- Базы данных. SQL

Содержание
- 2. Базы данных База данных (БД) - упорядоченный набор логически взаимосвязанных данных, используемых совместно, и которые хранятся
- 3. Базы данных Как правило, в современных информационных системах используют удалённые базы данных, расположенные на серверах (специально
- 4. Файл-серверные СУБД Файл-серверные СУБД (например, Microsoft Access) работают на компьютерах пользователей (они называются рабочими станциями). Это
- 5. Файл-серверные СУБД
- 6. Клиент-серверные СУБД Чтобы избавиться от этих недостатков, нужно переместить СУБД на сервер. Клиент-серверная СУБД расположена на
- 7. Клиент-серверные СУБД
- 8. Клиент-серверные СУБД Самые известные среди коммерческих клиент-серверных СУБД - Microsoft SQL Server и Oracle. Существуют и
- 9. Клиент-серверные СУБД В современных клиент-серверных СУБД для управления данными чаще всего используют язык SQL (Structured Query
- 10. Реляционные базы данных Реляционная база данных – это набор данных с предопределенными связями между ними. Эти
- 11. Реляционные базы данных
- 12. Реляционные базы данных Таблицы в реляционных базах данных обладают рядом свойств. Основными являются следующие: В таблице
- 13. Реляционные базы данных Предположим, мы захотели создать базу данных для форума. У форума есть зарегистрированные пользователи,
- 14. Реляционные базы данных Наша таблица Пользователи удовлетворяет всем условиям. А вот таблицы Темы и Сообщения -
- 15. Реляционные базы данных Первичный ключ (сокращенно РК - primary key) - столбец, значения которого во всех
- 16. Реляционные базы данных Давайте внесем поля первичных ключей в наши таблицы:
- 17. Реляционные базы данных Теперь каждая запись в наших таблицах уникальна. Нам осталось установить соответствие между темами
- 18. Реляционные базы данных Последний нюанс. Предположим, у нас добавился новый пользователь, и зовут его тоже Вася:
- 19. Реляционные базы данных Наша база данных готова. Схематично ее можно представить так:
- 20. ER диаграмма ENTITY RELATIONAL (ER) MODEL — это концептуальная модель модели данных высокого уровня. ER моделирование
- 21. SQL SQL — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе
- 22. SQL типы данных Символьные типы CHAR: представляет стоку фиксированной длины. Длина хранимой строки указывается в скобках,
- 23. SQL операторы Операции сравнения = сравнение на равенство != сравнение на равенство сравнение на неравенство >
- 24. SQL Создание таблицы: CREATE TABLE ( , , PRIMARY KEY( ), FOREIGN KEY( ) REFERENCES (
- 25. SQL Вставка записи в таблицу: Команда INSERT INTO в SQL отвечает за добавление данных в таблицу:
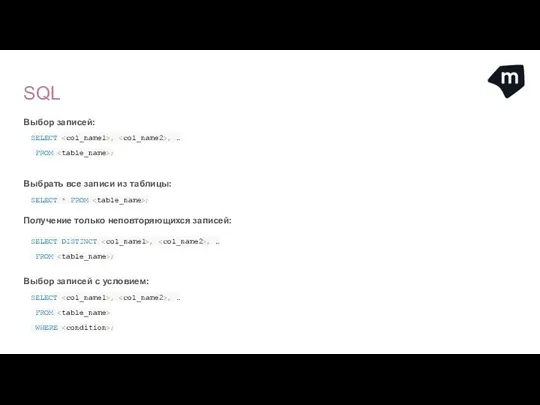
- 26. SQL Выбор записей: SELECT , , … FROM ; Выбрать все записи из таблицы: SELECT *
- 27. SQL Группировка: Оператор GROUP BY часто используется с агрегатными функциями, такими как COUNT, MAX, MIN, SUM
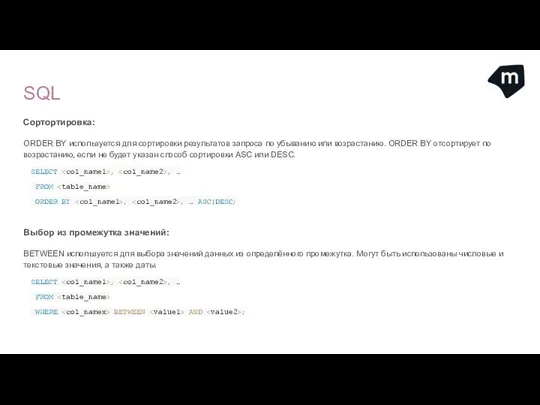
- 28. SQL Сортортировка: ORDER BY используется для сортировки результатов запроса по убыванию или возрастанию. ORDER BY отсортирует
- 29. SQL Шаблон поиска: Оператор LIKE используется в WHERE, чтобы задать шаблон поиска похожего значения. Есть два
- 30. SQL Выбор из промежутка значений: BETWEEN используется для выбора значений данных из определённого промежутка. Могут быть
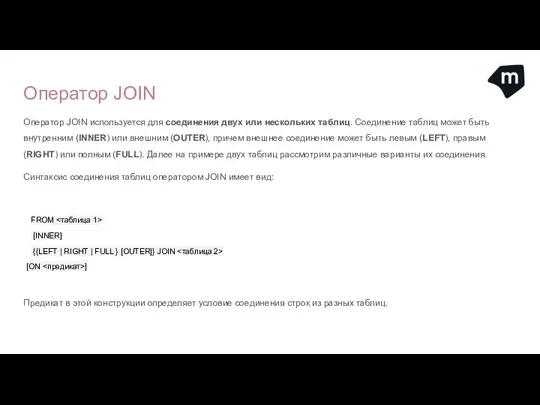
- 31. Оператор JOIN Оператор JOIN используется для соединения двух или нескольких таблиц. Соединение таблиц может быть внутренним
- 32. Оператор JOIN Допустим есть две таблицы (Auto слева и Selling справа), в каждой по четыре записи.
- 33. Оператор INNER JOIN Внутреннее соединение (INNER JOIN) означает, что в результирующий набор попадут только те соединения
- 34. Оператор FULL JOIN Внешнее соединение (OUTER JOIN) бывает нескольких видов. Первым рассмотрим полное внешнее объединение (FULL
- 35. Оператор LEFT JOIN Левое внешнее объединение (LEFT OUTER JOIN). В этом случае получаем все записи удовлетворяющие
- 37. Скачать презентацию

