- Ropes или веревочное дерево

Содержание
- 2. ROPE Rope — структура данных для хранения строки, представляющая из себя двоичное сбалансированное дерево и позволяющая
- 3. ROPE В таблице приведены трудоемкости операций очереди с приоритетом:
- 4. Представление ROPE Очевидно что наша структура — это двоичное дерево поиска, в листьях которого находятся элементарные
- 5. Представление ROPE Узлы дерева имеют характеристику — вес. Если в узле дерева хранится непосредственно часть символов
- 6. Представление ROPE Структура будет имет следующий вид: struct trie { char *string; int length; struct trie
- 7. Создание узла ROPE struct trie *trie_create(char *string) { struct trie *node; if ((node = (trie*)malloc(sizeof(*node))) ==
- 8. Операция Merge (Конкатенация строк) Когда приходит запрос на конкатенацию с другой строкой мы объединяем оба дерева,
- 9. Операция Merge (Конкатенация строк) struct trie *merge(struct trie *trie1, struct trie *trie2) { struct trie *node;
- 10. Получение символа по индексу Чтобы получить символ по некоторому индексу , будем спускаться по дереву из
- 11. Получение символа по индексу char get(int i, struct trie *node) { if (node->left != NULL) if
- 12. Split (Разбиение строки) Чтобы разбить строку на две по некоторому индексу необходимо спускаясь по дереву (аналогично
- 13. Split (Разбиение строки) Пускай дано дерево:
- 14. Получение символа по индексу Тогда результатом выполнения операции по индексу будет:
- 15. Возвращение функцией двух узлов Для того, чтобы возвращать сразу два узла, воспользуемся следующей структурой: struct d_trie
- 16. Получение символа по индексу struct d_trie *split(struct trie *node, int i) { struct d_trie *res; res
- 17. Получение символа по индексу if (node->left != NULL) if (node->left->length >= i) { res = split(node->left,
- 18. Операции удаления и вставки Нетрудно понять, что имея операции merge и split, можно легко через них
- 19. Операция удаления struct trie *_delete(struct trie *node, int beginIndex, int endIndex) { struct d_trie *res; res
- 21. Скачать презентацию

ROPE
Rope — структура данных для хранения строки, представляющая из себя двоичное
ROPE
Rope — структура данных для хранения строки, представляющая из себя двоичное
ROPE
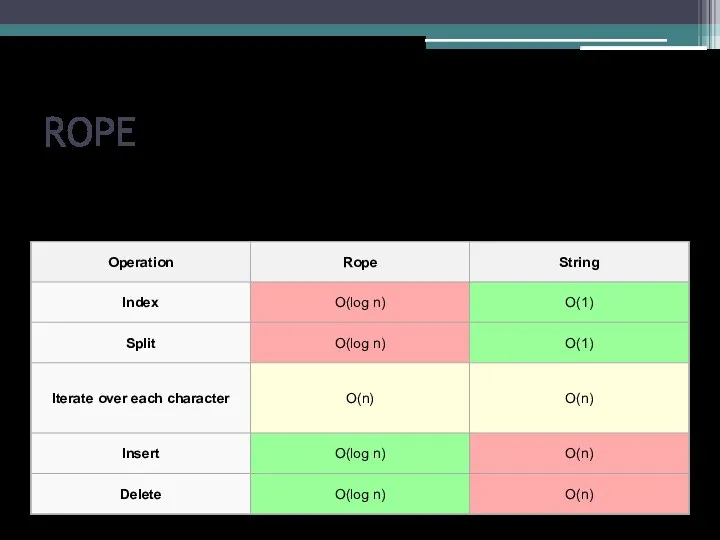
В таблице приведены трудоемкости операций очереди с приоритетом:
ROPE
В таблице приведены трудоемкости операций очереди с приоритетом:
Представление ROPE
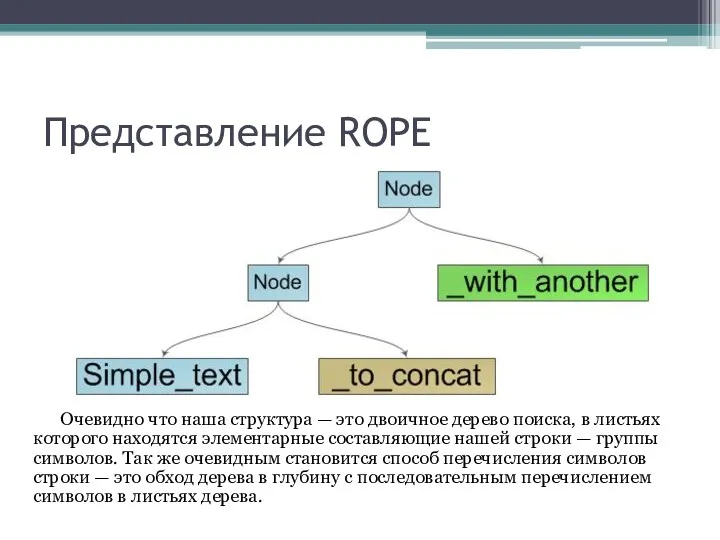
Очевидно что наша структура — это двоичное дерево поиска, в
Представление ROPE
Очевидно что наша структура — это двоичное дерево поиска, в

