- Сокращение размерности пространства признаков при классификации

Содержание
- 2. Результаты оформляются в виде таблицы
- 3. Понижение размерности Это процесс уменьшения анализируемого множества данных до размера, оптимального с точки зрения решаемой задачи
- 4. Поэтому во втором случае предъявляются очень жесткие требования по отбору данных: сокращение объема должно происходить за
- 5. Подмножество данных, полученное в результате сокращения размерности, должно унаследовать от исходного множества столько информации, сколько необходимо
- 6. Метод главных компонент Постараемся передать суть метода главных компонент, используя интуитивно-понятную геометрическую интерпретацию. Начнем с простейшего
- 7. Графическое представление двумерных данных
- 8. Каждой строке исходной таблицы соответствует точка на плоскости с соответствующими координатами. Они обозначены пустыми кружками на
- 11. В общем, многомерном случае, процесс выделения главных компонент происходит так: Ищется центр облака данных, и туда
- 12. В результате, мы переходим от большого количества переменных к новому представлению, размерность которого значительно меньше. Часто
- 13. Суть метода главных компонент - это существенное понижение размерности данных. Исходная матрица X заменяется двумя новыми
- 14. Формальное описание Пусть имеется матрица переменных X размерностью (I×J), где I - число строк, а J
- 15. Важным свойством PCA является ортогональность (независимость) главных компонент. Поэтому матрица счетов T не перестраивается при увеличении
- 16. Алгоритм Чаще всего для построения PCA счетов и нагрузок, используется рекуррентный алгоритм, который на каждом шаге
- 17. После того, как построено пространство из главных компонент, новые объекты Xnew могут быть на него спроецированы,
- 18. PCA и SVD Метод главных компонент тесно связан с другим разложением - по сингулярным значениям, SVD.
- 19. Собственные векторы и собственные значения Пусть A — это квадратная матрица. Вектор v называется собственным вектором
- 20. Собственные значения У матрицы A размерности (N×N) не может быть больше чем N собственных значений. Они
- 21. Собственные векторы У матрицы A размерности (N×N) не может быть больше чем N собственных векторов, каждый
- 22. Определение главных компонент в Matlab PC = princomp(X) [PC,SCORE,latent,tsquare] = princomp(X) PC = princomp(X) функция предназначена
- 23. [PC,SCORE,latent,tsquare] = princomp(X) функция возвращает матрицу главных компонент PC, матрицу Z-множества данных SCORE, собственные значения latent
- 24. Пример ирисов Фишера с genfis1 Выполним построение гибридной сети anfis для ирисов Фишера аналогично предыдущему. Для
- 25. load fisheriris; Xt1=meas(1:25,:); Xt2=meas(51:75,:); Xt3=meas(101:125,:); Xt=[Xt1;Xt2;Xt3]; Yt(1:25)=1; Yt(26:50)=2; Yt(51:75)=3; Xc1=meas(26:50,:); Xc2=meas(76:100,:); Xc3=meas(126:150,:); Xc=[Xc1;Xc2;Xc3]; Yc(1:25)=1; Yc(26:50)=2; Yc(51:75)=3;
- 26. grid on fis = genfis1(T,[3],char('trimf'),char('constant')) epoch_n = 10; [fis,trn_error] = anfis(T, fis) ; writefis(fis,'gf1'); subplot(2,2,2) plot(trn_error);xlabel('Epochs');
- 27. an_t=round(anfis_t); an_c=round(anfis_c); proc_t=length(find(an_t==Yt'))/75*100; proc_c=length(find(an_c==Yc'))/75*100;
- 28. Графики
- 29. Процент распознанных По обучающей выборке 100% По тестовой выборке 86.67% Время создания системы нечеткого вывода и
- 30. Система нечеткого вывода
- 31. Метод главных компонент Используем 2 первые главные компоненты Будем стандартизировать данные путем деления каждого столбца на
- 32. load fisheriris; stdr = std(meas); meas = meas./repmat(stdr,150,1); [coefs,scores,variances,t2] = princomp(meas); Yt(1:25)=1; Yt(26:50)=2; Yt(51:75)=3; Xt1=scores(1:25,1 :2);
- 33. Xt=[Xt1;Xt2;Xt3]; T=[Xt Yt']; C=[Xc Yc']; subplot(2,3,1) plot(Xt(:,1),Xt(:,2),' .'); grid on fis = genfis1(T,[3],char('trimf'),char('constant')); subplot(2,3,2) plotmf(fis,'input',1); epoch_n
- 34. Xt=[Xt1;Xt2;Xt3]; T=[Xt Yt']; C=[Xc Yc']; subplot(2,3,1) plot(Xt(:,1),Xt(:,2),' .'); grid on fis = genfis1(T,[3],char('trimf'),char('constant')); subplot(2,3,2) plotmf(fis,'input',1); epoch_n
- 35. Графики
- 36. Процент распознанных По обучающей выборке 92% По тестовой выборке 92% Время создания системы нечеткого вывода и
- 37. Система нечеткого вывода
- 38. Факторный анализ Многомерные данные часто содержат большое число признаков и часто эти признаки перекрываются в том