Базы данных
База данных (БД) - упорядоченный набор логически взаимосвязанных данных, используемых
Базы данных
База данных (БД) - упорядоченный набор логически взаимосвязанных данных, используемых

Базы данных
Как правило, в современных информационных системах используют удалённые базы данных,
Базы данных
Как правило, в современных информационных системах используют удалённые базы данных,

Файл-серверные СУБД
Файл-серверные СУБД (например, Microsoft Access) работают на компьютерах пользователей (они
Файл-серверные СУБД
Файл-серверные СУБД (например, Microsoft Access) работают на компьютерах пользователей (они
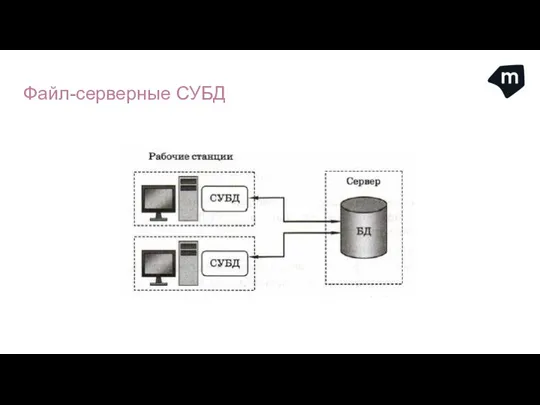
Файл-серверные СУБД
Файл-серверные СУБД

Клиент-серверные СУБД
Чтобы избавиться от этих недостатков, нужно переместить СУБД на сервер.
Клиент-серверные СУБД
Чтобы избавиться от этих недостатков, нужно переместить СУБД на сервер.
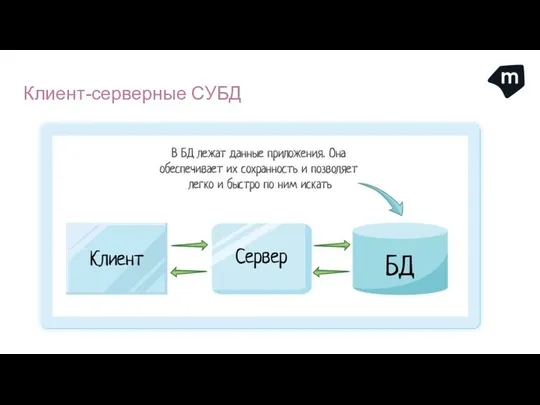
Клиент-серверные СУБД
Клиент-серверные СУБД

Клиент-серверные СУБД
Самые известные среди коммерческих клиент-серверных СУБД - Microsoft SQL Server
Клиент-серверные СУБД
Самые известные среди коммерческих клиент-серверных СУБД - Microsoft SQL Server

