- Анализ выбросов. Диаграммы размахов

Содержание
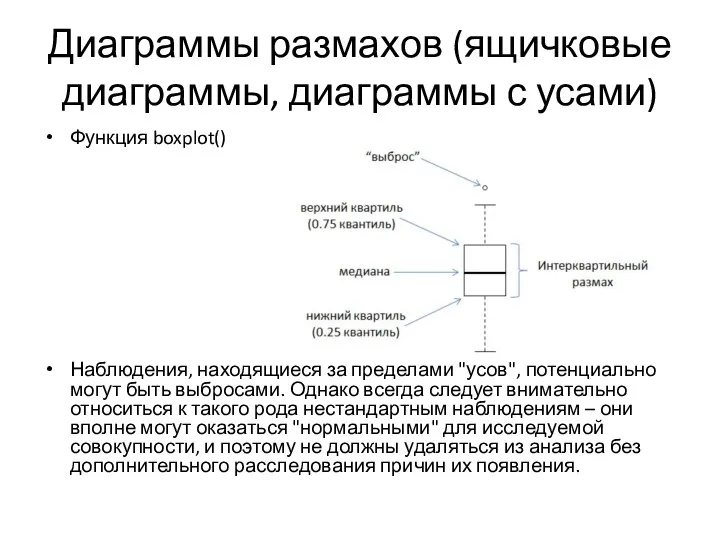
- 2. Диаграммы размахов (ящичковые диаграммы, диаграммы с усами) Функция boxplot() Наблюдения, находящиеся за пределами "усов", потенциально могут
- 3. Применение boxplot() Рассмотрим данные, полученные в ходе эксперимента по изучению эффективности шести видов инсектицидных средств. Каждым
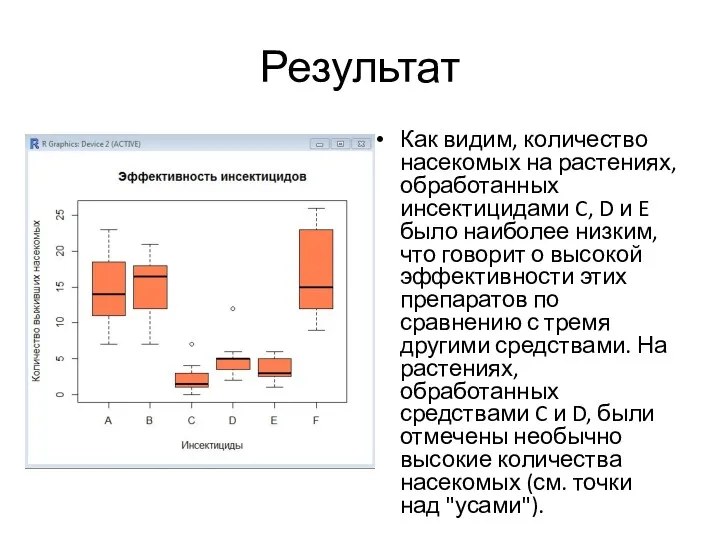
- 4. Результат Как видим, количество насекомых на растениях, обработанных инсектицидами C, D и E было наиболее низким,
- 5. Диаграммы Кливленда Точечные диаграммы Кливленда представляют собой графики, на которых точки используются для отображения значений некоторой
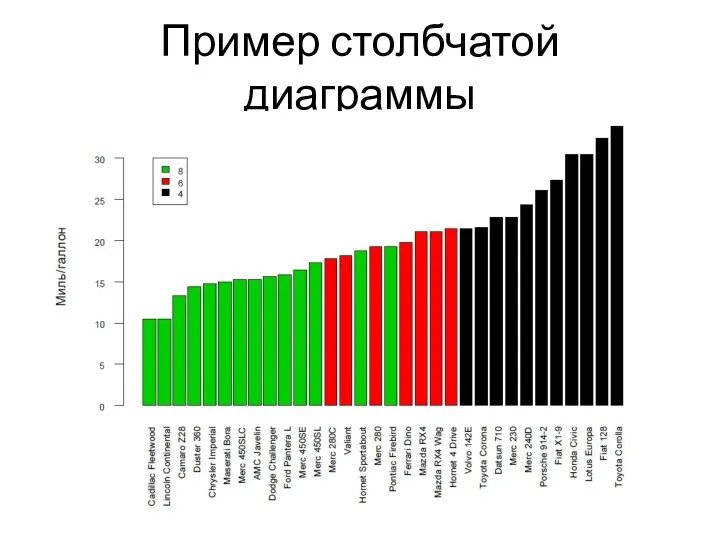
- 6. Пример столбчатой диаграммы
- 7. Точечная диаграмма dotchart(mtcars$mpg, labels = row.names(mtcars), main="Экономия топлива у 32 моделей автомобилей", xlab="Миль/галлон", cex = 0.8)
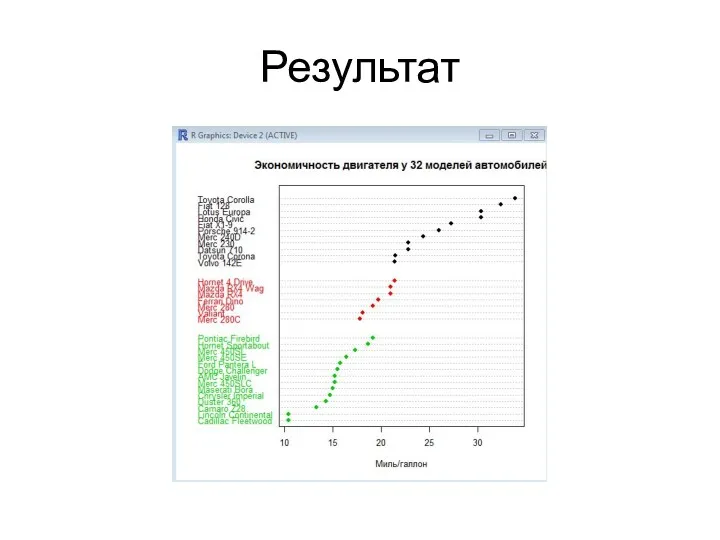
- 8. Результат Картина станет гораздо более ясной, если мы отсортируем данные по возрастанию пробега, сгруппируем данные по
- 9. Подготовка данных Отсортируем исходную таблицу по возрастанию mpg с использованием функции order()) и сохраним результат в
- 10. Результат
- 11. Выбросы Под "выбросом" мы будем понимать наблюдение, которое "слишком" велико или "слишком" мало по сравнению с
- 12. Диаграмма Кливленда распределения длин крыла воробьев
- 13. Интерпретация результатов На рисунке хорошо выделяется точка, соответствующая длине крыла 68 мм. Однако это значение длины