- 39. Модель факторного анализа В модели факторного анализа измеренные переменные зависят от меньшего количества ненаблюдаемых (скрытых) факторов.
- 40. Модель простого факторного анализа может быть представлена в виде X=μ+λf+e (1) где X- вектор наблюдений многомерной
- 41. Другой формой записи модели простого факторного анализа является выражение Cov(X)=λλT+C (2) где C=cov(e) . С является
- 42. Функция factoran [lambda,psi] = factoran(X,m) функция возвращает выходной параметр psi - вектор точечных оценок дисперсий специфических
- 43. Пример факторного анализа Факторные нагрузки В течение 100 недель были зарегистрированы процентные изменения цен на акции
- 44. В этом примере вначале загружаются данные и вызывается функция factoran, определяющая модель с 3 простыми факторами.
- 45. load stockreturns [Loadings,specificVar,T,stats] = ... factoran(stocks,3,'rotate','none'); Первые два выходных аргумента factoran представляют собой расчетные нагрузки и
- 46. Loadings Loadings = 0.8885 0.2367 -0.2354 0.7126 0.3862 0.0034 0.3351 0.2784 -0.0211 0.3088 0.1113 -0.1905 0.6277
- 47. Анализируя отклонения, можно видеть, что модель указывает на значительные изменения цены акций при изменении общих факторов.
- 48. Структура stats позволяет проверить нулевую гипотезу H0, состоящую в том, что число простых факторов равно m.
- 49. Чтобы определить, можно ли выбрать меньшее число факторов, чем 3, построим модель с двумя простыми факторами.
- 50. Вращение факторов Как показывают результаты, нагрузки, подсчитанные по факторам, не подвергающимся вращениям, имеют сложную структуру. Цель
- 51. Если рассматривать каждую строку матрицы нагрузок как координаты точки в M-мерном пространстве, то каждый фактор соответствует
- 52. [LoadingsPM,specVarPM] = factoran(stocks,3,'rotate','promax'); LoadingsPM LoadingsPM = 0.9452 0.1214 -0.0617 0.7064 -0.0178 0.2058 0.3885 -0.0994 0.0975 0.4162
- 53. Вращение promax создает более простую структуру нагрузок, в каждой из которых большинство компаний имеет большую нагрузку
- 54. biplot(coefs) создает график коэффициентов матрице coefs. График является двумерным , если coefs имеет два столбца или
- 55. Наиболее употребимые параметры: Scores Выводит матрицу coefs VarLabels Метки каждого вектора (переменной) с текстами в символьном
- 56. Для нашего примера biplot(LoadingsPM,'varlabels',num2str((1:10)')); выведет рисунок:
- 58. Этот график показывает, что косоугольное вращение привело нагрузки факторов к простейшей структуре. Каждая компания зависит в
- 59. Координаты факторов Часто полезно классифицировать наблюдения на основе координат их факторов. Например, если принята трехфакторная модель
- 60. [LoadingsPM,specVarPM,TPM,stats,F] = ... factoran(stocks, 3,'rotate','promax'); %TPM – матрица вращения %матрица F является матрицей с размерностью n×m.
- 62. Косоугольное вращение часто создает коррелированные факторы. Рисунок дает некоторые доказательства корреляции между первым и третьим факторами
- 63. Визуализация результатов Можно использовать функцию biplot для визуализации факторных нагрузок для каждой переменной и факторных множеств
- 65. В этом случае biplot является трехмерным. Каждая из 10 компаний представлена на этом графике вектором, и
- 66. Каждое из 100 наблюдений представлено на графике точкой, и их положение указывает координаты каждого наблюдения по
- 67. Пример с ирисами Фишера Так как число признаков d=4,то согласно ограничению можно создать только один фактор
- 68. Создадим модель с косоугольными вращениями и сохраним координаты факторов: [LoadingsPM,specVarPM,TPM,stats,F] = ... factoran(meas, 1,'rotate','promax'); Массив F
- 69. load fisheriris [Loadings2,specificVar2,T2,stats2] = ... factoran(meas,1,'rotate','none'); [LoadingsPM,specVarPM,TPM,stats,F] = ... factoran(meas, 1,'rotate','promax'); Xt1=F(1:25); Xt2=F(51:75); Xt3=F(101:125); Xt=[Xt1;Xt2;Xt3]; Yt(1:25)=1;
- 70. Построим систему нечеткого вывода с помощью genfis1 и настроим ее с помощью anfis fis = genfis1(T,[2],char('trimf'),char('constant'))
- 72. Посчитаем выходные значения по системе нечеткого вывода для обучающих и контролирующих данных: anfis_t = evalfis(Xt, fis);
- 74. Скачать презентацию
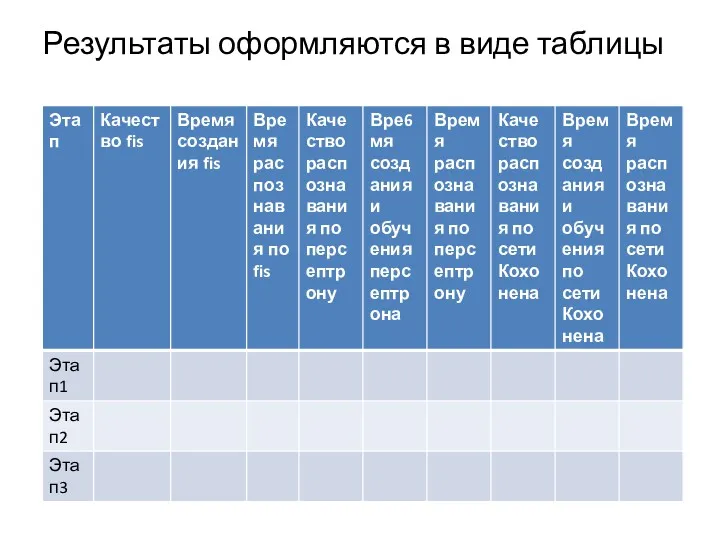
Результаты оформляются в виде таблицы
Результаты оформляются в виде таблицы

