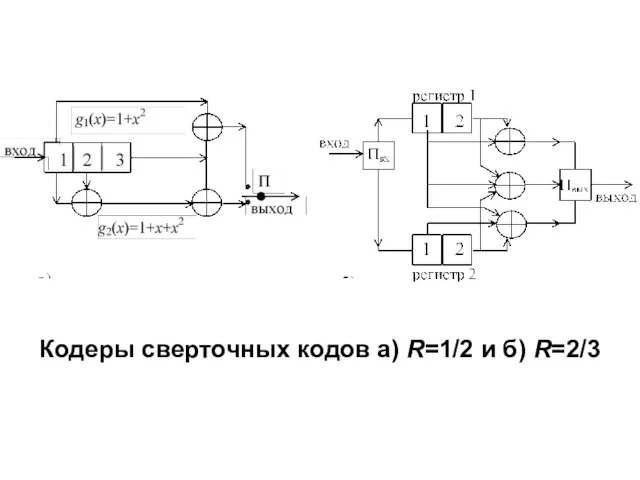
Кодеры сверточных кодов а) R=1/2 и б) R=2/3
Кодеры сверточных кодов а) R=1/2 и б) R=2/3

Кодеры работают следующим образом.
На вход регистра сдвига кодера (а) из
Кодеры работают следующим образом.
На вход регистра сдвига кодера (а) из

Матрица производящих полиномов кода R=2/3 (рисунок б) имеет вид
Регистры сдвига
Матрица производящих полиномов кода R=2/3 (рисунок б) имеет вид
Регистры сдвига

Переключатель Пвх разделяет входные информационные символы между регистрами, переключатель Пвых формирует
Переключатель Пвх разделяет входные информационные символы между регистрами, переключатель Пвых формирует


Кодовое дерево строится таким образом, что информационному символу «0» соответствует перемещение
Кодовое дерево строится таким образом, что информационному символу «0» соответствует перемещение

Это обстоятельство определяется состоянием двух последних ячеек памяти регистра сдвига кодера
Это обстоятельство определяется состоянием двух последних ячеек памяти регистра сдвига кодера

Решетка сверточного кода представляет состояния кодера в виде четырех уровней, а
Решетка сверточного кода представляет состояния кодера в виде четырех уровней, а

Если сверточный код является систематическим, то g1(x) = 1 (в верхней
Если сверточный код является систематическим, то g1(x) = 1 (в верхней

Для кодера рис. (а) длина кодового ограничения равна 3. Эта величина
Для кодера рис. (а) длина кодового ограничения равна 3. Эта величина

Таким образом, действие одного информационного символа, поступившего на вход кодера, ограничено
Таким образом, действие одного информационного символа, поступившего на вход кодера, ограничено

Существует несколько способов описания связей между разрядами в регистре сдвига и
Существует несколько способов описания связей между разрядами в регистре сдвига и

Каждый вектор имеет составляющих из нулей и единиц (количество разрядов в
Каждый вектор имеет составляющих из нулей и единиц (количество разрядов в

Единица (1) на i-й позиции вектора означает, что разряд с номером
Единица (1) на i-й позиции вектора означает, что разряд с номером

Так, для кодера на рис.(а) число сумматоров n=2 и будет вектор
Так, для кодера на рис.(а) число сумматоров n=2 и будет вектор

2. Второй способ позволяет представить связи между разрядами регистра и сумматорами
2. Второй способ позволяет представить связи между разрядами регистра и сумматорами

В зависимости от того, имеется ли связь между cоответствующими разрядами регистра
В зависимости от того, имеется ли связь между cоответствующими разрядами регистра

Для кодера рис.(а) полиноминальные генераторы будут иметь следующий вид:
С помощью полиноминальных
Для кодера рис.(а) полиноминальные генераторы будут иметь следующий вид:
С помощью полиноминальных

Пусть, например, на вход кодера поступает последовательность информационных символов
Этой последовательности соответствует
Пусть, например, на вход кодера поступает последовательность информационных символов
Этой последовательности соответствует

Сначала найдем произведения
,
Сначала найдем произведения
,

(значения сумм в круглых скобках
определяем по модулю 2).
(значения сумм в круглых скобках
определяем по модулю 2).

