- Робота з даними

Содержание
- 2. Сильні сторони статистики: 1. Статистика допомагає вилучати інформацію з даних, розуміти незрозуміле, те, що не лежить
- 3. Приклад. Види даних в менеджменті. Фінансова і статистична звітність. Інвестиційні звіти – курси та обсяги цінних
- 4. Висновок: Статистика – це одночасно і наука і мистецтво збирання і аналізу даних в усіх сферах
- 5. Чотири етапи статистичного аналізу: Планування збору даних (планування вибіркового дослідження в маркетингу; планування експерименту в хімії).
- 6. Приклади невідомих величин: - обсяг продажу в наступному кварталі; - реакція на населення міста на новий
- 7. Приклади гіпотез: - середні витрати мешканців в наступному місяці на купівлю продукту; - нові ліки безпечні
- 8. Словник термінів (c.38): Статистика – statistics Планування дослідження – designing the study Попереднє дослідження даних –
- 9. Проект (c.41) : Знайдіть в газеті, журналі або Інтернет статтю, де представлені результати опитування. Письмово опишіть,
- 10. Набір статистичних даних це результат експерименту (спостереження за об’єктами), що включає реєстрацію однієї і тієї ж
- 11. Існують чотири способи класифікації даних: 1. За кількістю інформації для кожного об’єкта: 2. За типом виміру
- 12. 1. За кількістю інформації для кожного об’єкта: - одновимірний – доходи окремих осіб, кількість дефектів вибірки
- 13. 2. За типом виміру (числа або категорії) для кожного об’єкта: - кількісні дані (числа): дискретні (кількість
- 14. Чотири способи класифікації даних: 3. За можливістю часової упорядкованості: часові ряди (динаміка фондового індексу, щомісячні обсяги
- 15. Приклад даних: Приклад первинних даних: інформація о продуктивності обладнання, дані соціологічного опитування. Приклад вторинних даних: економічні
- 16. Тренінг: 1. Знайти на сайті Державних статистичних служб різних країн світу дані про Індекс споживчих цін
- 17. Словник термінів (c.61) : Набір даних – data set Елементарні одиниці – elementary units Змінна –
- 18. Самостійна робота (c.69) : 1. Знайдіть в Інтернет статтю з таблицею даних і надайте відповіді на
- 19. Розподіл дає можливість відповісти на такі запитання: Які значення є типовими для даного набору даних? Як
- 20. Чому це має значення? Річ у тім, що більшість кількісних методів аналізу, особливо, пов’язаних зі встановленням
- 21. Приклад: Рівень ставки за позику під заставу нерухомості 45-ти кредиторів
- 22. Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості
- 23. Висновки: 1. Розмах значень перевищує 1 п.п.: від мінімуму 5,875% до максимуму – 7,25%. 2. Типове
- 24. Приклад: Стартова заробітна плата випускників за галузями економіки (річна)
- 25. Гістограма розподілу галузей за початковим рівнем заробітної плати.
- 26. Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості
- 27. Висновки: Кожен стовпчик гістограми може представляти більше однієї галузі. Стовпчики показують, які діапазони заробітної плати частіше,
- 28. Нормальний розподіл являє собой теоретичну гладку гістограму у формі колоколу без випадкових відхилень. Така крива представляє
- 29. Нормальний розподіл Фактично існує багато різних кривих нормального розподілу, форма яких нагадує симетричний колокол. Вони відрізняються
- 30. Чому нормальний розподіл відіграє таку важливу роль у статистиці? Зазвичай в статистиці припускають, що розподіл даних
- 31. Чи є нормальний розподіл? Гістограми для даних, витягнутих з нормально розподіленого набору. Обсяг кожної вибірки дорівнює
- 32. Чи є нормальний розподіл? Гістограми для даних, витягнутих з нормально розподіленого набору. Обсяг кожної вибірки дорівнює
- 33. Несиметричний (скошений) розподіл не є ані симетричним, ані нормальним, оскільки значення даних на одній стороні кривої
- 34. Несиметричний (скошений) розподіл Згладжені ідеальні криві несиметричних розподілів. Реальні розподіли мають деякі відхилення від таких ідеальних
- 35. Приклад: активи комерційних банків зі списку Fortune 500, млрд дол. (вибірка 50 банків) Це яскравий приклад
- 36. Асиметричний розподіл: самий високий стовпчик – це банки, які мають активи менше за 50 млрд дол.
- 37. Проблема з асиметрією: більшість найбільш поширених статистичних методів вимагають наявності принаймні приблизно нормального розподілу. Якщо ці
- 38. Вихід за допомогою перетворення: Один із способів впоратися з проблемою асиметрії полягає у використанні такою перетворення,
- 39. Вихід за допомогою перетворення: Логарифмування часто перетворює скошені (асиметричні) дані в симетричні, оскільки відбувається розтягування шкали
- 40. Гістограма чисельності населення штатів (фактичні дані): Порівнюючи гістограму чисельності населення зліва і справа можна відмітити, що
- 41. Логарифмічну шкалу можна інтерпретувати скоріше як мультиплікативну або процентну, ніж як адитивну. Використання логарифмічної шкапи призводить
- 42. Висновок: Таким чином, логарифмування стягує разом дуже великі числа, зменшуючи різницю між ними та іншими значеннями
- 43. Порівняльна таблиця фактичних значень й їхніх логарифмів
- 44. Бімодальні розподіли Важливо вміти визначати, коли набір даних складається з двох або більш чітко розрізняються між
- 45. Гістограма розподілу взаємних фондів за доходами на валютному ринку. Це бімодальний розподіл з двома чітко виділеними
- 46. Пояснення Річ у тім, що початковий набір даних містить заголовок «Вільні від податку», який відокремлює у
- 47. Середня вартість одного дня перебування у місцевій лікарні, дол.
- 48. Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні, дол. Це майже нормальний розподіл.
- 49. Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні, дол. Складається враження (невірне), що
- 50. Викиди – значення, що сильно відхиляються Існують два види викидів значень: помилки; коректні значення, що відрізняються
- 51. Приклади викидів В наборі даних щодо доходів грошового ринку може з'явитися кілька значень доходів фондів, які
- 52. Приклади викидів За повідомленням The Wall Street Journal, чистий дохід за другий квартал найбільших компаній США
- 53. Висновок: Таким чином, наявність викиду дає хибне уявлення про реальне зростання компаній. Може скластися невірна думка
- 54. На прикладі динаміки витрат на телевізійну рекламу провідних компаній простежимо як наявність викидів впливає на симетричність
- 55. Гістограма розподілу процентного зростання витрат на рекламу 25 компаній. В правій частині присутній викид компанії Regal
- 56. Гістограма розподілу процентного зростання витрат на рекламу 24 (23) компаній Після усунення викиду (компанії Regal Communications)
- 57. Гістограма розподілу процентного зростання витрат на рекламу 21 компанії
- 58. Висновки Дані цього аналізу свідчать про те, що витрати на рекламу сильно змінюються щодня. Крупні рекламодавці
- 59. Словник термінів (с. 101): Послідовність чисел – list of numbers Числова вісь – number line Гістограма
- 60. Самостійна робота з використанням бази даних (с. 114): За даними даних, наведеними в дод. А виконайте
- 61. Проекти (с. 115): Побудуйте гістограму для кожного з трьох наборів даних, що мають відношення до ваших
- 62. Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 115) "Цей Оуен викидає наші гроші на вітер! –
- 63. Ситуаційний аналіз: необхідність контролю виробничих втрат (42 спостереження)
