- САОД stl, метрика Левенштейна

Содержание
- 2. Контрольные вопросы Для каких целей применяются объекты, учитывающие ссылки? Можно ли сказать, что в .Net применяются
- 3. Рассмотрены STL Потоки Строки Средства отладки Общие свойства контейнеров Последовательные контейнеры: Список Динамический массив Очереди и
- 4. STL – стандартная библиотека (шаблонов) STL - Standard Template Library Набор абстрактных типов данных и алгоритмов.
- 5. Потоки (STL) Обобщенный способ организации ввода/вывода. Потоки ввода (istream), Потоки вывода (ostream), И потоки ввода-вывода (iostream).
- 6. Моды потоков Потоки открываются в бинарной и текстовой моде В текстовой моде можно управлять форматированием. Например,
- 7. Специальные потоки потоки cout, cin, cerr, clog связаны только со стандартным вводом выводом. Потоки стандартного ввода-вывода
- 8. Строковые потоки Часто потоки связываются со строкой. Так удобно накапливать результат или разбирать содержимое строк. Для
- 9. Файловые потоки Для работы с файловыми потоками нужно использовать заголовок #include #include #include using namespace std;
- 10. Файловые потоки int main(){ char fName[128]; cout cout ifstream ifs; ifs.open(fName); // (fName, ios_base::binary); if (ifs.is_open())
- 11. Файловые потоки Пример в бинарной моде int main(){ char fName[128]; cout cout char c = ‘0’;
- 12. Строки Стандартная библиотека предоставляет класс работы со строками – заголовок . Теперь вместо: char fName[128]; cout
- 13. Строки Минимальный набор Конструкторы: string(), string (const char *p) и string(const string &s) и др. Операции:
- 14. Отладка (assert) Полезный инструмент разработки в STL – макрос assert (подтвердить) Часто при реализации алгоритмов нужно
- 15. Контейнеры в STL Важная часть STL – шаблоны контейнеров. Контейнеры – классы для хранения объектов других
- 16. Общие свойства контейнеров Контейнеры STL можно параметризовать любыми типами, для которых определены операции =, == и
- 17. Итераторы Итераторы - типы, позволяющие двигаться по контейнеру ::iterator i = obj.begin(); ::iterator i = obj.end();
- 18. Итераторы Начиная с C++11 можно: for (auto &v : obj) { // Делаем что хотели с
- 19. Итераторы и .Net Как правило, использование итераторов позволяет более эффективно пройти по всему контейнеру, чем другие
- 20. Последовательные контейнеры Последовательными называются контейнеры, в которых имеет смысл (определен) порядок элементов. Очередь, массив, список –
- 21. Последовательные контейнеры Список typedef list LSTSTR; //Создание LSTSTR lst1, lst2(5, “abc”); LSTSTR lst3(lst2), lst4(lst2.begin(), --lst2.end()); //Проверка
- 22. Список //Добавление элементов lst1.push_back(“2”); // {2} lst1.push_front(“1”); // {1,2} lst1.insert(--lst1.end(), “a”); // list is {1,a,2} cout
- 23. Список //Присваивание lst2 = lst1; //Удаление элементов lst1.remove(“a”); // {3,2} lst1.erase(lst1.begin()) // {2} lst1.erase(lst1.end()) // empty
- 24. Последовательные контейнеры Динамический массив В принципе, другие контейнеры рассматриваем аналогично: как создать, какие операции и свойства,
- 25. Последовательные контейнеры Динамический массив // добавляем элемент в конец массива v2.push_back(11); cout // Можно и v2.insert(v2.begin(),
- 26. Последовательные контейнеры Динамический массив В дополнение к списку vector (как и string) имеет 2 характеристики размера:
- 27. Последовательные контейнеры Очереди и стеки - Double ended queue, двусторонняя очередь (сокращенно Дек). Позволяет помещать и
- 28. Ассоциативные контейнеры В ассоциативных контейнерах порядок элементов не играет значения (это вопрос реализации). Получаем или изменяем
- 29. Ассоциативные контейнеры Множество typedef set SETSTR; //Создание SETSTR s, s2; //Пустой cout //Добавление элементов s.insert (“abc”);
- 30. Пары pair – удобная абстракция pair pr; //ключом является int, значение – string. pr.first = 1;
- 31. Ассоциативные контейнеры Таблицы Таблицы (map), содержат пары: - typedef map STR2INT; //Создание STR2INT m; //Пустой cout
- 32. Ассоциативные контейнеры Таблицы Таблицы (map), содержат пары: - typedef map STR2INT; //Поиск STR2INT::iterator i = m.find(“a”);
- 33. Таблицы* int n = m.count(“a”); // 1 или 0 STR2INT::iterator i = m.find(“ab”); //i == m.end()
- 34. Ассоциативные контейнеры Hash-таблицы В STL имеются ассоциативные контейнеры даже более быстрые, чем set и map. Это
- 35. Ассоциативные контейнеры. Hash-таблицы. Аналогично map typedef unordered_map U_STR2INT; //Создание U_STR2INT u; //Пустой cout //Добавить и изменить
