- Проектирование Баз Данных. Основные понятия Теории Нормализации

Содержание
- 3. Основные понятия теории нормализации Нормализация отношений - это формализованный пошаговый процесс построения оптимальной структуры таблиц и
- 4. Основные свойства нормальных форм: каждая следующая нормальная форма (НФ) в некотором смысле лучше предыдущей; при переходе
- 5. Первая нормальная форма (1НФ) Первая нормальная форма требует, чтобы домены всех атрибутов базы данных содержали только
- 6. Первая нормальная форма (1НФ) Пример1 . Дано отношение КНИГИ: ID – первичный ключ ВТ – вычислительная
- 7. Основные понятия теории нормализации Следствия несовершенной структуры отношения: Отношение находится в 1НФ (1NF), если все его
- 8. Первая нормальная форма (1НФ) Отношение КНИГИ в 1НФ:
- 9. Прежде чем переходить к рассмотрению 2НФ, необходимо рассмотреть понятия функциональных зависимостей, которые есть в теории нормализации.
- 10. Определение 1. Функциональная зависимость (FD) (зависимость между атрибутами отношения) Основные понятия теории нормализации
- 11. или Пусть R (A1, A2,…, An) – схема отношения, а X и Y – произвольные подмножества
- 12. Набор атрибутов К называется суперключом отношения R, если все атрибуты R функционально зависят от К. Набор
- 13. Определение 3. Взаимно независимые атрибуты Атрибуты называются взаимно независимыми, если ни один из них не является
- 14. Определение 6. Транзитивная функциональная зависимость Функциональная зависимость X → Y называется транзитивной, если существует такой атрибут
- 15. Вторая нормальная форма (2НФ) Отношение R (A1, A2 ..., An) находится во 2НФ, если оно находится
- 16. Третья нормальная форма (3НФ) Отношение находится в 3НФ, если оно находится во 2НФ, и каждый неключевой
- 17. Нормальная форма Бойса-Кодда (BCNF) Определение. Детерминант ФЗ - минимальная группа атрибутов, от которой зависит некоторый другой
- 18. Нормальная форма Бойса-Кодда (BCNF) Приведение к НФБК. Если имеются отношения, содержащие несколько потенциальных ключей, то необходимо
- 19. Многозначные зависимости Многозначная зависимость (MDV) подразумевает, что два атрибута (или два множества атрибутов) независимы друг от
- 20. Многозначные зависимости Многозначность присутствует в тех отношениях, где моделируются связи типа 1:М. Определение. В отношении R(X,Y,Z)
- 21. Многозначные зависимости Следствие. Наличие многозначной зависимости X→→Y означает, что если 2 кортежа совпадают в части X,
- 23. Четвертая нормальная форма (4NF)
- 24. Многозначные зависимости Дальнейшая нормализация отношений основывается на теореме Фейджина: Отношение R (X, Y, Z) можно спроецировать
- 25. Четвертая нормальная форма (4NF) Определение. Отношение находится в 4НФ, если оно находится в 3НФ, и в
- 26. Соотношение между НФБК и многозначной зависимостью: Всякая функциональная зависимость есть частный случай многозначной зависимости; Поэтому, если
