- Введение в распределенные методы обработки информации. Большие данные + Hadoop

Содержание
- 2. Предыстория Первое упоминание – научная публикация Дата рождения термина — 3 сентября 2008 года, когда вышел
- 3. Предыстория Далее термин стали использовать бизнес-издания Большие данные сравнивали с минеральными ресурсами — the new oil
- 4. Существует ли проблема Больших Данных ? Большие Данные - red herring (букв. «копченая селедка» — ложный
- 5. Big Data — многозначный термин Под термином Большие Данные в разном контексте могут подразумеваться: данные большого
- 6. Данные большого объема В основе информационного взрыва лежит цифровизация нашей жизни. Данные накапливаются эксабайтами (1018 байт).
- 7. Источники Больших Данных Научные исследования Ядерная физика в большом адронном коллайдере в ЦЕРНе соударения частиц происходят
- 8. Источники Больших Данных Интернет По состоянию на 2012 год: количество email, отправляемых каждую секунду в мире,
- 9. Источники Больших Данных Мобильные устройства: Ожидается, что к 2020 году количество смартфонов увеличится с сегодняшних 2,7
- 10. Рост объемов цифровых данных На графике изображен рост объемов информации, согласно исследованию IDC — в 2011
- 11. Определяющие характеристики Аналитики Gartner в своих статьях описали три основных характеристики «Больших Данных», обозначаемых как «три
- 12. Большие данные = технологии их обработки Данных действительно становится все больше и больше, но при этом
- 13. Определение больших данных как технологии Большие данные – это: серия подходов, инструментов и методов обработки структурированных
- 14. Большие данные = проекты или рынок компаний, активно использующих эту технологию При принятии взвешенного решения о
- 15. Большие данные = проекты или рынок компаний, активно использующих эту технологию В 2010 году появляются первые
- 16. Большие данные = проекты или рынок компаний, активно использующих эту технологию Путем объединения и анализа больших
- 17. Большие данные – обобщающее определение Большие данные – это наборы данных такого объема, что традиционные инструменты
- 18. Реальная проблема Больших Данных Технические возможности работы с данными явно опередили уровень развития способностей к их
- 19. Классификация Больших Данных Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие данные на 3 группы:
- 20. Fast Data Обработка данных для Fast Data: не предполагает получения новых знаний, ее результаты соотносятся с
- 21. Технологии Big Analytics должны помогать в получении новых знаний они служат для преобразования зафиксированной в данных
- 22. Deep Insight предполагает обучение без учителя (unsupervised learning) использование современных методов аналитики, а также использование различных
- 23. Большие данные - перспективы Большие данные - качественный переход в компьютерных технологиях, способный повлечь за собой
- 24. Большие данные – примеры использования Парковки: технологии обработки больших данных помогают менеджерам оптимизировать использование наемного/временного персонала
- 25. Большие данные – примеры использования ГОРНЫЕ ЛЫЖИ борьба с фродом – недополученная выручка горнолыжных курортов может
- 26. Большие данные – примеры использования НАРУЖНАЯ РЕКЛАМА агентства смогут планировать размещение рекламы на основании того, как
- 27. Большие данные – примеры использования УПРАВЛЕНИЕ ДОРОЖНЫМ ДВИЖЕНИЕМ Используя относительно недорогие сенсоры радиоволн различных типов, исходящих
- 28. Большие данные – примеры использования НАЙМ ПЕРСОНАЛА Изучая миллионы записей о персонале в различных компаниях, можно
- 29. Большие данные – примеры использования АЗАРТНЫЕ ИГРЫ Онлайн-казино и сайты с разными типами азартных игр производят
- 30. Платформа Hadoop Hadoop – это это свободно распространяемый набор программных средств (Software Framework) для разработки и
- 31. Пользователи Hadoop
- 32. Компоненты платформы Hadoop Hadoop Distributed File System (HDFS) : распределенная файловая система, которая обеспечивает высокоскоростной доступ
- 33. Основные технические характеристики платформы Hadoop Масштабируемость: платформа масштабируется линейно и позволяет хранить и обрабатывать петабайты данных;
- 34. Бизнес-выгоды от использования Hadoop Гибкость: хранение и анализ структурированных и неструктурированных типов данных; Эффективность: в большинстве
- 35. Экосистема платформы Hadoop
- 36. Экосистема платформы Hadoop Центральное место экосистемы Hadoop занимает хранилище данных (Data Storage). Hadoop поддерживает хранение как
- 37. Экосистема платформы Hadoop (Hive) Hive – это надстройка над Hadoop для выполнение следующих задач: суммирование данных,
- 38. Экосистема платформы Hadoop (Pig) Pig – это надстройка, предназначенная для анализа больших наборов данных и состоящая
- 39. Экосистема платформы Hadoop (Sqoop) Sqoop – это инструмент, предназначенный для эффективной передачи больших массивов данных между
- 40. Spark In memory database Spark In memory database – специализированная распределенная система для ускорения обработки данных
- 41. Spark In memory database Поддерживается обработка данных в хранилищах HDFS, HBase, Cassandra, Hive и любом формате
- 42. Shark Shark – компонент Spark, обеспечивающий распределенный механизм SQL-запросов для данных Hadoop. Shark полностью совместим с
- 43. Файловая система HDFS Hadoop Distributed File System (HDFS) - распределенная файловая система, которая обеспечивает высокоскоростной доступ
- 44. Обязательные компоненты HDFS Узел имен (NameNode) – программный код, выполняющийся, в общем случае, на выделенной машине
- 46. Основные концепции и архитектурные решения Объем данных HDFS не должна иметь достижимых в обозримом будущем ограничений
- 47. Основные концепции и архитектурные решения Отказоустойчивость HDFS расценивает выход из строя узла данных как норму, а
- 48. Основные концепции и архитектурные решения Самодиагностика Диагностика исправности узлов в Hadoop-кластере не должна требовать дополнительного администрирования.