Понижение размерности
Это процесс уменьшения анализируемого множества данных до размера, оптимального с
Понижение размерности
Это процесс уменьшения анализируемого множества данных до размера, оптимального с

Поэтому во втором случае предъявляются очень жесткие требования по отбору данных:
Поэтому во втором случае предъявляются очень жесткие требования по отбору данных:

Подмножество данных, полученное в результате сокращения размерности, должно унаследовать от
Подмножество данных, полученное в результате сокращения размерности, должно унаследовать от

Метод главных компонент
Постараемся передать суть метода главных компонент, используя интуитивно-понятную геометрическую
Метод главных компонент
Постараемся передать суть метода главных компонент, используя интуитивно-понятную геометрическую

Графическое представление двумерных данных
Графическое представление двумерных данных

Каждой строке исходной таблицы соответствует точка на плоскости с соответствующими координатами.
Каждой строке исходной таблицы соответствует точка на плоскости с соответствующими координатами.
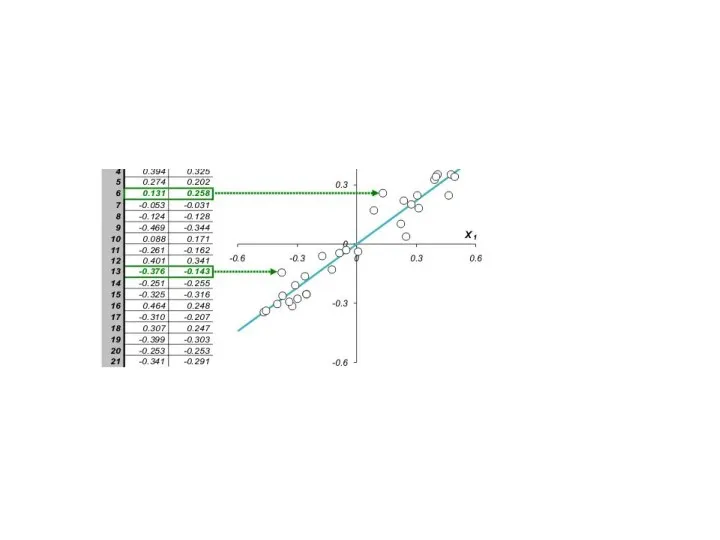
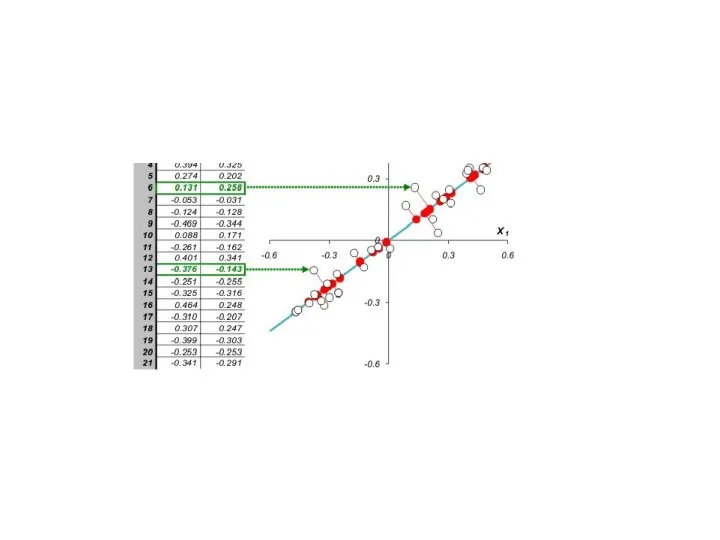

В общем, многомерном случае, процесс выделения главных компонент происходит так:
Ищется
В общем, многомерном случае, процесс выделения главных компонент происходит так:
Ищется

В результате, мы переходим от большого количества переменных к новому представлению,
В результате, мы переходим от большого количества переменных к новому представлению,

Суть метода главных компонент - это существенное понижение размерности данных. Исходная
Суть метода главных компонент - это существенное понижение размерности данных. Исходная

Формальное описание
Пусть имеется матрица переменных X размерностью (I×J), где I -
Формальное описание
Пусть имеется матрица переменных X размерностью (I×J), где I -

Важным свойством PCA является ортогональность (независимость) главных
компонент.
Поэтому матрица счетов
Важным свойством PCA является ортогональность (независимость) главных
компонент.
Поэтому матрица счетов

Алгоритм
Чаще всего для построения PCA счетов и нагрузок, используется рекуррентный
Алгоритм
Чаще всего для построения PCA счетов и нагрузок, используется рекуррентный

После того, как построено пространство из главных компонент,
новые объекты Xnew
После того, как построено пространство из главных компонент,
новые объекты Xnew

PCA и SVD
Метод главных компонент тесно связан с другим разложением -
PCA и SVD
Метод главных компонент тесно связан с другим разложением -

