- Создание базы данных

Содержание
- 2. Формы Бэкуса-Наура (BNF) Язык, в терминах которого дается описание языка SQL, называется метаязыком. При построении синтаксической
- 3. Формы Бэкуса-Наура (BNF) Символ ::= означает равенство по определению. Используется для пояснения элементов синтаксической диаграммы оператора.
- 4. Формы Бэкуса-Наура (BNF) Необязательные элементы оператора заключены в квадратные скобки "[ ]". [А] – повторение символа
- 5. Формы Бэкуса-Наура (BNF) Фигурные скобки "{ }" указывают, что все находящееся внутри них является единым целым
- 6. Формы Бэкуса-Наура (BNF) Многоточие, внутри которого есть запятая ".,.." (точнее, точка, запятая, две точки) указывает, что
- 7. СОЗДАНИЕ БД
- 8. Этапы создания БД 1. создание БД (файл с расширением *.mdf ). В файле БД записываются сведения
- 9. В стандарте ANSI нет команды CREATE DATABASE. Но почти все платформы СУБД поддерживают какой-либо вариант этой
- 10. Определение базы данных ::= CREATE DATABASE имя_БД [ON [PRIMARY] [ [,...n] ] [, [,...n] ] ]
- 11. Имя БД Имя БД – стандартный идентификатор, допустимый в SQL. Если имя БД содержит пробелы или
- 12. ON ON – определяет список файлов на диске для размещения информации, хранящейся в БД. Если в
- 13. LOG ON LOG ON – определяет список файлов на диске для размещения журнала транзакций (ЖТ). Имя
- 14. Определение файла При создании БД можно определить набор файлов, из которых она будет состоять. ::= ([
- 15. NAME=логическое_имя_файла NAME=логическое_имя_файла – это имя файла, под которым он будет распознаваться при выполнении различных SQL-команд. FILENAME='физическое_имя_файла'
- 16. SIZE=размер_файла SIZE=размер_файла определяет первоначальный размер файла; минимальный размер параметра – 512 Кб; если он не указан,
- 17. FILEGROWTH=величина_прироста FILEGROWTH=величина_прироста – величина автоматического прироста размера базы данных. Приращение – это либо абсолютная величина в
- 18. ::= Дополнительные файлы могут быть включены в группу: ::= FILEGROUP имя_группы_файлов [,...]
- 19. Пример 1. Создать БД, при этом для данных определить 3 файла на дисках D, E, F,
- 20. Краткая форма оператора создания базы данных CREATE DATABASE имя_базы_данных; В этом случае все значения параметров задаются
- 21. Изменение БД ::= ALTER DATABASE имя_базы_данных { ADD FILE [,...n] [TO FILEGROUP имя_группы_файлов ] | ADD
- 22. Удаление БД Удаление БД осуществляется командой: DROP DATABASE имя_базы_данных [,...n] Удаляются все содержащиеся в БД объекты,
- 23. Создание таблицы
- 24. Приступая к созданию таблицы, необходимо ответить на ряд вопросов: Как будет называться таблица? Как будут называться
- 25. Упрощённый синтаксис этой команды CREATE TABLE ( { [( )] [ …]} .,.. [, .,..] );
- 26. Базовый синтаксис команды создания таблицы ::= CREATE TABLE имя_таблицы ({имя_столбца тип_данных [ NOT NULL ] [
- 27. имя_столбца тип_данных имя_столбца – идентификатор столбца тип_данных - тип данных столбца. Обязательно должен быть указан размер
- 28. NOT NULL [NOT] NULL – NULL используется для указания того, что в данном столбце могут содержаться
- 29. UNIQUE UNIQUE – уникальное значение поля в пределах столбца таблицы.
- 30. PRIMARY KEY Создает первичный ключ таблицы. Каждая таблица может иметь только один первичный ключ. Обеспечивает отсутствие
- 31. IDENTITY [n, m] Для колонки с таким свойством сервером автоматически генерируется возрастающая последовательность, начиная с n
- 32. DEFAULT [DEFAULT ] - значение по умолчанию. Так, при добавлении новой записи столбец с таким ограничением
- 33. FOREIGN KEY [FOREIGN KEY REFERENCES имя_род_таблицы [ (имя_столбца_род_таблицы ) ] 1. Задает столбец или набор столбцов
- 34. FOREIGN KEY Требование – соответствие столбцов РК и FК по типу и размеру данных если FK
- 35. CHECK [ CHECK ( ) ] [,...n] используется для проверки допустимости данных, вводимых в конкретный столбец