- 49. Основные концепции и архитектурные решения Производительность В апреле 2008 года Hadoop побил мировой рекорд производительности в
- 50. Узлы имен Узел имен (NameNode) представляет собой программный код, выполняющийся, в общем случае, на выделенной машине
- 51. Узлы имен HDFS поддерживает вторичный узел имен – Secondary NameNode. Часто это факт является причиной заблуждения,
- 52. Узлы данных Узел данных (DataNode), как и узел NameNode, также представляет собой программный код, выполняющийся, как
- 53. Клиенты HDFS Клиенты представляют собой программных клиентов, работающих с файловой системой. В роли клиента может выступать
- 54. Клиенты HDFS Для клиента HDFS выглядит как обычная файловая система – иерархия каталогов с вложенными в
- 55. Клиенты HDFS Наиболее существенное отличие работы клиента с файловой системой HDFS от работы с файловой системой
- 56. Взаимодействие компонентов HDFS Взаимодействие узлов имен, узлов данных и клиентов осуществляется по протоколам, основывающимся на протоколе
- 57. Файловые операции и репликация Набор допустимых файловых операций в распределенной файловой системе HDFS схож с набором
- 58. Файловые операции и репликация Изначально клиент кэширует необходимую для записи информацию где-то во временном (или постоянном
- 59. Файловые операции и репликация После начала передачи файлового потока узлу DataNode, принимающий узел начинает автоматическую ретрансляцию
- 60. Ограничения HDFS Файловая система HDFS обладает следующими ограничениями: узел имен NameNode является единой точкой отказа; отсутствие
- 61. Hadoop MapReduce (общие сведения) Выполнение распределенных задач на платформе Hadoop происходит в рамках парадигмы map/reduce. map/reduce
- 62. Фаза map(ƒ,c) Принимает функцию ƒ и список c. Возвращает выходной список, являющийся результатом применения функции ƒ
- 63. Фаза reduce(ƒ,c) Принимает функцию ƒ и список c. Возвращает объект, образованный через свертку коллекции c через
- 64. Программная модель map/reduce Программная модель map/reduce была позаимствована из функционального программирования, хотя в реализации Hadoop и
- 65. Примеры программных реализаций модели map/reduce Google MapReduce – закрытая реализация от Google на C++; CouchDB и
- 66. Hadoop MapReduce – детальный обзор Hadoop MapReduce – программная модель (framework) выполнения распределенных вычислений для больших
- 67. Этапы работы Hadoop MapReduce Работу Hadoop MapReduce можно условно поделить на следующие этапы: Input read Входные
- 68. Этапы работы Hadoop MapReduce Partition / Combine Целью этапа partition (разделение) является распределение промежуточных результатов, полученных
- 69. Этапы работы Hadoop MapReduce Функция combine запускается после map-фазы. В ней происходит промежуточная свертка, локальных по
- 70. Этапы работы Hadoop MapReduce Copy / Сompare / Merge На этом этапе происходит: Copy: копирование результатов,
- 71. Этапы работы Hadoop MapReduce Reduce Framework вызывает функцию reduce для каждого уникального ключа k' в отсортированном
- 72. Oбязанность Map-функции конвертировать элементы исходной коллекции в ноль или несколько экземпляров Key/Value объектов
- 73. Следующим шагом, алгоритм отсортирует все пары Key/Value и создаст новые экземпляры объектов, где все значения (value
- 74. В заключении, функция Reduce вернет новый экземпляр объекта, который будет включен в результирующую коллекцию.
- 75. Пример Найти максимальную температуру, наблюдавшуюся в данном городе в определенный период: Массивы исходных данных Toronto, 20
- 76. Пример Действие функции map – образование последовательностей ключ-значение, где из каждого массива уже выбрана максимальная температура.
- 77. Hadoop MapReduce – детальный обзор Разработчику приложения для Hadoop MapReduce необходимо реализовать базовый обработчик, который на
- 78. Hadoop MapReduce – детальный обзор Все остальные фазы выполняются программной моделью MapReduce без дополнительного кодирования со
- 79. Архитектура Hadoop MapReduce Hadoop MapReduce использует архитектуру «master-worker», где master – единственный экземпляр управляющего процесса (JobTracker),
- 80. Архитектура Hadoop MapReduce TaskTracker исполняются в соответствии с принципом «данные близко», т.е. процесс TaskTracker располагается топологически
- 81. Архитектура Hadoop MapReduce JobTracker является единственным узлом, на котором выполняется приложение MapReduce, вызываемое программным клиентом. JobTracker
- 82. Архитектура Hadoop MapReduce В свою очередь, TaskTracker выполняет следующие функции: исполнение map- и reduce-заданий; управление исполнением
- 83. Архитектура Hadoop MapReduce Взаимодействие JobTracker-узла с клиентом (программным) проходит по следующей схеме: JobTracker принимает задание (Job)
- 84. Архитектура Hadoop MapReduce По аналогии с архитектурой HDFS, где NameNode является единичной точкой отказа (Single point
- 86. Преимущества Hadoop MapReduce Эффективная работа с большим (от 100 Гб) объемом данных; Масштабируемость; Отказоустойчивость; Унифицированность подхода;
- 87. Ограничения Hadoop MapReduce Смешение ответственности для Reducer (сортировка и агрегация данных). Таким образом, Reducer – это
- 88. Недостатки Hadoop MapReduce Применение MapReduce по производительности менее эффективно, чем специализированные решения; Эффективность применение MapReduce снижается
- 89. Области применения и ограничения Hadoop Hadoop MapReduce наиболее эффективно на больших кластерах, где издержки на межсетевые
- 90. Области применения и ограничения Hadoop Ограничениям платформы Hadoop складываются как из ограничений отдельных компонентов этой платформы
- 91. Области применения и ограничения Hadoop Сильная связанность фреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм.
- 92. Основные достоинства Hadoop Hadoop является способом построения программных комплексов с архитектурой, входящей в подмножество архитектур MIMD
- 93. Основные достоинства Hadoop Hadoop – уникальный продукт, объединивший многие известные концепции, и позволивший вынести задачу распараллеливания
- 95. Скачать презентацию