Собственные векторы и собственные значения
Пусть A — это квадратная матрица. Вектор
Собственные векторы и собственные значения
Пусть A — это квадратная матрица. Вектор

Собственные значения
У матрицы A размерности (N×N) не может быть больше чем
Собственные значения
У матрицы A размерности (N×N) не может быть больше чем

Собственные векторы
У матрицы A размерности (N×N) не может быть больше чем
Собственные векторы
У матрицы A размерности (N×N) не может быть больше чем
![Определение главных компонент в Matlab PC = princomp(X) [PC,SCORE,latent,tsquare] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-21.jpg)
Определение главных компонент в Matlab
PC = princomp(X)
[PC,SCORE,latent,tsquare] = princomp(X)
PC = princomp(X)
Определение главных компонент в Matlab
PC = princomp(X)
[PC,SCORE,latent,tsquare] = princomp(X)
PC = princomp(X)
![[PC,SCORE,latent,tsquare] = princomp(X) функция возвращает матрицу главных компонент PC, матрицу](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-22.jpg)
[PC,SCORE,latent,tsquare] = princomp(X) функция возвращает матрицу главных компонент PC, матрицу Z-множества
[PC,SCORE,latent,tsquare] = princomp(X) функция возвращает матрицу главных компонент PC, матрицу Z-множества

Пример ирисов Фишера с genfis1
Выполним построение гибридной сети anfis для ирисов
Пример ирисов Фишера с genfis1
Выполним построение гибридной сети anfis для ирисов
![load fisheriris; Xt1=meas(1:25,:); Xt2=meas(51:75,:); Xt3=meas(101:125,:); Xt=[Xt1;Xt2;Xt3]; Yt(1:25)=1; Yt(26:50)=2; Yt(51:75)=3; Xc1=meas(26:50,:);](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-24.jpg)
load fisheriris;
Xt1=meas(1:25,:);
Xt2=meas(51:75,:);
Xt3=meas(101:125,:);
Xt=[Xt1;Xt2;Xt3];
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xc1=meas(26:50,:);
Xc2=meas(76:100,:);
Xc3=meas(126:150,:);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,2,1)
plot3(Xt(:,1),Xt(:,2),Xt(:,3),' .');
load fisheriris;
Xt1=meas(1:25,:);
Xt2=meas(51:75,:);
Xt3=meas(101:125,:);
Xt=[Xt1;Xt2;Xt3];
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xc1=meas(26:50,:);
Xc2=meas(76:100,:);
Xc3=meas(126:150,:);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,2,1)
plot3(Xt(:,1),Xt(:,2),Xt(:,3),' .');
![grid on fis = genfis1(T,[3],char('trimf'),char('constant')) epoch_n = 10; [fis,trn_error] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-25.jpg)
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'))
epoch_n = 10; [fis,trn_error] = anfis(T, fis) ;
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'))
epoch_n = 10; [fis,trn_error] = anfis(T, fis) ;

an_t=round(anfis_t);
an_c=round(anfis_c);
proc_t=length(find(an_t==Yt'))/75*100;
proc_c=length(find(an_c==Yc'))/75*100;
an_t=round(anfis_t);
an_c=round(anfis_c);
proc_t=length(find(an_t==Yt'))/75*100;
proc_c=length(find(an_c==Yc'))/75*100;
Графики
Графики

Процент распознанных
По обучающей выборке 100%
По тестовой выборке 86.67%
Время создания системы нечеткого
Процент распознанных
По обучающей выборке 100%
По тестовой выборке 86.67%
Время создания системы нечеткого
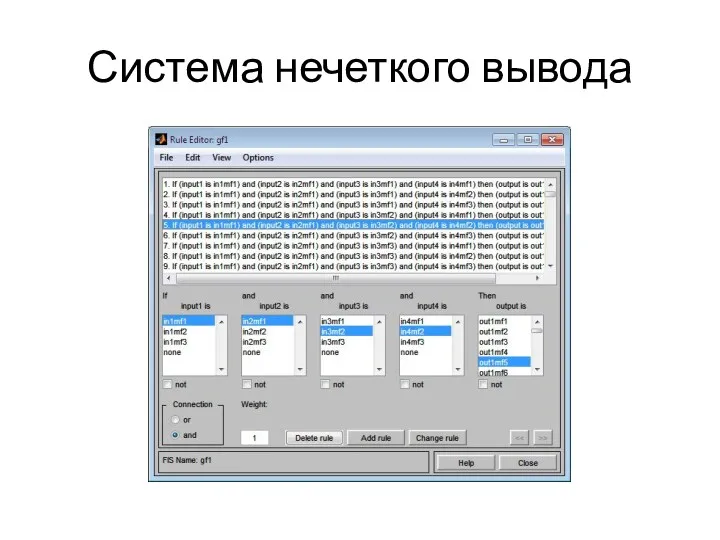
Система нечеткого вывода
Система нечеткого вывода

