- Стандарт OpenMP. Лекция 3

Содержание
- 2. Информационные ресурсы www.openmp.org http://parallel.ru/tech/tech_dev/openmp.html www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D., McDonald,
- 3. Стратегия подхода OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей памятью. Модели параллельного компьютера
- 4. Динамика развития стандарта OpenMP Fortran API v1.0 (1997) OpenMP C/C++ API v1.0 (1998) OpenMP Fortran API
- 5. Динамика развития стандарта OpenMP Fortran API v1.0 (1997) OpenMP C/C++ API v1.0 (1998) OpenMP Fortran API
- 6. Достоинства Поэтапное (инкрементальное) распараллеливание Единственность разрабатываемого кода Эффективность Стандартизированность
- 7. Принцип организации параллелизма Использование потоков Пульсирующий («вилочный») параллелизм
- 8. Структура OpenMP: Набор директив Библиотека функций Набор переменных окружения
- 9. Директивы OpenMP Формат #pragma omp имя_директивы [clause,…] Пример #pragma omp parallel default (shared) \ private (beta,
- 10. Области видимости директив
- 11. Типы директив Определение параллельной области; Разделение работы; Синхронизация.
- 12. Определение параллельной области Директива parallel: #pragma omp parallel [clause …] structured_block clause if (scalar_expression) private (list)
- 13. Определение параллельной области #include #include int main(int argc, char *argv[]) { int nthreads, tid; #pragma omp
- 14. Распределение вычислений DO/for – распараллеливание циклов sections – распараллеливание раздельных фрагментов кода single – директива последовательного
- 15. Директива DO/for Директива DO/for: #pragma omp for [clause …] for_loop clause scheldule (type [,chunk]) ordered private
- 16. Директива DO/for #include #include int main(int argc, char *argv[]) { int A[10], B[10], C[10], i, n;
- 17. Директива sections Директива section: #pragma omp sections [clause …] { #pragma omp section structured_block… } clause
- 18. Директива sections #include #include int main(int argc, char *argv[]) { int n = 0; #pragma omp
- 19. Директива single Директива single: #pragma omp single [clause …] { #pragma omp section structured_block… } clause
- 20. Директива master #include int main(int argc, char *argv[]) { int n; #pragma omp parallel private(n) {
- 21. Директива critical #include #include int main(int argc, char *argv[]) { int n; #pragma omp parallel {
- 22. Директива barrier #include #include int main(int argc, char *argv[]) { #pragma omp parallel { printf("Сообщение 1\n");
- 23. Директива atomic #include #include int main(int argc, char *argv[]) { int count = 0; #pragma omp
- 24. Директива flush #include #include int main(int argc, char *argv[]) { int count = 0; #pragma omp
- 25. Директива ordered #include #include int main(int argc, char *argv[]) { int i, n; #pragma omp parallel
- 26. Управление областью видимости if (scalar_expression) shared (list) private (list) clause: firstprivate (list) lastprivate (list) reduction (operator:
- 27. Параметр reduction Возможный формат записи: x = x op expr x = expr op x x
- 28. Совместимость директив и параметров
- 29. Библиотека функций OpenMP void omp_set_num_threads(int num) int omp_get_max_threads(void) int omp_get_num_threads(void) int omp_get_thread_num (void) int omp_get_num_procs (void)
- 30. Библиотека функций OpenMP void omp_init_lock(omp_lock_t *lock) void omp_nest_init_lock(omp_nest_lock_t *lock) void omp_destroy_lock(omp_lock_t *lock) void omp_destroy_nest_lock(omp_nest_lock_t *lock) void
- 31. Переменные среды OpenMP OMP_SCHEDULE OMP_NUM_THREADS OMP_DYNAMIC OMP_NESTED
- 33. Скачать презентацию