Предыстория
Первое упоминание – научная публикация
Дата рождения термина — 3 сентября 2008
Предыстория
Первое упоминание – научная публикация
Дата рождения термина — 3 сентября 2008

Предыстория
Далее термин стали использовать бизнес-издания
Большие данные сравнивали с
минеральными ресурсами —
Предыстория
Далее термин стали использовать бизнес-издания
Большие данные сравнивали с
минеральными ресурсами —

Существует ли проблема Больших Данных ?
Большие Данные - red herring (букв.
Существует ли проблема Больших Данных ?
Большие Данные - red herring (букв.

Big Data — многозначный термин
Под термином Большие Данные в разном контексте
Big Data — многозначный термин
Под термином Большие Данные в разном контексте

Данные большого объема
В основе информационного взрыва лежит цифровизация нашей жизни.
Данные накапливаются
Данные большого объема
В основе информационного взрыва лежит цифровизация нашей жизни.
Данные накапливаются

Источники Больших Данных
Научные исследования
Ядерная физика
в большом адронном коллайдере в ЦЕРНе соударения
Источники Больших Данных
Научные исследования
Ядерная физика
в большом адронном коллайдере в ЦЕРНе соударения

Источники Больших Данных
Интернет
По состоянию на 2012 год:
количество email, отправляемых каждую
Источники Больших Данных
Интернет
По состоянию на 2012 год:
количество email, отправляемых каждую

Источники Больших Данных
Мобильные устройства:
Ожидается, что к 2020 году
количество смартфонов увеличится
Источники Больших Данных
Мобильные устройства:
Ожидается, что к 2020 году
количество смартфонов увеличится
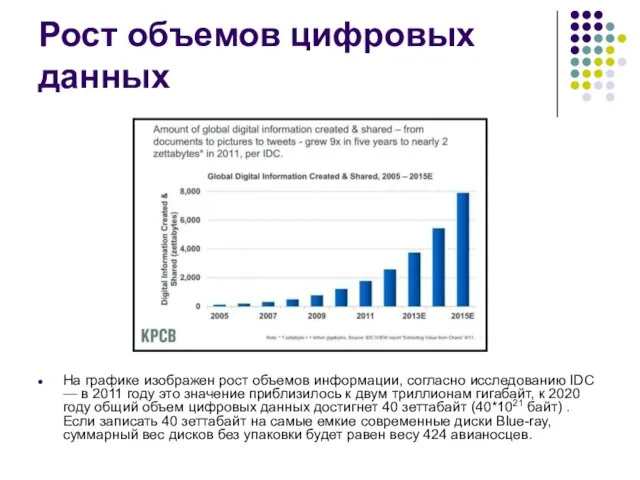
Рост объемов цифровых данных
На графике изображен рост объемов информации, согласно
Рост объемов цифровых данных
На графике изображен рост объемов информации, согласно
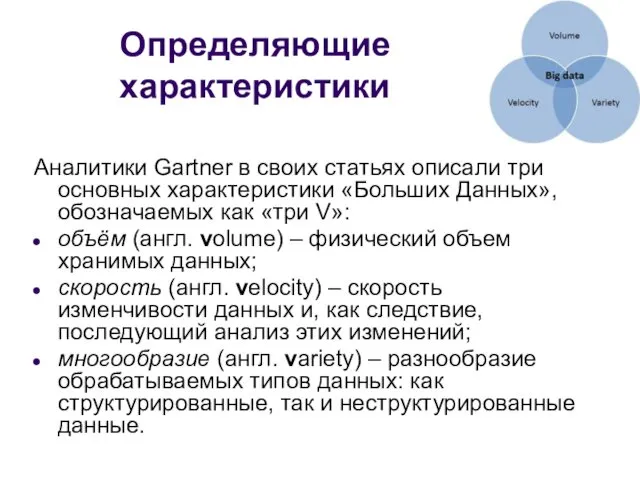
Определяющие характеристики
Аналитики Gartner в своих статьях описали три основных характеристики
Определяющие характеристики
Аналитики Gartner в своих статьях описали три основных характеристики

Большие данные = технологии их обработки
Данных действительно становится все больше и
Большие данные = технологии их обработки
Данных действительно становится все больше и

Определение больших данных как технологии
Большие данные – это:
серия подходов, инструментов и
Определение больших данных как технологии
Большие данные – это:
серия подходов, инструментов и