- 27. Полное множество функциональных зависимостей Заданное множество ФЗ для отношения R обозначается F. Полное множество функциональных зависимостей,
- 28. АКСИОМЫ АРМСТРОНГА Аксиома рефлексивности. Если Y входит в X, а X входит в U (Y⊆X⊆U), то
- 29. ПРАВИЛА ВЫВОДА ФЗ Правило самоопределения. X → Х Правило объединения. Если X → Y и X
- 30. Пятая нормальная форма (5NF) Зависимость соединения *(X,Y,...,Z) называется тривиальной, если выполняется одно из условий: Либо все
- 31. Пятая нормальная форма (5NF) Зависимость соединения является обобщением как многозначной, так и функциональной зависимости. Отношение находится
- 32. ВЫВОДЫ: Декомпозиция – это разделение отношения на две или более таблицы с целью устранения аномалий: Аномалия
- 33. Выводы: Нормализация устраняет следующие типы функциональных зависимостей: 2НФ — частичные зависимости неключевых атрибутов от ключевых; ЗНФ
- 34. Основные правила процедуры нормализации, применяемые к данным в информационной системе 1. Отношение в 1НФ следует разбить
- 35. Основные правила процедуры нормализации, применяемые к данным в информационной системе 4. Отношения в НФБК следует разбить
- 36. Проектирование баз данных на основе нормальных форм Пример. Имеется схема отношения: СТУДЕНТ (№_зачетки, Фамилия, Группа, Факультет,
- 37. На данный промежуток времени справедливы следующие функциональные зависимости: F1 = №_зачетки → Фамилия, Группа, Факультет F2
- 38. Многомерные базы данных
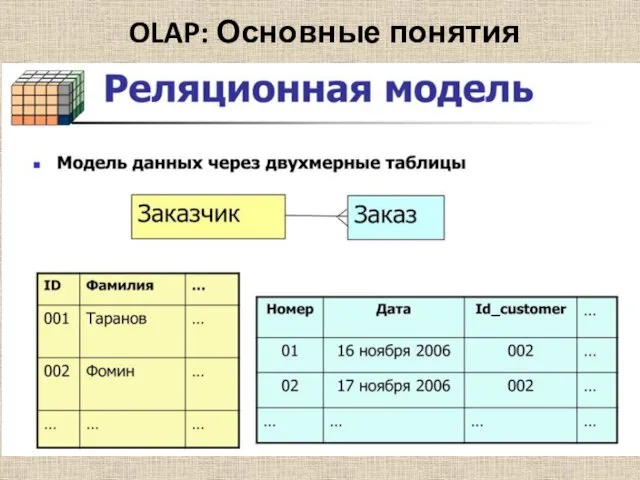
- 39. OLAP: Основные понятия Термин OLAP – (On-Line Analytical Processing - обработка данных в реальном времени) был
- 40. OLAP: Основные понятия
- 41. OLAP: Основные понятия
- 42. Проблемы анализа накопленной информации: В большой системе могут быть сотни связанных между собой сложными цепочками отношений
- 43. Многомерные базы. Хранилища данных.
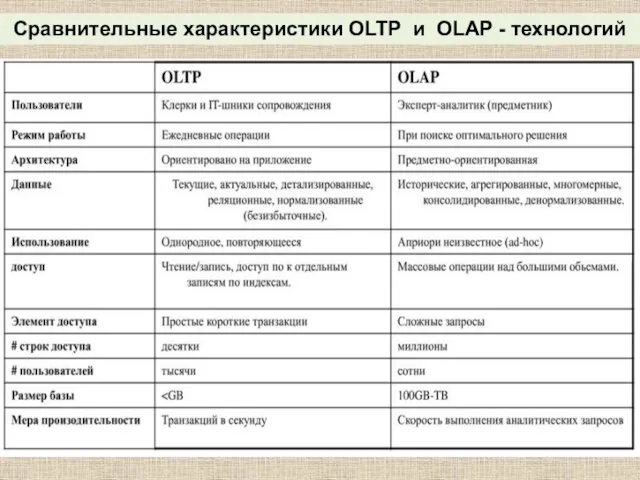
- 44. Сравнительные характеристики OLTP и OLAP - технологий
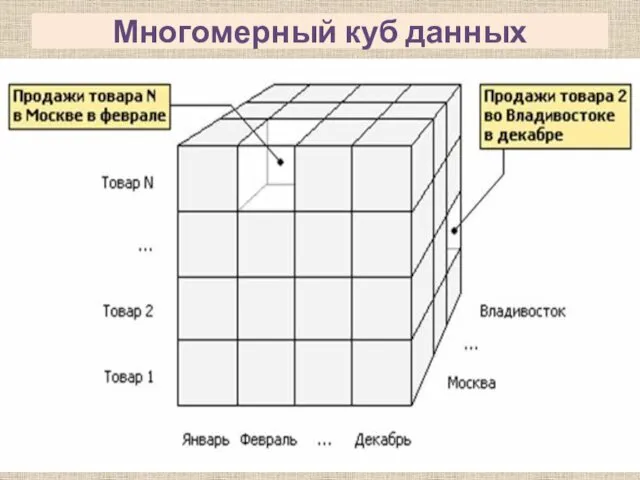
- 46. Многомерная модель данных Основной идеей является представление информации в виде многомерных кубов, где оси представляют собой
- 47. Многомерный куб данных
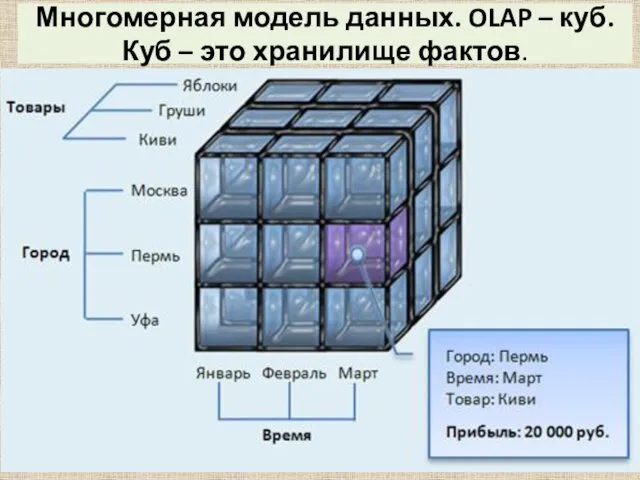
- 48. Многомерная модель данных. OLAP – куб. Куб – это хранилище фактов.
- 49. Из OLAP-куба может быть составлен обычный плоский отчёт. По столбцам и строкам отчёта будут бизнес-категории (грани
- 50. OLAP-кубы содержат бизнес-показатели, используемые для анализа и принятия управленческих решений, например: прибыль, рентабельность продукции, совокупные средства
- 53. OLAP: Основные понятия
- 58. Пример.Трехмерное представление данных о продажах
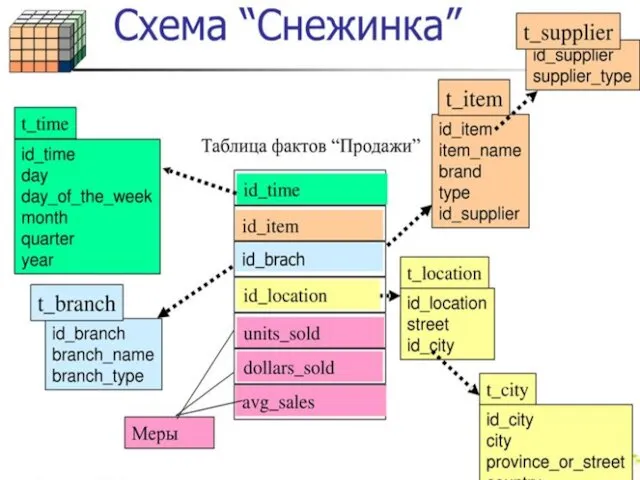
- 59. Схема «звезда» для хранилища данных
- 62. Витрины данных - это небольшие хранилища с упрощен-ной архитектурой, предназначен-ные для хранения небольшого подмножества данных и
- 65. Скачать презентацию