Клиент-серверные СУБД
В современных клиент-серверных СУБД для управления данными чаще всего используют
Клиент-серверные СУБД
В современных клиент-серверных СУБД для управления данными чаще всего используют

Реляционные базы данных
Реляционная база данных – это набор данных с предопределенными
Реляционные базы данных
Реляционная база данных – это набор данных с предопределенными
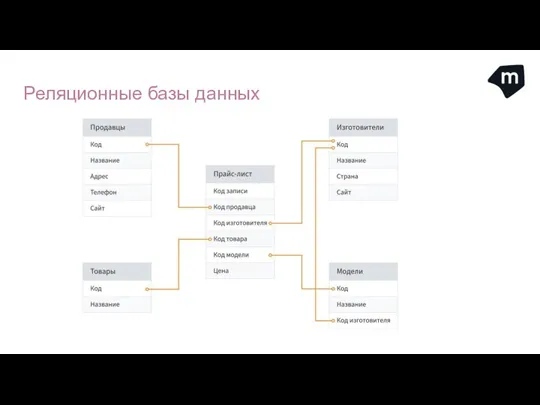
Реляционные базы данных
Реляционные базы данных

Реляционные базы данных
Таблицы в реляционных базах данных обладают рядом свойств. Основными
Реляционные базы данных
Таблицы в реляционных базах данных обладают рядом свойств. Основными

Реляционные базы данных
Предположим, мы захотели создать базу данных для форума. У
Реляционные базы данных
Предположим, мы захотели создать базу данных для форума. У

Реляционные базы данных
Наша таблица Пользователи удовлетворяет всем условиям. А вот таблицы
Реляционные базы данных
Наша таблица Пользователи удовлетворяет всем условиям. А вот таблицы

Реляционные базы данных
Первичный ключ (сокращенно РК - primary key) - столбец,
Реляционные базы данных
Первичный ключ (сокращенно РК - primary key) - столбец,

Реляционные базы данных
Давайте внесем поля первичных ключей в наши таблицы:
Реляционные базы данных
Давайте внесем поля первичных ключей в наши таблицы:

Реляционные базы данных
Теперь каждая запись в наших таблицах уникальна. Нам осталось
Реляционные базы данных
Теперь каждая запись в наших таблицах уникальна. Нам осталось

Реляционные базы данных
Последний нюанс. Предположим, у нас добавился новый пользователь, и
Реляционные базы данных
Последний нюанс. Предположим, у нас добавился новый пользователь, и

Реляционные базы данных
Наша база данных готова. Схематично ее можно представить так:
Реляционные базы данных
Наша база данных готова. Схематично ее можно представить так:
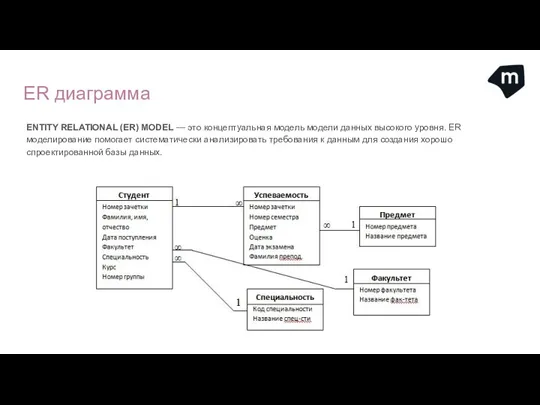
ER диаграмма
ENTITY RELATIONAL (ER) MODEL — это концептуальная модель модели данных
ER диаграмма
ENTITY RELATIONAL (ER) MODEL — это концептуальная модель модели данных

SQL
SQL — декларативный язык программирования, применяемый для создания, модификации и управления
SQL
SQL — декларативный язык программирования, применяемый для создания, модификации и управления

SQL типы данных
Символьные типы
CHAR: представляет стоку фиксированной длины. Длина хранимой строки
SQL типы данных
Символьные типы
CHAR: представляет стоку фиксированной длины. Длина хранимой строки

SQL операторы
Операции сравнения
= сравнение на равенство
!= сравнение на равенство
<> сравнение на
SQL операторы
Операции сравнения
= сравнение на равенство
!= сравнение на равенство
<> сравнение на

SQL
Создание таблицы:
CREATE TABLE (
,
,
PRIMARY KEY(),
FOREIGN
SQL
Создание таблицы:
CREATE TABLE
PRIMARY KEY(
FOREIGN

SQL
Вставка записи в таблицу:
Команда INSERT INTO в SQL отвечает за
SQL
Вставка записи в таблицу:
Команда INSERT INTO
SQL
Выбор записей:
SELECT , , …
FROM ;
Выбрать все записи из таблицы:
SELECT
SQL
Выбор записей:
SELECT
FROM
Выбрать все записи из таблицы:
SELECT

SQL
Группировка:
Оператор GROUP BY часто используется с агрегатными функциями, такими как COUNT,
SQL
Группировка:
Оператор GROUP BY часто используется с агрегатными функциями, такими как COUNT,
SQL
Сортортировка:
ORDER BY используется для сортировки результатов запроса по убыванию или возрастанию.
SQL
Сортортировка:
ORDER BY используется для сортировки результатов запроса по убыванию или возрастанию.

