- Проблемы создания эффективного параллельного прогаммного обеспечения

Содержание
- 2. Зачем нужны быстрые вычисления
- 3. Где применяются быстрые вычисления? В управлении сложными объектами (АЭС, самолеты,…) В обороне (раннее обнаружение противника,…) В
- 4. КОМПЬЮТЕРЫ И СУПЕРКОМПЬЮТЕРЫ Ранее высокопроизводительные вычисления относились только к суперкомпьютерам. Суперкомпьютеры производились в единичных экземплярах и
- 5. Проблемы эффективности последовательных программ
- 6. КОМПЬЮТЕРЫ МЕНЯЮТСЯ БЫСТРЕЕ, ЧЕМ ПРОГРАММЫ Мы привыкли к преемственности в смене IBM-совместимых компьютеров (с системой команд
- 7. Изменились условия оптимизации программ. Новые архитектуры требуют новых оптимизирующих преобразований программ X(i+2) = X(i+2)+5 заменять следующим
- 8. Следует осмотрительно использовать старые библиотеки программ. Для задачи перемножения матриц NxN есть стандартный алгоритм (N^3 умножений
- 9. Проблемы эффективности параллельных программ
- 10. Разным задачам – разные архитектуры Циклы с условными операторами выгодно отображать на асинхронные архитектуры Самые глубоко
- 11. ПРОБЛЕМЫ СОЗДАНИЯ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ Нет универсальных архитектур. Разные задачи эффективны на разных архитектурах Разработка параллельных
- 12. ПУТИ РАЗВИТИЯ ИНДУСТРИИ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ Создание систем полуавтоматических преобразований программ (распараллеливающих и оптимизирующих), как инструмента
- 13. Исследовательские университетские распараллеливающие системы POLARIS – распараллеливающая система Urbana University (штат Illinois), руководитель проекта David Padua.
- 14. Южный федеральный университет мехмат Открытая распараллеливающая система. ОРС – прототип инструмента создания эффективных параллельных программ В
- 15. ПАРАЛЛЕЛЬНО ВЫПОЛНЯЕМЫЕ ПРОГРАММНЫЕ ЦИКЛЫ. Под параллельным выполнением цикла понимается одновременное выполнение его итераций. Какие итерации можно
- 16. Определение распараллеливаемых циклов в ОРС. (помечены флажками слева) В окнах информация о возможной векторизации или распараллеливании.
- 17. Виды параллельных вычислений Параллельное выполнение задач Параллельное выполнение функций Параллельное выполнение циклов Параллельное выполнение операций Параллельное
- 18. Распараллеливание циклов Под параллельным вычислением цикла понимается одновременное выполнение его итераций. Термин «одновременное» допускает разные толкования
- 19. Граф информационных связей (Dependence graph) Вершины графа – вхождения переменных. Дуга соединяет пару вершин (v1,v2) тогда
- 20. Пример графа информационных связей, автоматически построенного в ОРС DO 99 J=2,N DO 99 I=2,N A(I,J) =
- 21. Циклически независимая и циклически порожденная зависимости. Пример. DO 99 I=2,N B(I) = A v1 v2 99
- 22. Пример (А.М. Шульженко). фрагмент программы умножения двух многочленов и решетчатый граф: For (k=0; k c[k]=0; %
- 23. История решетчатых графов Решетчатые графы использовались концептуально, для иллюстрации идей в методе гиперплоскостей Л. Лампорта, в
- 24. Направления работ группы ОРС по использованию решетчатых графов в распараллеливающих компиляторах: Использование решетчатых графов в преобразованиях
- 25. Пример анализа зависимостей с использованием решетчатого графа Пример. DO 99 i = 1, N DO 99
- 26. Полный решетчатый граф программы с дугами истинной зависимости, антизависимости и выходной самозависимости (граф построен с помощью
- 27. Преобразованная программа со вспомогательными массивами и только одним барьером. For (i=0; i a[i+1] = ... ;
- 28. Визуализация элементарного решетчатого графа для выделенной пары вхождений переменной в ОРС. В специальном окне представлены функции,
- 29. 3D-визуализация решетчатого графа в ОРС.
- 30. Открытая распараллеливающая система. Исследования. Автоматические оценки погрешностей Распараллеливание рекуррентных циклов Максимальное разбиение программных циклов Подстановка и
- 31. ОРС позволяет автоматически строить граф информационных связей решетчатый граф программы. В ОРС автоматически определяются параллельно выполняемые
- 33. Скачать презентацию

