- Технологии сбора информации и больших объемов данных (лекция 3)

Содержание
- 2. Лекция 3. Технологии сбора информации и больших объемов данных
- 3. Часть 1. Структурированные и неструктурированные данные
- 4. Материалы Объектно-ориентированный подход к хранению данных Понятие структуры данных. Структурированные данные Пример структурированных данных Неструктурированные данные
- 5. Объектно-ориентированный подход к хранению данных В объектно-ориентированном подходе (ООП) все сущности формализуются набором полей и методов.
- 6. Понятие структуры данных Структура данных в обработке и хранении данных это перечень полей и их типов
- 7. Структурированные данные Структурированными называются данные, отражающие отдельные факты предметной области и упорядоченные определенным образом с целью
- 8. Пример структурированных данных
- 9. Временные ряды Измерения показателя во времени для одного обособленного объекта. Содержат зависимые от времени и последовательности
- 10. Данные транзакций Транзакционные данные — это любая информация, которая связана с транзакциями. Ключевое отличие транзакционных данных
- 11. Данные объектов Таблицы данных объектов используются для хранения и извлечения больших двоичных объектов, например изображений, текстовых
- 12. Полуструктурированные данные JSON-LD XML XLS CSV
- 13. Данные документов Таблица данных документов управляет набором значений-документов. Обычно данные в этих хранилищах содержатся в виде
- 14. Неструктурированные данные Неструктурированные данные — данные, которые не соответствуют заранее определённой модели данных, и, как правило,
- 15. Неструктурированные данные Структурированные данные Неструктурированные данные Организованная, типизированная информация, относящаяся к одной сущности Не имеет предопределенной
- 16. Пример неструктурированных данных Текстовая информация Фото и видео
- 17. Методы структуризации данных Структуризация данных рассматривается как отдельный механизм преобразования неструктурированных данных в удобный для обработки
- 18. Часть 2. Шкалы данных. Обработка шкал данных. Вид данных
- 19. Понятие шкал структурированных данных Шкала измерения в статистике — это способ представления переменных и их группировки
- 20. Шкалы измерений, классификация Основными свойствами шкал измерений являются: Идентифицируемость Величина Равенство интервалов Абсолютный ноль Уровни измерений
- 21. Номинальная шкала Номинальная шкала: описание групп статистик, подписи визуализации. Отражают те или иные свойства объекта, выраженные
- 22. Порядковая шкала Порядковая шкала: то же, что и номинальная шкала и расчет квантилей, исследование градации оценки
- 23. Интервальная шкала Интервальная шкала: сравнение с эталоном, линейное преобразование (сдвиг), сложение и вычитание. Является метрической шкалой.
- 24. Шкала отношений Шкала отношений: присутствует дополнительное свойство — естественное и однозначное присутствие нулевой точки Точкой начала
- 25. Дискретные данные По характеру варьирования переменные делятся на дискретные и нерперывные. Дискретные данные являются значениями признака,
- 26. Непрерывные данные Непрерывные данные – это данные, которые могут принимать любые значения в некотором интервале. Над