- 36. Основные типы условий выбора: Сравнение Диапазон Принадлежность множеству Соответствие шаблону Отсутствие значений (Значение NULL)
- 37. 1. Сравнение Сравниваются результаты вычисления одного выражения с результатами вычисления другого. Условие поиска при сравнении имеет
- 38. 2. Диапазон Проверяется, попадает ли результат вычисления выражения в заданный диапазон значений. Диапазон значений задается с
- 39. 3. Принадлежность множеству проверяется, принадлежит ли результат вычислений выражения заданному множеству значений. Вхождение во множество задается
- 40. 3. Принадлежность множеству NOT IN используется для отбора любых значений, кроме тех, которые указаны в представленном
- 41. 4. Соответствие шаблону проверяется, отвечает ли некоторое строковое значение заданному шаблону. С помощью оператора LIKE можно
- 42. 4. Соответствие шаблону Пример 6. Телефон CHAR(10) NOT NULL CHECK(Телефон LIKE '[1-9][0-9]-[0-9][0-9]-[0-9][0-9]') Пример 7. Город CHAR(15)
- 43. 5. Отсутствие значений (Значение NULL) Допускается наличие неопределенных значений в столбце. Задается на уровне столбца.
- 44. База данных Magasin
- 45. Пример 7. Создание таблицы Сделка CREATE TABLE Сделка ( КодСделки INT IDENTITY (1,1) PRIMARY KEY, КодТовара
- 46. Пример 8. Создание таблицы Клиент CREATE TABLE Клиент (КодКлиента INT IDENTITY(1,1) PRIMARY KEY, Фирма VARCHAR(50) NOT
- 47. ИЗМЕНЕНИЕ ТАБЛИЦЫ
- 48. Изменение таблицы Структура существующей таблицы может быть модифицирована с помощью команды ALTER TABLE, упрощенный синтаксис которой
- 49. Изменение таблицы Некоторые реализации могут ограничить разработчика в использовании некоторых опций команды ALTER TABLE. Например, может
- 50. Изменение таблицы Возможны трудности, связанные с удалением из таблицы столбца, который зависит от некоторого столбца другой
- 51. Пример 9 Добавить в таблицу Клиент столбец ПаспДанные ALTER TABLE Клиент ADD ПаспДанные varchar (10) 2.
- 52. УДАЛЕНИЕ ТАБЛИЦЫ
- 53. DROP TABLE С течением времени структура БД меняется: создаются новые таблицы, а прежние становятся ненужными и
- 54. RESTRICT Если указано ключевое слово RESTRICT, то при наличии в БД хотя бы одного объекта, существование
- 55. CASCADE Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты БД, чье существование зависит
- 56. DROP TABLE Чаще всего оператор DROP TABLE используется для исправления ошибок, допущенных при создании таблицы. Если
- 57. TRUNCATE TABLE Команда DROP TABLE удалит не только указанную таблицу, но и все входящие в нее
- 58. Операторы модификации данных
- 59. ОПЕРАТОР ДОБАВЛЕНИЯ
- 60. Оператор добавления INSERT INTO Формат оператора: INSERT INTO [ (имя_столбца [,...n] ) ] VALUES (значение[,...n]) Эта
- 61. INSERT INTO Список столбцов указывает столбцы, которым будут присвоены значения в добавляемых записях. Список может быть
- 62. Список значений должен соответствовать списку столбцов следующим образом: количество элементов в обоих списках должно быть одинаковым;
- 63. Пример 10. Добавить в таблицу ТОВАР новую запись. INSERT INTO Товар (Название, Цена, Сорт, КодПроизводителя) VALUES(‘
- 64. ОПЕРАТОР УДАЛЕНИЯ
- 65. Оператор удаления Формат оператора: DELETE FROM [WHERE ]
- 66. Оператор удаления Если предложение WHERE присутствует, удаляются записи из таблицы, удовлетворяющие условию отбора. Если опустить предложение
- 67. Оператор удаления При удалении строк с помощью DELETE эти строки сохраняются в системных сегментах отката на
- 68. Пример 11. Удалить все прошлогодние сделки DELETE FROM Сделка WHERE Year(Сделка.Дата)=Year(GETDATE())-1
- 69. ОПЕРАТОР ОБНОВЛЕНИЯ
- 70. Оператор обновления Формат оператора: UPDATE имя_таблицы SET имя_столбца = [,...n] [WHERE ]
- 71. Оператор обновления В предложении SET указываются имена одного и более столбцов, данные в которых необходимо изменить.
- 73. Скачать презентацию