- 64. Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 116) Питання для обговорення: 1. Чи є розподіл вартості
- 65. Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних У складних ситуаціях один з найефективніших
- 66. Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних Середнє, медіана і мода – це
- 67. Як бути, якщо набір даних містить окремі значення, які неадекватно описуються цими показниками? Такі викиди можна
- 68. Приклад. Аналіз витрат Фірму цікавить скільки в цілому витрачають на медичні товари мешканці міста. Аналіз вибірки
- 69. Приклад. Скільки є бракованих деталей? Кожна партія виробів компанії Globular Ball Bearing Company містить 1000 виробів.
- 70. Зважене середнє (використовують також термін середньозважене). Схоже на середнє, але дає можливість врахувати різну важливість (значимість),
- 71. Приклад. Розрахунок середнього балу Середній бал (GPA – grade point average) результатів навчання в університеті обчислюється
- 72. Приклад. Вартість капіталу фірми Вартість капіталу фірми обчислюють як зважене середнє. Суть в тому, що фірма
- 73. Приклад. Вартість капіталу фірми Середньозважену вартість акціонерного капіталу можна пояснити у такий спосіб: якщо компанія вирішить
- 74. Приклад. Аналіз витрат (продовження) Розглянемо вибірку 300 мешканців міста з точки зору витрат на медичні товари.
- 75. Приклад. Обвал фондового ринку 19.10.1987 р. Обвал фондового ринку 1987 став екстраординарною подією, тоді ринок втратив
- 76. Приклад. Обвал фондового ринку 19.10.1987 р. З таблиці можна побачити, що навіть при відкритті торгів акції
- 77. Приклад. Обвал фондового ринку 19.10.1987 р. Гістограма розподілу процентного падіння вартості 29 промислових компаній зі списку
- 78. Приклад. Обвал фондового ринку 19.10.1987 р. Має місце невелика асиметрія у напряму низьких значень (хвіст зліва
- 79. Мода в контролі якості: метод Демінга Будь-яка виробнича діяльність має відхилення від ідеалу. Демінг запропонував систематичний
- 80. Мода в контролі якості: метод Демінга. Висновки. Зрозуміло, що модою в цьому наборі є проблеми з
- 81. Приклад. Зборка системних блоків. Розглянемо стан зборки системних комп’ютерних блоків: Так, медіана припадає на стадію виробництва
- 82. Приклад. Зборка системних блоків. Висновки В цьому прикладі стадія Е – це встановлення материнської плати в
- 83. Перцентилі. це показники набору даних, які характеризують ранги елементів у вигляді відсотків від 0 до 100%,
- 84. Перцентилі і блочна діаграма. 1. Найменше значення – 0-й перцентиль. 2. Нижній квартиль – 25-й перцентиль.
- 85. Приклад. Обвал фондового ринку 19.10.1987 р. продовження Блочна діаграма процентного падіння вартості 29 промислових компаній зі
- 86. Функція кумулятивного розподілу даних представляється у вигляді графіка, який показує перцентилі шляхом встановлення відповідності між даними
- 87. Приклад. Обвал фондового ринку 19.10.1987 р. продовження Кумулятивна діаграма процентного падіння вартості 29 промислових компаній зі
- 88. Словник термінів (с. 151): Узагальнення – summarization Усереднення – average Середнє – mean Зважене середнє –
- 89. Самостійна робота з використанням бази даних (с. 164): 1. Для розмірів річної заробітної плати: а) Визначте
- 90. Проекти (с. 164): 1. Використовуючи Internet чи економічні журнали, підберіть набір даних з 25 чисел, що
- 91. Ситуаційний аналіз (с. 165): Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача" Прийшовши на роботу,
- 92. Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача" Таблиця 1
- 93. Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача" Харрісу було нелегко. Прогноз містив
- 94. Ситуаційний аналіз: Чому виникають сумніви? Тому що, якщо прогноз невірний і обсяг продажів не збільшиться, фірма
- 95. Ситуаційний аналіз: У чому може бути помилка? Харріс і Макроурі вирішили уважніше вивчити дані. Нижче наведена
- 96. Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача" Таблиця 2
- 97. Ситуаційний аналіз: Таблиця 3
- 98. Ситуаційний аналіз: Питання для обговорення (с. 168) 1. Чи підходить в даному випадку звичайний метод, що
- 99. Мінливість даних, її статистичне оцінювання
- 100. Три способи опису ступеня мінливості набору даних
- 101. Три способи опису ступеня мінливості набору даних: приклад
- 102. Три способи опису ступеня мінливості набору даних: приклад Ваша фірма з бюджетом реклами в 19 млн
- 103. Три способи опису ступеня мінливості набору даних Особливого сенсу цей розподіл набуває в картах контролю, які
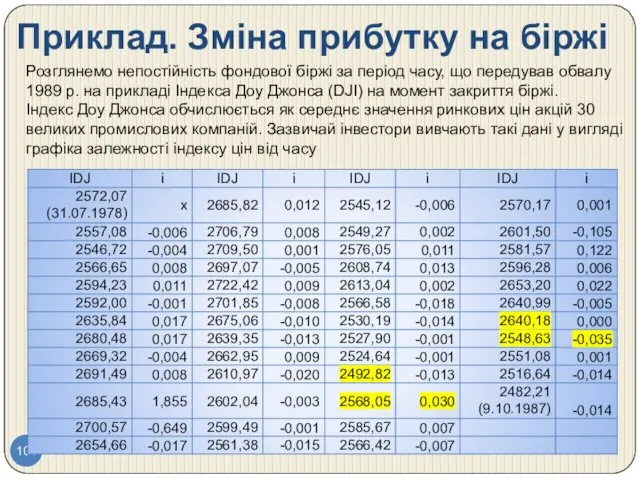
- 104. Приклад. Зміна прибутку на біржі Розглянемо непостійність фондової біржі за період часу, що передував обвалу 1989
- 105. Приклад . Індекс Доу Джонса цін акцій 30 великих промислових компаній за період з 31 липня
- 106. Приклад: продовження Розподіл денного прибутку акцій 30 великих промислових компаній за період з 1 серпня 1987
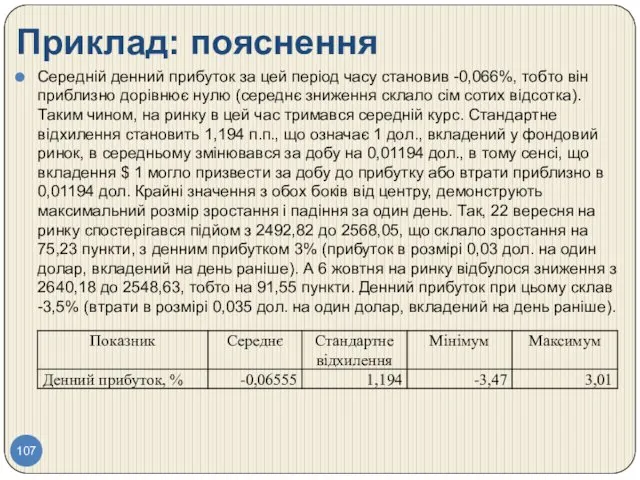
- 107. Приклад: пояснення Середній денний прибуток за цей період часу становив -0,066%, тобто він приблизно дорівнює нулю
- 108. Приклад: висновки Для того, щоб знаходитися в межах значення одного стандартного відхилення (1,194) від середнього значення
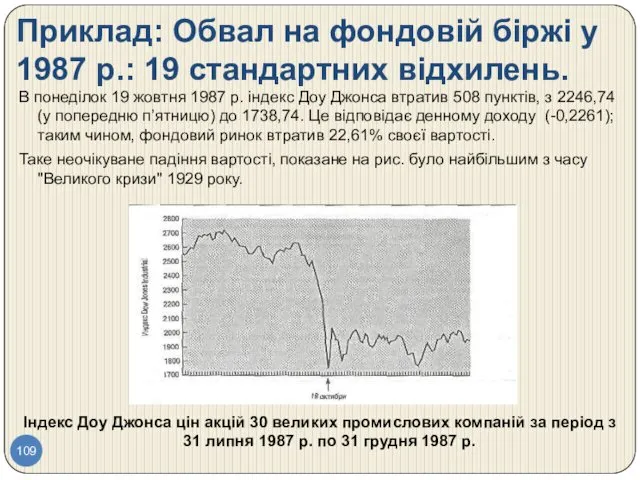
- 109. Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень. В понеділок 19 жовтня 1987
- 110. Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень. Для того щоб представити собі,
- 111. Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень. Якби денний дохід на біржі
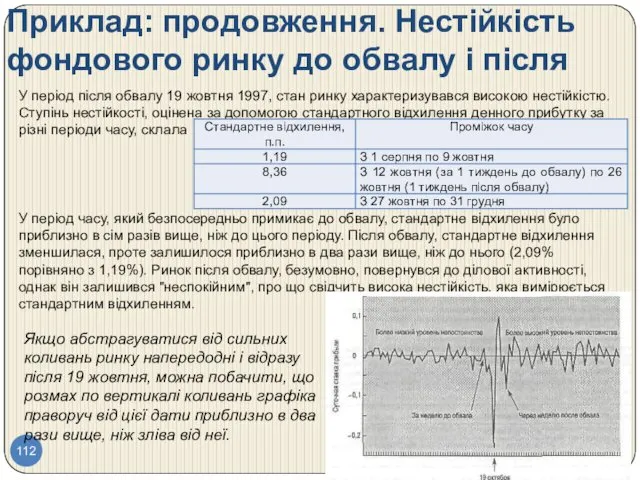
- 112. Приклад: продовження. Нестійкість фондового ринку до обвалу і після У період після обвалу 19 жовтня 1997,
- 113. Приклад: продовження. Нестійкість фондового ринку до обвалу і після Останнім часом нестійкість фондового ринку значно знизилася.
- 114. Приклад: Диверсифікація на фондовому ринку Розглянемо величину ризику для трьох випадків: (1) володіння тільки акціями Boeing,
- 115. Три способи опису ступеня мінливості набору даних
- 116. Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики. Цей гіпотетичний набір даних (тривалість перебування
- 117. Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики. Висновок: При ретельній перевірці було виявлено
- 118. Три способи опису ступеня мінливості набору даних
- 119. Приклад. Невизначеність прибутковості портфеля інвестицій Ви вклали 10000 дол. у 200 акцій корпорації, які продаються по
- 120. Приклад. Продуктивність праці у відділі торгівлі по телефону Розглянемо відділ торгівлі па телефону, в якому працюють
- 121. Приклад. Загальна вартість виробленого товару Розглянемо виробництво продукту для якого фіксовані витрати складають 1 млн дол.,
- 122. Словник термінів (с. 198): Мінливість – variability Різноманітність – diversity Невизначеність – uncertainly Розсіювання – dispersion
- 123. Самостійна робота з використанням бази даних (с. 215): Зверніться до бази даних про найманих працівників у
- 124. Проекти (с. 216): 1. У відповідності до власних інтересів візьміть набір значень для підприємств двох галузей
- 125. Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником? Ви і один з ваших
- 126. Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником? Ситуація видається цілком очевидною, однак
- 128. Скачать презентацию