- 27. Часть 3. Хранение информации в виде структурированных данных. Реляционная модель данных
- 28. Материалы Структура данных как шаблон Поля данных, домены, записи Записи как экземпляры класса Уникальность записи в
- 29. Базы данных База данных (БД) – это совокупность данных, хранящихся и упорядоченных в соответствии с определенной
- 30. Модели данных
- 31. Системы управления базами данных Базу данных невозможно было бы изменить или заполнить не будь системы для
- 32. Функции СУБД Все манипуляции с базой данных и с данными происходят через СУБД Основными функциями СУБД
- 33. Реляционная база данных В реляционной БД вся информация хранится в таблицах, состоящих из столбцов и строк.
- 34. Пример таблицы данных Таблица, хранящая данные об автолюбителях, имеет следующие атрибуты (столбцы): имя: строковый тип, фамилия:
- 35. Ключи первичный и внешний Первичный ключ (PRIMARY key) – уникальный атрибут, идентифицирующий отдельную запись таблицы данных.
- 36. Связь один к одному Связи между таблицами бывают следующих видов: один к одному, один ко многим,
- 37. Связь один ко многим Связь один ко многим – связь при которой одна строка первой таблицы
- 38. Связь многие ко многим Связь многие ко многим. «Один объект первой таблицы зависит от нескольких объектов
- 39. Понятие схемы данных В использованных ранее рисунках с иллюстрациями связей таблиц мы использовали наглядный инструмент отображения
- 40. Пример схемы РБД
- 41. Доступ к данным в реляционных СУБД Доступ к данным в РСУБД классически осуществляется с помощью языка
- 42. Доступ к данным в реляционных СУБД Доступ к данным в РСУБД также может осуществляться посредством ODBC
- 43. Доступ к данным в реляционных СУБД Пример выборки таблицы данных на языке DML для приведенной таблицы
- 44. Доступ к данным в реляционных СУБД Оператор SELECT состоит из нескольких предложений (разделов): SELECT определяет список
- 45. Доступ к данным в реляционных СУБД Оператор SELECT имеет следующую структуру: SELECT [DISTINCT | DISTINCTROW |
- 46. Часть 4. Внесение данных в РБД. Транзакции в РБД
- 47. Добавление информации в базу данных Операторы, отвечающие за внесение изменений в наполнение реляционной базы данных находятся
- 48. Транзакции в базу данных Изменения в базе данных, переводящие её из одного согласованного состояния в другое
- 49. Функции транзакций Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от
- 50. Часть 5. Очистка данных
- 51. Материалы Грязные данные, пропуски в данных, невалидные данные Понятие чистых данных Пропуски в строковых данных Пропуски
- 52. Грязные данные Грязные данные - это неверные, недостаточные, не несущие никакой пользы. К таковым относится информация,
- 53. Понятие чистых данных Чистые данные представляют собой табличный набор наблюдений в котором каждой строке данных соответствует
- 54. Профайлинг данных Профайлинг данных – процесс изучения данных с целью достижения понимания их структуры, содержимого и
- 55. Результат профайлинга данных
- 56. Пропуски в данных
- 57. Стратегии борьбы с пропусками Число пропусков: Очень малое (до 0.5 - 1%) – можно удалить примеры
- 59. Скачать презентацию