Зачем нужны быстрые вычисления
Зачем нужны быстрые вычисления

Где применяются быстрые вычисления?
В управлении сложными объектами (АЭС, самолеты,…)
В обороне (раннее
Где применяются быстрые вычисления?
В управлении сложными объектами (АЭС, самолеты,…)
В обороне (раннее

КОМПЬЮТЕРЫ И СУПЕРКОМПЬЮТЕРЫ
Ранее высокопроизводительные вычисления относились только к суперкомпьютерам.
Суперкомпьютеры производились
КОМПЬЮТЕРЫ И СУПЕРКОМПЬЮТЕРЫ
Ранее высокопроизводительные вычисления относились только к суперкомпьютерам.
Суперкомпьютеры производились

Проблемы эффективности последовательных программ
Проблемы эффективности последовательных программ

КОМПЬЮТЕРЫ МЕНЯЮТСЯ БЫСТРЕЕ, ЧЕМ ПРОГРАММЫ
Мы привыкли к преемственности в смене IBM-совместимых
КОМПЬЮТЕРЫ МЕНЯЮТСЯ БЫСТРЕЕ, ЧЕМ ПРОГРАММЫ
Мы привыкли к преемственности в смене IBM-совместимых

Изменились условия оптимизации программ.
Новые архитектуры требуют новых оптимизирующих преобразований программ
X(i+2)
Изменились условия оптимизации программ.
Новые архитектуры требуют новых оптимизирующих преобразований программ
X(i+2)

Следует осмотрительно использовать старые библиотеки программ.
Для задачи перемножения матриц NxN есть
Следует осмотрительно использовать старые библиотеки программ.
Для задачи перемножения матриц NxN есть

Проблемы эффективности параллельных программ
Проблемы эффективности параллельных программ

Разным задачам – разные архитектуры
Циклы с условными операторами выгодно отображать на
Разным задачам – разные архитектуры
Циклы с условными операторами выгодно отображать на

ПРОБЛЕМЫ СОЗДАНИЯ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Нет универсальных архитектур. Разные задачи эффективны на
ПРОБЛЕМЫ СОЗДАНИЯ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Нет универсальных архитектур. Разные задачи эффективны на

ПУТИ РАЗВИТИЯ ИНДУСТРИИ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Создание систем полуавтоматических преобразований программ (распараллеливающих
ПУТИ РАЗВИТИЯ ИНДУСТРИИ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Создание систем полуавтоматических преобразований программ (распараллеливающих

Исследовательские университетские распараллеливающие системы
POLARIS – распараллеливающая система Urbana University (штат Illinois),
Исследовательские университетские распараллеливающие системы
POLARIS – распараллеливающая система Urbana University (штат Illinois),

Южный федеральный университет
мехмат
Открытая распараллеливающая система.
ОРС – прототип инструмента
Южный федеральный университет
мехмат
Открытая распараллеливающая система.
ОРС – прототип инструмента

ПАРАЛЛЕЛЬНО ВЫПОЛНЯЕМЫЕ ПРОГРАММНЫЕ ЦИКЛЫ.
Под параллельным выполнением цикла понимается одновременное выполнение
ПАРАЛЛЕЛЬНО ВЫПОЛНЯЕМЫЕ ПРОГРАММНЫЕ ЦИКЛЫ.
Под параллельным выполнением цикла понимается одновременное выполнение
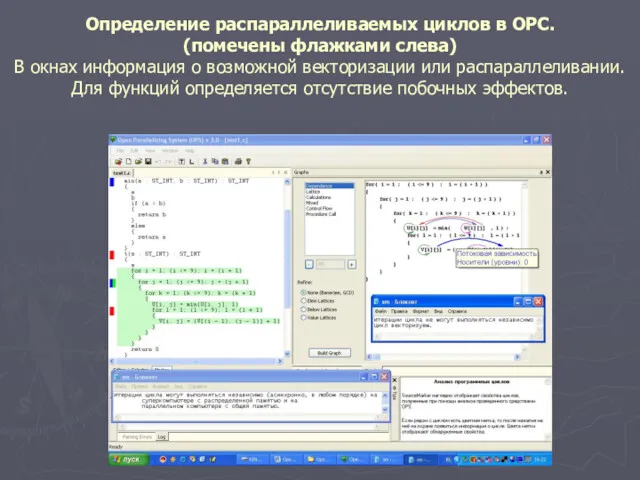
Определение распараллеливаемых циклов в ОРС.
(помечены флажками слева)
В окнах информация
Определение распараллеливаемых циклов в ОРС. (помечены флажками слева) В окнах информация