Метод главных компонент
Используем 2 первые главные компоненты
Будем стандартизировать данные путем
Метод главных компонент
Используем 2 первые главные компоненты
Будем стандартизировать данные путем
![load fisheriris; stdr = std(meas); meas = meas./repmat(stdr,150,1); [coefs,scores,variances,t2] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-31.jpg)
load fisheriris;
stdr = std(meas);
meas = meas./repmat(stdr,150,1);
[coefs,scores,variances,t2] = princomp(meas);
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xt1=scores(1:25,1 :2);
Xt2=scores(51:75,1:2);
Xt3=scores(101:125,1:2);
Xc1=scores(26:50,1:2);
Xc2=scores(76:100,1:2);
Xc3=scores(126:150,1:2);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
tic
load fisheriris;
stdr = std(meas);
meas = meas./repmat(stdr,150,1);
[coefs,scores,variances,t2] = princomp(meas);
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xt1=scores(1:25,1 :2);
Xt2=scores(51:75,1:2);
Xt3=scores(101:125,1:2);
Xc1=scores(26:50,1:2);
Xc2=scores(76:100,1:2);
Xc3=scores(126:150,1:2);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
tic
![Xt=[Xt1;Xt2;Xt3]; T=[Xt Yt']; C=[Xc Yc']; subplot(2,3,1) plot(Xt(:,1),Xt(:,2),' .'); grid on](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-32.jpg)
Xt=[Xt1;Xt2;Xt3];
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,3,1)
plot(Xt(:,1),Xt(:,2),' .');
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'));
subplot(2,3,2)
plotmf(fis,'input',1);
epoch_n = 10;
Xt=[Xt1;Xt2;Xt3];
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,3,1)
plot(Xt(:,1),Xt(:,2),' .');
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'));
subplot(2,3,2)
plotmf(fis,'input',1);
epoch_n = 10;
![Xt=[Xt1;Xt2;Xt3]; T=[Xt Yt']; C=[Xc Yc']; subplot(2,3,1) plot(Xt(:,1),Xt(:,2),' .'); grid on](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-33.jpg)
Xt=[Xt1;Xt2;Xt3];
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,3,1)
plot(Xt(:,1),Xt(:,2),' .');
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'));
subplot(2,3,2)
plotmf(fis,'input',1);
epoch_n = 10;
Xt=[Xt1;Xt2;Xt3];
T=[Xt Yt'];
C=[Xc Yc'];
subplot(2,3,1)
plot(Xt(:,1),Xt(:,2),' .');
grid on
fis = genfis1(T,[3],char('trimf'),char('constant'));
subplot(2,3,2)
plotmf(fis,'input',1);
epoch_n = 10;
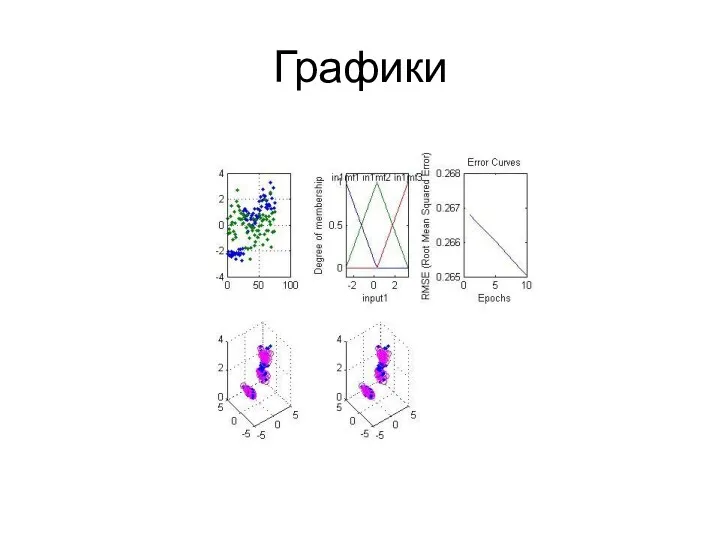
Графики
Графики

Процент распознанных
По обучающей выборке 92%
По тестовой выборке 92%
Время создания системы нечеткого
Процент распознанных
По обучающей выборке 92%
По тестовой выборке 92%
Время создания системы нечеткого
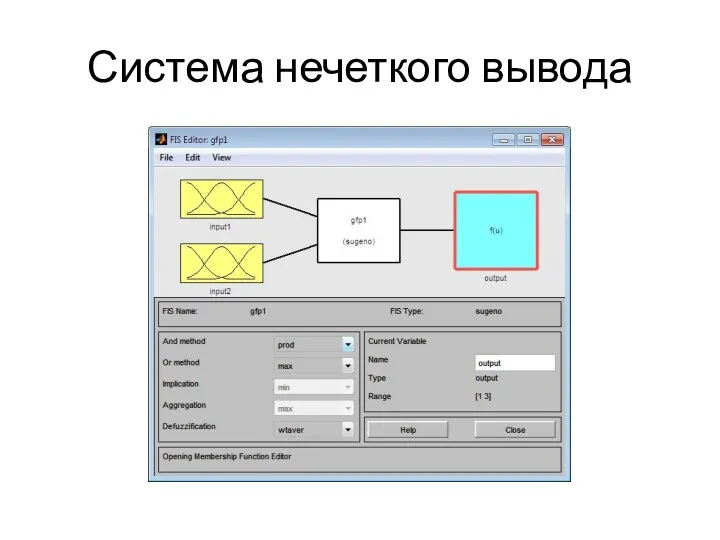
Система нечеткого вывода
Система нечеткого вывода

Факторный анализ
Многомерные данные часто содержат большое число признаков и часто эти
Факторный анализ
Многомерные данные часто содержат большое число признаков и часто эти

Модель факторного анализа
В модели факторного анализа измеренные переменные зависят от меньшего
Модель факторного анализа
В модели факторного анализа измеренные переменные зависят от меньшего

