Принципы управления данными с помощью языка структурированных запросов SQL на примере различных реляционных СУБД презентация
- Принципы управления данными с помощью языка структурированных запросов SQL на примере различных реляционных СУБД

Содержание
- 2. Что будет изучено Правила Кодда Основы SQL Нормальные формы. Синтаксис основных команд SQL Основные возможности и
- 3. Словарь (СУБД) База данных (БД, database) - поименованная совокупность структурированных данных, относящихся к определенной предметной области.
- 4. Словарь (таблица) Реляционная БД - основной тип современных баз данных. Состоит из таблиц, между которыми могут
- 5. 1-6 правило Кодда Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности.
- 6. 7-12 правило Кодда Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных,
- 7. Диаграмма «сущность-связи»
- 8. Нормализация Нормализация - это формальный метод анализа отношений на основе их первичного ключа и существующих связей.
- 9. 1НФ Первая нормальная форма (1НФ) связана с понятиями простого и сложного атрибутов. Простой атрибут - это
- 10. 1НФ Отношение приведено к 1НФ, если все его атрибуты - простые, т.е. значение атрибута не должно
- 11. 2 НФ Вторая нормальная форма (2НФ) применяется к отношениям с составными ключами (состоящими из двух и
- 12. 2 НФ Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального ключа. Эта часть
- 13. 3 НФ Третья нормальная форма (3НФ) связана с понятием транзитивной зависимости. Пусть A, B, C -
- 14. 3 НФ Отношение находится в 3НФ, если оно находится во 2НФ и не имеет атрибутов, не
- 15. 3 НФ SELECT НФ3Клиент.Имя, НФ3Клиент.Адрес, НФ3Заказ.[№ заказа], НФ3Заказ.[Дата заказа], НФ3СоставЗаказа.Категория, НФ3СоставЗаказа.Количество FROM (НФ3Клиент INNER JOIN НФ3Заказ
- 16. 4,5 НФ Существуют также нормальная форма Бойса-Кодда (НФБК), 4НФ и 5НФ. Однако наибольшее значение имеет 1НФ,
- 17. Проблемы нормализации Моделирование структуры базы данных при помощи алгоритма нормализации имеет серьезные недостатки: Методика нормализации предполагает
- 18. Ссылочная целостность Соблюдение условий ссылочной целостности в реляционной базе данных Правило соответствия внешних ключей первичным -
- 19. СЦ родительской таблицы Для родительской таблицы: Вставка. Возникает новое значение первичного ключа. Существование записей в родительской
- 20. СЦ дочерней таблицы Для дочерней таблицы: Вставка. Нельзя вставить запись в дочернюю таблицу, если для новой
- 21. Стратегия поддержания СЦ Основные: RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
- 22. Обозначения ::= Равно по определению | Необходимость выбора одного из нескольких приведенных значений Описанная с помощью
- 23. Типы данных Символьный CHAR | VARCHAR Битовый BIT | BIT VARYING Точные числа NUMERIC | DECIMAL
- 24. Создание БД CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ [,...n] ] [, [,...n] ] ] [ LOG
- 25. Пример создания БД CREATE DATABASE Archive ON PRIMARY ( NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch2, FILENAME=’c:\user\data\archdat2.mdf’,
- 26. Изменение БД ::= ALTER DATABASE имя_базы_данных { ADD FILE [,...n] [TO FILEGROUP имя_группы_файлов ] | ADD
- 27. Основные объекты структуры базы данных SQL-сервера Tables Таблицы базы данных, в которых хранятся собственно данные Views
- 28. Create table CREATE [ { GLOBAL | LOCAL } ] TEMPORARY] TABLE имя_таблицы ( { column
- 29. Ограничения столбца NOT NULL - в любой добавляемой или изменяемой строке столбец всегда должен иметь значение,
- 30. Ограничения таблицы CHECK (condition) - указываемое в скобках условие использует для сравнения значение столбца и возвращает
- 31. Пример создания CREATE TABLE Товар (Название VARCHAR(50) NOT NULL, Цена MONEY NOT NULL, Тип VARCHAR(50) NOT
- 32. Изменение таблицы ALTER TABLE имя_таблицы {[ALTER COLUMN имя_столбца {новый_тип_данных [(точность[,масштаб])] [ NULL | NOT NULL ]}]
- 33. Select SELECT [ALL | DISTINCT ] {*|[имя_столбца [AS новое_имя]]} [,...n] FROM имя_таблицы [[AS] псевдоним] [,...n] [WHERE
- 34. Очередность выполнения FROM – определяются имена используемых таблиц; WHERE – выполняется фильтрация строк объекта в соответствии