Виды параллельных вычислений
Параллельное выполнение задач
Параллельное выполнение функций
Параллельное выполнение циклов
Параллельное выполнение операций
Параллельное
Виды параллельных вычислений
Параллельное выполнение задач
Параллельное выполнение функций
Параллельное выполнение циклов
Параллельное выполнение операций
Параллельное

Распараллеливание циклов
Под параллельным вычислением цикла понимается одновременное выполнение его итераций.
Термин
Распараллеливание циклов
Под параллельным вычислением цикла понимается одновременное выполнение его итераций.
Термин

Граф информационных связей
(Dependence graph)
Вершины графа – вхождения переменных.
Дуга соединяет пару
Граф информационных связей
(Dependence graph)
Вершины графа – вхождения переменных.
Дуга соединяет пару

Пример графа информационных связей,
автоматически построенного в ОРС
DO 99 J=2,N
DO
Пример графа информационных связей,
автоматически построенного в ОРС
DO 99 J=2,N
DO

Циклически независимая и циклически порожденная зависимости. Пример.
DO 99 I=2,N
B(I) =
Циклически независимая и циклически порожденная зависимости. Пример.
DO 99 I=2,N
B(I) =

Пример (А.М. Шульженко). фрагмент программы умножения двух многочленов и решетчатый граф:
For
Пример (А.М. Шульженко). фрагмент программы умножения двух многочленов и решетчатый граф:
For

История решетчатых графов
Решетчатые графы использовались концептуально, для иллюстрации идей в методе
История решетчатых графов
Решетчатые графы использовались концептуально, для иллюстрации идей в методе

Направления работ группы ОРС по использованию решетчатых графов в распараллеливающих компиляторах:
Использование
Направления работ группы ОРС по использованию решетчатых графов в распараллеливающих компиляторах:
Использование

Пример анализа зависимостей с использованием решетчатого графа
Пример.
DO 99 i =
Пример анализа зависимостей с использованием решетчатого графа
Пример.
DO 99 i =
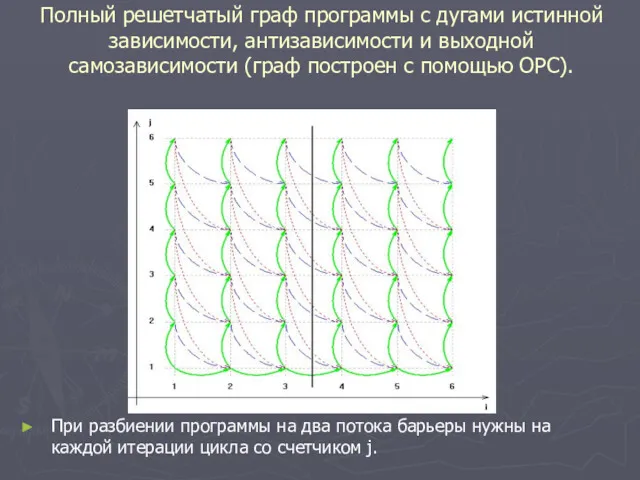
Полный решетчатый граф программы с дугами истинной зависимости, антизависимости и выходной
Полный решетчатый граф программы с дугами истинной зависимости, антизависимости и выходной