Полином b(x), коэффициентами которого будут кодовые символы на выходе кодера, определим
Полином b(x), коэффициентами которого будут кодовые символы на выходе кодера, определим

Последовательность кодовых символов определяется двойными коэффициентами в круглых скобках полинома b(x),
Последовательность кодовых символов определяется двойными коэффициентами в круглых скобках полинома b(x),

Построение решетчатой диаграммы
Решетчатая диаграмма также состоит из ребер и узлов. Все
Построение решетчатой диаграммы
Решетчатая диаграмма также состоит из ребер и узлов. Все

При построении решетки, как и для древовидной диаграммы, предполагается, что первоначально
При построении решетки, как и для древовидной диаграммы, предполагается, что первоначально

Если на вход кодера, находящегося в состоянии a=00, поступает информационный символ
Если на вход кодера, находящегося в состоянии a=00, поступает информационный символ

На 1-м уровне имеется два узла «a» и «b», из которых
На 1-м уровне имеется два узла «a» и «b», из которых

На 3-м уровне наблюдается принципиальное отличие древовидной и решетчатой диаграмм. На
На 3-м уровне наблюдается принципиальное отличие древовидной и решетчатой диаграмм. На

Аналогично происходит и с другими узлами «b»,«c» и «d».
На 4-м
Аналогично происходит и с другими узлами «b»,«c» и «d».
На 4-м

Таким образом, в результате описанных отождествлений получается решетчатая диаграмма, на которой
Таким образом, в результате описанных отождествлений получается решетчатая диаграмма, на которой

В рассматриваемом примере кодера
Поэтому получаем
В рассматриваемом примере кодера
Поэтому получаем

Алгоритм сверточного декодирования Витерби
Пример декодирования по алгоритму Витерби R=1/2
Предположим, что
Алгоритм сверточного декодирования Витерби
Пример декодирования по алгоритму Витерби R=1/2
Предположим, что
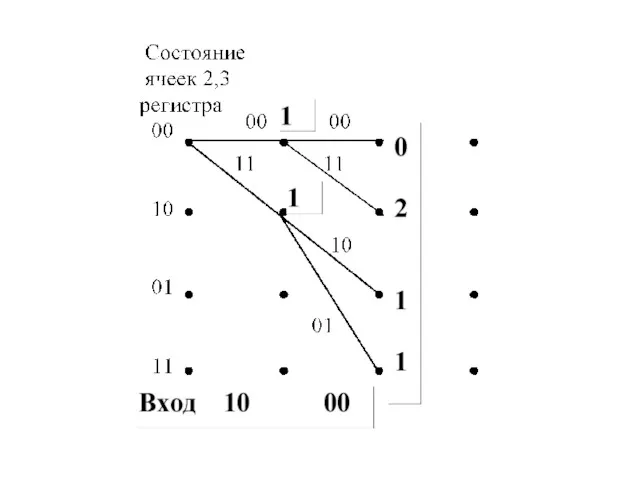
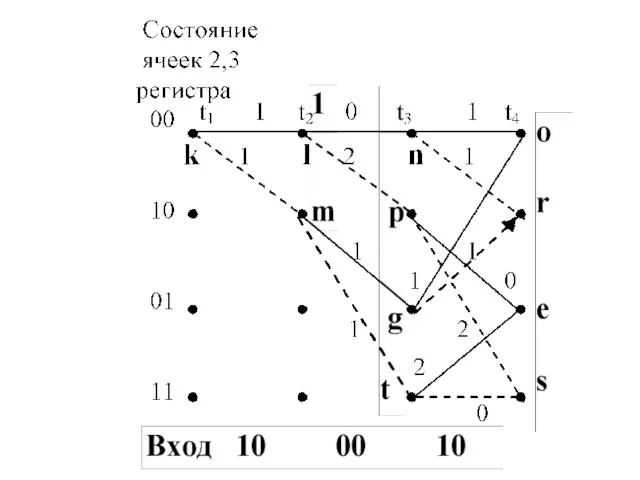




Из построенной диаграммы декодера видно, что от момента t1 до момента
Из построенной диаграммы декодера видно, что от момента t1 до момента


Декодер принимает решение, что на интервале от t1 до t6 по
Декодер принимает решение, что на интервале от t1 до t6 по

