- Введение в методы параллельного программирования

Содержание
- 2. из 77 Постановка задачи Способы распределения данных Последовательный алгоритм Алгоритм 1 – ленточная схема, разделение матрицы
- 3. из 77 Умножение матрицы на вектор или ⮲ Задача умножения матрицы на вектор может быть сведена
- 4. Москва, 2017 г. из 77 Непрерывное (последовательное) распределение Способы распределения данных: ленточная схема горизонтальные полосы вертикальные
- 5. Москва, 2017 г. из 77 Чередующееся (цикличное) горизонтальное разбиение Способы распределения данных: ленточная схема
- 6. Москва, 2017 г. из 77 Способы распределения данных: блочная схема
- 7. Москва, 2017 г. из 77 Для выполнения матрично-векторного умножения необходимо выполнить m операций вычисления скалярного произведения
- 8. Москва, 2017 г. из 77 Распределение данных – ленточная схема (разбиение матрицы по строкам) Алгоритм 1:
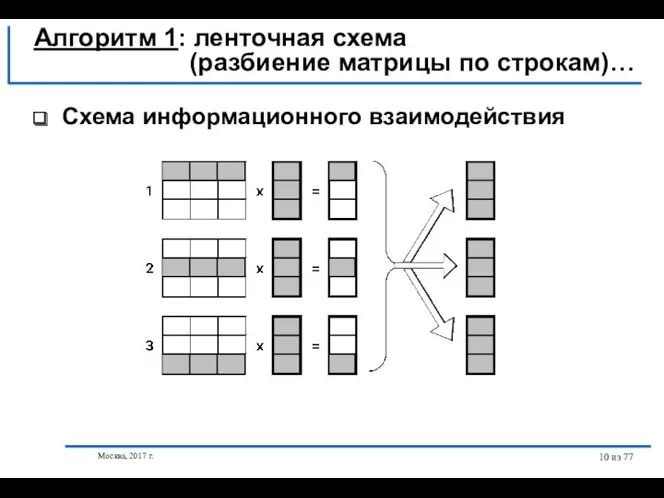
- 9. Москва, 2017 г. из 77 Выделение информационных зависимостей Алгоритм 1: ленточная схема (разбиение матрицы по строкам)…
- 10. Москва, 2017 г. из 77 Схема информационного взаимодействия Алгоритм 1: ленточная схема (разбиение матрицы по строкам)…
- 11. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам Если число процессоров p меньше
- 12. Москва, 2017 г. из 77 Анализ эффективности Общая оценка показателей ускорения и эффективности Алгоритм 1: ленточная
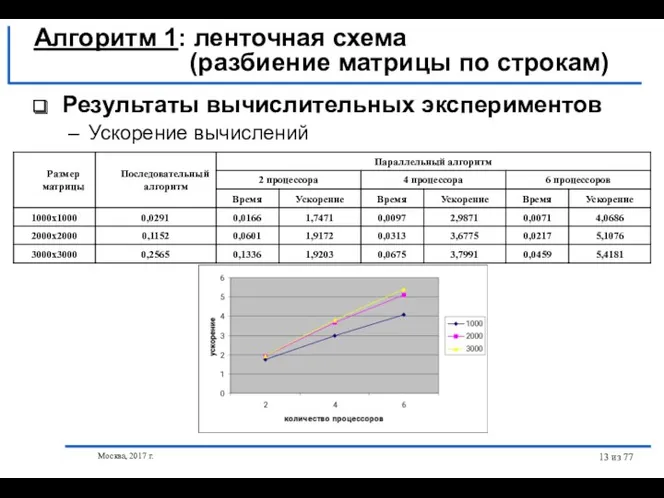
- 13. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Алгоритм 1: ленточная схема (разбиение матрицы
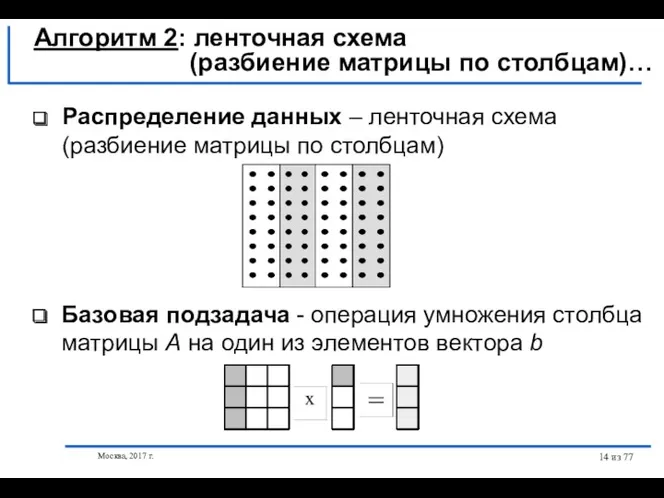
- 14. Москва, 2017 г. из 77 Распределение данных – ленточная схема (разбиение матрицы по столбцам) Базовая подзадача
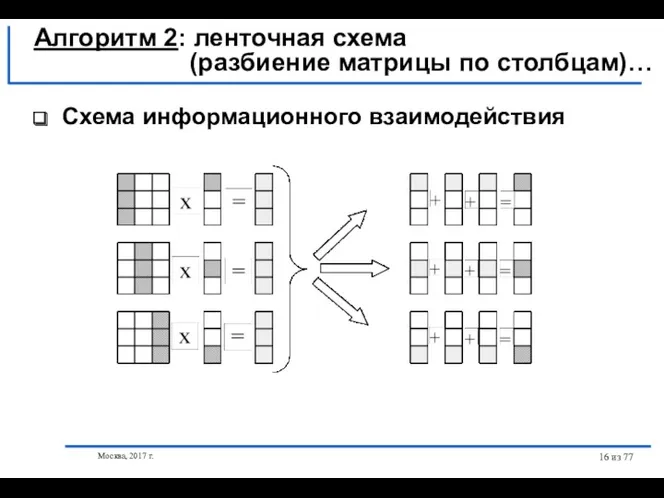
- 15. Москва, 2017 г. из 77 Алгоритм 2: ленточная схема (разбиение матрицы по столбцам)… Выделение информационных зависимостей
- 16. Москва, 2017 г. из 77 Схема информационного взаимодействия Алгоритм 2: ленточная схема (разбиение матрицы по столбцам)…
- 17. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам В случае, когда количество столбцов
- 18. Москва, 2017 г. из 77 Алгоритм 2: ленточная схема (разбиение матрицы по столбцам)… Анализ эффективности Общая
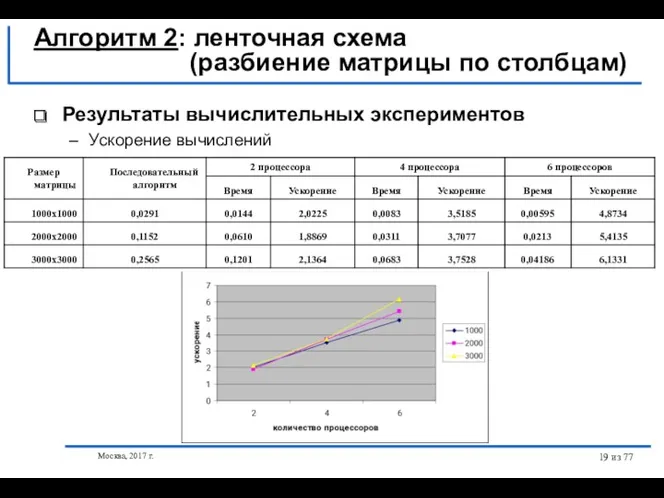
- 19. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Алгоритм 2: ленточная схема (разбиение матрицы