Информационные ресурсы
www.openmp.org
http://parallel.ru/tech/tech_dev/openmp.html
www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D.,
Информационные ресурсы
www.openmp.org
http://parallel.ru/tech/tech_dev/openmp.html
www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D.,
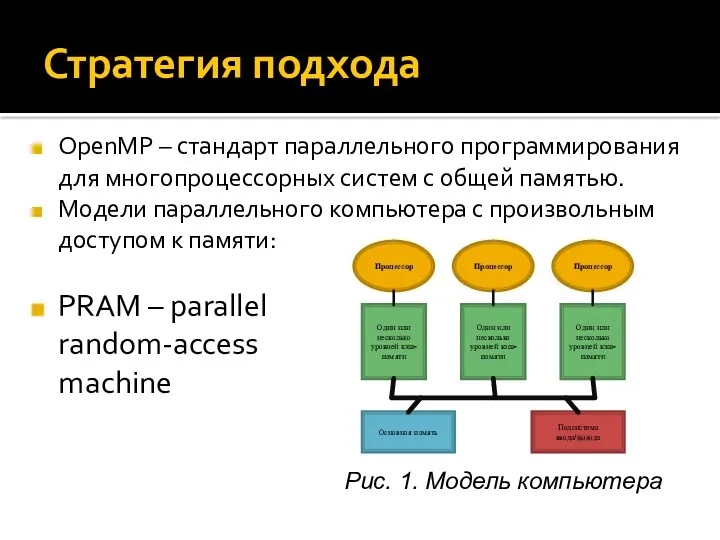
Стратегия подхода
OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей
Стратегия подхода
OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей

Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP
Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP

Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP
Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP

Достоинства
Поэтапное (инкрементальное) распараллеливание
Единственность разрабатываемого кода
Эффективность
Стандартизированность
Достоинства
Поэтапное (инкрементальное) распараллеливание
Единственность разрабатываемого кода
Эффективность
Стандартизированность
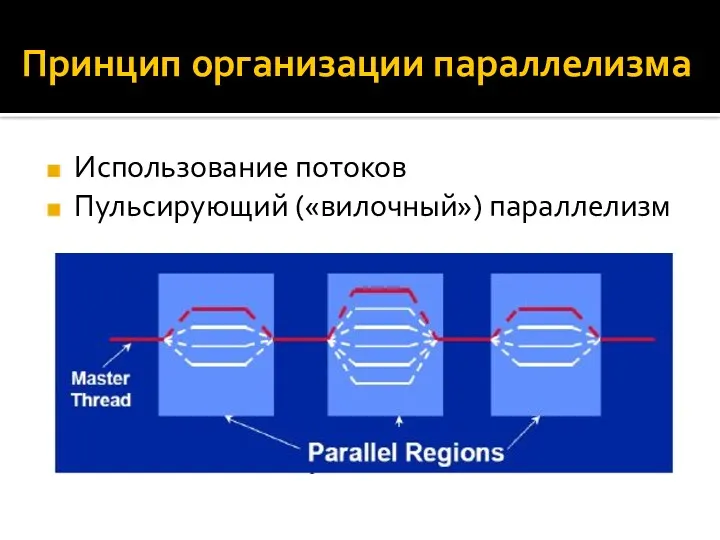
Принцип организации параллелизма
Использование потоков
Пульсирующий («вилочный») параллелизм
Принцип организации параллелизма
Использование потоков
Пульсирующий («вилочный») параллелизм

Структура OpenMP:
Набор директив
Библиотека функций
Набор переменных окружения
Структура OpenMP:
Набор директив
Библиотека функций
Набор переменных окружения
![Директивы OpenMP Формат #pragma omp имя_директивы [clause,…] Пример #pragma omp](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-8.jpg)
Директивы OpenMP
Формат
#pragma omp имя_директивы [clause,…]
Пример
#pragma omp parallel default (shared)
Директивы OpenMP
Формат
#pragma omp имя_директивы [clause,…]
Пример
#pragma omp parallel default (shared)
Области видимости директив
Области видимости директив

Типы директив
Определение параллельной области;
Разделение работы;
Синхронизация.
Типы директив
Определение параллельной области;
Разделение работы;
Синхронизация.
![Определение параллельной области Директива parallel: #pragma omp parallel [clause …]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-11.jpg)
Определение параллельной области
Директива parallel:
#pragma omp parallel [clause …] structured_block
clause
if (scalar_expression)
private
Определение параллельной области
Директива parallel:
#pragma omp parallel [clause …] structured_block
clause
if (scalar_expression)
private
![Определение параллельной области #include #include int main(int argc, char *argv[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-12.jpg)
Определение параллельной области
#include
#include
int main(int argc, char *argv[])
Определение параллельной области
#include
#include
int main(int argc, char *argv[])

