- Технологии распределённой обработки данных компании Google

Содержание
- 2. Начало истории Google 1996 г. ‑ Ларри Пейдж (Larry Page) и Сергей Брин в Стэнфордский университет.
- 3. Начало истории Google. 1997 г.
- 4. Начало истории Google. 1999 г.
- 5. Начало истории Google. 2000 г.
- 6. Начало истории Google. 2001 г.
- 7. Главная цель компании Google Организация обработки информации при постоянном увеличении её объемов. Возможность обеспечить информацией всех
- 8. Составляющие системы распределённой обработки данных Google Map Reduce – технология распределённой обработки данных и модель параллельного
- 9. Модель программирования MapReduce разработана на основе современных представлений о проектировании программных интерфейсов; учитывает необходимость поддержки разработанных
- 10. Обработка данных в модели программирования MapReduce Программист определяет две функции: map () - формирование множества промежуточных
- 11. Модель программирования MapReduce Ограничения по использованию модели программирования
- 12. Пример решения задачи в модели программирования MapReduce Исходные данные задачи: Я два раза не повторяю! Не
- 13. Пример решения задачи в модели программирования MapReduce Функция map(): list > map ( char inputChar )
- 14. Пример решения задачи в модели программирования MapReduce Функция reduce(): pair reduce ( char key, list subproduct
- 15. Технология распределённой обработки данных MapReduce Аппаратная платформа - большое число недорогих серверов из массовых комплектующих: двухпроцессорные
- 16. Архитектура MapReduce кластера Выбор управляющего процесса, отслеживание состояния процессов и их синхронизация осуществляется с помощью службы
- 17. Процесс обработки данных по технологии MapReduce Разбиение входных данных на части (16-64 Мбайт). Запуск копий службы
- 18. Обеспечение отказоустойчивости в технологии MapReduce Отслеживание состояния рабочих процессов управляющим процессом и выявление фактов отказа вычислительных
- 20. Скачать презентацию

Начало истории Google
1996 г. ‑ Ларри Пейдж (Larry Page) и Сергей
Начало истории Google
1996 г. ‑ Ларри Пейдж (Larry Page) и Сергей

Начало истории Google. 1997 г.
Начало истории Google. 1997 г.

Начало истории Google. 1999 г.
Начало истории Google. 1999 г.

Начало истории Google. 2000 г.
Начало истории Google. 2000 г.

Начало истории Google. 2001 г.
Начало истории Google. 2001 г.

Главная цель компании Google
Организация обработки информации при постоянном увеличении её объемов.
Главная цель компании Google
Организация обработки информации при постоянном увеличении её объемов.

Составляющие системы распределённой обработки данных Google
Map Reduce – технология распределённой обработки
Составляющие системы распределённой обработки данных Google
Map Reduce – технология распределённой обработки

Модель программирования MapReduce
разработана на основе современных представлений о проектировании программных интерфейсов;
учитывает
Модель программирования MapReduce
разработана на основе современных представлений о проектировании программных интерфейсов;
учитывает
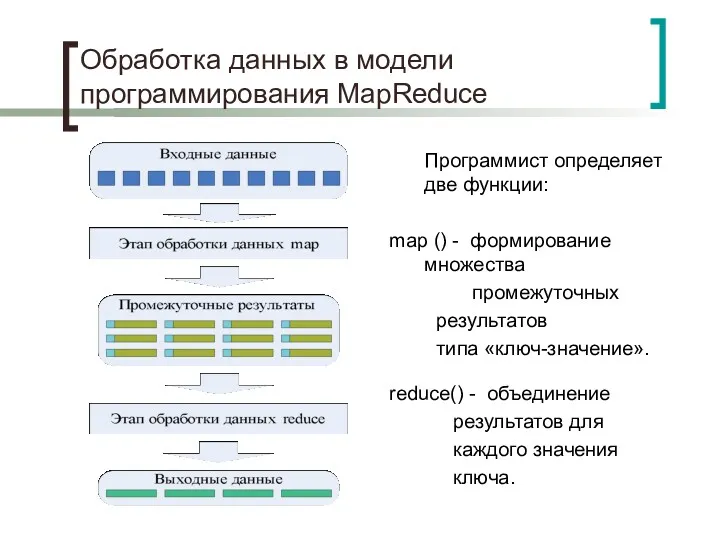
Обработка данных в модели программирования MapReduce
Программист определяет две функции:
map ()
Обработка данных в модели программирования MapReduce
Программист определяет две функции:
map ()

Модель программирования MapReduce
Ограничения по использованию модели программирования
Модель программирования MapReduce
Ограничения по использованию модели программирования

Пример решения задачи в модели программирования MapReduce
Исходные данные задачи:
Я два раза
Пример решения задачи в модели программирования MapReduce
Исходные данные задачи:
Я два раза

Пример решения задачи в модели программирования MapReduce
Функция map():
list< pair< char, int
Пример решения задачи в модели программирования MapReduce
Функция map():
list< pair< char, int

Пример решения задачи в модели программирования MapReduce
Функция reduce():
pair< char, int >
Пример решения задачи в модели программирования MapReduce
Функция reduce():
pair< char, int >