- 20. Москва, 2017 г. из 77 Распределение данных – блочная схема предполагается, что количество процессоров p=s·q ,
- 21. Москва, 2017 г. из 77 Базовая подзадача определяется на основе вычислений, выполняемых над матричными блоками: Подзадачи
- 22. Москва, 2017 г. из 77 Выделение информационных зависимостей Поэлементное суммирование векторов частичных результатов для каждой горизонтальной
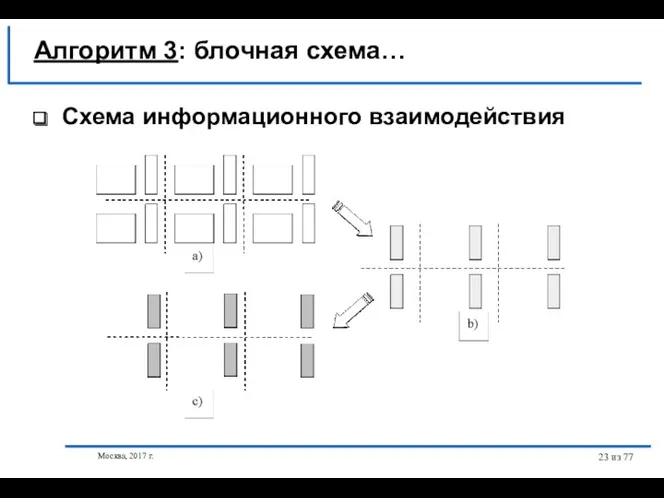
- 23. Москва, 2017 г. из 77 Схема информационного взаимодействия Алгоритм 3: блочная схема…
- 24. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам Размер блоков матрицы А может
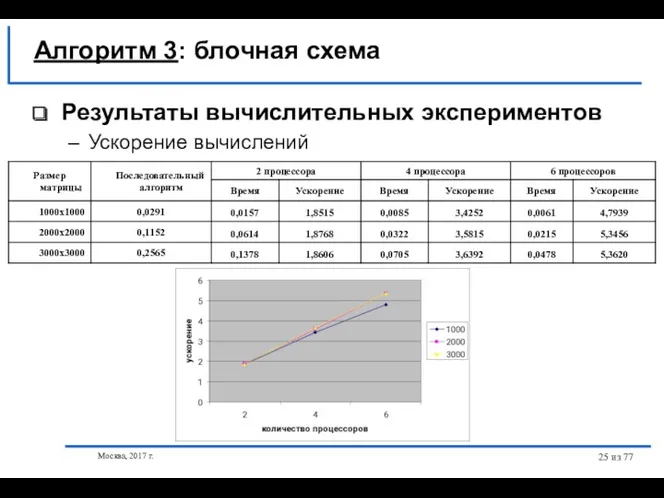
- 25. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Алгоритм 3: блочная схема
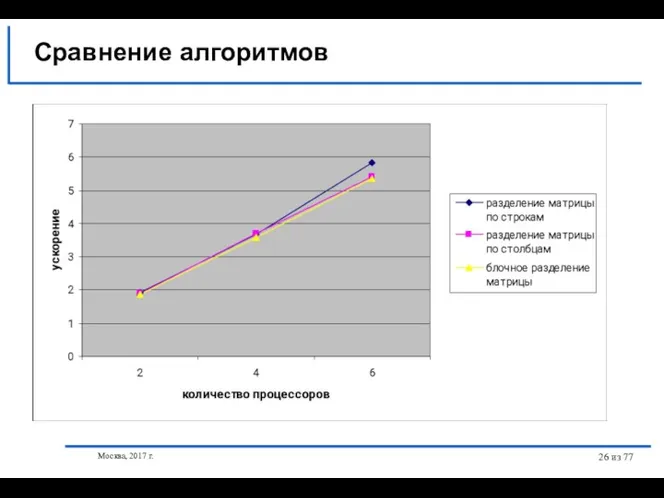
- 26. Москва, 2017 г. из 77 Сравнение алгоритмов
- 27. Москва, 2017 г. из 77 Постановка задачи Последовательный алгоритм Алгоритм 1 – ленточная схема Алгоритм 2
- 28. Москва, 2017 г. из 77 Постановка задачи Умножение матриц: или ⮲ Задача умножения матрицы на вектор
- 29. Москва, 2017 г. из 77 // Последовательный алгоритм матричного умножения double MatrixA[Size][Size]; double MatrixB[Size][Size]; double MatrixC[Size][Size];
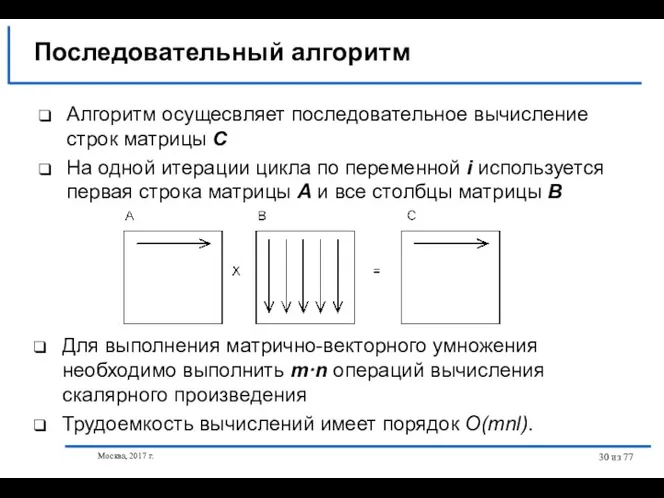
- 30. Москва, 2017 г. из 77 Последовательный алгоритм Для выполнения матрично-векторного умножения необходимо выполнить m·n операций вычисления
- 31. Москва, 2017 г. из 77 Достигнутый уровень параллелизма - количество базовых подзадач равно n2 – является
- 32. Москва, 2017 г. из 77 Распределение данных – ленточная схема (разбиение матрицы A по строкам и
- 33. Москва, 2017 г. из 77 Выделение информационных зависимостей Каждая подзадача содержит по одной строке матрицы А
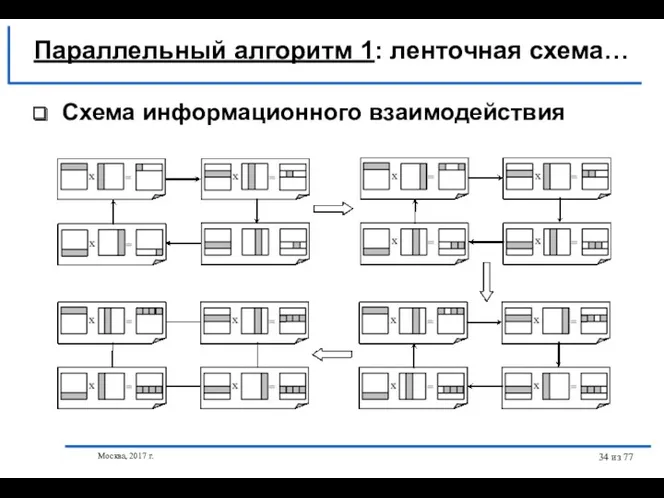
- 34. Москва, 2017 г. из 77 Схема информационного взаимодействия Параллельный алгоритм 1: ленточная схема…
- 35. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам Если число процессоров p меньше
- 36. Москва, 2017 г. из 77 Анализ эффективности Общая оценка показателей ускорения и эффективности Параллельный алгоритм 1:
- 37. Москва, 2017 г. из 77 Анализ эффективности (уточненные оценки) - Время выполнения параллельного алгоритма, связанное непосредственно
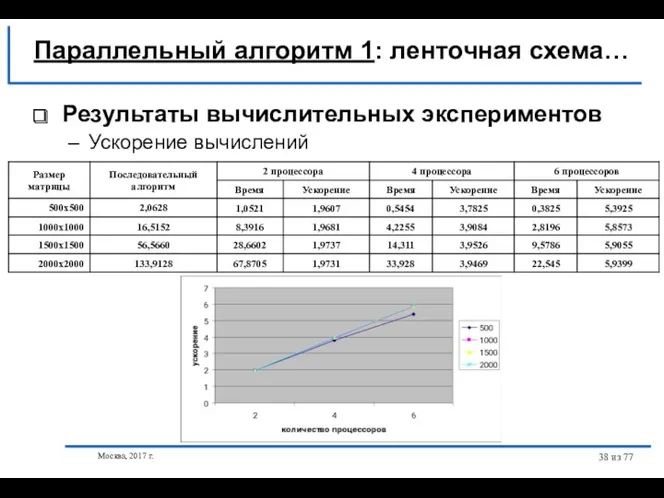
- 38. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Параллельный алгоритм 1: ленточная схема…
- 39. Москва, 2017 г. из 77 Другой возможный вариант распределения данных состоит в разбиении матриц A и