- 36. Ассоциативные контейнеры. Hash-таблицы. продолжение //Поиск U_STR2INT::iterator i = u.find(“a”); // i != u.end(), // (*i).first ==
- 37. Прочие шаблоны Иногда полезно иметь контейнер для хранения нескольких элементов с одинаковым ключом. В STL это
- 38. Прочие шаблоны STL имеет набор стандартных алгоритмов. Описаны в заголовочном файле операции с контейнерами для их
- 39. Аналоги контейнеров в .Net List - динамический массив, аналог vector Dictionary - словарь, таблица, аналог map
- 40. Зачем столько контейнеров? Сложность изменения списка O(1), а чтения элемента с заданным номером O(N); Сложность изменения
- 41. Примеры применения контейнеров. Задача. Найти N самых частых слов в тексте. Задачу можно решить в 2
- 42. Примеры применения контейнеров. typedef map STR2INT; Предположим, что все слова в верхнем регистре, т.е. “Hello” и
- 43. Примеры применения контейнеров int N=16; //подготовили множество пар typedef set > SET_OF_N_STR; SET_OF_N_STR mostFriquent; for (auto
- 44. Контрольные вопросы Почему контейнеры называются абстрактными типами данных? Что такое последовательные и ассоциативные контейнеры? Приведите примеры
- 45. Умные указатели (smart pointers) Одна из распространенных ошибок в C++ связана с new ... Нет соответствующего
- 46. Умные указатели (smart pointers) В примерах будем использовать класс Test class Test { public: int val;
- 47. Умные указатели (smart pointers) shared_ptr pt(new Test); pt – это объект типа shared_ptr , проинициализированный указателем
- 48. Умные указатели Основные операции shared_ptr pt(new Test); Конструкторы копирования и инициализации, = - присваивание, ->, *
- 49. Умные указатели демонстрация shared_ptr pt(new Test); cout cout cout val shared_ptr ps; cout cout cout val
- 50. Умные указатели Заключительные замечания Умные указатели shard_ptr реализуют подсчет ссылок на объект владения. Имеются и другие
- 51. Алгоритмы хеширования Отмечали, что unordered_... являются hash-таблицами. Хеширование применяется не только для построения hash-таблиц, а также:
- 52. Алгоритмы хеширования в STL Шаблон класса std::hash имеет единственный метод size_t operator ()(const T& v) Используется
- 53. Кольцевые алгоритмы хеширования
- 54. Контрольные вопросы Что означает термин “умные указатели” (smart pointers)? Зачем они введены в STL? Как называется
- 55. Близость строк Применения: задачи нечеткой логики; подсказка при проверке правописания; коррекция орфографических ошибок в поисковых машинах;
- 56. Близость строк В.И. Левенштейн , 1965 г. Метрика (расстояние) – симметричная неотрицательная функция, удовлетворяющая “правилу треугольника”:
- 57. Близость строк “выравнивание” Применительно к биоинформатике выявление различий между аминокислотами называется “выравниванием”. Задача выглядит так. Имеется
- 58. Близость строк Расстояние Один из алгоритмов вычисления расстояния - Вагнер и Фишер (1974). Для вычисления расстояния
- 59. Близость строк Алгоритм заполнения D после инициализации можно описать рекуррентной формулой: D[i, j] = min (
- 60. Близость строк Рассмотрим на примере слов: но, оно. Вычислим элемент матрицы (1,1). Первые символы не совпали.
- 61. Близость строк Анимация алгоритма на примере слов: но и оно О 0 ? 1 2 3
- 62. Близость строк динамическое программирование Алгоритм Вагнера-Фишера - пример динамического программирования. Метод динамического программирования применим, когда задача
- 63. Близость строк Редакционное предписание После достраивания таблицы (красным курсивом) Выясняем, что расстояние (наименьшее количество операций) между
- 64. Близость строк Редакционное предписание. Шаг 1. Редакционное предписание – последовательность операций, которая позволяет первую строку (по
- 65. Близость строк Редакционное предписание. Шаг 2. ^ см. предыдущий слайд … 3. Теперь мы находимся или
- 66. Близость строк Редакционное предписание. Пример. Вернемся к примеру слов: но, оно. н о о н о
- 67. Близость строк Редакционное предписание. Пояснение. Длина предписания всегда равна длине наибольшей строки. Алгоритм восстановления редакционного предписания
- 68. Близость строк Можно обобщить алгоритм, считая, что стоимость различных операций различна. Алгоритм при этом несколько модифицируется*.
- 69. Близость строк Сложность При больших объемах данных важна память и эффективность по времени исполнения. Алгоритм Вагнера-Фишера
- 71. Скачать презентацию

