- Разработка параллельных программ для GPU. Введение в CUDA

Содержание
- 2. АППАРАТНЫЕ ОСОБЕННОСТИ GPU Краткий обзор архитектурных особенностей GPU
- 3. Основные тенденции Переход к многопроцессорным системам Развития технологий параллельного программирования OpenMP, MPI, TPL etc. Простота в
- 4. Классификация архитектур Виды параллелизма На уровне данных (Data) На уровне задач (Instruction) *GPU: SIMT – Single
- 5. Архитектура многоядерных CPU Кэш первого уровня для инструкций (L1-I) для данных (L1-D) Кэш второго уровня на
- 6. Архитектура GPU: Device
- 7. Архитектура GPU: TPC Кластер текстурных блоков (TPC) Память для текстур Потоковый мультипроцессор
- 8. Архитектура GPU: SM Память констант Память инструкций Регистровая память Разделяемая память 8 скалярных процессоров 2 суперфункциональных
- 9. Основные отличия GPU от CPU Высокая степень параллелизма (SIMT) Минимальные затраты на кэш-память Ограничения функциональности
- 10. РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU Развитие технологии неграфических вычислений
- 11. Эволюция GPU
- 12. GPGPU General-Purpose Computation on GPU Вычисления на GPU общего (неграфического) назначения AMD FireStream NVIDIA CUDA DirectCompute
- 13. ПРОГРАММНАЯ МОДЕЛЬ CUDA Основные понятия и определения CUDA
- 14. CUDA – Compute Unified Device Architecture Host – CPU (Central Processing Unit) Device – GPU (Graphics
- 15. Организация работы CUDA GPU
- 16. Warp и латентность Warp Порция потоков для выполнения на потоковом мультипроцессоре (SM) Латентность Общая задержка всех
- 17. Топология блоков (block) Возможна 1, 2 и 3-мерная топология Количество потоков в блоке ограничено (512)
- 18. Топология сетки блоков (grid) Возможна 1 и 2-мерная топология Количество блоков в каждом измерении ограничено 65536=216
- 19. Адресация элементов данных CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки blockIdx blockDim threadIdx 1D
- 20. Барьерная синхронизация Синхронизация потоков блока осуществляется встроенным оператором __synchronize
- 21. CUDA: РАСШИРЕНИЕ C++ Особенности написания программ для GPU CUDA
- 22. Расширение языка С++ Новые типы данных Спецификаторы для функций Спецификаторы для переменных Встроенные переменные (для ядра)
- 23. Процесс компиляции Файлы CUDA (GPU) *.cu Файлы CPU *.cpp, *.h Исполняемый модуль *.dll, *.exe nvcc VC90
- 24. Типы данных CUDA 1, 2, 3 и 4-мерные вектора базовых типов Целые: (u)char, (u)int, (u)short, (u)long,
- 25. Спецификаторы функций
- 26. Спецификаторы функций Ядро помечается __global__ Ядро не может возвращать значение Возможно совместное использование __host__ и __device__
- 27. Ограничения функций GPU Не поддерживается рекурсия Не поддерживаются static-переменные Нельзя брать адрес функции __device__ Не поддерживается
- 28. Спецификаторы переменных
- 29. Ограничения переменных GPU Переменные __shared__ не могут инициализироваться при объявлении Запись в __constant__ может производить только
- 30. Переменные ядра dim3 gridDim unit3 blockIdx dim3 blockDim uint3 threadIdx int warpSize
- 31. Директива запуска ядра Kernel >>(data) blocks – число блоков в сетке threads – число потоков в
- 32. Общая структура программы CUDA __global__ void Kernel(float* data) { . . . } void main() {
- 33. Предустановки Видеокарта NVIDIA с поддержкой CUDA Драйвера устройства с поддержкой CUDA NVIDIA CUDA Toolkit NVIDIA CUDA
- 34. Литература NVIDIA Developer Zone http://developer.nvidia.com/cuda NVIDAI CUDA – Неграфические вычисления на графических процессорах http://www.ixbt.com/video3/cuda-1.shtml Создание простого
- 36. Скачать презентацию

АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU
АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU

Основные тенденции
Переход к многопроцессорным системам
Развития технологий параллельного программирования
OpenMP, MPI, TPL etc.
Простота
Основные тенденции
Переход к многопроцессорным системам
Развития технологий параллельного программирования
OpenMP, MPI, TPL etc.
Простота

Классификация архитектур
Виды параллелизма
На уровне данных (Data)
На уровне задач (Instruction)
*GPU: SIMT –
Классификация архитектур
Виды параллелизма
На уровне данных (Data)
На уровне задач (Instruction)
*GPU: SIMT –
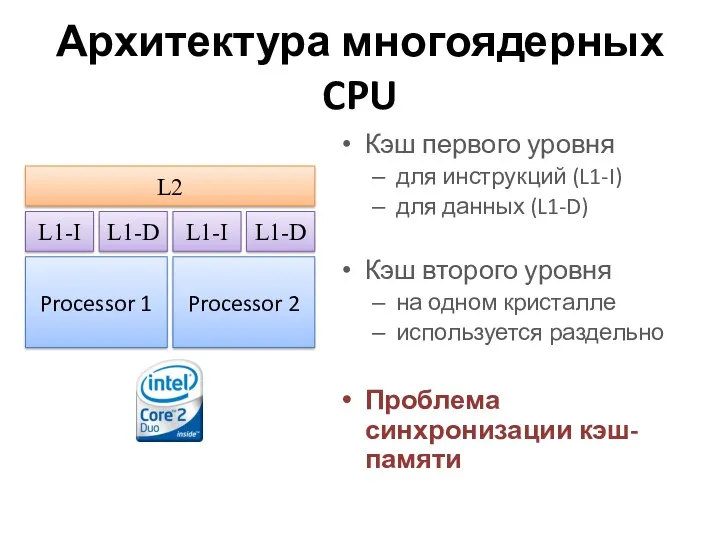
Архитектура многоядерных CPU
Кэш первого уровня
для инструкций (L1-I)
для данных (L1-D)
Кэш второго уровня
на
Архитектура многоядерных CPU
Кэш первого уровня
для инструкций (L1-I)
для данных (L1-D)
Кэш второго уровня
на
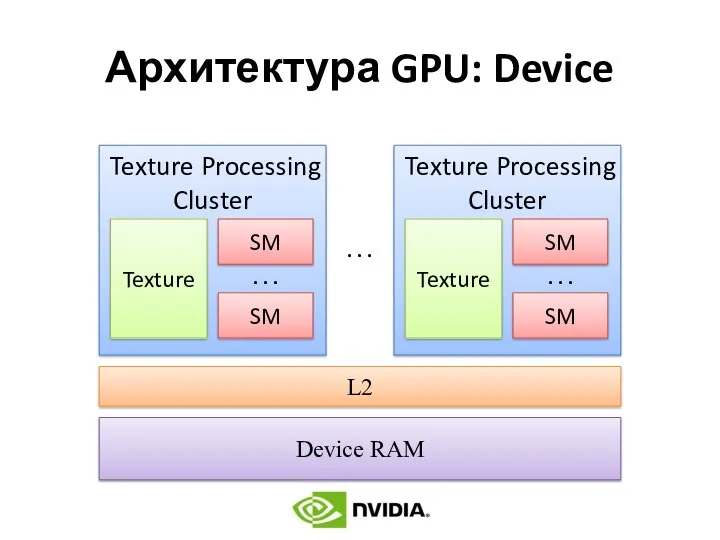
Архитектура GPU: Device
Архитектура GPU: Device
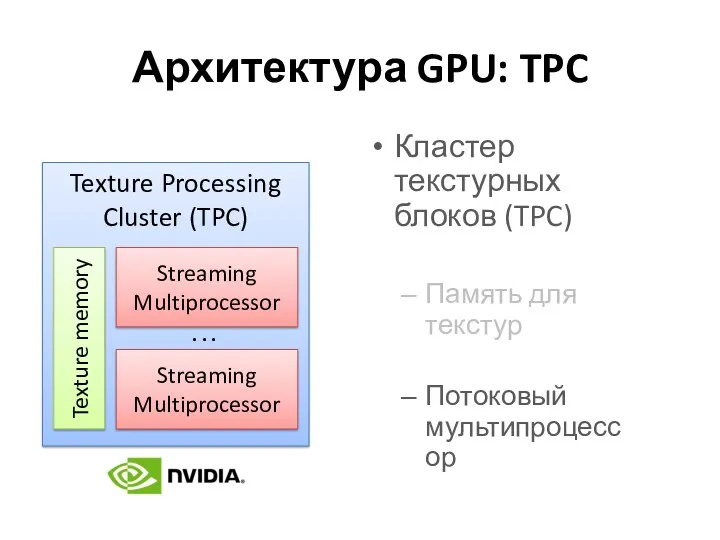
Архитектура GPU: TPC
Кластер текстурных блоков (TPC)
Память для текстур
Потоковый мультипроцессор
Архитектура GPU: TPC
Кластер текстурных блоков (TPC)
Память для текстур
Потоковый мультипроцессор
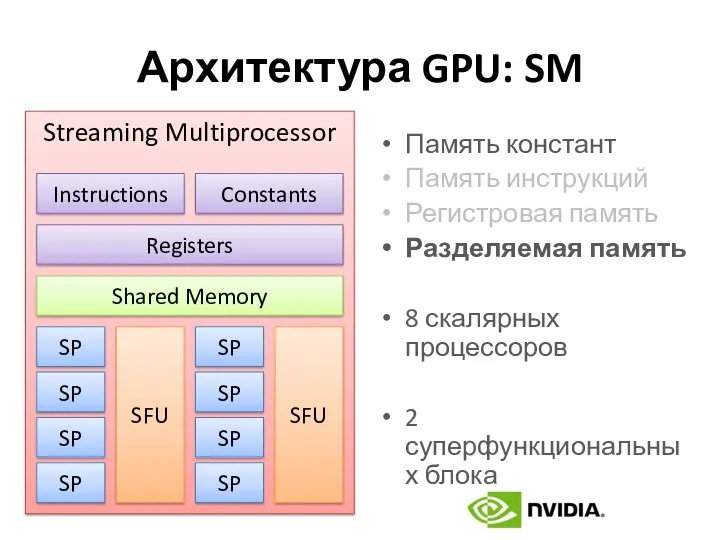
Архитектура GPU: SM
Память констант
Память инструкций
Регистровая память
Разделяемая память
8 скалярных процессоров
2 суперфункциональных блока
Архитектура GPU: SM
Память констант
Память инструкций
Регистровая память
Разделяемая память
8 скалярных процессоров
2 суперфункциональных блока