Алгоритм сверточного декодирования Витерби
1.При декодировании используются как решетчатая диаграмма кодера, так
Алгоритм сверточного декодирования Витерби
1.При декодировании используются как решетчатая диаграмма кодера, так

Эти расстояния пишут над соответствующими ребрами решетчатой диаграммы декодера. Обозначения на
Эти расстояния пишут над соответствующими ребрами решетчатой диаграммы декодера. Обозначения на

2. С помощью пометок (цифр) на ребрах решетчатой диаграммы декодера для
2. С помощью пометок (цифр) на ребрах решетчатой диаграммы декодера для

Для каждого момента времени ti (где i >3) имеем четыре узла
Для каждого момента времени ti (где i >3) имеем четыре узла

Декодирование Витерби состоит в том, что из двух путей, приходящих в
Декодирование Витерби состоит в том, что из двух путей, приходящих в

Отсекание одного из двух путей, сходящихся в узле решетки, гарантирует, что
Отсекание одного из двух путей, сходящихся в узле решетки, гарантирует, что

В результате использования алгоритма декодирования Витерби находится наиболее вероятный (с минимальным
В результате использования алгоритма декодирования Витерби находится наиболее вероятный (с минимальным

Основные трудности при реализации алгоритма Витерби определяются тем, что сложность декодера
Основные трудности при реализации алгоритма Витерби определяются тем, что сложность декодера

Декодирование по алгоритму Витерби кода R=2/3 оказывается существенно сложнее по сравнению
Декодирование по алгоритму Витерби кода R=2/3 оказывается существенно сложнее по сравнению

В общем случае для кодов R=k0/n0 требуется -ичное сравнение, что приводит
В общем случае для кодов R=k0/n0 требуется -ичное сравнение, что приводит

Например, для получения кода R=3/4 выкалывается каждый третий символ, сформированный кодером,
Например, для получения кода R=3/4 выкалывается каждый третий символ, сформированный кодером,

Сверточные коды R=1/n0 строятся аналогично кодам R=1/2, но имеют большее кодовое
Сверточные коды R=1/n0 строятся аналогично кодам R=1/2, но имеют большее кодовое

В качестве дополнительного производящего полинома g3(x) может быть взят g1(x) или
В качестве дополнительного производящего полинома g3(x) может быть взят g1(x) или

Последовательное декодирование
В отличие от алгоритма Витерби при последовательном декодировании производится продолжение
Последовательное декодирование
В отличие от алгоритма Витерби при последовательном декодировании производится продолжение

Если решение о декодируемом символе, находящемся в начале пути, принять невозможно,
Если решение о декодируемом символе, находящемся в начале пути, принять невозможно,

Основное достоинство
последовательного алгоритма заключается в том, что в среднем длина пути,
Основное достоинство
последовательного алгоритма заключается в том, что в среднем длина пути,

Недостатки определяются тем, что длина пути, приводящего к правильному декодированию, является
Недостатки определяются тем, что длина пути, приводящего к правильному декодированию, является

В практике построения последовательных декодеров применяются два варианта алгоритма последовательного декодирования,
В практике построения последовательных декодеров применяются два варианта алгоритма последовательного декодирования,

Декодер создает стек, состоящий из просмотренных ранее путей (могут иметь различную
Декодер создает стек, состоящий из просмотренных ранее путей (могут иметь различную

Пример.
Дано:
передаваемая информационная последовательность I(x)=100, скорость кода R=1/2, na=3, производящие полиномы
Пример.
Дано:
передаваемая информационная последовательность I(x)=100, скорость кода R=1/2, na=3, производящие полиномы

Найти: оценку переданного слова с использованием стек-алгоритма декодирования сверточных кодов.
Решение:
переданная кодовая
Найти: оценку переданного слова с использованием стек-алгоритма декодирования сверточных кодов.
Решение:
переданная кодовая

