- Высокопроизводительные вычисления

Содержание
- 2. Высокопроизводительные вычисления выбор вычислительной модели; использование эффективного вычислительного алгоритма; использование оптимальных структур данных и средств кодирования;
- 3. Внедрение параллельного программирования Применение компиляторов, автоматически распараллеливающих фрагменты кода Применение специализированных библиотек, реализующих параллельные алгоритмы вычислений
- 4. Автоматически распараллеливающие компиляторы Некоторые компиляторы позволяют выполнять автоматическое распараллеливание фрагментов кода программы. Б Большинство распараллеливающих компиляторов
- 5. Классификация вычислительных систем
- 6. Распределенные системы Для взаимодействия, как правило, используются интерфейсы передачи сообщений (MPI, WCF, ..)
- 7. Многопроцессорные системы Системы с общей памятью (shared memory systems), многоядерные системы
- 8. Технологии параллельного программирования
- 9. Технологии ПП для многоядерных систем Низкоуровневые средства (потоки) Библиотеки для С/С++: pthreads, Windows Threads, boost::thread, std::thread
- 10. Потоки vs. задачи Работа с потоками предполагает: декомпозиция задачи на части; создание и управление потоками; синхронизация
- 11. Стандарт OpenMP Стандарт для многопроцессорного программирования на языках C/C++/Fortran Развивается с 1997 г. Последнее обновление: версия
- 12. Intel Cilk Plus Расширение для языка C++ от Intel Средства распараллеливания: 3 ключевых слова, расширенная векторная
- 13. Библиотека Intel TBB Кроссплатформенная библиотека шаблонов С++, разработанная компанией Intel для параллельного программирования. Включает типовые шаблоны
- 14. Технологии программирования распределенных систем Интерфейсы передачи сообщений (MPI, WCF, ..) Библиотеки-оболочки над интерфейсом MPI (OO-MPI, boost
- 15. MPI-программа int rank; float msg = 0.0; MPI_Status status; MPI_Init(); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0)
- 16. MPI.NET static void Main(string[] args) { using (new MPI.Environment(ref args)) { Intracommunicator comm = Communicator.world; string
- 17. Программирование GPU Современные графические процессоры (GPU) представляют собой гибко программируемые массивно-параллельные вычислительные устройства с высоким быстродействием
- 18. Организация GPU-устройств (G80) 8 поточных процессоров (SP) Каждый SP-процессор исполняет 32 потока 2 специальных процессора SFU
- 20. Графические интерфейсы Данные средства были разработаны для решения задач визуализации, поэтому при их использовании для задач
- 21. Специализированные интерфейсы Специализированные средства от производителей позволяют разрабатывать программу на диалекте языка C и отказаться от
- 22. Средства гетерогенного программирования Данные средства реализуют модель гетерогенных вычислений, которая предполагает возможность использования в одной программе
- 23. Интерфейс CUDA Технология CUDA (Compute Unified Device Architecture) представляет собой архитектуру параллельных вычислений на графических процессорах
- 24. Программирование GPU с помощью CUDA Общая схема исполнения программ 1. Подготовка данных на CPU 2. Копирование
- 25. “Hello-world” на CUDA // Выделяем память на GPU для копий переменных a, b, c cudaMalloc((void **)&d_a,
- 26. Стандарт OpenCL OpenCL (Open Computing Language) является открытым межплатформенным стандартом для параллельных вычислений на современных процессорах
- 27. Стандарт OpenACC Cтандарт для упрощения программирования GPU разных производителей “OpenACC: More Science Less Programming“ Поддерживается компиляторами:
- 28. Пример OpenACC-функции // Умножение вектора на число void VectorMultiplication(int n, float a, float *x, float *
- 29. Вычисления на GPU на других языках Для языка C#: Cloo, OpenCL.NET, CUDA.NET Для языка F#: AleaGPU,
- 30. Облачные вычисления Комплексное решение, предоставляющее компьютерные ресурсы в виде сервиса. Ресурсы могут предоставляться через Интернет или
- 31. В облачной инфраструктуре выделяют несколько уровней, каждый из которых обеспечивает тот или иной вид сервиса для
- 32. Уровень инфраструктуры Уровень инфраструктуры или уровень IaaS (Infrastructure as a Service — инфраструктура как сервис) предоставляет
- 33. Уровень платформы Уровень платформы или уровень PaaS (Platform as a Service — платформа как сервис) —
- 34. Уровень программного обеспечения Уровень приложений или уровень SaaS (Software as a Service — программное обеспечение как
- 35. Типы развертывания Частное облако (private cloud) — используется для предоставления сервисов внутри одной компании, которая является
- 36. Достоинства и недостатки облачных решений Среди основных преимуществ технологий облачных вычислений можно выделить: доступность и открытость,
- 37. Анализ данных Data mining - процесс извлечения закономерностей (шаблонов) в больших массивах информации. “DM - процесс
- 38. Программные продукты анализа данных
- 39. http://www.kdnuggets.com/polls/2015/analytics-data-mining-data-science-software-used.html
- 41. Скачать презентацию