Формы Бэкуса-Наура (BNF)
Язык, в терминах которого дается описание языка SQL, называется
Формы Бэкуса-Наура (BNF)
Язык, в терминах которого дается описание языка SQL, называется

Формы Бэкуса-Наура (BNF)
Символ ::= означает равенство по определению. Используется для пояснения
Формы Бэкуса-Наура (BNF)
Символ ::= означает равенство по определению. Используется для пояснения

Формы Бэкуса-Наура (BNF)
Необязательные элементы оператора заключены в квадратные скобки "[ ]".
Формы Бэкуса-Наура (BNF)
Необязательные элементы оператора заключены в квадратные скобки "[ ]".

Формы Бэкуса-Наура (BNF)
Фигурные скобки "{ }" указывают, что все находящееся внутри
Формы Бэкуса-Наура (BNF)
Фигурные скобки "{ }" указывают, что все находящееся внутри

Формы Бэкуса-Наура (BNF)
Многоточие, внутри которого есть запятая ".,.." (точнее, точка, запятая,
Формы Бэкуса-Наура (BNF)
Многоточие, внутри которого есть запятая ".,.." (точнее, точка, запятая,

СОЗДАНИЕ БД
СОЗДАНИЕ БД

Этапы создания БД
1. создание БД (файл с расширением *.mdf ). В
Этапы создания БД
1. создание БД (файл с расширением *.mdf ). В

В стандарте ANSI нет команды CREATE DATABASE. Но почти все платформы
В стандарте ANSI нет команды CREATE DATABASE. Но почти все платформы
![Определение базы данных ::= CREATE DATABASE имя_БД [ON [PRIMARY] [](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-9.jpg)
Определение базы данных
<определение_базы_данных> ::=
CREATE DATABASE имя_БД
[ON [PRIMARY]
Определение базы данных
<определение_базы_данных> ::=
CREATE DATABASE имя_БД
[ON [PRIMARY]

Имя БД
Имя БД – стандартный идентификатор, допустимый в SQL. Если
Имя БД
Имя БД – стандартный идентификатор, допустимый в SQL. Если

ON
ON – определяет список файлов на диске для размещения информации,
ON
ON – определяет список файлов на диске для размещения информации,

LOG ON
LOG ON – определяет список файлов на диске для
LOG ON
LOG ON – определяет список файлов на диске для

Определение файла
При создании БД можно определить набор файлов, из которых она
Определение файла
При создании БД можно определить набор файлов, из которых она

NAME=логическое_имя_файла
NAME=логическое_имя_файла – это имя файла, под которым он будет распознаваться
NAME=логическое_имя_файла
NAME=логическое_имя_файла – это имя файла, под которым он будет распознаваться

SIZE=размер_файла
SIZE=размер_файла определяет первоначальный размер файла; минимальный размер параметра – 512 Кб;
SIZE=размер_файла
SIZE=размер_файла определяет первоначальный размер файла; минимальный размер параметра – 512 Кб;

FILEGROWTH=величина_прироста
FILEGROWTH=величина_прироста – величина автоматического прироста размера базы данных. Приращение – это
FILEGROWTH=величина_прироста
FILEGROWTH=величина_прироста – величина автоматического прироста размера базы данных. Приращение – это
![::= Дополнительные файлы могут быть включены в группу: ::= FILEGROUP имя_группы_файлов [,...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-17.jpg)
<определение_группы>::=
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=
FILEGROUP имя_группы_файлов <определение_файла>[,...]
<определение_группы>::=
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=
FILEGROUP имя_группы_файлов <определение_файла>[,...]

