- Технология программирования гетерогенных систем OpenCL. Лекция 1

Содержание
- 2. Балльно-рейтинговая система
- 3. Технологии программирования Разные ускорители Разные языки и библиотеки NVidia — CUDA AMD — Brook+ CELL BE
- 4. Цели OpenCL Стандарт программирования Многоядерные процессоры Ускорители, GPU Мобильные медиапроцессоры Стандарт функциональности Производителям процессоров
- 5. Назначение OpenCL OpenCL (Open Computing Language) – открытый стандарт параллельного программирования для гетерогенных платформ, включающих центральные,
- 6. Рабочая группа OpenCL
- 7. Рабочая группа OpenCL
- 8. Что такое OpenCL Открытая спецификация Спецификация, разрабатываемая мировыми лидерами в области разработки и производства вычислительных устройств
- 9. План лекции Введение в параллельные вычисления Параллельные вычисления на GPU Программная модель вычисления на GPU Аппаратная
- 10. Параллелизм Параллелизм описывает возможность одновременного выполнения нескольких частей задачи Чтобы использовать параллелизм, мы должны иметь физические
- 11. Параллелизм Закон Амдаля : максимальное теоретическое ускорение, которое мы можем добиться с использованием параллелизма в задаче,
- 12. Параллелизм Для традиционных архитектур процессоров часто говорим о параллелизме на уровне инструкций (ILP) Высокопроизводительные процессоры часто
- 13. Декомпозиция Для нетривиальных задач декомпозиция помогает иметь более формальные понятия для определения параллелизма Когда мы думаем
- 14. Декомпозиция задачи Декомпозиция задачи сводит алгоритм к функционально независимым частям Задачи могут иметь зависимости от других
- 15. Граф зависимости задач Мы можем создать простой график зависимостей задачи для выпечки Любые задачи, которые не
- 16. Декомпозиция данных Декомпозиция данных - это способ разбить работу на несколько независимых задач, но каждая задача
- 17. Декомпозиция выходных данных Для большинства научных и инженерных приложений декомпозиция выполняется на основе выходных данных Примеры
- 18. Декомпозиция выходных данных (пример) Фильтр Box выполняет операции над каждым пикселем независимо результаты помещаются в независимых
- 19. Декомпозиция входных данных Разделение входных данных аналогично, за исключением алгоритмов, которые являются функцией «один ко многим»
- 20. Параллельные вычисления Декомпозиция основана исключительно на алгоритме Однако при реализации параллельного алгоритма необходимо учитывать как аппаратные,
- 21. Параллельные вычисления Существуют аппаратные и программные подходы к параллелизму Большая часть 90-х годов была потрачена на
- 22. Параллелизм на уровне вычислительных устройств Аппаратное обеспечение обычно предназначено для определенного типа параллелизма В настоящее время
- 23. Извлечение параллелизма: «разворачивание» цикла Loop strip mining (разворачивание цикла) - это метод преобразования цикла, который разбивает
- 24. Параллелизм на уровне программы – SPMD Программы GPU называются «ядрами» и записываются с использованием модели программирования
- 25. Параллелизм на уровне программы – SPMD Consider the following vector addition example Combining SPMD with loop
- 26. Параллелизм на уровне программы – SPMD В примере добавления векторов каждый фрагмент данных может быть выполнен
- 27. Параллелизм на уровне программы – SPMD 0 1 2 3 4 5 6 7 8 9
- 28. Параллелизм на уровне ВУ – SIMD Каждый обрабатывающий элемент ВУ выполняет одну и ту же инструкцию
- 29. Параллелизм на уровне ВУ – SIMD A SIMD hardware unit Control PE Data (Memory, Registers, Immediates,
- 30. Параллелизм на уровне ВУ – SIMD В примере сложения вектора SIMD-блок с шириной в четыре может
- 31. Проблемы реализации параллельных вычислений На процессорах аппаратные атомарные операции обеспечивают параллелизм Атомарные операции позволяют считывать и
- 32. Почему OpenCL Производительность зависит не от частоты процессора, а от уровня и типа параллелизма задачи Гетерогенное
- 33. OpenCL совместимые устройства Большинство CPU и GPU Следующие типы устройств могут быть совместимы: мультимедийные чипы; FPGA;
- 34. Назначение OpenCL Простая модель вычисления – чистый API Поддержка ANSI-C99 Дополнительные спецификаторы, встроенные типы данных и
- 35. Где OpenCL может использоваться Обработка видео, аудио – информации и изображений Научно-исследовательские вычисления Медицинские расчеты Финансовые
- 36. Средства параллельного программирования
- 37. Краткая история OpenCL Таблица - Основные этапы развития OpenCL
- 38. OpenCL и OpenGL OpenCL и OpenGL совместно работают хорошо Основное вычисление выполняется с помощью OpenCL и
- 39. Когда не следует применять OpenCL Последовательные задачи Вычисления с зависимостью по данным Вычисления, которые подразумевают значительное
- 40. Почему вычисления на GPU? Высокая производительность на операциях с плавающей точкой; Спроектирован для высоко масштабируемого параллелизма;
- 41. Ограничения CPU Системы на GPU ограничены На GPU «тяжело» реализуются аналитические алгоритмы GPU тяжело отлаживать GPU
- 42. OpenCL Demo
- 44. Скачать презентацию
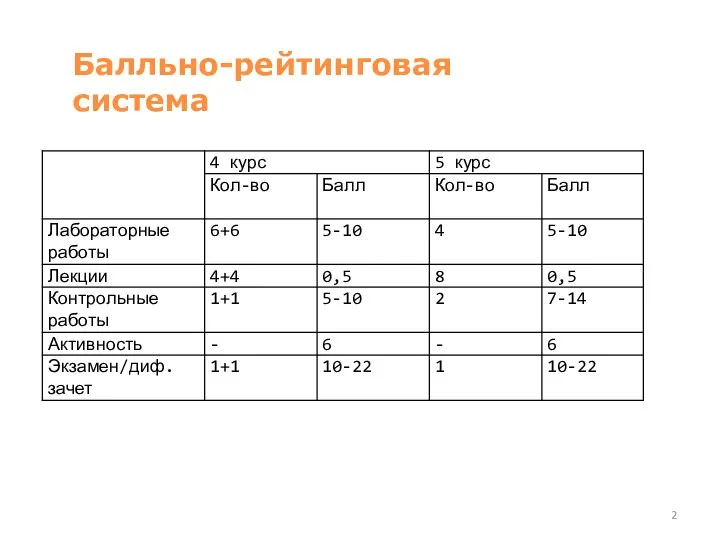
Балльно-рейтинговая система
Балльно-рейтинговая система