Распределение вычислений
DO/for – распараллеливание циклов
sections – распараллеливание раздельных фрагментов кода
single –
Распределение вычислений
DO/for – распараллеливание циклов
sections – распараллеливание раздельных фрагментов кода
single –
![Директива DO/for Директива DO/for: #pragma omp for [clause …] for_loop](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-14.jpg)
Директива DO/for
Директива DO/for:
#pragma omp for [clause …]
for_loop
clause
scheldule (type [,chunk])
ordered
private (list)
firstprivate (list)
lastprivate
Директива DO/for
Директива DO/for:
#pragma omp for [clause …]
for_loop
clause
scheldule (type [,chunk])
ordered
private (list)
firstprivate (list)
lastprivate
![Директива DO/for #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-15.jpg)
Директива DO/for
#include
#include
int main(int argc, char *argv[]) {
Директива DO/for
#include
#include
int main(int argc, char *argv[]) {
![Директива sections Директива section: #pragma omp sections [clause …] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-16.jpg)
Директива sections
Директива section:
#pragma omp sections [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
Директива sections
Директива section:
#pragma omp sections [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
![Директива sections #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-17.jpg)
Директива sections
#include
#include
int main(int argc, char *argv[]) {
Директива sections
#include
#include
int main(int argc, char *argv[]) {
![Директива single Директива single: #pragma omp single [clause …] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-18.jpg)
Директива single
Директива single:
#pragma omp single [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
Директива single
Директива single:
#pragma omp single [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
![Директива master #include int main(int argc, char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-19.jpg)
Директива master
#include
int main(int argc, char *argv[]) {
int
Директива master
#include
int main(int argc, char *argv[]) {
int
![Директива critical #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-20.jpg)
Директива critical
#include
#include
int main(int argc, char *argv[])
{
Директива critical
#include
#include
int main(int argc, char *argv[])
{
![Директива barrier #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-21.jpg)
Директива barrier
#include
#include
int main(int argc, char *argv[])
{
Директива barrier
#include
#include
int main(int argc, char *argv[])
{
![Директива atomic #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-22.jpg)
Директива atomic
#include
#include
int main(int argc, char *argv[])
{
Директива atomic
#include
#include
int main(int argc, char *argv[])
{
![Директива flush #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-23.jpg)
Директива flush
#include
#include
int main(int argc, char *argv[])
{
Директива flush
#include
#include
int main(int argc, char *argv[])
{
![Директива ordered #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/233928/slide-24.jpg)
Директива ordered
#include
#include
int main(int argc, char *argv[]) {
Директива ordered
#include
#include
int main(int argc, char *argv[]) {

Управление областью видимости
if (scalar_expression)
shared (list)
private (list)
clause:
firstprivate (list)
lastprivate (list)
reduction (operator: list)
default (shared
Управление областью видимости
if (scalar_expression)
shared (list)
private (list)
clause:
firstprivate (list)
lastprivate (list)
reduction (operator: list)
default (shared

Параметр reduction
Возможный формат записи:
x = x op expr
x =
Параметр reduction
Возможный формат записи:
x = x op expr
x =
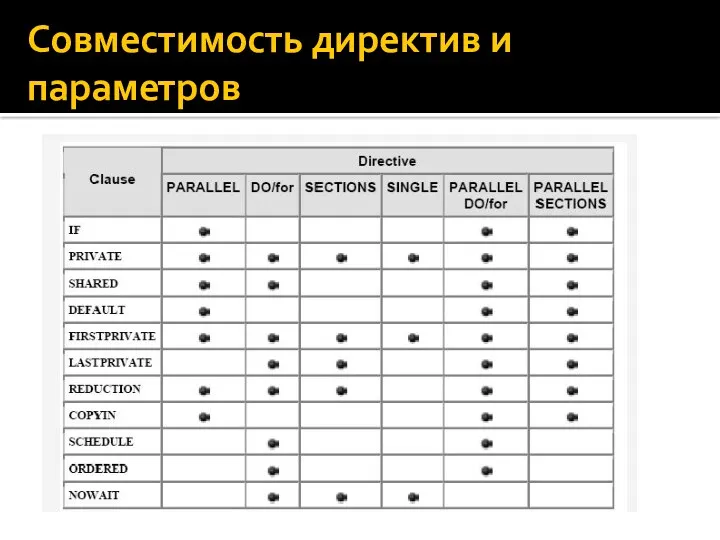
Совместимость директив и параметров
Совместимость директив и параметров