Пример 1. Создать БД, при этом для данных определить 3 файла
Пример 1. Создать БД, при этом для данных определить 3 файла

Краткая форма оператора создания базы данных
CREATE DATABASE имя_базы_данных;
В этом случае
Краткая форма оператора создания базы данных
CREATE DATABASE имя_базы_данных;
В этом случае
![Изменение БД ::= ALTER DATABASE имя_базы_данных { ADD FILE [,...n]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-20.jpg)
Изменение БД
<изменение_базы_данных> ::=
ALTER DATABASE имя_базы_данных
{ ADD FILE
Изменение БД
<изменение_базы_данных> ::=
ALTER DATABASE имя_базы_данных
{ ADD FILE
![Удаление БД Удаление БД осуществляется командой: DROP DATABASE имя_базы_данных [,...n]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-21.jpg)
Удаление БД
Удаление БД осуществляется командой:
DROP DATABASE имя_базы_данных [,...n]
Удаляются все
Удаление БД
Удаление БД осуществляется командой:
DROP DATABASE имя_базы_данных [,...n]
Удаляются все
Создание таблицы
Создание таблицы

Приступая к созданию таблицы, необходимо ответить на ряд вопросов:
Как будет называться
Приступая к созданию таблицы, необходимо ответить на ряд вопросов:
Как будет называться
![Упрощённый синтаксис этой команды CREATE TABLE ( { [( )] [ …]} .,.. [, .,..] );](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-24.jpg)
Упрощённый синтаксис этой команды
CREATE TABLE <имя таблицы>
( {<имя столбца> <тип данных>
Упрощённый синтаксис этой команды
CREATE TABLE <имя таблицы>
( {<имя столбца> <тип данных>

Базовый синтаксис команды создания таблицы
<определение_таблицы> ::=
CREATE TABLE имя_таблицы
({имя_столбца тип_данных [
Базовый синтаксис команды создания таблицы
<определение_таблицы> ::=
CREATE TABLE имя_таблицы
({имя_столбца тип_данных [

имя_столбца тип_данных
имя_столбца – идентификатор столбца
тип_данных - тип данных столбца.
Обязательно должен
имя_столбца тип_данных
имя_столбца – идентификатор столбца
тип_данных - тип данных столбца.
Обязательно должен
![NOT NULL [NOT] NULL – NULL используется для указания того,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-27.jpg)
NOT NULL
[NOT] NULL – NULL используется для указания того, что
NOT NULL
[NOT] NULL – NULL используется для указания того, что

UNIQUE
UNIQUE – уникальное значение поля в пределах столбца таблицы.
UNIQUE
UNIQUE – уникальное значение поля в пределах столбца таблицы.

PRIMARY KEY
Создает первичный ключ таблицы. Каждая таблица может иметь
PRIMARY KEY
Создает первичный ключ таблицы. Каждая таблица может иметь
![IDENTITY [n, m] Для колонки с таким свойством сервером автоматически](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-30.jpg)
IDENTITY [n, m]
Для колонки с таким свойством сервером автоматически генерируется возрастающая
IDENTITY [n, m]
Для колонки с таким свойством сервером автоматически генерируется возрастающая
![DEFAULT [DEFAULT ] - значение по умолчанию. Так, при добавлении](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-31.jpg)
DEFAULT
[DEFAULT <значение>] - значение по умолчанию.
Так, при добавлении новой
DEFAULT
[DEFAULT <значение>] - значение по умолчанию.
Так, при добавлении новой
![FOREIGN KEY [FOREIGN KEY REFERENCES имя_род_таблицы [ (имя_столбца_род_таблицы ) ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-32.jpg)
FOREIGN KEY
[FOREIGN KEY REFERENCES имя_род_таблицы
[ (имя_столбца_род_таблицы ) ]
1.
FOREIGN KEY
[FOREIGN KEY REFERENCES имя_род_таблицы
[ (имя_столбца_род_таблицы ) ]
1.

FOREIGN KEY
Требование – соответствие столбцов РК и FК по типу и
FOREIGN KEY
Требование – соответствие столбцов РК и FК по типу и
![CHECK [ CHECK ( ) ] [,...n] используется для проверки](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-34.jpg)
CHECK
[ CHECK (<условие_выбора> ) ] [,...n]
используется для проверки допустимости данных,
CHECK
[ CHECK (<условие_выбора> ) ] [,...n]
используется для проверки допустимости данных,

Основные типы условий выбора:
Сравнение
Диапазон
Принадлежность множеству
Соответствие шаблону
Отсутствие значений (Значение NULL)
Основные типы условий выбора:
Сравнение
Диапазон
Принадлежность множеству
Соответствие шаблону
Отсутствие значений (Значение NULL)

1. Сравнение
Сравниваются результаты вычисления одного выражения с результатами вычисления другого.
Условие
1. Сравнение
Сравниваются результаты вычисления одного выражения с результатами вычисления другого.
Условие

2. Диапазон
Проверяется, попадает ли результат вычисления выражения в заданный диапазон значений.
2. Диапазон
Проверяется, попадает ли результат вычисления выражения в заданный диапазон значений.