Контрольные вопросы
Для каких целей применяются объекты, учитывающие ссылки?
Можно ли сказать, что
Контрольные вопросы
Для каких целей применяются объекты, учитывающие ссылки?
Можно ли сказать, что

Рассмотрены
STL
Потоки
Строки
Средства отладки
Общие свойства контейнеров
Последовательные контейнеры:
Список
Динамический массив
Очереди и стеки
Ассоциативные контейнеры:
Множества
Словари (map)
Hash –
Рассмотрены
STL
Потоки
Строки
Средства отладки
Общие свойства контейнеров
Последовательные контейнеры:
Список
Динамический массив
Очереди и стеки
Ассоциативные контейнеры:
Множества
Словари (map)
Hash –

STL – стандартная библиотека (шаблонов)
STL - Standard Template Library
Набор абстрактных типов
STL – стандартная библиотека (шаблонов)
STL - Standard Template Library
Набор абстрактных типов

Потоки (STL)
Обобщенный способ организации ввода/вывода.
Потоки ввода (istream),
Потоки вывода (ostream),
И
Потоки (STL)
Обобщенный способ организации ввода/вывода.
Потоки ввода (istream),
Потоки вывода (ostream),
И

Моды потоков
Потоки открываются в бинарной и текстовой моде
В текстовой моде можно
Моды потоков
Потоки открываются в бинарной и текстовой моде
В текстовой моде можно

Специальные потоки
потоки cout, cin, cerr, clog связаны только со стандартным вводом
Специальные потоки
потоки cout, cin, cerr, clog связаны только со стандартным вводом

Строковые потоки
Часто потоки связываются со строкой.
Так удобно накапливать результат или разбирать
Строковые потоки
Часто потоки связываются со строкой.
Так удобно накапливать результат или разбирать

Файловые потоки
Для работы с файловыми потоками нужно использовать заголовок #include
#include
Файловые потоки
Для работы с файловыми потоками нужно использовать заголовок #include
#include
![Файловые потоки int main(){ char fName[128]; cout cout ifstream ifs;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581722/slide-9.jpg)
Файловые потоки
int main(){
char fName[128];
cout << "File name ? : "; cin.getline(fName,
Файловые потоки
int main(){
char fName[128];
cout << "File name ? : "; cin.getline(fName,
![Файловые потоки Пример в бинарной моде int main(){ char fName[128];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581722/slide-10.jpg)
Файловые потоки
Пример в бинарной моде
int main(){
char fName[128];
cout << "File name ?
Файловые потоки
Пример в бинарной моде
int main(){
char fName[128];
cout << "File name ?

