- Структуры данных

Содержание
- 2. Структуры данных – что это? Структура данных – способ организации хранения данных и доступа к ним,
- 3. Простейшие структуры данных массив линейный однонаправленный список стек очередь
- 4. Массив Удобные операции: доступ к элементу массива по индексу; просмотр элементов по возрастанию индексов; поиск элемента
- 5. Дихотомия Дихотомия («деление пополам») – алгоритм поиска элемента по значению в упорядоченном по возрастанию массиве Описание
- 6. Реализация дихотомии bool Find(int what, int* mass, int first, int last) { if (first>last) return false;
- 7. Списки Список – совокупность элементов, каждый из которых, кроме последнего, содержит информацию (ссылку) о следующем элементе.
- 8. Структура линейного однонаправленного списка
- 9. Реализация списка с использованием динамической памяти struct ListItem { int Info; ListItem *Next; }; ListItem *First;
- 10. Схема добавления в список нового элемента
- 11. Реализация вставки в список нового элемента В начало списка ListItem *P = new ListItem; // заполнение
- 12. Схема удаления элемента из списка
- 13. Реализация удаления элемента из списка Из начала списка if (First == NULL) // обработать ситуацию ”List
- 14. Просмотр всех элементов списка ListItem *P = First; while (P != NULL) { // выполнить действия
- 15. Организация списка с использованием массива
- 16. Проблема "сборки мусора" Суть проблемы: как организовать повторное использование памяти, освободившейся после удаления элемента списка При
- 17. Сборка мусора при организации списка в виде массива Индекс начального элемента: 5 Индекс начального свободного элемента:
- 18. Инициализация списка в виде массива Индекс начального элемента: -1 Индекс начального свободного элемента: 0
- 19. Работа со списком в виде массива Добавляем «Кузнецов» Индекс начального элемента: 0 Индекс начального свободного элемента:
- 20. Работа со списком в виде массива (часть 2) Добавляем «Иванов» Индекс начального элемента: 1 Индекс начального
- 21. Работа со списком в виде массива (часть 3) Добавляем «Ковалёв» Индекс начального элемента: 1 Индекс начального
- 22. Работа со списком в виде массива (часть 4) Удаляем «Иванов» Индекс начального элемента: 2 Индекс начального
- 23. Стеки Стек – структура данных, предназначенная для выполнения следующих операций: основные занесение нового элемента на вершину
- 24. Реализация стека с использованием массивов
- 25. Реализация стека на массивах int * Stack, Top = 0; … Stack = new int [N];
- 26. Очереди Очередь – структура данных, предназначенная для выполнения следующих операций: основные занесение нового элемента в конец
- 27. Реализация очереди на массивах голова (начало) хвост (конец)
- 28. Организация циклической очереди голова, хвост голова хвост Пустая очередь Заполненная полностью очередь
- 29. Программная реализация циклической очереди int *Queue, Front = 0, Rear = 0; … Queue = new
- 31. Скачать презентацию

Структуры данных – что это?
Структура данных – способ организации хранения данных
Структуры данных – что это?
Структура данных – способ организации хранения данных

Простейшие структуры данных
массив
линейный однонаправленный список
стек
очередь
Простейшие структуры данных
массив
линейный однонаправленный список
стек
очередь

Массив
Удобные операции:
доступ к элементу массива по индексу;
просмотр элементов по возрастанию индексов;
поиск
Массив
Удобные операции:
доступ к элементу массива по индексу;
просмотр элементов по возрастанию индексов;
поиск

Дихотомия
Дихотомия («деление пополам») – алгоритм поиска элемента по значению в упорядоченном
Дихотомия
Дихотомия («деление пополам») – алгоритм поиска элемента по значению в упорядоченном

Реализация дихотомии
bool Find(int what, int* mass, int first, int last) {
if
Реализация дихотомии
bool Find(int what, int* mass, int first, int last) {
if