- 35. Select … Where Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления другого. Диапазон: проверяется, попадает
- 36. Select … ORDER BY SELECT Клиент.Фамилия, Клиент.Фирма FROM Клиент ORDER BY Клиент.Фамилия SELECT Клиент.Фирма, Клиент.Фамилия FROM
- 37. Выборка Операция выборки - построение горизонтального подмножества, т.е. подмножества кортежей, обладающих заданными свойствами. Операция выборки работает
- 38. Проекция Операция проекции - построение вертикального подмножества отношения, т.е. подмножества кортежей, получаемого выбором одних и исключением
- 39. Декартово произведение Декартово произведение RxS двух отношений (двух таблиц) определяет новое отношение - результат конкатенации (т.е.
- 40. Соединение Соединение - это процесс, когда две или более таблицы объединяются в одну. Способность объединять информацию
- 41. Варианты соединения тета-соединение соединение по эквивалентности естественное соединение внешнее соединение полусоединение
- 42. Операция тета-соединения Операция тета-соединения определяет отношение, которое содержит кортежи из декартова произведения отношений R и S,
- 43. Естественное соединение Естественным соединением называется соединение по эквивалентности двух отношений R и S, выполненное по всем
- 44. Внешние и внутренние соединения Внешнее соединение похоже на внутреннее, но в результирующий набор данных включаются также
- 45. Левое и правое внешнее соединение Левым внешним соединением называется соединение, при котором кортежи отношения R, не
- 46. Полусоединение Операция полусоединения определяет отношение, содержащее те кортежи отношения R, которые входят в соединение отношений R
- 47. Объединение Объединение (UNION) R S отношений R и S можно получить в результате их конкатенации с
- 48. Пересечение Операция пересечения (INTERSECT) R S=R-(R-S) определяет отношение, которое содержит кортежи, присутствующие как в отношении R,
- 49. Разность Разность (EXCEPT) R-S двух отношений R и S состоит из кортежей, которые имеются в отношении
- 50. Вычисляемые поля В общем случае для создания вычисляемого (производного) поля в списке SELECT следует указать некоторое
- 51. Итоговые функции С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить ряд обобщающих статистических сведений
- 52. Select … Group By Часто в запросах требуется формировать промежуточные итоги, что обычно отображается появлением в
- 53. Select … having При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY блоки данных, удовлетворяющие
- 54. Подзапросы Подзапрос – это инструмент создания временной таблицы, содержимое которой извлекается и обрабатывается внешним оператором. Текст
- 55. Подзапросы, возвращающие единичное значение Определить дату продажи максимальной партии товара. SELECT Дата, Количество FROM Сделка WHERE
- 56. Подзапросы, возвращающие множество значений Во многих случаях значение, подлежащее сравнению в предложениях WHERE или HAVING, представляет
- 57. Exist Ключевые слова EXISTS и NOT EXISTS предназначены для использования только совместно с подзапросами. Результат их
- 58. Модификация данных Язык SQL ориентирован на выполнение операций над группами записей, хотя в некоторых случаях их
- 59. Запрос добавления Оператор INSERT применяется для добавления записей в таблицу. Формат оператора: ::=INSERT INTO [(имя_столбца [,...n])]
- 60. Пример добавления INSERT INTO Товар (Название, Тип, Цена) VALUES(" Славянский ", " шоколад ", 12) Или
- 61. Запрос удаления Оператор DELETE предназначен для удаления группы записей из таблицы. Формат оператора: ::=DELETE FROM [WHERE
- 62. Запрос обновления Оператор UPDATE применяется для изменения значений в группе записей или в одной записи указанной
- 63. Определение представления Представления, или просмотры (VIEW), представляют собой временные, производные (иначе - виртуальные) таблицы и являются
- 64. Примеры представлений CREATE VIEW view1 AS SELECT КодКлиента, Фамилия, ГородКлиента FROM Клиент WHERE ГородКлиента='Москва' Пример обращения:
- 65. Понятие функции пользователя Функции пользователя представляют собой самостоятельные объекты базы данных, такие, например, как хранимые процедуры
- 67. Скачать презентацию

