- PostgreSQL

Содержание
- 2. Занятие первое Темы: Вводная часть Способы подключения к PostgreeSQL Создание БД Схемы Констрейнты, ограничения, первичные и
- 3. Почему PostgreSQL? Free & Open Source Лучший выбор для изучения: проинсталлировал и «понеслась»! «Взрослая» СУБД, поддерживает
- 4. SQL – Structured Query Language ANSI SQL-92 DDL – Data Definition Language (CREATE, ALTER, DROP) DML
- 5. Подключаемся к базе данных DBeaver Community https://dbeaver.io/download/ pgAdmin https://www.pgadmin.org/download/ Инструкции по настройке подключений тут: https://disk.yandex.ru/d/djGiu1dvaB4IHQ
- 6. Создание, редактирование и удаление баз данных Шаблоны Табличные пространства Кодировка символов Владелец Создание базы: CREATE DATABASE
- 7. Правила наименования объектов в PostgreSQL PostgreSQL работает в нижнем регистре и все наши скрипты в него
- 8. Численные типы данных PostgreSQL *decimal / numeric дают точный результат, но операции с ними выполняются медленнее,
- 9. Текстовые типы данных PostgreSQL https://postgrespro.ru/docs/postgrespro/15/datatype-character
- 10. Типы данных даты и времени в PostgreSQL https://postgrespro.ru/docs/postgrespro/15/datatype-datetime
- 11. Прочие типы данных PostgreSQL https://postgrespro.ru/docs/postgrespro/15/datatype
- 12. Схемы Есть несколько возможных объяснений, для чего стоит применять схемы: Чтобы одну базу данных могли использовать
- 13. Операции со схемами Создать схему CREATE SCHEMA test; Удалить пустую схему DROP SCHEMA test; Удалить схему
- 14. Таблицы: основные понятия Число и порядок столбцов фиксированы, а каждый столбец имеет имя Число строк переменно
- 15. Первичные ключи таблиц Ограничение первичного ключа означает, что образующий его столбец или группа столбцов может быть
- 16. Внешние ключи таблиц Ограничение внешнего ключа указывает, что значения столбца (или группы столбцов) должны соответствовать значениям
- 17. Создание и удаление таблиц . Создание таблицы: CREATE TABLE mytbl (id INTEGER PRIMARY KEY, name TEXT);
- 18. Изменение таблиц . Добавление столбца: ALTER TABLE mytbl ADD COLUMN new_col VARCHAR(100); Удаление столбца: ALTER TABLE
- 19. Анализ исходного xlsx-файла . Анализируем файл «Продукты питания.xlsx» Определяем, на сколько таблиц нужно разбить данную структуру
- 20. Домашнее задание №1 Проанализировать данные в исходном файле «HomeWork_1.xlsx» Создать в своей тестовой базе данных схему
- 21. Занятие второе Темы: Основные операторы DML: Select, Insert, Update и Delete Условия выборки Where Сортировка результатов
- 22. Добавление данных (INSERT) . Вставка одной строки: INSERT INTO mytbl VALUES (1, ‘txt-1’); Вставка нескольких строк:
- 23. Чтение данных (SELECT) . Простой запрос: SELECT * FROM mytbl; Псевдонимы имен таблиц и полей: SELECT
- 24. Изменение данных (UPDATE) . Изменение одного поля в строке: UPDATE mytbl SET name = ‘new_txt’ WHERE
- 25. Удаление данных (DELETE и TRUNCATE) . Удаление одной строки: DELETE FROM mytbl WHERE id = 1;
- 26. Копирование данных (COPY) . Копирование из таблицы в файл: COPY(SELECT * FROM tbl_1) TO 'C:/Data/tbl_data.csv' CSV
- 27. Домашнее задание №2 В первом задании вы создали набор таблиц на основе файла «HomeWork_1.xlsx» На сервере
- 28. Занятие третье Темы: Табличные пространства Способы приведения типов данных Cast Работа с представлениями View Объединение запросов
- 29. Табличные пространства . Назначение табличного пространства: 1. Нехватка места в разделе, на котором был инициализирован кластер
- 30. Приведение типов (CAST) . Функция приведения типов: SELECT CAST (‘22’ AS INTEGER); Аналогичного результата можно добиться
- 31. Представления (VIEW) . Создание представления: CREATE VIEW my_view AS SELECT * FROM tbl_1 WHERE type=‘2’; Переопределить
- 32. Сочетание запросов (UNION, INTERSECT, EXCEPT) . Объединение запросов UNION. Добавляет результаты второго запроса к результатам первого
- 33. Соединение запросов (JOIN) . Внутреннее соединение INNER JOIN или просто JOIN. Такое соединение, при котором выбираются
- 34. Домашнее задание №3 Изучить структуру таблиц в схеме «bookings» в своей тестовой базе данных. Подробно о
- 35. Занятие четвертое Темы: Последовательности Sequence Группировка и агрегатные функции Group By Оконные функции Табличные выражения With
- 36. Последовательности (SEQUENCE) . Создание последовательности для поля id в таблице my_tbl: CREATE SEQUENCE my_seq INCREMENT 1
- 37. Группировка (GROUP BY) . Выражение GROUP BY собирает в одну строку все строки, имеющие одинаковые значения
- 38. Агрегатные функции . ARRAY_AGG() собирает значения в массив. AVG() вычисляет среднее арифметическое. COUNT() возвращает количество строк.
- 39. Оконные функции . ROW_NUMBER() Создает нумерацию строк [по группам]. FIRST_VALUE() Возвращает первое значение из рамки. LAST_VALUE()
- 40. Табличные выражения (WITH) . Оператор WITH предоставляет возможность использовать подзапрос, как временную таблицу, существующую в рамках
- 42. Скачать презентацию

