- Сжатие данных

Содержание
- 2. Цели сжатия данных – экономия ресурсов при хранении или передаче данных Сжатие данных это процесс, обеспечивающий
- 3. Коэффициент сжатия – это величина для обозначения эффективности метода сжатия, равная отношению количества информации до и
- 4. Сжатие данных может происходить с потерями и без потерь Сжатие без потерь (полностью обратимое) – это
- 5. Сжатие с потерями Сжатие без потерь
- 6. Алгоритмы сжатия символьных данных Статистические методы – это методы сжатия, основанные на статистической обработке текста. Словарное
- 7. Упаковка однородных данных Закодируем сообщение длиной 16 символов 0,258-23,5+18,01 В кодировке ASCII сообщение составляет 16 байт.
- 8. + коэффициент сжатия увеличивается с увеличением размера символьного сообщения; необходимо указывать для распаковки новую кодовую таблицу;
- 9. Статистический метод сжатия Алгоритм Хаффмана Разные символы встречаются в сообщении с разной частотой, например для русского
- 10. Хаффмановское кодирование (сжатие) – это метод сжатия, присваивающий символам алфавита коды переменной длины, основы-ваясь на частоте
- 11. Проблема декодирования Пример : пусть коды символов a-10, b -101, c-1010 Декодировать сообщение 10101011010 10 101
- 12. Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового
- 13. Пример: построить код Хаффмана для фразы ОТ_ТОПОТА_КОПЫТ_ПЫЛЬ_ПО_ПОЛЮ_ЛЕТИТ Определим частоту вхождения символов в фразу: Строим орграф Хаффмана:
- 14. КОРЕНЬ ДЕРЕВА Т- О- Ы- Л- Ю- Ь- Е- К- И- А- 0 0 0 0
- 15. Построены префиксные коды символов: Сообщение в новых кодах содержит 110 бит, в кодировке ASCII – 34
- 16. Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов; Классический алгоритм Хаффмана требует хранения
- 17. Метод словарей Алгоритм сжатия LZ Этот алгоритм был впервые описан в работах А. Лемпеля и Дж.
- 18. Алгоритм разработан израильскими математиками Якобом Зивом и Аб рахам ом Лемпелем. Словарь содержит, кроме многих других,
- 19. -применим для любых данных; - очень высокая скорость сжатия; - высок коэффициент сжатия; + - Достоинства
- 20. Вопросы по теме: Что такое архивирование данных? Для данных каких типов возможно применять архивирование? Для каких
- 22. Скачать презентацию
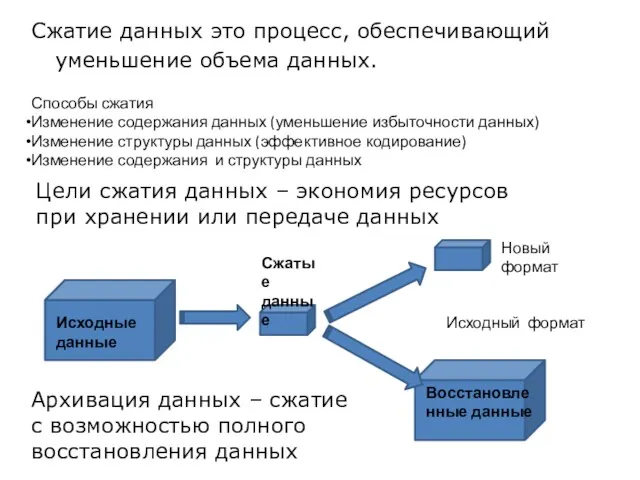
Цели сжатия данных – экономия ресурсов при хранении или передаче данных
Сжатие
Цели сжатия данных – экономия ресурсов при хранении или передаче данных
Сжатие
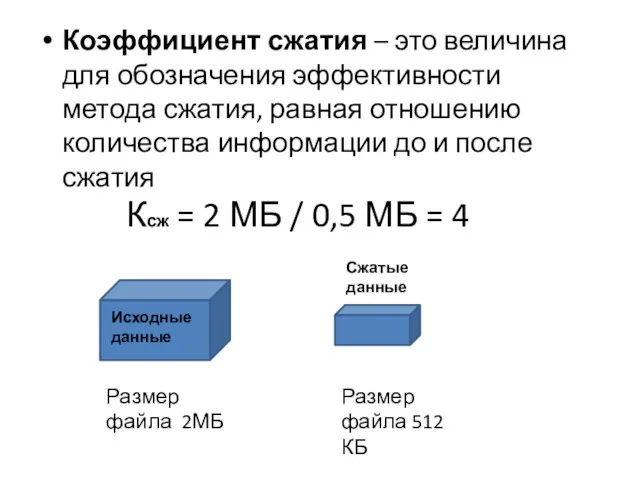
Коэффициент сжатия – это величина для обозначения эффективности метода сжатия, равная
Коэффициент сжатия – это величина для обозначения эффективности метода сжатия, равная