Большие данные = проекты или рынок компаний, активно использующих эту технологию
При
Большие данные = проекты или рынок компаний, активно использующих эту технологию
При

Большие данные = проекты или рынок компаний, активно использующих эту технологию
В
Большие данные = проекты или рынок компаний, активно использующих эту технологию
В

Большие данные = проекты или рынок компаний, активно использующих эту технологию
Путем
Большие данные = проекты или рынок компаний, активно использующих эту технологию
Путем

Большие данные – обобщающее определение
Большие данные – это наборы данных такого
Большие данные – обобщающее определение
Большие данные – это наборы данных такого

Реальная проблема Больших Данных
Технические возможности работы с данными явно опередили уровень
Реальная проблема Больших Данных
Технические возможности работы с данными явно опередили уровень

Классификация Больших Данных
Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие
Классификация Больших Данных
Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие

Fast Data
Обработка данных для Fast Data:
не предполагает получения новых знаний,
Fast Data
Обработка данных для Fast Data:
не предполагает получения новых знаний,

Технологии Big Analytics
должны помогать в получении новых знаний
они служат
Технологии Big Analytics
должны помогать в получении новых знаний
они служат

Deep Insight
предполагает обучение без учителя (unsupervised learning)
использование современных методов
Deep Insight
предполагает обучение без учителя (unsupervised learning)
использование современных методов

Большие данные - перспективы
Большие данные - качественный переход в компьютерных технологиях,
Большие данные - перспективы
Большие данные - качественный переход в компьютерных технологиях,

Большие данные – примеры использования
Парковки:
технологии обработки больших данных помогают менеджерам
Большие данные – примеры использования
Парковки:
технологии обработки больших данных помогают менеджерам

Большие данные – примеры использования
ГОРНЫЕ ЛЫЖИ
борьба с фродом – недополученная
Большие данные – примеры использования
ГОРНЫЕ ЛЫЖИ
борьба с фродом – недополученная

Большие данные – примеры использования
НАРУЖНАЯ РЕКЛАМА
агентства смогут планировать размещение рекламы
Большие данные – примеры использования
НАРУЖНАЯ РЕКЛАМА
агентства смогут планировать размещение рекламы

Большие данные – примеры использования
УПРАВЛЕНИЕ ДОРОЖНЫМ ДВИЖЕНИЕМ
Используя относительно недорогие сенсоры
Большие данные – примеры использования
УПРАВЛЕНИЕ ДОРОЖНЫМ ДВИЖЕНИЕМ
Используя относительно недорогие сенсоры

Большие данные – примеры использования
НАЙМ ПЕРСОНАЛА
Изучая миллионы записей о персонале
Большие данные – примеры использования
НАЙМ ПЕРСОНАЛА
Изучая миллионы записей о персонале

Большие данные – примеры использования
АЗАРТНЫЕ ИГРЫ
Онлайн-казино и сайты с разными
Большие данные – примеры использования
АЗАРТНЫЕ ИГРЫ
Онлайн-казино и сайты с разными

Платформа Hadoop
Hadoop – это это свободно распространяемый набор программных средств (Software
Платформа Hadoop
Hadoop – это это свободно распространяемый набор программных средств (Software

Пользователи Hadoop
Пользователи Hadoop

Компоненты платформы Hadoop
Hadoop Distributed File System (HDFS) : распределенная файловая система,
Компоненты платформы Hadoop
Hadoop Distributed File System (HDFS) : распределенная файловая система,

Основные технические характеристики платформы Hadoop
Масштабируемость: платформа масштабируется линейно и позволяет
Основные технические характеристики платформы Hadoop
Масштабируемость: платформа масштабируется линейно и позволяет

Бизнес-выгоды от использования Hadoop
Гибкость: хранение и анализ структурированных и неструктурированных типов
Бизнес-выгоды от использования Hadoop
Гибкость: хранение и анализ структурированных и неструктурированных типов
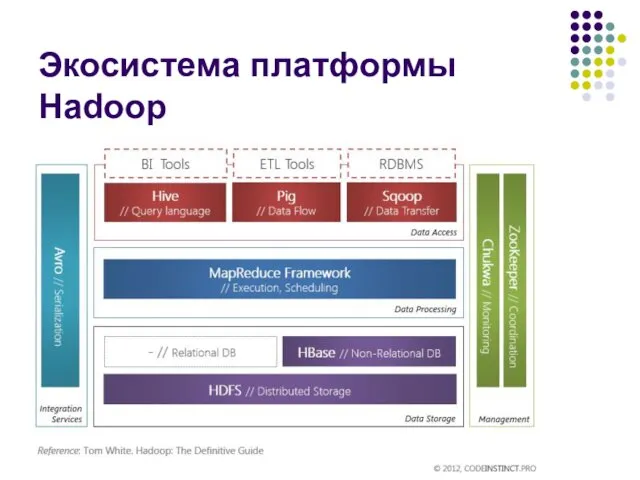
Экосистема платформы Hadoop
Экосистема платформы Hadoop

Экосистема платформы Hadoop
Центральное место экосистемы Hadoop занимает хранилище данных (Data
Экосистема платформы Hadoop
Центральное место экосистемы Hadoop занимает хранилище данных (Data

Экосистема платформы Hadoop (Hive)
Hive – это надстройка над Hadoop для выполнение
Экосистема платформы Hadoop (Hive)
Hive – это надстройка над Hadoop для выполнение