Что будет изучено
Правила Кодда
Основы SQL
Нормальные формы.
Синтаксис основных команд SQL
Основные возможности и
Что будет изучено
Правила Кодда
Основы SQL
Нормальные формы.
Синтаксис основных команд SQL
Основные возможности и

Словарь (СУБД)
База данных (БД, database) - поименованная совокупность структурированных данных, относящихся
Словарь (СУБД)
База данных (БД, database) - поименованная совокупность структурированных данных, относящихся

Словарь (таблица)
Реляционная БД - основной тип современных баз данных. Состоит из
Словарь (таблица)
Реляционная БД - основной тип современных баз данных. Состоит из

1-6 правило Кодда
Реляционная СУБД должна быть способна полностью управлять базой данных
1-6 правило Кодда
Реляционная СУБД должна быть способна полностью управлять базой данных

7-12 правило Кодда
Вставка, обновление и удаление - СУБД поддерживает не только
7-12 правило Кодда
Вставка, обновление и удаление - СУБД поддерживает не только
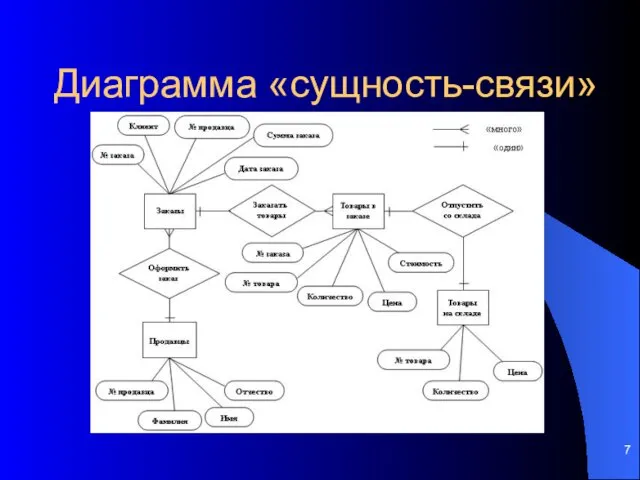
Диаграмма «сущность-связи»
Диаграмма «сущность-связи»

Нормализация
Нормализация - это формальный метод анализа отношений на основе их первичного
Нормализация
Нормализация - это формальный метод анализа отношений на основе их первичного

1НФ
Первая нормальная форма (1НФ) связана с понятиями простого и сложного атрибутов.
Простой
1НФ
Первая нормальная форма (1НФ) связана с понятиями простого и сложного атрибутов.
Простой

1НФ
Отношение приведено к 1НФ, если все его атрибуты - простые, т.е.
1НФ
Отношение приведено к 1НФ, если все его атрибуты - простые, т.е.

2 НФ
Вторая нормальная форма (2НФ) применяется к отношениям с составными ключами
2 НФ
Вторая нормальная форма (2НФ) применяется к отношениям с составными ключами

2 НФ
Во второй нормальной форме устраняются атрибуты, зависящие только от части
2 НФ
Во второй нормальной форме устраняются атрибуты, зависящие только от части

3 НФ
Третья нормальная форма (3НФ) связана с понятием транзитивной зависимости. Пусть
3 НФ
Третья нормальная форма (3НФ) связана с понятием транзитивной зависимости. Пусть
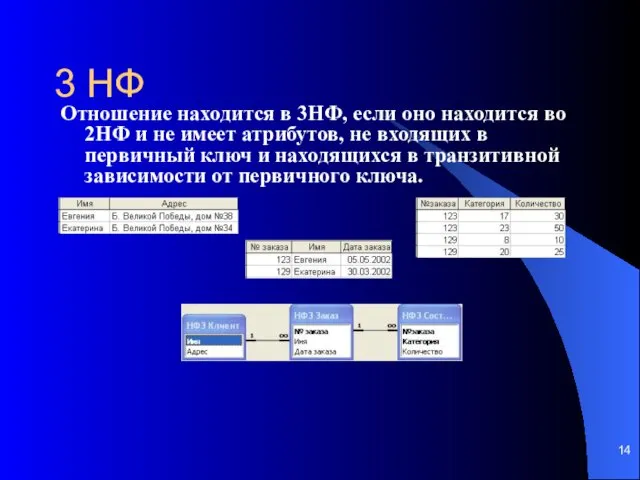
3 НФ
Отношение находится в 3НФ, если оно находится во 2НФ и
3 НФ
Отношение находится в 3НФ, если оно находится во 2НФ и
![3 НФ SELECT НФ3Клиент.Имя, НФ3Клиент.Адрес, НФ3Заказ.[№ заказа], НФ3Заказ.[Дата заказа], НФ3СоставЗаказа.Категория,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-14.jpg)
3 НФ
SELECT НФ3Клиент.Имя, НФ3Клиент.Адрес, НФ3Заказ.[№ заказа], НФ3Заказ.[Дата заказа], НФ3СоставЗаказа.Категория, НФ3СоставЗаказа.Количество
FROM (НФ3Клиент
3 НФ
SELECT НФ3Клиент.Имя, НФ3Клиент.Адрес, НФ3Заказ.[№ заказа], НФ3Заказ.[Дата заказа], НФ3СоставЗаказа.Категория, НФ3СоставЗаказа.Количество
FROM (НФ3Клиент