Высокопроизводительные вычисления
выбор вычислительной модели;
использование эффективного вычислительного алгоритма;
использование оптимальных структур данных и
Высокопроизводительные вычисления
выбор вычислительной модели;
использование эффективного вычислительного алгоритма;
использование оптимальных структур данных и

Внедрение параллельного программирования
Применение компиляторов, автоматически распараллеливающих фрагменты кода
Применение специализированных библиотек, реализующих
Внедрение параллельного программирования
Применение компиляторов, автоматически распараллеливающих фрагменты кода
Применение специализированных библиотек, реализующих

Автоматически распараллеливающие компиляторы
Некоторые компиляторы позволяют выполнять автоматическое распараллеливание фрагментов кода программы.
Автоматически распараллеливающие компиляторы
Некоторые компиляторы позволяют выполнять автоматическое распараллеливание фрагментов кода программы.
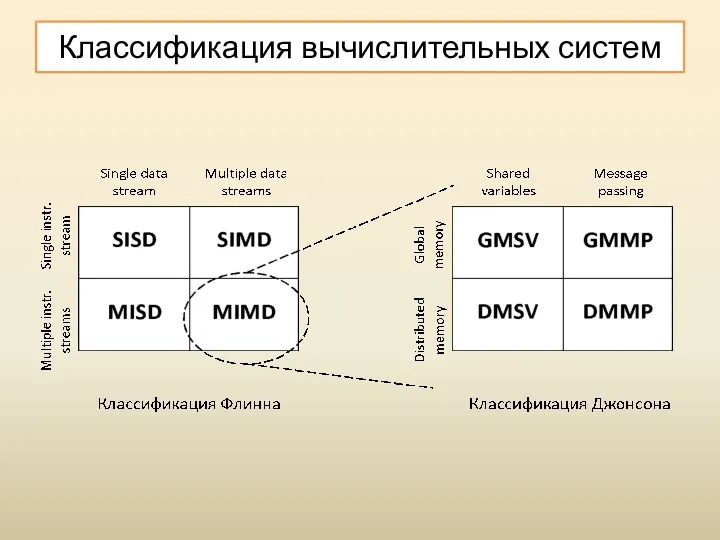
Классификация вычислительных систем
Классификация вычислительных систем
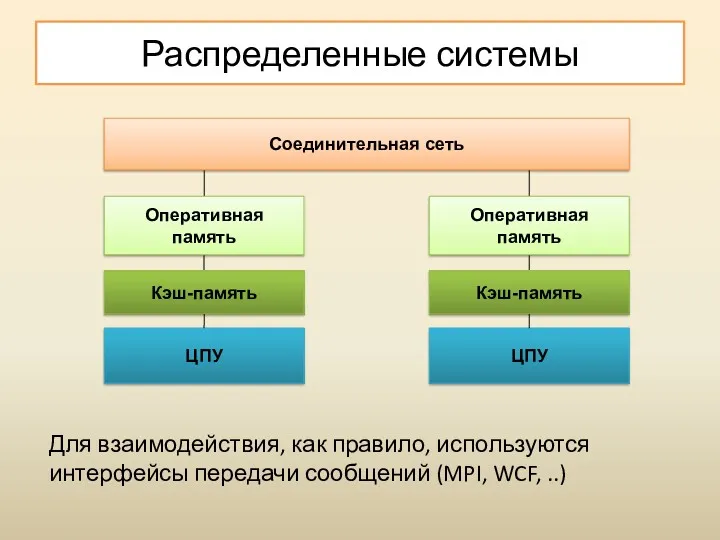
Распределенные системы
Для взаимодействия, как правило, используются интерфейсы передачи сообщений (MPI, WCF,
Распределенные системы
Для взаимодействия, как правило, используются интерфейсы передачи сообщений (MPI, WCF,
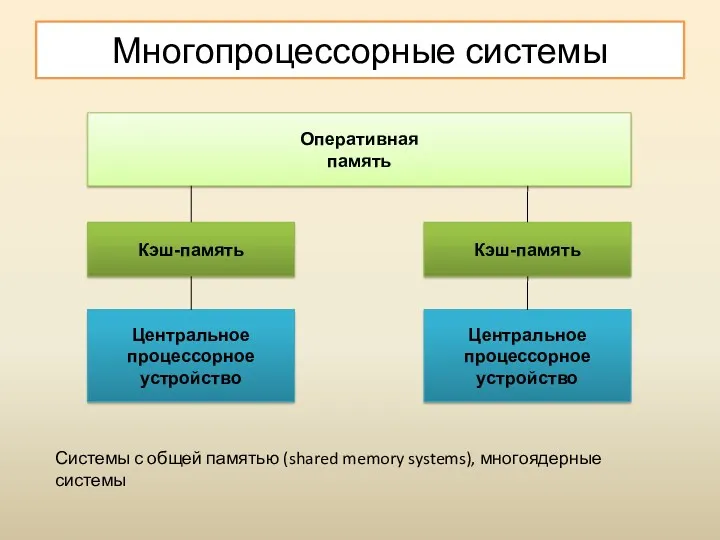
Многопроцессорные системы
Системы с общей памятью (shared memory systems), многоядерные системы
Многопроцессорные системы
Системы с общей памятью (shared memory systems), многоядерные системы

