- Математические методы в психологии

Содержание
- 2. Рекомендуемая литература Наследов, А.Д. Математические методы психологического исследования. Анализ и интерпретация данных. – СПб. : Речь,
- 3. Тема 1. Измерение в психологии Предмет и назначение дисциплины Измерение в психологии. Взаимоотношение параметров, признаков, показателей
- 4. Определение статистики Термин «статистика» имеет несколько значений: ∙ это совокупность данных и сведений, посвященных какому-либо вопросу,
- 5. Соотношение обыденного и научного познания
- 6. Связь «Математических методов в психологии» с другими дисциплинами
- 7. Понятие переменных в психологии, их виды Признаки и переменные - это измеряемые психологические явления
- 8. Измерение — это приписывание объекту числа по определенному правилу. Это правило устанавливает соответствие между измеряемым свойством
- 9. Сводка характеристик и примеры измерительных шкал
- 10. Типы данных
- 11. Наглядное представление данных
- 12. Графическое представление данных В самом общем виде диаграммы делятся на: 1. Столбиковые: Вертикальные; Горизонтальные; 2. Линейные
- 13. Правила графического оформления Вся структура графика предполагает его чтение слева направо, вертикальные шкалы — снизу вверх.
- 14. Правила табличного представления первичных данных Вся структура таблицы предполагает ее чтение слева направо. В первом столбце
- 15. Тема 3. Способы представления данных в психологии Представление данных. Понятие о квантилях. Понятие о рангах. Процедура
- 16. Представление данных в психологии бывает в виде: Массив данных – первичные результаты измерения искомых параметров сводятся
- 17. Варианты представления данных
- 18. Меры положения – квантили Квантиль — это точка на числовой оси измеренного признака, которая делит всю
- 19. Нахождение процентиля Р-й процентиль представляет собой точку, ниже которой лежит Р % процентов всех наблюдений. Формула
- 20. Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов. В качестве оценки теста выбиралось
- 21. Ранговый порядок Ранжирование – это приписывание объектам чисел в зависимости от степени выраженности измеряемого свойства Установите
- 22. Ранжирование данных Ранжирование связанных рангов
- 23. Распределение частот Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько раз встречается каждое значение
- 24. Таблица распределения частот Абсолютная и относительная частоты связаны соотношением: где fa — абсолютная частота некоторого значения
- 25. Табулирование данных - это методы и способы построения таблиц Таблица 1 – Результаты исследования младших школьников
- 26. Этапы построения распределения сгруппированных частот Уточнение лимитов (крайних значений интервала) – производится округление лимитов - min
- 27. Графическое представление Гистограмма – это последовательность столбцов, каждый из которых опирается на один раздельный интервал, а
- 29. Тема 4. Меры центральной тенденции Определение меры центральной тенденции; Мода; Медиана; Среднее; Выбор и особенности мер
- 30. Меры центральной тенденции - предназначены для замены множества значений признака, измеренного на выборке, одним числом и
- 31. Мода (Mode) — это такое значение из множества измерений, которое встречается наиболее часто. Если все значения
- 32. Медиана (Median) — это такое значение признака, которое делит упорядоченное множество данных пополам так, что одна
- 33. Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как сумма всех значений измеренного признака,
- 34. Выбор и особенности мер центральной тенденции Для номинативных данных единственной подходящей мерой центральной тенденции является мода.
- 35. Графическое соотношение среднего, моды, медианы
- 36. Сравнение преимуществ и ограничений мер центральной тенденции
- 37. Тема 5. Меры изменчивости Понятие меры изменчивости Лимиты. Размах вариации и его разновидности. Дисперсия и ее
- 38. Меры изменчивости
- 39. Меры рассеяния независящие от распределения Лимиты – это характеристики, определяющие верхнюю (max) и нижнюю (min) границы
- 40. Меры рассеяния характеризующие нормальное распределение Дисперсия (Variance) — мера изменчивости для метрических данных, пропорциональная сумме квадратов
- 41. Расчет дисперсии
- 42. Меры рассеяния характеризующие нормальное распределение Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) — положительное значение квадратного
- 43. Меры формы Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида относительно среднего значения:
- 44. Тема 6. Стандартизация данных Понятие стандартизации данных. Основные формы стандартизации. z-преобразование данных.