4,5 НФ
Существуют также нормальная форма Бойса-Кодда (НФБК), 4НФ и 5НФ. Однако
4,5 НФ
Существуют также нормальная форма Бойса-Кодда (НФБК), 4НФ и 5НФ. Однако

Проблемы нормализации
Моделирование структуры базы данных при помощи алгоритма нормализации имеет серьезные
Проблемы нормализации
Моделирование структуры базы данных при помощи алгоритма нормализации имеет серьезные

Ссылочная целостность
Соблюдение условий ссылочной целостности в реляционной базе данных
Правило соответствия внешних
Ссылочная целостность
Соблюдение условий ссылочной целостности в реляционной базе данных
Правило соответствия внешних

СЦ родительской таблицы
Для родительской таблицы:
Вставка. Возникает новое значение первичного ключа. Существование
СЦ родительской таблицы
Для родительской таблицы:
Вставка. Возникает новое значение первичного ключа. Существование

СЦ дочерней таблицы
Для дочерней таблицы:
Вставка. Нельзя вставить запись в дочернюю таблицу,
СЦ дочерней таблицы
Для дочерней таблицы:
Вставка. Нельзя вставить запись в дочернюю таблицу,

Стратегия поддержания СЦ
Основные:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к
Стратегия поддержания СЦ
Основные:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к

Обозначения
::= Равно по определению
| Необходимость выбора одного из нескольких приведенных значений
<…> Описанная с помощью
Обозначения
::= Равно по определению
| Необходимость выбора одного из нескольких приведенных значений
<…> Описанная с помощью

Типы данных
Символьный CHAR | VARCHAR
Битовый BIT | BIT VARYING
Точные числа NUMERIC
Типы данных
Символьный CHAR | VARCHAR
Битовый BIT | BIT VARYING
Точные числа NUMERIC
![Создание БД CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ [,...n] ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-23.jpg)
Создание БД
CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ <определение_файла> [,...n] ] [,<определение_группы>
Создание БД
CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ <определение_файла> [,...n] ] [,<определение_группы>

Пример создания БД
CREATE DATABASE Archive ON PRIMARY ( NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB,
Пример создания БД
CREATE DATABASE Archive ON PRIMARY ( NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB,
![Изменение БД ::= ALTER DATABASE имя_базы_данных { ADD FILE [,...n]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-25.jpg)
Изменение БД
<изменение_базы_данных> ::= ALTER DATABASE имя_базы_данных { ADD FILE <определение_файла>[,...n] [TO
Изменение БД
<изменение_базы_данных> ::= ALTER DATABASE имя_базы_данных { ADD FILE <определение_файла>[,...n] [TO

Основные объекты структуры базы данных SQL-сервера
Tables Таблицы базы данных, в
Основные объекты структуры базы данных SQL-сервера
Tables Таблицы базы данных, в
![Create table CREATE [ { GLOBAL | LOCAL } ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-27.jpg)
Create table
CREATE [ { GLOBAL | LOCAL } ] TEMPORARY] TABLE
Create table
CREATE [ { GLOBAL | LOCAL } ] TEMPORARY] TABLE

Ограничения столбца
NOT NULL - в любой добавляемой или изменяемой строке столбец
Ограничения столбца
NOT NULL - в любой добавляемой или изменяемой строке столбец

Ограничения таблицы
CHECK (condition) - указываемое в скобках условие использует для сравнения
Ограничения таблицы
CHECK (condition) - указываемое в скобках условие использует для сравнения

