- Работа в СУБД PostgreSQL

Содержание
- 2. Поддержка логической модели данных (определение данных, оперирование данными) Восстановление данных (транзакции, журнализация, контрольные точки) Управление одновременным
- 3. СУБД Oracle MS SQL Server SyBase MySQL MS Access PostgreSQL Firebird ...
- 4. Состав СУБД СУБД состоит из ядра, находящегося в памяти сервера неограниченного количества программ клиентов, выполняющих поставленные
- 5. О PostgreSQL Работа над проектом началась в 1985 году, и до 1988 года был опубликован ряд
- 6. Немного истории К 1996 году стало ясно, что название Postgres95 не выдержит испытание временем, и было
- 7. Немного истории В 2015 году Олег Бартунов, астроном и научный сотрудник ГАИШ МГУ, вместе с Федором
- 8. Немного истории Цикл работы над очередной версией PostgreSQL обычно занимает около года За это время от
- 9. Характеристики СУБД PostgreSQL
- 10. Характеристики СУБД PostgreSQL
- 11. Характеристики СУБД PostgreSQL
- 12. Возможности разработчика
- 13. Стандарт SQL/MED SQL/MED, или Management of External Data (управление внешними данными) — расширение стандарта SQL, закреплённое
- 14. SQL стал результатом исследовательского проекта компании IBM, проект включал создание реляционной системы базы данных и языка
- 15. История языка SQL Начало 1970-х г. – IBM разрабатывает 1-ю версию языка, первая публикация 1974г. (SEQUEL)
- 16. Стандартизация SQL 1982 году Американский национальный институт стандартов (American National Standards Institute — ANSI) создал комитет
- 17. Стандартизация SQL
- 18. Возможности SQL определение, переопределение и удаление таблиц базы данных и других ее объектов (доменов, представлений, индексов,
- 19. Категории языка SQL DML (Data Manipulation Language) Работа с данными DDL (Data Definition Language) –работа с
- 20. DDL (Data Definition Language) Операторы DDL (Data Definition Language) - операторы определения объектов базы данных (CREATE
- 21. DML (Data Manipulation Language) Операторы DML (Data Manipulation Language) - операторы манипулирования данными (SELECT, INSERT, UPDATE,
- 22. TCL (Transaction Control Language) Операторы TCL (Transaction Control Language) - применяется для управления изменениями, защиты и
- 23. DCL (Data Control Language или Access Control Language) Операторы DCL (Data Control Language или Access Control
- 24. Клиент для PostgreSQL
- 25. Клиенты СУБД Консольный клиент psql Графические клиенты pgAdmin Dbeaver ? 8 лучших GUI клиентов PostgreSQL в
- 26. ПОДКЛЮЧЕНИЕ К БАЗЕ ДАННЫХ TEST
- 27. СОЗДАНИЕ БАЗЫ ДАННЫХ И ПОДКЛЮЧЕНИЕ К НЕЙ
- 28. Подключение к другой БД Не забудьте про точку с запятой в конце команды — пока PostgreSQL
- 29. СПЕЦИАЛЬНЫЕ КОМАНДЫ, КОТОРЫЕ ПОНИМАЕТ ТОЛЬКО PSQL Справочная информация довольна объемна, показывается с помощью настроенной в операционной
- 30. Полезные команды psql \h Справка по SQL: список доступных команд или синтаксис конкретной команды \x Переключает
- 31. ТАБЛИЦЫ В реляционных СУБД данные представляются в виде таблиц Заголовок таблицы определяет столбцы; собственно данные располагаются
- 32. Типы данных Для каждого столбца устанавливается тип данных и существует возможность создания новых типов данных Помимо
- 33. Числовые типы данных serial: представляет автоинкрементирующееся числовое значение, которое занимает 4 байта и может хранить числа
- 34. Числовые типы данных numeric: хранит числа с фиксированной точностью, которые могут иметь до 131072 знаков в
- 35. Типы для работы с валютой (денежными единицами) Для работы с денежными единицами определен тип money, который
- 36. Символьные типы character(n): представляет строку из фиксированного количества символов. С помощью параметра задается количество символов в
- 37. Бинарные данные Для хранения бинарных данных определен тип bytea. Он хранит данные в виде бинарных строк,
- 38. Типы для работы с датами и временем timestamp: хранит дату и время. Занимает 8 байт. Для
- 39. Логический тип Тип boolean может хранить одно из двух значений: true или false. Вместо true можно
- 40. Типы для представления интернет-адресов cidr: интернет-адрес в формате IPv4 и IPv6. Например, 192.168.0.1. Занимает от 7
- 41. Геометрические типы point: представляет точку на плоскости в формате (x,y). Занимает 16 байт. line: представляет линию
- 42. Другие типы данных json: хранит данные json в текстовом виде jsonb: хранит данные json в бинарном
- 43. Создание таблиц Точный синтаксис команды CREATE TABLE можно посмотреть в документации, а можно прямо в psql
- 44. Ввод данных Если вам требуется массовая загрузка данных из внешнего источника можно использовать предназначенную для этого
- 45. ДЗ Написать инструкции для создания таблиц, изменения структуры таблицы (из практического задания №1) Написать выборку с
- 47. Скачать презентацию