- 14. Поиск выбросов с помощью диаграммы размаха > set.seed(3147) > x > summary(x) Min. 1st Qu. Median
- 15. Поиск выбросов с помощью диаграммы размаха > y > df > rm(x, y) > head(df) x
- 16. Поиск выбросов с помощью диаграммы размаха > attach(df) > # find the index of outliers from
- 17. Результат
- 18. Поиск выбросов > # outliers in either x or y > (outlier.list2 [1] 1 33 64
- 19. Удаление выбросов Более строгий подход к определению выбросов состоит в оценке того, какое влияние эти необычные
- 20. Нормализующее преобразование Альтернативой удалению необычных значений предиктора является нормализующее преобразование (чаще всего, логарифмирование). В общем случае,
- 21. Пример Проанализируем уровень зараженности двустворчатого моллюска Dreissena polymorpha инфузорией Conchophthirus acuminatus в трех озерах Беларуси. Данные
- 22. Пример Моллюски read.table("http://figshare.com/media/download/98923/97987", header=TRUE, sep="\t", strip.white=TRUE) library(car) # Поиск максимума функции правдоподобия и построение графика #
- 23. Оптимальное значение λ = 0.182
- 24. Эффект преобразования CAnumber по методу Бокса-Кокса После БК-преобразования распределение значений CAnumber приблизилось к нормальному, в связи
- 26. Скачать презентацию
Диаграммы размахов (ящичковые диаграммы, диаграммы с усами)
Функция boxplot()
Наблюдения, находящиеся за пределами
Диаграммы размахов (ящичковые диаграммы, диаграммы с усами)
Функция boxplot()
Наблюдения, находящиеся за пределами