Технологии параллельного программирования
Технологии параллельного программирования

Технологии ПП для многоядерных систем
Низкоуровневые средства (потоки)
Библиотеки для С/С++: pthreads, Windows
Технологии ПП для многоядерных систем
Низкоуровневые средства (потоки)
Библиотеки для С/С++: pthreads, Windows

Потоки vs. задачи
Работа с потоками предполагает:
декомпозиция задачи на части;
создание и
Потоки vs. задачи
Работа с потоками предполагает:
декомпозиция задачи на части;
создание и

Стандарт OpenMP
Стандарт для многопроцессорного программирования на языках C/C++/Fortran
Развивается с 1997 г.
Стандарт OpenMP
Стандарт для многопроцессорного программирования на языках C/C++/Fortran
Развивается с 1997 г.

Intel Cilk Plus
Расширение для языка C++ от Intel
Средства распараллеливания: 3 ключевых
Intel Cilk Plus
Расширение для языка C++ от Intel
Средства распараллеливания: 3 ключевых

Библиотека Intel TBB
Кроссплатформенная библиотека шаблонов С++, разработанная компанией Intel для параллельного
Библиотека Intel TBB
Кроссплатформенная библиотека шаблонов С++, разработанная компанией Intel для параллельного

Технологии программирования распределенных систем
Интерфейсы передачи сообщений (MPI, WCF, ..)
Библиотеки-оболочки над интерфейсом
Технологии программирования распределенных систем
Интерфейсы передачи сообщений (MPI, WCF, ..)
Библиотеки-оболочки над интерфейсом

MPI-программа
int rank;
float msg = 0.0;
MPI_Status status;
MPI_Init();
MPI_Comm_rank(MPI_COMM_WORLD,
MPI-программа
int rank;
float msg = 0.0;
MPI_Status status;
MPI_Init();
MPI_Comm_rank(MPI_COMM_WORLD,
![MPI.NET static void Main(string[] args) { using (new MPI.Environment(ref args))](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/224285/slide-15.jpg)
MPI.NET
static void Main(string[] args)
{
using (new MPI.Environment(ref args))
{
MPI.NET
static void Main(string[] args)
{
using (new MPI.Environment(ref args))
{