Сильні сторони статистики:
1. Статистика допомагає вилучати інформацію з даних, розуміти незрозуміле,
Сильні сторони статистики:
1. Статистика допомагає вилучати інформацію з даних, розуміти незрозуміле,

Приклад. Види даних в менеджменті.
Фінансова і статистична звітність.
Інвестиційні звіти – курси
Приклад. Види даних в менеджменті.
Фінансова і статистична звітність.
Інвестиційні звіти – курси

Висновок:
Статистика – це одночасно і наука і мистецтво збирання і аналізу
Висновок:
Статистика – це одночасно і наука і мистецтво збирання і аналізу

Чотири етапи статистичного аналізу:
Планування збору даних (планування вибіркового дослідження в маркетингу;
Чотири етапи статистичного аналізу:
Планування збору даних (планування вибіркового дослідження в маркетингу;

Приклади невідомих величин:
- обсяг продажу в наступному кварталі;
- реакція на населення
Приклади невідомих величин:
- обсяг продажу в наступному кварталі;
- реакція на населення

Приклади гіпотез:
- середні витрати мешканців в наступному місяці на купівлю продукту;
-
Приклади гіпотез:
- середні витрати мешканців в наступному місяці на купівлю продукту;
-

Словник термінів (c.38):
Статистика – statistics
Планування дослідження – designing the study
Попереднє дослідження
Словник термінів (c.38):
Статистика – statistics
Планування дослідження – designing the study
Попереднє дослідження

Проект (c.41) :
Знайдіть в газеті, журналі або Інтернет статтю, де представлені
Проект (c.41) :
Знайдіть в газеті, журналі або Інтернет статтю, де представлені

Набір статистичних даних
це результат експерименту (спостереження за об’єктами), що
Набір статистичних даних
це результат експерименту (спостереження за об’єктами), що

Існують чотири способи класифікації даних:
1. За кількістю інформації для кожного об’єкта:
Існують чотири способи класифікації даних:
1. За кількістю інформації для кожного об’єкта:

1. За кількістю інформації для кожного об’єкта:
- одновимірний –
1. За кількістю інформації для кожного об’єкта:
- одновимірний –

2. За типом виміру (числа або категорії) для кожного об’єкта:
- кількісні
2. За типом виміру (числа або категорії) для кожного об’єкта:
- кількісні

Чотири способи класифікації даних:
3. За можливістю часової упорядкованості: часові ряди
Чотири способи класифікації даних:
3. За можливістю часової упорядкованості: часові ряди

Приклад даних:
Приклад первинних даних: інформація о продуктивності обладнання, дані
Приклад даних:
Приклад первинних даних: інформація о продуктивності обладнання, дані

Тренінг:
1. Знайти на сайті Державних статистичних служб різних
Тренінг:
1. Знайти на сайті Державних статистичних служб різних

Словник термінів (c.61) :
Набір даних – data set
Елементарні одиниці
Словник термінів (c.61) :
Набір даних – data set
Елементарні одиниці

Самостійна робота (c.69) :
1. Знайдіть в Інтернет статтю з таблицею
Самостійна робота (c.69) :
1. Знайдіть в Інтернет статтю з таблицею

Розподіл дає можливість відповісти на такі запитання:
Які значення є типовими
Розподіл дає можливість відповісти на такі запитання:
Які значення є типовими

Чому це має значення?
Річ у тім, що більшість кількісних методів
Чому це має значення?
Річ у тім, що більшість кількісних методів
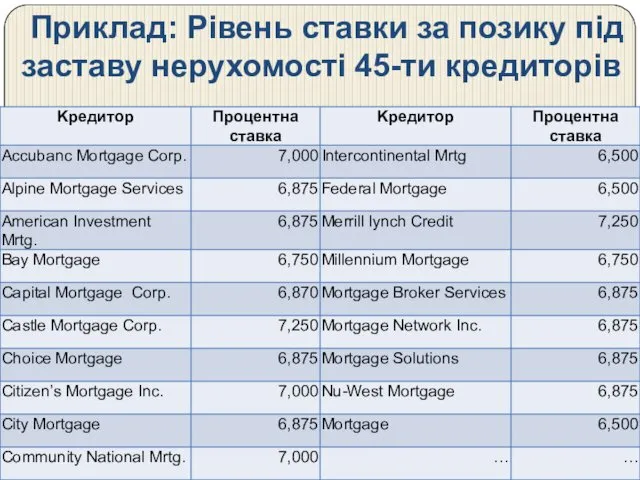
Приклад: Рівень ставки за позику під заставу нерухомості 45-ти кредиторів
Приклад: Рівень ставки за позику під заставу нерухомості 45-ти кредиторів

Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості
Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості

Висновки:
1. Розмах значень перевищує 1 п.п.: від мінімуму 5,875% до максимуму
Висновки:
1. Розмах значень перевищує 1 п.п.: від мінімуму 5,875% до максимуму
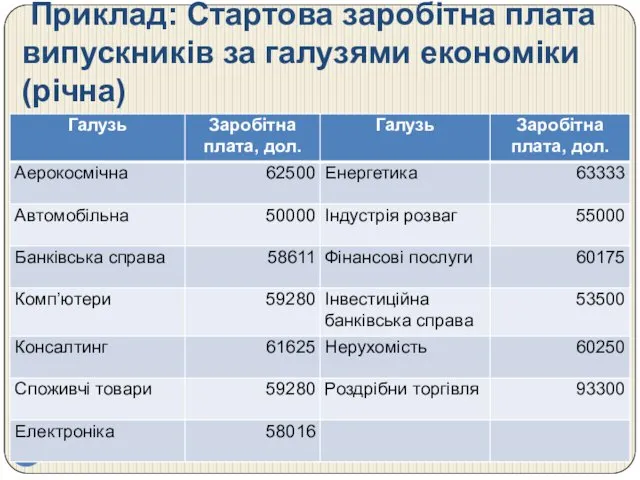
Приклад: Стартова заробітна плата випускників за галузями економіки (річна)
Приклад: Стартова заробітна плата випускників за галузями економіки (річна)

Гістограма розподілу галузей за початковим рівнем заробітної плати.
Гістограма розподілу галузей за початковим рівнем заробітної плати.

Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості
Гістограма розподілу кредиторів за рівнем процентних ставок під заставу нерухомості

Висновки:
Кожен стовпчик гістограми може представляти більше однієї галузі. Стовпчики показують, які
Висновки:
Кожен стовпчик гістограми може представляти більше однієї галузі. Стовпчики показують, які
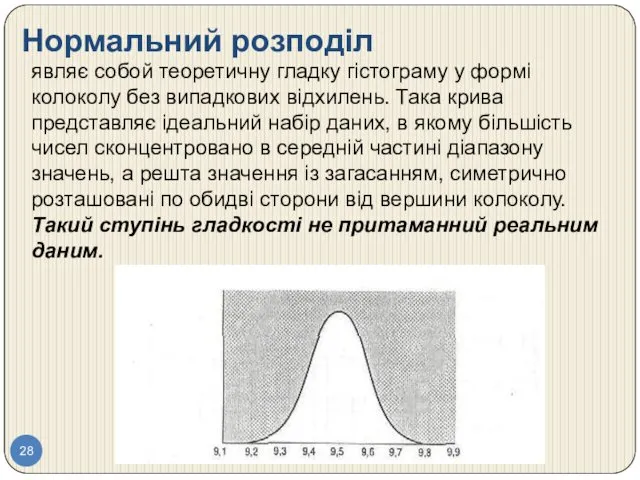
Нормальний розподіл
являє собой теоретичну гладку гістограму у формі колоколу без випадкових
Нормальний розподіл
являє собой теоретичну гладку гістограму у формі колоколу без випадкових
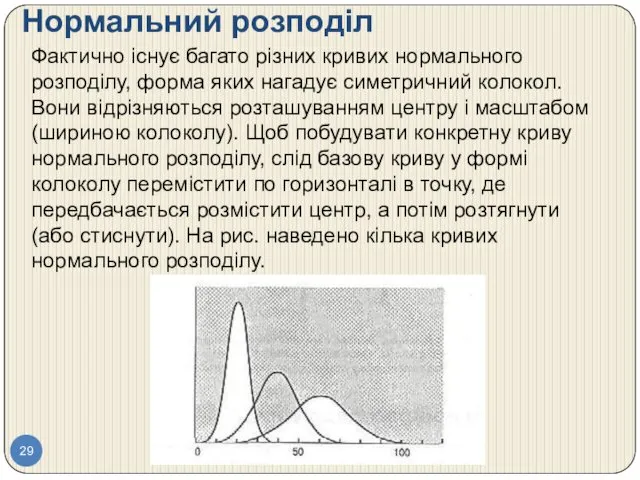
Нормальний розподіл
Фактично існує багато різних кривих нормального розподілу, форма яких нагадує
Нормальний розподіл
Фактично існує багато різних кривих нормального розподілу, форма яких нагадує

Чому нормальний розподіл відіграє таку важливу роль у статистиці?
Зазвичай в статистиці
Чому нормальний розподіл відіграє таку важливу роль у статистиці?
Зазвичай в статистиці
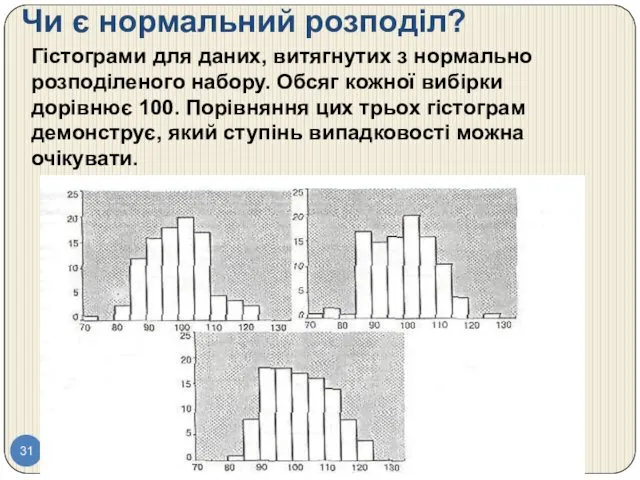
Чи є нормальний розподіл?
Гістограми для даних, витягнутих з нормально розподіленого набору.
Чи є нормальний розподіл?
Гістограми для даних, витягнутих з нормально розподіленого набору.

Чи є нормальний розподіл?
Гістограми для даних, витягнутих з нормально розподіленого набору.
Чи є нормальний розподіл?
Гістограми для даних, витягнутих з нормально розподіленого набору.

Несиметричний (скошений) розподіл
не є ані симетричним, ані нормальним, оскільки значення даних
Несиметричний (скошений) розподіл
не є ані симетричним, ані нормальним, оскільки значення даних
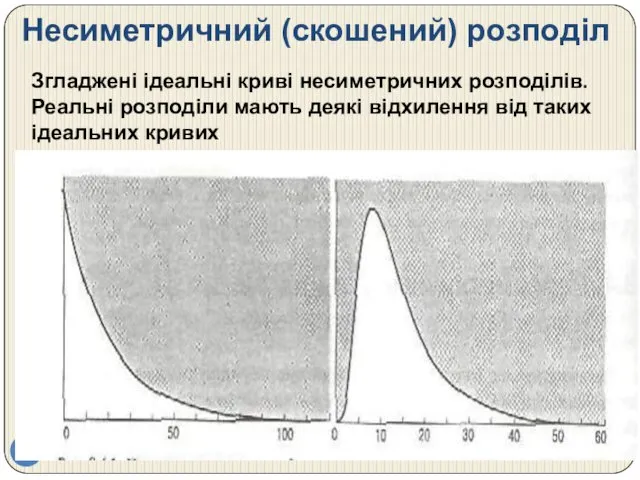
Несиметричний (скошений) розподіл
Згладжені ідеальні криві несиметричних розподілів. Реальні розподіли мають деякі
Несиметричний (скошений) розподіл
Згладжені ідеальні криві несиметричних розподілів. Реальні розподіли мають деякі
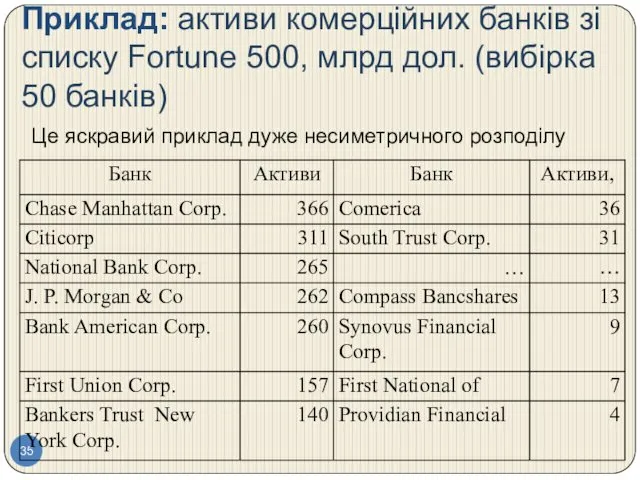
Приклад: активи комерційних банків зі списку Fortune 500, млрд дол. (вибірка
Приклад: активи комерційних банків зі списку Fortune 500, млрд дол. (вибірка

