- Структуры данных

Содержание
- 2. Структура данных – это способ хранения и организации данных, облегчающих доступ к этим данным и их
- 3. ТИПИЧНЫЕ ОПЕРАЦИИ СО СТРУКТУРАМИ ДАННЫХ Search Insert Delete Minimum Maximum Sort
- 4. СТРУКТУРА ДАННЫХ СТЕК Стек (stack) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу
- 5. СТРУКТУРА ДАННЫХ СТЕК Возможны три операции со стеком: добавление элемента (иначе проталкивание, push), удаление элемента (pop)
- 6. СВЯЗНЫЙ СПИСОК Связный список — базовая динамическая структура данных, состоящая из узлов, каждый из которых содержит
- 7. СВЯЗНЫЙ СПИСОК Односвязный список Двусвязный список Кольцевой связный список
- 8. БИНАРНОЕ ДЕРЕВО Двоичное дерево — иерархическая структура данных, в которой каждый узел имеет не более двух
- 9. КРАСНО-ЧЕРНОЕ ДЕРЕВО Красно-чёрное дерево — это одно из самобалансирующихся двоичных деревьев поиска, гарантирующих логарифмический рост высоты
- 10. КРАСНО-ЧЕРНОЕ ДЕРЕВО
- 11. ХЭШ-ТАБЛИЦЫ Хеш-таблица — это структура данных, реализующая интерфейс ассоциативного массива, а именно, она позволяет хранить пары
- 12. ХЭШ-ТАБЛИЦЫ Хеширование применяется в следующих случаях: при построении ассоциативных массивов; при поиске дубликатов в сериях наборов
- 13. ХЭШ-ТАБЛИЦЫ Существуют два основных варианта хеш-таблиц: с цепочками и открытой адресацией. Хеш-таблица содержит некоторый массив, элементы
- 14. ХЭШ-ТАБЛИЦЫ
- 15. ХЭШ-ТАБЛИЦЫ
- 17. Скачать презентацию

Структура данных – это способ хранения и организации данных, облегчающих доступ

ТИПИЧНЫЕ ОПЕРАЦИИ СО СТРУКТУРАМИ ДАННЫХ
Search
Insert
Delete
Minimum
Maximum
Sort
Search
Insert
Delete
Minimum
Maximum
Sort

СТРУКТУРА ДАННЫХ СТЕК
Стек (stack) — абстрактный тип данных, представляющий собой список
СТРУКТУРА ДАННЫХ СТЕК
Стек (stack) — абстрактный тип данных, представляющий собой список
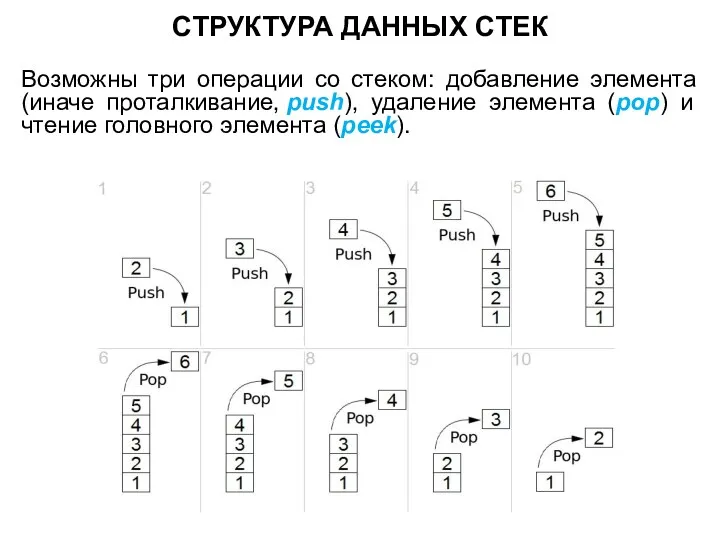
СТРУКТУРА ДАННЫХ СТЕК
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push),
СТРУКТУРА ДАННЫХ СТЕК
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push),