Представление ROPE
Узлы дерева имеют характеристику — вес. Если в узле дерева
Представление ROPE
Узлы дерева имеют характеристику — вес. Если в узле дерева

Представление ROPE
Структура будет имет следующий вид:
struct trie
{
char *string;
int length;
struct trie *left;
struct
Представление ROPE
Структура будет имет следующий вид:
struct trie
{
char *string;
int length;
struct trie *left;
struct

Создание узла ROPE
struct trie *trie_create(char *string)
{
struct trie *node;
if ((node =
Создание узла ROPE
struct trie *trie_create(char *string)
{
struct trie *node;
if ((node =
Операция Merge (Конкатенация строк)
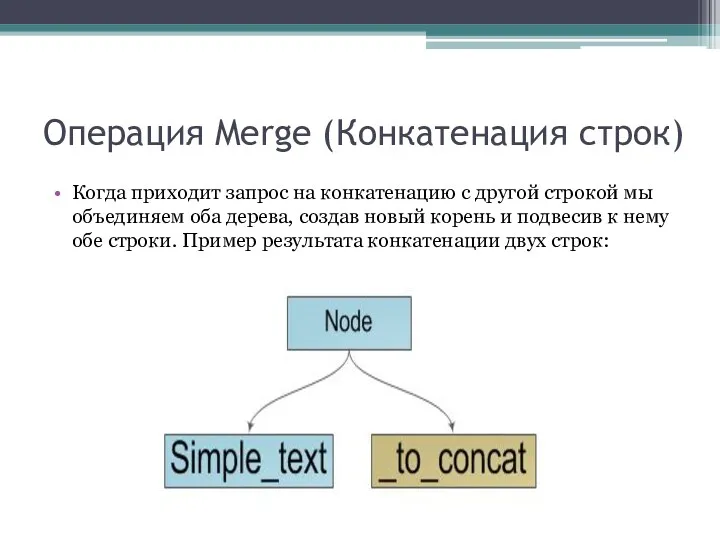
Когда приходит запрос на конкатенацию с другой строкой
Операция Merge (Конкатенация строк)
Когда приходит запрос на конкатенацию с другой строкой

Операция Merge (Конкатенация строк)
struct trie *merge(struct trie *trie1, struct trie *trie2)
{
struct
Операция Merge (Конкатенация строк)
struct trie *merge(struct trie *trie1, struct trie *trie2)
{
struct

Получение символа по индексу
Чтобы получить символ по некоторому индексу , будем спускаться
Получение символа по индексу
Чтобы получить символ по некоторому индексу , будем спускаться

Получение символа по индексу
char get(int i, struct trie *node)
{
if (node->left !=
Получение символа по индексу
char get(int i, struct trie *node)
{
if (node->left !=