Строки
Стандартная библиотека предоставляет класс работы со строками – заголовок .
Теперь вместо:
char
Строки
Стандартная библиотека предоставляет класс работы со строками – заголовок
Теперь вместо:
char

Строки
Минимальный набор
Конструкторы: string(), string (const char *p) и string(const string
Строки
Минимальный набор
Конструкторы: string(), string (const char *p) и string(const string

Отладка
(assert)
Полезный инструмент разработки в STL – макрос assert (подтвердить)
Часто при реализации
Отладка
(assert)
Полезный инструмент разработки в STL – макрос assert (подтвердить)
Часто при реализации

Контейнеры в STL
Важная часть STL – шаблоны контейнеров.
Контейнеры – классы для
Контейнеры в STL
Важная часть STL – шаблоны контейнеров.
Контейнеры – классы для

Общие свойства контейнеров
Контейнеры STL можно параметризовать любыми типами, для которых определены
Общие свойства контейнеров
Контейнеры STL можно параметризовать любыми типами, для которых определены

Итераторы
Итераторы - типы, позволяющие двигаться по контейнеру
::iterator i = obj.begin();
Итераторы
Итераторы - типы, позволяющие двигаться по контейнеру

Итераторы
Начиная с C++11 можно:
for (auto &v : obj) {
// Делаем что
Итераторы
Начиная с C++11 можно:
for (auto &v : obj) {
// Делаем что

Итераторы и .Net
Как правило, использование итераторов позволяет более эффективно пройти по
Итераторы и .Net
Как правило, использование итераторов позволяет более эффективно пройти по

Последовательные контейнеры
Последовательными называются контейнеры, в которых имеет смысл (определен) порядок
Последовательные контейнеры
Последовательными называются контейнеры, в которых имеет смысл (определен) порядок

Последовательные контейнеры Список
typedef list LSTSTR;
//Создание
LSTSTR lst1, lst2(5, “abc”);
LSTSTR lst3(lst2), lst4(lst2.begin(),
Последовательные контейнеры Список
typedef list
//Создание
LSTSTR lst1, lst2(5, “abc”);
LSTSTR lst3(lst2), lst4(lst2.begin(),

Список
//Добавление элементов
lst1.push_back(“2”); // {2}
lst1.push_front(“1”); // {1,2}
lst1.insert(--lst1.end(), “a”); // list is {1,a,2}
cout
Список
//Добавление элементов
lst1.push_back(“2”); // {2}
lst1.push_front(“1”); // {1,2}
lst1.insert(--lst1.end(), “a”); // list is {1,a,2}
cout

Список
//Присваивание
lst2 = lst1;
//Удаление элементов
lst1.remove(“a”); // {3,2}
lst1.erase(lst1.begin()) // {2}
lst1.erase(lst1.end()) // empty
//Отсортировать список методом
Список
//Присваивание
lst2 = lst1;
//Удаление элементов
lst1.remove(“a”); // {3,2}
lst1.erase(lst1.begin()) // {2}
lst1.erase(lst1.end()) // empty
//Отсортировать список методом

Последовательные контейнеры Динамический массив
В принципе, другие контейнеры рассматриваем аналогично:
как создать,
Последовательные контейнеры Динамический массив
В принципе, другие контейнеры рассматриваем аналогично:
как создать,

Последовательные контейнеры Динамический массив
// добавляем элемент в конец массива
v2.push_back(11);
cout <<
Последовательные контейнеры Динамический массив
// добавляем элемент в конец массива
v2.push_back(11);
cout <<