Сжатие данных может происходить с потерями и без потерь
Сжатие без
Сжатие данных может происходить с потерями и без потерь
Сжатие без
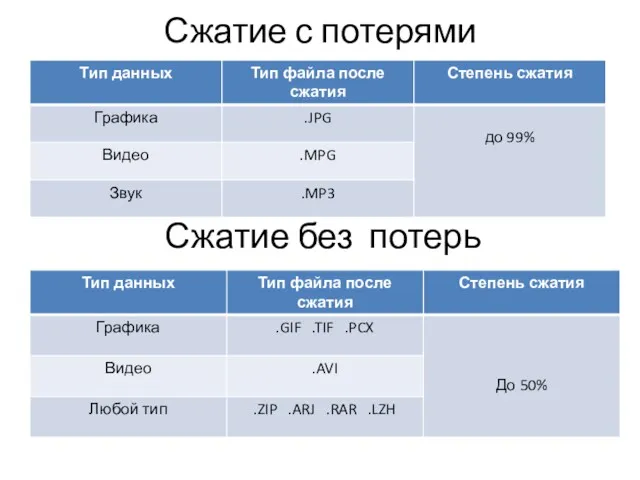
Сжатие с потерями
Сжатие без потерь
Сжатие с потерями
Сжатие без потерь

Алгоритмы сжатия символьных данных
Статистические методы – это методы сжатия, основанные на
Алгоритмы сжатия символьных данных
Статистические методы – это методы сжатия, основанные на

Упаковка однородных данных
Закодируем сообщение длиной 16 символов
0,258-23,5+18,01
В кодировке ASCII сообщение составляет
Упаковка однородных данных
Закодируем сообщение длиной 16 символов
0,258-23,5+18,01
В кодировке ASCII сообщение составляет

+ коэффициент сжатия увеличивается с увеличением размера символьного сообщения;
необходимо указывать для
+ коэффициент сжатия увеличивается с увеличением размера символьного сообщения;
необходимо указывать для

Статистический метод сжатия
Алгоритм Хаффмана
Разные символы встречаются в сообщении с разной
Статистический метод сжатия
Алгоритм Хаффмана
Разные символы встречаются в сообщении с разной

