- Языки SQL и QBE

Содержание
- 2. Цели лекции В этой лекции будут бегло рассмотрены основы наиболее известных языков баз данных реляционного типа
- 3. Часть I. Язык SQL © Бессарабов Н.В.2019
- 4. История из реальной жизни …
- 5. 1.1.Структура языка SQL В этом разделе рассмотрим расширение языка запросов, основанного на исчислении на кортежах, за
- 6. Немного истории Язык SQL (Structured Query Language). Произношение названия эс-кью-эл]. Профессионалы часто произносят как [сиквел] --
- 7. Та же история, но чуть подробнее
- 8. Подъязыки SQL Выделяются следующие подъязыки: Язык определения данных (ЯОД). Он же Data Definition Language (DDL). Определяет
- 9. О терминологии SQL Вспомним, что язык SQL оперирует терминами, отличающимися от терминов принятых в реляционной теории:
- 10. Базы, схемы, хранимые объекты базы Хранимые объекты базы реляционного типа, образующие схему базы: Таблицы – в
- 11. Язык DDL. Операторы определения объектов базы данных Для каждого типа хранимых объектов базы (таблица, представление, последовательность,
- 12. Виды таблиц в Oracle Heap organized tables - обычные таблицы (heap - куча), данные хранятся неупорядоченно.
- 13. Создание таблицы (1/3) Часть синтаксиса инструкции создания таблицы: CREATE TABLE имя_таблицы (столбец [,{столбец|именованное_ограничение_целостности}] .... ) где
- 14. Создание таблицы (2/3) Виды ограничений целостности: NOT NULL | NULL — ограничитель NOT NULL запрещает вводить
- 15. Создание таблицы (3/3) Удобно пользоваться синтаксическими диаграммами. Ниже пример для Oracle 11g. Обратите внимание, насколько в
- 16. Первичный и внешний ключи: CREATE TABLE example5 ( table_id NUMBER(10) PRIMARY KEY, example_table_id NUMBER(10) REFERENCES example4(table_id),
- 17. Удаление и изменение таблиц Удаление таблицы: DROP TABLE имя_таблицы [CASCADE|RESTRICT] Изменение таблицы (опять неполный синтаксис): ALTER
- 18. Изменение таблиц в Oracle (малая часть диаграммы) © Бессарабов Н.В.2019
- 19. Языки DML и DCL. Манипулирование и управление данными Манипулирование данными (DML): INSERT - добавить строки в
- 20. Инструкции DML Новая строка вводится в таблицу инструкцией INSERT, имеющей в простейшем случае формат: INSERT INTO
- 21. 1.2. Запросы в SQL © Бессарабов Н.В.2019
- 22. Язык SQL. Запрос в рамках TRC Если оставаться строго в рамках исчисления на кортежах, то инструкция
- 23. Язык SQL. Простейший запрос А теперь как простой SELECT выглядит на самом деле: SELECT [DISTINCT] {[*]|{столбец|константа|функция[
- 24. Выполнение однотабличного запроса Запрос выполняется путём поочерёдного применения фраз, образующих инструкцию: По фразе FROM выбираются (считываются)
- 25. Сравнение запросов SQL и запросов в языке TRC (1/3) Расширения языка запросов SQL по сравнению с
- 26. Сравнение запросов SQL и запросов в языке TRC (2/3) Выражение CASE также играет роль встроенного IF-THEN-ELSE.
- 27. Сравнение запросов SQL и запросов в языке TRC (3/3) 4. Использование строк с разделителями и списков
- 28. Три вида запросов SQL Простые запросы (запросы без подзапросов) Соединения запросов Запросы с подзапросами Учитывая что
- 29. Соединение результатов запросов Результаты нескольких запросов можно объединить операциями UNION и UNION ALL. Объединение возможно, если
- 30. Соединения таблиц Соединения двух и более таблиц могут выполняться в одном запросе с указанием условий соединения.
- 31. Внутренние и внешние соединения В рассмотренном на предыдущем слайде примере и операциях соединения реляционной алгебры (по
- 32. Внешние соединения Для задания внешнего соединения до появления стандарта SQL92 во фразе WHERE использовались специальные обозначения,
- 33. Выполнение внешних соединений Порядок действий при выполнении полного внешнего соединения двух таблиц: Построить внутреннее cоединение таблиц.
- 34. Соединения в стандарте SQL92 (1/2) В стандарте SQL92 внешние соединения определяются во фразе FROM, которая получает
- 35. Соединения в стандарте SQL92 (2/2) Внешние соединения – полное, левое, правое. Синтаксис: SELECT список_SELECT FROM имя_таблицы
- 36. Запросы с группированием Фраза GROUP BY, упоминавшаяся ранее, обеспечивает объединение строк с одинаковыми значениями в перечисленных
- 37. Выполнение запросов с группированием Порядок действий при выполнении запросов с фразой GROUP BY: По фразе FROM
- 38. Отбор групп строк -- фраза HAVING Фраза HAVING предназначена для организации отбора групп. Формат записываемого в
- 39. Выполнение запросов с фразой HAVING Ограничения на условия отбора групп: Операндами в условиях отбора могут быть
- 40. Подзапросы Подзапрос - это инструкция SELECT, вложенная в другую инструкцию SELECT для получения промежуточных результатов. Подзапросы