Списки
Список – совокупность элементов, каждый из которых, кроме последнего, содержит информацию
Списки
Список – совокупность элементов, каждый из которых, кроме последнего, содержит информацию
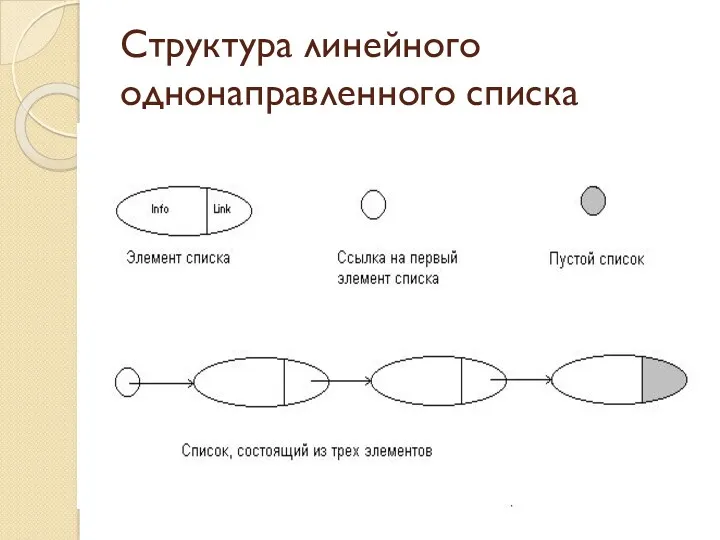
Структура линейного однонаправленного списка
Структура линейного однонаправленного списка

Реализация списка с использованием динамической памяти
struct ListItem {
int Info;
ListItem *Next;
};
ListItem
Реализация списка с использованием динамической памяти
struct ListItem {
int Info;
ListItem *Next;
};
ListItem
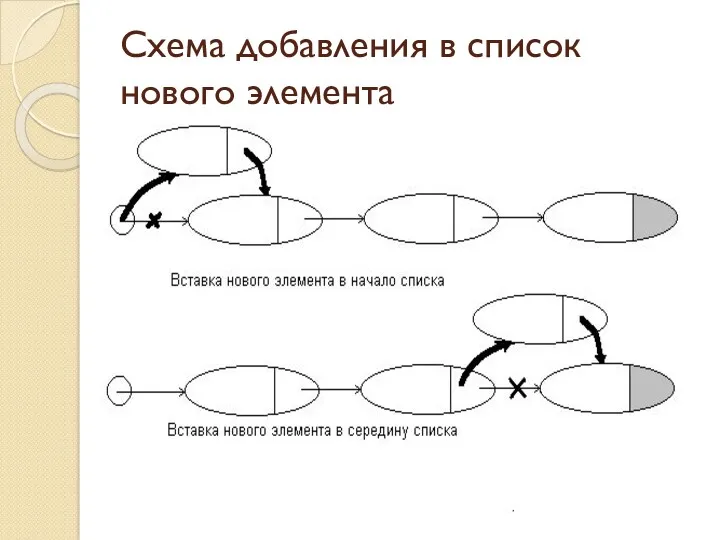
Схема добавления в список нового элемента
Схема добавления в список нового элемента