Экосистема платформы Hadoop (Pig)
Pig – это надстройка, предназначенная для анализа
Экосистема платформы Hadoop (Pig)
Pig – это надстройка, предназначенная для анализа

Экосистема платформы Hadoop (Sqoop)
Sqoop – это инструмент, предназначенный для эффективной
Экосистема платформы Hadoop (Sqoop)
Sqoop – это инструмент, предназначенный для эффективной

Spark In memory database
Spark In memory database – специализированная распределенная система
Spark In memory database
Spark In memory database – специализированная распределенная система

Spark In memory database
Поддерживается обработка данных в хранилищах HDFS, HBase, Cassandra,
Spark In memory database
Поддерживается обработка данных в хранилищах HDFS, HBase, Cassandra,

Shark
Shark – компонент Spark, обеспечивающий распределенный механизм SQL-запросов для данных Hadoop.
Shark
Shark – компонент Spark, обеспечивающий распределенный механизм SQL-запросов для данных Hadoop.

Файловая система HDFS
Hadoop Distributed File System (HDFS) - распределенная файловая система,
Файловая система HDFS
Hadoop Distributed File System (HDFS) - распределенная файловая система,

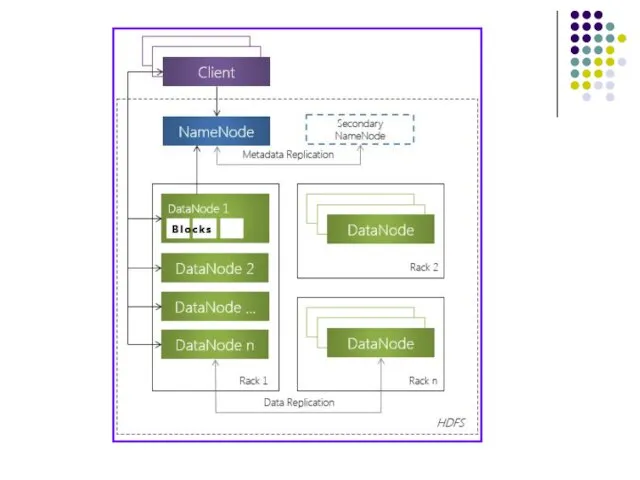
Обязательные компоненты HDFS
Узел имен (NameNode) – программный код, выполняющийся, в общем
Обязательные компоненты HDFS
Узел имен (NameNode) – программный код, выполняющийся, в общем

Основные концепции и архитектурные решения
Объем данных
HDFS не должна иметь достижимых в
Основные концепции и архитектурные решения
Объем данных
HDFS не должна иметь достижимых в

Основные концепции и архитектурные решения
Отказоустойчивость
HDFS расценивает выход из строя узла данных
Основные концепции и архитектурные решения
Отказоустойчивость
HDFS расценивает выход из строя узла данных

Основные концепции и архитектурные решения
Самодиагностика
Диагностика исправности узлов в Hadoop-кластере не должна
Основные концепции и архитектурные решения
Самодиагностика
Диагностика исправности узлов в Hadoop-кластере не должна

Основные концепции и архитектурные решения
Производительность
В апреле 2008 года Hadoop побил мировой
Основные концепции и архитектурные решения
Производительность
В апреле 2008 года Hadoop побил мировой

Узлы имен
Узел имен (NameNode) представляет собой программный код, выполняющийся, в общем случае,
Узлы имен
Узел имен (NameNode) представляет собой программный код, выполняющийся, в общем случае,

Узлы имен
HDFS поддерживает вторичный узел имен – Secondary NameNode. Часто это
Узлы имен
HDFS поддерживает вторичный узел имен – Secondary NameNode. Часто это

Узлы данных
Узел данных (DataNode), как и узел NameNode, также представляет собой
Узлы данных
Узел данных (DataNode), как и узел NameNode, также представляет собой

Клиенты HDFS
Клиенты представляют собой программных клиентов, работающих с файловой системой.
В
Клиенты HDFS
Клиенты представляют собой программных клиентов, работающих с файловой системой.
В

Клиенты HDFS
Для клиента HDFS выглядит как обычная файловая система – иерархия каталогов
Клиенты HDFS
Для клиента HDFS выглядит как обычная файловая система – иерархия каталогов

Клиенты HDFS
Наиболее существенное отличие работы клиента с файловой системой HDFS от
Клиенты HDFS
Наиболее существенное отличие работы клиента с файловой системой HDFS от

Взаимодействие компонентов HDFS
Взаимодействие узлов имен, узлов данных и клиентов осуществляется по
Взаимодействие компонентов HDFS
Взаимодействие узлов имен, узлов данных и клиентов осуществляется по

Файловые операции и репликация
Набор допустимых файловых операций в распределенной файловой
Файловые операции и репликация
Набор допустимых файловых операций в распределенной файловой

Файловые операции и репликация
Изначально клиент кэширует необходимую для записи информацию
Файловые операции и репликация
Изначально клиент кэширует необходимую для записи информацию

Файловые операции и репликация
После начала передачи файлового потока узлу DataNode,
Файловые операции и репликация
После начала передачи файлового потока узлу DataNode,

Ограничения HDFS
Файловая система HDFS обладает следующими ограничениями:
узел имен NameNode является
Ограничения HDFS
Файловая система HDFS обладает следующими ограничениями:
узел имен NameNode является