- 40. Москва, 2017 г. из 77 Параллельный алгоритм 1': ленточная схема… Выделение информационных зависимостей Каждая подзадача содержит
- 41. Москва, 2017 г. из 77 Параллельный алгоритм 1': ленточная схема Схема информационного взаимодействия
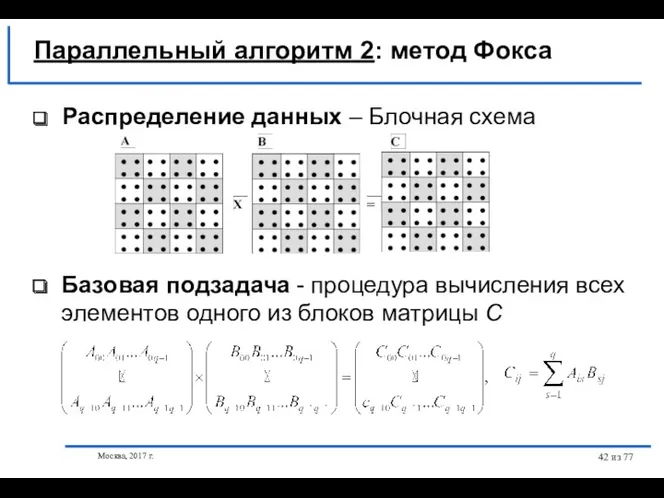
- 42. Москва, 2017 г. из 77 Распределение данных – Блочная схема Базовая подзадача - процедура вычисления всех
- 43. Москва, 2017 г. из 77 Выделение информационных зависимостей Подзадача (i,j) отвечает за вычисление блока Cij, как
- 44. Москва, 2017 г. из 77 Выделение информационных зависимостей - для каждой итерации l, 0≤ l блок
- 45. Москва, 2017 г. из 77 Схема информационного взаимодействия Параллельный алгоритм 2: метод Фокса…
- 46. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам Размеры блоков могут быть подобраны
- 47. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Параллельный алгоритм 2: метод Фокса
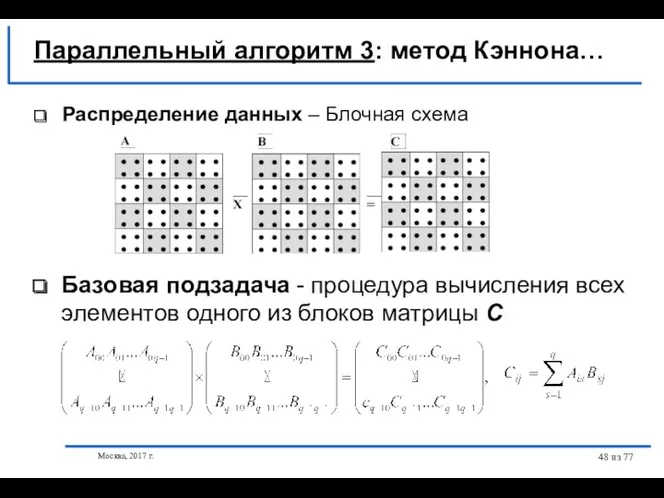
- 48. Москва, 2017 г. из 77 Параллельный алгоритм 3: метод Кэннона… Распределение данных – Блочная схема Базовая
- 49. Москва, 2017 г. из 77 Выделение информационных зависимостей Подзадача (i,j) отвечает за вычисление блока Cij, все
- 50. Москва, 2017 г. из 77 Перераспределение блоков исходных матриц на начальном этапе выполнения метода Параллельный алгоритм
- 51. Москва, 2017 г. из 77 Выделение информационных зависимостей В результате начального распределения в каждой базовой подзадаче
- 52. Москва, 2017 г. из 77 Масштабирование и распределение подзадач по процессорам Размер блоков может быть подобран
- 53. Москва, 2017 г. из 77 Анализ эффективности Общая оценка показателей ускорения и эффективности Разработанный способ параллельных
- 54. Москва, 2017 г. из 77 Результаты вычислительных экспериментов Ускорение вычислений Параллельный алгоритм 3: метод Кэннона
- 55. Москва, 2017 г. из 77 Показатели ускорения рассмотренных параллельных алгоритмов при умножении матриц по результатам вычислительных
- 56. Москва, 2017 г. из 77 Постановка задачи Принципы распараллеливания Пузырьковая сортировка Сортировка Шелла Параллельная быстрая сортировка
- 57. Москва, 2017 г. из 77 Постановка задачи Сортировка является одной из типовых проблем обработки данных и
- 58. Москва, 2017 г. из 77 Базовая операция – "сравнить и переставить" (compare-exchange) Принципы распараллеливания… // базовая