Реализация вставки в список нового элемента
В начало списка
ListItem *P = new
Реализация вставки в список нового элемента
В начало списка
ListItem *P = new
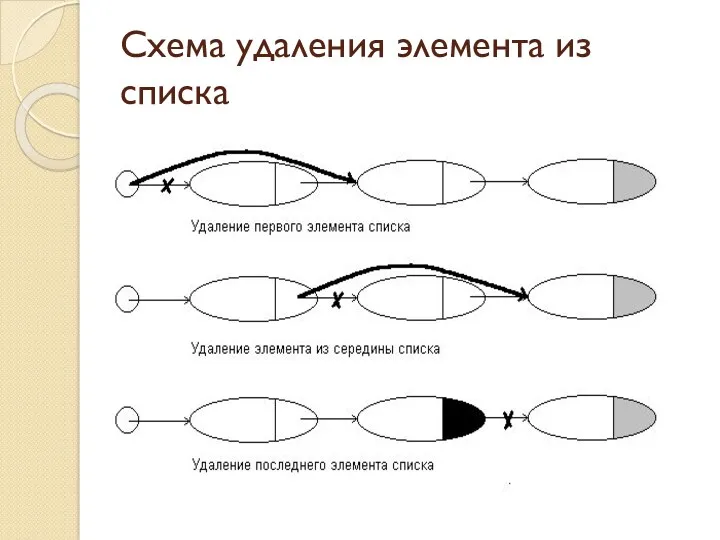
Схема удаления элемента из списка
Схема удаления элемента из списка

Реализация удаления элемента из списка
Из начала списка
if (First == NULL)
//
Реализация удаления элемента из списка
Из начала списка
if (First == NULL)
//

Просмотр всех элементов списка
ListItem *P = First;
while (P != NULL) {
Просмотр всех элементов списка
ListItem *P = First;
while (P != NULL) {
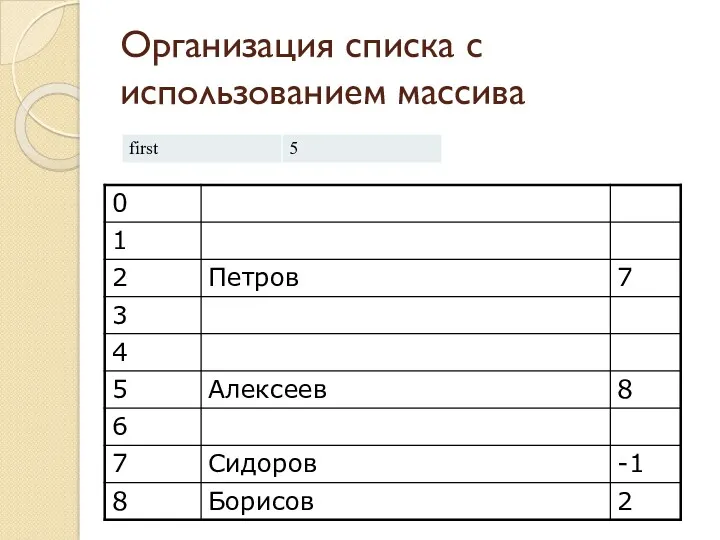
Организация списка с использованием массива
Организация списка с использованием массива

Проблема "сборки мусора"
Суть проблемы: как организовать повторное использование памяти, освободившейся после
Проблема "сборки мусора"
Суть проблемы: как организовать повторное использование памяти, освободившейся после

Сборка мусора при организации списка в виде массива
Индекс начального элемента: 5
Индекс
Сборка мусора при организации списка в виде массива
Индекс начального элемента: 5
Индекс

Инициализация списка в виде массива
Индекс начального элемента: -1
Индекс начального свободного элемента:
Инициализация списка в виде массива
Индекс начального элемента: -1
Индекс начального свободного элемента:
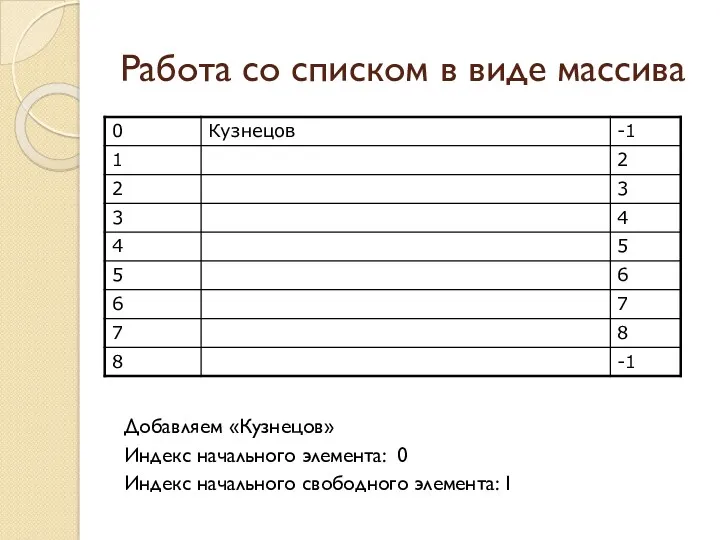
Работа со списком в виде массива
Добавляем «Кузнецов»
Индекс начального элемента: 0
Индекс начального
Работа со списком в виде массива
Добавляем «Кузнецов»
Индекс начального элемента: 0
Индекс начального