Занятие первое
Темы:
Вводная часть
Способы подключения к PostgreeSQL
Создание БД
Схемы
Констрейнты, ограничения, первичные и внешние
Занятие первое
Темы:
Вводная часть
Способы подключения к PostgreeSQL
Создание БД
Схемы
Констрейнты, ограничения, первичные и внешние

Почему PostgreSQL?
Free & Open Source
Лучший выбор для изучения: проинсталлировал и «понеслась»!
«Взрослая»
Почему PostgreSQL?
Free & Open Source
Лучший выбор для изучения: проинсталлировал и «понеслась»!
«Взрослая»

SQL – Structured Query Language
ANSI SQL-92
DDL – Data Definition Language
SQL – Structured Query Language
ANSI SQL-92
DDL – Data Definition Language

Подключаемся к базе данных
DBeaver Community https://dbeaver.io/download/
pgAdmin https://www.pgadmin.org/download/
Инструкции по настройке подключений тут:
Подключаемся к базе данных
DBeaver Community https://dbeaver.io/download/
pgAdmin https://www.pgadmin.org/download/
Инструкции по настройке подключений тут:

Создание, редактирование и удаление баз данных
Шаблоны
Табличные пространства
Кодировка символов
Владелец
Создание базы: CREATE DATABASE
Создание, редактирование и удаление баз данных
Шаблоны
Табличные пространства
Кодировка символов
Владелец
Создание базы: CREATE DATABASE

Правила наименования объектов в PostgreSQL
PostgreSQL работает в нижнем регистре и все
Правила наименования объектов в PostgreSQL
PostgreSQL работает в нижнем регистре и все
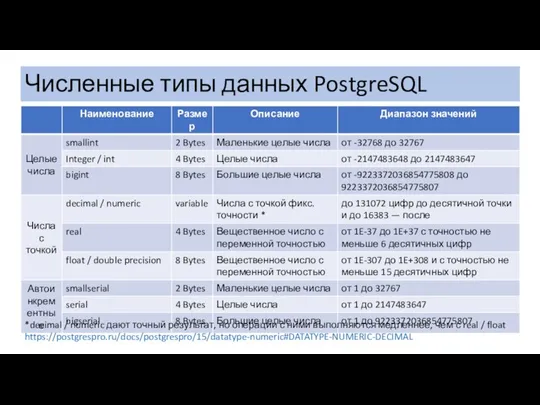
Численные типы данных PostgreSQL
*decimal / numeric дают точный результат, но операции
Численные типы данных PostgreSQL
*decimal / numeric дают точный результат, но операции