Технологии программирования
Разные ускорители
Разные языки и библиотеки
NVidia — CUDA
AMD
Технологии программирования
Разные ускорители
Разные языки и библиотеки
NVidia — CUDA
AMD

Цели OpenCL
Стандарт программирования
Многоядерные процессоры
Ускорители, GPU
Мобильные медиапроцессоры
Стандарт
Цели OpenCL
Стандарт программирования
Многоядерные процессоры
Ускорители, GPU
Мобильные медиапроцессоры
Стандарт

Назначение OpenCL
OpenCL (Open Computing Language) – открытый стандарт параллельного программирования для
Назначение OpenCL
OpenCL (Open Computing Language) – открытый стандарт параллельного программирования для

Рабочая группа OpenCL
Рабочая группа OpenCL

Рабочая группа OpenCL
Рабочая группа OpenCL

Что такое OpenCL
Открытая спецификация
Спецификация, разрабатываемая мировыми лидерами в области разработки и
Что такое OpenCL
Открытая спецификация
Спецификация, разрабатываемая мировыми лидерами в области разработки и

План лекции
Введение в параллельные вычисления
Параллельные вычисления на GPU
Программная
План лекции
Введение в параллельные вычисления
Параллельные вычисления на GPU
Программная

Параллелизм
Параллелизм описывает возможность одновременного выполнения нескольких частей задачи
Чтобы использовать параллелизм, мы
Параллелизм
Параллелизм описывает возможность одновременного выполнения нескольких частей задачи
Чтобы использовать параллелизм, мы

Параллелизм
Закон Амдаля : максимальное теоретическое ускорение, которое мы можем добиться с
Параллелизм
Закон Амдаля : максимальное теоретическое ускорение, которое мы можем добиться с

Параллелизм
Для традиционных архитектур процессоров часто говорим о параллелизме на уровне инструкций
Параллелизм
Для традиционных архитектур процессоров часто говорим о параллелизме на уровне инструкций