Работа со списком в виде массива (часть 2)
Добавляем «Иванов»
Индекс начального элемента:
Работа со списком в виде массива (часть 2)
Добавляем «Иванов»
Индекс начального элемента:

Работа со списком в виде массива (часть 3)
Добавляем «Ковалёв»
Индекс начального элемента:
Работа со списком в виде массива (часть 3)
Добавляем «Ковалёв»
Индекс начального элемента:

Работа со списком в виде массива (часть 4)
Удаляем «Иванов»
Индекс начального элемента:
Работа со списком в виде массива (часть 4)
Удаляем «Иванов»
Индекс начального элемента:

Стеки
Стек – структура данных, предназначенная для выполнения следующих операций:
основные
занесение нового элемента
Стеки
Стек – структура данных, предназначенная для выполнения следующих операций:
основные
занесение нового элемента

Реализация стека с использованием массивов
Реализация стека с использованием массивов

Реализация стека на массивах
int * Stack, Top = 0;
…
Stack = new
Реализация стека на массивах
int * Stack, Top = 0;
…
Stack = new

Очереди
Очередь – структура данных, предназначенная для выполнения следующих операций:
основные
занесение нового элемента
Очереди
Очередь – структура данных, предназначенная для выполнения следующих операций:
основные
занесение нового элемента
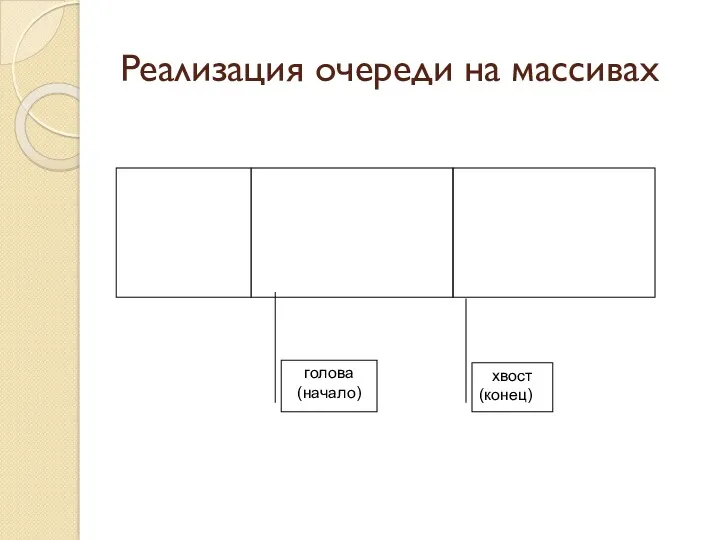
Реализация очереди на массивах
голова (начало)
хвост
(конец)
Реализация очереди на массивах
голова (начало)
хвост
(конец)
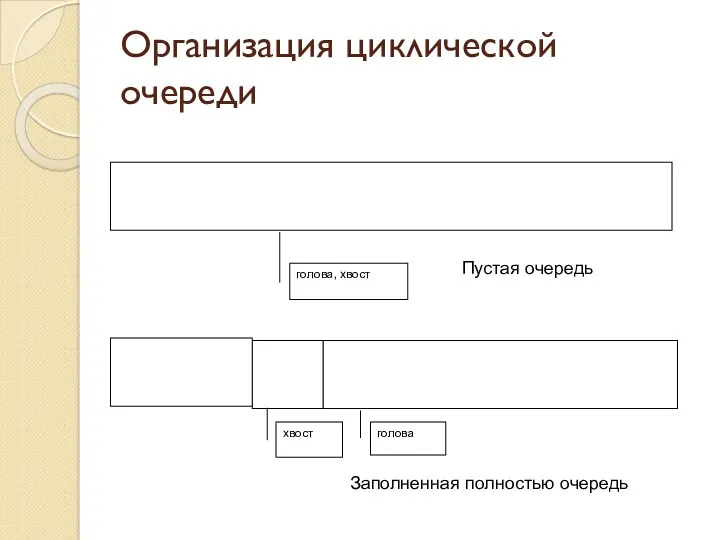
Организация циклической очереди
голова, хвост
голова
хвост
Пустая очередь
Заполненная полностью очередь
Организация циклической очереди
голова, хвост
голова
хвост
Пустая очередь
Заполненная полностью очередь