- 59. Москва, 2017 г. из 77 Принципы распараллеливания… Параллельное обобщение базовой операции при p = n (каждый
- 60. Москва, 2017 г. из 77 Принципы распараллеливания… Результат выполнения параллельного алгоритма: имеющиеся на процессорах данные упорядочены,
- 61. Москва, 2017 г. из 77 Параллельное обобщение базовой операции при p упорядочить блок на каждом процессоре
- 62. Москва, 2017 г. из 77 Трудоемкость вычислений имеет порядок O(n2) В прямом виде сложен для распараллеливания
- 63. Москва, 2017 г. из 77 Пузырьковая сортировка: алгоритм чет-нечетной перестановки… Вводятся два разных правила выполнения итераций
- 64. Москва, 2017 г. из 77 Пузырьковая сортировка: алгоритм чет-нечетной перестановки/// // Последовательный алгоритм чет-нечетной перестановки OddEvenSort(double
- 65. Москва, 2017 г. из 77 Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки… // Параллельный алгоритм чет-нечетной перестановки
- 66. Москва, 2017 г. из 77 Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
- 67. Москва, 2017 г. из 77 Результаты вычислительных экспериментов: Ускорение вычислений Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
- 68. Москва, 2017 г. из 77 ⮲ Параллельный вариант алгоритма работает медленнее исходного последовательного метода пузырьковой сортировки:
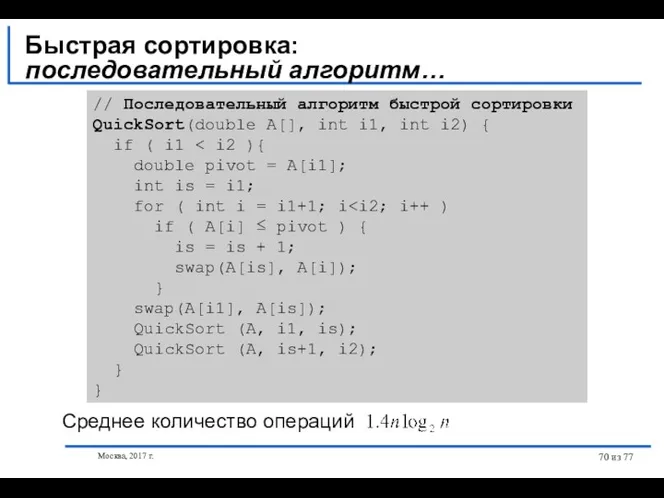
- 69. Москва, 2017 г. из 77 Быстрая сортировка: последовательный алгоритм… Алгоритм быстрой сортировки, предложенной Хоаром (Hoare C.A.R.),
- 70. Москва, 2017 г. из 77 Быстрая сортировка: последовательный алгоритм… // Последовательный алгоритм быстрой сортировки QuickSort(double A[],
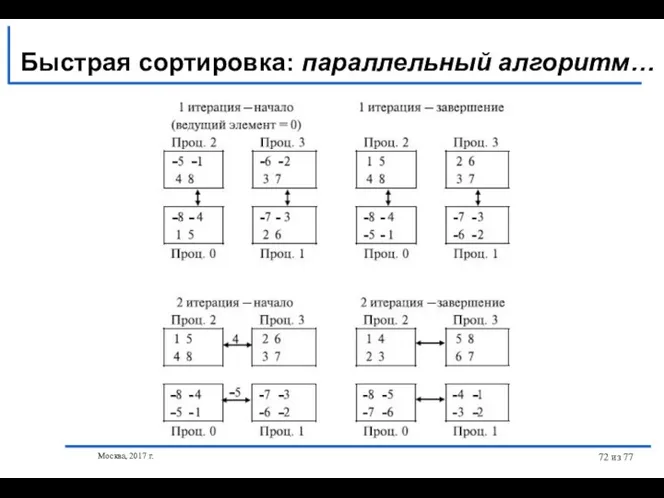
- 71. Москва, 2017 г. из 77 Быстрая сортировка: параллельный алгоритм… Пусть топология коммуникационной сети имеет вид N-мерного
- 72. Москва, 2017 г. из 77 Быстрая сортировка: параллельный алгоритм…
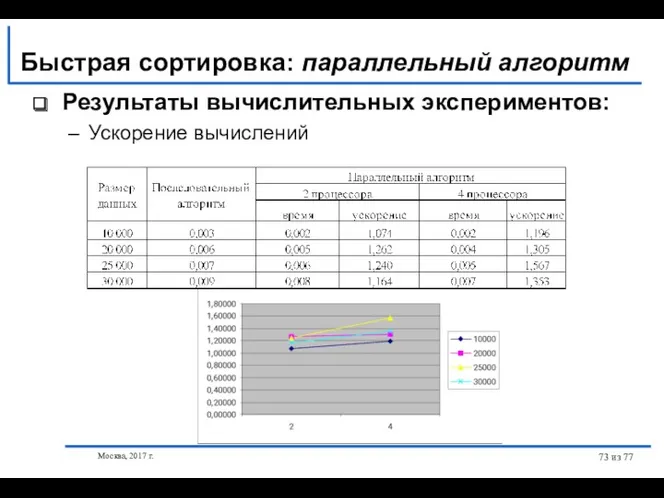
- 73. Москва, 2017 г. из 77 Результаты вычислительных экспериментов: Ускорение вычислений Быстрая сортировка: параллельный алгоритм
- 74. Москва, 2017 г. из 77 Обобщенная быстрая сортировка: параллельный алгоритм… Основное отличие от предыдущего алгоритма –
- 75. Москва, 2017 г. из 77 Первый этап: упорядочивание блоков каждым процессором независимо друг от друга при
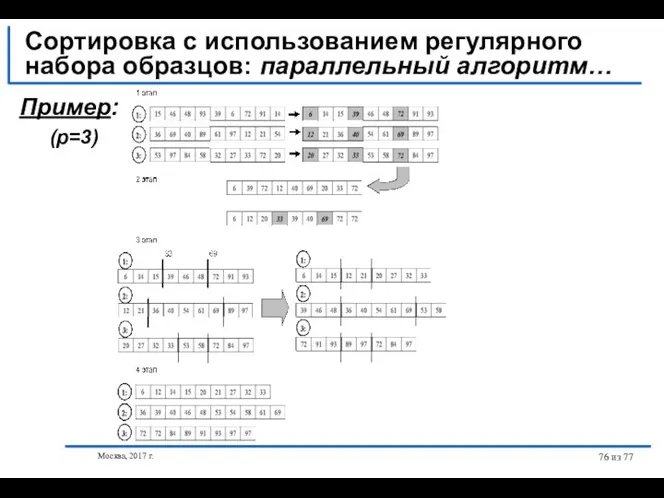
- 76. Москва, 2017 г. из 77 Сортировка с использованием регулярного набора образцов: параллельный алгоритм… Пример: (p=3)
- 78. Скачать презентацию