Декомпозиция
Для нетривиальных задач декомпозиция помогает иметь более формальные понятия для определения
Декомпозиция
Для нетривиальных задач декомпозиция помогает иметь более формальные понятия для определения
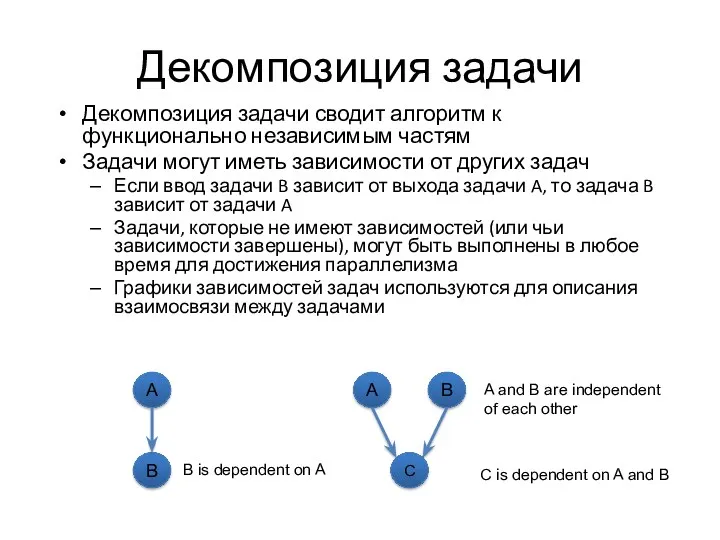
Декомпозиция задачи
Декомпозиция задачи сводит алгоритм к функционально независимым частям
Задачи могут иметь
Декомпозиция задачи
Декомпозиция задачи сводит алгоритм к функционально независимым частям
Задачи могут иметь
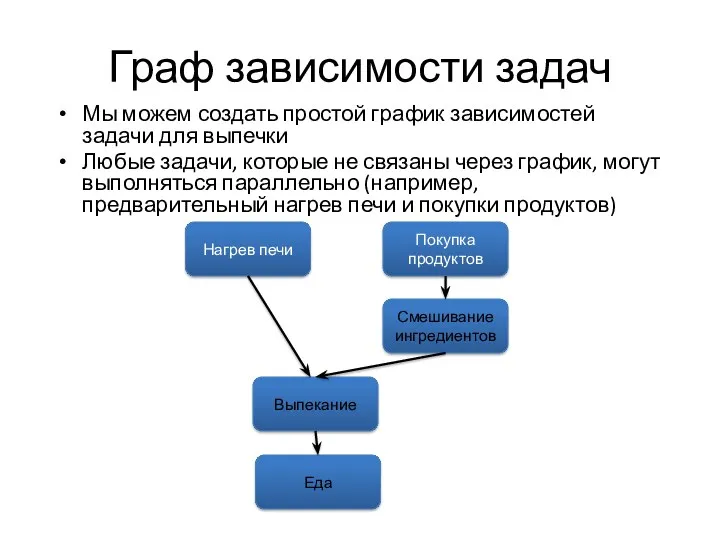
Граф зависимости задач
Мы можем создать простой график зависимостей задачи для выпечки
Любые
Граф зависимости задач
Мы можем создать простой график зависимостей задачи для выпечки
Любые

Декомпозиция данных
Декомпозиция данных - это способ разбить работу на несколько независимых
Декомпозиция данных
Декомпозиция данных - это способ разбить работу на несколько независимых

Декомпозиция выходных данных
Для большинства научных и инженерных приложений декомпозиция выполняется на
Декомпозиция выходных данных
Для большинства научных и инженерных приложений декомпозиция выполняется на

Декомпозиция выходных данных
(пример)
Фильтр Box
выполняет операции над каждым пикселем независимо
результаты помещаются в
Декомпозиция выходных данных
(пример)
Фильтр Box
выполняет операции над каждым пикселем независимо
результаты помещаются в

Декомпозиция входных данных
Разделение входных данных аналогично, за исключением алгоритмов, которые являются
Декомпозиция входных данных
Разделение входных данных аналогично, за исключением алгоритмов, которые являются