- 41. Однострочные подзапросы Однострочный подзапрос возвращает ровно одну строку. С однострочными подзапросами используются однострочные операторы сравнения: >,
- 42. Многострочные подзапросы Многострочный подзапрос может вернуть несколько строк. Операторы сравнения для многострочных подзапросов: IN (подзапрос) -
- 43. Примеры многострочных подзапросов Многострочный подзапрос с оператором сравнения ANY: SELECT empno, ename, job, sal FROM emp
- 44. Коррелированные подзапросы Обычный подзапрос выполняется первым, внешний запрос вторым. Коррелированными называются подзапросы, выполняющиеся для каждой строки-кандидата
- 45. Пример коррелированного подзапроса Найдите всех работников, которые получают зарплату выше средней в своем отделе: SELECT ENAME,
- 46. Иерархические структуры в таблицах Уже упоминалось, что таблица может хранить дерево (лек. 7, сл.10). В синтаксис
- 47. Иерархическая структура в таблице emp В таблице emp хранится следующая иерархия: Пример запроса снизу вверх начиная
- 48. Примеры запросов к иерархиям В запросе к EMP начинаем с президента King, не имеющего начальника: ...
- 49. Храним деревья и сети в таблицах В табличной базе для работы с деревьями необходимо вводить в
- 51. Что такое представление (VIEW) Представления создаются инструкцией похожей на инструкцию создания таблиц. Фразы ORDER BY и
- 52. Часть диаграммы синтаксиса создания представления
- 53. Опция WITH CHECK OPTION Как уже упоминалось, применение операций INSERT, UPDATE и DELETE к представлению не
- 54. Пример WITH CHECK OPTION 1/2 Запись в emp через emp10 сделана, но через emp10 её не
- 55. Пример WITH CHECK OPTION 2/2 Добавим опцию WITH CHECK OPTION в определение представления. Теперь нельзя добавить
- 56. Встроенный SQL Ограничения SQL можно преодолеть двумя способами: встраивая SQL в процедурный язык общего назначения; расширяя
- 57. Встроенный SQL. Примеры 1. Для создания таблицы пишем программу &sql(create table QQ ( C1 SMALLINT PRIMARY
- 58. Непервая нормальная форма и регулярные выражения Использование сложных структур в составе значения, которое с точки зрения
- 59. Где можно встретить регулярные выражения? Почти везде! Простые варианты регулярных выражений есть в: в DOS (помните
- 60. Регулярные выражения. Основные понятия Задача, требующая замены или поиска фрагментов текста, может быть решена с помощью
- 61. Специальные символы (метасимволы) Метасимволы задают : тип символов искомой строки; способ окружения искомой строки в тексте;
- 62. Символьные классы Классы символов или скобочные выражения -- это сокращенные именования типов строк. Используются в Oracle
- 63. Синтаксис функций REGEXP REGEXP_LIKE (исходная_строка, шаблон [, параметр_соответствия]) -- выбирает все строки соответствующие шаблону рег. выражения
- 64. Синтаксис функции REGEXP_SUBSTR REGEXP_SUBSTR находит соответствие указанной части обрабатываемой строки. Синтаксис: REGEXP_SUBSTR (исходная_строка, -- переменная, либо
- 65. Примеры использования функций REGEXP в Oracle '^Ste(v|ph)en$' : ^ указывает на начало фразы $ указывает на
- 66. II. Язык QBE (Query-by-example) © Бессарабов Н.В.2019
- 67. Язык QBE QBE (Query-By-Example) – язык исчисления с переменными на доменах. Разработан М. Злуфом в IBM
- 68. Изобразительные средства QBE (1/2) Исходное изображение – прямоугольник (рис.1), в котором пользователь вводит имя таблицы. Если
- 69. Изобразительные средства QBE (2/2) Что можно записать в нижней строке? Один из ограниченного (это хорошо) набора
- 70. Основы QBE (1/5) Часть языка, связанную с запросами, следуя основополагающей работе М.Злуфа, рассмотрим на схеме: EMP(NAME,
- 71. Основы QBE (2/5) Если же таблица существует, появится ее схема: В нижней строке в столбце ITEM
- 72. Основы QBE (3/5) Подчеркивание в имени определяет переменную. Использование переменных позволяет связывать таблицы. В частности, реализуем
- 73. Основы QBE (4/5) В записи условия выбора можно работать с шаблонами. Для этого вводят частичное подчеркивание
- 74. Основы QBE (5/5) В QBE можно организовывать запросы в логике второго порядка. Как вы помните, в
- 75. Выборка с использованием блока условий В Query-by-Example существует два двухмерных объекта. Один из них - шаблон
- 76. QBE. Команды DML Вставка Удаление Обновление © Бессарабов Н.В.2019
- 77. QBE. Создание таблицы Создается таблица с именем EMP и столбцами NAME, SAL, MGR, DEPT. Начав с
- 78. Ограниченность QBE Возможно, вы заметили, что QBE в представленной версии существенно уже чем SQL. Например, отсутствуют
- 79. QBE. Приложение: Содержание использованных таблиц © Бессарабов Н.В.2019
- 81. Скачать презентацию