Декодирование осуществляется за несколько шагов, где состояния представляют собой возможные состояния
Декодирование осуществляется за несколько шагов, где состояния представляют собой возможные состояния
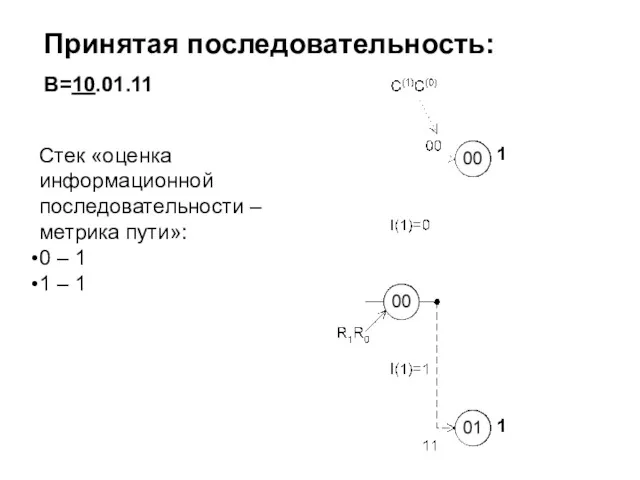
Принятая последовательность:
B=10.01.11
Стек «оценка информационной последовательности – метрика пути»:
0
Принятая последовательность:
B=10.01.11
Стек «оценка информационной последовательности – метрика пути»:
0
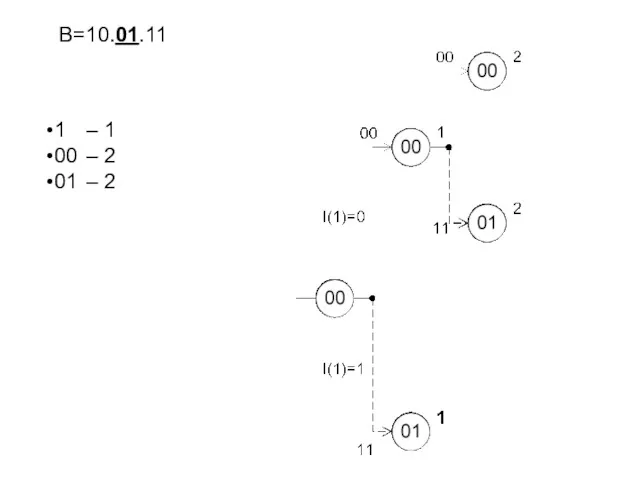
B=10.01.11
1 – 1
00 – 2
01 – 2
B=10.01.11
1 – 1
00 – 2
01 – 2
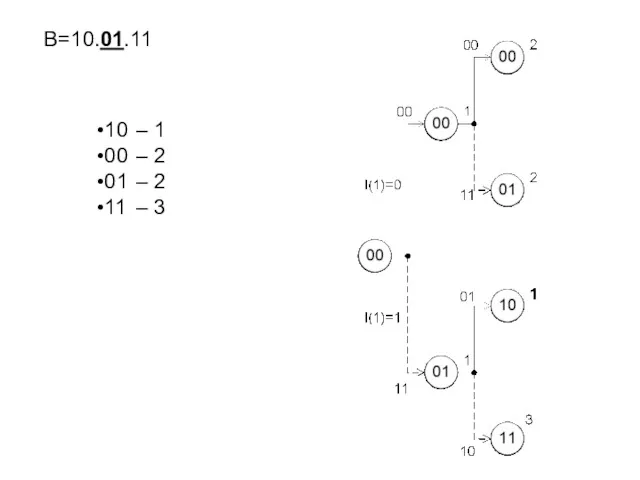
B=10.01.11
10 – 1
00 – 2
01 – 2
11 – 3
B=10.01.11
10 – 1
00 – 2
01 – 2
11 – 3
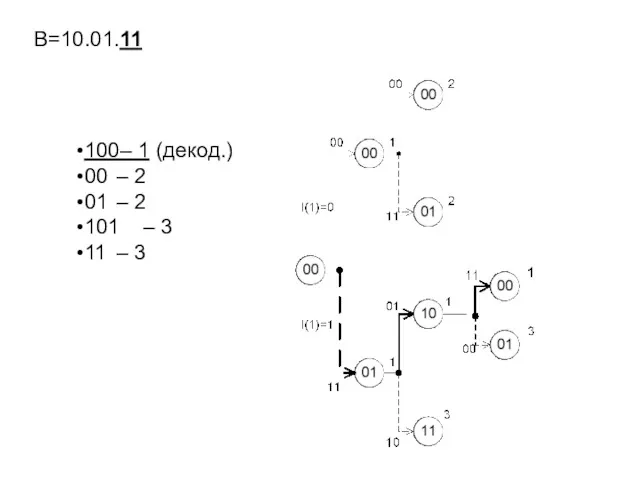
B=10.01.11
100– 1 (декод.)
00 – 2
01 – 2
101 – 3
11 – 3
B=10.01.11
100– 1 (декод.)
00 – 2
01 – 2
101 – 3
11 – 3