Библиотека функций OpenMP
void omp_set_num_threads(int num)
int omp_get_max_threads(void)
int omp_get_num_threads(void)
int omp_get_thread_num (void)
int omp_get_num_procs (void)
int omp_in_parallel (void)
void omp_set_dynamic(int num)
int omp_get_dynamic(void)
void omp_get_nested(void)
void omp_set_nested(int nested)
Библиотека функций OpenMP
void omp_set_num_threads(int num)
int omp_get_max_threads(void)
int omp_get_num_threads(void)
int omp_get_thread_num (void)
int omp_get_num_procs (void)
int omp_in_parallel (void)
void omp_set_dynamic(int num)
int omp_get_dynamic(void)
void omp_get_nested(void)
void omp_set_nested(int nested)

Библиотека функций OpenMP
void omp_init_lock(omp_lock_t *lock)
void omp_nest_init_lock(omp_nest_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_destroy_nest_lock(omp_nest_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_set_nest_lock(omp_nest_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
void omp_unset_nest_lock(omp_nest_lock_t *lock)
void omp_test_lock(omp_lock_t *lock)
void omp_test_nest_lock(omp_nest_lock_t *lock)
Библиотека функций OpenMP
void omp_init_lock(omp_lock_t *lock)
void omp_nest_init_lock(omp_nest_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_destroy_nest_lock(omp_nest_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_set_nest_lock(omp_nest_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
void omp_unset_nest_lock(omp_nest_lock_t *lock)
void omp_test_lock(omp_lock_t *lock)
void omp_test_nest_lock(omp_nest_lock_t *lock)

Переменные среды OpenMP
OMP_SCHEDULE
OMP_NUM_THREADS
OMP_DYNAMIC
OMP_NESTED
Переменные среды OpenMP
OMP_SCHEDULE
OMP_NUM_THREADS
OMP_DYNAMIC
OMP_NESTED
 Робота з елементами форми
Робота з елементами форми Системный анализ распределенной информационно-управляющей системы
Системный анализ распределенной информационно-управляющей системы Спойлеры в Повер Поинт
Спойлеры в Повер Поинт Структура программы на Си. Состав языка. (лекция 1)
Структура программы на Си. Состав языка. (лекция 1) Конфигурации микросервисной архитектуры, шина данных, протоколы сообщений между сервисами. Лекция 4.1
Конфигурации микросервисной архитектуры, шина данных, протоколы сообщений между сервисами. Лекция 4.1 Создадим небольшой офис из трёх сегментов VLAN2, VLAN3, VLAN4
Создадим небольшой офис из трёх сегментов VLAN2, VLAN3, VLAN4 Линейный алгоритм, записанный на алгоритмическом языке. Конкурс
Линейный алгоритм, записанный на алгоритмическом языке. Конкурс Системы счисления
Системы счисления Табличный процессор Excel 2007
Табличный процессор Excel 2007 Глобальная сеть Интернет
Глобальная сеть Интернет Основи програмної інженерії (лекція 1)
Основи програмної інженерії (лекція 1) Основы применения методов системного анализа в проектировании информационных систем и формализации фармацевтической информации
Основы применения методов системного анализа в проектировании информационных систем и формализации фармацевтической информации Базы данных. Основные понятия
Базы данных. Основные понятия Як стати відомим блогером?
Як стати відомим блогером? Локальная компьютерная сеть
Локальная компьютерная сеть Язык программирования Turbo Pascal 7.0. Часть 1
Язык программирования Turbo Pascal 7.0. Часть 1 Моделирование бизнес-процессов
Моделирование бизнес-процессов Урок по темеЛинейные вычислительные алгоритмы.
Урок по темеЛинейные вычислительные алгоритмы. Призначення й використання математичних, статистичних функцій табличного процесора
Призначення й використання математичних, статистичних функцій табличного процесора Краткий обзор интернет-портала OCS
Краткий обзор интернет-портала OCS Табличное решение логических задач
Табличное решение логических задач Интегрированный урок Использование Excel при построении модели рационального питания
Интегрированный урок Использование Excel при построении модели рационального питания PowerShell vs. Unix Bash
PowerShell vs. Unix Bash Настройка BIOS или UEFI для последующей установки операционной системы
Настройка BIOS или UEFI для последующей установки операционной системы Тема: Циклы в Паскале.
Тема: Циклы в Паскале. Персональный компьютер. Компьютер как универсальное устройство для работы с информацией. Информатика. 7 класс
Персональный компьютер. Компьютер как универсальное устройство для работы с информацией. Информатика. 7 класс Модель даних “сутність-зв’язок”
Модель даних “сутність-зв’язок” Социальные сети ПАО Сбербанк
Социальные сети ПАО Сбербанк