Программирование GPU
Современные графические процессоры (GPU) представляют собой гибко программируемые массивно-параллельные вычислительные
Программирование GPU
Современные графические процессоры (GPU) представляют собой гибко программируемые массивно-параллельные вычислительные
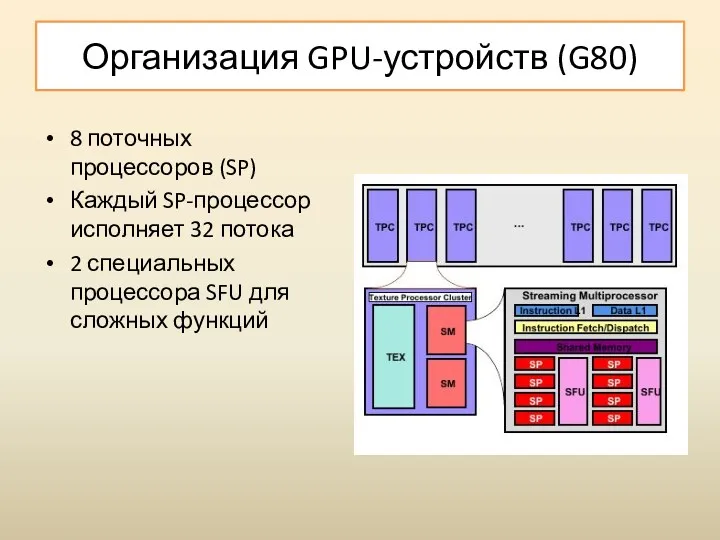
Организация GPU-устройств (G80)
8 поточных процессоров (SP)
Каждый SP-процессор исполняет 32 потока
2 специальных
Организация GPU-устройств (G80)
8 поточных процессоров (SP)
Каждый SP-процессор исполняет 32 потока
2 специальных
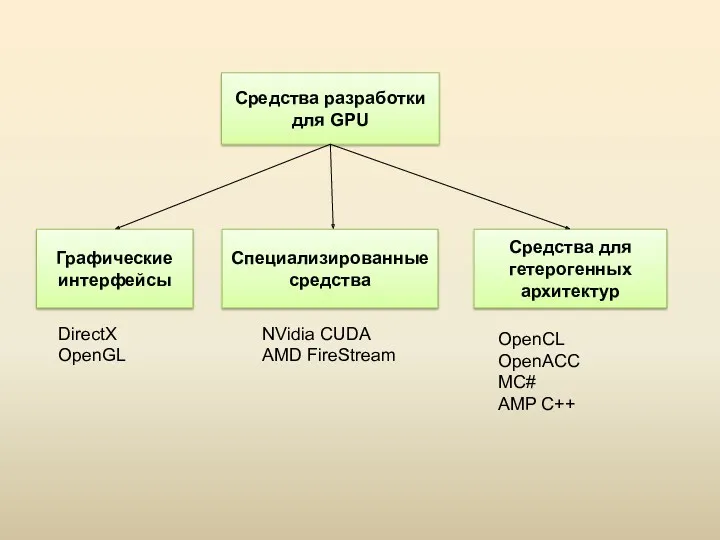

Графические интерфейсы
Данные средства были разработаны для решения задач визуализации, поэтому при
Графические интерфейсы
Данные средства были разработаны для решения задач визуализации, поэтому при

Специализированные интерфейсы
Специализированные средства от производителей позволяют разрабатывать программу на диалекте языка
Специализированные интерфейсы
Специализированные средства от производителей позволяют разрабатывать программу на диалекте языка

Средства гетерогенного программирования
Данные средства реализуют модель гетерогенных вычислений, которая предполагает возможность
Средства гетерогенного программирования
Данные средства реализуют модель гетерогенных вычислений, которая предполагает возможность

Интерфейс CUDA
Технология CUDA (Compute Unified Device Architecture) представляет собой архитектуру параллельных
Интерфейс CUDA
Технология CUDA (Compute Unified Device Architecture) представляет собой архитектуру параллельных