Асиметричний розподіл:
самий високий стовпчик – це банки, які мають активи менше
Асиметричний розподіл:
самий високий стовпчик – це банки, які мають активи менше

Проблема з асиметрією:
більшість найбільш поширених статистичних методів вимагають наявності принаймні приблизно
Проблема з асиметрією:
більшість найбільш поширених статистичних методів вимагають наявності принаймні приблизно

Вихід за допомогою перетворення:
Один із способів впоратися з проблемою асиметрії полягає
Вихід за допомогою перетворення:
Один із способів впоратися з проблемою асиметрії полягає

Вихід за допомогою перетворення:
Логарифмування часто перетворює скошені (асиметричні) дані в симетричні,
Вихід за допомогою перетворення:
Логарифмування часто перетворює скошені (асиметричні) дані в симетричні,
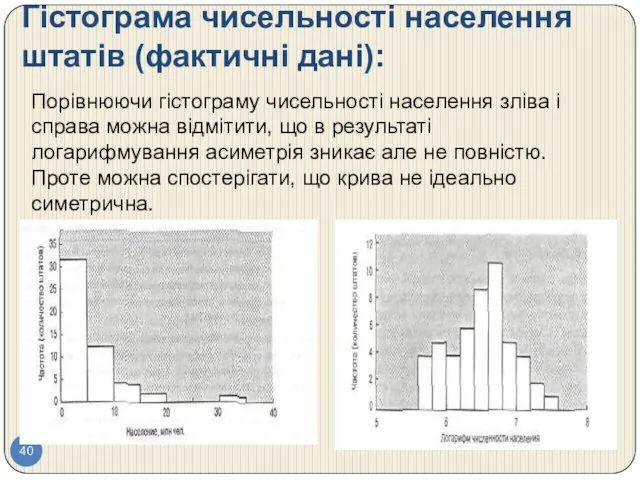
Гістограма чисельності населення штатів (фактичні дані):
Порівнюючи гістограму чисельності населення зліва і
Гістограма чисельності населення штатів (фактичні дані):
Порівнюючи гістограму чисельності населення зліва і

Логарифмічну шкалу можна інтерпретувати скоріше як мультиплікативну або процентну, ніж як
Логарифмічну шкалу можна інтерпретувати скоріше як мультиплікативну або процентну, ніж як

Висновок:
Таким чином, логарифмування стягує разом дуже великі числа, зменшуючи різницю
Висновок:
Таким чином, логарифмування стягує разом дуже великі числа, зменшуючи різницю
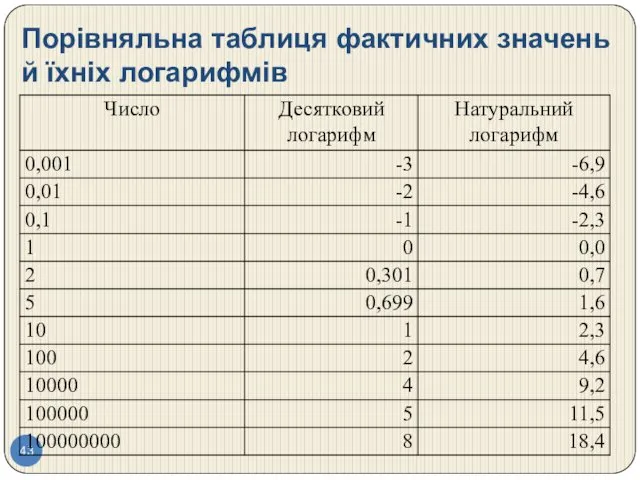
Порівняльна таблиця фактичних значень й їхніх логарифмів
Порівняльна таблиця фактичних значень й їхніх логарифмів

Бімодальні розподіли
Важливо вміти визначати, коли набір даних складається з двох або
Бімодальні розподіли
Важливо вміти визначати, коли набір даних складається з двох або
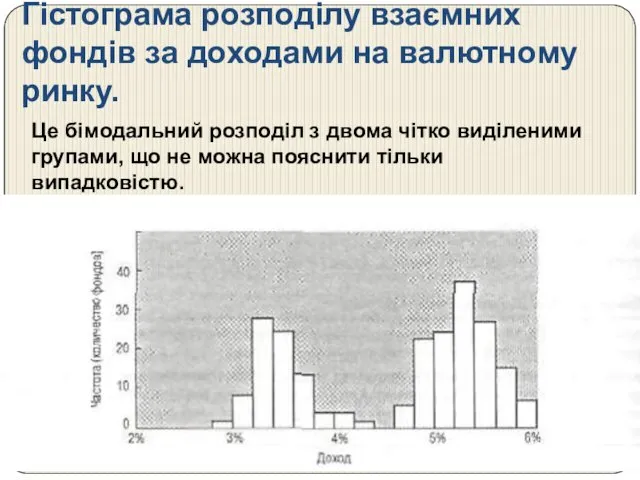
Гістограма розподілу взаємних фондів за доходами на валютному ринку.
Це бімодальний розподіл
Гістограма розподілу взаємних фондів за доходами на валютному ринку.
Це бімодальний розподіл

Пояснення
Річ у тім, що початковий набір даних містить заголовок «Вільні від
Пояснення
Річ у тім, що початковий набір даних містить заголовок «Вільні від
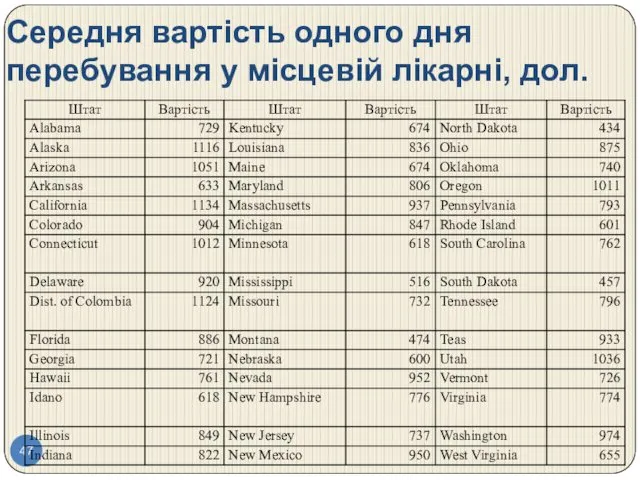
Середня вартість одного дня перебування у місцевій лікарні, дол.
Середня вартість одного дня перебування у місцевій лікарні, дол.

Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні,
Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні,

Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні,
Гістограма розподілу штатів за вартістю одного дня перебування у місцевій лікарні,

Викиди – значення, що сильно відхиляються
Існують два види викидів значень:
помилки;
коректні
Викиди – значення, що сильно відхиляються
Існують два види викидів значень:
помилки;
коректні

Приклади викидів
В наборі даних щодо доходів грошового ринку може з'явитися кілька
Приклади викидів
В наборі даних щодо доходів грошового ринку може з'явитися кілька

Приклади викидів
За повідомленням The Wall Street Journal, чистий дохід за другий
Приклади викидів
За повідомленням The Wall Street Journal, чистий дохід за другий

Висновок:
Таким чином, наявність викиду дає хибне уявлення про реальне зростання компаній.
Висновок:
Таким чином, наявність викиду дає хибне уявлення про реальне зростання компаній.
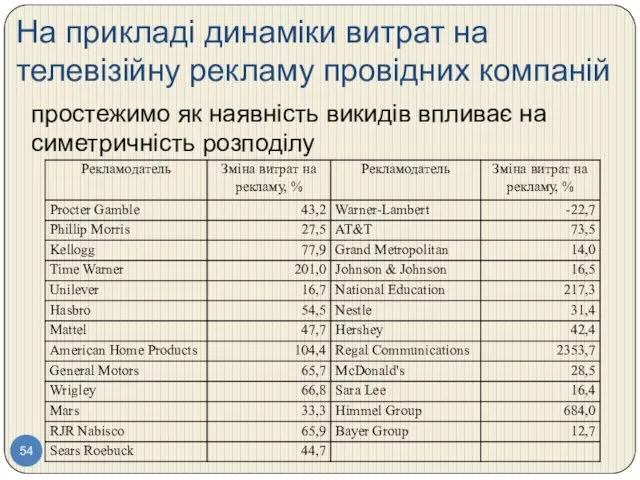
На прикладі динаміки витрат на телевізійну рекламу провідних компаній
простежимо як наявність
На прикладі динаміки витрат на телевізійну рекламу провідних компаній
простежимо як наявність