Лекция 3. Технологии сбора информации и больших объемов данных
Лекция 3. Технологии сбора информации и больших объемов данных

Часть 1. Структурированные и неструктурированные данные
Часть 1. Структурированные и неструктурированные данные

Материалы
Объектно-ориентированный подход к хранению данных
Понятие структуры данных.
Структурированные данные
Пример структурированных данных
Неструктурированные данные
Пример
Материалы
Объектно-ориентированный подход к хранению данных
Понятие структуры данных.
Структурированные данные
Пример структурированных данных
Неструктурированные данные
Пример

Объектно-ориентированный подход к хранению данных
В объектно-ориентированном подходе (ООП) все сущности формализуются
Объектно-ориентированный подход к хранению данных
В объектно-ориентированном подходе (ООП) все сущности формализуются

Понятие структуры данных
Структура данных в обработке и хранении данных это перечень
Понятие структуры данных
Структура данных в обработке и хранении данных это перечень

Структурированные данные
Структурированными называются данные, отражающие отдельные факты предметной области и упорядоченные
Структурированные данные
Структурированными называются данные, отражающие отдельные факты предметной области и упорядоченные
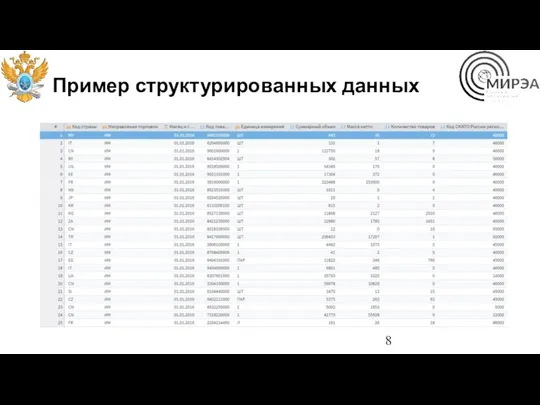
Пример структурированных данных
Пример структурированных данных
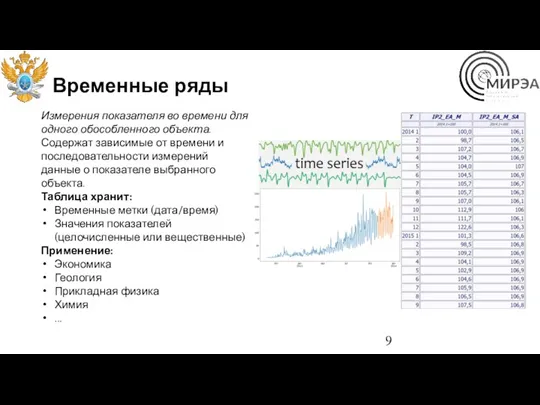
Временные ряды
Измерения показателя во времени для одного обособленного объекта.
Содержат зависимые от
Временные ряды
Измерения показателя во времени для одного обособленного объекта.
Содержат зависимые от

Данные транзакций
Транзакционные данные — это любая информация, которая связана с транзакциями.
Данные транзакций
Транзакционные данные — это любая информация, которая связана с транзакциями.

Данные объектов
Таблицы данных объектов используются для хранения и извлечения больших двоичных
Данные объектов
Таблицы данных объектов используются для хранения и извлечения больших двоичных

Полуструктурированные данные
JSON-LD
XML
XLS
CSV
Полуструктурированные данные
JSON-LD
XML
XLS
CSV

Данные документов
Таблица данных документов управляет набором значений-документов.
Обычно данные в этих
Данные документов
Таблица данных документов управляет набором значений-документов.
Обычно данные в этих

Неструктурированные данные
Неструктурированные данные — данные, которые не соответствуют заранее определённой модели
Неструктурированные данные
Неструктурированные данные — данные, которые не соответствуют заранее определённой модели
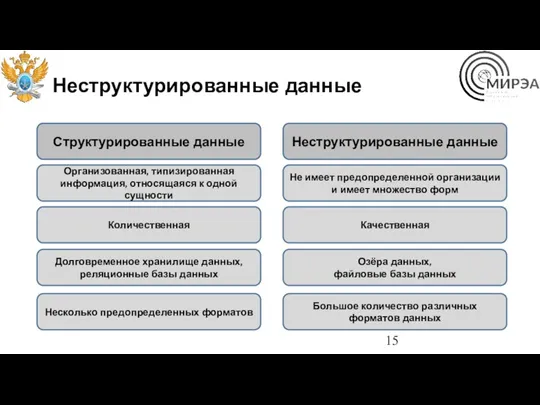
Неструктурированные данные
Структурированные данные
Неструктурированные данные
Организованная, типизированная информация, относящаяся к одной сущности
Не имеет
Неструктурированные данные
Структурированные данные
Неструктурированные данные
Организованная, типизированная информация, относящаяся к одной сущности
Не имеет

Пример неструктурированных данных
Текстовая информация
Фото и видео
Пример неструктурированных данных
Текстовая информация
Фото и видео

Методы структуризации данных
Структуризация данных рассматривается как отдельный механизм преобразования неструктурированных данных
Методы структуризации данных
Структуризация данных рассматривается как отдельный механизм преобразования неструктурированных данных

Часть 2. Шкалы данных. Обработка шкал данных. Вид данных
Часть 2. Шкалы данных. Обработка шкал данных. Вид данных
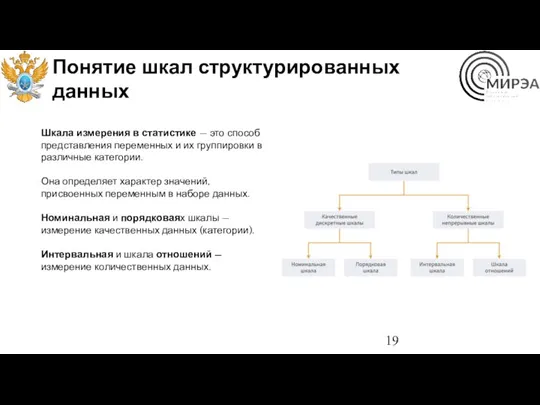
Понятие шкал структурированных данных
Шкала измерения в статистике — это способ представления
Понятие шкал структурированных данных
Шкала измерения в статистике — это способ представления