Последовательные контейнеры Динамический массив
В дополнение к списку vector (как и string)
Последовательные контейнеры Динамический массив
В дополнение к списку vector (как и string)

Последовательные контейнеры Очереди и стеки
- Double ended queue, двусторонняя очередь
Последовательные контейнеры Очереди и стеки

Ассоциативные контейнеры
В ассоциативных контейнерах порядок элементов не играет значения (это вопрос
Ассоциативные контейнеры
В ассоциативных контейнерах порядок элементов не играет значения (это вопрос

Ассоциативные контейнеры
Множество
typedef set SETSTR;
//Создание
SETSTR s, s2;
//Пустой
cout << s.empty() << endl; //true
//Добавление
Ассоциативные контейнеры
Множество
typedef set
//Создание
SETSTR s, s2;
//Пустой
cout << s.empty() << endl; //true
//Добавление

Пары
pair – удобная абстракция <ключ, значение>
pair pr; //ключом является int,
Пары
pair – удобная абстракция <ключ, значение>
pair

Ассоциативные контейнеры
Таблицы
Таблицы (map), содержат пары: <ключ>-<значение>
typedef map STR2INT;
//Создание
STR2INT m;
//Пустой
cout <<
Ассоциативные контейнеры
Таблицы
Таблицы (map), содержат пары: <ключ>-<значение>
typedef map
//Создание
STR2INT m;
//Пустой
cout <<

Ассоциативные контейнеры
Таблицы
Таблицы (map), содержат пары: <ключ>-<значение>
typedef map STR2INT;
//Поиск
STR2INT::iterator i =
Ассоциативные контейнеры
Таблицы
Таблицы (map), содержат пары: <ключ>-<значение>
typedef map
//Поиск
STR2INT::iterator i =

Таблицы*
int n = m.count(“a”); // 1 или 0
STR2INT::iterator i = m.find(“ab”);
Таблицы*
int n = m.count(“a”); // 1 или 0
STR2INT::iterator i = m.find(“ab”);

Ассоциативные контейнеры
Hash-таблицы
В STL имеются ассоциативные контейнеры даже более быстрые, чем set
Ассоциативные контейнеры
Hash-таблицы
В STL имеются ассоциативные контейнеры даже более быстрые, чем set

Ассоциативные контейнеры.
Hash-таблицы.
Аналогично map
typedef unordered_map U_STR2INT;
//Создание
U_STR2INT u;
//Пустой
cout << u.empty() << endl;
Ассоциативные контейнеры.
Hash-таблицы.
Аналогично map
typedef unordered_map
//Создание
U_STR2INT u;
//Пустой
cout << u.empty() << endl;

Ассоциативные контейнеры.
Hash-таблицы.
продолжение
//Поиск
U_STR2INT::iterator i = u.find(“a”); // i != u.end(),
// (*i).first
Ассоциативные контейнеры.
Hash-таблицы.
продолжение
//Поиск
U_STR2INT::iterator i = u.find(“a”); // i != u.end(),
// (*i).first

Прочие шаблоны
Иногда полезно иметь контейнер для хранения нескольких элементов с одинаковым
Прочие шаблоны
Иногда полезно иметь контейнер для хранения нескольких элементов с одинаковым

Прочие шаблоны
STL имеет набор стандартных алгоритмов.
Описаны в заголовочном файле
операции с
Прочие шаблоны
STL имеет набор стандартных алгоритмов.
Описаны в заголовочном файле

Аналоги контейнеров в .Net
List<> - динамический массив, аналог vector
Dictionary<,> - словарь,
Аналоги контейнеров в .Net
List<> - динамический массив, аналог vector
Dictionary<,> - словарь,

Зачем столько контейнеров?
Сложность изменения списка O(1), а чтения элемента с заданным
Зачем столько контейнеров?
Сложность изменения списка O(1), а чтения элемента с заданным

Примеры применения контейнеров.
Задача. Найти N самых частых слов в тексте.
Задачу можно
Примеры применения контейнеров.
Задача. Найти N самых частых слов в тексте.
Задачу можно