Параллельные вычисления
Декомпозиция основана исключительно на алгоритме
Однако при реализации параллельного алгоритма необходимо
Параллельные вычисления
Декомпозиция основана исключительно на алгоритме
Однако при реализации параллельного алгоритма необходимо

Параллельные вычисления
Существуют аппаратные и программные подходы к параллелизму
Большая часть 90-х годов
Параллельные вычисления
Существуют аппаратные и программные подходы к параллелизму
Большая часть 90-х годов

Параллелизм на уровне вычислительных устройств
Аппаратное обеспечение обычно предназначено для определенного типа
Параллелизм на уровне вычислительных устройств
Аппаратное обеспечение обычно предназначено для определенного типа

Извлечение параллелизма: «разворачивание» цикла
Loop strip mining (разворачивание цикла) - это метод
Извлечение параллелизма: «разворачивание» цикла
Loop strip mining (разворачивание цикла) - это метод

Параллелизм на уровне программы – SPMD
Программы GPU называются «ядрами» и записываются
Параллелизм на уровне программы – SPMD
Программы GPU называются «ядрами» и записываются
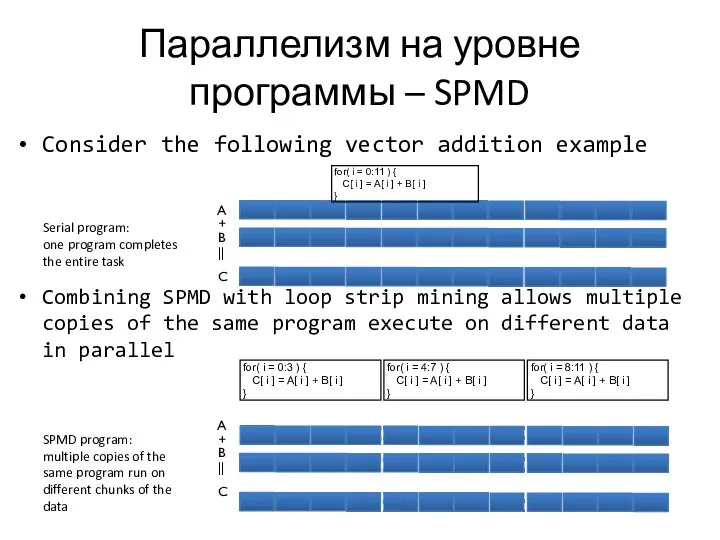
Параллелизм на уровне программы – SPMD
Consider the following vector addition example
Combining
Параллелизм на уровне программы – SPMD
Consider the following vector addition example
Combining

Параллелизм на уровне программы – SPMD
В примере добавления векторов каждый фрагмент
Параллелизм на уровне программы – SPMD
В примере добавления векторов каждый фрагмент
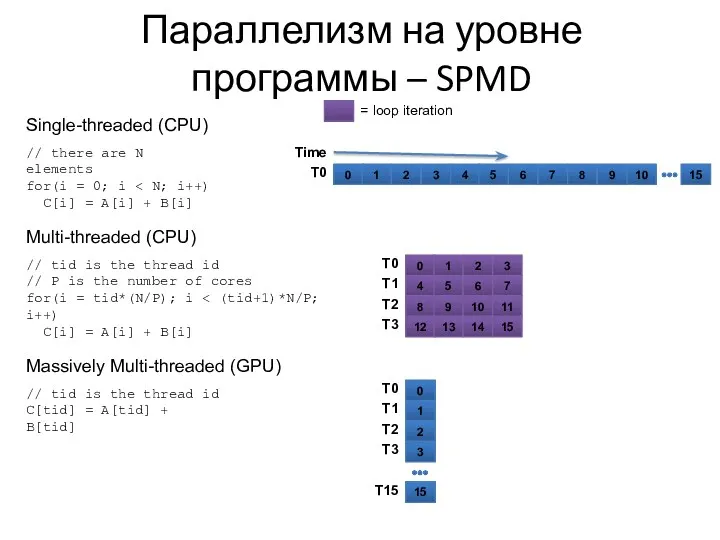
Параллелизм на уровне программы – SPMD
0
1
2
3
4
5
6
7
8
9
15
10
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
1
2
3
15
= loop iteration
Time
T0
T0
T1
T2
T3
T0
T1
T2
T3
T15
Параллелизм на уровне программы – SPMD
0
1
2
3
4
5
6
7
8
9
15
10
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
1
2
3
15
= loop iteration
Time
T0
T0
T1
T2
T3
T0
T1
T2
T3
T15

