- TechDays

Содержание
- 2. General Programming on Graphical Processing Units Quentin Ochem October 4th, 2018
- 3. What is GPGPU? GPU were traditionally dedicated to graphical rendering … … but their capability is
- 4. GPGPU Programming Paradigm Debug? Optimize data transfer? How to optimize occupancy Avoid data races? Refactor parallel
- 5. Why do we care about Ada? (1/2) Source: https://www.adacore.com/uploads/techPapers/Controlling-Costs-with-Software-Language-Choice-AdaCore-VDC-WP.PDF
- 6. Why do we care about Ada (2/2) Signal processing Machine learning Monte-carlo simulation Trajectory prediction Cryptography
- 7. Available Hardware NVIDIA GeForce / Tesla / Quadro AMD Radeon Intel HD NVIDIA Tegra ARM Mali
- 8. Ada Support
- 9. Three options Interfacing with existing libraries “Ada-ing” existing languages Ada 2020
- 10. Interfacing existing libraries Already possible and straightforward effort “gcc –fdump-ada-specs” will provide a first binding of
- 11. “Ada-ing” existing languages CUDA – kernel-based language specific to NVIDIA OpenCL – portable version of CUDA
- 12. CUDA Example (Device code) procedure Test_Cuda (A : out Float_Array; B, C : Float_Array) with Export
- 13. CUDA Example (Host code) A, B, C : Float_Array; begin -- initialization of B and C
- 14. OpenCL example Similar to CUDA in principle Requires more code on the host code (no call
- 15. OpenACC example (Device & Host) procedure Test_OpenACC is A, B, C : Float_Array; begin -- initialization
- 16. Ada 2020 procedure Test_Ada2020 is A, B, C : Float_Array; begin -- initialization of B and
- 17. Lots of other language considerations Identification of memory layout (per thread, per block, global) Thread allocation
- 18. A word on SPARK X_Size : 1000; Y_Size : 10; Data : array (1 .. X_Size
- 20. Скачать презентацию

General Programming on Graphical Processing Units
Quentin Ochem
October 4th, 2018
General Programming on Graphical Processing Units
Quentin Ochem
October 4th, 2018

What is GPGPU?
GPU were traditionally dedicated to graphical rendering …
… but
What is GPGPU?
GPU were traditionally dedicated to graphical rendering …
… but

GPGPU Programming Paradigm
Debug?
Optimize data transfer?
How to optimize occupancy
Avoid data races?
Refactor parallel
GPGPU Programming Paradigm
Debug?
Optimize data transfer?
How to optimize occupancy
Avoid data races?
Refactor parallel
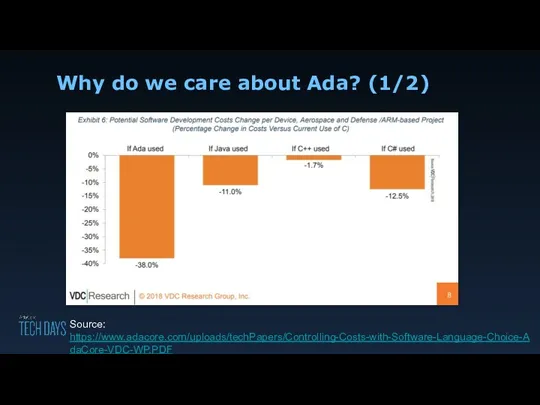
Why do we care about Ada? (1/2)
Source: https://www.adacore.com/uploads/techPapers/Controlling-Costs-with-Software-Language-Choice-AdaCore-VDC-WP.PDF
Why do we care about Ada? (1/2)
Source: https://www.adacore.com/uploads/techPapers/Controlling-Costs-with-Software-Language-Choice-AdaCore-VDC-WP.PDF

Why do we care about Ada (2/2)
Signal processing
Machine learning
Monte-carlo simulation
Trajectory prediction
Cryptography
Image
Why do we care about Ada (2/2)
Signal processing
Machine learning
Monte-carlo simulation
Trajectory prediction
Cryptography
Image

Available Hardware
NVIDIA GeForce / Tesla / Quadro
AMD Radeon
Intel HD
NVIDIA Tegra
ARM Mali
Qualcomm
Available Hardware
NVIDIA GeForce / Tesla / Quadro
AMD Radeon
Intel HD
NVIDIA Tegra
ARM Mali
Qualcomm

Ada Support
Ada Support

Three options
Interfacing with existing libraries
“Ada-ing” existing languages
Ada 2020
Three options
Interfacing with existing libraries
“Ada-ing” existing languages
Ada 2020

