- Распределения итераций и дополнительные сведения о синхронизации. (Лекция 3)

Содержание
- 2. 1. Пример параллельно исполняемых итераций
- 3. 2. Распределение итераций по потокам
- 4. 3. Опция schedule( type [, chunk]) задаёт, каким образом итерации цикла распределяются между нитями: static –
- 5. 4. Опция schedule( type [, chunk]) - продолжение guided – динамическое распределение итераций, при котором размер
- 6. 5. Демонстрация влияния опции schedule на распределение итераций по потокам int main(int argc, char *argv[]) {
- 7. 6. Распределение итераций по потокам
- 8. 7. Результаты демонстрации влияния опции schedule на распределение итераций по потокам В ячейках таблицы указаны номера
- 9. 8. Задачи ( tasks ) Директива task применяется для выделения отдельной независимой задачи: #pragma omp task
- 10. 9. Опции директивы task private(список), firstprivate(список), shared(список); if(условие) — порождение новой задачи только при выполнении некоторого
- 11. 10. Директива ordered Директивы ordered определяют блок внутри тела цикла, который должен выполняться в том порядке,
- 12. 11. Директива ordered и опция ordered int main(int argc, char *argv[]) { int i, n; #pragma
- 13. 12. Синхронизация с использованием механизма замков (locks) В качестве замков используются общие целочисленные переменные (размер должен
- 14. 13. Инициализация замков Для инициализации простого или множественного замка используются соответственно функции : void omp_init_lock(omp_lock_t *lock);
- 15. 14. Захват замков Для захвата замков используются функции: void omp_set_lock(omp_lock_t *lock); void omp_set_nest_lock(omp_nest_lock_t *lock); Вызвавший эту
- 16. 15. Пример использования замков #include #include omp_lock_t lock; int main(int argc, char *argv[]) { int n;
- 17. 16. Неблокирующие попытки захвата Для неблокирующей попытки захвата замка используются функции: int omp_test_lock(omp_lock_t *lock); int omp_test_nest_lock(omp_lock_t
- 18. 17. Пример использования функции omp_test_lock() int main(int argc, char *argv[]) { omp_lock_t lock; int n; omp_init_lock(&lock);
- 19. 18. Директива flush Поскольку в современных параллельных вычислительных системах может использоваться сложная структура и иерархия памяти,
- 20. 19. Неявное применение директивы flush Неявно flush без параметров присутствует в директиве barrier , на входе
- 21. 20. Использование технологии OpenMP Если целевая вычислительная платформа является многопроцессорной и/или многоядерной, то для повышения быстродействия
- 22. 21. Синхронизация и ускорение OpenMP-программ 1. Наибольший ресурс параллелизма сосредоточен в циклах, поэтому наиболее распространенным способом
- 23. 22. Особенности использование технологии OpenMP 1. Взяв за основу последовательный код, пользователь шаг за шагом может
- 24. 23. Фрагмент программы вычисления числа Пи. //Для распараллеливания достаточно добавить в последовательную программу //всего две строчки.
- 25. 24. Программа перемножения матриц #include #include #define N 4096 double a[N][N], b[N][N], c[N][N]; int main() {
- 26. 25. Времена выполнения произведения матриц на узле суперкомпьютера СКИФ МГУ «ЧЕБЫШЁВ».
- 28. Скачать презентацию

1. Пример параллельно исполняемых итераций
1. Пример параллельно исполняемых итераций

2. Распределение итераций по потокам
2. Распределение итераций по потокам
![3. Опция schedule( type [, chunk]) задаёт, каким образом итерации](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/231261/slide-3.jpg)
3. Опция schedule( type [, chunk]) задаёт, каким образом итерации цикла
3. Опция schedule( type [, chunk]) задаёт, каким образом итерации цикла
![4. Опция schedule( type [, chunk]) - продолжение guided –](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/231261/slide-4.jpg)
4. Опция schedule( type [, chunk]) - продолжение
guided – динамическое
4. Опция schedule( type [, chunk]) - продолжение
guided – динамическое