из 77
Постановка задачи
Способы распределения данных
Последовательный алгоритм
Алгоритм 1 – ленточная схема,
из 77
Постановка задачи
Способы распределения данных
Последовательный алгоритм
Алгоритм 1 – ленточная схема,

из 77
Умножение матрицы на вектор
или
⮲ Задача умножения матрицы на вектор
из 77
Умножение матрицы на вектор
или
⮲ Задача умножения матрицы на вектор

Москва, 2017 г.
из 77
Непрерывное (последовательное) распределение
Способы распределения данных: ленточная схема
горизонтальные
Москва, 2017 г.
из 77
Непрерывное (последовательное) распределение
Способы распределения данных: ленточная схема
горизонтальные

Москва, 2017 г.
из 77
Чередующееся (цикличное) горизонтальное разбиение
Способы распределения данных: ленточная
Москва, 2017 г.
из 77
Чередующееся (цикличное) горизонтальное разбиение
Способы распределения данных: ленточная

Москва, 2017 г.
из 77
Способы распределения данных: блочная схема
Москва, 2017 г.
из 77
Способы распределения данных: блочная схема

Москва, 2017 г.
из 77
Для выполнения матрично-векторного умножения необходимо выполнить m
Москва, 2017 г.
из 77
Для выполнения матрично-векторного умножения необходимо выполнить m

Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы
Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы

Москва, 2017 г.
из 77
Выделение информационных зависимостей
Алгоритм 1: ленточная схема (разбиение
Москва, 2017 г.
из 77
Выделение информационных зависимостей
Алгоритм 1: ленточная схема (разбиение
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 1: ленточная схема
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 1: ленточная схема

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Если число
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Если число

Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Алгоритм
Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Алгоритм
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 1: ленточная схема
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 1: ленточная схема
Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы
Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы

Москва, 2017 г.
из 77
Алгоритм 2: ленточная схема (разбиение матрицы по
Москва, 2017 г.
из 77
Алгоритм 2: ленточная схема (разбиение матрицы по
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 2: ленточная схема
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 2: ленточная схема

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
В случае,
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
В случае,

Москва, 2017 г.
из 77
Алгоритм 2: ленточная схема (разбиение матрицы по
Москва, 2017 г.
из 77
Алгоритм 2: ленточная схема (разбиение матрицы по
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 2: ленточная схема
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 2: ленточная схема

Москва, 2017 г.
из 77
Распределение данных – блочная схема
предполагается, что количество
Москва, 2017 г.
из 77
Распределение данных – блочная схема
предполагается, что количество

Москва, 2017 г.
из 77
Базовая подзадача определяется на основе вычислений, выполняемых
Москва, 2017 г.
из 77
Базовая подзадача определяется на основе вычислений, выполняемых

Москва, 2017 г.
из 77
Выделение информационных зависимостей
Поэлементное суммирование векторов частичных результатов
Москва, 2017 г.
из 77
Выделение информационных зависимостей
Поэлементное суммирование векторов частичных результатов
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 3: блочная схема…
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Алгоритм 3: блочная схема…

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размер блоков
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размер блоков
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 3: блочная схема
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Алгоритм 3: блочная схема
Москва, 2017 г.
из 77
Сравнение алгоритмов
Москва, 2017 г.
из 77
Сравнение алгоритмов