Гістограма розподілу процентного зростання витрат на рекламу 25 компаній.
В правій
Гістограма розподілу процентного зростання витрат на рекламу 25 компаній.
В правій

Гістограма розподілу процентного зростання витрат на рекламу 24 (23) компаній
Після усунення
Гістограма розподілу процентного зростання витрат на рекламу 24 (23) компаній
Після усунення

Гістограма розподілу процентного зростання витрат на рекламу 21 компанії
Гістограма розподілу процентного зростання витрат на рекламу 21 компанії

Висновки
Дані цього аналізу свідчать про те, що витрати на рекламу сильно
Висновки
Дані цього аналізу свідчать про те, що витрати на рекламу сильно

Словник термінів (с. 101):
Послідовність чисел – list of numbers
Числова вісь –
Словник термінів (с. 101):
Послідовність чисел – list of numbers
Числова вісь –

Самостійна робота з використанням бази даних (с. 114):
За даними даних, наведеними
Самостійна робота з використанням бази даних (с. 114):
За даними даних, наведеними

Проекти (с. 115):
Побудуйте гістограму для кожного з трьох наборів даних, що
Проекти (с. 115):
Побудуйте гістограму для кожного з трьох наборів даних, що

Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 115)
"Цей Оуен викидає наші
Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 115)
"Цей Оуен викидає наші
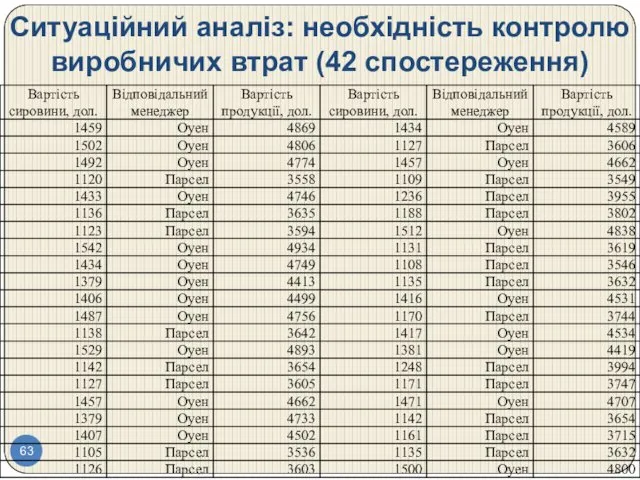
Ситуаційний аналіз: необхідність контролю виробничих втрат (42 спостереження)
Ситуаційний аналіз: необхідність контролю виробничих втрат (42 спостереження)

Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 116)
Питання для обговорення:
1. Чи
Ситуаційний аналіз: необхідність контролю виробничих втрат (с. 116)
Питання для обговорення:
1. Чи

Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних
У
Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних
У

Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних
Середнє,
Узагальнюючі показники набору статистичних даних. Типове значення набору статистичних даних
Середнє,

Як бути, якщо набір даних містить окремі значення, які неадекватно описуються
Як бути, якщо набір даних містить окремі значення, які неадекватно описуються

Приклад. Аналіз витрат
Фірму цікавить скільки в цілому витрачають на медичні товари
Приклад. Аналіз витрат
Фірму цікавить скільки в цілому витрачають на медичні товари

Приклад. Скільки є бракованих деталей?
Кожна партія виробів компанії Globular Ball Bearing
Приклад. Скільки є бракованих деталей?
Кожна партія виробів компанії Globular Ball Bearing

Зважене середнє
(використовують також термін середньозважене). Схоже на середнє, але дає можливість
Зважене середнє
(використовують також термін середньозважене). Схоже на середнє, але дає можливість
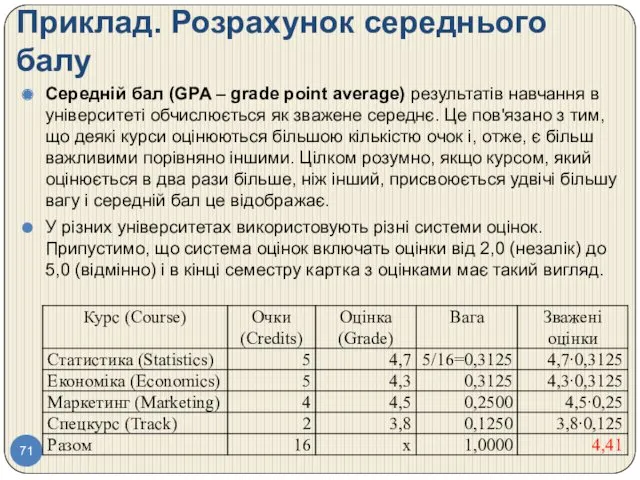
Приклад. Розрахунок середнього балу
Середній бал (GPA – grade point average) результатів
Приклад. Розрахунок середнього балу
Середній бал (GPA – grade point average) результатів

Приклад. Вартість капіталу фірми
Вартість капіталу фірми обчислюють як зважене середнє. Суть
Приклад. Вартість капіталу фірми
Вартість капіталу фірми обчислюють як зважене середнє. Суть
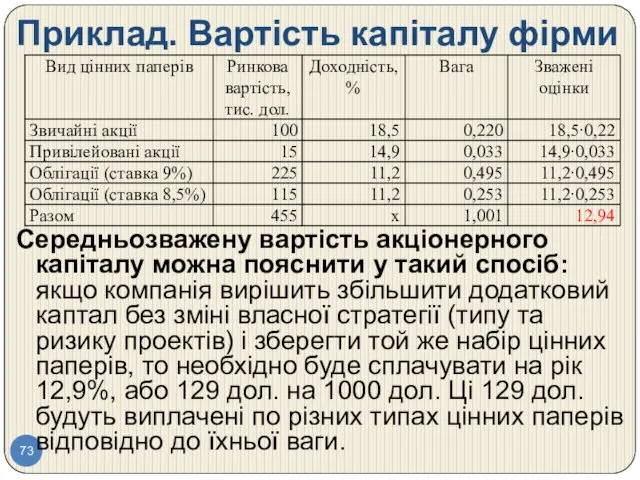
Приклад. Вартість капіталу фірми
Середньозважену вартість акціонерного капіталу можна пояснити у такий
Приклад. Вартість капіталу фірми
Середньозважену вартість акціонерного капіталу можна пояснити у такий

Приклад. Аналіз витрат (продовження)
Розглянемо вибірку 300 мешканців міста з точки зору
Приклад. Аналіз витрат (продовження)
Розглянемо вибірку 300 мешканців міста з точки зору

Приклад. Обвал фондового ринку 19.10.1987 р.
Обвал фондового ринку 1987 став екстраординарною
Приклад. Обвал фондового ринку 19.10.1987 р.
Обвал фондового ринку 1987 став екстраординарною
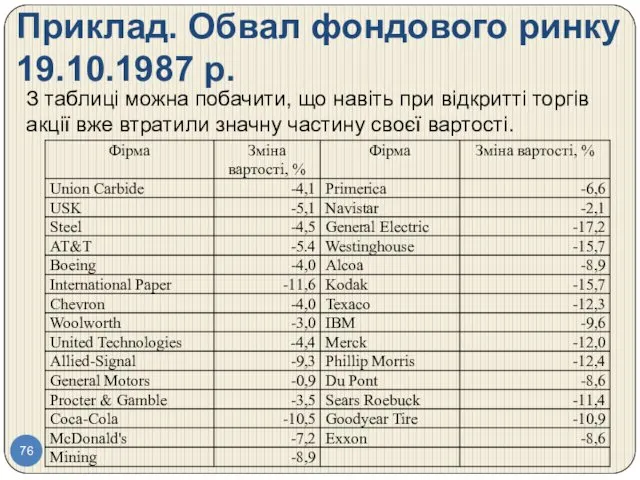
Приклад. Обвал фондового ринку 19.10.1987 р.
З таблиці можна побачити, що навіть
Приклад. Обвал фондового ринку 19.10.1987 р.
З таблиці можна побачити, що навіть