Поддержка логической модели данных (определение данных, оперирование данными)
Восстановление данных (транзакции, журнализация,
Поддержка логической модели данных (определение данных, оперирование данными)
Восстановление данных (транзакции, журнализация,

СУБД
Oracle
MS SQL Server
SyBase
MySQL
MS Access
PostgreSQL
Firebird
...
СУБД
Oracle
MS SQL Server
SyBase
MySQL
MS Access
PostgreSQL
Firebird
...

Состав СУБД
СУБД состоит из
ядра, находящегося в памяти
сервера
неограниченного количества программ клиентов,
Состав СУБД
СУБД состоит из
ядра, находящегося в памяти
сервера
неограниченного количества программ клиентов,

О PostgreSQL
Работа над проектом началась в 1985 году, и до 1988
О PostgreSQL
Работа над проектом началась в 1985 году, и до 1988
Немного истории
К 1996 году стало ясно, что название Postgres95 не выдержит
Немного истории
К 1996 году стало ясно, что название Postgres95 не выдержит
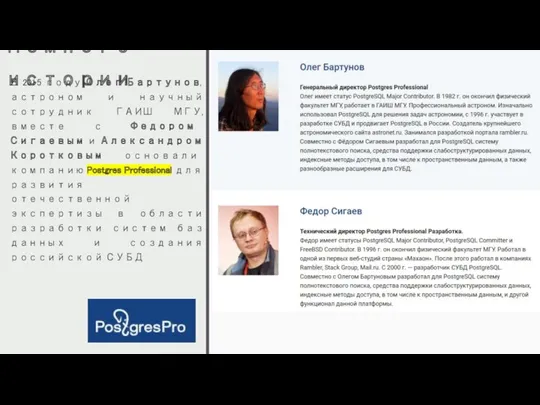
Немного истории
В 2015 году Олег Бартунов, астроном и научный сотрудник ГАИШ
Немного истории
В 2015 году Олег Бартунов, астроном и научный сотрудник ГАИШ

Немного истории
Цикл работы над очередной версией PostgreSQL обычно занимает около года
За
Немного истории
Цикл работы над очередной версией PostgreSQL обычно занимает около года
За

Характеристики СУБД PostgreSQL
Характеристики СУБД PostgreSQL

Характеристики СУБД PostgreSQL
Характеристики СУБД PostgreSQL

Характеристики СУБД PostgreSQL
Характеристики СУБД PostgreSQL

Возможности разработчика
Возможности разработчика

Стандарт SQL/MED
SQL/MED, или Management of External Data (управление внешними данными) — расширение
Стандарт SQL/MED
SQL/MED, или Management of External Data (управление внешними данными) — расширение