Выводы:
Последовательное декодирование позволяет использовать большие значения длины кодового ограничения (на
Выводы:
Последовательное декодирование позволяет использовать большие значения длины кодового ограничения (на

Синдромное декодирование
Синдромное декодирование сверточных кодов, в принципе, не отличается от синдромного
Синдромное декодирование
Синдромное декодирование сверточных кодов, в принципе, не отличается от синдромного

Практически используются, в основном, два метода синдромного декодирования:
декодирование с табличным
Практически используются, в основном, два метода синдромного декодирования:
декодирование с табличным

Декодирование с табличным поиском заключается в том, что вычисленный синдром ошибки
Декодирование с табличным поиском заключается в том, что вычисленный синдром ошибки

Применение:
Сверточные коды с малым кодовым ограничением (na≤10÷20) и с малым энергетическим
Применение:
Сверточные коды с малым кодовым ограничением (na≤10÷20) и с малым энергетическим

Пороговое декодирование возможно для определенного класса линейных кодов как блочных, так
Пороговое декодирование возможно для определенного класса линейных кодов как блочных, так
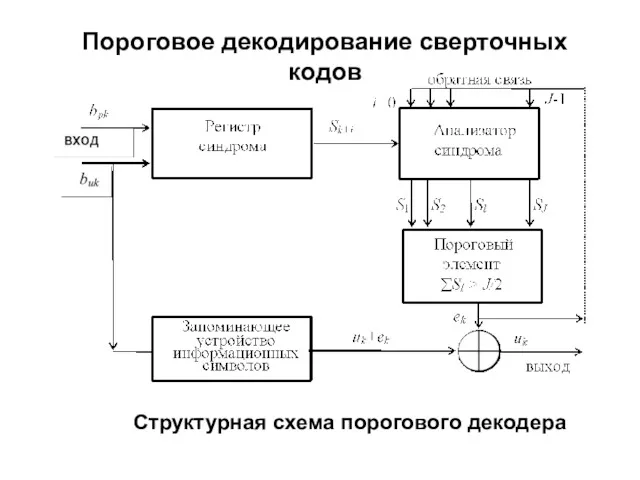
Пороговое декодирование сверточных кодов
Структурная схема порогового декодера
Пороговое декодирование сверточных кодов
Структурная схема порогового декодера

Последовательность символов канала bk после разделения на информационные buk и проверочные
Последовательность символов канала bk после разделения на информационные buk и проверочные

Исправление ошибки происходит в сумматоре по модулю два, на второй вход
Исправление ошибки происходит в сумматоре по модулю два, на второй вход

КАСКАДНЫЕ КОДЫ
Каскадные коды используются в практике передачи дискретных сигналов в
КАСКАДНЫЕ КОДЫ
Каскадные коды используются в практике передачи дискретных сигналов в
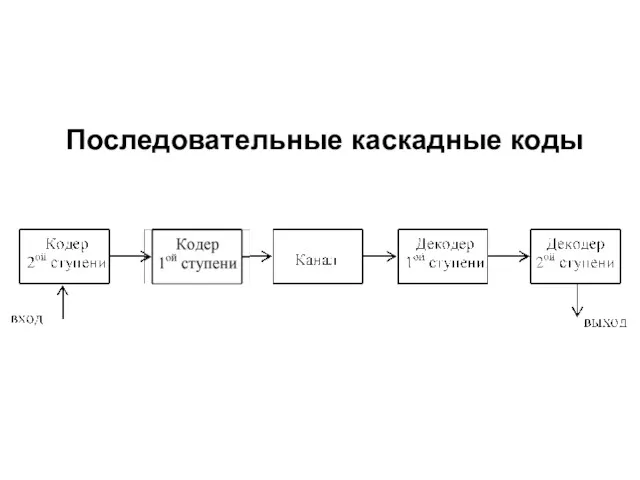
Последовательные каскадные коды
Последовательные каскадные коды