Примеры применения контейнеров.
typedef map STR2INT;
Предположим, что все слова в верхнем
Примеры применения контейнеров.
typedef map
Предположим, что все слова в верхнем

Примеры применения контейнеров
int N=16;
//подготовили множество пар <целое - строка>
typedef set>
Примеры применения контейнеров
int N=16;
//подготовили множество пар <целое - строка>
typedef set

Контрольные вопросы
Почему контейнеры называются абстрактными типами данных?
Что такое последовательные и ассоциативные
Контрольные вопросы
Почему контейнеры называются абстрактными типами данных?
Что такое последовательные и ассоциативные

Умные указатели
(smart pointers)
Одна из распространенных ошибок в C++ связана с new
Умные указатели
(smart pointers)
Одна из распространенных ошибок в C++ связана с new

Умные указатели
(smart pointers)
В примерах будем использовать класс Test
class Test
{
public:
int val;
Test() {val
Умные указатели
(smart pointers)
В примерах будем использовать класс Test
class Test
{
public:
int val;
Test() {val

Умные указатели
(smart pointers)
shared_ptr pt(new Test);
pt – это объект типа shared_ptr ,
Умные указатели
(smart pointers)
shared_ptr
pt – это объект типа shared_ptr

Умные указатели
Основные операции
shared_ptr pt(new Test);
Конструкторы копирования и инициализации,
= - присваивание,
->, *
Умные указатели
Основные операции
shared_ptr
Конструкторы копирования и инициализации,
= - присваивание,
->, *

Умные указатели
демонстрация
shared_ptr pt(new Test);
cout << (bool)pt << endl; // 1
cout <<
Умные указатели
демонстрация
shared_ptr
cout << (bool)pt << endl; // 1
cout <<

Умные указатели
Заключительные замечания
Умные указатели shard_ptr реализуют подсчет ссылок на объект владения.
Имеются
Умные указатели
Заключительные замечания
Умные указатели shard_ptr реализуют подсчет ссылок на объект владения.
Имеются

Алгоритмы хеширования
Отмечали, что unordered_... являются hash-таблицами.
Хеширование применяется не только для
Алгоритмы хеширования
Отмечали, что unordered_... являются hash-таблицами.
Хеширование применяется не только для

Алгоритмы хеширования
в STL
Шаблон класса std::hash имеет единственный метод
size_t operator ()(const
Алгоритмы хеширования
в STL
Шаблон класса std::hash имеет единственный метод
size_t operator ()(const

Кольцевые алгоритмы
хеширования
Кольцевые алгоритмы
хеширования

Контрольные вопросы
Что означает термин “умные указатели” (smart pointers)? Зачем они введены
Контрольные вопросы
Что означает термин “умные указатели” (smart pointers)? Зачем они введены

Близость строк
Применения:
задачи нечеткой логики;
подсказка при проверке правописания;
коррекция орфографических ошибок
Близость строк
Применения:
задачи нечеткой логики;
подсказка при проверке правописания;
коррекция орфографических ошибок

Близость строк
В.И. Левенштейн , 1965 г.
Метрика (расстояние) – симметричная неотрицательная функция,
Близость строк
В.И. Левенштейн , 1965 г.
Метрика (расстояние) – симметричная неотрицательная функция,

Близость строк
“выравнивание”
Применительно к биоинформатике выявление различий между аминокислотами называется “выравниванием”.
Задача выглядит
Близость строк
“выравнивание”
Применительно к биоинформатике выявление различий между аминокислотами называется “выравниванием”.
Задача выглядит

Близость строк
Расстояние
Один из алгоритмов вычисления расстояния - Вагнер и Фишер (1974).
Для
Близость строк
Расстояние
Один из алгоритмов вычисления расстояния - Вагнер и Фишер (1974).
Для

Близость строк
Алгоритм заполнения D после инициализации можно описать рекуррентной формулой:
D[i, j]
Близость строк
Алгоритм заполнения D после инициализации можно описать рекуррентной формулой:
D[i, j]