Основные отличия GPU от CPU
Высокая степень параллелизма (SIMT)
Минимальные затраты на кэш-память
Ограничения
Основные отличия GPU от CPU
Высокая степень параллелизма (SIMT)
Минимальные затраты на кэш-память
Ограничения

РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU
Развитие технологии неграфических вычислений
РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU
Развитие технологии неграфических вычислений
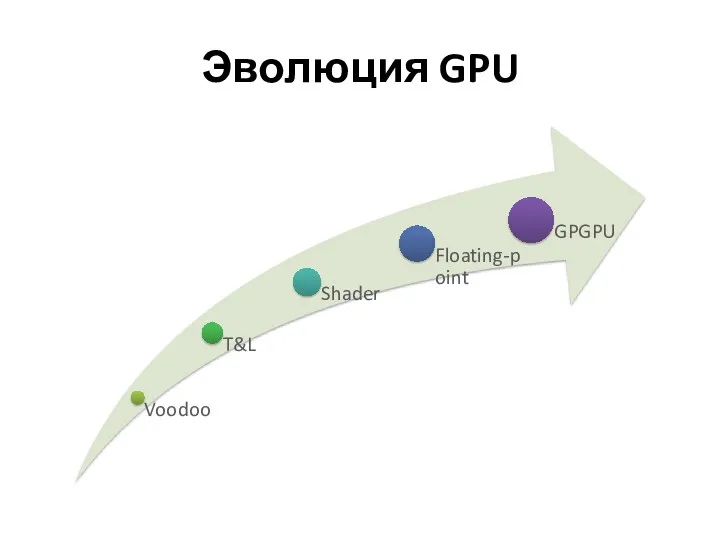
Эволюция GPU
Эволюция GPU