Цели лекции
В этой лекции будут бегло рассмотрены основы наиболее известных
языков
Цели лекции
В этой лекции будут бегло рассмотрены основы наиболее известных
языков

Часть I. Язык SQL
© Бессарабов Н.В.2019
Часть I. Язык SQL
© Бессарабов Н.В.2019

История из реальной жизни …
История из реальной жизни …

1.1.Структура языка SQL
В этом разделе рассмотрим расширение языка запросов,
основанного на исчислении
1.1.Структура языка SQL
В этом разделе рассмотрим расширение языка запросов,
основанного на исчислении
![Немного истории Язык SQL (Structured Query Language). Произношение названия эс-кью-эл].](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1952/slide-5.jpg)
Немного истории
Язык SQL (Structured Query Language). Произношение названия эс-кью-эл].
Немного истории
Язык SQL (Structured Query Language). Произношение названия эс-кью-эл].
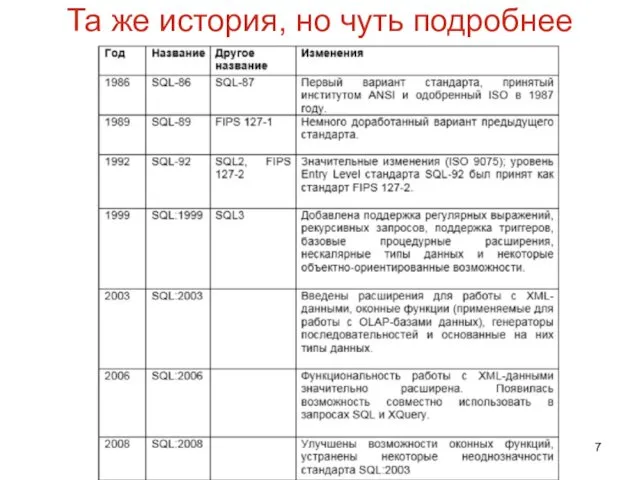
Та же история, но чуть подробнее
Та же история, но чуть подробнее

Подъязыки SQL
Выделяются следующие подъязыки:
Язык определения данных (ЯОД). Он же Data Definition
Подъязыки SQL
Выделяются следующие подъязыки:
Язык определения данных (ЯОД). Он же Data Definition
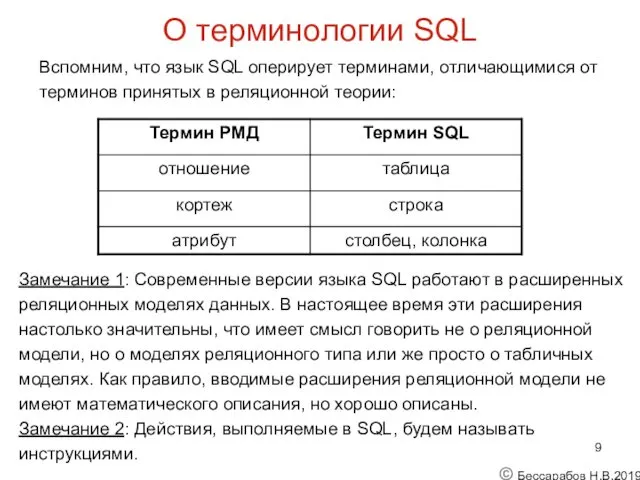
О терминологии SQL
Вспомним, что язык SQL оперирует терминами, отличающимися от
терминов
О терминологии SQL
Вспомним, что язык SQL оперирует терминами, отличающимися от
терминов

Базы, схемы, хранимые объекты базы
Хранимые объекты базы реляционного типа, образующие
Базы, схемы, хранимые объекты базы
Хранимые объекты базы реляционного типа, образующие

Язык DDL. Операторы определения объектов базы данных
Для каждого типа хранимых объектов
Язык DDL. Операторы определения объектов базы данных
Для каждого типа хранимых объектов

Виды таблиц в Oracle
Heap organized tables - обычные таблицы (heap - куча),
Виды таблиц в Oracle
Heap organized tables - обычные таблицы (heap - куча),

Создание таблицы (1/3)
Часть синтаксиса инструкции создания таблицы:
CREATE TABLE имя_таблицы
Создание таблицы (1/3)
Часть синтаксиса инструкции создания таблицы:
CREATE TABLE имя_таблицы

Создание таблицы (2/3)
Виды ограничений целостности:
NOT NULL | NULL — ограничитель NOT
Создание таблицы (2/3)
Виды ограничений целостности:
NOT NULL | NULL — ограничитель NOT
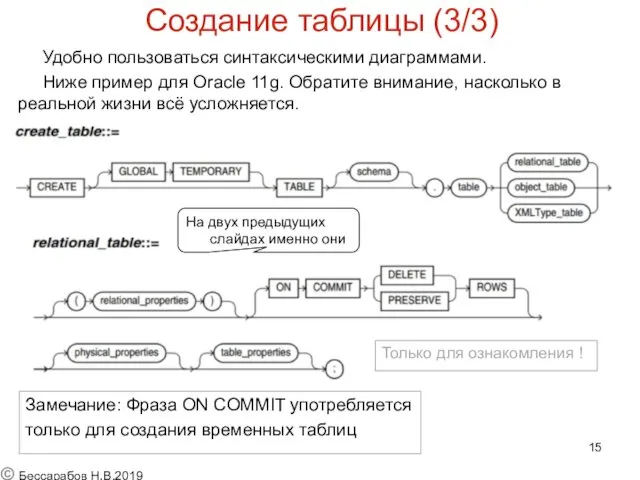
Создание таблицы (3/3)
Удобно пользоваться синтаксическими диаграммами.
Ниже пример для
Создание таблицы (3/3)
Удобно пользоваться синтаксическими диаграммами.
Ниже пример для