Вторая ступень кодирования в последовательном каскадном кодеке формирует k2 строк, каждая
Вторая ступень кодирования в последовательном каскадном кодеке формирует k2 строк, каждая

К k2 информационным символам внешнего кода приписывается (n2-k2) проверочных символов, каждый
К k2 информационным символам внешнего кода приписывается (n2-k2) проверочных символов, каждый

При этом следует иметь в виду, что кодовое слово кода 1-ой
При этом следует иметь в виду, что кодовое слово кода 1-ой

В другом методе формирования каскадного кода (иногда называемого итеративным кодом) k2
В другом методе формирования каскадного кода (иногда называемого итеративным кодом) k2

Каждый ее столбец образует k2 символов, которые являются информационными символами кода
Каждый ее столбец образует k2 символов, которые являются информационными символами кода

В результате и в том и другом случае образуется блок двоичных
В результате и в том и другом случае образуется блок двоичных

где aij − информационные символы, bij − проверочные символы
где aij − информационные символы, bij − проверочные символы

В качестве кодов 1-ой и 2-ой ступеней могут использоваться как блочные,
В качестве кодов 1-ой и 2-ой ступеней могут использоваться как блочные,

В качестве внешнего кода могут применяться как блочные (например, циклические), так
В качестве внешнего кода могут применяться как блочные (например, циклические), так

Вероятность ошибки на выходе декодера кодов РС в каналах с независимыми
Вероятность ошибки на выходе декодера кодов РС в каналах с независимыми

Каскадное кодирование с внешним кодом РС (или сверточным кодом с итерационным
Каскадное кодирование с внешним кодом РС (или сверточным кодом с итерационным

Параллельные каскадные коды
Параллельные каскадные коды с итерационным декодированием, обычно называют
Параллельные каскадные коды
Параллельные каскадные коды с итерационным декодированием, обычно называют

Турбокод образуется при параллельном каскадировании двух или более систематических кодов. Обычно
Турбокод образуется при параллельном каскадировании двух или более систематических кодов. Обычно
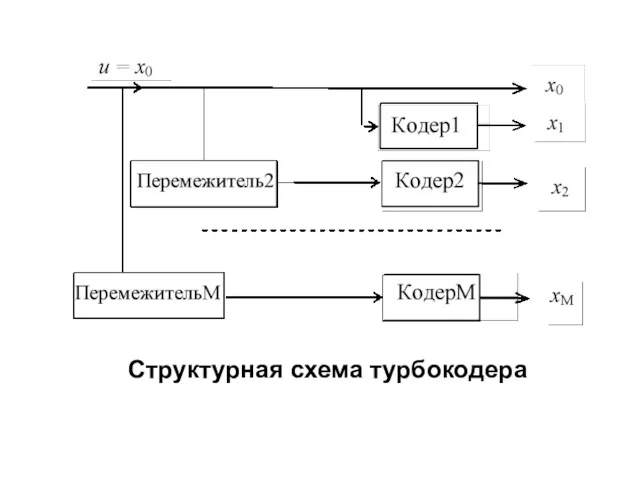
Структурная схема турбокодера
Структурная схема турбокодера

Блок данных u длиной k символов поступает сначала на вход турбокодера.
Блок данных u длиной k символов поступает сначала на вход турбокодера.

В этой схеме передаваемая информация совместно используется во всех компонентных кодерах.
В этой схеме передаваемая информация совместно используется во всех компонентных кодерах.

Возможность исправления ошибок зависят не только от минимального кодового расстояния, но
Возможность исправления ошибок зависят не только от минимального кодового расстояния, но

Поэтому задачей перемежителя является преобразование входной последовательности таким образом, чтобы последовательности,
Поэтому задачей перемежителя является преобразование входной последовательности таким образом, чтобы последовательности,

На выходах компонентных кодеров каждой из М ветвей образуются последовательности проверочных
На выходах компонентных кодеров каждой из М ветвей образуются последовательности проверочных

Эта информационная последовательность x0 мультиплексируется с проверочными последовательностями x1... xM, образуя
Эта информационная последовательность x0 мультиплексируется с проверочными последовательностями x1... xM, образуя