СВЯЗНЫЙ СПИСОК
Связный список — базовая динамическая структура данных, состоящая из узлов,
СВЯЗНЫЙ СПИСОК
Связный список — базовая динамическая структура данных, состоящая из узлов,
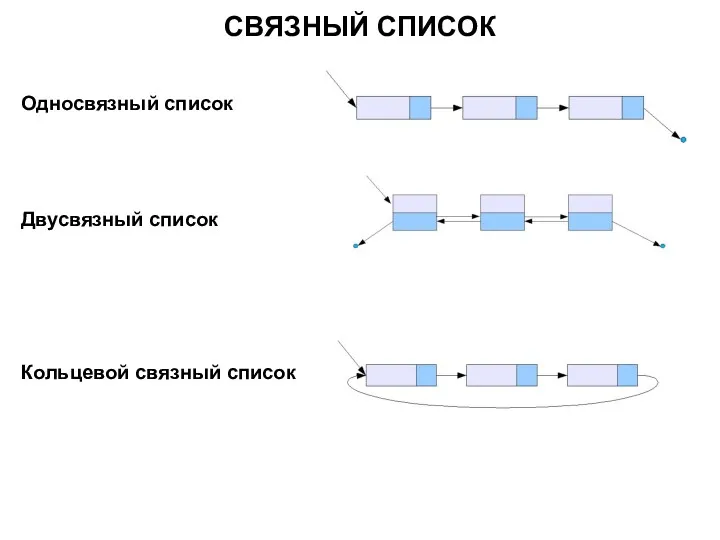
СВЯЗНЫЙ СПИСОК
Односвязный список
Двусвязный список
Кольцевой связный список
СВЯЗНЫЙ СПИСОК
Односвязный список
Двусвязный список
Кольцевой связный список
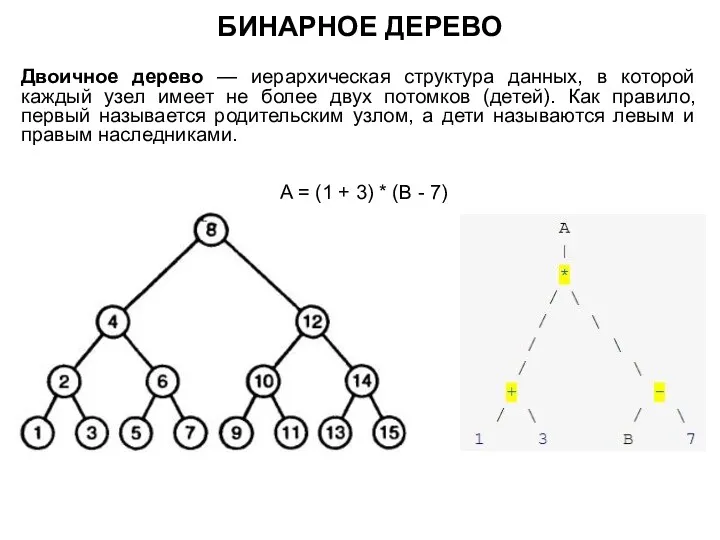
БИНАРНОЕ ДЕРЕВО
Двоичное дерево — иерархическая структура данных, в которой каждый узел
БИНАРНОЕ ДЕРЕВО
Двоичное дерево — иерархическая структура данных, в которой каждый узел

КРАСНО-ЧЕРНОЕ ДЕРЕВО
Красно-чёрное дерево — это одно из самобалансирующихся двоичных деревьев поиска,
КРАСНО-ЧЕРНОЕ ДЕРЕВО
Красно-чёрное дерево — это одно из самобалансирующихся двоичных деревьев поиска,
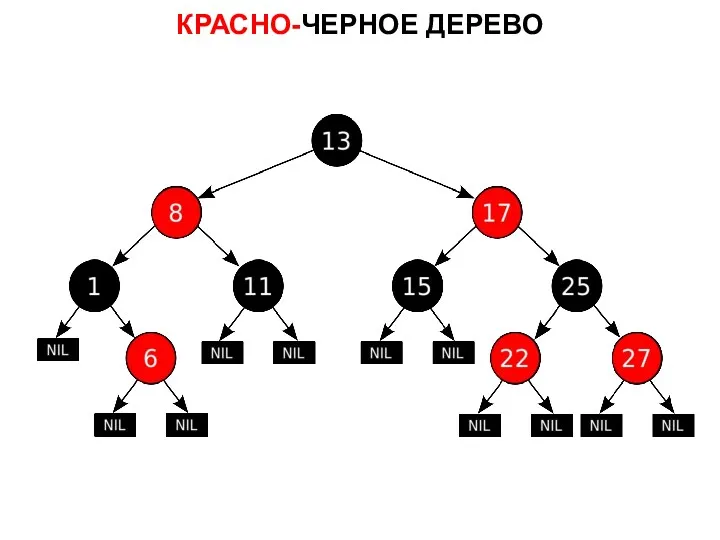
КРАСНО-ЧЕРНОЕ ДЕРЕВО
КРАСНО-ЧЕРНОЕ ДЕРЕВО

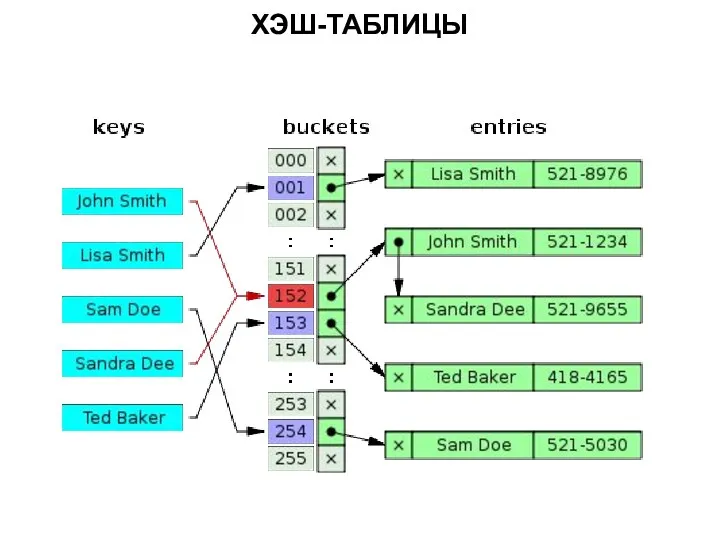
ХЭШ-ТАБЛИЦЫ
Хеш-таблица — это структура данных, реализующая интерфейс ассоциативного массива, а именно,
ХЭШ-ТАБЛИЦЫ
Хеш-таблица — это структура данных, реализующая интерфейс ассоциативного массива, а именно,