Пример создания
CREATE TABLE
Товар
(Название VARCHAR(50) NOT NULL, Цена
Пример создания
CREATE TABLE
Товар
(Название VARCHAR(50) NOT NULL, Цена
![Изменение таблицы ALTER TABLE имя_таблицы {[ALTER COLUMN имя_столбца {новый_тип_данных [(точность[,масштаб])]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-31.jpg)
Изменение таблицы
ALTER TABLE имя_таблицы {[ALTER COLUMN имя_столбца {новый_тип_данных [(точность[,масштаб])] [ NULL
Изменение таблицы
ALTER TABLE имя_таблицы {[ALTER COLUMN имя_столбца {новый_тип_данных [(точность[,масштаб])] [ NULL
![Select SELECT [ALL | DISTINCT ] {*|[имя_столбца [AS новое_имя]]} [,...n]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/90451/slide-32.jpg)
Select
SELECT [ALL | DISTINCT ] {*|[имя_столбца [AS новое_имя]]} [,...n] FROM имя_таблицы
Select
SELECT [ALL | DISTINCT ] {*|[имя_столбца [AS новое_имя]]} [,...n] FROM имя_таблицы

Очередность выполнения
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация
Очередность выполнения
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация

Select … Where
Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления
Select … Where
Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления

Select … ORDER BY
SELECT Клиент.Фамилия, Клиент.Фирма FROM Клиент ORDER BY Клиент.Фамилия
Select … ORDER BY
SELECT Клиент.Фамилия, Клиент.Фирма FROM Клиент ORDER BY Клиент.Фамилия

Выборка
Операция выборки - построение горизонтального подмножества, т.е. подмножества кортежей, обладающих заданными
Выборка
Операция выборки - построение горизонтального подмножества, т.е. подмножества кортежей, обладающих заданными

Проекция
Операция проекции - построение вертикального подмножества отношения, т.е. подмножества кортежей, получаемого
Проекция
Операция проекции - построение вертикального подмножества отношения, т.е. подмножества кортежей, получаемого

Декартово произведение
Декартово произведение RxS двух отношений (двух таблиц) определяет новое отношение
Декартово произведение
Декартово произведение RxS двух отношений (двух таблиц) определяет новое отношение

Соединение
Соединение - это процесс, когда две или более таблицы объединяются в
Соединение
Соединение - это процесс, когда две или более таблицы объединяются в

Варианты соединения
тета-соединение
соединение по эквивалентности
естественное соединение
внешнее соединение
полусоединение
Варианты соединения
тета-соединение
соединение по эквивалентности
естественное соединение
внешнее соединение
полусоединение

Операция тета-соединения
Операция тета-соединения определяет отношение, которое содержит кортежи из декартова
Операция тета-соединения
Операция тета-соединения определяет отношение, которое содержит кортежи из декартова

Естественное соединение
Естественным соединением называется соединение по эквивалентности двух отношений R
Естественное соединение
Естественным соединением называется соединение по эквивалентности двух отношений R

Внешние и внутренние соединения
Внешнее соединение похоже на внутреннее, но в результирующий
Внешние и внутренние соединения
Внешнее соединение похоже на внутреннее, но в результирующий

Левое и правое внешнее соединение
Левым внешним соединением называется соединение, при
Левое и правое внешнее соединение
Левым внешним соединением называется соединение, при

Полусоединение
Операция полусоединения определяет отношение, содержащее те кортежи отношения R, которые
Полусоединение
Операция полусоединения определяет отношение, содержащее те кортежи отношения R, которые

Объединение
Объединение (UNION) R S отношений R и S можно получить в
Объединение
Объединение (UNION) R S отношений R и S можно получить в

Пересечение
Операция пересечения (INTERSECT) R S=R-(R-S) определяет отношение, которое содержит кортежи, присутствующие
Пересечение
Операция пересечения (INTERSECT) R S=R-(R-S) определяет отношение, которое содержит кортежи, присутствующие

Разность
Разность (EXCEPT) R-S двух отношений R и S состоит из кортежей,
Разность
Разность (EXCEPT) R-S двух отношений R и S состоит из кортежей,

Вычисляемые поля
В общем случае для создания вычисляемого (производного) поля в списке
Вычисляемые поля
В общем случае для создания вычисляемого (производного) поля в списке

Итоговые функции
С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить
Итоговые функции
С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить

Select … Group By
Часто в запросах требуется формировать промежуточные итоги, что
Select … Group By
Часто в запросах требуется формировать промежуточные итоги, что

Select … having
При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP
Select … having
При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP

Подзапросы
Подзапрос – это инструмент создания временной таблицы, содержимое которой извлекается и
Подзапросы
Подзапрос – это инструмент создания временной таблицы, содержимое которой извлекается и

Подзапросы, возвращающие единичное значение
Определить дату продажи максимальной партии товара.
SELECT Дата, Количество
Подзапросы, возвращающие единичное значение
Определить дату продажи максимальной партии товара.
SELECT Дата, Количество