Шкалы измерений, классификация
Основными свойствами шкал измерений являются:
Идентифицируемость
Величина
Равенство интервалов
Абсолютный ноль
Уровни измерений данных
Номинальная
Шкалы измерений, классификация
Основными свойствами шкал измерений являются:
Идентифицируемость
Величина
Равенство интервалов
Абсолютный ноль
Уровни измерений данных
Номинальная

Номинальная шкала
Номинальная шкала: описание групп статистик, подписи визуализации.
Отражают те или иные
Номинальная шкала
Номинальная шкала: описание групп статистик, подписи визуализации.
Отражают те или иные

Порядковая шкала
Порядковая шкала: то же, что и номинальная шкала и расчет
Порядковая шкала
Порядковая шкала: то же, что и номинальная шкала и расчет

Интервальная шкала
Интервальная шкала: сравнение с эталоном, линейное преобразование (сдвиг), сложение и
Интервальная шкала
Интервальная шкала: сравнение с эталоном, линейное преобразование (сдвиг), сложение и

Шкала отношений
Шкала отношений: присутствует дополнительное свойство — естественное и однозначное присутствие
Шкала отношений
Шкала отношений: присутствует дополнительное свойство — естественное и однозначное присутствие

Дискретные данные
По характеру варьирования переменные делятся на дискретные и нерперывные.
Дискретные данные
Дискретные данные
По характеру варьирования переменные делятся на дискретные и нерперывные.
Дискретные данные

Непрерывные данные
Непрерывные данные – это данные, которые могут принимать любые значения
Непрерывные данные
Непрерывные данные – это данные, которые могут принимать любые значения

Часть 3. Хранение информации в виде структурированных данных. Реляционная модель данных
Часть 3. Хранение информации в виде структурированных данных. Реляционная модель данных

Материалы
Структура данных как шаблон
Поля данных, домены, записи
Записи как экземпляры класса
Уникальность записи
Материалы
Структура данных как шаблон
Поля данных, домены, записи
Записи как экземпляры класса
Уникальность записи

Базы данных
База данных (БД) – это совокупность данных, хранящихся и упорядоченных
Базы данных
База данных (БД) – это совокупность данных, хранящихся и упорядоченных
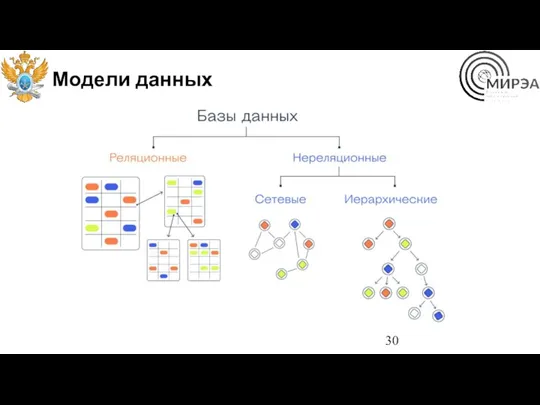
Модели данных
Модели данных

Системы управления базами данных
Базу данных невозможно было бы изменить или заполнить
Системы управления базами данных
Базу данных невозможно было бы изменить или заполнить

Функции СУБД
Все манипуляции с базой данных и с данными происходят через
Функции СУБД
Все манипуляции с базой данных и с данными происходят через