5. Демонстрация влияния опции schedule на распределение итераций по потокам
int main(int
5. Демонстрация влияния опции schedule на распределение итераций по потокам
int main(int
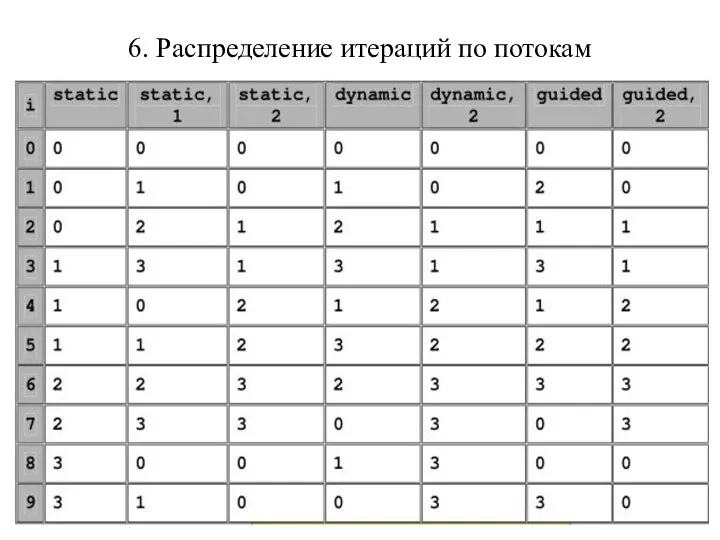
6. Распределение итераций по потокам
6. Распределение итераций по потокам

7. Результаты демонстрации влияния опции schedule на распределение итераций по потокам
7. Результаты демонстрации влияния опции schedule на распределение итераций по потокам

8. Задачи ( tasks )
Директива task применяется для выделения отдельной независимой
8. Задачи ( tasks )
Директива task применяется для выделения отдельной независимой

9. Опции директивы task
private(список), firstprivate(список), shared(список);
if(условие) — порождение новой задачи
9. Опции директивы task
private(список), firstprivate(список), shared(список);
if(условие) — порождение новой задачи

10. Директива ordered
Директивы ordered определяют блок внутри
тела цикла, который должен выполняться
10. Директива ordered
Директивы ordered определяют блок внутри
тела цикла, который должен выполняться

11. Директива ordered и опция ordered
int main(int argc, char *argv[])
{ int
11. Директива ordered и опция ordered
int main(int argc, char *argv[])
{ int

12. Синхронизация с использованием механизма
замков (locks)
В качестве замков используются общие
12. Синхронизация с использованием механизма
замков (locks)
В качестве замков используются общие

13. Инициализация замков
Для инициализации простого или множественного замка используются соответственно функции
13. Инициализация замков
Для инициализации простого или множественного замка используются соответственно функции

14. Захват замков
Для захвата замков используются функции:
void omp_set_lock(omp_lock_t *lock);
void
14. Захват замков
Для захвата замков используются функции:
void omp_set_lock(omp_lock_t *lock);
void

15. Пример использования замков
#include
#include
omp_lock_t lock;
int main(int argc, char *argv[])
{
15. Пример использования замков
#include
#include
omp_lock_t lock;
int main(int argc, char *argv[])
{

16. Неблокирующие попытки захвата
Для неблокирующей попытки захвата замка используются функции:
int omp_test_lock(omp_lock_t
16. Неблокирующие попытки захвата
Для неблокирующей попытки захвата замка используются функции:
int omp_test_lock(omp_lock_t
![17. Пример использования функции omp_test_lock() int main(int argc, char *argv[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/231261/slide-17.jpg)
17. Пример использования функции omp_test_lock()
int main(int argc, char *argv[])
{ omp_lock_t lock;
17. Пример использования функции omp_test_lock()
int main(int argc, char *argv[])
{ omp_lock_t lock;

18. Директива flush
Поскольку в современных параллельных вычислительных системах может использоваться сложная
18. Директива flush
Поскольку в современных параллельных вычислительных системах может использоваться сложная

19. Неявное применение директивы flush
Неявно flush без параметров присутствует в директиве
19. Неявное применение директивы flush
Неявно flush без параметров присутствует в директиве

20. Использование технологии OpenMP
Если целевая вычислительная платформа является многопроцессорной и/или многоядерной,
20. Использование технологии OpenMP
Если целевая вычислительная платформа является многопроцессорной и/или многоядерной,

21. Синхронизация и ускорение OpenMP-программ
1. Наибольший ресурс параллелизма сосредоточен в
21. Синхронизация и ускорение OpenMP-программ
1. Наибольший ресурс параллелизма сосредоточен в

22. Особенности использование технологии OpenMP
1. Взяв за основу последовательный код,
22. Особенности использование технологии OpenMP
1. Взяв за основу последовательный код,

23. Фрагмент программы вычисления числа Пи.
//Для распараллеливания достаточно добавить в
23. Фрагмент программы вычисления числа Пи.
//Для распараллеливания достаточно добавить в