Первичный и внешний ключи:
CREATE TABLE example5 (
table_id NUMBER(10) PRIMARY
Первичный и внешний ключи:
CREATE TABLE example5 (
table_id NUMBER(10) PRIMARY
![Удаление и изменение таблиц Удаление таблицы: DROP TABLE имя_таблицы [CASCADE|RESTRICT]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1952/slide-16.jpg)
Удаление и изменение таблиц
Удаление таблицы:
DROP TABLE имя_таблицы [CASCADE|RESTRICT]
Изменение таблицы (опять
неполный
Удаление и изменение таблиц
Удаление таблицы:
DROP TABLE имя_таблицы [CASCADE|RESTRICT]
Изменение таблицы (опять
неполный
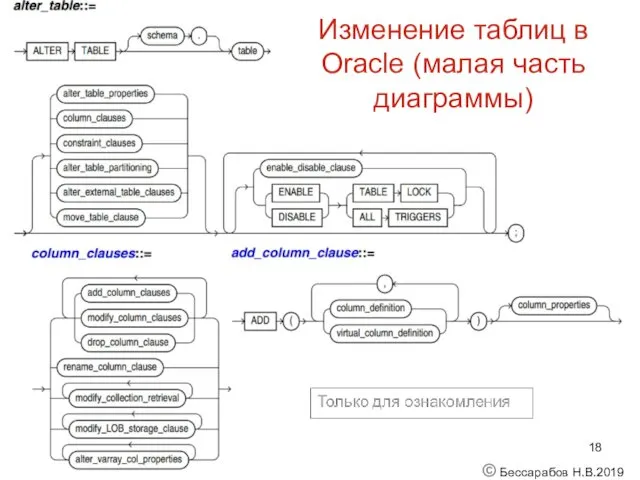
Изменение таблиц в Oracle (малая часть диаграммы)
© Бессарабов Н.В.2019
Изменение таблиц в Oracle (малая часть диаграммы)
© Бессарабов Н.В.2019

Языки DML и DCL. Манипулирование и управление данными
Манипулирование данными (DML):
INSERT -
Языки DML и DCL. Манипулирование и управление данными
Манипулирование данными (DML):
INSERT -

Инструкции DML
Новая строка вводится в таблицу инструкцией INSERT,
имеющей в простейшем
Инструкции DML
Новая строка вводится в таблицу инструкцией INSERT,
имеющей в простейшем

1.2. Запросы в SQL
© Бессарабов Н.В.2019
1.2. Запросы в SQL
© Бессарабов Н.В.2019

Язык SQL. Запрос в рамках TRC
Если оставаться строго в рамках исчисления
Язык SQL. Запрос в рамках TRC
Если оставаться строго в рамках исчисления

Язык SQL. Простейший запрос
А теперь как простой SELECT выглядит на
Язык SQL. Простейший запрос
А теперь как простой SELECT выглядит на

Выполнение однотабличного запроса
Запрос выполняется путём поочерёдного применения фраз,
образующих инструкцию:
По
Выполнение однотабличного запроса
Запрос выполняется путём поочерёдного применения фраз,
образующих инструкцию:
По

Сравнение запросов SQL и запросов в языке TRC (1/3)
Расширения языка запросов
Сравнение запросов SQL и запросов в языке TRC (1/3)
Расширения языка запросов

Сравнение запросов SQL и запросов в языке TRC (2/3)
Выражение CASE также
Сравнение запросов SQL и запросов в языке TRC (2/3)
Выражение CASE также

Сравнение запросов SQL и запросов в языке TRC (3/3)
4. Использование строк
Сравнение запросов SQL и запросов в языке TRC (3/3)
4. Использование строк
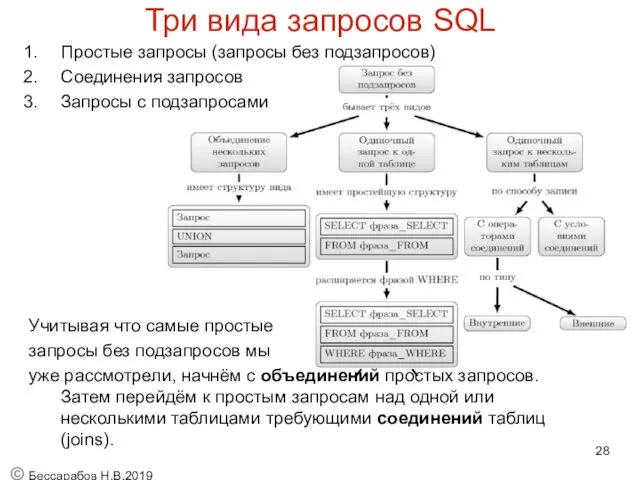
Три вида запросов SQL
Простые запросы (запросы без подзапросов)
Соединения запросов
Запросы с подзапросами
Учитывая
Три вида запросов SQL
Простые запросы (запросы без подзапросов)
Соединения запросов
Запросы с подзапросами
Учитывая

Соединение результатов запросов
Результаты нескольких запросов можно объединить операциями
UNION и UNION
Соединение результатов запросов
Результаты нескольких запросов можно объединить операциями
UNION и UNION

Соединения таблиц
Соединения двух и более таблиц могут выполняться в одном
запросе
Соединения таблиц
Соединения двух и более таблиц могут выполняться в одном
запросе

Внутренние и внешние соединения
В рассмотренном на предыдущем слайде примере и операциях
Внутренние и внешние соединения
В рассмотренном на предыдущем слайде примере и операциях

Внешние соединения
Для задания внешнего соединения до появления стандарта SQL92
во фразе WHERE
Внешние соединения
Для задания внешнего соединения до появления стандарта SQL92
во фразе WHERE

Выполнение внешних соединений
Порядок действий при выполнении полного внешнего
соединения двух
Выполнение внешних соединений
Порядок действий при выполнении полного внешнего
соединения двух
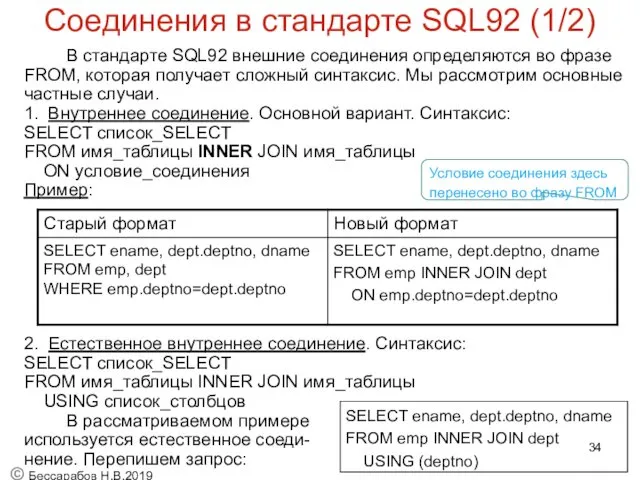
Соединения в стандарте SQL92 (1/2)
В стандарте SQL92 внешние соединения определяются во
Соединения в стандарте SQL92 (1/2)
В стандарте SQL92 внешние соединения определяются во