Модель простого факторного анализа может быть представлена в виде
X=μ+λf+e (1)
где X-
Модель простого факторного анализа может быть представлена в виде
X=μ+λf+e (1)
где X-

Другой формой записи модели простого факторного анализа является выражение
Cov(X)=λλT+C (2)
где C=cov(e)
Другой формой записи модели простого факторного анализа является выражение
Cov(X)=λλT+C (2)
где C=cov(e)
![Функция factoran [lambda,psi] = factoran(X,m) функция возвращает выходной параметр psi](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-41.jpg)
Функция factoran
[lambda,psi] = factoran(X,m)
функция возвращает выходной параметр psi - вектор
Функция factoran
[lambda,psi] = factoran(X,m)
функция возвращает выходной параметр psi - вектор

Пример факторного анализа
Факторные нагрузки
В течение 100 недель были зарегистрированы процентные изменения
Пример факторного анализа
Факторные нагрузки
В течение 100 недель были зарегистрированы процентные изменения

В этом примере вначале загружаются данные и вызывается функция factoran, определяющая
В этом примере вначале загружаются данные и вызывается функция factoran, определяющая
![load stockreturns [Loadings,specificVar,T,stats] = ... factoran(stocks,3,'rotate','none'); Первые два выходных аргумента](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-44.jpg)
load stockreturns
[Loadings,specificVar,T,stats] = ...
factoran(stocks,3,'rotate','none');
Первые два выходных аргумента factoran представляют собой
load stockreturns
[Loadings,specificVar,T,stats] = ...
factoran(stocks,3,'rotate','none');
Первые два выходных аргумента factoran представляют собой
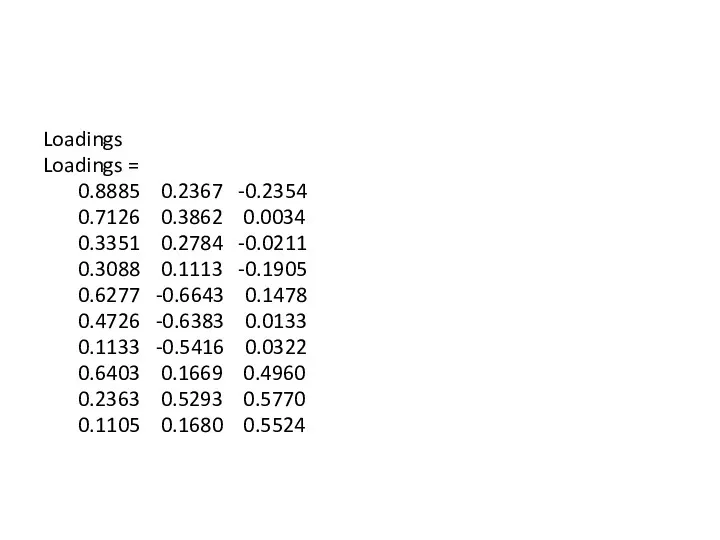
Loadings
Loadings =
0.8885 0.2367 -0.2354
0.7126 0.3862 0.0034
0.3351 0.2784 -0.0211
Loadings
Loadings =
0.8885 0.2367 -0.2354
0.7126 0.3862 0.0034
0.3351 0.2784 -0.0211

Анализируя отклонения, можно видеть, что модель указывает на значительные изменения цены
Анализируя отклонения, можно видеть, что модель указывает на значительные изменения цены

Структура stats позволяет проверить нулевую гипотезу H0, состоящую в том, что
Структура stats позволяет проверить нулевую гипотезу H0, состоящую в том, что

Чтобы определить, можно ли выбрать меньшее число факторов, чем 3, построим
Чтобы определить, можно ли выбрать меньшее число факторов, чем 3, построим

Вращение факторов
Как показывают результаты, нагрузки, подсчитанные по факторам, не подвергающимся вращениям,
Вращение факторов
Как показывают результаты, нагрузки, подсчитанные по факторам, не подвергающимся вращениям,

Если рассматривать каждую строку матрицы нагрузок как координаты точки в M-мерном
Если рассматривать каждую строку матрицы нагрузок как координаты точки в M-мерном
![[LoadingsPM,specVarPM] = factoran(stocks,3,'rotate','promax'); LoadingsPM LoadingsPM = 0.9452 0.1214 -0.0617 0.7064](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-51.jpg)
[LoadingsPM,specVarPM] = factoran(stocks,3,'rotate','promax');
LoadingsPM
LoadingsPM =
0.9452 0.1214 -0.0617
0.7064 -0.0178 0.2058
0.3885
[LoadingsPM,specVarPM] = factoran(stocks,3,'rotate','promax');
LoadingsPM
LoadingsPM =
0.9452 0.1214 -0.0617
0.7064 -0.0178 0.2058
0.3885

Вращение promax создает более простую структуру нагрузок, в каждой из которых
Вращение promax создает более простую структуру нагрузок, в каждой из которых

biplot(coefs) создает график коэффициентов матрице coefs. График является двумерным , если
biplot(coefs) создает график коэффициентов матрице coefs. График является двумерным , если

Наиболее употребимые параметры:
Scores
Выводит матрицу coefs
VarLabels
Метки каждого вектора (переменной) с текстами
Наиболее употребимые параметры:
Scores
Выводит матрицу coefs
VarLabels
Метки каждого вектора (переменной) с текстами