Hadoop MapReduce (общие сведения)
Выполнение распределенных задач на платформе Hadoop происходит
Hadoop MapReduce (общие сведения)
Выполнение распределенных задач на платформе Hadoop происходит
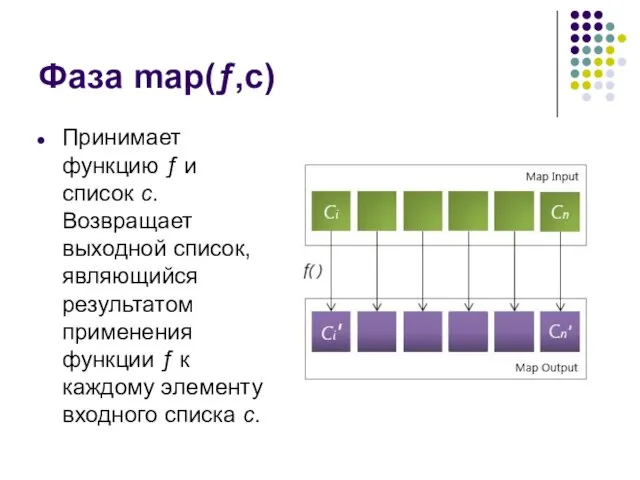
Фаза map(ƒ,c)
Принимает функцию ƒ и список c. Возвращает выходной список, являющийся
Фаза map(ƒ,c)
Принимает функцию ƒ и список c. Возвращает выходной список, являющийся
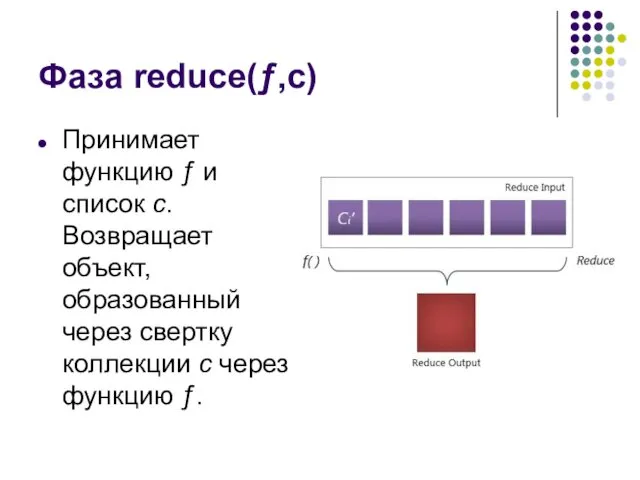
Фаза reduce(ƒ,c)
Принимает функцию ƒ и список c. Возвращает объект, образованный через
Фаза reduce(ƒ,c)
Принимает функцию ƒ и список c. Возвращает объект, образованный через

Программная модель map/reduce
Программная модель map/reduce была позаимствована из функционального программирования,
Программная модель map/reduce
Программная модель map/reduce была позаимствована из функционального программирования,

Примеры программных реализаций модели map/reduce
Google MapReduce – закрытая реализация от Google
Примеры программных реализаций модели map/reduce
Google MapReduce – закрытая реализация от Google

Hadoop MapReduce – детальный обзор
Hadoop MapReduce – программная модель (framework) выполнения распределенных
Hadoop MapReduce – детальный обзор
Hadoop MapReduce – программная модель (framework) выполнения распределенных

Этапы работы Hadoop MapReduce
Работу Hadoop MapReduce можно условно поделить на
Этапы работы Hadoop MapReduce
Работу Hadoop MapReduce можно условно поделить на

Этапы работы Hadoop MapReduce
Partition / Combine
Целью этапа partition (разделение) является распределение промежуточных результатов, полученных
Этапы работы Hadoop MapReduce
Partition / Combine Целью этапа partition (разделение) является распределение промежуточных результатов, полученных
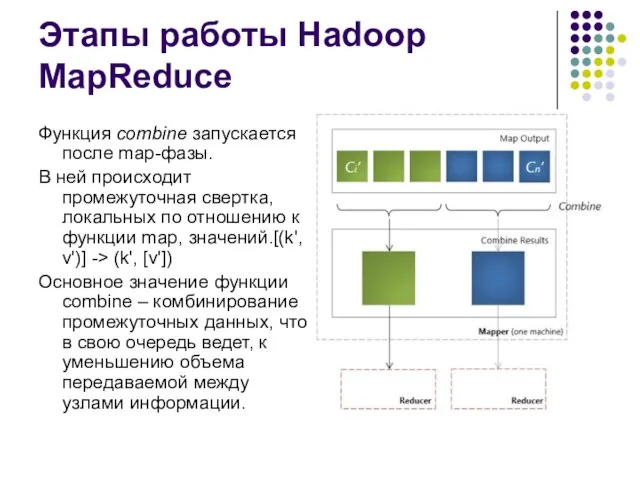
Этапы работы Hadoop MapReduce
Функция combine запускается после map-фазы.
В ней происходит промежуточная
Этапы работы Hadoop MapReduce
Функция combine запускается после map-фазы.
В ней происходит промежуточная

Этапы работы Hadoop MapReduce
Copy / Сompare / Merge
На этом этапе происходит:
Copy: копирование результатов, полученных в
Этапы работы Hadoop MapReduce
Copy / Сompare / Merge
На этом этапе происходит:
Copy: копирование результатов, полученных в