Для повышения скорости кода применяют выкалывание (перфорацию) определенных проверочных символов выходной
Для повышения скорости кода применяют выкалывание (перфорацию) определенных проверочных символов выходной
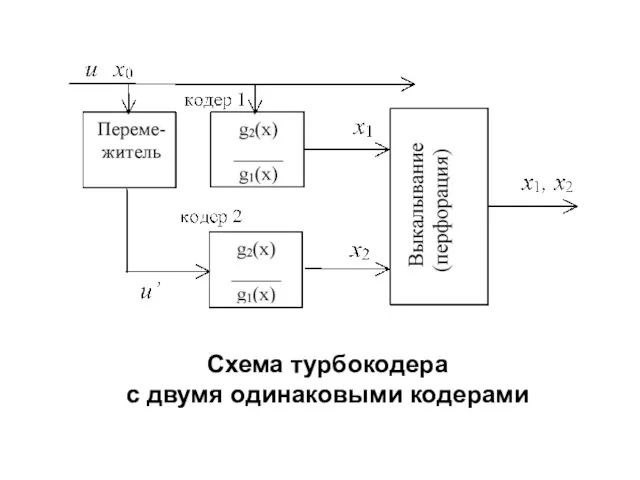
Схема турбокодера
с двумя одинаковыми кодерами
Схема турбокодера
с двумя одинаковыми кодерами

Операция выкалывания сводится к передаче в канал нечетных проверочных символов первого
Операция выкалывания сводится к передаче в канал нечетных проверочных символов первого

Выкалывание позволяет устанавливать произвольное значение кодовой скорости и даже адаптировать параметры
Выкалывание позволяет устанавливать произвольное значение кодовой скорости и даже адаптировать параметры


Декодирование турбокодов.
В основе декодирования кодов, исправляющих ошибки, лежит сравнение вероятностных характеристик
Декодирование турбокодов.
В основе декодирования кодов, исправляющих ошибки, лежит сравнение вероятностных характеристик

Если имеется некоторое предварительное знание о принимаемом сигнале до его декодирования,
Если имеется некоторое предварительное знание о принимаемом сигнале до его декодирования,
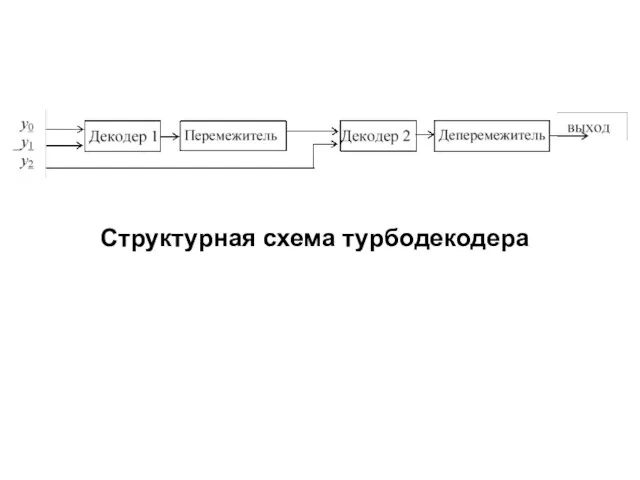
Структурная схема турбодекодера
Структурная схема турбодекодера

Рассмотрим процесс декодирования для случая, когда кодирование осуществляется двухкомпонентным турбокодером.
При
Рассмотрим процесс декодирования для случая, когда кодирование осуществляется двухкомпонентным турбокодером.
При

После декодирования информационной и первой проверочной последовательностей получается начальная оценка информационной
После декодирования информационной и первой проверочной последовательностей получается начальная оценка информационной

Такой подход требует, чтобы компонентный декодер мог использовать мягкое решение для
Такой подход требует, чтобы компонентный декодер мог использовать мягкое решение для

КОДЫ БЧХ И РИДА-СОЛОМОНА
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических
КОДЫ БЧХ И РИДА-СОЛОМОНА
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических

Кодирующий многочлен g(x) для БЧХ-кода, длина кодовых слов n которого ,
Кодирующий многочлен g(x) для БЧХ-кода, длина кодовых слов n которого ,

Построенный кодирующий многочлен производит код с минимальным расстоянием между кодовыми словами,
Построенный кодирующий многочлен производит код с минимальным расстоянием между кодовыми словами,

Пример
Построить код БЧХ при n=7 для исправления независимых ошибок кратности
Пример
Построить код БЧХ при n=7 для исправления независимых ошибок кратности