Соединения в стандарте SQL92 (2/2)
Внешние соединения – полное, левое, правое.
Синтаксис:
SELECT список_SELECT
FROM
Соединения в стандарте SQL92 (2/2)
Внешние соединения – полное, левое, правое.
Синтаксис:
SELECT список_SELECT
FROM

Запросы с группированием
Фраза GROUP BY, упоминавшаяся ранее, обеспечивает
объединение строк с
Запросы с группированием
Фраза GROUP BY, упоминавшаяся ранее, обеспечивает
объединение строк с

Выполнение запросов с группированием
Порядок действий при выполнении запросов с фразой GROUP
Выполнение запросов с группированием
Порядок действий при выполнении запросов с фразой GROUP

Отбор групп строк -- фраза HAVING
Фраза HAVING предназначена для организации отбора
Отбор групп строк -- фраза HAVING
Фраза HAVING предназначена для организации отбора

Выполнение запросов с фразой HAVING
Ограничения на условия отбора групп: Операндами в
Выполнение запросов с фразой HAVING
Ограничения на условия отбора групп: Операндами в

Подзапросы
Подзапрос - это инструкция SELECT, вложенная в другую
инструкцию SELECT для
Подзапросы
Подзапрос - это инструкция SELECT, вложенная в другую
инструкцию SELECT для

Однострочные подзапросы
Однострочный подзапрос возвращает ровно одну строку.
С однострочными подзапросами используются однострочные
Однострочные подзапросы
Однострочный подзапрос возвращает ровно одну строку.
С однострочными подзапросами используются однострочные

Многострочные подзапросы
Многострочный подзапрос может вернуть несколько строк.
Операторы сравнения для многострочных подзапросов:
Многострочные подзапросы
Многострочный подзапрос может вернуть несколько строк.
Операторы сравнения для многострочных подзапросов:

Примеры многострочных подзапросов
Многострочный подзапрос с оператором сравнения ANY:
SELECT empno, ename, job,
Примеры многострочных подзапросов
Многострочный подзапрос с оператором сравнения ANY:
SELECT empno, ename, job,
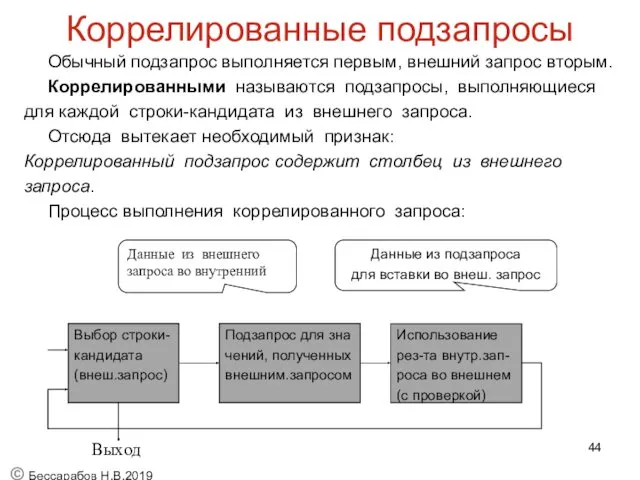
Коррелированные подзапросы
Обычный подзапрос выполняется первым, внешний запрос вторым.
Коррелированными называются подзапросы, выполняющиеся
Коррелированные подзапросы
Обычный подзапрос выполняется первым, внешний запрос вторым.
Коррелированными называются подзапросы, выполняющиеся

Пример коррелированного подзапроса
Найдите всех работников, которые получают зарплату выше
средней в
Пример коррелированного подзапроса
Найдите всех работников, которые получают зарплату выше
средней в

Иерархические структуры в таблицах
Уже упоминалось, что таблица может хранить дерево (лек.
Иерархические структуры в таблицах
Уже упоминалось, что таблица может хранить дерево (лек.
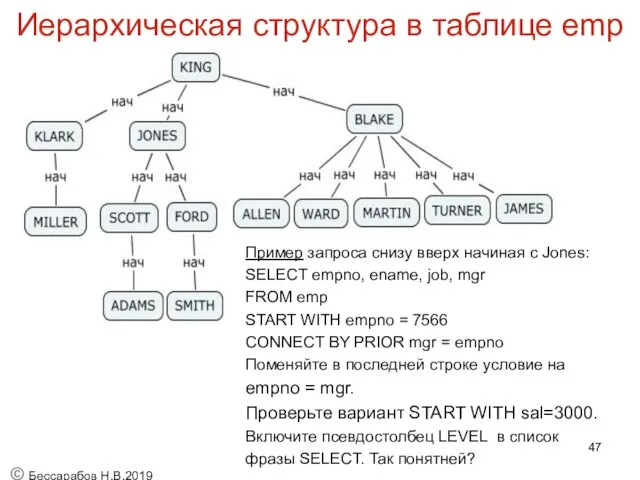
Иерархическая структура в таблице emp
В таблице emp хранится следующая иерархия:
Пример
Иерархическая структура в таблице emp
В таблице emp хранится следующая иерархия:
Пример