- 45. Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры и оценок теста. Различают две
- 46. Преобразование первичных оценок в новую шкалу Центрирование – это линейная трансформация величин признака, при котором средняя
- 47. Пример преобразования в z-значения, Т-баллы
- 48. Тема 7. Теоретические распределения, используемые при статистических выводах Нормальное распределение Единичное нормальное распределение и его свойства
- 49. Виды распределения данных
- 50. Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего встречаются средние значения соответствующих показателей,
- 51. Единичное нормальное распределение и его свойства Если применить z-преобразование ко всем возможным измерениям свойств, все многообразие
- 52. Свойства единичного нормального распределения □ Единицей измерения единичного нормального распределения является стандартное отклонение. □ Кривая приближается
- 53. Соответствия между диапазонами значений и площадью под кривой М± σ соответствует ≈ 68% (точно — 68,26%)
- 54. Проверка нормальности распределения 1. Нормальность распределения результативного признака можно проверить путем расчета показателей асимметрии и эксцесса
- 55. 2. Еще одним из критериев проверки на нормальность - является критерий Колмагорова-Смирнова. Он позволяет оценить вероятность
- 56. Биноминальное распределение Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень вероятности. Оно отражает распределение
- 57. Распределение Пуассона Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в отдельных случаях мала, но
- 58. Тема 8. Статистическое оценивание и проверка гипотез Понятие генеральной совокупности и выборки Виды вероятностной выборки Зависимые
- 59. Этапы статистического вывода
- 60. Понятие генеральной совокупности и выборки Генеральной совокупностью – называется всякая большая (конечная или бесконечная) коллекция или
- 61. Виды вероятностной выборки Случайная выборка – сформированная на основе случайного отбора. Минус случайной выборки: отобранная часть
- 62. Зависимые и независимые выборки Независимые выборки характеризуются тем, что вероятность отбора любого испытуемого одной выборки не
- 63. Объем выборки – определяется численностью входящих в нее элементов. Объем выборки зависит от целей и методов
- 64. Гипотеза – это утверждение, истинность или ложность которого неизвестны, но могут быть проверены опытным путем Статистическая
- 65. Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как H0 и называется нулевой потому,
- 66. Статистический критерий Статистический критерий – это решающее правило, обеспечивающее надежное поведение, т.е. принятие истинной и отклонение
- 68. Основание выбора критерия а) в какой шкале представлены признаки; б) мощность критерия в) применимость по отношению
- 69. Степень свободы Число степеней свободы – это количество возможных направлений изменчивости признака. Это характеристика распределения, используемая
- 70. Показатели степеней свободы для зависимых и независимых выборок Если имеются две независимые выборки, то число степеней
- 71. Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level), — основной результат проверки статистической гипотезы,
- 72. Схема определения р – уровня Свойства статистической значимости Чем меньше значение р-уровня, тем выше статистическая значимость
- 73. Статистический вывод — это формулирование вывода на основе статистической значимости. Статистический вывод — это рассуждение от
- 74. Ошибки 1 и 2 рода Ошибка I рода - ошибка, состоящая в том, что мы отклонили
- 75. Алгоритм проверки статистических гипотез Обоснование применения критерия. Выполнение ограничений (если есть). Формулирование статистических гипотез (Н0 и
- 76. Тема 9. Меры связи Понятие корреляции. Диаграмма рассеяния. Классификация коэффициентов корреляции. Корреляционные матрицы. Интерпретация коэффициентов корреляции.
- 77. Понятие корреляции и ее основные параметры Корреляционная связь – это согласованное изменение двух или более признаков.