Текстовые типы данных PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype-character
Текстовые типы данных PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype-character
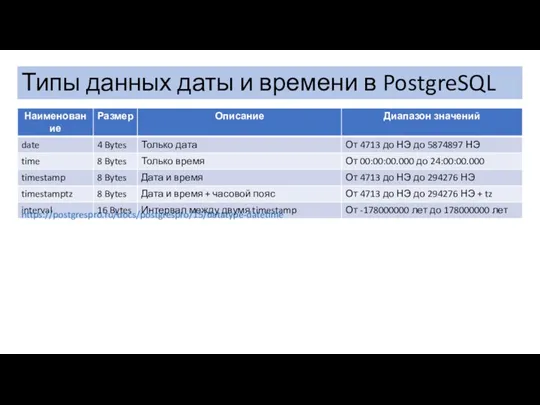
Типы данных даты и времени в PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype-datetime
Типы данных даты и времени в PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype-datetime
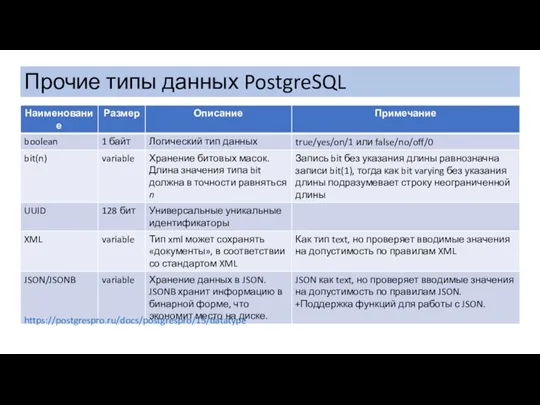
Прочие типы данных PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype
Прочие типы данных PostgreSQL
https://postgrespro.ru/docs/postgrespro/15/datatype

Схемы
Есть несколько возможных объяснений, для чего стоит применять схемы:
Чтобы одну
Схемы
Есть несколько возможных объяснений, для чего стоит применять схемы:
Чтобы одну

Операции со схемами
Создать схему CREATE SCHEMA test;
Удалить пустую схему DROP SCHEMA
Операции со схемами
Создать схему CREATE SCHEMA test;
Удалить пустую схему DROP SCHEMA

Таблицы: основные понятия
Число и порядок столбцов фиксированы, а каждый столбец имеет
Таблицы: основные понятия
Число и порядок столбцов фиксированы, а каждый столбец имеет

Первичные ключи таблиц
Ограничение первичного ключа означает, что образующий его столбец или
Первичные ключи таблиц
Ограничение первичного ключа означает, что образующий его столбец или

Внешние ключи таблиц
Ограничение внешнего ключа указывает, что значения столбца (или группы
Внешние ключи таблиц
Ограничение внешнего ключа указывает, что значения столбца (или группы

Создание и удаление таблиц
.
Создание таблицы: CREATE TABLE mytbl (id INTEGER
Создание и удаление таблиц
.
Создание таблицы: CREATE TABLE mytbl (id INTEGER

Изменение таблиц
.
Добавление столбца: ALTER TABLE mytbl ADD COLUMN new_col VARCHAR(100);
Удаление
Изменение таблиц
.
Добавление столбца: ALTER TABLE mytbl ADD COLUMN new_col VARCHAR(100);
Удаление

Анализ исходного xlsx-файла
.
Анализируем файл «Продукты питания.xlsx»
Определяем, на сколько таблиц нужно
Анализ исходного xlsx-файла
.
Анализируем файл «Продукты питания.xlsx»
Определяем, на сколько таблиц нужно

Домашнее задание №1
Проанализировать данные в исходном файле «HomeWork_1.xlsx»
Создать в своей тестовой
Домашнее задание №1
Проанализировать данные в исходном файле «HomeWork_1.xlsx»
Создать в своей тестовой

Занятие второе
Темы:
Основные операторы DML: Select, Insert, Update и Delete
Условия выборки
Занятие второе
Темы:
Основные операторы DML: Select, Insert, Update и Delete
Условия выборки