Преобразованная программа со вспомогательными массивами и только одним барьером.
For (i=0;
Преобразованная программа со вспомогательными массивами и только одним барьером.
For (i=0;
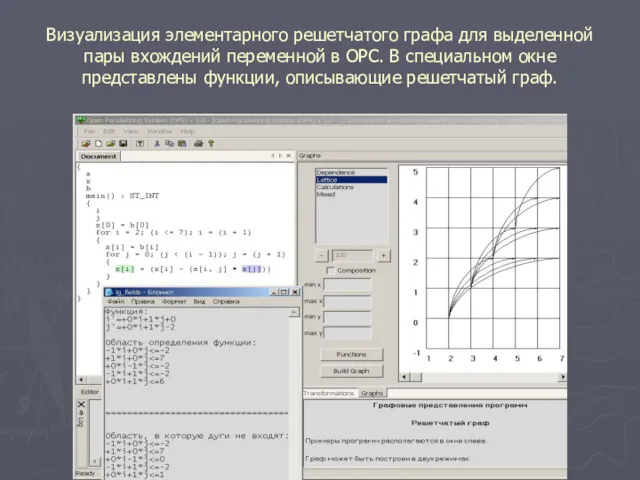
Визуализация элементарного решетчатого графа для выделенной пары вхождений переменной в ОРС.
Визуализация элементарного решетчатого графа для выделенной пары вхождений переменной в ОРС.
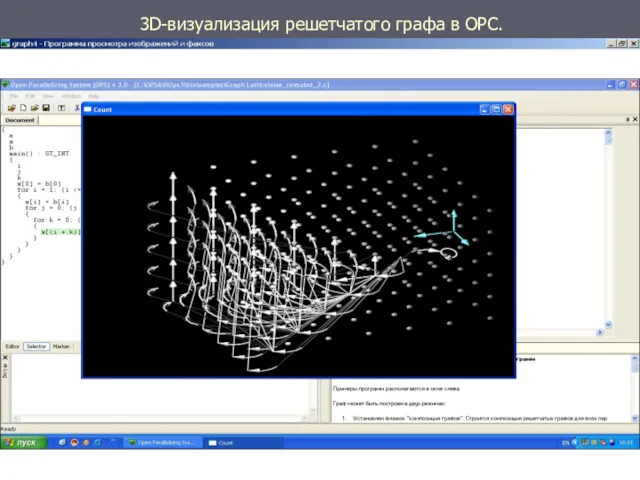
3D-визуализация решетчатого графа в ОРС.
3D-визуализация решетчатого графа в ОРС.

Открытая распараллеливающая система. Исследования.
Автоматические оценки погрешностей
Распараллеливание рекуррентных циклов
Максимальное разбиение программных циклов
Подстановка
Открытая распараллеливающая система. Исследования.
Автоматические оценки погрешностей
Распараллеливание рекуррентных циклов
Максимальное разбиение программных циклов
Подстановка

 Влияние интернета на подростка и формирование его личности
Влияние интернета на подростка и формирование его личности Internet advertising
Internet advertising Қауіпсіздік ережесі
Қауіпсіздік ережесі Классические архитектуры ИС. Лекция 10
Классические архитектуры ИС. Лекция 10 Разновидности объектов и их классификация
Разновидности объектов и их классификация Обработка информации
Обработка информации Алфавитный подход к определению количества информации
Алфавитный подход к определению количества информации Алгоритмы. Теория алгоритмов
Алгоритмы. Теория алгоритмов Типология современных радиостанций
Типология современных радиостанций Электронные образовательные ресурсы нового поколения
Электронные образовательные ресурсы нового поколения Модуль для 1с-Битрикс. Руководство и настройка
Модуль для 1с-Битрикс. Руководство и настройка Принципы построения компьютеров. Архитектура компьютера
Принципы построения компьютеров. Архитектура компьютера Машины Тьюринга
Машины Тьюринга Управление памятью
Управление памятью Использование электронной доски для развития творческих способностей учащихся начальной школы. Часть 2.
Использование электронной доски для развития творческих способностей учащихся начальной школы. Часть 2. Предыстория информатики
Предыстория информатики Введение в цикл разработки ПО
Введение в цикл разработки ПО Высказывания. Истинные и ложные высказывания. Логические структуры если- то- иначе
Высказывания. Истинные и ложные высказывания. Логические структуры если- то- иначе Установка СУФД-портала
Установка СУФД-портала Формы представления информации
Формы представления информации Компьютерные сети и телекоммуникации. Модель OSI
Компьютерные сети и телекоммуникации. Модель OSI Программирование (C++)
Программирование (C++) Курс веб-разработка. Редактируемая главная страница
Курс веб-разработка. Редактируемая главная страница Онлайн мошенничество
Онлайн мошенничество Робота у локальній мережі
Робота у локальній мережі Памятка пользователя для интернет-сервися
Памятка пользователя для интернет-сервися Монетизация
Монетизация Количественные методы исследований (SPSS) DATA ANALYSIS
Количественные методы исследований (SPSS) DATA ANALYSIS