Программирование GPU с помощью CUDA
Общая схема исполнения программ
1. Подготовка данных на
Программирование GPU с помощью CUDA
Общая схема исполнения программ
1. Подготовка данных на

“Hello-world” на CUDA
// Выделяем память на GPU для копий переменных
“Hello-world” на CUDA
// Выделяем память на GPU для копий переменных

Стандарт OpenCL
OpenCL (Open Computing Language) является открытым межплатформенным стандартом для параллельных
Стандарт OpenCL
OpenCL (Open Computing Language) является открытым межплатформенным стандартом для параллельных

Стандарт OpenACC
Cтандарт для упрощения программирования GPU разных производителей
“OpenACC: More Science
Стандарт OpenACC
Cтандарт для упрощения программирования GPU разных производителей
“OpenACC: More Science

Пример OpenACC-функции
// Умножение вектора на число
void VectorMultiplication(int n, float a, float
Пример OpenACC-функции
// Умножение вектора на число
void VectorMultiplication(int n, float a, float

Вычисления на GPU на других языках
Для языка C#: Cloo, OpenCL.NET, CUDA.NET
Для
Вычисления на GPU на других языках
Для языка C#: Cloo, OpenCL.NET, CUDA.NET
Для

Облачные вычисления
Комплексное решение, предоставляющее компьютерные ресурсы в виде сервиса.
Ресурсы могут
Облачные вычисления
Комплексное решение, предоставляющее компьютерные ресурсы в виде сервиса.
Ресурсы могут
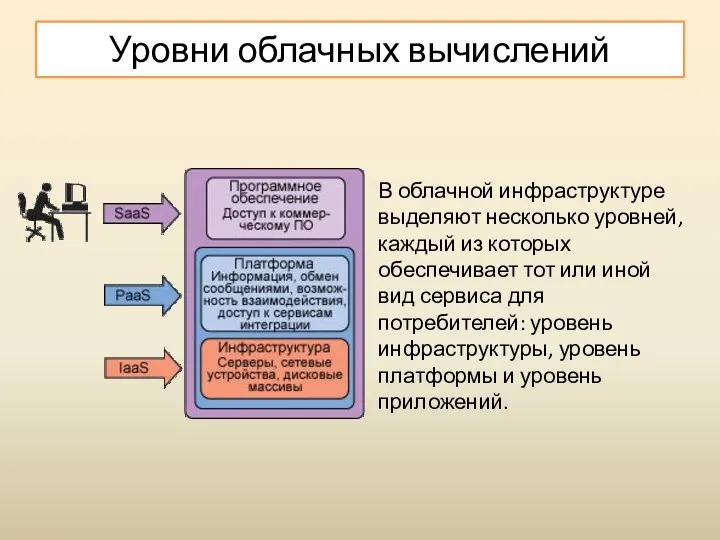
В облачной инфраструктуре выделяют несколько уровней, каждый из которых обеспечивает тот
В облачной инфраструктуре выделяют несколько уровней, каждый из которых обеспечивает тот

Уровень инфраструктуры
Уровень инфраструктуры или уровень IaaS (Infrastructure as a Service —
Уровень инфраструктуры
Уровень инфраструктуры или уровень IaaS (Infrastructure as a Service —

Уровень платформы
Уровень платформы или уровень PaaS (Platform as a Service —
Уровень платформы
Уровень платформы или уровень PaaS (Platform as a Service —

Уровень программного обеспечения
Уровень приложений или уровень SaaS (Software as a Service
Уровень программного обеспечения
Уровень приложений или уровень SaaS (Software as a Service

Типы развертывания
Частное облако (private cloud) — используется для предоставления сервисов внутри
Типы развертывания
Частное облако (private cloud) — используется для предоставления сервисов внутри

Достоинства и недостатки облачных решений
Среди основных преимуществ технологий облачных вычислений можно
Достоинства и недостатки облачных решений
Среди основных преимуществ технологий облачных вычислений можно

Анализ данных
Data mining - процесс извлечения закономерностей (шаблонов) в больших
Анализ данных
Data mining - процесс извлечения закономерностей (шаблонов) в больших