Основные понятия теории нормализации
Нормализация отношений - это формализованный пошаговый процесс
Основные понятия теории нормализации
Нормализация отношений - это формализованный пошаговый процесс

Основные свойства нормальных форм:
каждая следующая нормальная форма (НФ) в некотором
Основные свойства нормальных форм:
каждая следующая нормальная форма (НФ) в некотором

Первая нормальная форма (1НФ)
Первая нормальная форма требует, чтобы домены всех атрибутов
Первая нормальная форма (1НФ)
Первая нормальная форма требует, чтобы домены всех атрибутов
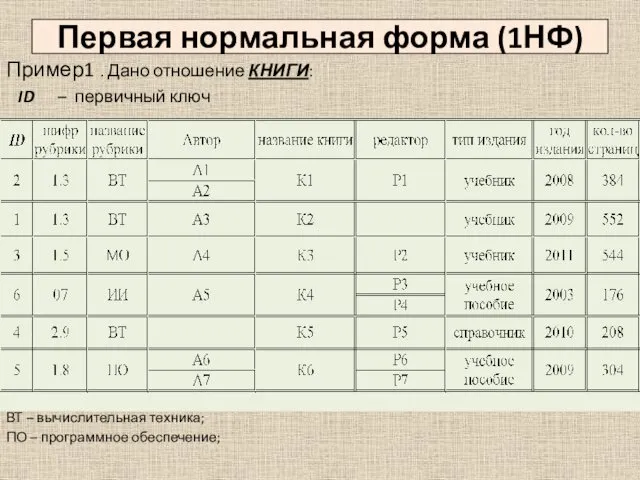
Первая нормальная форма (1НФ)
Пример1 . Дано отношение КНИГИ:
ID – первичный
Первая нормальная форма (1НФ)
Пример1 . Дано отношение КНИГИ:
ID – первичный