Примеры запросов к иерархиям
В запросе к EMP начинаем с президента
Примеры запросов к иерархиям
В запросе к EMP начинаем с президента

Храним деревья и сети в таблицах
В табличной базе для работы с
Храним деревья и сети в таблицах
В табличной базе для работы с
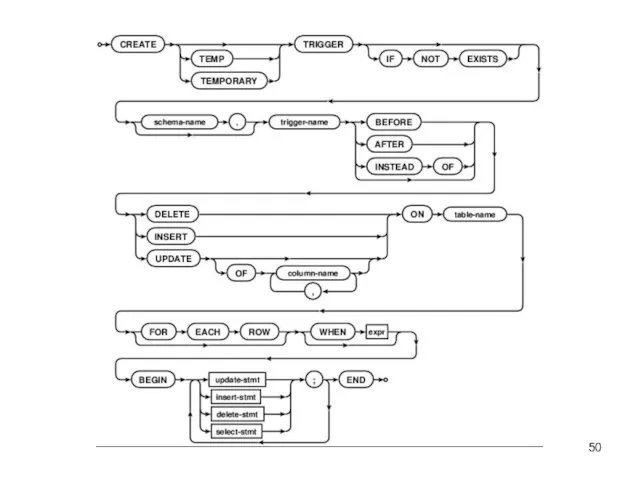

Что такое представление (VIEW)
Представления создаются инструкцией похожей на инструкцию
создания
Что такое представление (VIEW)
Представления создаются инструкцией похожей на инструкцию
создания
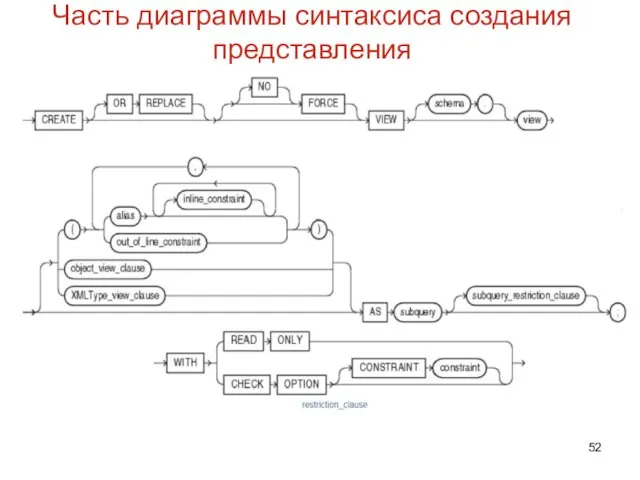
Часть диаграммы синтаксиса создания представления
Часть диаграммы синтаксиса создания представления

Опция WITH CHECK OPTION
Как уже упоминалось, применение операций INSERT, UPDATE
Опция WITH CHECK OPTION
Как уже упоминалось, применение операций INSERT, UPDATE
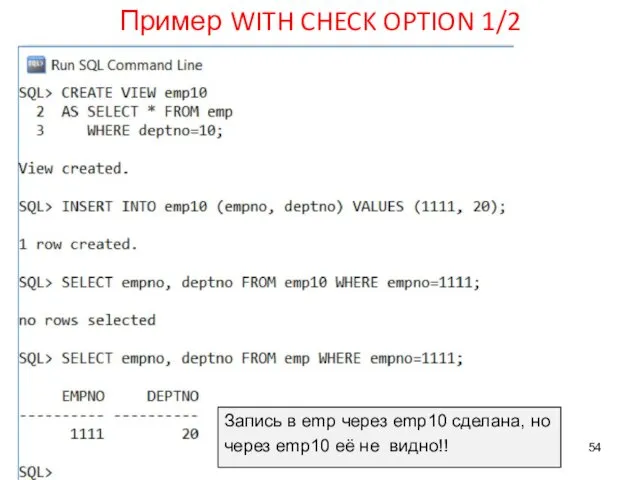
Пример WITH CHECK OPTION 1/2
Запись в emp через emp10 сделана,
Пример WITH CHECK OPTION 1/2
Запись в emp через emp10 сделана,
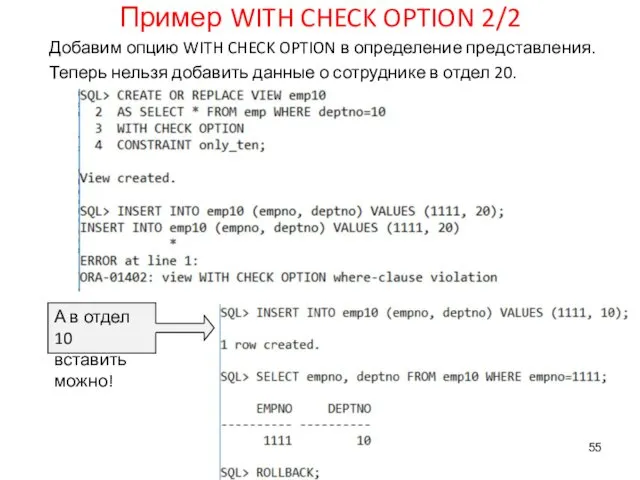
Пример WITH CHECK OPTION 2/2
Добавим опцию WITH CHECK OPTION в
Пример WITH CHECK OPTION 2/2
Добавим опцию WITH CHECK OPTION в

Встроенный SQL
Ограничения SQL можно преодолеть двумя способами:
встраивая SQL в
Встроенный SQL
Ограничения SQL можно преодолеть двумя способами:
встраивая SQL в

Встроенный SQL. Примеры
1. Для создания таблицы пишем программу
&sql(create table QQ (
Встроенный SQL. Примеры
1. Для создания таблицы пишем программу
&sql(create table QQ (