Программные продукты анализа данных
Программные продукты анализа данных
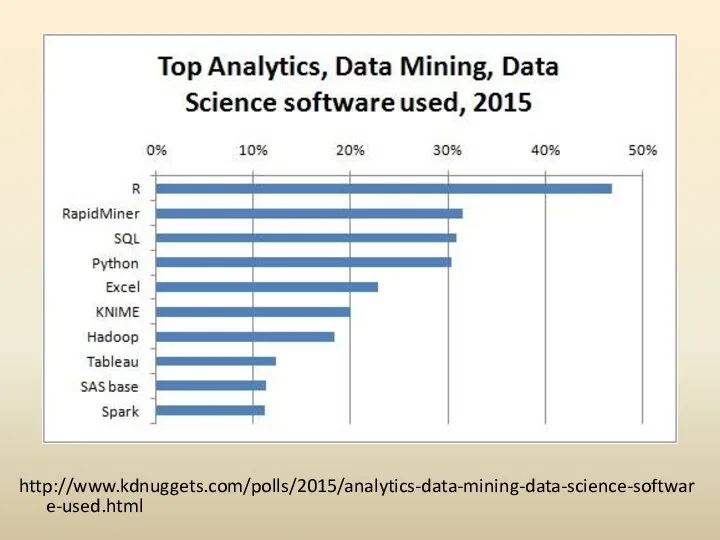
http://www.kdnuggets.com/polls/2015/analytics-data-mining-data-science-software-used.html
http://www.kdnuggets.com/polls/2015/analytics-data-mining-data-science-software-used.html
 Локальные компьютерные сети
Локальные компьютерные сети Программы Microsoft
Программы Microsoft Комплексное решение 1С:Колледж ПРОФ: назначение, функциональные возможности, порядок приобретения и сопровождения
Комплексное решение 1С:Колледж ПРОФ: назначение, функциональные возможности, порядок приобретения и сопровождения Обратная польская запись (ОПЗ). Тема 4
Обратная польская запись (ОПЗ). Тема 4 Искусственный интеллект (урок 10)
Искусственный интеллект (урок 10) Игра Сетикет (1)
Игра Сетикет (1) MySQL ортасындағы деректер қоры кестесін құрып және байланыстыру. Зертханалық жұмыс №4
MySQL ортасындағы деректер қоры кестесін құрып және байланыстыру. Зертханалық жұмыс №4 Нормализация отношений
Нормализация отношений Сучасні мобільні комунікатори
Сучасні мобільні комунікатори Моделирование технологической операции химико-механической планаризации диоксида кремния
Моделирование технологической операции химико-механической планаризации диоксида кремния Планирование и подготовка к презентации
Планирование и подготовка к презентации Типи тестування
Типи тестування Кодирование информации
Кодирование информации ABCDs of Effective Creative for YouTube
ABCDs of Effective Creative for YouTube Основні функції ЗМІ
Основні функції ЗМІ Образовательный комплекс Компьютерные сети. Модель ISOOSI
Образовательный комплекс Компьютерные сети. Модель ISOOSI Табличное представление информации
Табличное представление информации Текстовый процессор Microsoft Office Word
Текстовый процессор Microsoft Office Word Обработка информации. Часть 1
Обработка информации. Часть 1 Компьютерная графика. Обработка графической информации. Информатика. 7 класс
Компьютерная графика. Обработка графической информации. Информатика. 7 класс Прикладные направления компьютерной лингвистики. Лекция 5
Прикладные направления компьютерной лингвистики. Лекция 5 Offline Conversion Tracking
Offline Conversion Tracking Основы алгоритмизации и программирования на языках высокого уровня. (Лекция 1)
Основы алгоритмизации и программирования на языках высокого уровня. (Лекция 1) PE Linker. Лабораторная работа № 6
PE Linker. Лабораторная работа № 6 Операционная система Android
Операционная система Android Строки, символы и регулярные выражения. (Лекция 6)
Строки, символы и регулярные выражения. (Лекция 6) Представление чисел в памяти компьютера. 9 класс
Представление чисел в памяти компьютера. 9 класс Топ десяти игр всех времен
Топ десяти игр всех времен