Близость строк
Рассмотрим на примере слов: но, оно.
Вычислим элемент матрицы (1,1). Первые
Близость строк
Рассмотрим на примере слов: но, оно.
Вычислим элемент матрицы (1,1). Первые
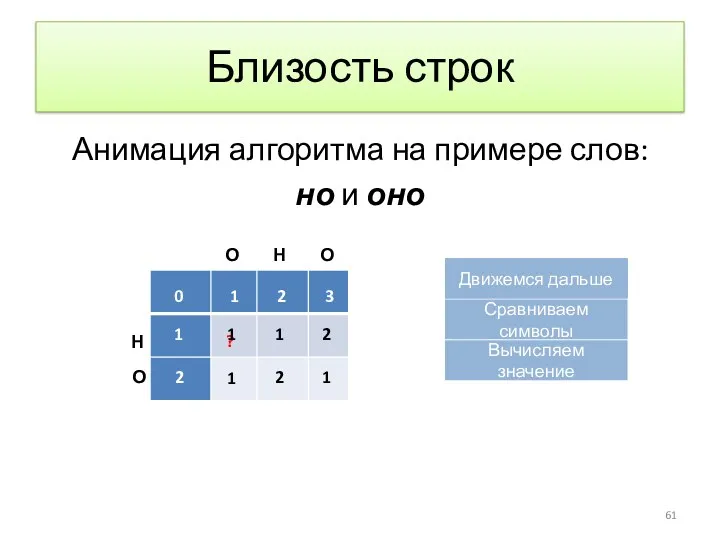
Близость строк
Анимация алгоритма на примере слов:
но и оно
О
0
?
1
2
3
1
2
О
Н
О
Н
1
1
Сравниваем символы
Вычисляем значение
2
1
1
2
Начинаем
Близость строк
Анимация алгоритма на примере слов:
но и оно
О
0
?
1
2
3
1
2
О
Н
О
Н
1
1
Сравниваем символы
Вычисляем значение
2
1
1
2
Начинаем

Близость строк
динамическое программирование
Алгоритм Вагнера-Фишера - пример динамического программирования.
Метод динамического программирования применим,
Близость строк
динамическое программирование
Алгоритм Вагнера-Фишера - пример динамического программирования.
Метод динамического программирования применим,
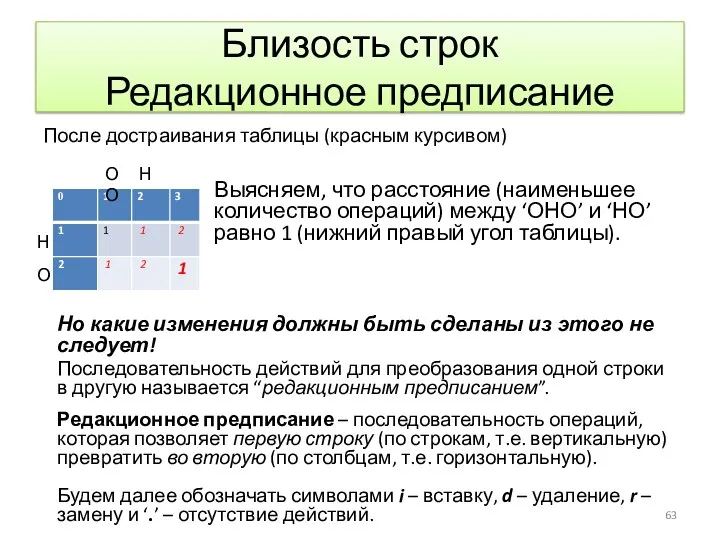
Близость строк
Редакционное предписание
После достраивания таблицы (красным курсивом)
Выясняем, что расстояние (наименьшее
Близость строк
Редакционное предписание
После достраивания таблицы (красным курсивом)
Выясняем, что расстояние (наименьшее