Основные понятия теории нормализации
Следствия несовершенной структуры отношения:
Отношение находится в 1НФ
Основные понятия теории нормализации
Следствия несовершенной структуры отношения:
Отношение находится в 1НФ
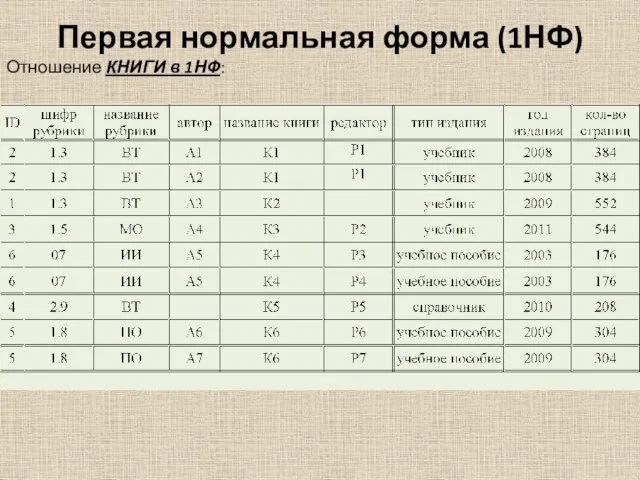
Первая нормальная форма (1НФ)
Отношение КНИГИ в 1НФ:
Первая нормальная форма (1НФ)
Отношение КНИГИ в 1НФ:

Прежде чем переходить к рассмотрению 2НФ, необходимо рассмотреть понятия функциональных зависимостей,
Прежде чем переходить к рассмотрению 2НФ, необходимо рассмотреть понятия функциональных зависимостей,

Определение 1. Функциональная зависимость (FD) (зависимость между атрибутами отношения)
Основные понятия теории
Определение 1. Функциональная зависимость (FD) (зависимость между атрибутами отношения)
Основные понятия теории

или
Пусть R (A1, A2,…, An) – схема отношения, а X и
или
Пусть R (A1, A2,…, An) – схема отношения, а X и

Набор атрибутов К называется суперключом отношения R, если все атрибуты R

Определение 3. Взаимно независимые атрибуты
Атрибуты называются взаимно независимыми, если ни
Определение 3. Взаимно независимые атрибуты
Атрибуты называются взаимно независимыми, если ни

Определение 6.
Транзитивная функциональная зависимость
Функциональная зависимость X → Y называется транзитивной,
Определение 6.
Транзитивная функциональная зависимость
Функциональная зависимость X → Y называется транзитивной,

Вторая нормальная форма (2НФ)
Отношение R (A1, A2 ..., An) находится во
Вторая нормальная форма (2НФ)
Отношение R (A1, A2 ..., An) находится во

Третья нормальная форма (3НФ)
Отношение находится в 3НФ, если оно находится во
Третья нормальная форма (3НФ)
Отношение находится в 3НФ, если оно находится во

Нормальная форма Бойса-Кодда (BCNF)
Определение.
Детерминант ФЗ - минимальная группа атрибутов, от
Нормальная форма Бойса-Кодда (BCNF)
Определение.
Детерминант ФЗ - минимальная группа атрибутов, от

Нормальная форма Бойса-Кодда (BCNF)
Приведение к НФБК.
Если имеются отношения, содержащие несколько
Нормальная форма Бойса-Кодда (BCNF)
Приведение к НФБК.
Если имеются отношения, содержащие несколько

Многозначные зависимости
Многозначная зависимость (MDV) подразумевает, что два атрибута (или два множества
Многозначные зависимости
Многозначная зависимость (MDV) подразумевает, что два атрибута (или два множества

Многозначные зависимости
Многозначность присутствует в тех отношениях, где моделируются связи типа 1:М.
Многозначные зависимости
Многозначность присутствует в тех отношениях, где моделируются связи типа 1:М.