SQL стал результатом исследовательского проекта компании IBM, проект включал создание реляционной
SQL стал результатом исследовательского проекта компании IBM, проект включал создание реляционной

История языка SQL
Начало 1970-х г. – IBM разрабатывает 1-ю версию языка,
История языка SQL
Начало 1970-х г. – IBM разрабатывает 1-ю версию языка,

Стандартизация SQL
1982 году Американский национальный институт стандартов (American National Standards Institute
Стандартизация SQL
1982 году Американский национальный институт стандартов (American National Standards Institute

Стандартизация SQL
Стандартизация SQL

Возможности SQL
определение, переопределение и удаление таблиц базы данных и других ее
Возможности SQL
определение, переопределение и удаление таблиц базы данных и других ее

Категории языка SQL
DML (Data Manipulation Language) Работа с данными
DDL (Data Definition
Категории языка SQL
DML (Data Manipulation Language) Работа с данными
DDL (Data Definition

DDL
(Data Definition Language)
Операторы DDL (Data Definition Language) - операторы определения
DDL
(Data Definition Language)
Операторы DDL (Data Definition Language) - операторы определения

DML
(Data Manipulation Language)
Операторы DML (Data Manipulation Language) - операторы манипулирования
DML
(Data Manipulation Language)
Операторы DML (Data Manipulation Language) - операторы манипулирования

TCL (Transaction Control Language)
Операторы TCL (Transaction Control Language) - применяется для
TCL (Transaction Control Language)
Операторы TCL (Transaction Control Language) - применяется для

DCL
(Data Control Language или Access Control Language)
Операторы DCL (Data Control
DCL
(Data Control Language или Access Control Language)
Операторы DCL (Data Control

Клиент для PostgreSQL
Клиент для PostgreSQL
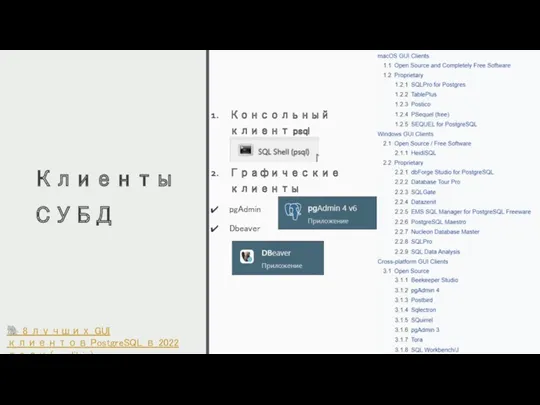
Клиенты СУБД
Консольный клиент psql
Графические клиенты
pgAdmin
Dbeaver
? 8 лучших GUI клиентов PostgreSQL
Клиенты СУБД
Консольный клиент psql
Графические клиенты
pgAdmin
Dbeaver
? 8 лучших GUI клиентов PostgreSQL
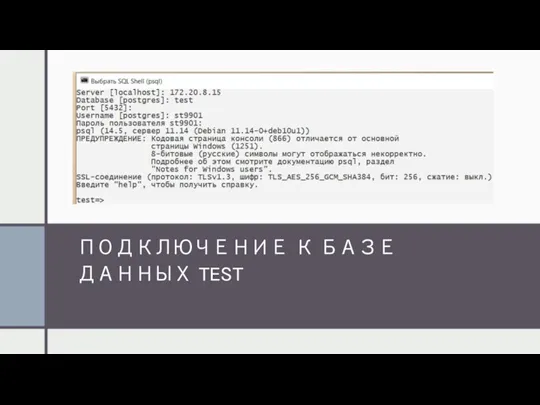
ПОДКЛЮЧЕНИЕ К БАЗЕ ДАННЫХ TEST
ПОДКЛЮЧЕНИЕ К БАЗЕ ДАННЫХ TEST