GPGPU
General-Purpose Computation on GPU
Вычисления на GPU общего (неграфического) назначения
AMD FireStream
NVIDIA CUDA
DirectCompute
GPGPU
General-Purpose Computation on GPU
Вычисления на GPU общего (неграфического) назначения
AMD FireStream
NVIDIA CUDA
DirectCompute

ПРОГРАММНАЯ МОДЕЛЬ CUDA
Основные понятия и определения CUDA
ПРОГРАММНАЯ МОДЕЛЬ CUDA
Основные понятия и определения CUDA

CUDA – Compute Unified Device Architecture
Host – CPU (Central Processing Unit)
Device
CUDA – Compute Unified Device Architecture
Host – CPU (Central Processing Unit)
Device
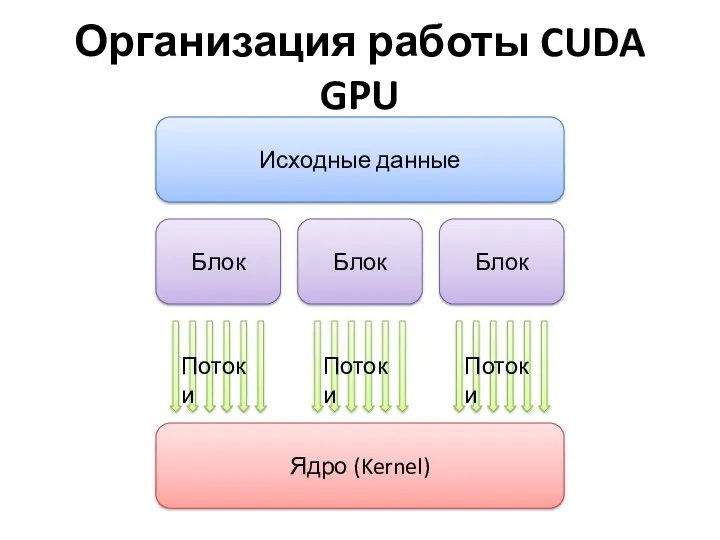
Организация работы CUDA GPU
Организация работы CUDA GPU