Этапы работы Hadoop MapReduce
Reduce
Framework вызывает функцию reduce для каждого уникального ключа
Этапы работы Hadoop MapReduce
Reduce Framework вызывает функцию reduce для каждого уникального ключа
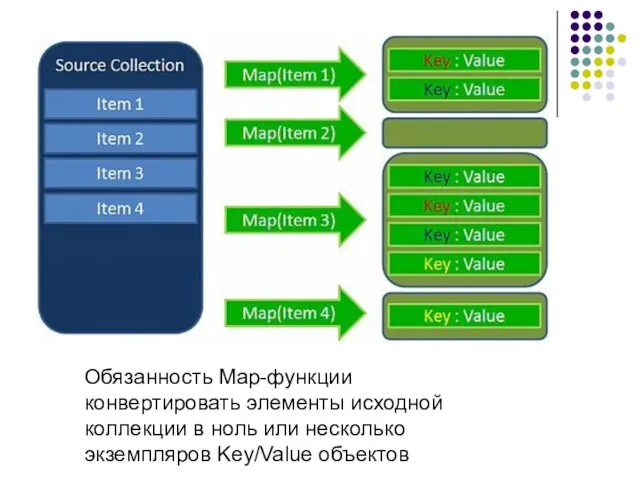
Oбязанность Map-функции конвертировать элементы исходной коллекции в ноль или несколько экземпляров
Oбязанность Map-функции конвертировать элементы исходной коллекции в ноль или несколько экземпляров
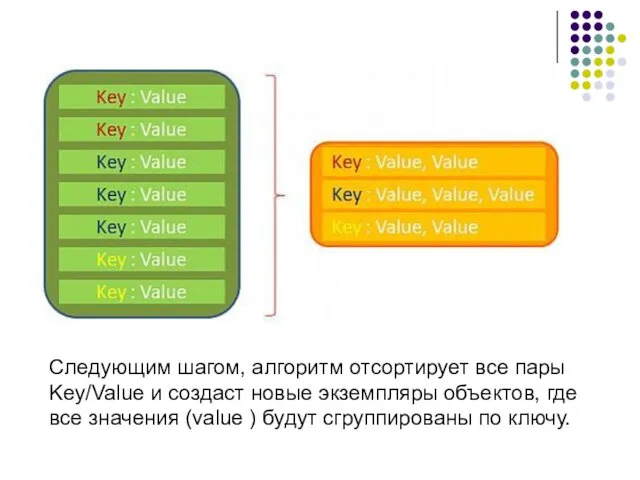
Следующим шагом, алгоритм отсортирует все пары Key/Value и создаст новые экземпляры
Следующим шагом, алгоритм отсортирует все пары Key/Value и создаст новые экземпляры
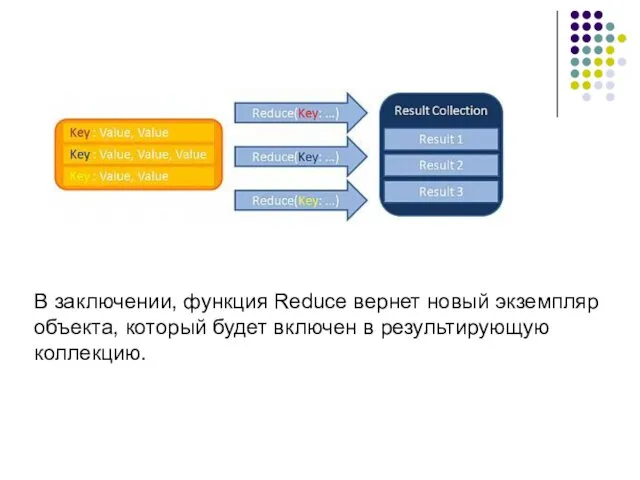
В заключении, функция Reduce вернет новый экземпляр объекта, который будет включен
В заключении, функция Reduce вернет новый экземпляр объекта, который будет включен

Пример
Найти максимальную температуру, наблюдавшуюся в данном городе в определенный период:
Массивы исходных
Пример
Найти максимальную температуру, наблюдавшуюся в данном городе в определенный период:
Массивы исходных

Пример
Действие функции map – образование последовательностей ключ-значение, где из каждого массива
Пример
Действие функции map – образование последовательностей ключ-значение, где из каждого массива

Hadoop MapReduce – детальный обзор
Разработчику приложения для Hadoop MapReduce необходимо реализовать
Hadoop MapReduce – детальный обзор
Разработчику приложения для Hadoop MapReduce необходимо реализовать

Hadoop MapReduce – детальный обзор
Все остальные фазы выполняются программной моделью MapReduce
Hadoop MapReduce – детальный обзор
Все остальные фазы выполняются программной моделью MapReduce

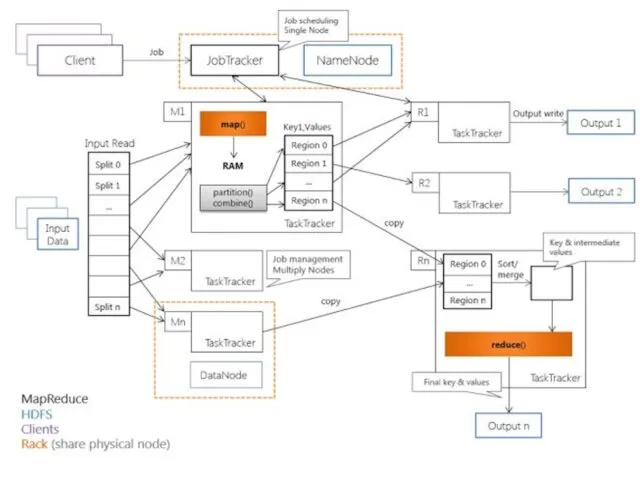
Архитектура Hadoop MapReduce
Hadoop MapReduce использует архитектуру «master-worker», где master – единственный экземпляр
Архитектура Hadoop MapReduce
Hadoop MapReduce использует архитектуру «master-worker», где master – единственный экземпляр