Применение boxplot()
Рассмотрим данные, полученные в ходе эксперимента по изучению эффективности шести
Применение boxplot()
Рассмотрим данные, полученные в ходе эксперимента по изучению эффективности шести
Результат
Как видим, количество насекомых на растениях, обработанных инсектицидами C, D и
Результат
Как видим, количество насекомых на растениях, обработанных инсектицидами C, D и

Диаграммы Кливленда
Точечные диаграммы Кливленда представляют собой графики, на которых точки используются
Диаграммы Кливленда
Точечные диаграммы Кливленда представляют собой графики, на которых точки используются
Пример столбчатой диаграммы
Пример столбчатой диаграммы

Точечная диаграмма
dotchart(mtcars$mpg, labels = row.names(mtcars), main="Экономия топлива у 32 моделей автомобилей",
Точечная диаграмма
dotchart(mtcars$mpg, labels = row.names(mtcars), main="Экономия топлива у 32 моделей автомобилей",

Результат
Картина станет гораздо более ясной, если мы отсортируем данные по возрастанию
Результат
Картина станет гораздо более ясной, если мы отсортируем данные по возрастанию

Подготовка данных
Отсортируем исходную таблицу по возрастанию mpg с использованием функции order())
Подготовка данных
Отсортируем исходную таблицу по возрастанию mpg с использованием функции order())
Результат
Результат

Выбросы
Под "выбросом" мы будем понимать наблюдение, которое "слишком" велико или "слишком"
Выбросы
Под "выбросом" мы будем понимать наблюдение, которое "слишком" велико или "слишком"
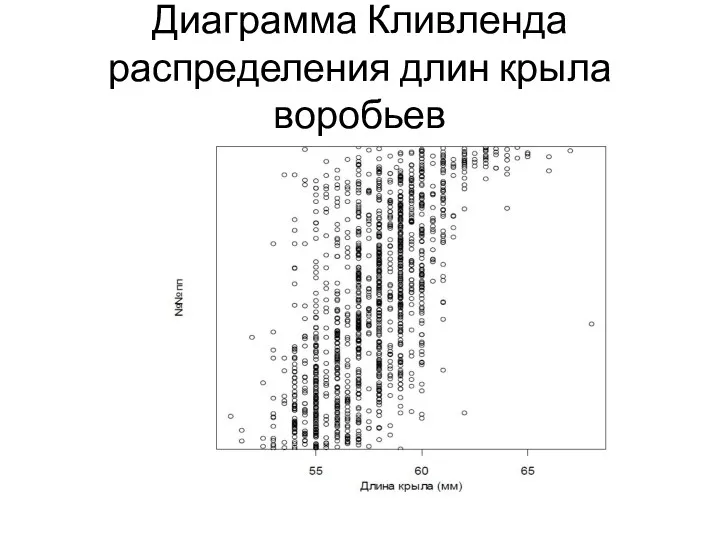
Диаграмма Кливленда распределения длин крыла воробьев
Диаграмма Кливленда распределения длин крыла воробьев

Интерпретация результатов
На рисунке хорошо выделяется точка, соответствующая длине крыла 68 мм.
Интерпретация результатов
На рисунке хорошо выделяется точка, соответствующая длине крыла 68 мм.

Поиск выбросов с помощью диаграммы размаха
> set.seed(3147)
> x <- rnorm(100)
> summary(x)
Min.
Поиск выбросов с помощью диаграммы размаха
> set.seed(3147)
> x <- rnorm(100)
> summary(x)
Min.

Поиск выбросов с помощью диаграммы размаха
> y <- rnorm(100)
> df <-
Поиск выбросов с помощью диаграммы размаха
> y <- rnorm(100)
> df <-

Поиск выбросов с помощью диаграммы размаха
> attach(df)
> # find the index
Поиск выбросов с помощью диаграммы размаха
> attach(df)
> # find the index
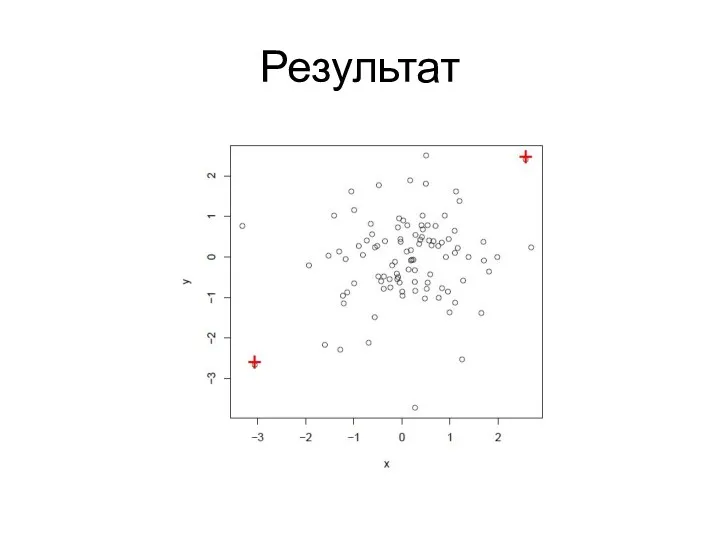
Результат
Результат
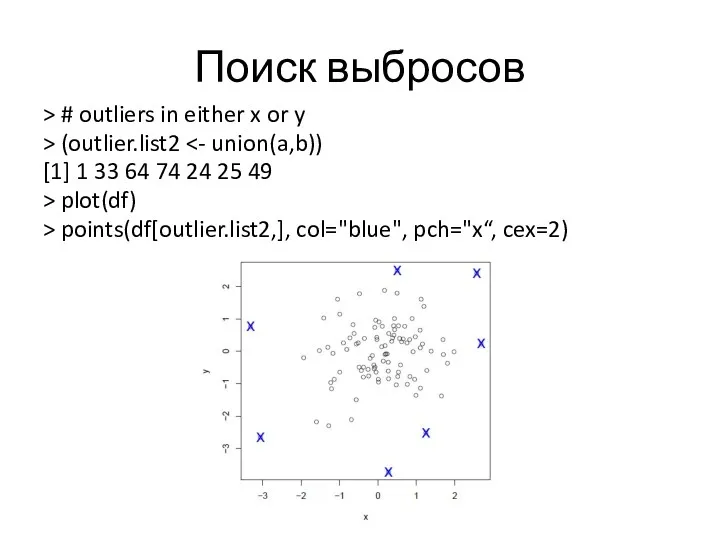
Поиск выбросов
> # outliers in either x or y
> (outlier.list2 <-
Поиск выбросов
> # outliers in either x or y
> (outlier.list2 <-

