- Элементы теории вероятностей. Элементы математической статистики

Содержание
- 2. Основные комбинаторные конфигурации. Для формулировки и решения комбинаторных задач используют различные модели комбинаторных конфигураций. Примерами комбинаторных
- 3. Примеры комбинаторных задач: Сколькими способами можно разместить n предметов по m ящикам, чтобы выполнялись заданные ограничения?
- 4. Распределение данных по частотам Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений). Математически
- 5. Распределение данных по частотам Пример распределения частот (абсолютное): прогноз возрастного распределения в Германии в 2050 году.
- 6. Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём совокупности, основные виды выборок. В
- 7. Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём совокупности, основные виды выборок. Медиана
- 8. Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём совокупности, основные виды выборок.
- 9. Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём совокупности, основные виды выборок. Одной
- 10. Практическое занятие: решение задач на оценку неизвестных параметров случайной величины
- 12. Скачать презентацию

Основные комбинаторные конфигурации.
Для формулировки и решения комбинаторных задач используют различные модели комбинаторных
Основные комбинаторные конфигурации.
Для формулировки и решения комбинаторных задач используют различные модели комбинаторных

Примеры комбинаторных задач:
Сколькими способами можно разместить n предметов по m ящикам, чтобы выполнялись заданные ограничения?
Сколько существует
Примеры комбинаторных задач:
Сколькими способами можно разместить n предметов по m ящикам, чтобы выполнялись заданные ограничения?
Сколько существует

Распределение данных по частотам
Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений).
Распределение данных по частотам
Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений).

Распределение данных по частотам
Пример распределения частот (абсолютное): прогноз возрастного распределения в
Распределение данных по частотам
Пример распределения частот (абсолютное): прогноз возрастного распределения в

Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём
Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём

Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём
Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём
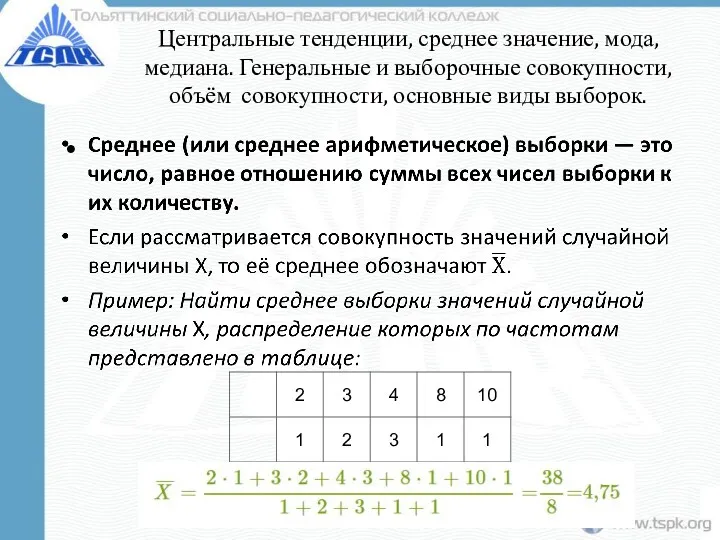
Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём
Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём

Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём
Центральные тенденции, среднее значение, мода, медиана. Генеральные и выборочные совокупности, объём

Практическое занятие:
решение задач на оценку неизвестных параметров случайной величины
Практическое занятие:
решение задач на оценку неизвестных параметров случайной величины
 Интерактивный тренажер Парашютисты
Интерактивный тренажер Парашютисты Параллельные прямые
Параллельные прямые Информационное моделирование. Математические модели
Информационное моделирование. Математические модели Таблица истинности
Таблица истинности Умножение числа 2
Умножение числа 2 Теория вероятностей. События. Виды событий. Вероятностное пространство. Вероятностные схемы: классическая, геометрическая
Теория вероятностей. События. Виды событий. Вероятностное пространство. Вероятностные схемы: классическая, геометрическая Презентация к уроку математики по теме Симметрия
Презентация к уроку математики по теме Симметрия Понятие соответствия. Понятие отображения
Понятие соответствия. Понятие отображения Решение логарифмических уравнений
Решение логарифмических уравнений Плоскость в пространстве
Плоскость в пространстве Решение текстовых задач в 1 классе.
Решение текстовых задач в 1 классе. Зв’язаність графів. Шляхи, цикли ізоморфізм
Зв’язаність графів. Шляхи, цикли ізоморфізм Повторення матеріалу вивченого за курс 5 класу
Повторення матеріалу вивченого за курс 5 класу Математический досуг
Математический досуг Урок математики в 1 классе тема: Число 10 и один десяток. умк ПНШ
Урок математики в 1 классе тема: Число 10 и один десяток. умк ПНШ Вписанные и описанные окружности
Вписанные и описанные окружности Mathematics and visual arts
Mathematics and visual arts Система подготовки учащихся к ОГЭ по математике
Система подготовки учащихся к ОГЭ по математике Математическая раскраска
Математическая раскраска Практика по темам Последовательность и Арифметическая прогрессия
Практика по темам Последовательность и Арифметическая прогрессия Логические основы ЭВМ. Алгоритмы логики. Построение таблиц истинности
Логические основы ЭВМ. Алгоритмы логики. Построение таблиц истинности Урок – путешествие по математике с применением ИКТ Закрепление изученных приёмов письменного сложения и вычитания в пределах 100
Урок – путешествие по математике с применением ИКТ Закрепление изученных приёмов письменного сложения и вычитания в пределах 100 Маршрутизация перевозок грузов. Модель транспортной сети
Маршрутизация перевозок грузов. Модель транспортной сети Теорема Ербрана. (Лекция 4)
Теорема Ербрана. (Лекция 4) Теоремы об углах, образованных двумя параллельными
Теоремы об углах, образованных двумя параллельными Пример решения транспортной задачи (открытая модель)
Пример решения транспортной задачи (открытая модель) Числовая последовательность. Арифметическая прогрессия
Числовая последовательность. Арифметическая прогрессия Натуральные числа. Делимость натуральных чисел. Действительные числа
Натуральные числа. Делимость натуральных чисел. Действительные числа