24. Программа перемножения матриц
#include
#include
#define N 4096
double a[N][N], b[N][N],
24. Программа перемножения матриц
#include
#include
#define N 4096
double a[N][N], b[N][N],

25. Времена выполнения произведения матриц на узле
суперкомпьютера СКИФ МГУ «ЧЕБЫШЁВ».
25. Времена выполнения произведения матриц на узле
суперкомпьютера СКИФ МГУ «ЧЕБЫШЁВ».
 PostgreSQL. День 1. Курс PostgreSQL разработка (5 дней)
PostgreSQL. День 1. Курс PostgreSQL разработка (5 дней) FLEX Application Instructions Program Year 2018-2019
FLEX Application Instructions Program Year 2018-2019 Информационная безопасность. Для 5-9 классов
Информационная безопасность. Для 5-9 классов Автосервис
Автосервис АИС Параграф система Знак
АИС Параграф система Знак Компьютерные презентации. Анимация. 5 класс
Компьютерные презентации. Анимация. 5 класс CSRF. Danger. Detection. Defenses
CSRF. Danger. Detection. Defenses разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON
разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON Системное программное обеспечение ПК
Системное программное обеспечение ПК Алгоритми та методи обчислень. Tестування
Алгоритми та методи обчислень. Tестування Информационные технологии в управлении персоналом. Понятие информационной безопасности (лекция 4)
Информационные технологии в управлении персоналом. Понятие информационной безопасности (лекция 4) Текстовый процессор Microsoft Office Word
Текстовый процессор Microsoft Office Word Компьютеризированные системы регистрации и хранения данных в лаборатории -
Компьютеризированные системы регистрации и хранения данных в лаборатории - Научный корреспондент. Открытая публикация учебных и научных работ
Научный корреспондент. Открытая публикация учебных и научных работ Защита от вредоносных программ
Защита от вредоносных программ Программирование на Python. Работа с библиотеками Python. 22 занятие
Программирование на Python. Работа с библиотеками Python. 22 занятие Глобальная компьютерная сеть Интернет. Состав и Адресация
Глобальная компьютерная сеть Интернет. Состав и Адресация Путешествие в страну Инфознайка
Путешествие в страну Инфознайка Основные алгоритмические конструкции
Основные алгоритмические конструкции История развития информатики, ее роль и место в системе наук
История развития информатики, ее роль и место в системе наук Информация, ее свойства. Информация и управление
Информация, ее свойства. Информация и управление Виды и форматы графических файлов. Основы обработки графической информации. Системы компьютерной графики
Виды и форматы графических файлов. Основы обработки графической информации. Системы компьютерной графики Компоненты компьютерной сети
Компоненты компьютерной сети Научно-образовательные ресурсы рунета
Научно-образовательные ресурсы рунета Искусственный интеллект (урок 10)
Искусственный интеллект (урок 10)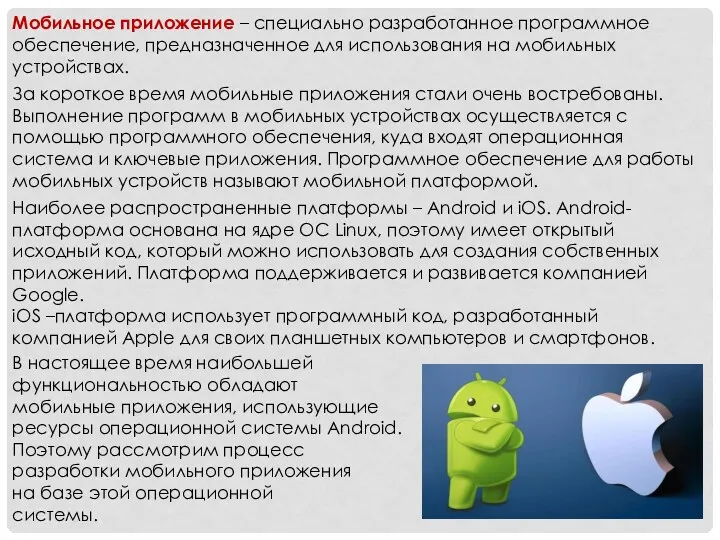 Мобильное приложение
Мобильное приложение Введение в информатику
Введение в информатику Форматирование абзацев. Стилевое форматирование. Microsoft Office Word. Обработка текстовой информации
Форматирование абзацев. Стилевое форматирование. Microsoft Office Word. Обработка текстовой информации