Удаление выбросов
Более строгий подход к определению выбросов состоит в оценке того,
Удаление выбросов
Более строгий подход к определению выбросов состоит в оценке того,

Нормализующее преобразование
Альтернативой удалению необычных значений предиктора является нормализующее преобразование (чаще всего,
Нормализующее преобразование
Альтернативой удалению необычных значений предиктора является нормализующее преобразование (чаще всего,

Пример
Проанализируем уровень зараженности двустворчатого моллюска Dreissena polymorpha инфузорией Conchophthirus acuminatus в
Пример
Проанализируем уровень зараженности двустворчатого моллюска Dreissena polymorpha инфузорией Conchophthirus acuminatus в

Пример
Моллюски <-
read.table("http://figshare.com/media/download/98923/97987",
header=TRUE, sep="\t", strip.white=TRUE)
library(car)
# Поиск максимума функции правдоподобия и построение
Пример
Моллюски <-
read.table("http://figshare.com/media/download/98923/97987",
header=TRUE, sep="\t", strip.white=TRUE)
library(car)
# Поиск максимума функции правдоподобия и построение
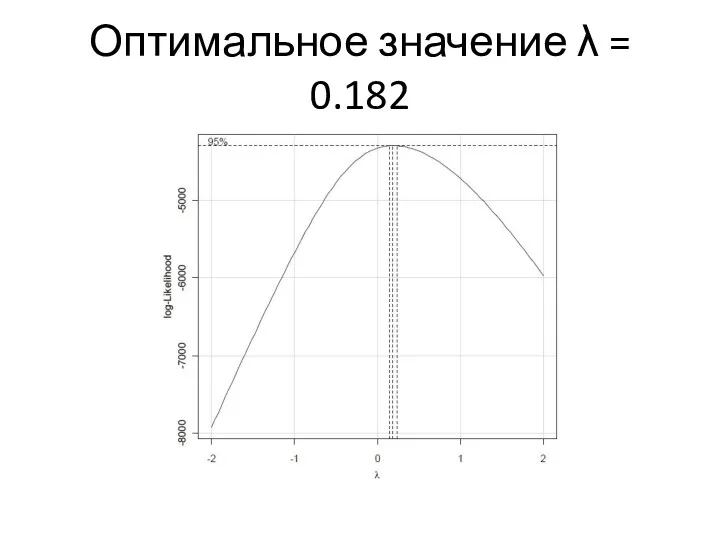
Оптимальное значение λ = 0.182
Оптимальное значение λ = 0.182
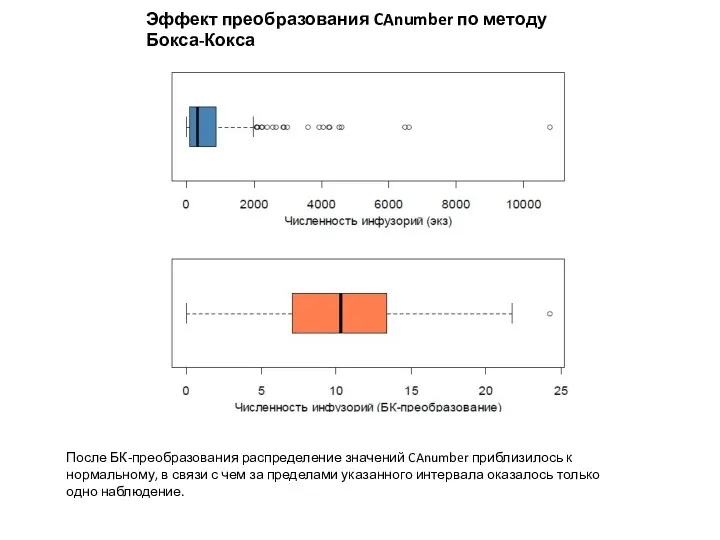
Эффект преобразования CAnumber по методу Бокса-Кокса
После БК-преобразования распределение значений CAnumber приблизилось
Эффект преобразования CAnumber по методу Бокса-Кокса
После БК-преобразования распределение значений CAnumber приблизилось
 Решение задач оптимизации методом ветвей и границ
Решение задач оптимизации методом ветвей и границ Признаки делимости на 10, на 5, на 2
Признаки делимости на 10, на 5, на 2 Применение технологии проблемного обучения на уроках математики (из опыта работы)
Применение технологии проблемного обучения на уроках математики (из опыта работы) Название чисел в записи действий
Название чисел в записи действий Умножение положительных и отрицательных чисел