3. Принадлежность множеству
проверяется, принадлежит ли результат вычислений выражения заданному множеству значений.
3. Принадлежность множеству
проверяется, принадлежит ли результат вычислений выражения заданному множеству значений.

3. Принадлежность множеству
NOT IN используется для отбора любых значений, кроме тех,
3. Принадлежность множеству
NOT IN используется для отбора любых значений, кроме тех,

4. Соответствие шаблону
проверяется, отвечает ли некоторое строковое значение заданному шаблону.
С помощью
4. Соответствие шаблону
проверяется, отвечает ли некоторое строковое значение заданному шаблону.
С помощью

4. Соответствие шаблону
Пример 6.
Телефон CHAR(10) NOT NULL
CHECK(Телефон LIKE '[1-9][0-9]-[0-9][0-9]-[0-9][0-9]')
Пример 7.
Город
4. Соответствие шаблону
Пример 6.
Телефон CHAR(10) NOT NULL
CHECK(Телефон LIKE '[1-9][0-9]-[0-9][0-9]-[0-9][0-9]')
Пример 7.
Город

5. Отсутствие значений (Значение NULL)
Допускается наличие неопределенных значений в столбце.
5. Отсутствие значений (Значение NULL)
Допускается наличие неопределенных значений в столбце.
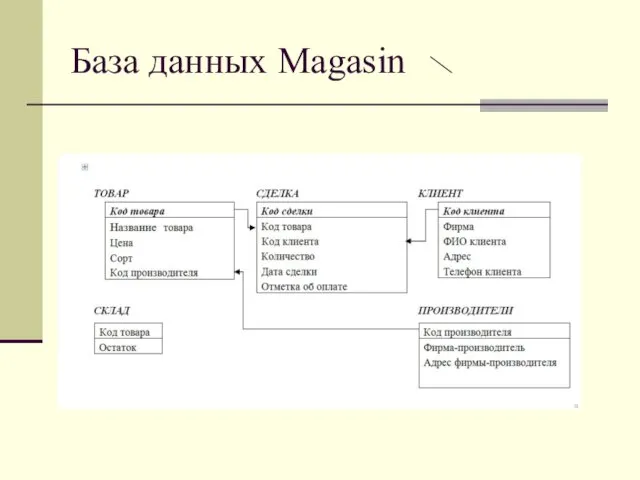
База данных Magasin
База данных Magasin

Пример 7. Создание таблицы Сделка
CREATE TABLE Сделка
( КодСделки INT IDENTITY (1,1)
Пример 7. Создание таблицы Сделка
CREATE TABLE Сделка
( КодСделки INT IDENTITY (1,1)

Пример 8. Создание таблицы Клиент
CREATE TABLE Клиент
(КодКлиента INT IDENTITY(1,1) PRIMARY
Пример 8. Создание таблицы Клиент
CREATE TABLE Клиент
(КодКлиента INT IDENTITY(1,1) PRIMARY

ИЗМЕНЕНИЕ ТАБЛИЦЫ
ИЗМЕНЕНИЕ ТАБЛИЦЫ

Изменение таблицы
Структура существующей таблицы может быть модифицирована с помощью команды
Изменение таблицы
Структура существующей таблицы может быть модифицирована с помощью команды

Изменение таблицы
Некоторые реализации могут ограничить разработчика в использовании некоторых опций
Изменение таблицы
Некоторые реализации могут ограничить разработчика в использовании некоторых опций

Изменение таблицы
Возможны трудности, связанные с удалением из таблицы столбца, который
Изменение таблицы
Возможны трудности, связанные с удалением из таблицы столбца, который

Пример 9
Добавить в таблицу Клиент столбец ПаспДанные
ALTER TABLE Клиент ADD ПаспДанные
Пример 9
Добавить в таблицу Клиент столбец ПаспДанные
ALTER TABLE Клиент ADD ПаспДанные