Реляционная база данных
В реляционной БД вся информация хранится в таблицах, состоящих
Реляционная база данных
В реляционной БД вся информация хранится в таблицах, состоящих
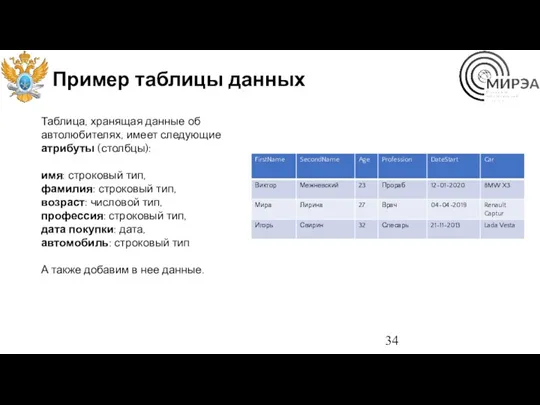
Пример таблицы данных
Таблица, хранящая данные об автолюбителях, имеет следующие атрибуты (столбцы):
имя:
Пример таблицы данных
Таблица, хранящая данные об автолюбителях, имеет следующие атрибуты (столбцы):
имя:
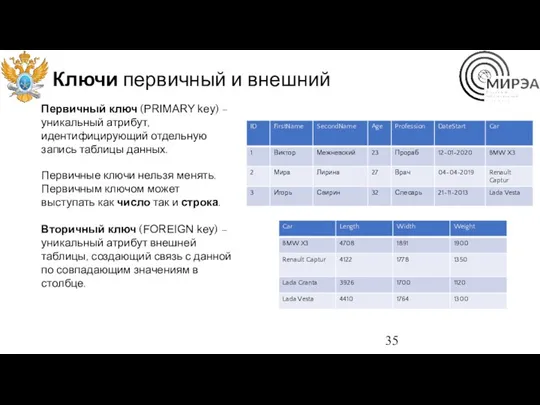
Ключи первичный и внешний
Первичный ключ (PRIMARY key) – уникальный атрибут, идентифицирующий
Ключи первичный и внешний
Первичный ключ (PRIMARY key) – уникальный атрибут, идентифицирующий

Связь один к одному
Связи между таблицами бывают следующих видов:
один к одному,
один
Связь один к одному
Связи между таблицами бывают следующих видов:
один к одному,
один

Связь один ко многим
Связь один ко многим – связь при которой
Связь один ко многим
Связь один ко многим – связь при которой

Связь многие ко многим
Связь многие ко многим. «Один объект первой таблицы
Связь многие ко многим
Связь многие ко многим. «Один объект первой таблицы

Понятие схемы данных
В использованных ранее рисунках с иллюстрациями связей таблиц мы
Понятие схемы данных
В использованных ранее рисунках с иллюстрациями связей таблиц мы
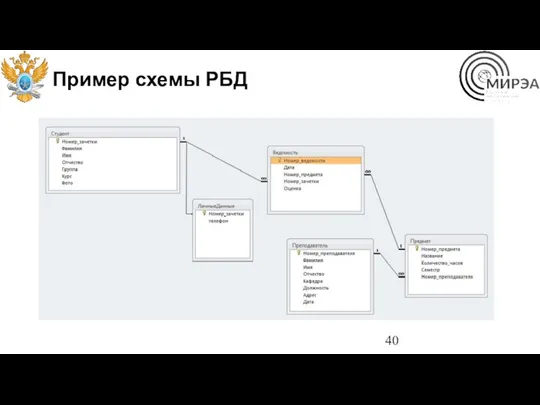
Пример схемы РБД
Пример схемы РБД

Доступ к данным в реляционных СУБД
Доступ к данным в РСУБД классически
Доступ к данным в реляционных СУБД
Доступ к данным в РСУБД классически

Доступ к данным в реляционных СУБД
Доступ к данным в РСУБД также
Доступ к данным в реляционных СУБД
Доступ к данным в РСУБД также

Доступ к данным в реляционных СУБД
Пример выборки таблицы данных на языке
Доступ к данным в реляционных СУБД
Пример выборки таблицы данных на языке

Доступ к данным в реляционных СУБД
Оператор SELECT состоит из нескольких предложений
Доступ к данным в реляционных СУБД
Оператор SELECT состоит из нескольких предложений

Доступ к данным в реляционных СУБД
Оператор SELECT имеет следующую структуру:
SELECT
[DISTINCT
Доступ к данным в реляционных СУБД
Оператор SELECT имеет следующую структуру:
SELECT
[DISTINCT