Для нашего примера
biplot(LoadingsPM,'varlabels',num2str((1:10)'));
выведет рисунок:
Для нашего примера
biplot(LoadingsPM,'varlabels',num2str((1:10)'));
выведет рисунок:
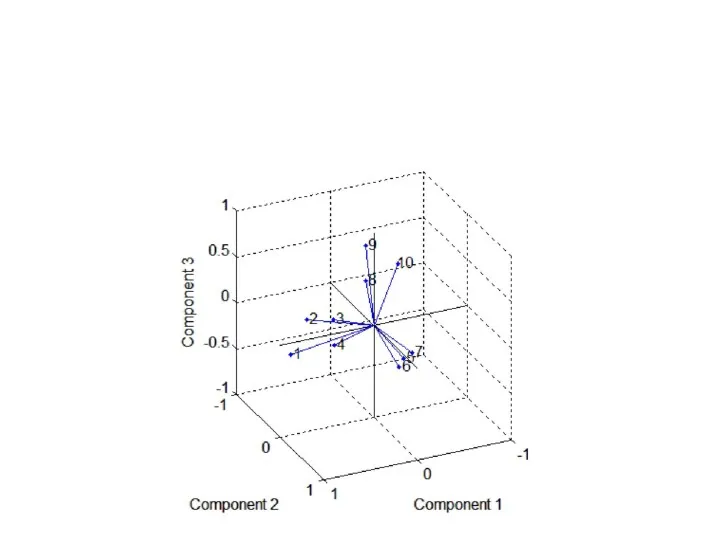

Этот график показывает, что косоугольное вращение привело нагрузки факторов к простейшей
Этот график показывает, что косоугольное вращение привело нагрузки факторов к простейшей

Координаты факторов
Часто полезно классифицировать наблюдения на основе координат их факторов. Например,
Координаты факторов
Часто полезно классифицировать наблюдения на основе координат их факторов. Например,
![[LoadingsPM,specVarPM,TPM,stats,F] = ... factoran(stocks, 3,'rotate','promax'); %TPM – матрица вращения %матрица](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-59.jpg)
[LoadingsPM,specVarPM,TPM,stats,F] = ...
factoran(stocks, 3,'rotate','promax');
%TPM – матрица вращения
%матрица F является
[LoadingsPM,specVarPM,TPM,stats,F] = ...
factoran(stocks, 3,'rotate','promax');
%TPM – матрица вращения
%матрица F является
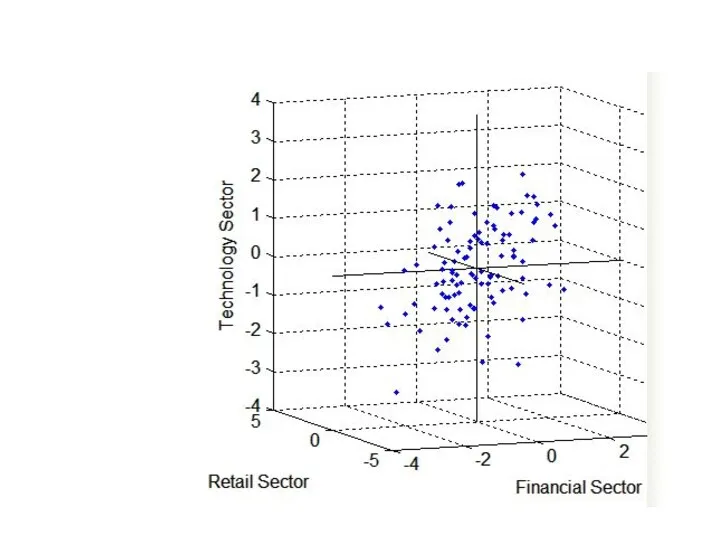

Косоугольное вращение часто создает коррелированные факторы.
Рисунок дает некоторые доказательства корреляции
Косоугольное вращение часто создает коррелированные факторы.
Рисунок дает некоторые доказательства корреляции

Визуализация результатов
Можно использовать функцию biplot для визуализации факторных нагрузок для каждой
Визуализация результатов
Можно использовать функцию biplot для визуализации факторных нагрузок для каждой
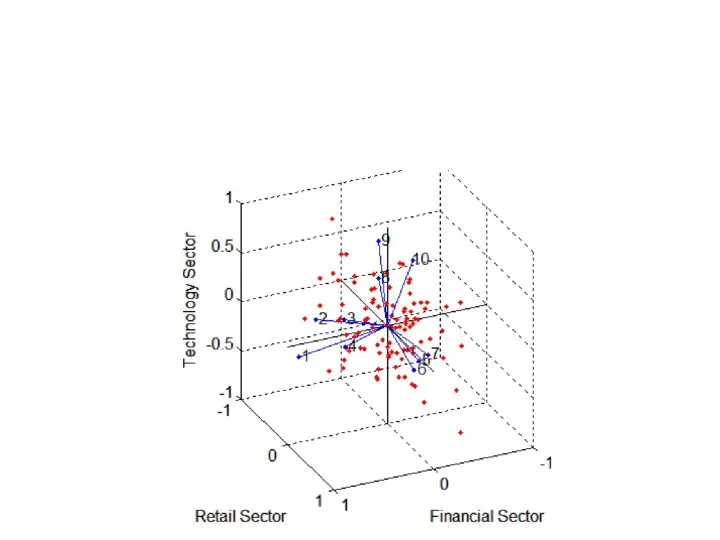