УДАЛЕНИЕ ТАБЛИЦЫ
УДАЛЕНИЕ ТАБЛИЦЫ

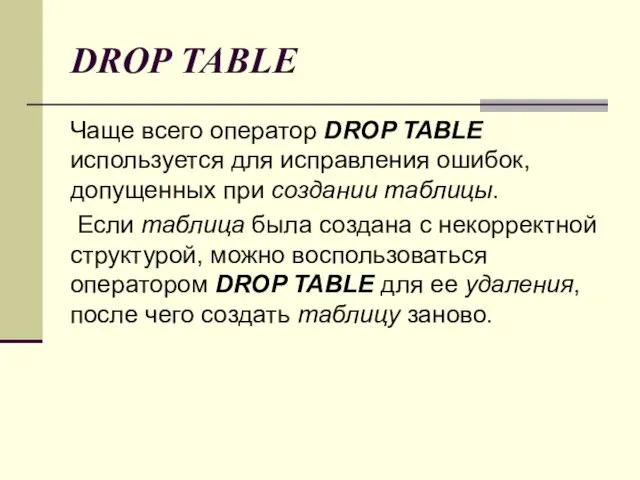
DROP TABLE
С течением времени структура БД меняется: создаются новые таблицы,
DROP TABLE
С течением времени структура БД меняется: создаются новые таблицы,

RESTRICT
Если указано ключевое слово RESTRICT, то при наличии в БД хотя
RESTRICT
Если указано ключевое слово RESTRICT, то при наличии в БД хотя

CASCADE
Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты
CASCADE
Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты
DROP TABLE
Чаще всего оператор DROP TABLE используется для исправления ошибок,
DROP TABLE
Чаще всего оператор DROP TABLE используется для исправления ошибок,
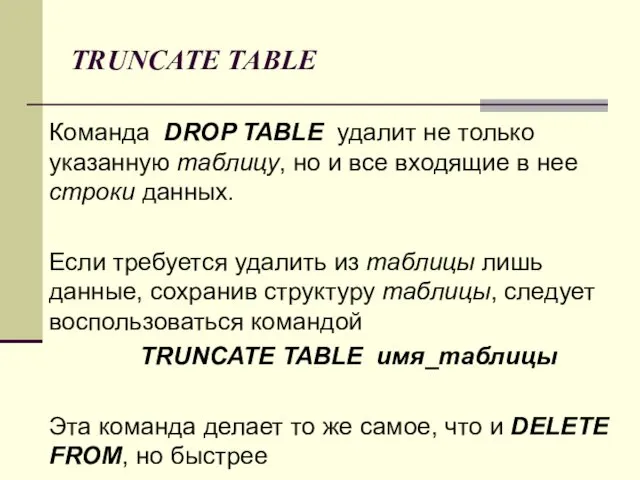
TRUNCATE TABLE
Команда DROP TABLE удалит не только указанную таблицу, но
TRUNCATE TABLE
Команда DROP TABLE удалит не только указанную таблицу, но
Операторы модификации данных
Операторы модификации данных

ОПЕРАТОР ДОБАВЛЕНИЯ
ОПЕРАТОР ДОБАВЛЕНИЯ

Оператор добавления
INSERT INTO
Формат оператора:
INSERT INTO <имя_таблицы> [ (имя_столбца [,...n] )
Оператор добавления
INSERT INTO
Формат оператора:
INSERT INTO <имя_таблицы> [ (имя_столбца [,...n] )

INSERT INTO
Список столбцов указывает столбцы, которым будут присвоены значения в добавляемых
INSERT INTO
Список столбцов указывает столбцы, которым будут присвоены значения в добавляемых

Список значений должен соответствовать списку столбцов следующим образом:
количество элементов в обоих
Список значений должен соответствовать списку столбцов следующим образом:
количество элементов в обоих

Пример 10. Добавить в таблицу ТОВАР новую запись.
INSERT INTO Товар (Название,
Пример 10. Добавить в таблицу ТОВАР новую запись.
INSERT INTO Товар (Название,

ОПЕРАТОР УДАЛЕНИЯ
ОПЕРАТОР УДАЛЕНИЯ
![Оператор удаления Формат оператора: DELETE FROM [WHERE ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-64.jpg)
Оператор удаления
Формат оператора:
DELETE FROM <имя_таблицы>[WHERE <условие_отбора>]
Оператор удаления
Формат оператора:
DELETE FROM <имя_таблицы>[WHERE <условие_отбора>]