Добавление данных (INSERT)
.
Вставка одной строки: INSERT INTO mytbl VALUES (1,
Добавление данных (INSERT)
.
Вставка одной строки: INSERT INTO mytbl VALUES (1,

Чтение данных (SELECT)
.
Простой запрос: SELECT * FROM mytbl;
Псевдонимы имен таблиц
Чтение данных (SELECT)
.
Простой запрос: SELECT * FROM mytbl;
Псевдонимы имен таблиц

Изменение данных (UPDATE)
.
Изменение одного поля в строке: UPDATE mytbl SET
Изменение данных (UPDATE)
.
Изменение одного поля в строке: UPDATE mytbl SET

Удаление данных (DELETE и TRUNCATE)
.
Удаление одной строки: DELETE FROM mytbl
Удаление данных (DELETE и TRUNCATE)
.
Удаление одной строки: DELETE FROM mytbl

Копирование данных (COPY)
.
Копирование из таблицы в файл: COPY(SELECT * FROM
Копирование данных (COPY)
.
Копирование из таблицы в файл: COPY(SELECT * FROM

Домашнее задание №2
В первом задании вы создали набор таблиц на основе
Домашнее задание №2
В первом задании вы создали набор таблиц на основе

Занятие третье
Темы:
Табличные пространства
Способы приведения типов данных Cast
Работа с представлениями View
Объединение
Занятие третье
Темы:
Табличные пространства
Способы приведения типов данных Cast
Работа с представлениями View
Объединение

Табличные пространства
.
Назначение табличного пространства:
1. Нехватка места в разделе, на котором
Табличные пространства
.
Назначение табличного пространства:
1. Нехватка места в разделе, на котором

Приведение типов (CAST)
.
Функция приведения типов: SELECT CAST (‘22’ AS INTEGER);
Аналогичного
Приведение типов (CAST)
.
Функция приведения типов: SELECT CAST (‘22’ AS INTEGER);
Аналогичного

Представления (VIEW)
.
Создание представления: CREATE VIEW my_view AS SELECT * FROM
Представления (VIEW)
.
Создание представления: CREATE VIEW my_view AS SELECT * FROM

Сочетание запросов (UNION, INTERSECT, EXCEPT)
.
Объединение запросов UNION. Добавляет результаты второго
Сочетание запросов (UNION, INTERSECT, EXCEPT)
.
Объединение запросов UNION. Добавляет результаты второго

Соединение запросов (JOIN)
.
Внутреннее соединение INNER JOIN или просто JOIN. Такое
Соединение запросов (JOIN)
.
Внутреннее соединение INNER JOIN или просто JOIN. Такое

Домашнее задание №3
Изучить структуру таблиц в схеме «bookings» в своей тестовой
Домашнее задание №3
Изучить структуру таблиц в схеме «bookings» в своей тестовой

Занятие четвертое
Темы:
Последовательности Sequence
Группировка и агрегатные функции Group By
Оконные функции
Занятие четвертое
Темы:
Последовательности Sequence
Группировка и агрегатные функции Group By
Оконные функции

Последовательности (SEQUENCE)
.
Создание последовательности для поля id в таблице my_tbl:
Последовательности (SEQUENCE)
.
Создание последовательности для поля id в таблице my_tbl:

Группировка (GROUP BY)
.
Выражение GROUP BY собирает в одну строку все
Группировка (GROUP BY)
.
Выражение GROUP BY собирает в одну строку все

Агрегатные функции
.
ARRAY_AGG() собирает значения в массив.
AVG() вычисляет среднее арифметическое.
COUNT() возвращает
Агрегатные функции
.
ARRAY_AGG() собирает значения в массив.
AVG() вычисляет среднее арифметическое.
COUNT() возвращает
![Оконные функции . ROW_NUMBER() Создает нумерацию строк [по группам]. FIRST_VALUE()](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/591543/slide-38.jpg)
Оконные функции
.
ROW_NUMBER() Создает нумерацию строк [по группам].
FIRST_VALUE() Возвращает первое значение
Оконные функции
.
ROW_NUMBER() Создает нумерацию строк [по группам].
FIRST_VALUE() Возвращает первое значение