В этом случае biplot является трехмерным. Каждая из 10 компаний представлена
В этом случае biplot является трехмерным. Каждая из 10 компаний представлена

Каждое из 100 наблюдений представлено на графике точкой, и их положение
Каждое из 100 наблюдений представлено на графике точкой, и их положение

Пример с ирисами Фишера
Так как число признаков d=4,то согласно ограничению
можно
Пример с ирисами Фишера
Так как число признаков d=4,то согласно ограничению
можно
![Создадим модель с косоугольными вращениями и сохраним координаты факторов: [LoadingsPM,specVarPM,TPM,stats,F]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-67.jpg)
Создадим модель с косоугольными вращениями и сохраним координаты факторов:
[LoadingsPM,specVarPM,TPM,stats,F] = ...
Создадим модель с косоугольными вращениями и сохраним координаты факторов:
[LoadingsPM,specVarPM,TPM,stats,F] = ...
![load fisheriris [Loadings2,specificVar2,T2,stats2] = ... factoran(meas,1,'rotate','none'); [LoadingsPM,specVarPM,TPM,stats,F] = ... factoran(meas,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/228855/slide-68.jpg)
load fisheriris
[Loadings2,specificVar2,T2,stats2] = ...
factoran(meas,1,'rotate','none');
[LoadingsPM,specVarPM,TPM,stats,F] = ...
factoran(meas, 1,'rotate','promax');
Xt1=F(1:25);
Xt2=F(51:75);
Xt3=F(101:125);
Xt=[Xt1;Xt2;Xt3];
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xc1=F(26:50);
Xc2=F(76:100);
Xc3=F(126:150);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
T=[Xt Yt'];
C=[Xc Yc'];
tic
load fisheriris
[Loadings2,specificVar2,T2,stats2] = ...
factoran(meas,1,'rotate','none');
[LoadingsPM,specVarPM,TPM,stats,F] = ...
factoran(meas, 1,'rotate','promax');
Xt1=F(1:25);
Xt2=F(51:75);
Xt3=F(101:125);
Xt=[Xt1;Xt2;Xt3];
Yt(1:25)=1;
Yt(26:50)=2;
Yt(51:75)=3;
Xc1=F(26:50);
Xc2=F(76:100);
Xc3=F(126:150);
Xc=[Xc1;Xc2;Xc3];
Yc(1:25)=1;
Yc(26:50)=2;
Yc(51:75)=3;
T=[Xt Yt'];
C=[Xc Yc'];
tic

Построим систему нечеткого вывода с помощью genfis1 и настроим ее с
Построим систему нечеткого вывода с помощью genfis1 и настроим ее с

Посчитаем выходные значения по системе нечеткого вывода для обучающих и контролирующих
Посчитаем выходные значения по системе нечеткого вывода для обучающих и контролирующих
 Git. Python tools. Basic operators
Git. Python tools. Basic operators Требования к оформлению презентаций
Требования к оформлению презентаций Образовательный комплекс. Компьютерные сети
Образовательный комплекс. Компьютерные сети Основные понятия теории баз данных
Основные понятия теории баз данных Game-Theoretic Methods in Machine Learning
Game-Theoretic Methods in Machine Learning Мастер-класс. Как прикрепить документы на сайт через Google-диск
Мастер-класс. Как прикрепить документы на сайт через Google-диск SAFA results: aircraft types Russian Federation State of Design
SAFA results: aircraft types Russian Federation State of Design Автоматизоване робоче місце інспектора з охорони праці
Автоматизоване робоче місце інспектора з охорони праці Автоматизированные и автоматические системы управления
Автоматизированные и автоматические системы управления Introduction and paradigms. Programming language concepts. (Lecture 1)
Introduction and paradigms. Programming language concepts. (Lecture 1) Операционная система
Операционная система Как работают чат-боты и кто их разрабатывает?
Как работают чат-боты и кто их разрабатывает? Информатика. Классификации компьютерной техники
Информатика. Классификации компьютерной техники Spatial data development for SDI
Spatial data development for SDI Computer Science
Computer Science Криптовалюта: опыт биткоинов
Криптовалюта: опыт биткоинов Разработка требований к ИС. Управление требованиями к ИС
Разработка требований к ИС. Управление требованиями к ИС IT-профессия программист
IT-профессия программист Устройства хранения информации
Устройства хранения информации Киберспорт как феномен
Киберспорт как феномен Співпраця в мережі
Співпраця в мережі Информационная инфраструктура на территории Ульяновской области. Качество сотовой связи и сети интернет
Информационная инфраструктура на территории Ульяновской области. Качество сотовой связи и сети интернет Программирование на языке Python. Алгоритм и его свойства
Программирование на языке Python. Алгоритм и его свойства Тестирование и тест-дизайн. Основы функционального тестирования. Модульные тесты
Тестирование и тест-дизайн. Основы функционального тестирования. Модульные тесты Создание компьютерных игр в среде Unity
Создание компьютерных игр в среде Unity Персональные компьютеры
Персональные компьютеры Циклічні програми
Циклічні програми Система межведомственного электронного взаимодействия Санкт-Петербурга
Система межведомственного электронного взаимодействия Санкт-Петербурга