- Схема работы лексического анализатора

Содержание
- 2. Лексический анализатор Синтаксический анализатор Семантический разбор и т.п. Исходная программа Таблица символов Токен запрос следующего Дерево
- 3. Токены, шаблоны, лексемы
- 4. Пример результирующего набора лексем 1. Лексема id («Идентификатор») с номером лексемы и таблицу с именами идентификаторов.
- 5. Пример обработки входного потока if distance >= speed * (endtime-starttime) then distance := distance – delta;
- 6. Простейший вариант конечного автомата
- 7. Атрибуты лексем Атрибуты – это способ хранения дополнительной информации о лексеме (например, конкретное значение константы, имя
- 8. Пример: bool c; int a=1,b=2; c = a>b>>2; Последний оператор порождает следующую последовательность лексем и их
- 9. Таблица представлений Место хранения экземпляров (по одному) всех внешних представлений идентификаторов (и, возможно, также для всех
- 10. Разработка лексера с Coco/R Coco/R использует метод рекурсивного спуска для анализа LL(1)-грамматик, т.е. грамматик, для которых
- 11. Грамматика Pascal для Coco/R COMPILER Pascal IGNORE CASE CHARACTERS eol = CHR(13) . letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
- 12. Разработка лексера с lex/Flex Инструмент для создания лексически анализаторов – Lex, состоящий из Lex-языка и Lex-компилятора.
- 13. Грамматика Pascal для lex %{ #include #include "y.tab.h" int line_no = 1; %} A [aA] B
- 14. {A}{N}{D} return(AND); {A}{R}{R}{A}{Y} return(ARRAY); {C}{A}{S}{E} return(CASE); {C}{O}{N}{S}{T} return(CONST); {D}{I}{V} return(DIV); {D}{O} return(DO); {D}{O}{W}{N}{T}{O} return(DOWNTO); {E}{L}{S}{E} return(ELSE);
- 15. ":=" return(ASSIGNMENT); '({NQUOTE}|'')+' return(CHARACTER_STRING); ":" return(COLON); "," return(COMMA); [0-9]+ return(DIGSEQ); "." return(DOT); ".." return(DOTDOT); "=" return(EQUAL);
- 16. "(*" | "{" { register int c; while ((c = input())) { if (c == '}')
- 17. while (1) { fix=i; switch(s[i]) { case '"': // Распознавание строковой константы ". . ." с
- 18. Подсчет числа слов и строк в файле /***************** Раздел определений *********************/ NODELIM [^" "\t\n] /* NODELIM
- 19. Специальные конструкции и функции Lex yytext – указатель на отождествленную цепочку символов, оканчивающуюся нулем; yyleng –
- 21. Скачать презентацию
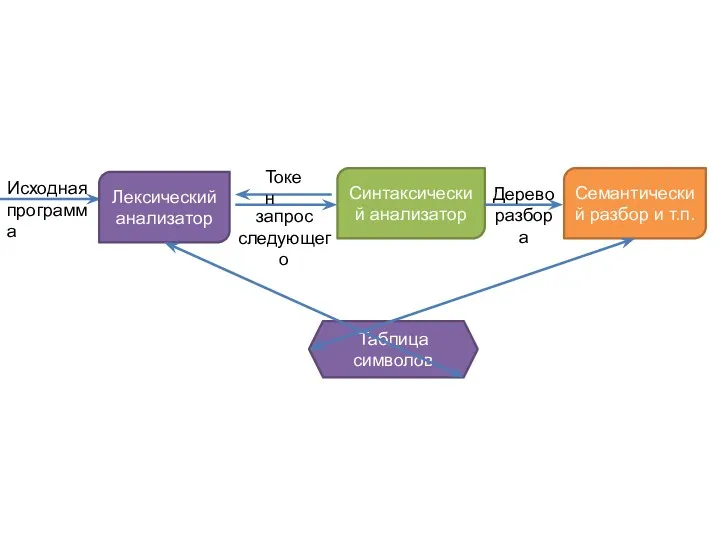
Лексический анализатор
Синтаксический анализатор
Семантический разбор и т.п.
Исходная
программа
Таблица символов
Токен
запрос
следующего
Дерево
разбора
Лексический анализатор
Синтаксический анализатор
Семантический разбор и т.п.
Исходная
программа
Таблица символов
Токен
запрос
следующего
Дерево
разбора