Непервая нормальная форма и регулярные выражения
Использование сложных структур в составе значения,
Непервая нормальная форма и регулярные выражения
Использование сложных структур в составе значения,

Где можно встретить регулярные выражения?
Почти везде! Простые варианты регулярных
Где можно встретить регулярные выражения?
Почти везде! Простые варианты регулярных

Регулярные выражения. Основные понятия
Задача, требующая замены или поиска фрагментов текста,
Регулярные выражения. Основные понятия
Задача, требующая замены или поиска фрагментов текста,

Специальные символы (метасимволы)
Метасимволы задают :
тип символов искомой строки;
способ окружения искомой
Специальные символы (метасимволы)
Метасимволы задают :
тип символов искомой строки;
способ окружения искомой

Символьные классы
Классы символов или скобочные выражения -- это сокращенные
именования
Символьные классы
Классы символов или скобочные выражения -- это сокращенные
именования
![Синтаксис функций REGEXP REGEXP_LIKE (исходная_строка, шаблон [, параметр_соответствия]) -- выбирает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1952/slide-62.jpg)
Синтаксис функций REGEXP
REGEXP_LIKE (исходная_строка, шаблон [, параметр_соответствия])
-- выбирает все
Синтаксис функций REGEXP
REGEXP_LIKE (исходная_строка, шаблон [, параметр_соответствия])
-- выбирает все

Синтаксис функции REGEXP_SUBSTR
REGEXP_SUBSTR находит соответствие указанной части
обрабатываемой строки. Синтаксис:
REGEXP_SUBSTR
Синтаксис функции REGEXP_SUBSTR
REGEXP_SUBSTR находит соответствие указанной части
обрабатываемой строки. Синтаксис:
REGEXP_SUBSTR

Примеры использования функций REGEXP в Oracle
'^Ste(v|ph)en$' :
^ указывает на начало
Примеры использования функций REGEXP в Oracle
'^Ste(v|ph)en$' :
^ указывает на начало

II. Язык QBE (Query-by-example)
© Бессарабов Н.В.2019
II. Язык QBE (Query-by-example)
© Бессарабов Н.В.2019

Язык QBE
QBE (Query-By-Example) – язык исчисления с переменными на
Язык QBE
QBE (Query-By-Example) – язык исчисления с переменными на

Изобразительные средства QBE (1/2)
Исходное изображение – прямоугольник (рис.1), в котором
пользователь
Изобразительные средства QBE (1/2)
Исходное изображение – прямоугольник (рис.1), в котором
пользователь

Изобразительные средства QBE (2/2)
Что можно записать в нижней строке?
Один из ограниченного
Изобразительные средства QBE (2/2)
Что можно записать в нижней строке?
Один из ограниченного

Основы QBE (1/5)
Часть языка, связанную с запросами, следуя основополагающей
работе М.Злуфа,
Основы QBE (1/5)
Часть языка, связанную с запросами, следуя основополагающей
работе М.Злуфа,

Основы QBE (2/5)
Если же таблица существует,
появится ее схема:
В нижней строке
Основы QBE (2/5)
Если же таблица существует,
появится ее схема:
В нижней строке
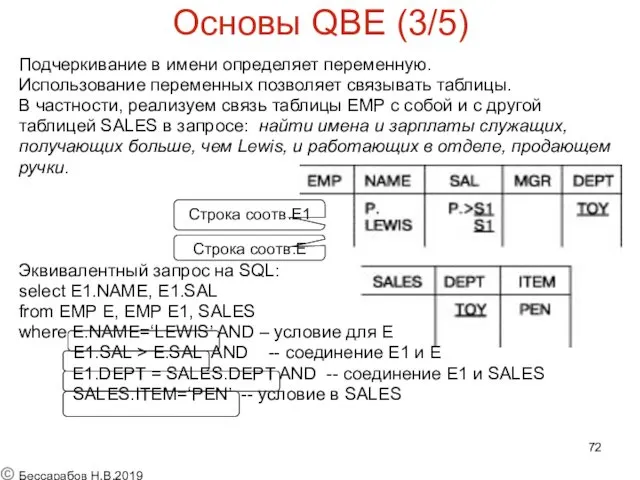
Основы QBE (3/5)
Подчеркивание в имени определяет переменную.
Использование переменных позволяет связывать
Основы QBE (3/5)
Подчеркивание в имени определяет переменную.
Использование переменных позволяет связывать

Основы QBE (4/5)
В записи условия выбора можно работать с шаблонами.
Для этого
Основы QBE (4/5)
В записи условия выбора можно работать с шаблонами.
Для этого

Основы QBE (5/5)
В QBE можно организовывать запросы в логике второго порядка.
Основы QBE (5/5)
В QBE можно организовывать запросы в логике второго порядка.