Warp и латентность
Warp
Порция потоков для выполнения на потоковом мультипроцессоре (SM)
Латентность
Общая задержка
Warp и латентность
Warp
Порция потоков для выполнения на потоковом мультипроцессоре (SM)
Латентность
Общая задержка
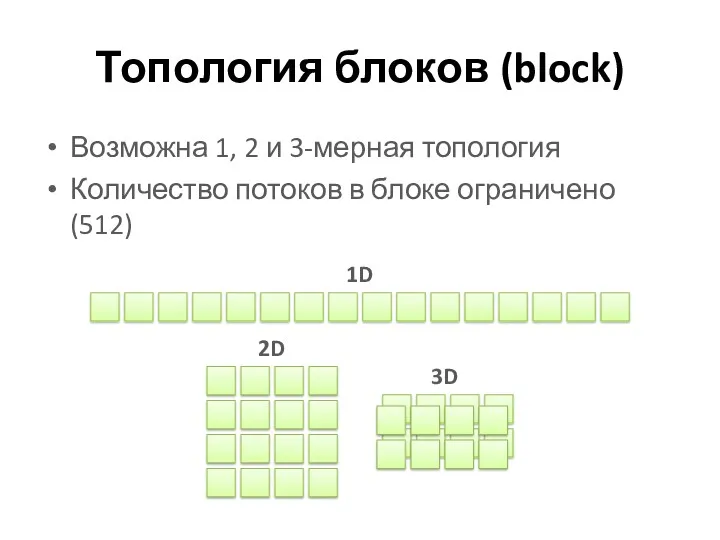
Топология блоков (block)
Возможна 1, 2 и 3-мерная топология
Количество потоков в блоке
Топология блоков (block)
Возможна 1, 2 и 3-мерная топология
Количество потоков в блоке
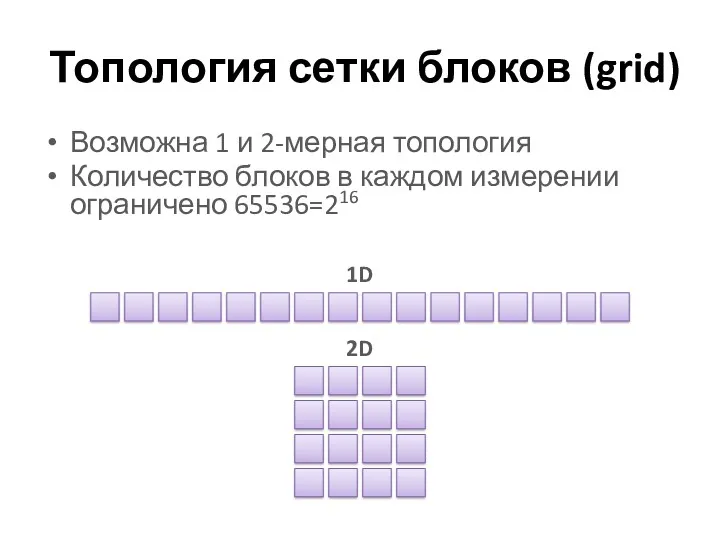
Топология сетки блоков (grid)
Возможна 1 и 2-мерная топология
Количество блоков в каждом
Топология сетки блоков (grid)
Возможна 1 и 2-мерная топология
Количество блоков в каждом

Адресация элементов данных
CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки
blockIdx
blockDim
threadIdx
1D
Адресация элементов данных
CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки
blockIdx
blockDim
threadIdx
1D
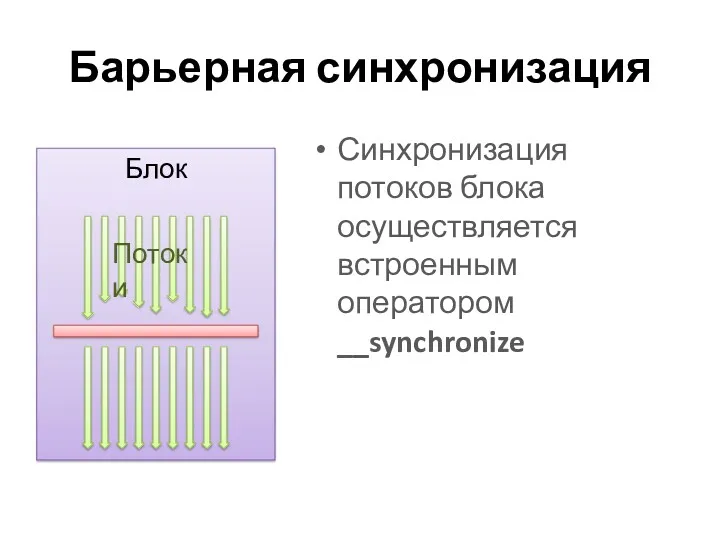
Барьерная синхронизация
Синхронизация потоков блока осуществляется встроенным оператором __synchronize
Барьерная синхронизация
Синхронизация потоков блока осуществляется встроенным оператором __synchronize

CUDA: РАСШИРЕНИЕ C++
Особенности написания программ для GPU CUDA
CUDA: РАСШИРЕНИЕ C++
Особенности написания программ для GPU CUDA