SQL
Шаблон поиска:
Оператор LIKE используется в WHERE, чтобы задать шаблон поиска похожего
SQL
Шаблон поиска:
Оператор LIKE используется в WHERE, чтобы задать шаблон поиска похожего

SQL
Выбор из промежутка значений:
BETWEEN используется для выбора значений данных из определённого
SQL
Выбор из промежутка значений:
BETWEEN используется для выбора значений данных из определённого
Оператор JOIN
Оператор JOIN используется для соединения двух или нескольких таблиц. Соединение
Оператор JOIN
Оператор JOIN используется для соединения двух или нескольких таблиц. Соединение

Оператор JOIN
Допустим есть две таблицы (Auto слева и Selling справа), в
Оператор JOIN
Допустим есть две таблицы (Auto слева и Selling справа), в

Оператор INNER JOIN
Внутреннее соединение (INNER JOIN) означает, что в результирующий набор
Оператор INNER JOIN
Внутреннее соединение (INNER JOIN) означает, что в результирующий набор

Оператор FULL JOIN
Внешнее соединение (OUTER JOIN) бывает нескольких видов. Первым рассмотрим
Оператор FULL JOIN
Внешнее соединение (OUTER JOIN) бывает нескольких видов. Первым рассмотрим

Оператор LEFT JOIN
Левое внешнее объединение (LEFT OUTER JOIN). В этом случае
Оператор LEFT JOIN
Левое внешнее объединение (LEFT OUTER JOIN). В этом случае
 Социальная сеть Big House centre. Партнерская программа
Социальная сеть Big House centre. Партнерская программа Построение классификаторов аналогичных каскаду Виолы-Джонса с использованием признаков Хаара и искусственных нейронных сетей
Построение классификаторов аналогичных каскаду Виолы-Джонса с использованием признаков Хаара и искусственных нейронных сетей Представление чисел в компьютере
Представление чисел в компьютере Проектирование баз данных и работа с ними веб-приложений. (Лекция 8)
Проектирование баз данных и работа с ними веб-приложений. (Лекция 8) Списки. Microsoft Office Word. Обработка текстовой информации
Списки. Microsoft Office Word. Обработка текстовой информации Персональный компьютер
Персональный компьютер Программирование на языке Python (10 класс)
Программирование на языке Python (10 класс) Билл Гейтс
Билл Гейтс Клиентская часть
Клиентская часть Пользовательский интерфейс. 7 класс
Пользовательский интерфейс. 7 класс Змінювання значень властивостей об’єкта в програмі
Змінювання значень властивостей об’єкта в програмі Metody fizyczne przeciwdriałania zagrożeniom informacji i systemow teleinformatycznych organizacji
Metody fizyczne przeciwdriałania zagrożeniom informacji i systemow teleinformatycznych organizacji Проектирование Базы данных
Проектирование Базы данных Web index report. Аудитория интернет-проектов. Результаты исследования: Март 2016
Web index report. Аудитория интернет-проектов. Результаты исследования: Март 2016 Таблицы. Графические изображения. Обработка текстовой информации
Таблицы. Графические изображения. Обработка текстовой информации Графи. Частина 2
Графи. Частина 2 Презентация по теме Определение количества информации. Содержательный подход
Презентация по теме Определение количества информации. Содержательный подход презентация, сопровождающая объяснение нового материала
презентация, сопровождающая объяснение нового материала Архитектура компьютера 11 класс
Архитектура компьютера 11 класс Технологии поиска информации в интернете
Технологии поиска информации в интернете Профессия программист
Профессия программист Экспериментальная исследовательская студенческая пресс-служба ФНС
Экспериментальная исследовательская студенческая пресс-служба ФНС Исторя систем счисления
Исторя систем счисления Operating systems. Introduction to computer and internet
Operating systems. Introduction to computer and internet Internet
Internet Библиография: термины и определения
Библиография: термины и определения Электронные заказные письма в личном кабинете. Почта России
Электронные заказные письма в личном кабинете. Почта России Вечер информатики в Шипунихинской школе
Вечер информатики в Шипунихинской школе