- 78. Сила связи достигает максимума при условии взаимно однозначного соответствия: когда каждому значению одной переменной соответствует только
- 79. Формулировка статистических гипотез Н0: Корреляция между переменными не отличается от нуля. Н1: Корреляция между переменными отличается
- 80. Виды связей Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически изображаются в виде
- 81. Примеры графиков часто встречающихся функций
- 82. Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а каждый испытуемый представляет собой точку
- 83. Классификация мер связи При r ≤ 0.3 (слабая связь), 0,3 0,7 (сильная связь)
- 84. Алгоритм выбора коэффициента корреляции
- 86. Представление данных корреляционного анализа Построение корреляционных матриц и их анализ 1 вид - Квадратная матрица 2
- 87. Графическое представление данных корреляционного анализа Поле рассеяния и Корреляционные плеяды
- 88. Классификация мер связи
- 89. Коэффициент корреляции rxy- Пирсона Коэффициент был создан Карлом (Чарлзом) Пирсоном (англ. Karl (Charles) Pearson), выдающимся английским
- 90. Основные положения r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических переменных, измеренных на одной и
- 91. Нахождение коэффициента корреляции rxy-Пирсона rxy = 25,6 = 0,57 р ≤ 0,01 1,735 * 1,501 *
- 93. Поле рассеяния
- 94. Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла Чарльз Э́двард Спи́рмен (англ. Charles Edward Spearman) - английский психолог,
- 95. Основные положения Коэффициентов корреляции rs-Спирмена и ι-Кендалла Коэффициенты ранговой корреляции: r-Спирмена или ι-Кенделла применяются если обе
- 96. Нахождение коэффициента корреляции rs-Спирмена rs = 1 – 6*474 = - 0,65 р ≤ 0,05 12(144
- 97. Формула ι-Кенделла : Пояснения к формуле Р — общее число совпадений. Q — общее число инверсий
- 98. Нахождение коэффициента корреляции ι-Кенделла ι = 21-7 = 0,5 р = 0,08 8(8-1)/2 Статистический вывод: взаимосвязь
- 99. Тема 10. Анализ качественных признаков (номинативных данных) Корреляция номинативных данных критерий χ2-Пирсона Корреляция бинарных данных фи-коэффициент
- 100. Анализ качественных признаков (номинативных данных)
- 101. Корреляция номинативных данных критерий χ2-Пирсона Критерий χ2-Пирсона применяется если обе переменные представлены в номинативной шкале, одна
- 102. Нахождение критерия χ2-Пирсона Теоретические частоты fe женский и синий = 4 x 8 = 2,1 15
- 103. Нахождение критерия χ2-Пирсона Расчет χ2= 11,8 k = 3; j = 2; df = (k –
- 104. Корреляция бинарных данных фи-коэффициент сопряженности Пирсона Коэффициент сопряженности φ-Пирсона применяется если обе переменные представлены в номинативной
- 105. Нахождение коэффициента сопряженности φ-Пирсона
- 106. Тема 11. Анализ различий между 2 группами независимых выборок Классификация методов сравнения Представление данных сравнительного анализа
- 107. Методы сравнения В зависимости от решаемых задач методы внутри этой группы классифицируются по трем основаниям: Количество
- 108. Представление данных сравнительного анализа Графическое представление данных
- 109. Построение таблиц
- 110. Классификация методов сравнения
- 111. Критерий t-Стьюдента Уи́льям Си́ли Го́ссет - известный учёный-статистик. Родился 13 июня 1876 г. в Кентербери (Англия)
- 112. Параметрический критерий t-Стьюдента для двух независимых выборок Метод позволяет проверить гипотезу о том, что средние значения
- 113. Нахождение критерия t-Стьюдента для двух независимых выборок tэ = 44,1-34,9 =2,5 √9,12/10+7,19/10 df = 10 +
- 114. Критерий U-Манна-Уитни Настоящий статистический метод был предложен Фрэнком Вилкоксоном в 1945 году. Однако в 1947 году
- 115. Непараметрический критерий U-Манна-Уитни для двух независимых выборок Критерий предназначен для оценки различий между двумя выборками по
- 116. Нахождение критерия U-Манна-Уитни Ш а г 1. Значения двух выборок объединяются в один ряд и упорядочиваются.
- 117. Тема 12. Анализ различий между 2 группами зависимых выборок Параметрический критерий t-Стьюдента для двух зависимых выборок
- 118. Параметрический критерий t-Стьюдента для двух зависимых выборок Метод позволяет проверить гипотезу о том, что средние значения
- 119. Нахождение критерия t-Стьюдента для двух зависимых выборок Ша г 1. Эмпирическое значение критерия по формуле: средняя
- 120. Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп Критерий предназначен для оценки различий между двумя зависимыми
- 121. Нахождение непараметрического критерия Т-Уилкоксона Ш а г 1. Подсчитать разности значений для каждого объекта выборки (строка
- 122. Тема 13. Анализ различий между 3 и более группами независимых выборок Непараметрический критерий Н-Краскала-Уоллеса для сравнения
- 123. Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп Критерий Краскала — Уоллиса предназначен для проверки
- 124. Основные положения Критерий Н-Краскала-Уоллеса позволяет проверять гипотезы о различии более двух выборок по уровню выраженности изучаемого
- 125. Нахождение Н-Краскала-Уоллеса Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность каждого значения к выборке
- 126. Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок Критерий χ2-Фридмана позволяет проверять гипотезы о различии
- 127. Нахождение критерия χ2-Фридмана Шаг 1. Для каждого объекта условия ранжируются (по строке). Ш а г 2.