Многозначные зависимости
Следствие.
Наличие многозначной зависимости X→→Y означает, что если 2 кортежа
Многозначные зависимости
Следствие.
Наличие многозначной зависимости X→→Y означает, что если 2 кортежа


Четвертая нормальная форма (4NF)
Четвертая нормальная форма (4NF)

Многозначные зависимости
Дальнейшая нормализация отношений основывается на теореме Фейджина:
Отношение R (X, Y,
Многозначные зависимости
Дальнейшая нормализация отношений основывается на теореме Фейджина:
Отношение R (X, Y,

Четвертая нормальная форма (4NF)
Определение. Отношение находится в 4НФ, если оно находится
Четвертая нормальная форма (4NF)
Определение. Отношение находится в 4НФ, если оно находится

Соотношение между НФБК и многозначной зависимостью:
Всякая функциональная зависимость есть частный
Соотношение между НФБК и многозначной зависимостью:
Всякая функциональная зависимость есть частный

Полное множество
функциональных зависимостей
Заданное множество ФЗ для отношения R обозначается F.
Полное
Полное множество
функциональных зависимостей
Заданное множество ФЗ для отношения R обозначается F.
Полное

АКСИОМЫ АРМСТРОНГА
Аксиома рефлексивности.
Если Y входит в X, а X входит
АКСИОМЫ АРМСТРОНГА
Аксиома рефлексивности.
Если Y входит в X, а X входит

ПРАВИЛА ВЫВОДА ФЗ
Правило самоопределения. X → Х
Правило объединения.
Если X →
ПРАВИЛА ВЫВОДА ФЗ
Правило самоопределения. X → Х
Правило объединения.
Если X →

Пятая нормальная форма (5NF)
Зависимость соединения *(X,Y,...,Z) называется тривиальной, если выполняется одно
Пятая нормальная форма (5NF)
Зависимость соединения *(X,Y,...,Z) называется тривиальной, если выполняется одно

Пятая нормальная форма (5NF)
Зависимость соединения является обобщением как многозначной, так и
Пятая нормальная форма (5NF)
Зависимость соединения является обобщением как многозначной, так и

ВЫВОДЫ:
Декомпозиция – это разделение отношения на две или более таблицы с
ВЫВОДЫ:
Декомпозиция – это разделение отношения на две или более таблицы с

Выводы: Нормализация устраняет следующие типы функциональных зависимостей:
2НФ — частичные зависимости неключевых
Выводы: Нормализация устраняет следующие типы функциональных зависимостей:
2НФ — частичные зависимости неключевых

Основные правила процедуры нормализации, применяемые к данным в информационной системе
1. Отношение
Основные правила процедуры нормализации, применяемые к данным в информационной системе
1. Отношение

Основные правила процедуры нормализации, применяемые к данным в информационной системе
4. Отношения
Основные правила процедуры нормализации, применяемые к данным в информационной системе
4. Отношения