Близость строк
Редакционное предписание. Шаг 1.
Редакционное предписание – последовательность операций, которая позволяет
Близость строк
Редакционное предписание. Шаг 1.
Редакционное предписание – последовательность операций, которая позволяет

Близость строк
Редакционное предписание. Шаг 2.
^
см. предыдущий слайд …
3. Теперь мы находимся
Близость строк
Редакционное предписание. Шаг 2.
^
см. предыдущий слайд …
3. Теперь мы находимся

Близость строк
Редакционное предписание. Пример.
Вернемся к примеру слов: но, оно.
н
о
о н о
Путь
Близость строк
Редакционное предписание. Пример.
Вернемся к примеру слов: но, оно.
н
о
о н о
Путь

Близость строк
Редакционное предписание. Пояснение.
Длина предписания всегда равна длине наибольшей строки.
Алгоритм восстановления
Близость строк
Редакционное предписание. Пояснение.
Длина предписания всегда равна длине наибольшей строки.
Алгоритм восстановления

Близость строк
Можно обобщить алгоритм, считая, что стоимость различных операций различна.
Алгоритм при
Близость строк
Можно обобщить алгоритм, считая, что стоимость различных операций различна.
Алгоритм при

Близость строк
Сложность
При больших объемах данных важна память и эффективность по времени
Близость строк
Сложность
При больших объемах данных важна память и эффективность по времени
 Средства отладки программ. Контроль текста программы
Средства отладки программ. Контроль текста программы Создание универсального строительного калькулятора по расчету стоимости постройки гаража
Создание универсального строительного калькулятора по расчету стоимости постройки гаража Российские ОС на основе Линукс для госкомпаний и бизнеса
Российские ОС на основе Линукс для госкомпаний и бизнеса Стандартные функции языка CLIPS. Стандартные арифметические функции
Стандартные функции языка CLIPS. Стандартные арифметические функции Возможности динамических (электронных) таблиц
Возможности динамических (электронных) таблиц Интернетугрозы. Кибербезопасность
Интернетугрозы. Кибербезопасность Microsoft Word кестелер, суреттер және су белгілерін енгізу
Microsoft Word кестелер, суреттер және су белгілерін енгізу Семиуровневая модель OSI
Семиуровневая модель OSI Методы представления графических изображений
Методы представления графических изображений Шаблон
Шаблон Информационные технологии в отрасли (области знаний)
Информационные технологии в отрасли (области знаний) Основные устройства компьютера
Основные устройства компьютера Software Development Life Cycle and Methodologies
Software Development Life Cycle and Methodologies Программное обеспечение персонального компьютера
Программное обеспечение персонального компьютера Основы программирования: ТЕМА 02. СТРУКТУРА ПРОГРАММЫ В ПАСКАЛЕ. ВВОД И ВЫВОД ДАННЫХ.
Основы программирования: ТЕМА 02. СТРУКТУРА ПРОГРАММЫ В ПАСКАЛЕ. ВВОД И ВЫВОД ДАННЫХ. Методические рекомендации по оформлению мультимедийных презентаций
Методические рекомендации по оформлению мультимедийных презентаций Arrays Loops. Java Core
Arrays Loops. Java Core Programming Language Java
Programming Language Java Газета совета студенческого самоуправления. Колледж-City
Газета совета студенческого самоуправления. Колледж-City Что такое Unity и Vuforia
Что такое Unity и Vuforia Мемы и русский язык
Мемы и русский язык Прикладные информационные технологии. Представление знаний в информационных системах
Прикладные информационные технологии. Представление знаний в информационных системах Алгоритм работы с входящей заявкой/сделкой от oператора
Алгоритм работы с входящей заявкой/сделкой от oператора Операционная система. Назначение и основные функции
Операционная система. Назначение и основные функции Решение математических задач в MS Excel
Решение математических задач в MS Excel Мобильное оборудование. Проблема выбора
Мобильное оборудование. Проблема выбора Операционная система
Операционная система Угадай и отгадай!
Угадай и отгадай!