Приклад. Обвал фондового ринку 19.10.1987 р.
Гістограма розподілу процентного падіння вартості 29
Приклад. Обвал фондового ринку 19.10.1987 р.
Гістограма розподілу процентного падіння вартості 29

Приклад. Обвал фондового ринку 19.10.1987 р.
Має місце невелика асиметрія у напряму
Приклад. Обвал фондового ринку 19.10.1987 р.
Має місце невелика асиметрія у напряму
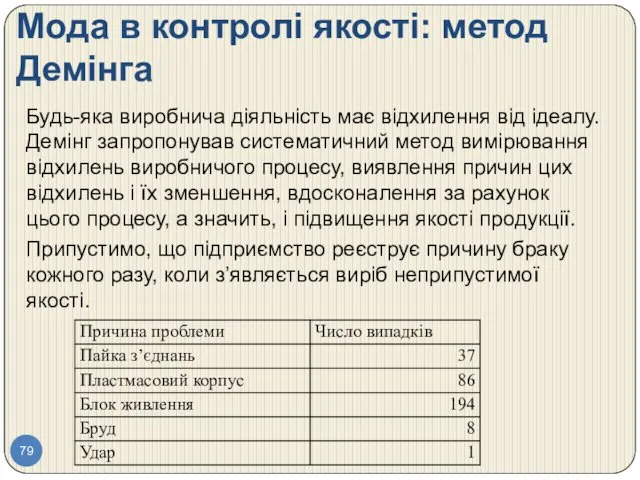
Мода в контролі якості: метод Демінга
Будь-яка виробнича діяльність має відхилення від
Мода в контролі якості: метод Демінга
Будь-яка виробнича діяльність має відхилення від

Мода в контролі якості: метод Демінга. Висновки.
Зрозуміло, що модою в цьому
Мода в контролі якості: метод Демінга. Висновки.
Зрозуміло, що модою в цьому

Приклад. Зборка системних блоків.
Розглянемо стан зборки системних комп’ютерних блоків:
Так, медіана припадає
Приклад. Зборка системних блоків.
Розглянемо стан зборки системних комп’ютерних блоків:
Так, медіана припадає

Приклад. Зборка системних блоків. Висновки
В цьому прикладі стадія Е – це
Приклад. Зборка системних блоків. Висновки
В цьому прикладі стадія Е – це

Перцентилі.
це показники набору даних, які характеризують ранги елементів у вигляді відсотків
Перцентилі.
це показники набору даних, які характеризують ранги елементів у вигляді відсотків

Перцентилі і блочна діаграма.
1. Найменше значення – 0-й перцентиль.
2. Нижній квартиль
Перцентилі і блочна діаграма.
1. Найменше значення – 0-й перцентиль.
2. Нижній квартиль

Приклад. Обвал фондового ринку 19.10.1987 р. продовження
Блочна діаграма процентного падіння вартості
Приклад. Обвал фондового ринку 19.10.1987 р. продовження
Блочна діаграма процентного падіння вартості

Функція кумулятивного розподілу даних
представляється у вигляді графіка, який показує перцентилі шляхом
Функція кумулятивного розподілу даних
представляється у вигляді графіка, який показує перцентилі шляхом

Приклад. Обвал фондового ринку 19.10.1987 р. продовження
Кумулятивна діаграма процентного падіння вартості
Приклад. Обвал фондового ринку 19.10.1987 р. продовження
Кумулятивна діаграма процентного падіння вартості

Словник термінів (с. 151):
Узагальнення – summarization
Усереднення – average
Середнє – mean
Зважене середнє
Словник термінів (с. 151):
Узагальнення – summarization
Усереднення – average
Середнє – mean
Зважене середнє

Самостійна робота з використанням бази даних (с. 164):
1. Для розмірів річної
Самостійна робота з використанням бази даних (с. 164):
1. Для розмірів річної

Проекти (с. 164):
1. Використовуючи Internet чи економічні журнали, підберіть набір даних
Проекти (с. 164):
1. Використовуючи Internet чи економічні журнали, підберіть набір даних

Ситуаційний аналіз (с. 165): Управлінські прогнози виробництва та маркетингу, або "Випадок
Ситуаційний аналіз (с. 165): Управлінські прогнози виробництва та маркетингу, або "Випадок
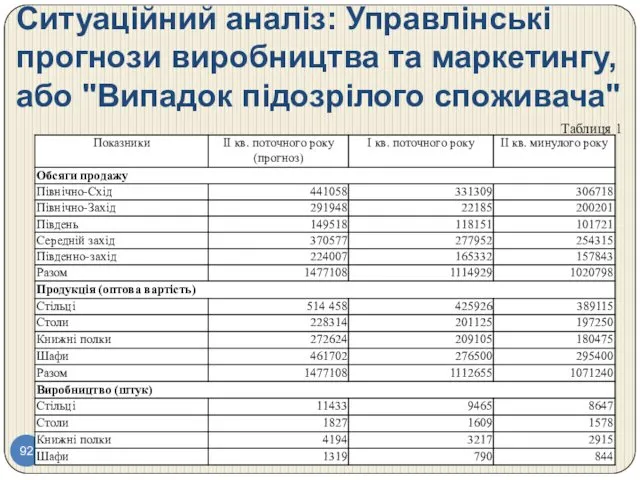
Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Таблиця
Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Таблиця

Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Харрісу
Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Харрісу

Ситуаційний аналіз:
Чому виникають сумніви?
Тому що, якщо прогноз невірний і
Ситуаційний аналіз:
Чому виникають сумніви?
Тому що, якщо прогноз невірний і

Ситуаційний аналіз: У чому може бути помилка?
Харріс і Макроурі вирішили
Ситуаційний аналіз: У чому може бути помилка?
Харріс і Макроурі вирішили
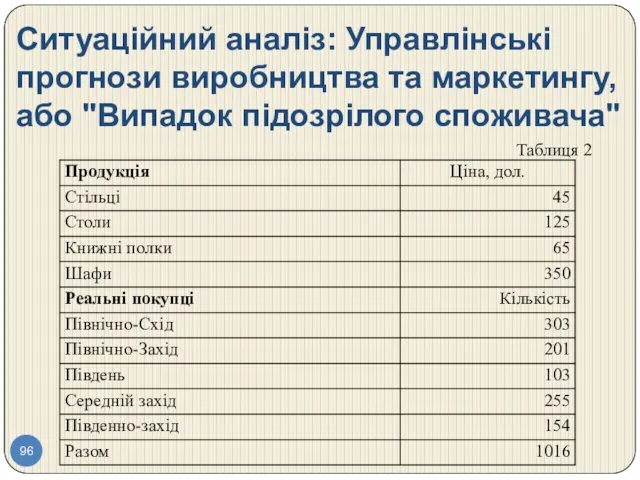
Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Таблиця
Ситуаційний аналіз: Управлінські прогнози виробництва та маркетингу, або "Випадок підозрілого споживача"
Таблиця
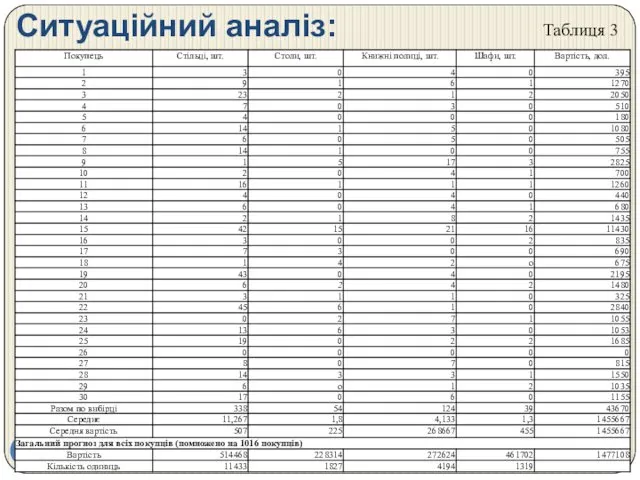
Ситуаційний аналіз:
Таблиця 3
Ситуаційний аналіз:
Таблиця 3