Программная реализация циклической очереди
int *Queue, Front = 0, Rear = 0;
…
Queue
Программная реализация циклической очереди
int *Queue, Front = 0, Rear = 0;
…
Queue
 Кодирование текстовой информации. Представление информации в компьютере
Кодирование текстовой информации. Представление информации в компьютере HTML Forms
HTML Forms Технология ATM, Fire Wire. Беспроводные технологии. Лекция №6
Технология ATM, Fire Wire. Беспроводные технологии. Лекция №6 Продвижение ВФСК ГТО в социальных сетях
Продвижение ВФСК ГТО в социальных сетях Информация
Информация Архітектура, розроблення та експлуатація інформаційних систем корпоративного і національного рівнів
Архітектура, розроблення та експлуатація інформаційних систем корпоративного і національного рівнів Глобальное информационное общество
Глобальное информационное общество Персональный компьютер
Персональный компьютер Презентация. Оперативная память
Презентация. Оперативная память Construct 2. Знакомство c программой Part 2 event sheet & текстовая строка
Construct 2. Знакомство c программой Part 2 event sheet & текстовая строка Запуск и Интерфейс программы AutoCAD-2014
Запуск и Интерфейс программы AutoCAD-2014 Основы логики
Основы логики Инструкция участия в вебинаре в системе веб-коммуникаций на базе IVA R
Инструкция участия в вебинаре в системе веб-коммуникаций на базе IVA R Антивирустық бағдарламалар. Кірме сөздер
Антивирустық бағдарламалар. Кірме сөздер Основы программирования (ОП)
Основы программирования (ОП) Презентации
Презентации Протокол NAT. Характеристики NAT
Протокол NAT. Характеристики NAT Оборудование биометрической системы контроля и управления доступом БиоСКУД Сонда Эксперт
Оборудование биометрической системы контроля и управления доступом БиоСКУД Сонда Эксперт Cyber-Safety
Cyber-Safety Ввод-вывод. (Тема 16)
Ввод-вывод. (Тема 16) ВКР: Разработка прототипа автоматизированного рабочего места диспетчера учебного учреждения
ВКР: Разработка прототипа автоматизированного рабочего места диспетчера учебного учреждения Анимации в презентации
Анимации в презентации Использование современных технологий в обучении музыке
Использование современных технологий в обучении музыке 1_1 Энтропия как мера степени неопределенности
1_1 Энтропия как мера степени неопределенности Информационные модели на графах
Информационные модели на графах Внеклассное мероприятие. Путешествие с Инфознайкой
Внеклассное мероприятие. Путешествие с Инфознайкой Комп’ютерне моделювання процесу дорожнього руху
Комп’ютерне моделювання процесу дорожнього руху Работа с аудиоредактором звуковых файлов Audacity
Работа с аудиоредактором звуковых файлов Audacity