Москва, 2017 г.
из 77
Постановка задачи
Последовательный алгоритм
Алгоритм 1 – ленточная схема
Алгоритм
Москва, 2017 г.
из 77
Постановка задачи
Последовательный алгоритм
Алгоритм 1 – ленточная схема
Алгоритм

Москва, 2017 г.
из 77
Постановка задачи
Умножение матриц:
или
⮲ Задача умножения матрицы на
Москва, 2017 г.
из 77
Постановка задачи
Умножение матриц:
или
⮲ Задача умножения матрицы на
Москва, 2017 г.
из 77
// Последовательный алгоритм матричного умножения
double MatrixA[Size][Size];
Москва, 2017 г.
из 77
// Последовательный алгоритм матричного умножения
double MatrixA[Size][Size];
Москва, 2017 г.
из 77
Последовательный алгоритм
Для выполнения матрично-векторного умножения необходимо выполнить
Москва, 2017 г.
из 77
Последовательный алгоритм
Для выполнения матрично-векторного умножения необходимо выполнить

Москва, 2017 г.
из 77
Достигнутый уровень параллелизма - количество базовых подзадач
Москва, 2017 г.
из 77
Достигнутый уровень параллелизма - количество базовых подзадач

Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы
Москва, 2017 г.
из 77
Распределение данных – ленточная схема (разбиение матрицы

Москва, 2017 г.
из 77
Выделение информационных зависимостей
Каждая подзадача содержит по
Москва, 2017 г.
из 77
Выделение информационных зависимостей
Каждая подзадача содержит по
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Параллельный алгоритм 1: ленточная
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Параллельный алгоритм 1: ленточная

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Если число
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Если число

Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Параллельный
Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Параллельный

Москва, 2017 г.
из 77
Анализ эффективности (уточненные оценки)
- Время выполнения параллельного
Москва, 2017 г.
из 77
Анализ эффективности (уточненные оценки)
- Время выполнения параллельного
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 1: ленточная
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 1: ленточная

Москва, 2017 г.
из 77
Другой возможный вариант распределения данных состоит в
Москва, 2017 г.
из 77
Другой возможный вариант распределения данных состоит в

Москва, 2017 г.
из 77
Параллельный алгоритм 1': ленточная схема…
Выделение
Москва, 2017 г.
из 77
Параллельный алгоритм 1': ленточная схема…
Выделение
Москва, 2017 г.
из 77
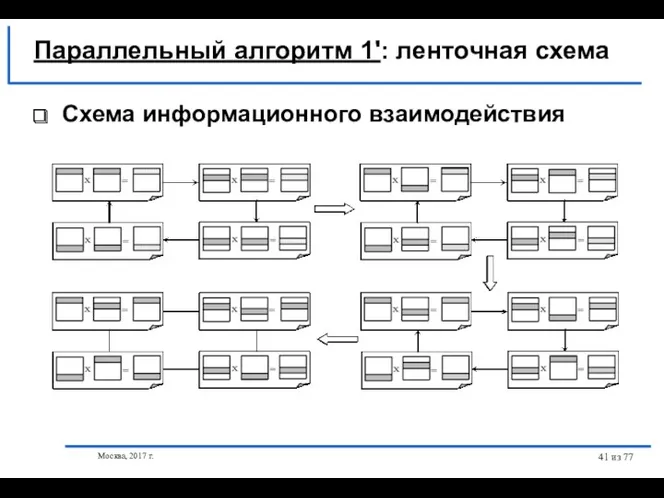
Параллельный алгоритм 1': ленточная схема
Схема информационного
Москва, 2017 г.
из 77
Параллельный алгоритм 1': ленточная схема
Схема информационного
Москва, 2017 г.
из 77
Распределение данных – Блочная схема
Базовая подзадача -
Москва, 2017 г.
из 77
Распределение данных – Блочная схема
Базовая подзадача -

Москва, 2017 г.
из 77
Выделение информационных зависимостей
Подзадача (i,j) отвечает за вычисление
Москва, 2017 г.
из 77
Выделение информационных зависимостей
Подзадача (i,j) отвечает за вычисление

Москва, 2017 г.
из 77
Выделение информационных зависимостей - для каждой итерации
Москва, 2017 г.
из 77
Выделение информационных зависимостей - для каждой итерации

Москва, 2017 г.
из 77
Схема информационного взаимодействия
Параллельный алгоритм 2: метод
Москва, 2017 г.
из 77
Схема информационного взаимодействия
Параллельный алгоритм 2: метод

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размеры блоков
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размеры блоков
Москва, 2017 г.
из 77
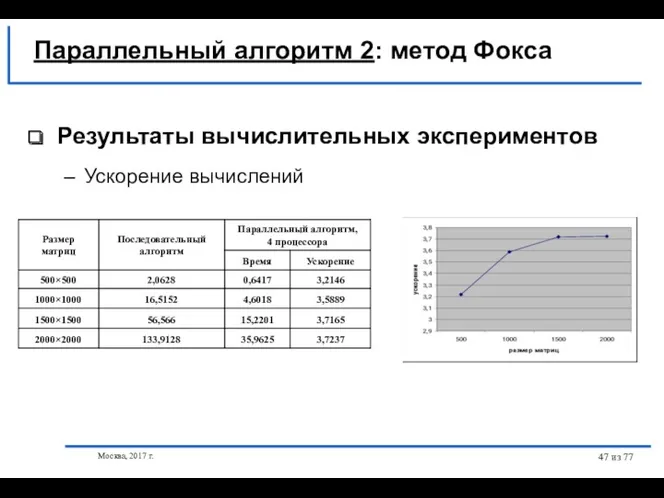
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 2: метод
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 2: метод
Москва, 2017 г.
из 77
Параллельный алгоритм 3: метод Кэннона…
Распределение данных –
Москва, 2017 г.
из 77
Параллельный алгоритм 3: метод Кэннона…
Распределение данных –