Interfacing existing libraries
Already possible and straightforward effort
“gcc –fdump-ada-specs” will provide a
Interfacing existing libraries
Already possible and straightforward effort
“gcc –fdump-ada-specs” will provide a

“Ada-ing” existing languages
CUDA – kernel-based language specific to NVIDIA
OpenCL – portable
“Ada-ing” existing languages
CUDA – kernel-based language specific to NVIDIA
OpenCL – portable

CUDA Example (Device code)
procedure Test_Cuda
(A : out Float_Array; B,
CUDA Example (Device code)
procedure Test_Cuda
(A : out Float_Array; B,

CUDA Example (Host code)
A, B, C : Float_Array;
begin
-- initialization
CUDA Example (Host code)
A, B, C : Float_Array;
begin
-- initialization

OpenCL example
Similar to CUDA in principle
Requires more code on the host
OpenCL example
Similar to CUDA in principle
Requires more code on the host

OpenACC example (Device & Host)
procedure Test_OpenACC is
A, B, C :
OpenACC example (Device & Host)
procedure Test_OpenACC is
A, B, C :

Ada 2020
procedure Test_Ada2020 is
A, B, C : Float_Array;
begin
-- initialization
Ada 2020
procedure Test_Ada2020 is
A, B, C : Float_Array;
begin
-- initialization

Lots of other language considerations
Identification of memory layout (per thread, per
Lots of other language considerations
Identification of memory layout (per thread, per

A word on SPARK
X_Size : 1000;
Y_Size : 10;
Data
A word on SPARK
X_Size : 1000;
Y_Size : 10;
Data
 Фізичні основи сучасних бездротових засобів зв'язку. Радіолокація
Фізичні основи сучасних бездротових засобів зв'язку. Радіолокація Інформаційні системи та технології
Інформаційні системи та технології ТехноПорт. Современные методы проектирования, создания авиамоделей и их запуска. Основы радиоэлектроники
ТехноПорт. Современные методы проектирования, создания авиамоделей и их запуска. Основы радиоэлектроники Кодирование графической информации
Кодирование графической информации The architecture of Web-based products
The architecture of Web-based products Языки программирования. Язык Паскаль
Языки программирования. Язык Паскаль Google Forms
Google Forms Оператор присваивания. Операторы ввода-вывода. Структура программы на Паскале
Оператор присваивания. Операторы ввода-вывода. Структура программы на Паскале ЕГЭ по информатике: 2018 и далее
ЕГЭ по информатике: 2018 и далее Електронні словники та програми-перекладачі. Інтерактивні та мультимедійні курси іноземних мов
Електронні словники та програми-перекладачі. Інтерактивні та мультимедійні курси іноземних мов Стилі CSS. (Лекція 5)
Стилі CSS. (Лекція 5) Язык описания данных ORACLE. Типы данных ORACLE. Таблицы. Представления
Язык описания данных ORACLE. Типы данных ORACLE. Таблицы. Представления Виды мошенничества в интернете
Виды мошенничества в интернете С помощью чего и как искать информацию?
С помощью чего и как искать информацию? Исследование возможностей применения BIM-технологии в компьютерном дизайне (на примере интерьера загородного дома)
Исследование возможностей применения BIM-технологии в компьютерном дизайне (на примере интерьера загородного дома) Единицы измерения информации
Единицы измерения информации Построение графиков в табличном процессоре. 9 класс
Построение графиков в табличном процессоре. 9 класс Двоичная система счисления
Двоичная система счисления Методические рекомендации для студентов по самостоятельному изучению английского языка в сети Интернет
Методические рекомендации для студентов по самостоятельному изучению английского языка в сети Интернет Виртуальный музей
Виртуальный музей Информационно-технологический модуль. Overflow. Display. Псевдоэлементы 2019
Информационно-технологический модуль. Overflow. Display. Псевдоэлементы 2019 Принципы автоматизированного управления тепловыми пунктами
Принципы автоматизированного управления тепловыми пунктами Информационные ресурсы Интернета.
Информационные ресурсы Интернета. Компьютерное информационное моделирование
Компьютерное информационное моделирование Excel 2007
Excel 2007 Флэш-презентации
Флэш-презентации Програми та бази даних для збереження інформації параметрів технологічного процесу
Програми та бази даних для збереження інформації параметрів технологічного процесу Что такое система? Информационные процессы в естественных и искусственных системах
Что такое система? Информационные процессы в естественных и искусственных системах