Параллелизм на уровне ВУ – SIMD
Каждый обрабатывающий элемент ВУ выполняет одну
Параллелизм на уровне ВУ – SIMD
Каждый обрабатывающий элемент ВУ выполняет одну
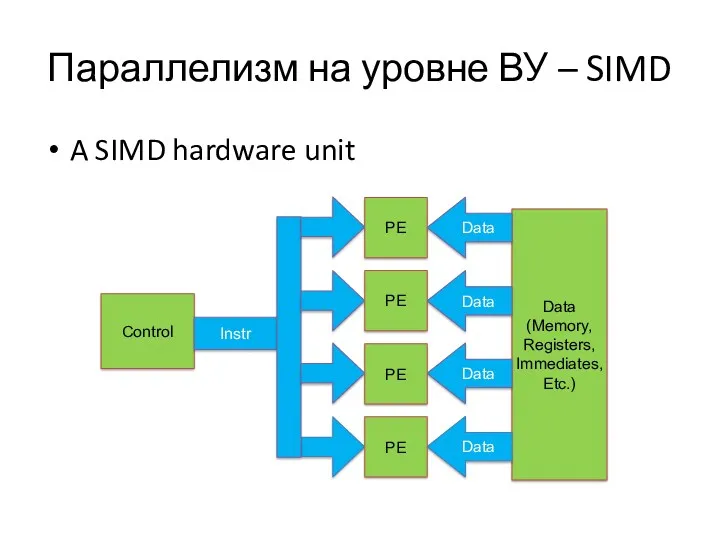
Параллелизм на уровне ВУ – SIMD
A SIMD hardware unit
Control
PE
Data
(Memory, Registers,
Immediates,
Etc.)
Instr
Data
Data
Data
Data
PE
PE
PE
Параллелизм на уровне ВУ – SIMD
A SIMD hardware unit
Control
PE
Data
(Memory, Registers,
Immediates,
Etc.)
Instr
Data
Data
Data
Data
PE
PE
PE

Параллелизм на уровне ВУ – SIMD
В примере сложения вектора SIMD-блок с
Параллелизм на уровне ВУ – SIMD
В примере сложения вектора SIMD-блок с

Проблемы реализации параллельных вычислений
На процессорах аппаратные атомарные операции обеспечивают параллелизм
Атомарные операции
Проблемы реализации параллельных вычислений
На процессорах аппаратные атомарные операции обеспечивают параллелизм
Атомарные операции

Почему OpenCL
Производительность зависит не от частоты процессора, а от уровня и
Почему OpenCL
Производительность зависит не от частоты процессора, а от уровня и

OpenCL совместимые устройства
Большинство CPU и GPU
Следующие типы устройств могут быть
OpenCL совместимые устройства
Большинство CPU и GPU
Следующие типы устройств могут быть

Назначение OpenCL
Простая модель вычисления – чистый API
Поддержка ANSI-C99
Дополнительные спецификаторы, встроенные
Назначение OpenCL
Простая модель вычисления – чистый API
Поддержка ANSI-C99
Дополнительные спецификаторы, встроенные

Где OpenCL может использоваться
Обработка видео, аудио – информации и изображений
Научно-исследовательские вычисления
Медицинские
Где OpenCL может использоваться
Обработка видео, аудио – информации и изображений
Научно-исследовательские вычисления
Медицинские
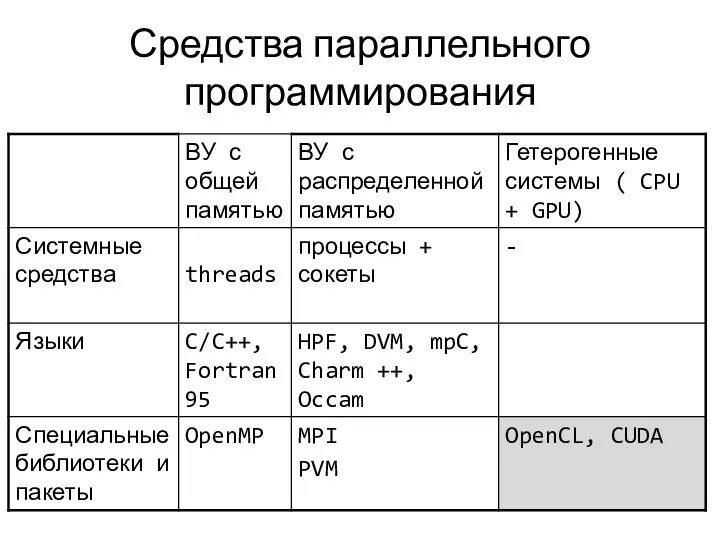
Средства параллельного программирования
Средства параллельного программирования