Оператор удаления
Если предложение WHERE присутствует, удаляются записи из таблицы, удовлетворяющие условию
Оператор удаления
Если предложение WHERE присутствует, удаляются записи из таблицы, удовлетворяющие условию

Оператор удаления
При удалении строк с помощью DELETE эти строки сохраняются в
Оператор удаления
При удалении строк с помощью DELETE эти строки сохраняются в

Пример 11. Удалить все прошлогодние сделки
DELETE FROM Сделка
WHERE Year(Сделка.Дата)=Year(GETDATE())-1
Пример 11. Удалить все прошлогодние сделки
DELETE FROM Сделка
WHERE Year(Сделка.Дата)=Year(GETDATE())-1

ОПЕРАТОР ОБНОВЛЕНИЯ
ОПЕРАТОР ОБНОВЛЕНИЯ
![Оператор обновления Формат оператора: UPDATE имя_таблицы SET имя_столбца = [,...n] [WHERE ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1887/slide-69.jpg)
Оператор обновления
Формат оператора:
UPDATE имя_таблицы
SET имя_столбца = <выражение>[,...n] [WHERE <условие_отбора>]
Оператор обновления
Формат оператора:
UPDATE имя_таблицы
SET имя_столбца = <выражение>[,...n] [WHERE <условие_отбора>]

Оператор обновления
В предложении SET указываются имена одного и более столбцов, данные
Оператор обновления
В предложении SET указываются имена одного и более столбцов, данные
 7 класс, урок Устройства ввода-вывода
7 класс, урок Устройства ввода-вывода Особенности программирования на GPU
Особенности программирования на GPU Уведення та вставлення текстів на слайдах. Редагування і форматування текстів на слайдах. Урок №16. 5 клас
Уведення та вставлення текстів на слайдах. Редагування і форматування текстів на слайдах. Урок №16. 5 клас Действия с информацией
Действия с информацией Принципы обработки информации компьютером. Алгоритмы и способы их описания
Принципы обработки информации компьютером. Алгоритмы и способы их описания Основы работы в системе управления базами данных (СУБД) MS Access
Основы работы в системе управления базами данных (СУБД) MS Access Сетевой этикет
Сетевой этикет Средства массовой информации
Средства массовой информации Урок в 5 классе по теме Табличная форма представления информации
Урок в 5 классе по теме Табличная форма представления информации Программирование на С++. Функции
Программирование на С++. Функции Условный оператор в Паскале. 9 класс
Условный оператор в Паскале. 9 класс Краткая инструкция о том, как за 1 час поставить себе цель и сдвинуться с мёртвой точки
Краткая инструкция о том, как за 1 час поставить себе цель и сдвинуться с мёртвой точки Электронная библиотека издательства ЮРАЙТ. Общие сведения
Электронная библиотека издательства ЮРАЙТ. Общие сведения Цифровая схемотехника и архитектура компьютера. Микроархитектура. (Глава 7)
Цифровая схемотехника и архитектура компьютера. Микроархитектура. (Глава 7) Подход к решению задачи 27 Обработка строк
Подход к решению задачи 27 Обработка строк Facebook - социальная сеть
Facebook - социальная сеть A Display Model and Graphics Classes
A Display Model and Graphics Classes Кодирование текстовой информации. Представление информации в компьютере
Кодирование текстовой информации. Представление информации в компьютере Кибербуллинг: как помочь ребенку в ситуации онлайн-травли
Кибербуллинг: как помочь ребенку в ситуации онлайн-травли Компьютерные сети, Интернет и мультимедиа технологии. Архитектура сетей
Компьютерные сети, Интернет и мультимедиа технологии. Архитектура сетей Сеть поисковых систем Google
Сеть поисковых систем Google Задание правил проектирования для печатных плат
Задание правил проектирования для печатных плат презентация к уроку информатики в 9 классе.
презентация к уроку информатики в 9 классе. Применение электронных ресурсов при проведении уроков информатики
Применение электронных ресурсов при проведении уроков информатики О группе Однажды в сказке/ Once Upon A Time
О группе Однажды в сказке/ Once Upon A Time Компьютерная игра Tower Defense
Компьютерная игра Tower Defense Что такое Dota 2?
Что такое Dota 2? Аналіз впливу збільшення розмірності задачі на довжину паралельного упорядкування
Аналіз впливу збільшення розмірності задачі на довжину паралельного упорядкування