Подзапросы, возвращающие множество значений
Во многих случаях значение, подлежащее сравнению в предложениях
Подзапросы, возвращающие множество значений
Во многих случаях значение, подлежащее сравнению в предложениях

Exist
Ключевые слова EXISTS и NOT EXISTS предназначены для использования только совместно
Exist
Ключевые слова EXISTS и NOT EXISTS предназначены для использования только совместно

Модификация данных
Язык SQL ориентирован на выполнение операций над группами записей, хотя
Модификация данных
Язык SQL ориентирован на выполнение операций над группами записей, хотя

Запрос добавления
Оператор INSERT применяется для добавления записей в таблицу. Формат
Запрос добавления
Оператор INSERT применяется для добавления записей в таблицу. Формат

Пример добавления
INSERT INTO Товар
(Название, Тип, Цена)
VALUES(" Славянский ", "
Пример добавления
INSERT INTO Товар
(Название, Тип, Цена)
VALUES(" Славянский ", "

Запрос удаления
Оператор DELETE предназначен для удаления группы записей из таблицы.
Формат
Запрос удаления
Оператор DELETE предназначен для удаления группы записей из таблицы.
Формат

Запрос обновления
Оператор UPDATE применяется для изменения значений в группе записей
Запрос обновления
Оператор UPDATE применяется для изменения значений в группе записей

Определение представления
Представления, или просмотры (VIEW), представляют собой временные, производные (иначе
Определение представления
Представления, или просмотры (VIEW), представляют собой временные, производные (иначе

Примеры представлений
CREATE VIEW view1 AS
SELECT КодКлиента, Фамилия, ГородКлиента
FROM Клиент
Примеры представлений
CREATE VIEW view1 AS
SELECT КодКлиента, Фамилия, ГородКлиента
FROM Клиент

Понятие функции пользователя
Функции пользователя представляют собой самостоятельные объекты базы данных,
Понятие функции пользователя
Функции пользователя представляют собой самостоятельные объекты базы данных,
 Экспертные системы. Характеристика и состав, примеры применения ЭС
Экспертные системы. Характеристика и состав, примеры применения ЭС Текстовый процессор MS Word
Текстовый процессор MS Word Решение задач ЕГЭ типа В12
Решение задач ЕГЭ типа В12 Разработка мобильных приложений. Responsive Web Design
Разработка мобильных приложений. Responsive Web Design Программное обеспечение ПК. История развития ПО
Программное обеспечение ПК. История развития ПО Алгоритм
Алгоритм Модели бизнеса на цифровом рынке. Электронные рынки. Понятия, состав, модели и средства связи с внешней средой
Модели бизнеса на цифровом рынке. Электронные рынки. Понятия, состав, модели и средства связи с внешней средой Что такое нейросеть и её виды?
Что такое нейросеть и её виды? Команды создания графических объектов. Слои
Команды создания графических объектов. Слои Презентация к уроку Моделирование в программе QCAD
Презентация к уроку Моделирование в программе QCAD Код Хэмминга. Пример работы алгоритма
Код Хэмминга. Пример работы алгоритма ВКР: Автоматизация деятельности страховой компании
ВКР: Автоматизация деятельности страховой компании SQL Server
SQL Server Компьютерная графика. 7 класс
Компьютерная графика. 7 класс Разработка автоматизированной системы для центра управления паролями
Разработка автоматизированной системы для центра управления паролями Маршрутизация IP
Маршрутизация IP Бесплатное продвижение во ВКонтакте
Бесплатное продвижение во ВКонтакте Передача информации. Схема передачи информации. Электронная почта
Передача информации. Схема передачи информации. Электронная почта Конкурс знатоков
Конкурс знатоков Прапорці та групи перемикачів (урок 23)
Прапорці та групи перемикачів (урок 23) Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста
Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста ТЗ. Конструктор фигурок
ТЗ. Конструктор фигурок История развития вычислительной техники
История развития вычислительной техники Конструктор сайтов А5
Конструктор сайтов А5 Проект Визуальная новелла. Жанр компьютерных игр
Проект Визуальная новелла. Жанр компьютерных игр Право и этика СМИ
Право и этика СМИ Представление о базе данных и ее объектах
Представление о базе данных и ее объектах Работа с контрольно-кассовой техникой (ККТ) в ИМ Лабиринт
Работа с контрольно-кассовой техникой (ККТ) в ИМ Лабиринт