- Язык си. Часть 5. Приведение типов. Символы и строки

Содержание
- 2. Приведение типов
- 3. Приведение типов Некоторые операции в зависимости от своих операндов могут инициировать преобразование значений из одного типа
- 4. Преобразования целых типов Знаковые и беззнаковые значения типа char, short int и enum могут использоваться в
- 5. Преобр-е «целое – веществ-е» При преобразовании из вещественного типа в целочисленный дробная часть числа отбрасывается; если
- 6. Преобр-е вещественных типов При преобразовании из вещественного типа меньшей точности к типу большей точности число не
- 8. Арифметические преобразования если один операнд имеет тип: то другой преобраз-ся в: Во-первых,
- 9. Преобразования указателей Любой указатель можно привести к типу void * без потери информации. Если результат подвергнуть
- 10. Работа со строками и символами
- 11. Кодировки символов Для представления текста в цифровом формате необходимо придумать систему кодирования, в которой каждой букве
- 12. Кодировка ASCII 1967 год – американский стандартный код для обмена информацией (American Standard Code for Information
- 13. Полная ASCII-таблица есть в файле ascii.pdf. Там же есть и расширенные таблицы 866 и CP-1251.
- 14. Unicode 1988 год – таблица кодирования символов, которая содержит 1 114 112 кодов для символов всех
- 15. Тип char Переменная типа char занимает 1 байт памяти и хранит целое число, обозначающее код символа
- 16. Функции для работы с char Ввод/вывод: 1. Указание типа в printf/scanf - %c. Пример: вывод всей
- 17. Функции для анализа символов isalnum (c) ИСТИННО isalpha(с)ИЛИ isdigit(с) isalpha (с) ИСТИННО isupper(с)ИЛИ islower(с) iscntrl (c)
- 18. #define EOF (-1) Макрос EOF – определен в файле stdio.h и служит для индикации того, что
- 19. Строки Строка – это массив элементов типа char, заканчивающийся символом ‘\0’ (NULL). char A1[20] = {
- 20. Ввод строки: scanf(“ %s”, str); // до 1-го пробельного символа gets( str ); // ввод до
- 22. Скачать презентацию

Приведение типов
Приведение типов

Приведение типов
Некоторые операции в зависимости от своих операндов могут инициировать преобразование
Приведение типов
Некоторые операции в зависимости от своих операндов могут инициировать преобразование

Преобразования целых типов
Знаковые и беззнаковые значения типа char, short int и
Преобразования целых типов
Знаковые и беззнаковые значения типа char, short int и

Преобр-е «целое – веществ-е»
При преобразовании из вещественного типа в целочисленный дробная
Преобр-е «целое – веществ-е»
При преобразовании из вещественного типа в целочисленный дробная

Преобр-е вещественных типов
При преобразовании из вещественного типа меньшей точности к типу
Преобр-е вещественных типов
При преобразовании из вещественного типа меньшей точности к типу


Арифметические преобразования
если один операнд имеет тип:
то другой преобраз-ся в:
Во-первых,
Арифметические преобразования
если один операнд имеет тип:
то другой преобраз-ся в:
Во-первых,

Преобразования указателей
Любой указатель можно привести к типу void * без потери
Преобразования указателей
Любой указатель можно привести к типу void * без потери

Работа со строками и символами
Работа со строками и символами

Кодировки символов
Для представления текста в цифровом формате необходимо придумать систему кодирования,
Кодировки символов
Для представления текста в цифровом формате необходимо придумать систему кодирования,

Кодировка ASCII 1967 год
– американский стандартный код для обмена информацией (American
Кодировка ASCII 1967 год
– американский стандартный код для обмена информацией (American
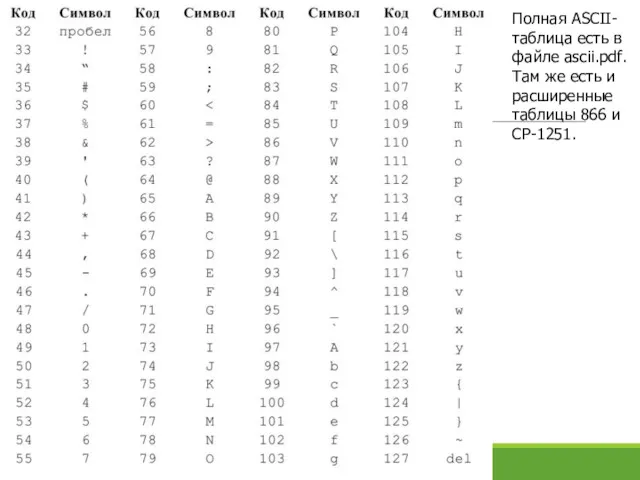
Полная ASCII-таблица есть в файле ascii.pdf. Там же есть и расширенные
Полная ASCII-таблица есть в файле ascii.pdf. Там же есть и расширенные

Unicode 1988 год
– таблица кодирования символов, которая содержит 1 114 112 кодов
Unicode 1988 год
– таблица кодирования символов, которая содержит 1 114 112 кодов

Тип char
Переменная типа char занимает 1 байт памяти и хранит целое
Тип char
Переменная типа char занимает 1 байт памяти и хранит целое

Функции для работы с char
Ввод/вывод:
1. Указание типа в printf/scanf - %c.
Функции для работы с char
Ввод/вывод:
1. Указание типа в printf/scanf - %c.