Расширение языка С++
Новые типы данных
Спецификаторы для функций
Спецификаторы для переменных
Встроенные переменные (для
Расширение языка С++
Новые типы данных
Спецификаторы для функций
Спецификаторы для переменных
Встроенные переменные (для
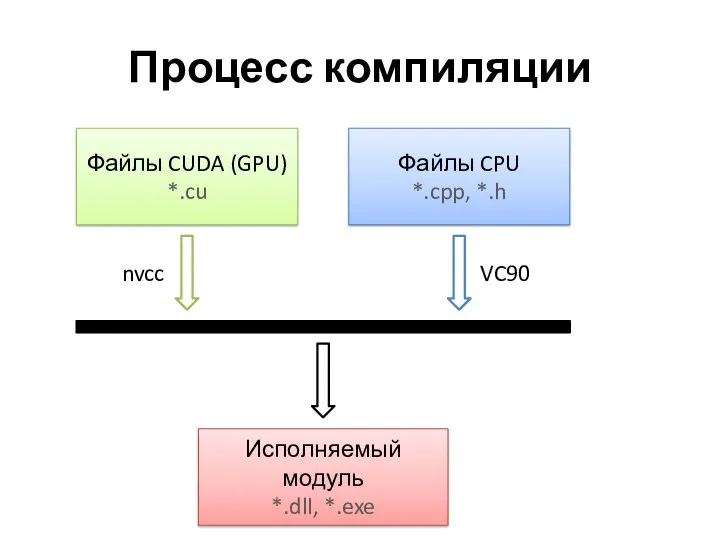
Процесс компиляции
Файлы CUDA (GPU)
*.cu
Файлы CPU
*.cpp, *.h
Исполняемый модуль
*.dll, *.exe
nvcc
VC90
Процесс компиляции
Файлы CUDA (GPU)
*.cu
Файлы CPU
*.cpp, *.h
Исполняемый модуль
*.dll, *.exe
nvcc
VC90

Типы данных CUDA
1, 2, 3 и 4-мерные вектора базовых типов
Целые: (u)char,
Типы данных CUDA
1, 2, 3 и 4-мерные вектора базовых типов
Целые: (u)char,
Спецификаторы функций
Спецификаторы функций

Спецификаторы функций
Ядро помечается __global__
Ядро не может возвращать значение
Возможно совместное использование __host__
Спецификаторы функций
Ядро помечается __global__
Ядро не может возвращать значение
Возможно совместное использование __host__

Ограничения функций GPU
Не поддерживается рекурсия
Не поддерживаются static-переменные
Нельзя брать адрес функции __device__
Не
Ограничения функций GPU
Не поддерживается рекурсия
Не поддерживаются static-переменные
Нельзя брать адрес функции __device__
Не
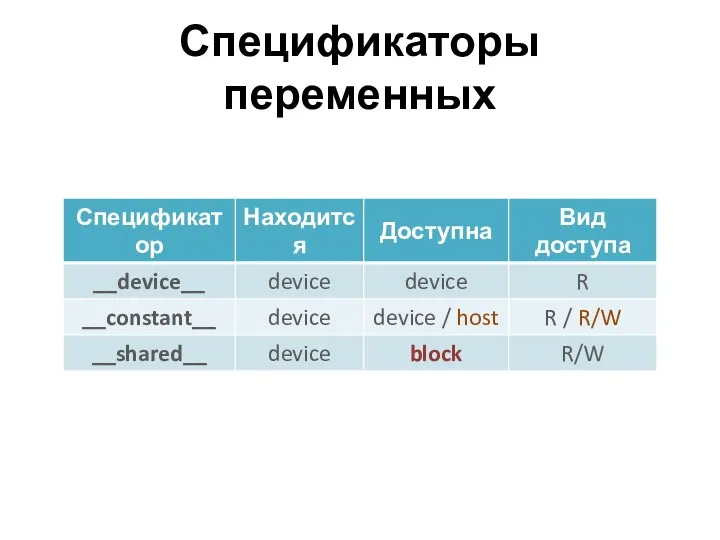
Спецификаторы переменных
Спецификаторы переменных

Ограничения переменных GPU
Переменные __shared__ не могут инициализироваться при объявлении
Запись в __constant__
Ограничения переменных GPU
Переменные __shared__ не могут инициализироваться при объявлении
Запись в __constant__

Переменные ядра
dim3 gridDim
unit3 blockIdx
dim3 blockDim
uint3 threadIdx
int
Переменные ядра
dim3 gridDim
unit3 blockIdx
dim3 blockDim
uint3 threadIdx
int