Split (Разбиение строки)
Чтобы разбить строку на две по некоторому индексу необходимо спускаясь
Split (Разбиение строки)
Чтобы разбить строку на две по некоторому индексу необходимо спускаясь
Split (Разбиение строки)
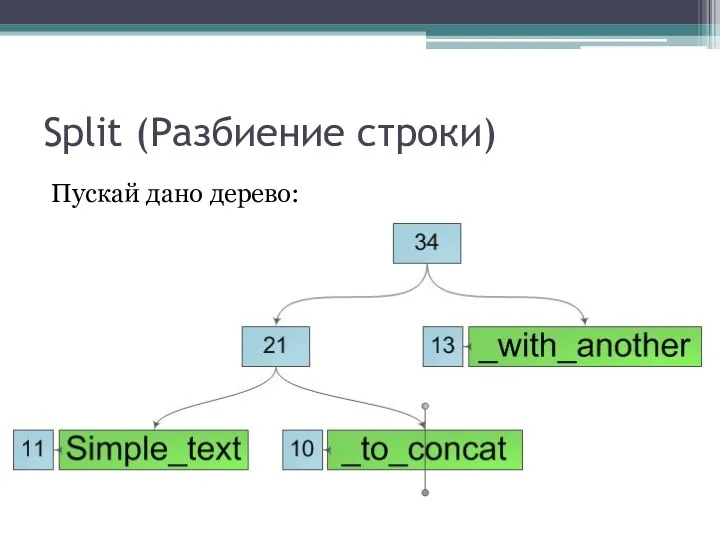
Пускай дано дерево:
Split (Разбиение строки)
Пускай дано дерево:
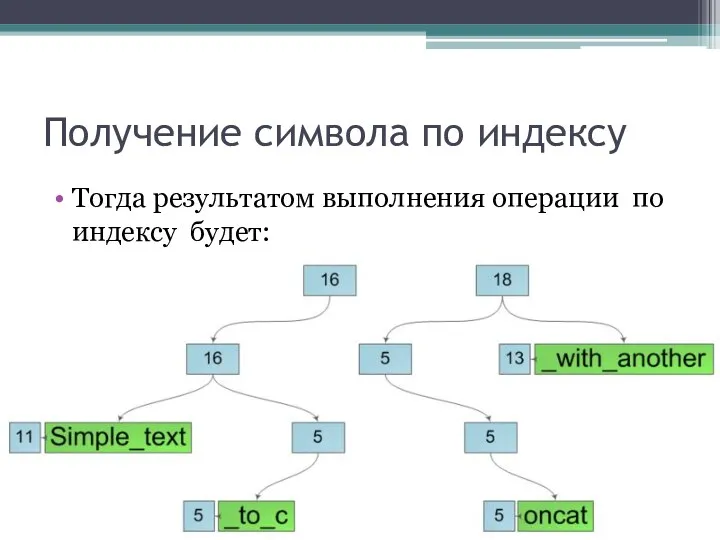
Получение символа по индексу
Тогда результатом выполнения операции по индексу будет:
Получение символа по индексу
Тогда результатом выполнения операции по индексу будет:

Возвращение функцией двух узлов
Для того, чтобы возвращать сразу два узла, воспользуемся
Возвращение функцией двух узлов
Для того, чтобы возвращать сразу два узла, воспользуемся

Получение символа по индексу
struct d_trie *split(struct trie *node, int i)
{
struct d_trie
Получение символа по индексу
struct d_trie *split(struct trie *node, int i)
{
struct d_trie

Получение символа по индексу
if (node->left != NULL)
if (node->left->length >= i)
{
res =
Получение символа по индексу
if (node->left != NULL)
if (node->left->length >= i)
{
res =

Операции удаления и вставки
Нетрудно понять, что имея операции merge и split, можно легко через
Операции удаления и вставки
Нетрудно понять, что имея операции merge и split, можно легко через

Операция удаления
struct trie *_delete(struct trie *node, int beginIndex, int endIndex)
{
struct d_trie
Операция удаления
struct trie *_delete(struct trie *node, int beginIndex, int endIndex)
{
struct d_trie
 Пресс-службы в органах власти
Пресс-службы в органах власти Computer club. Бизнес-проект
Computer club. Бизнес-проект Сотовые и спутниковые системы
Сотовые и спутниковые системы Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Проектирование баз данных
Проектирование баз данных Публицистический стиль. Основные признаки. Подстили и жанры. Языковые особенности
Публицистический стиль. Основные признаки. Подстили и жанры. Языковые особенности Технология Drag and Drop
Технология Drag and Drop Своя игра по информатике
Своя игра по информатике Презентация Инновационные подходы в образовании
Презентация Инновационные подходы в образовании Warcraft III
Warcraft III The method of software upgrade for tablet PC B902
The method of software upgrade for tablet PC B902 Электронные услуги в сфере образования
Электронные услуги в сфере образования Введение в цикл разработки ПО
Введение в цикл разработки ПО Общие свойства объектов одного класса. Информатика, 3 класс, 1 часть
Общие свойства объектов одного класса. Информатика, 3 класс, 1 часть Алгоритмы и исполнители
Алгоритмы и исполнители Сети и системы телекоммуникаций. Транспортный уровень
Сети и системы телекоммуникаций. Транспортный уровень Вирусы и антивирусы
Вирусы и антивирусы Гуманитарные образовательные технологии как отражение инновационных процессов в образовании
Гуманитарные образовательные технологии как отражение инновационных процессов в образовании Понятие. Понятие личности
Понятие. Понятие личности Теория автоматов и формальных языков
Теория автоматов и формальных языков Циклические структуры
Циклические структуры ФГИС ЕГРН. Общая информация
ФГИС ЕГРН. Общая информация Система стандартов по информации, библиотечному и издательскому делу. Организационно-распорядительная документация
Система стандартов по информации, библиотечному и издательскому делу. Организационно-распорядительная документация Язык HTML — язык тегов
Язык HTML — язык тегов Международная журналистика
Международная журналистика Алгоритмы на графах
Алгоритмы на графах Самостоятельная работа по информатике 6 класс. классификации
Самостоятельная работа по информатике 6 класс. классификации Программирование на языке Си#. Форма. Лекция 40
Программирование на языке Си#. Форма. Лекция 40