Хаффмановское кодирование (сжатие) – это метод сжатия, присваивающий символам алфавита
Хаффмановское кодирование (сжатие) – это метод сжатия, присваивающий символам алфавита
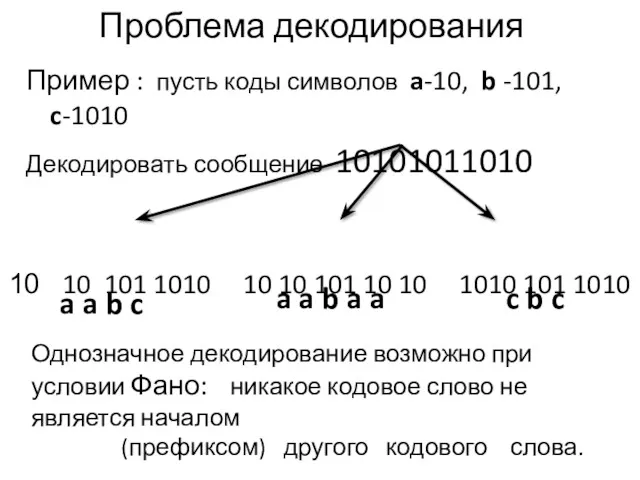
Проблема декодирования
Пример : пусть коды символов a-10, b -101, c-1010
Декодировать
Проблема декодирования
Пример : пусть коды символов a-10, b -101, c-1010
Декодировать
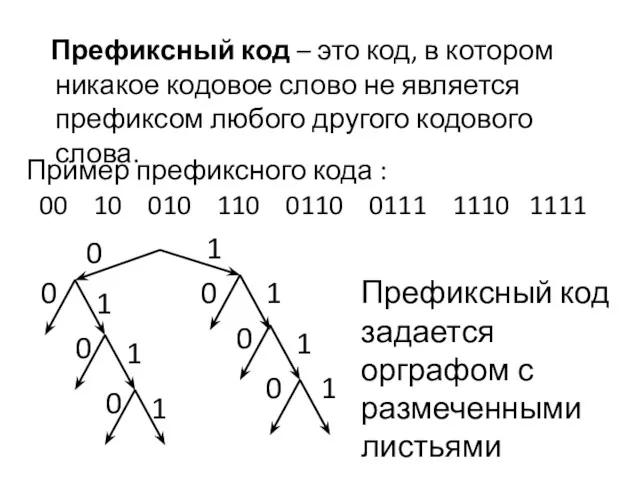
Префиксный код – это код, в котором никакое кодовое слово
Префиксный код – это код, в котором никакое кодовое слово

Пример: построить код Хаффмана для фразы
ОТ_ТОПОТА_КОПЫТ_ПЫЛЬ_ПО_ПОЛЮ_ЛЕТИТ
Определим частоту вхождения символов в
Пример: построить код Хаффмана для фразы
ОТ_ТОПОТА_КОПЫТ_ПЫЛЬ_ПО_ПОЛЮ_ЛЕТИТ
Определим частоту вхождения символов в
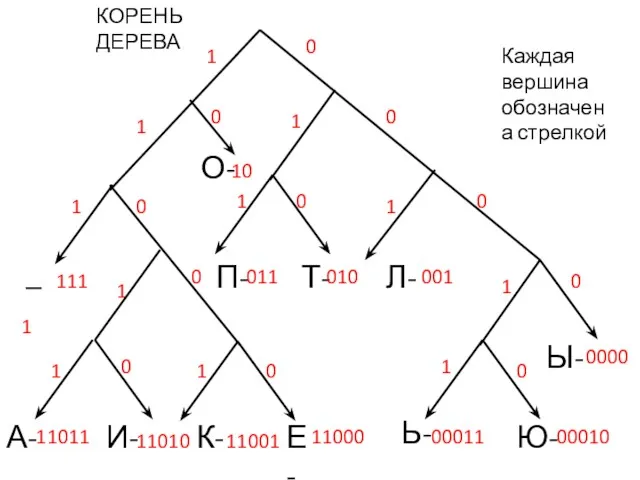
КОРЕНЬ ДЕРЕВА
Т-
О-
Ы-
Л-
Ю-
Ь-
Е-
К-
И-
А-
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
00011
00010
11000
11001
11011
11010
001
010
011
111
10
0000
Каждая вершина обозначена стрелкой
КОРЕНЬ ДЕРЕВА
Т-
О-
Ы-
Л-
Ю-
Ь-
Е-
К-
И-
А-
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
00011
00010
11000
11001
11011
11010
001
010
011
111
10
0000
Каждая вершина обозначена стрелкой