Архитектура Hadoop MapReduce
TaskTracker исполняются в соответствии с принципом «данные близко»,
Архитектура Hadoop MapReduce
TaskTracker исполняются в соответствии с принципом «данные близко»,

Архитектура Hadoop MapReduce
JobTracker является единственным узлом, на котором выполняется приложение
Архитектура Hadoop MapReduce
JobTracker является единственным узлом, на котором выполняется приложение

Архитектура Hadoop MapReduce
В свою очередь, TaskTracker выполняет следующие функции:
исполнение map-
Архитектура Hadoop MapReduce
В свою очередь, TaskTracker выполняет следующие функции:
исполнение map-

Архитектура Hadoop MapReduce
Взаимодействие JobTracker-узла с клиентом (программным) проходит по следующей
Архитектура Hadoop MapReduce
Взаимодействие JobTracker-узла с клиентом (программным) проходит по следующей

Архитектура Hadoop MapReduce
По аналогии с архитектурой HDFS, где NameNode является
Архитектура Hadoop MapReduce
По аналогии с архитектурой HDFS, где NameNode является

Преимущества Hadoop MapReduce
Эффективная работа с большим (от 100 Гб) объемом
Преимущества Hadoop MapReduce
Эффективная работа с большим (от 100 Гб) объемом

Ограничения Hadoop MapReduce
Смешение ответственности для Reducer (сортировка и агрегация данных).
Ограничения Hadoop MapReduce
Смешение ответственности для Reducer (сортировка и агрегация данных).

Недостатки Hadoop MapReduce
Применение MapReduce по производительности менее эффективно, чем специализированные
Недостатки Hadoop MapReduce
Применение MapReduce по производительности менее эффективно, чем специализированные

Области применения и ограничения Hadoop
Hadoop MapReduce наиболее эффективно на больших
Области применения и ограничения Hadoop
Hadoop MapReduce наиболее эффективно на больших

Области применения и ограничения Hadoop
Ограничениям платформы Hadoop складываются как из
Области применения и ограничения Hadoop
Ограничениям платформы Hadoop складываются как из

Области применения и ограничения Hadoop
Сильная связанность фреймворка распределенных вычислений и
Области применения и ограничения Hadoop
Сильная связанность фреймворка распределенных вычислений и

Основные достоинства Hadoop
Hadoop является способом построения программных комплексов с архитектурой, входящей
Основные достоинства Hadoop
Hadoop является способом построения программных комплексов с архитектурой, входящей

Основные достоинства Hadoop
Hadoop – уникальный продукт, объединивший многие известные концепции, и
Основные достоинства Hadoop
Hadoop – уникальный продукт, объединивший многие известные концепции, и
 Чат-боты в мессенджерах
Чат-боты в мессенджерах История серии видеоигр: Doom, Rage, Left 4 Dead
История серии видеоигр: Doom, Rage, Left 4 Dead Антивирусные программы
Антивирусные программы Киберспорт - это спорт?
Киберспорт - это спорт? Локальные и глобальные компьютерные сети. Коммуникационные технологии
Локальные и глобальные компьютерные сети. Коммуникационные технологии Понятие информационных технологий и этапы их развития. Классификация ИТ
Понятие информационных технологий и этапы их развития. Классификация ИТ Network core packet switching, circuit switching
Network core packet switching, circuit switching Вычислительная математика. Теория и практика в среде
Вычислительная математика. Теория и практика в среде Разработка игры “Epic Bounce” на языке Python
Разработка игры “Epic Bounce” на языке Python Виды источников информации
Виды источников информации Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование
Электронные ресурсы для детей и юношества в общедоступных библиотеках: создание и использование Ethetnet жергілікті есептеу торабы
Ethetnet жергілікті есептеу торабы Методическая разработка урока информатики по теме Законы алгебры логики в 9 классе
Методическая разработка урока информатики по теме Законы алгебры логики в 9 классе Портфолио по профессиональному модулю ПМ 02
Портфолио по профессиональному модулю ПМ 02 Протокол разделения секрета и другие протоколы
Протокол разделения секрета и другие протоколы API-Телефония. Что такое API-Телефония’?
API-Телефония. Что такое API-Телефония’? Информатика в жизни общества
Информатика в жизни общества Информация как продукт (лекция 3)
Информация как продукт (лекция 3) Smart technology. Internet of Things. Big data
Smart technology. Internet of Things. Big data Пресс - конференция. Структура и этапы
Пресс - конференция. Структура и этапы Інформаційні системи у сучасному суспільстві
Інформаційні системи у сучасному суспільстві Предмет и задачи информатики
Предмет и задачи информатики Методы и технологии искусственного интеллекта
Методы и технологии искусственного интеллекта Introduction to Information and Communication Technologies. Properties and classification of ICTs
Introduction to Information and Communication Technologies. Properties and classification of ICTs Переменная. Использование переменной
Переменная. Использование переменной Основные компоненты компьютера и их свойства
Основные компоненты компьютера и их свойства Представления об объектах окружающего мира. 8 класс
Представления об объектах окружающего мира. 8 класс Основы PHP. Лекция 1
Основы PHP. Лекция 1