СОЗДАНИЕ БАЗЫ ДАННЫХ И ПОДКЛЮЧЕНИЕ К НЕЙ
СОЗДАНИЕ БАЗЫ ДАННЫХ И ПОДКЛЮЧЕНИЕ К НЕЙ

Подключение к другой БД
Не забудьте про точку с запятой в конце
Подключение к другой БД
Не забудьте про точку с запятой в конце

СПЕЦИАЛЬНЫЕ КОМАНДЫ, КОТОРЫЕ ПОНИМАЕТ ТОЛЬКО PSQL
Справочная информация довольна объемна, показывается
СПЕЦИАЛЬНЫЕ КОМАНДЫ, КОТОРЫЕ ПОНИМАЕТ ТОЛЬКО PSQL
Справочная информация довольна объемна, показывается

Полезные команды psql
\h Справка по SQL: список доступных команд или синтаксис
Полезные команды psql
\h Справка по SQL: список доступных команд или синтаксис
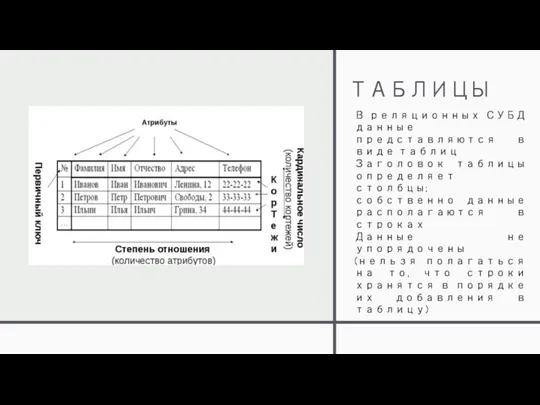
ТАБЛИЦЫ
В реляционных СУБД данные представляются в виде таблиц
Заголовок таблицы определяет столбцы;
ТАБЛИЦЫ
В реляционных СУБД данные представляются в виде таблиц
Заголовок таблицы определяет столбцы;

Типы данных
Для каждого столбца устанавливается тип данных и существует возможность создания
Типы данных
Для каждого столбца устанавливается тип данных и существует возможность создания

Числовые типы данных
serial: представляет автоинкрементирующееся числовое значение, которое занимает 4 байта
Числовые типы данных
serial: представляет автоинкрементирующееся числовое значение, которое занимает 4 байта

Числовые типы данных
numeric: хранит числа с фиксированной точностью, которые могут иметь
Числовые типы данных
numeric: хранит числа с фиксированной точностью, которые могут иметь

Типы для работы с валютой (денежными единицами)
Для работы с денежными единицами
Типы для работы с валютой (денежными единицами)
Для работы с денежными единицами

Символьные типы
character(n): представляет строку из фиксированного количества символов. С помощью параметра
Символьные типы
character(n): представляет строку из фиксированного количества символов. С помощью параметра

Бинарные данные
Для хранения бинарных данных определен тип bytea. Он хранит данные в
Бинарные данные
Для хранения бинарных данных определен тип bytea. Он хранит данные в

Типы для работы с датами и временем
timestamp: хранит дату и время.
Типы для работы с датами и временем
timestamp: хранит дату и время.

Логический тип
Тип boolean может хранить одно из двух значений: true или
Логический тип
Тип boolean может хранить одно из двух значений: true или

Типы для представления интернет-адресов
cidr: интернет-адрес в формате IPv4 и IPv6. Например,
Типы для представления интернет-адресов
cidr: интернет-адрес в формате IPv4 и IPv6. Например,

Геометрические типы
point: представляет точку на плоскости в формате (x,y). Занимает 16 байт.
line:
Геометрические типы
point: представляет точку на плоскости в формате (x,y). Занимает 16 байт.
line:

Другие типы данных
json: хранит данные json в текстовом виде
jsonb: хранит данные
Другие типы данных
json: хранит данные json в текстовом виде
jsonb: хранит данные