Выборка с использованием блока условий
В Query-by-Example существует два двухмерных
Выборка с использованием блока условий
В Query-by-Example существует два двухмерных
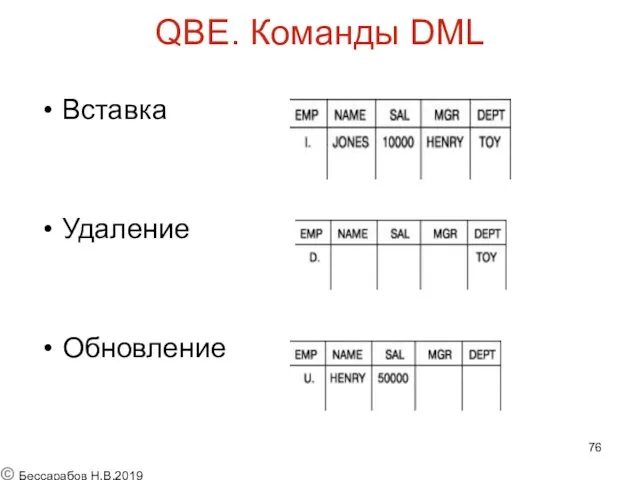
QBE. Команды DML
Вставка
Удаление
Обновление
© Бессарабов Н.В.2019
QBE. Команды DML
Вставка
Удаление
Обновление
© Бессарабов Н.В.2019
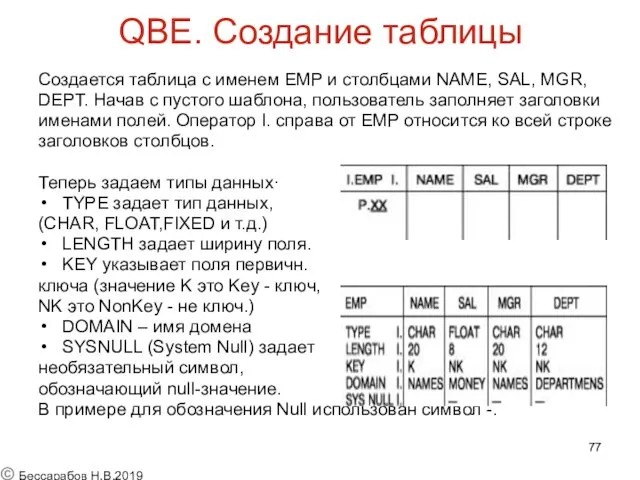
QBE. Создание таблицы
Создается таблица с именем EMP и столбцами NAME,
QBE. Создание таблицы
Создается таблица с именем EMP и столбцами NAME,

Ограниченность QBE
Возможно, вы заметили, что QBE в представленной версии
существенно уже
Ограниченность QBE
Возможно, вы заметили, что QBE в представленной версии
существенно уже
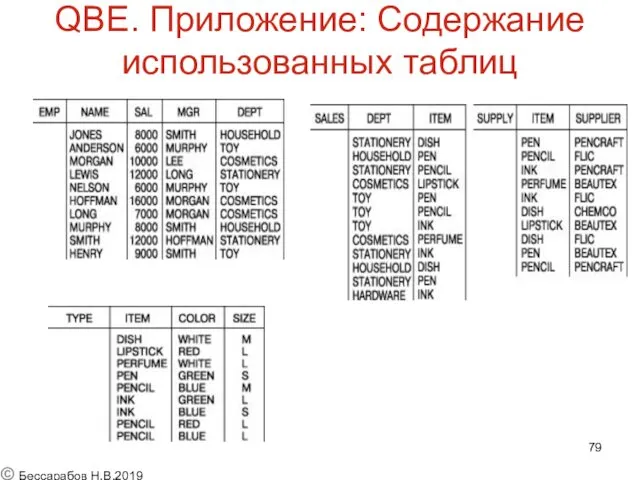
QBE. Приложение: Содержание использованных таблиц
© Бессарабов Н.В.2019
QBE. Приложение: Содержание использованных таблиц
© Бессарабов Н.В.2019
 Аватария
Аватария Основы безопасности жизнедеятельности в сети Интернет
Основы безопасности жизнедеятельности в сети Интернет Создание элементов управления и гипертекстовых ссылок в MS PowerPoint
Создание элементов управления и гипертекстовых ссылок в MS PowerPoint Основы хранения, обработки и управления данными предприятия. Лекция 4
Основы хранения, обработки и управления данными предприятия. Лекция 4 Розробка бази даних фермерського господарства
Розробка бази даних фермерського господарства Управление периодической печати, книгоиздания и полиграфии
Управление периодической печати, книгоиздания и полиграфии Introduction to HFSS
Introduction to HFSS Как образуются понятия
Как образуются понятия Код Хэмминга. Пример работы алгоритма
Код Хэмминга. Пример работы алгоритма Устройство компьютера и периферийное оборудование
Устройство компьютера и периферийное оборудование Виды мониторов, их характеристики
Виды мониторов, их характеристики Назначение и общая классификация CAD/CAM/CAE-систем
Назначение и общая классификация CAD/CAM/CAE-систем Растровая и векторная графика
Растровая и векторная графика Информатика и информатизация общества
Информатика и информатизация общества Методика структурного анализа потоков данных DFD (Data Flow Diagrams)
Методика структурного анализа потоков данных DFD (Data Flow Diagrams) Зарубежные библиографические и полнотекстовые электронные ресурсы, доступные в СПбГАСУ
Зарубежные библиографические и полнотекстовые электронные ресурсы, доступные в СПбГАСУ Системы счисления (§7-11). 10 класс
Системы счисления (§7-11). 10 класс Основы журналистики. Журналистика и СМИ
Основы журналистики. Журналистика и СМИ Interfaces of the microcontrollers
Interfaces of the microcontrollers Журналистика: что это такое и зачем она нужна
Журналистика: что это такое и зачем она нужна Телевидение в системе СМИ
Телевидение в системе СМИ Методы искусственного интеллекта
Методы искусственного интеллекта Искусственный интеллект способен на всё, что делает человек
Искусственный интеллект способен на всё, что делает человек 3D-панорама
3D-панорама Основные понятия алгебры логики. Логические операции
Основные понятия алгебры логики. Логические операции Типы алгоритмов. Алгоритмы с ветвлениями
Типы алгоритмов. Алгоритмы с ветвлениями Знакомство с электронными таблицами Calc
Знакомство с электронными таблицами Calc Восприятие игрового окружения
Восприятие игрового окружения