Москва, 2017 г.
из 77
Выделение информационных зависимостей
Подзадача (i,j) отвечает за
Москва, 2017 г.
из 77
Выделение информационных зависимостей
Подзадача (i,j) отвечает за
Москва, 2017 г.
из 77
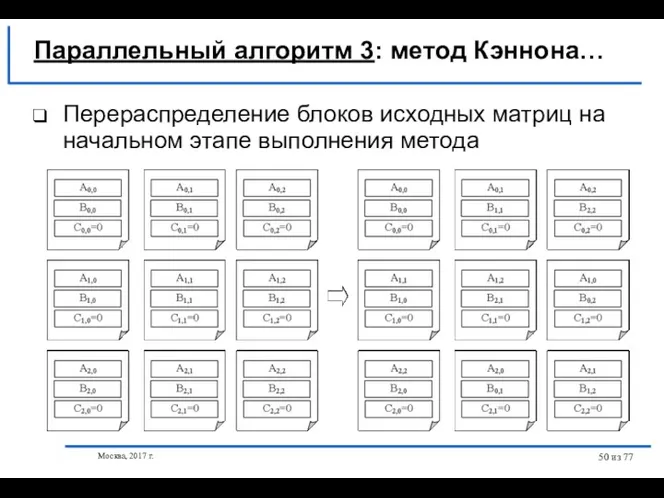
Перераспределение блоков исходных матриц на начальном этапе
Москва, 2017 г.
из 77
Перераспределение блоков исходных матриц на начальном этапе

Москва, 2017 г.
из 77
Выделение информационных зависимостей
В результате начального распределения в
Москва, 2017 г.
из 77
Выделение информационных зависимостей
В результате начального распределения в

Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размер блоков
Москва, 2017 г.
из 77
Масштабирование и распределение подзадач по процессорам
Размер блоков

Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Разработанный
Москва, 2017 г.
из 77
Анализ эффективности
Общая оценка показателей ускорения и эффективности
Разработанный
Москва, 2017 г.
из 77
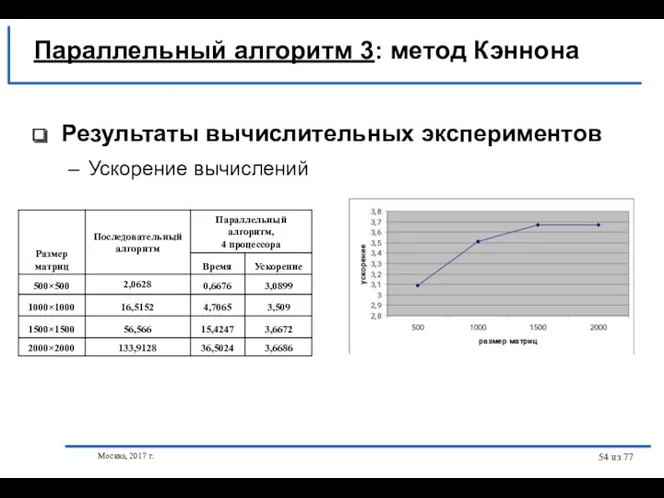
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 3: метод
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов
Ускорение вычислений
Параллельный алгоритм 3: метод

Москва, 2017 г.
из 77
Показатели ускорения рассмотренных параллельных алгоритмов при умножении
Москва, 2017 г.
из 77
Показатели ускорения рассмотренных параллельных алгоритмов при умножении

Москва, 2017 г.
из 77
Постановка задачи
Принципы распараллеливания
Пузырьковая сортировка
Сортировка Шелла
Параллельная быстрая сортировка
Обобщенная
Москва, 2017 г.
из 77
Постановка задачи
Принципы распараллеливания
Пузырьковая сортировка
Сортировка Шелла
Параллельная быстрая сортировка
Обобщенная

Москва, 2017 г.
из 77
Постановка задачи
Сортировка является одной из типовых проблем
Москва, 2017 г.
из 77
Постановка задачи
Сортировка является одной из типовых проблем

Москва, 2017 г.
из 77
Базовая операция – "сравнить и переставить" (compare-exchange)
Москва, 2017 г.
из 77
Базовая операция – "сравнить и переставить" (compare-exchange)

Москва, 2017 г.
из 77
Принципы распараллеливания…
Параллельное обобщение базовой операции при p
Москва, 2017 г.
из 77
Принципы распараллеливания…
Параллельное обобщение базовой операции при p

Москва, 2017 г.
из 77
Принципы распараллеливания…
Результат выполнения параллельного алгоритма:
имеющиеся на
Москва, 2017 г.
из 77
Принципы распараллеливания…
Результат выполнения параллельного алгоритма:
имеющиеся на

Москва, 2017 г.
из 77
Параллельное обобщение базовой операции при p <
Москва, 2017 г.
из 77
Параллельное обобщение базовой операции при p <

Москва, 2017 г.
из 77
Трудоемкость вычислений имеет порядок O(n2)
В прямом виде
Москва, 2017 г.
из 77
Трудоемкость вычислений имеет порядок O(n2)
В прямом виде

Москва, 2017 г.
из 77
Пузырьковая сортировка:
алгоритм чет-нечетной перестановки…
Вводятся два разных
Москва, 2017 г.
из 77
Пузырьковая сортировка:
алгоритм чет-нечетной перестановки…
Вводятся два разных

Москва, 2017 г.
из 77
Пузырьковая сортировка:
алгоритм чет-нечетной перестановки///
// Последовательный алгоритм
Москва, 2017 г.
из 77
Пузырьковая сортировка:
алгоритм чет-нечетной перестановки///
// Последовательный алгоритм