3) Число проверочных символов
; .
4) Находим производящий полином, учитывая, что
3) Число проверочных символов
; .
4) Находим производящий полином, учитывая, что

5)Строим производящую матрицу, которая образуется добавлением n-k нулей к производящему полиному,
5)Строим производящую матрицу, которая образуется добавлением n-k нулей к производящему полиному,

6)Суммируя по модулю два во всевозможных сочетаниях строки производящей матрицы, получим
6)Суммируя по модулю два во всевозможных сочетаниях строки производящей матрицы, получим

Также к ним применимы все методы, используемые для декодирования циклических кодов.
Также к ним применимы все методы, используемые для декодирования циклических кодов.

Код Рида-Соломона является частным случаем БЧХ-кода.
Коды Рида — Соломона — недвоичные циклические коды,
Код Рида-Соломона является частным случаем БЧХ-кода.
Коды Рида — Соломона — недвоичные циклические коды,

Построение недвоичных (q-ичных) кодов БЧХ мало отличается от построения двоичных кодов
Построение недвоичных (q-ичных) кодов БЧХ мало отличается от построения двоичных кодов

Код Рида — Соломона, исправляющий t ошибок, требует 2t проверочных символов
Код Рида — Соломона, исправляющий t ошибок, требует 2t проверочных символов

Кодирование с помощью кода Рида — Соломона может быть реализовано двумя
Кодирование с помощью кода Рида — Соломона может быть реализовано двумя

При систематическом кодировании к информационному блоку из k символов приписываются 2t
При систематическом кодировании к информационному блоку из k символов приписываются 2t

При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного

К исходному слову приписываются 2t нулей, получается полином .
Этот полином
К исходному слову приписываются 2t нулей, получается полином .
Этот полином

Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия:
-
Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия:
-

Вычисление синдрома ошибки
Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое
Вычисление синдрома ошибки
Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое

Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове.
Нахождение
Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове.
Нахождение

Определение характера ошибки и ее исправление
По синдрому ошибки и найденным
Определение характера ошибки и ее исправление
По синдрому ошибки и найденным
 Лекція 8. База даних Access
Лекція 8. База даних Access Автоматизированная система Музей-3
Автоматизированная система Музей-3 Информационные системы
Информационные системы Ошибки в безопасности. SQL Injection
Ошибки в безопасности. SQL Injection Структура курсового проекта
Структура курсового проекта Практикум: создание простого интерактивного приложения
Практикум: создание простого интерактивного приложения Telegram бот с информацией о погоде
Telegram бот с информацией о погоде Библиографическое оформление рефератов, курсовых, дипломных работ, диссертаций
Библиографическое оформление рефератов, курсовых, дипломных работ, диссертаций Лекция 2. Основы компьютерных сетей. Назначение и структура
Лекция 2. Основы компьютерных сетей. Назначение и структура Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации
Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации Интернет. Правила безопасности в сети Интернет
Интернет. Правила безопасности в сети Интернет Flight controls
Flight controls Форматирование символов. MS WORD 1
Форматирование символов. MS WORD 1 1C-Администратор. Новый сервис для продвинутых пользователей
1C-Администратор. Новый сервис для продвинутых пользователей Электронно-библиотечные системы (ЭБС)
Электронно-библиотечные системы (ЭБС) Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Второй уровень информационного взаимодействия. Вторичные информационные процессы
Второй уровень информационного взаимодействия. Вторичные информационные процессы Настройка контекстной рекламы Яндекс Директ
Настройка контекстной рекламы Яндекс Директ Информационная глобальная компьютерная сеть интернет. (Лекция 3)
Информационная глобальная компьютерная сеть интернет. (Лекция 3) Право и этика в интернете
Право и этика в интернете Высокопроизводительные вычисления
Высокопроизводительные вычисления Складання алгоритмів
Складання алгоритмів Управление эксплуатацией вооружения и военной техники Космических войск. Лекция №02
Управление эксплуатацией вооружения и военной техники Космических войск. Лекция №02 ПРЕЗЕНТАЦИЯ
ПРЕЗЕНТАЦИЯ Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (Аккумуляторная)
Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (Аккумуляторная) 3D-Blender
3D-Blender Кластерлер сипаттамасы
Кластерлер сипаттамасы Интернет безопасность
Интернет безопасность