Умножение положительных и отрицательных чисел Множественная линейная регрессия
Множественная линейная регрессия Решение квадратных уравнений
Решение квадратных уравнений Закрепление. Деление суммы на число. Решение задач. 3 класс
Закрепление. Деление суммы на число. Решение задач. 3 класс Корреляция. Корреляционная связь
Корреляция. Корреляционная связь Занимательная математика. Устный счёт- гимнастика ума
Занимательная математика. Устный счёт- гимнастика ума Проектируем сад
Проектируем сад Кроссворд Пифагор
Кроссворд Пифагор Математика 3 класс Задачи на кратное сравнение
Математика 3 класс Задачи на кратное сравнение введение вероятностно-статестической линиии в школьный курс математики 5 - 6 классов
введение вероятностно-статестической линиии в школьный курс математики 5 - 6 классов Системы линейных уравнений
Системы линейных уравнений Функция и способы ее задания
Функция и способы ее задания Логарифмическая функция
Логарифмическая функция Предел функции
Предел функции Деление десятичных дробей на натуральные числа
Деление десятичных дробей на натуральные числа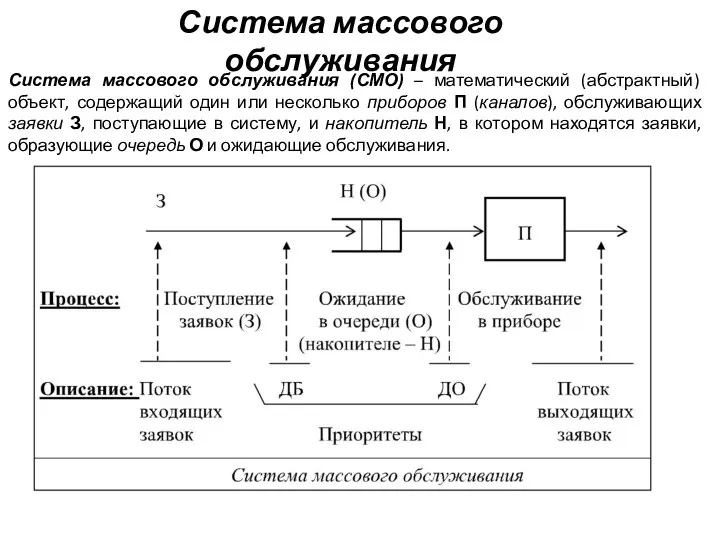 Система массового обслуживания (СМО)
Система массового обслуживания (СМО) Принцип Дирихле
Принцип Дирихле Решение задач и выражений. Закрепление вычислительных навыков
Решение задач и выражений. Закрепление вычислительных навыков Тема урока : Деление на 3
Тема урока : Деление на 3 Прямые. Взаимное расположение прямых в пространстве. Признак скрещивающихся прямых
Прямые. Взаимное расположение прямых в пространстве. Признак скрещивающихся прямых Задачи по геометрии
Задачи по геометрии Квадрат суммы трёх чисел
Квадрат суммы трёх чисел Mathcad жүйесінде алгебралық теңдеулерді шешу
Mathcad жүйесінде алгебралық теңдеулерді шешу Необычный урок математики. Паралимпийские игры
Необычный урок математики. Паралимпийские игры