Токены, шаблоны, лексемы
Токены, шаблоны, лексемы

Пример результирующего
набора лексем
1. Лексема id («Идентификатор») с номером лексемы и
Пример результирующего
набора лексем
1. Лексема id («Идентификатор») с номером лексемы и
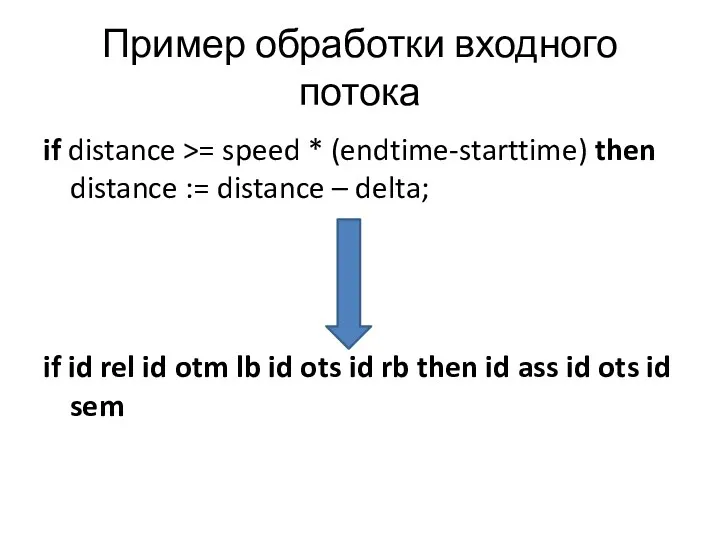
Пример обработки входного потока
if distance >= speed * (endtime-starttime) then distance
Пример обработки входного потока
if distance >= speed * (endtime-starttime) then distance
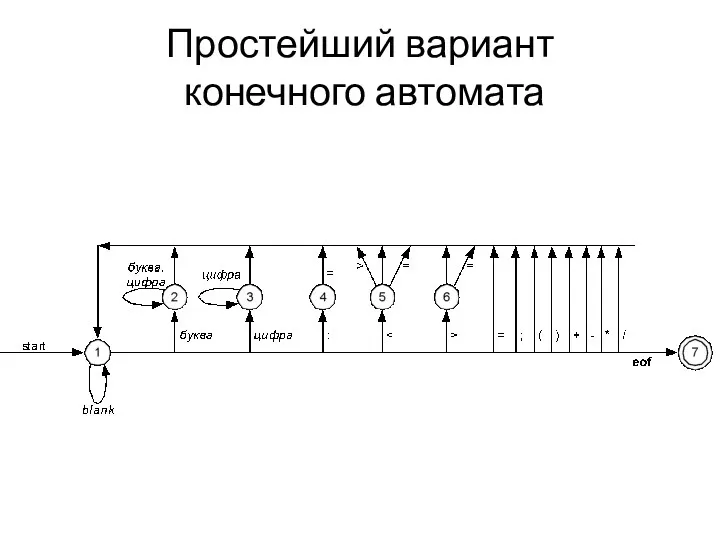
Простейший вариант
конечного автомата
Простейший вариант
конечного автомата

Атрибуты лексем
Атрибуты – это способ хранения дополнительной информации о лексеме (например,
Атрибуты лексем
Атрибуты – это способ хранения дополнительной информации о лексеме (например,

Пример:
bool c; int a=1,b=2;
c = a>b>>2;
Последний оператор порождает следующую последовательность
Пример:
bool c; int a=1,b=2;
c = a>b>>2;
Последний оператор порождает следующую последовательность

Таблица представлений
Место хранения экземпляров (по одному) всех внешних представлений идентификаторов (и,
Таблица представлений
Место хранения экземпляров (по одному) всех внешних представлений идентификаторов (и,

Разработка лексера с Coco/R
Coco/R использует метод рекурсивного спуска для анализа LL(1)-грамматик,
Разработка лексера с Coco/R
Coco/R использует метод рекурсивного спуска для анализа LL(1)-грамматик,

Грамматика Pascal для Coco/R
COMPILER Pascal
IGNORE CASE
CHARACTERS
eol = CHR(13) .
letter
Грамматика Pascal для Coco/R
COMPILER Pascal
IGNORE CASE
CHARACTERS
eol = CHR(13) .
letter
Разработка лексера с lex/Flex
Инструмент для создания лексически анализаторов – Lex, состоящий
Разработка лексера с lex/Flex
Инструмент для создания лексически анализаторов – Lex, состоящий

Грамматика Pascal для lex
%{
#include
#include "y.tab.h"
int line_no = 1;
%}
A [aA]
B [bB]
C
Грамматика Pascal для lex
%{
#include
#include "y.tab.h"
int line_no = 1;
%}
A [aA]
B [bB]
C