Москва, 2017 г.
из 77
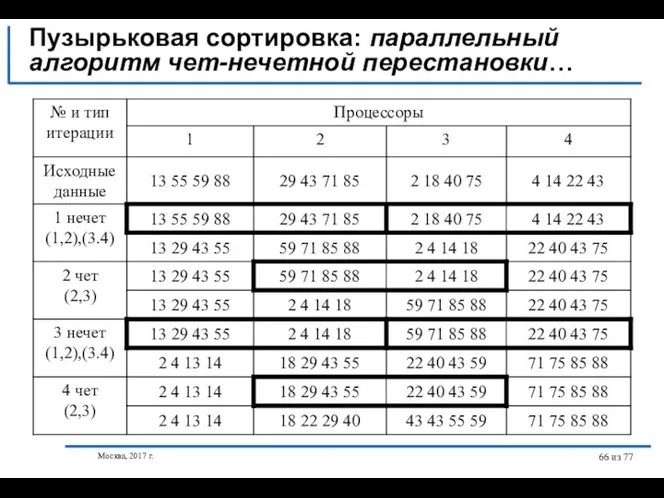
Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
// Параллельный
Москва, 2017 г.
из 77
Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
// Параллельный
Москва, 2017 г.
из 77
Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
Москва, 2017 г.
из 77
Пузырьковая сортировка: параллельный алгоритм чет-нечетной перестановки…
Москва, 2017 г.
из 77
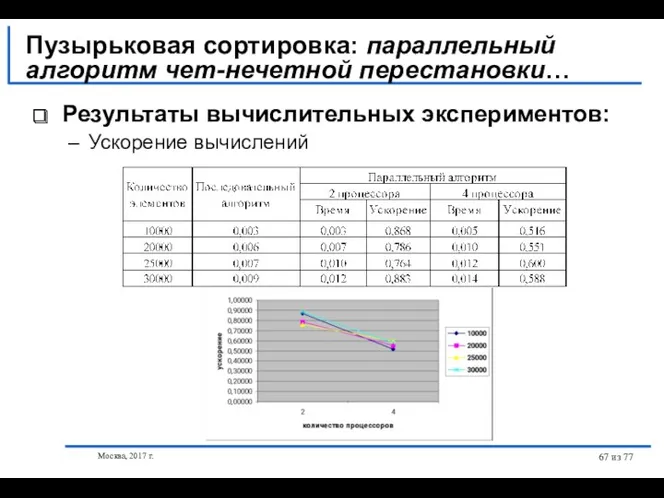
Результаты вычислительных экспериментов:
Ускорение вычислений
Пузырьковая сортировка: параллельный алгоритм
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов:
Ускорение вычислений
Пузырьковая сортировка: параллельный алгоритм

Москва, 2017 г.
из 77
⮲ Параллельный вариант алгоритма работает медленнее исходного
Москва, 2017 г.
из 77
⮲ Параллельный вариант алгоритма работает медленнее исходного

Москва, 2017 г.
из 77
Быстрая сортировка:
последовательный алгоритм…
Алгоритм быстрой
Москва, 2017 г.
из 77
Быстрая сортировка:
последовательный алгоритм…
Алгоритм быстрой
Москва, 2017 г.
из 77
Быстрая сортировка:
последовательный алгоритм…
// Последовательный алгоритм
Москва, 2017 г.
из 77
Быстрая сортировка:
последовательный алгоритм…
// Последовательный алгоритм

Москва, 2017 г.
из 77
Быстрая сортировка: параллельный алгоритм…
Пусть топология коммуникационной
Москва, 2017 г.
из 77
Быстрая сортировка: параллельный алгоритм…
Пусть топология коммуникационной
Москва, 2017 г.
из 77
Быстрая сортировка: параллельный алгоритм…
Москва, 2017 г.
из 77
Быстрая сортировка: параллельный алгоритм…
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов:
Ускорение вычислений
Быстрая сортировка: параллельный алгоритм
Москва, 2017 г.
из 77
Результаты вычислительных экспериментов:
Ускорение вычислений
Быстрая сортировка: параллельный алгоритм

Москва, 2017 г.
из 77
Обобщенная быстрая сортировка:
параллельный алгоритм…
Основное отличие от
Москва, 2017 г.
из 77
Обобщенная быстрая сортировка:
параллельный алгоритм…
Основное отличие от

Москва, 2017 г.
из 77
Первый этап: упорядочивание блоков каждым процессором независимо
Москва, 2017 г.
из 77
Первый этап: упорядочивание блоков каждым процессором независимо
Москва, 2017 г.
из 77
Сортировка с использованием регулярного
набора образцов: параллельный
Москва, 2017 г.
из 77
Сортировка с использованием регулярного набора образцов: параллельный
 Ассоциация школьных библиотекарей русского мира. Развитие школьной библиотеки
Ассоциация школьных библиотекарей русского мира. Развитие школьной библиотеки Повторення правил уведення, редагування та форматування символів тексту та абзаців
Повторення правил уведення, редагування та форматування символів тексту та абзаців История развития ЭВМ
История развития ЭВМ Технология NAT-Network Address Translation
Технология NAT-Network Address Translation Архитектура ЭВМ и вычислительных систем
Архитектура ЭВМ и вычислительных систем С++. Базовый уровень. Создание оконных приложений
С++. Базовый уровень. Создание оконных приложений СМЕТА-2014
СМЕТА-2014 Основные понятия языка Паскаль
Основные понятия языка Паскаль Управление 2D персонажем
Управление 2D персонажем Тематический библиографический список, как одна из форм библиографических пособий малых форм
Тематический библиографический список, как одна из форм библиографических пособий малых форм Етапи розроблення програмного забезпечення
Етапи розроблення програмного забезпечення Информационная безопасность в локально-вычислительных сетях
Информационная безопасность в локально-вычислительных сетях Логические функции MS Excel
Логические функции MS Excel ЕГЭ информатика, задания А1 и А2
ЕГЭ информатика, задания А1 и А2 История развития вычислительной техники
История развития вычислительной техники Примеры циклов пересчет
Примеры циклов пересчет Задание №16: рекурсия. Решение через Excel
Задание №16: рекурсия. Решение через Excel Подготовка к выгрузке данных в ФСПЭО из АИС Сетевой город. Образование версия 5.0 и АИС Е-Услуги
Подготовка к выгрузке данных в ФСПЭО из АИС Сетевой город. Образование версия 5.0 и АИС Е-Услуги Введение в тестирование ПО. Место тестирования в процессе разработки ПО
Введение в тестирование ПО. Место тестирования в процессе разработки ПО Язык программирования Паскаль
Язык программирования Паскаль Программирование на языке ЛИСП. Символ. Определение функций
Программирование на языке ЛИСП. Символ. Определение функций Організація роботи з документами в установах державної влади
Організація роботи з документами в установах державної влади Информатика. Базовые понятия и определения
Информатика. Базовые понятия и определения Технические и программные средства телекоммуникационных технологий
Технические и программные средства телекоммуникационных технологий Компьютерная лексикография (электронные словари в интернете)
Компьютерная лексикография (электронные словари в интернете) Структура программы на языке Паскаль
Структура программы на языке Паскаль Всемирная паутина
Всемирная паутина Архітектура комп’ютера
Архітектура комп’ютера