Построены префиксные коды символов:
Сообщение в новых кодах содержит 110 бит, в
Построены префиксные коды символов:
Сообщение в новых кодах содержит 110 бит, в

Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых

Метод словарей
Алгоритм сжатия LZ
Этот алгоритм был впервые описан в
Метод словарей
Алгоритм сжатия LZ
Этот алгоритм был впервые описан в

Алгоритм разработан израильскими математиками Якобом Зивом и Аб рахам ом Лемпелем.
Алгоритм разработан израильскими математиками Якобом Зивом и Аб рахам ом Лемпелем.

-применим для любых данных;
- очень высокая скорость сжатия;
- высок коэффициент сжатия;
+
-
Достоинства
-применим для любых данных;
- очень высокая скорость сжатия;
- высок коэффициент сжатия;
+
-
Достоинства

Вопросы по теме:
Что такое архивирование данных? Для данных каких типов возможно
Вопросы по теме:
Что такое архивирование данных? Для данных каких типов возможно
 Теория вычислительных процессов
Теория вычислительных процессов Интернет: вред и польза
Интернет: вред и польза Положительное и отрицательное влияние сети Интернет
Положительное и отрицательное влияние сети Интернет Урок в 8 классе Перевод из двоичной системы счисления в десятичную
Урок в 8 классе Перевод из двоичной системы счисления в десятичную Автоматическая обработка информации
Автоматическая обработка информации Управление памятью
Управление памятью Большие данные
Большие данные CSS (Cascading Style Sheets)
CSS (Cascading Style Sheets) Файловые системы
Файловые системы Жизненный цикл ИС. Основы применения инструментальных средств ИТ . Создание автоматизированных информационных систем
Жизненный цикл ИС. Основы применения инструментальных средств ИТ . Создание автоматизированных информационных систем Всё о видео
Всё о видео ColorGate Final. Полезные функции ColorGate
ColorGate Final. Полезные функции ColorGate Microsoft Solutions Framework. Модель процессов MSF
Microsoft Solutions Framework. Модель процессов MSF Электрондық құжат айналымы
Электрондық құжат айналымы Операції над об’єктами файлової системи
Операції над об’єктами файлової системи Информационная культура. Основные понятия
Информационная культура. Основные понятия Основні поняття позиційної і непозиційної системи числення
Основні поняття позиційної і непозиційної системи числення Роботы -наше продолжение или погибель?
Роботы -наше продолжение или погибель? Вставка объектов. Как добавить в презентацию объекты WordArt
Вставка объектов. Как добавить в презентацию объекты WordArt Operating System Concepts. Chapter 1: Introduction
Operating System Concepts. Chapter 1: Introduction Транзакції та блокування
Транзакції та блокування Жұлдызды сәт. І тур Дешифратор ІІ тур Қисынды ойлай білейік
Жұлдызды сәт. І тур Дешифратор ІІ тур Қисынды ойлай білейік Инструкция по запуску дистанционных курсов
Инструкция по запуску дистанционных курсов Мастер-класс в 9 классе на тему: Создание собственных публикаций. Проект: Визитная карточка школы.
Мастер-класс в 9 классе на тему: Создание собственных публикаций. Проект: Визитная карточка школы. Основные свойства MPI - Message Passing Interface, интерфейс передачи сообщений Стандарт MPI 4.0. Лекция 4
Основные свойства MPI - Message Passing Interface, интерфейс передачи сообщений Стандарт MPI 4.0. Лекция 4 Оформление визиток: правила и типичные ошибки
Оформление визиток: правила и типичные ошибки Криптография. Симметричные алгоритмы шифрования
Криптография. Симметричные алгоритмы шифрования Правила техники безопасности в компьютерном классе
Правила техники безопасности в компьютерном классе