ХЭШ-ТАБЛИЦЫ
Хеширование применяется в следующих случаях:
при построении ассоциативных массивов;
при поиске дубликатов в
ХЭШ-ТАБЛИЦЫ
Хеширование применяется в следующих случаях:
при построении ассоциативных массивов;
при поиске дубликатов в

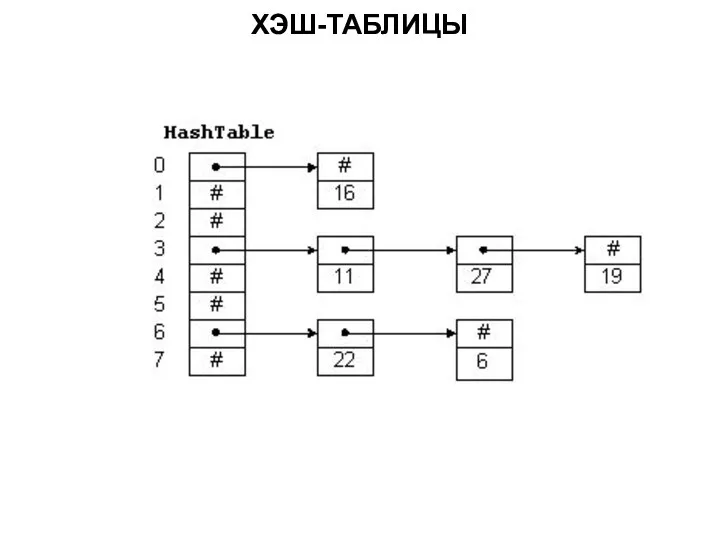
ХЭШ-ТАБЛИЦЫ
Существуют два основных варианта хеш-таблиц: с цепочками и открытой адресацией. Хеш-таблица
ХЭШ-ТАБЛИЦЫ
Существуют два основных варианта хеш-таблиц: с цепочками и открытой адресацией. Хеш-таблица
ХЭШ-ТАБЛИЦЫ
ХЭШ-ТАБЛИЦЫ
ХЭШ-ТАБЛИЦЫ
ХЭШ-ТАБЛИЦЫ
 Установка Camtasia Studio 8
Установка Camtasia Studio 8 Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN
Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN Вестник ХММР №4, июль 2018
Вестник ХММР №4, июль 2018 Структура компьютера. Понятие вычислительной системы
Структура компьютера. Понятие вычислительной системы Информационные технологии в юридической деятельности. 2 семестр. Компьютерные сети и технологии
Информационные технологии в юридической деятельности. 2 семестр. Компьютерные сети и технологии Компьютерные сети
Компьютерные сети This is your presentation title
This is your presentation title This is your presentation title
This is your presentation title Веб-сервис по анализу цен интернет-магазинов
Веб-сервис по анализу цен интернет-магазинов Создание видеороликов. Мастер-класс
Создание видеороликов. Мастер-класс IP-адреса, маски подсетей
IP-адреса, маски подсетей Информационные ресурсы. Этические и правовые нормы информационной деятельности людей.
Информационные ресурсы. Этические и правовые нормы информационной деятельности людей. ВКР: Разработка ANDROID приложения с использованием MVP архитектуры
ВКР: Разработка ANDROID приложения с использованием MVP архитектуры Тематический библиографический список, как одна из форм библиографических пособий малых форм
Тематический библиографический список, как одна из форм библиографических пособий малых форм Application State services
Application State services Оператор ветвления (условный оператор)
Оператор ветвления (условный оператор) Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3
Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3 Инструкция по заполнению регистрационной формы конференции
Инструкция по заполнению регистрационной формы конференции Программирование на языке Java. Тема 23. Рекурсия
Программирование на языке Java. Тема 23. Рекурсия Сравнительная характеристика OC Windows XP и OC Windows 8
Сравнительная характеристика OC Windows XP и OC Windows 8 Создание проекта супермаркета в 3D-редакторе SKETCHUP
Создание проекта супермаркета в 3D-редакторе SKETCHUP Среда Visual Basic. Основные понятия VB
Среда Visual Basic. Основные понятия VB Алгоритм. Кто такой исполнитель?
Алгоритм. Кто такой исполнитель? Етапи побудови інформаційної моделі (урок 7)
Етапи побудови інформаційної моделі (урок 7) HTML/CSS
HTML/CSS Закачка сайта на сервер по ftp-протоколу в среде Dreamweaver.
Закачка сайта на сервер по ftp-протоколу в среде Dreamweaver. Презентация к уроку Основные этапы разработки и исследования моделей на компьютере
Презентация к уроку Основные этапы разработки и исследования моделей на компьютере Анимация. Создать черепашку
Анимация. Создать черепашку