Технология распределённой обработки данных MapReduce
Аппаратная платформа - большое число
недорогих серверов из
Технология распределённой обработки данных MapReduce
Аппаратная платформа - большое число
недорогих серверов из
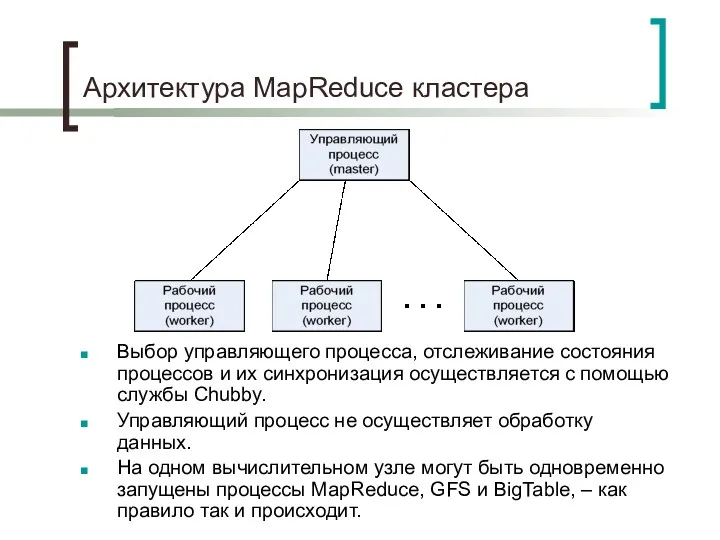
Архитектура MapReduce кластера
Выбор управляющего процесса, отслеживание состояния процессов и их синхронизация
Архитектура MapReduce кластера
Выбор управляющего процесса, отслеживание состояния процессов и их синхронизация
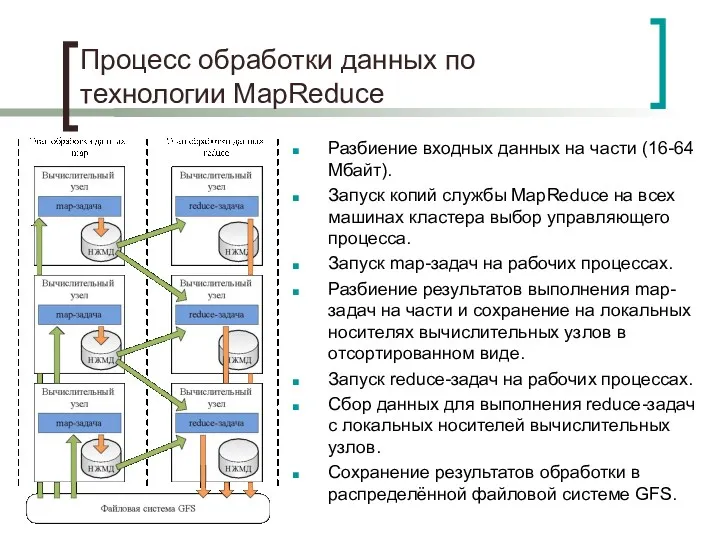
Процесс обработки данных по технологии MapReduce
Разбиение входных данных на части (16-64
Процесс обработки данных по технологии MapReduce
Разбиение входных данных на части (16-64

Обеспечение отказоустойчивости в технологии MapReduce
Отслеживание состояния рабочих процессов управляющим процессом и
Обеспечение отказоустойчивости в технологии MapReduce
Отслеживание состояния рабочих процессов управляющим процессом и
 Установка Camtasia Studio 8
Установка Camtasia Studio 8 Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN
Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN Вестник ХММР №4, июль 2018
Вестник ХММР №4, июль 2018 Структура компьютера. Понятие вычислительной системы
Структура компьютера. Понятие вычислительной системы Информационные технологии в юридической деятельности. 2 семестр. Компьютерные сети и технологии
Информационные технологии в юридической деятельности. 2 семестр. Компьютерные сети и технологии Компьютерные сети
Компьютерные сети This is your presentation title
This is your presentation title This is your presentation title
This is your presentation title Веб-сервис по анализу цен интернет-магазинов
Веб-сервис по анализу цен интернет-магазинов Создание видеороликов. Мастер-класс
Создание видеороликов. Мастер-класс IP-адреса, маски подсетей
IP-адреса, маски подсетей Информационные ресурсы. Этические и правовые нормы информационной деятельности людей.
Информационные ресурсы. Этические и правовые нормы информационной деятельности людей. ВКР: Разработка ANDROID приложения с использованием MVP архитектуры
ВКР: Разработка ANDROID приложения с использованием MVP архитектуры Тематический библиографический список, как одна из форм библиографических пособий малых форм
Тематический библиографический список, как одна из форм библиографических пособий малых форм Application State services
Application State services Оператор ветвления (условный оператор)
Оператор ветвления (условный оператор) Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3
Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3 Инструкция по заполнению регистрационной формы конференции
Инструкция по заполнению регистрационной формы конференции Программирование на языке Java. Тема 23. Рекурсия
Программирование на языке Java. Тема 23. Рекурсия Сравнительная характеристика OC Windows XP и OC Windows 8
Сравнительная характеристика OC Windows XP и OC Windows 8 Создание проекта супермаркета в 3D-редакторе SKETCHUP
Создание проекта супермаркета в 3D-редакторе SKETCHUP Среда Visual Basic. Основные понятия VB
Среда Visual Basic. Основные понятия VB Алгоритм. Кто такой исполнитель?
Алгоритм. Кто такой исполнитель? Етапи побудови інформаційної моделі (урок 7)
Етапи побудови інформаційної моделі (урок 7) HTML/CSS
HTML/CSS Закачка сайта на сервер по ftp-протоколу в среде Dreamweaver.
Закачка сайта на сервер по ftp-протоколу в среде Dreamweaver. Презентация к уроку Основные этапы разработки и исследования моделей на компьютере
Презентация к уроку Основные этапы разработки и исследования моделей на компьютере Анимация. Создать черепашку
Анимация. Создать черепашку