Часть 4. Внесение данных в РБД. Транзакции в РБД
Часть 4. Внесение данных в РБД. Транзакции в РБД

Добавление информации в базу данных
Операторы, отвечающие за внесение изменений в наполнение
Добавление информации в базу данных
Операторы, отвечающие за внесение изменений в наполнение

Транзакции в базу данных
Изменения в базе данных, переводящие её из одного
Транзакции в базу данных
Изменения в базе данных, переводящие её из одного

Функции транзакций
Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность
Функции транзакций
Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность

Часть 5. Очистка данных
Часть 5. Очистка данных

Материалы
Грязные данные, пропуски в данных, невалидные данные
Понятие чистых данных
Пропуски в строковых
Материалы
Грязные данные, пропуски в данных, невалидные данные
Понятие чистых данных
Пропуски в строковых

Грязные данные
Грязные данные - это неверные, недостаточные, не несущие никакой пользы.
Грязные данные
Грязные данные - это неверные, недостаточные, не несущие никакой пользы.

Понятие чистых данных
Чистые данные представляют собой табличный набор наблюдений в котором
Понятие чистых данных
Чистые данные представляют собой табличный набор наблюдений в котором

Профайлинг данных
Профайлинг данных – процесс изучения данных с целью достижения понимания
Профайлинг данных
Профайлинг данных – процесс изучения данных с целью достижения понимания

Результат профайлинга данных
Результат профайлинга данных

Пропуски в данных
Пропуски в данных

Стратегии борьбы с пропусками
Число пропусков:
Очень малое (до 0.5 - 1%) –
Стратегии борьбы с пропусками
Число пропусков:
Очень малое (до 0.5 - 1%) –
 Компоненти і структура IT
Компоненти і структура IT Тема3-4-Графический Редактор GIMP-3Установка-4Инструменты
Тема3-4-Графический Редактор GIMP-3Установка-4Инструменты Документационное обеспечение управления
Документационное обеспечение управления Different types of operating system
Different types of operating system Программирование на языке Python. Символьные строки
Программирование на языке Python. Символьные строки Базы данных. SQL
Базы данных. SQL What is a computer?
What is a computer? Смайлы и няшные картинки на стену в вк!
Смайлы и няшные картинки на стену в вк! Школьное печатное издание газета ОБЪЕКТИВ
Школьное печатное издание газета ОБЪЕКТИВ Лекция 2. Основные компоненты ГИС
Лекция 2. Основные компоненты ГИС Sky Bridge. Разработка игрового приложения в жанре Визуальная новелла
Sky Bridge. Разработка игрового приложения в жанре Визуальная новелла Безопасный Интернет
Безопасный Интернет Создание и разметка жесткого диска в UNIX-системах
Создание и разметка жесткого диска в UNIX-системах Web-программист. Навыки и умения для разработки сайтов и сервисов
Web-программист. Навыки и умения для разработки сайтов и сервисов Презентация Microsoft Office PowerPoint
Презентация Microsoft Office PowerPoint Вводная лекция СЭД Directum
Вводная лекция СЭД Directum Программирование на языках высокого уровня
Программирование на языках высокого уровня Скандалы в игровой индустрии
Скандалы в игровой индустрии Искусственный интеллект (ИИ)
Искусственный интеллект (ИИ) Системы объектов
Системы объектов СМИ в политике. (Обществознание, 11 класс)
СМИ в политике. (Обществознание, 11 класс) Архитектура фон Неймана
Архитектура фон Неймана Компьютерные преступления и защита от них
Компьютерные преступления и защита от них Обработка данных средствами электронных таблиц Microsoft Excel
Обработка данных средствами электронных таблиц Microsoft Excel День написания письма в будущее
День написания письма в будущее Особенности управления возвратными потоками в электронной коммерции
Особенности управления возвратными потоками в электронной коммерции Презентация История компьютерной мыши
Презентация История компьютерной мыши UX Scenario Document File Version 4.1 SWEET.TV
UX Scenario Document File Version 4.1 SWEET.TV