Проектирование баз данных
на основе нормальных форм
Пример.
Имеется схема отношения:
СТУДЕНТ (№_зачетки, Фамилия,
Проектирование баз данных
на основе нормальных форм
Пример.
Имеется схема отношения:
СТУДЕНТ (№_зачетки, Фамилия,
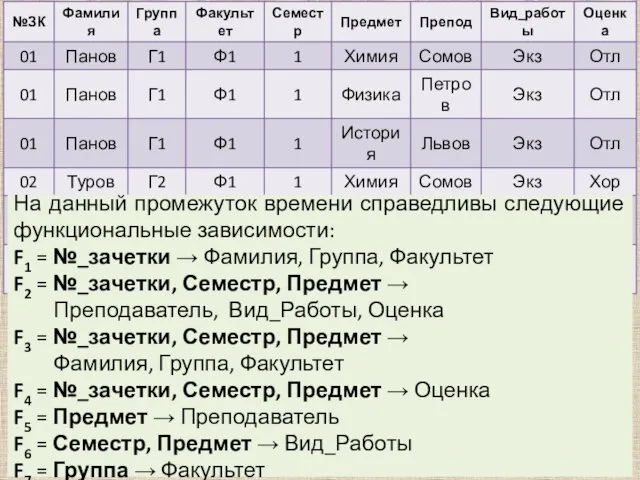
На данный промежуток времени справедливы следующие функциональные зависимости:
F1 = №_зачетки →
На данный промежуток времени справедливы следующие функциональные зависимости:
F1 = №_зачетки →
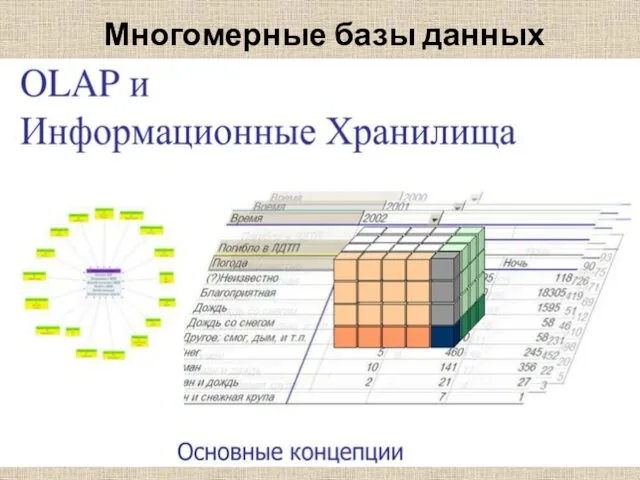
Многомерные базы данных
Многомерные базы данных

OLAP: Основные понятия
Термин OLAP – (On-Line Analytical Processing - обработка данных
OLAP: Основные понятия
Термин OLAP – (On-Line Analytical Processing - обработка данных
OLAP: Основные понятия
OLAP: Основные понятия

OLAP: Основные понятия
OLAP: Основные понятия

Проблемы анализа накопленной информации:
В большой системе могут быть сотни связанных между
Проблемы анализа накопленной информации:
В большой системе могут быть сотни связанных между

Многомерные базы. Хранилища данных.
Многомерные базы. Хранилища данных.
Сравнительные характеристики OLTP и OLAP - технологий
Сравнительные характеристики OLTP и OLAP - технологий


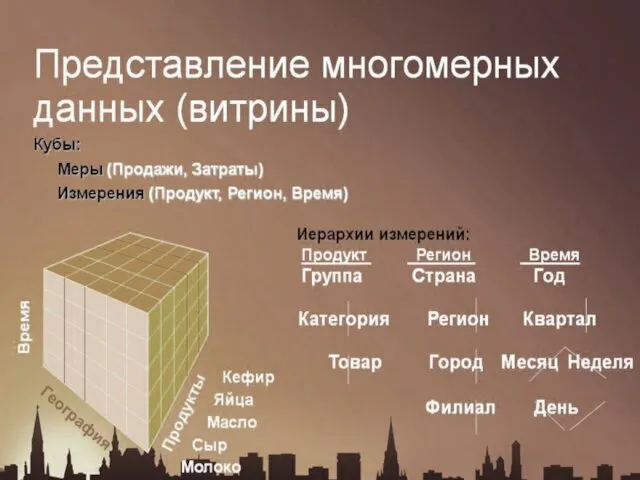
Многомерная модель данных
Основной идеей является представление информации в виде многомерных кубов,
Многомерная модель данных
Основной идеей является представление информации в виде многомерных кубов,
Многомерный куб данных
Многомерный куб данных
Многомерная модель данных. OLAP – куб.
Куб – это хранилище фактов.
Многомерная модель данных. OLAP – куб.
Куб – это хранилище фактов.
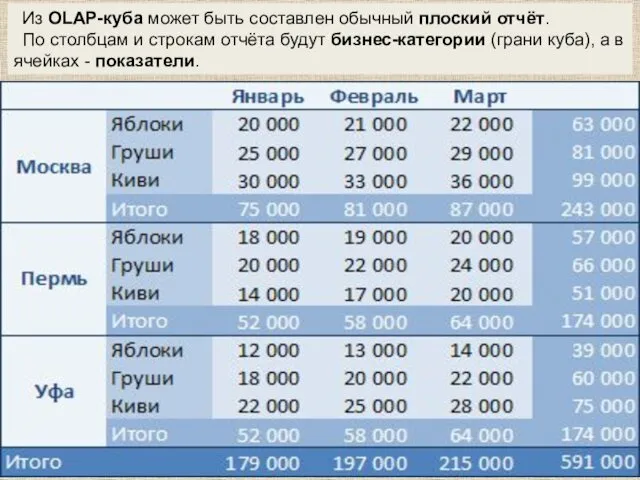
Из OLAP-куба может быть составлен обычный плоский отчёт.
По столбцам и
Из OLAP-куба может быть составлен обычный плоский отчёт.
По столбцам и