Создание таблиц
Точный синтаксис команды CREATE TABLE можно посмотреть в документации, а
Создание таблиц
Точный синтаксис команды CREATE TABLE можно посмотреть в документации, а
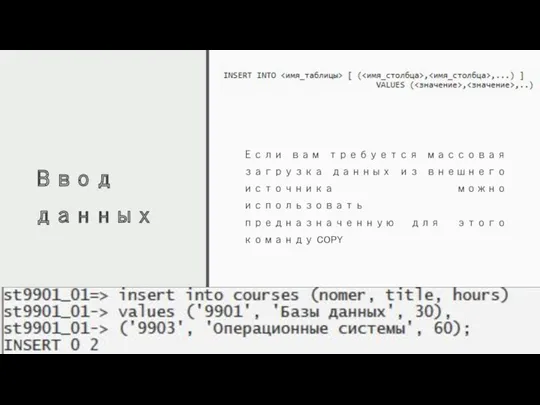
Ввод данных
Если вам требуется массовая загрузка данных из внешнего источника можно
Ввод данных
Если вам требуется массовая загрузка данных из внешнего источника можно

ДЗ
Написать инструкции для создания таблиц, изменения структуры таблицы (из практического задания
ДЗ
Написать инструкции для создания таблиц, изменения структуры таблицы (из практического задания
 Триггеры Oracle. СУБД. (Лекция 11)
Триггеры Oracle. СУБД. (Лекция 11) Информационная безопасность. Общие принципы. (Лекция 2)
Информационная безопасность. Общие принципы. (Лекция 2) Проектирование изделий из листового металла в NX
Проектирование изделий из листового металла в NX Кодирование как изменение формы представления информации
Кодирование как изменение формы представления информации Программирование на языке PL/SQL
Программирование на языке PL/SQL Связь математики и астрономии. Созвездия в координатах
Связь математики и астрономии. Созвездия в координатах Клієнт-серверна платформа на базі ARM процесору з використанням технології Ktor
Клієнт-серверна платформа на базі ARM процесору з використанням технології Ktor Методы, технология и инструменты программирования
Методы, технология и инструменты программирования Решение задач на компьютере. Алгоритмизация и программирование
Решение задач на компьютере. Алгоритмизация и программирование Двоичная система счисления
Двоичная система счисления Цифровая модель проактивного управления территорией (городом)
Цифровая модель проактивного управления территорией (городом) Компьютерные локальные сети и телекоммуникации связи
Компьютерные локальные сети и телекоммуникации связи Определение информационной безопасности. Классификация угроз безопасности. Лекция №1
Определение информационной безопасности. Классификация угроз безопасности. Лекция №1 Программирование на Python. Строки
Программирование на Python. Строки Професія в галузі інформаційних технологій
Професія в галузі інформаційних технологій Основы html/css
Основы html/css Робота з файлами. Текстові файли. Лекция 17
Робота з файлами. Текстові файли. Лекция 17 Этапы и стадии разработки информационных систем
Этапы и стадии разработки информационных систем PPM University Training Rules and Training Proces
PPM University Training Rules and Training Proces Технології програмування КС. Лекція 2 (частина 2)
Технології програмування КС. Лекція 2 (частина 2) Алгоритмы и исполнители
Алгоритмы и исполнители Удаленная работа с ПК
Удаленная работа с ПК Інформація та інформаційні процеси
Інформація та інформаційні процеси Архитектура персонального компьютера
Архитектура персонального компьютера Загальні відомості про електронну комерцію
Загальні відомості про електронну комерцію Разработка компьютерной игры в жанре RPG на платформе UNITY 3D
Разработка компьютерной игры в жанре RPG на платформе UNITY 3D Горячие клавиши
Горячие клавиши Електропостачання електровозної відкатки. Електровози
Електропостачання електровозної відкатки. Електровози