Краткая история OpenCL
Таблица - Основные этапы развития OpenCL
Краткая история OpenCL
Таблица - Основные этапы развития OpenCL

OpenCL и OpenGL
OpenCL и OpenGL совместно работают хорошо
Основное вычисление выполняется с
OpenCL и OpenGL
OpenCL и OpenGL совместно работают хорошо
Основное вычисление выполняется с

Когда не следует применять OpenCL
Последовательные задачи
Вычисления с зависимостью по данным
Вычисления, которые
Когда не следует применять OpenCL
Последовательные задачи
Вычисления с зависимостью по данным
Вычисления, которые

Почему вычисления на GPU?
Высокая производительность на операциях с плавающей точкой;
Спроектирован для
Почему вычисления на GPU?
Высокая производительность на операциях с плавающей точкой;
Спроектирован для

Ограничения CPU
Системы на GPU ограничены
На GPU «тяжело» реализуются аналитические алгоритмы
GPU тяжело
Ограничения CPU
Системы на GPU ограничены
На GPU «тяжело» реализуются аналитические алгоритмы
GPU тяжело

OpenCL Demo
OpenCL Demo
 Повторение. Подготовка к промежуточной аттестации по информатике
Повторение. Подготовка к промежуточной аттестации по информатике ПРЕЗЕНТАЦИЯ Решение логических задач табличным способом. Решение логических задач графическим способом
ПРЕЗЕНТАЦИЯ Решение логических задач табличным способом. Решение логических задач графическим способом Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа
Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа Создание и использование логотипов
Создание и использование логотипов Творческий проект Дизайн школьного кабинета
Творческий проект Дизайн школьного кабинета Системы счисления. Перевод чисел из одной системы счисления в другую систему счисления
Системы счисления. Перевод чисел из одной системы счисления в другую систему счисления Принципы подходов к моделированию систем
Принципы подходов к моделированию систем О религии в компьютерных играх
О религии в компьютерных играх СУБД. Назначение и функции
СУБД. Назначение и функции Решение задач с использованием ввода-вывода из файлов
Решение задач с использованием ввода-вывода из файлов Программно аппаратный комплекс ФПСУ IP
Программно аппаратный комплекс ФПСУ IP Методы представления графических изображений
Методы представления графических изображений Основы логики
Основы логики Система геометрического моделирования и программирования обработки для станков с ЧПУ. Опыт использования. НТЦ ГеММа
Система геометрического моделирования и программирования обработки для станков с ЧПУ. Опыт использования. НТЦ ГеММа Автоматизированная форма бухгалтерского учета
Автоматизированная форма бухгалтерского учета Презентация у уроку по информатике Архивация данных
Презентация у уроку по информатике Архивация данных Поведенческие паттерны
Поведенческие паттерны Трансформация рынка юридических услуг как результат диджитализации бизнеса
Трансформация рынка юридических услуг как результат диджитализации бизнеса Тема 4: Технологія створення та редагування таблиць в СУБД Ms Access
Тема 4: Технологія створення та редагування таблиць в СУБД Ms Access Упаковка прибыльного Instagramаккаунта
Упаковка прибыльного Instagramаккаунта 1 Объекты конфигурации
1 Объекты конфигурации Презентации для уроков информатики для 10 класса
Презентации для уроков информатики для 10 класса Создание открытки в текстовом редакторе. Работа с графикой.
Создание открытки в текстовом редакторе. Работа с графикой. Регулярные выражения
Регулярные выражения Компьютерные сети
Компьютерные сети Культура использования информации. Библиографическое оформление результатов поиска информации
Культура использования информации. Библиографическое оформление результатов поиска информации Игра по информатике Умники и умницы
Игра по информатике Умники и умницы Технология хранения, поиска, сортировки данных
Технология хранения, поиска, сортировки данных