OLAP-кубы содержат бизнес-показатели, используемые для анализа и принятия управленческих решений, например:
OLAP-кубы содержат бизнес-показатели, используемые для анализа и принятия управленческих решений, например:

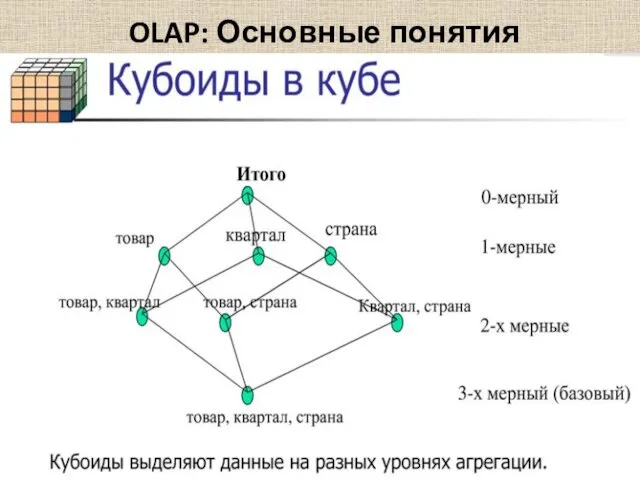
OLAP: Основные понятия
OLAP: Основные понятия


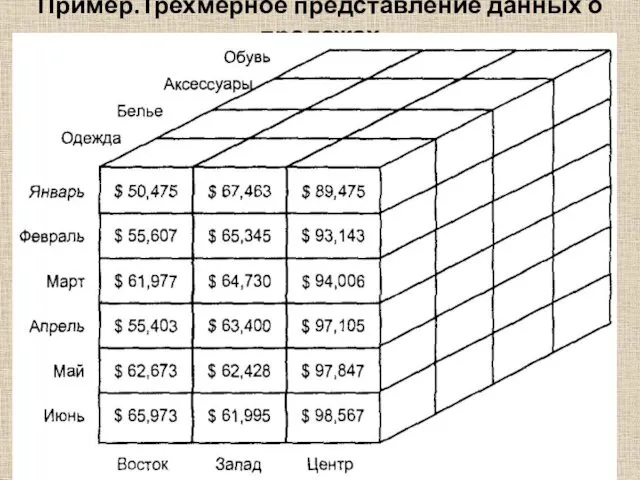
Пример.Трехмерное представление данных о продажах
Пример.Трехмерное представление данных о продажах
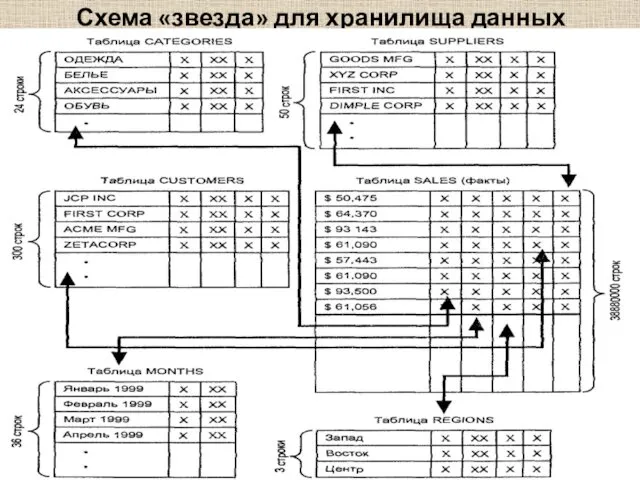
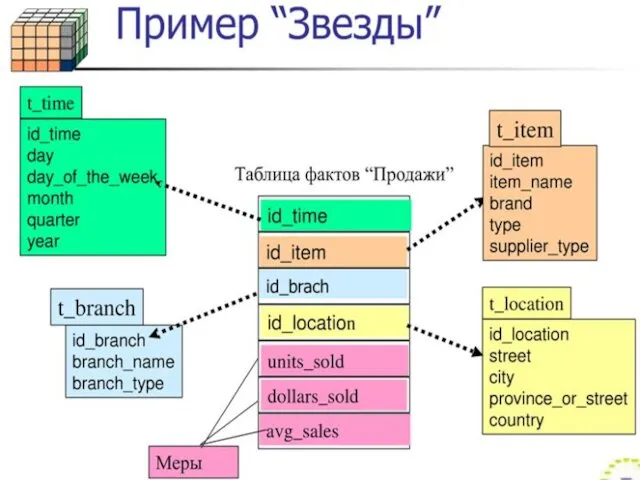
Схема «звезда» для хранилища данных
Схема «звезда» для хранилища данных