Ситуаційний аналіз:
Питання для обговорення (с. 168)
1. Чи підходить в даному
Ситуаційний аналіз:
Питання для обговорення (с. 168)
1. Чи підходить в даному

Мінливість даних, її статистичне оцінювання
Мінливість даних, її статистичне оцінювання

Три способи опису ступеня мінливості набору даних
Три способи опису ступеня мінливості набору даних

Три способи опису ступеня мінливості набору даних: приклад
Три способи опису ступеня мінливості набору даних: приклад

Три способи опису ступеня мінливості набору даних: приклад
Ваша фірма з
Три способи опису ступеня мінливості набору даних: приклад
Ваша фірма з

Три способи опису ступеня мінливості набору даних
Особливого сенсу цей розподіл набуває
Три способи опису ступеня мінливості набору даних
Особливого сенсу цей розподіл набуває
Приклад. Зміна прибутку на біржі
Розглянемо непостійність фондової біржі за період часу,
Приклад. Зміна прибутку на біржі
Розглянемо непостійність фондової біржі за період часу,

Приклад . Індекс Доу Джонса цін акцій 30 великих промислових компаній
Приклад . Індекс Доу Джонса цін акцій 30 великих промислових компаній

Приклад: продовження
Розподіл денного прибутку акцій 30 великих промислових компаній за
Приклад: продовження
Розподіл денного прибутку акцій 30 великих промислових компаній за
Приклад: пояснення
Середній денний прибуток за цей період часу становив -0,066%,
Приклад: пояснення
Середній денний прибуток за цей період часу становив -0,066%,

Приклад: висновки
Для того, щоб знаходитися в межах значення одного стандартного
Приклад: висновки
Для того, щоб знаходитися в межах значення одного стандартного
Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
В
Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
В

Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
Для
Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
Для

Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
Якби
Приклад: Обвал на фондовій біржі у 1987 р.: 19 стандартних відхилень.
Якби
Приклад: продовження. Нестійкість фондового ринку до обвалу і після
У період після
Приклад: продовження. Нестійкість фондового ринку до обвалу і після
У період після

Приклад: продовження. Нестійкість фондового ринку до обвалу і після
Останнім часом нестійкість
Приклад: продовження. Нестійкість фондового ринку до обвалу і після
Останнім часом нестійкість

Приклад: Диверсифікація на фондовому ринку
Розглянемо величину ризику для трьох випадків:
(1)
Приклад: Диверсифікація на фондовому ринку
Розглянемо величину ризику для трьох випадків:
(1)

Три способи опису ступеня мінливості набору даних
Три способи опису ступеня мінливості набору даних
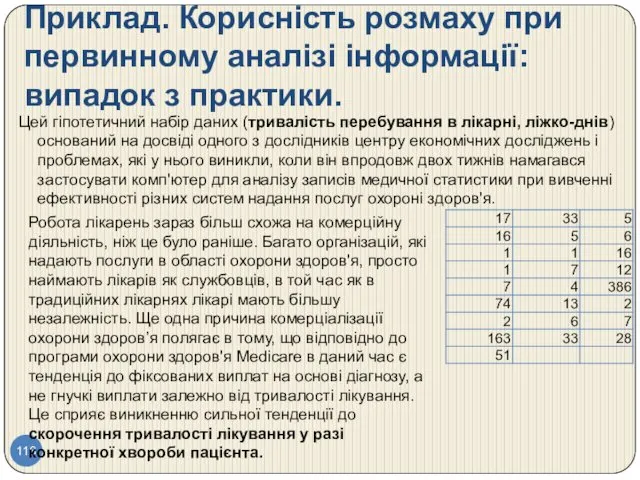
Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики.
Цей гіпотетичний
Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики.
Цей гіпотетичний

Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики.
Висновок:
При ретельній
Приклад. Корисність розмаху при первинному аналізі інформації: випадок з практики.
Висновок:
При ретельній

Три способи опису ступеня мінливості набору даних
Три способи опису ступеня мінливості набору даних

Приклад. Невизначеність прибутковості портфеля інвестицій
Ви вклали 10000 дол. у 200 акцій
Приклад. Невизначеність прибутковості портфеля інвестицій
Ви вклали 10000 дол. у 200 акцій

Приклад. Продуктивність праці у відділі торгівлі по телефону
Розглянемо відділ торгівлі па
Приклад. Продуктивність праці у відділі торгівлі по телефону
Розглянемо відділ торгівлі па

Приклад. Загальна вартість виробленого товару
Розглянемо виробництво продукту для якого фіксовані витрати
Приклад. Загальна вартість виробленого товару
Розглянемо виробництво продукту для якого фіксовані витрати

Словник термінів (с. 198):
Мінливість – variability
Різноманітність – diversity
Невизначеність –
Словник термінів (с. 198):
Мінливість – variability
Різноманітність – diversity
Невизначеність –

Самостійна робота з використанням бази даних (с. 215):
Зверніться до бази даних
Самостійна робота з використанням бази даних (с. 215):
Зверніться до бази даних

Проекти (с. 216):
1. У відповідності до власних інтересів візьміть набір значень
Проекти (с. 216):
1. У відповідності до власних інтересів візьміть набір значень

Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником?
Ви
Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником?
Ви

Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником?
Ситуація
Ситуаційний аналіз (с. 216-217): Чи слід продовжувати роботу з цим постачальником?
Ситуація
 Продукты IBM для разработки программных приложений. (Тема 9)
Продукты IBM для разработки программных приложений. (Тема 9) Основы программирования на C++
Основы программирования на C++ Единая сеть электросвязи РФ
Единая сеть электросвязи РФ Построение и исследование физической модели
Построение и исследование физической модели Базовые требования при подготовке презентаций
Базовые требования при подготовке презентаций Максимально эффективное использование ScienceDirect
Максимально эффективное использование ScienceDirect Подготовка школьников к ЕГЭ по информатике
Подготовка школьников к ЕГЭ по информатике Презентация к уроку Цикл с постусловием
Презентация к уроку Цикл с постусловием История серии видеоигры: Grand Theft Auto
История серии видеоигры: Grand Theft Auto Основы программирования на Python
Основы программирования на Python Онлайн сервис
Онлайн сервис Django. Запись данных. Урок 11
Django. Запись данных. Урок 11 Презентация к уроку Тексты в компьютерной памяти
Презентация к уроку Тексты в компьютерной памяти Информационная модель объекта
Информационная модель объекта Инструмент гарантированного доступа к госзакупкам. Портал поставщиков
Инструмент гарантированного доступа к госзакупкам. Портал поставщиков Обзор вариантов установки программ
Обзор вариантов установки программ конспект урока по информатике 9 класс по теме: Операторы ветвления+презентация
конспект урока по информатике 9 класс по теме: Операторы ветвления+презентация класс. 04.02.22
класс. 04.02.22 Вероятностный подход к определению количества информации
Вероятностный подход к определению количества информации Сети мобильной связи нового поколения. Лекция 7. Подсистема IP-мультимедиа (IMS)
Сети мобильной связи нового поколения. Лекция 7. Подсистема IP-мультимедиа (IMS) Программа курса “Введение в тестирование ПО”. Динамическое тестирование
Программа курса “Введение в тестирование ПО”. Динамическое тестирование Модели объектов. Моделирование
Модели объектов. Моделирование Мобильные вирусы и антивирусы
Мобильные вирусы и антивирусы Графикалық редакциялау
Графикалық редакциялау Проектирование программных средств
Проектирование программных средств 10 Useful, Weird or Entertaining Websites to Waste Time On
10 Useful, Weird or Entertaining Websites to Waste Time On Компьютерная графика
Компьютерная графика Программирование на языке Си
Программирование на языке Си