Директива запуска ядра
Kernel<<>>(data)
blocks – число блоков в сетке
threads – число
Директива запуска ядра
Kernel<<
blocks – число блоков в сетке
threads – число

Общая структура программы CUDA
__global__ void Kernel(float* data)
{
. . .
}
void main()
{
Общая структура программы CUDA
__global__ void Kernel(float* data)
{
. . .
}
void main()
{

Предустановки
Видеокарта NVIDIA с поддержкой CUDA
Драйвера устройства с поддержкой CUDA
NVIDIA CUDA Toolkit
NVIDIA
Предустановки
Видеокарта NVIDIA с поддержкой CUDA
Драйвера устройства с поддержкой CUDA
NVIDIA CUDA Toolkit
NVIDIA

Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDAI CUDA – Неграфические вычисления на графических процессорах
http://www.ixbt.com/video3/cuda-1.shtml
Создание простого
Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDAI CUDA – Неграфические вычисления на графических процессорах
http://www.ixbt.com/video3/cuda-1.shtml
Создание простого
 Простейшая (каскадная) модель жизненного цикла ПО. Техническое задание. Требования к содержанию и оформлению
Простейшая (каскадная) модель жизненного цикла ПО. Техническое задание. Требования к содержанию и оформлению Финансовая отчетность для владельца бизнеса. 1С:Управление небольшой фирмой 8
Финансовая отчетность для владельца бизнеса. 1С:Управление небольшой фирмой 8 СУБД MySQL PHP. Лекція №7
СУБД MySQL PHP. Лекція №7 Профессия: Оператор компьютерного набора
Профессия: Оператор компьютерного набора Знакомство с языком программирования Python. Ввод. Вывод. Оператор присваивания
Знакомство с языком программирования Python. Ввод. Вывод. Оператор присваивания Устройство компьютера. Схема устройства компьютера
Устройство компьютера. Схема устройства компьютера Лидар. Сбор входных данных
Лидар. Сбор входных данных Рекурсия
Рекурсия Программирование разветвляющихся алгоритмов
Программирование разветвляющихся алгоритмов Фейковые новости и как их отличать от настоящих
Фейковые новости и как их отличать от настоящих Как создать свой сайт
Как создать свой сайт Берсерк. Самоучитель
Берсерк. Самоучитель Миркомир. Игра
Миркомир. Игра Предметно-ориентированные информационные системы
Предметно-ориентированные информационные системы Розробка системи обміну повідомленнями для Twitter, на базі мобільних технологій
Розробка системи обміну повідомленнями для Twitter, на базі мобільних технологій Эффективные инструменты визуализации учебной информации
Эффективные инструменты визуализации учебной информации Тестирование программного обеспечения. Основы реляционных баз данных. Работа с SQL. (Урок 6)
Тестирование программного обеспечения. Основы реляционных баз данных. Работа с SQL. (Урок 6) Логические выражения и таблицы истинности. Логика
Логические выражения и таблицы истинности. Логика Что такое Unity и Vuforia
Что такое Unity и Vuforia Хранение и предварительная обработка больших наборов данных с помощью Tensor Flow
Хранение и предварительная обработка больших наборов данных с помощью Tensor Flow Турбопоиск. Предложение для компании “Концепт-Строй”
Турбопоиск. Предложение для компании “Концепт-Строй” Кодирование звуковой информации. Представление информации в компьютере
Кодирование звуковой информации. Представление информации в компьютере Математичне програмування. Задачі оптимізації. Задача лінійного програмування. Лекція 5
Математичне програмування. Задачі оптимізації. Задача лінійного програмування. Лекція 5 Внешние устройства компьютера
Внешние устройства компьютера История развития вычислительной техники
История развития вычислительной техники Проектирование реляционных баз данных
Проектирование реляционных баз данных Графический редактор PAINT
Графический редактор PAINT Методы анализа сложности рекурсивных алгоритмов
Методы анализа сложности рекурсивных алгоритмов