Табличные выражения (WITH)
.
Оператор WITH предоставляет возможность использовать подзапрос, как временную
Табличные выражения (WITH)
.
Оператор WITH предоставляет возможность использовать подзапрос, как временную
 Поворение материала 1 семестра. Основы языка С#. Основы ООП. Типы и структуры данных
Поворение материала 1 семестра. Основы языка С#. Основы ООП. Типы и структуры данных Использование мобильного приложения Наблюдатель Единой России и передача сведений с участковых избирательных комиссий
Использование мобильного приложения Наблюдатель Единой России и передача сведений с участковых избирательных комиссий Глобальные системы бронирования
Глобальные системы бронирования Дополнительные возможности текстового процессора. 8 класс
Дополнительные возможности текстового процессора. 8 класс Разветвляющиеся алгоритмы. Оператор условия if
Разветвляющиеся алгоритмы. Оператор условия if Вредоносное программное обеспечение и защита информации
Вредоносное программное обеспечение и защита информации Одномерные статические массивы (язык C)
Одномерные статические массивы (язык C) Засоби перегляду зображень
Засоби перегляду зображень Development of web services for managing events in the corporate system
Development of web services for managing events in the corporate system Урок Группы клавиш. Основная позиция пальцев на клавиатуре 5 класс
Урок Группы клавиш. Основная позиция пальцев на клавиатуре 5 класс Использование информационных и коммуникационных технологий в образовании
Использование информационных и коммуникационных технологий в образовании Место информатики в начальной школе
Место информатики в начальной школе Введение в CSS. Определение селекторов. Оформление текста
Введение в CSS. Определение селекторов. Оформление текста Знакомство с языком программирования Python
Знакомство с языком программирования Python Разработка Web-сайтов с использованием языка разметки гипертекста HTML. (8 класс)
Разработка Web-сайтов с использованием языка разметки гипертекста HTML. (8 класс) ГИС технологии в современной картографии
ГИС технологии в современной картографии Використання системних утиліт (урок 12)
Використання системних утиліт (урок 12) Стандарты беспроводной связи
Стандарты беспроводной связи Геоинформатика
Геоинформатика Ответы на вопросы на тему Интернет
Ответы на вопросы на тему Интернет Подход к автоматизации программ лояльности на базе Masterdata Loyalty Management
Подход к автоматизации программ лояльности на базе Masterdata Loyalty Management PyQt: GUI на Python при помощи Qt
PyQt: GUI на Python при помощи Qt Порядок назначения IP-адресов
Порядок назначения IP-адресов JavaScript. Циклы
JavaScript. Циклы Понятие информационных технологий и этапы их развития. Классификация ИТ
Понятие информационных технологий и этапы их развития. Классификация ИТ ИКТ-компетентность участников образовательного процесса
ИКТ-компетентность участников образовательного процесса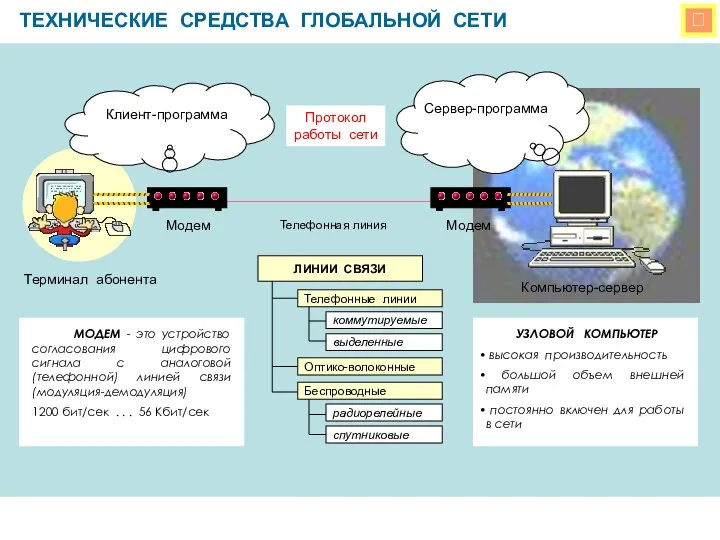 Технические средства глобальных сетей.
Технические средства глобальных сетей. Компьютерные игры The elder scrolls
Компьютерные игры The elder scrolls