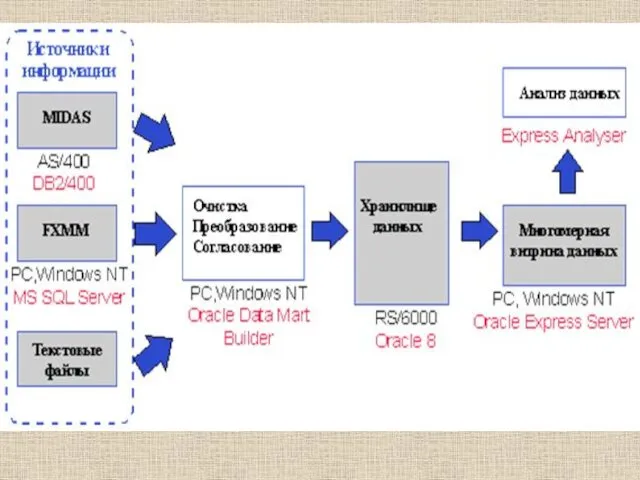

Витрины данных - это небольшие хранилища с упрощен-ной архитектурой, предназначен-ные для
Витрины данных - это небольшие хранилища с упрощен-ной архитектурой, предназначен-ные для

 Пресс-службы в органах власти
Пресс-службы в органах власти Computer club. Бизнес-проект
Computer club. Бизнес-проект Сотовые и спутниковые системы
Сотовые и спутниковые системы Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Проектирование баз данных
Проектирование баз данных Публицистический стиль. Основные признаки. Подстили и жанры. Языковые особенности
Публицистический стиль. Основные признаки. Подстили и жанры. Языковые особенности Технология Drag and Drop
Технология Drag and Drop Своя игра по информатике
Своя игра по информатике Презентация Инновационные подходы в образовании
Презентация Инновационные подходы в образовании Warcraft III
Warcraft III The method of software upgrade for tablet PC B902
The method of software upgrade for tablet PC B902 Электронные услуги в сфере образования
Электронные услуги в сфере образования Введение в цикл разработки ПО
Введение в цикл разработки ПО Общие свойства объектов одного класса. Информатика, 3 класс, 1 часть
Общие свойства объектов одного класса. Информатика, 3 класс, 1 часть Алгоритмы и исполнители
Алгоритмы и исполнители Сети и системы телекоммуникаций. Транспортный уровень
Сети и системы телекоммуникаций. Транспортный уровень Вирусы и антивирусы
Вирусы и антивирусы Гуманитарные образовательные технологии как отражение инновационных процессов в образовании
Гуманитарные образовательные технологии как отражение инновационных процессов в образовании Понятие. Понятие личности
Понятие. Понятие личности Теория автоматов и формальных языков
Теория автоматов и формальных языков Циклические структуры
Циклические структуры ФГИС ЕГРН. Общая информация
ФГИС ЕГРН. Общая информация Система стандартов по информации, библиотечному и издательскому делу. Организационно-распорядительная документация
Система стандартов по информации, библиотечному и издательскому делу. Организационно-распорядительная документация Язык HTML — язык тегов
Язык HTML — язык тегов Международная журналистика
Международная журналистика Алгоритмы на графах
Алгоритмы на графах Самостоятельная работа по информатике 6 класс. классификации
Самостоятельная работа по информатике 6 класс. классификации Программирование на языке Си#. Форма. Лекция 40
Программирование на языке Си#. Форма. Лекция 40