{A}{N}{D} return(AND);
{A}{R}{R}{A}{Y} return(ARRAY);
{C}{A}{S}{E} return(CASE);
{C}{O}{N}{S}{T} return(CONST);
{D}{I}{V} return(DIV);
{D}{O} return(DO);
{D}{O}{W}{N}{T}{O} return(DOWNTO);
{E}{L}{S}{E} return(ELSE);
{E}{N}{D} return(END);
{E}{X}{T}{E}{R}{N} |
{E}{X}{T}{E}{R}{N}{A}{L}
{A}{N}{D} return(AND);
{A}{R}{R}{A}{Y} return(ARRAY);
{C}{A}{S}{E} return(CASE);
{C}{O}{N}{S}{T} return(CONST);
{D}{I}{V} return(DIV);
{D}{O} return(DO);
{D}{O}{W}{N}{T}{O} return(DOWNTO);
{E}{L}{S}{E} return(ELSE);
{E}{N}{D} return(END);
{E}{X}{T}{E}{R}{N} |
{E}{X}{T}{E}{R}{N}{A}{L}
![":=" return(ASSIGNMENT); '({NQUOTE}|'')+' return(CHARACTER_STRING); ":" return(COLON); "," return(COMMA); [0-9]+ return(DIGSEQ);](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/348621/slide-14.jpg)
":=" return(ASSIGNMENT);
'({NQUOTE}|'')+' return(CHARACTER_STRING);
":" return(COLON);
"," return(COMMA);
[0-9]+ return(DIGSEQ);
"." return(DOT);
".." return(DOTDOT);
"=" return(EQUAL);
">=" return(GE);
">" return(GT);
"["
":=" return(ASSIGNMENT);
'({NQUOTE}|'')+' return(CHARACTER_STRING);
":" return(COLON);
"," return(COMMA);
[0-9]+ return(DIGSEQ);
"." return(DOT);
".." return(DOTDOT);
"=" return(EQUAL);
">=" return(GE);
">" return(GT);
"["

"(*" |
"{" { register int c;
while ((c = input()))
{
"{" { register int c;
while ((c = input()))
{
![while (1) { fix=i; switch(s[i]) { case '"': // Распознавание](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/348621/slide-16.jpg)
while (1)
{ fix=i;
switch(s[i])
{
case '"': // Распознавание строковой константы ". .
while (1)
{ fix=i;
switch(s[i])
{
case '"': // Распознавание строковой константы ". .

Подсчет числа слов и строк в файле
/***************** Раздел определений *********************/
NODELIM [^"
Подсчет числа слов и строк в файле
/***************** Раздел определений *********************/
NODELIM [^"

Специальные конструкции и
функции Lex
yytext – указатель на отождествленную цепочку символов, оканчивающуюся
Специальные конструкции и
функции Lex
yytext – указатель на отождествленную цепочку символов, оканчивающуюся
 Управление реляционными базами данных. Языки определения данных и языки манипулирования данными
Управление реляционными базами данных. Языки определения данных и языки манипулирования данными Защита информации
Защита информации Кодирование и обработка звуковой информации. Создание звукового клипа
Кодирование и обработка звуковой информации. Создание звукового клипа Динамические структуры данных. Односвязные и двусвязные списки
Динамические структуры данных. Односвязные и двусвязные списки Опасности в Интернете
Опасности в Интернете Помощники человека при счёте
Помощники человека при счёте Слова с компьютерной начинкой. Блиц-турнир
Слова с компьютерной начинкой. Блиц-турнир Характеристика и типы линий связи
Характеристика и типы линий связи Условный рендеринг
Условный рендеринг Администрирование межсетевых экранов. Лекция 7
Администрирование межсетевых экранов. Лекция 7 Как GC освобождает память
Как GC освобождает память Ресурсы для организации дистанционного обучения (1)
Ресурсы для организации дистанционного обучения (1) Устройство и функционирование информационной системы
Устройство и функционирование информационной системы Технология JSF (Java Server Faces)
Технология JSF (Java Server Faces) Алгоритм работы с фрагментами рисунка: поворот, наклон
Алгоритм работы с фрагментами рисунка: поворот, наклон Административно-правовые формы и методы реализации исполнительной власти
Административно-правовые формы и методы реализации исполнительной власти Основы работы в системе управления базами данных (СУБД) MS Access
Основы работы в системе управления базами данных (СУБД) MS Access Табличный процессор Microsoft Excel 2007
Табличный процессор Microsoft Excel 2007 Технологии программирования
Технологии программирования Язык С. Алгоритмические структуры
Язык С. Алгоритмические структуры SVG: Syntax Sprites Animation
SVG: Syntax Sprites Animation Как продвигать свой бизнес без сложных настроек
Как продвигать свой бизнес без сложных настроек Введение в JavaScript. Лекция 16
Введение в JavaScript. Лекция 16 Язык Python. Виключення
Язык Python. Виключення Мультемедиялық тенологияларды ң оқу үдеріснде пайдалану
Мультемедиялық тенологияларды ң оқу үдеріснде пайдалану Разработка Web-сайтовс использованием языка разметки гипертекста НТМL.
Разработка Web-сайтовс использованием языка разметки гипертекста НТМL. Моделювання технологічних процесів експлуатації засобів електротранспорту
Моделювання технологічних процесів експлуатації засобів електротранспорту Краткая характеристика содержания произведения печати или рукописи - аннотация
Краткая характеристика содержания произведения печати или рукописи - аннотация