Функции для анализа символов
isalnum (c) ИСТИННО isalpha(с)ИЛИ isdigit(с)
isalpha (с) ИСТИННО
Функции для анализа символов
isalnum (c) ИСТИННО isalpha(с)ИЛИ isdigit(с)
isalpha (с) ИСТИННО

#define EOF (-1)
Макрос EOF – определен в файле stdio.h и
#define EOF (-1)
Макрос EOF – определен в файле stdio.h и

Строки
Строка – это массив элементов типа char, заканчивающийся символом ‘\0’ (NULL).
Строки
Строка – это массив элементов типа char, заканчивающийся символом ‘\0’ (NULL).

Ввод строки:
scanf(“ %s”, str); // до 1-го пробельного символа
gets( str );
Ввод строки:
scanf(“ %s”, str); // до 1-го пробельного символа
gets( str );
 Разработка алгоритмов распознавания дефекта изделия с использованием нейронных сетей
Разработка алгоритмов распознавания дефекта изделия с использованием нейронных сетей Сравнительная характеристика операционной системы Windows XP и Vista (11 класс)
Сравнительная характеристика операционной системы Windows XP и Vista (11 класс) Введение в SMM. Урок №1
Введение в SMM. Урок №1 4. Java OOP. 3. Encapsulation
4. Java OOP. 3. Encapsulation Паттерн фабричный метод (шаблон)
Паттерн фабричный метод (шаблон) Методы и технологии прототипирования изделий. (Лекция 7)
Методы и технологии прототипирования изделий. (Лекция 7) Взаимодействие с сервером Oracle
Взаимодействие с сервером Oracle Технические решения и проектирование подсистем автоматического управления в ЭСБ различного функционального назначения (Часть 6)
Технические решения и проектирование подсистем автоматического управления в ЭСБ различного функционального назначения (Часть 6) Независимые повторности, как основа для вероятностных выводов о свойствах генеральной совокупности. (Лекция 6)
Независимые повторности, как основа для вероятностных выводов о свойствах генеральной совокупности. (Лекция 6) Рост эффективности, инвестиционной привлекательности и капитализации бизнеса при использовании ERP-решений фирмы 1С
Рост эффективности, инвестиционной привлекательности и капитализации бизнеса при использовании ERP-решений фирмы 1С Программирование передачи информации между компьютерами по сети. Клиент-серверные приложения
Программирование передачи информации между компьютерами по сети. Клиент-серверные приложения Instructions for use. Edit in Google slides edit in PowerPoint®
Instructions for use. Edit in Google slides edit in PowerPoint® Связь web-страницы с базой данных
Связь web-страницы с базой данных Правила заполнения таблицы
Правила заполнения таблицы Структура интернет-рынка в России
Структура интернет-рынка в России Ресурсы сети в научных исследованиях: преимущества и недостатки
Ресурсы сети в научных исследованиях: преимущества и недостатки Информационная безопасность для сотрудников компании. Законы информирования внутри организации
Информационная безопасность для сотрудников компании. Законы информирования внутри организации Организация циклов, условные операторы, написание функций
Организация циклов, условные операторы, написание функций Электронные системы тестирования
Электронные системы тестирования Programming paradigms
Programming paradigms Мова програмування Java 2 (Java SE 6, Java SE 7)
Мова програмування Java 2 (Java SE 6, Java SE 7) Отцы и дети онлайн. Чего не знают родители
Отцы и дети онлайн. Чего не знают родители Позиционирование, Декоративные элементы
Позиционирование, Декоративные элементы Индексы в СУБД PostgreSQL
Индексы в СУБД PostgreSQL Презентация 7 класс Типы таблиц
Презентация 7 класс Типы таблиц Право и этика СМИ
Право и этика СМИ Администрирование межсетевых экранов. Лекция 7
Администрирование межсетевых экранов. Лекция 7 Кейсы и антикейсы: SEO для новых рынков - как продвигаться, если выдача и конкуренция меняется каждый день
Кейсы и антикейсы: SEO для новых рынков - как продвигаться, если выдача и конкуренция меняется каждый день