- 128. Тема 14. Дисперсионный анализ (ANOVA) Однофакторный дисперсионный анализ ANOVA Методы множественного сравнения
- 129. Дисперсионный анализ ANOVA (от англоязычного ANalysis Of VАriance) Анализ предназначен для изучения различий у трех и
- 130. Последовательность вычислений для ANOVA В общей изменчивости зависимой переменной выделяются основные ее составляющие. (В однофакторном ANOVA
- 131. Виды дисперсионного анализа (ДА)
- 132. Нахождение однофакторного ANOVA Общее среднее: М= 7. Среднее для разных условий: М1 = 5; М2 =
- 133. Методы множественного сравнения
- 134. Тема 15. Многомерные методы Определение и классификация многомерных методов Регрессионный анализ (частный случай множественного регрессионного анализа)
- 135. Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания изучаемых явлений. ММ воспроизводят мыслительные
- 136. Классификация многомерных методов
- 137. Регрессионный анализ (частный случай множественного регрессионного анализа) Регрессионный анализ — основан на коэффициенте детерминации. Регрессионный анализ
- 138. Уравнение линейной регрессии Если переменные пропорциональны друг другу, то графически связь между ними можно представить в
- 139. Расчеты уравнения регрессии Пример: Школьникам была дана тестовая задача, которую им необходимо было решить, при этом
- 140. Множественный регрессионный анализ Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей -
- 141. Основными целями МРА являются Определение того, в какой мере «зависимая» переменная связана с совокупностью «независимых» переменных,
- 142. Дискриминантный анализ Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у) и нескольких других переменных
- 143. Основные результаты дискриминантного анализа Определение статистической значимости различения классов при помощи данного набора дискриминантных переменных. Показатели
- 144. Факторный анализ Главная цель факторного анализа — уменьшение размерности исходных данных. Результатом факторного анализа является переход
- 145. Основные этапы факторного анализа Выбор исходных данных. Предварительное решение проблемы числа факторов: используются критерий отсеивания Р.
- 146. Кластерный анализ Кластерный анализ — это процедура упорядочивания объектов в сравнительно однородные классы на основе попарного
- 147. Этапы кластерного анализа 1. Отбор объектов для кластеризации. Объектами могут быть, в зависимости от цели исследования:
- 148. Многомерное шкалирование Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества объектов Главная задача МШ
- 149. Основные этапы многомерного шкалирования Определение величины стресса (φ-Stress), который является показателем точности - наиболее приемлемый для
- 150. Тема 16. Математическое моделирование в психологии Системные подходы. Теория функциональных систем. Становление кибернетики. Системный анализ. Теория
- 151. Система - множество элементов, находящихся в отношениях и связях друг с другом, которое образует определенную целостность,
- 152. Теория функциональных систем (модель П. К. Анохина) Центральная нервная система представлена в виде нервной модели
- 153. Кибернетика Н. Винера Человек, один из самых сложных объектов реального мира, известных науке в настоящее время.
- 154. Синергетика (Г. Хакена) По Хакену, синергетика занимается изучением систем, состоящих из большого (очень большого, «огромного») числа
- 155. Общая теория систем Л. Фон Берталанфи Общая теория систем Л. Фон Берталанфи состоит в том, что
- 156. Теория развития И.Р. Пригожина Теория развития И.Р. Пригожина гласит, что если отток энтропии (меры необратимого рассеяния
- 157. Теория катастроф Катастрофами называются скачкообразные изменения, возникающие в виде внезапного ответа объекта па плавные изменения внешних
- 158. Системный анализ Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных объектов с учетом их
- 159. Моделирование сложных систем Этапы моделирования сложных процессов и явлений: Формулировка цели моделирования. Анализ объекта исследования, включающий
- 160. Метод моделирования в психодиагностике
- 161. Тема 17. Анализ данных на компьютере. Использование MS Excel Статистические пакеты: SPSS, STATISTICA. Особенности подготовки данных
- 162. Алгоритм применения анализа данных на компьютере
- 163. Использование MS Excel Плюсы и минусы MC Excel В Microsoft Excel входит набор средств анализа данных
- 164. Статистические пакеты: SPSS, STATISTICA STATISTICA for Windows представляет собой интегрированную систему статистического анализа и обработки данных.
- 166. Скачать презентацию

Рекомендуемая литература
Наследов, А.Д. Математические методы психологического исследования. Анализ и интерпретация данных.
Рекомендуемая литература
Наследов, А.Д. Математические методы психологического исследования. Анализ и интерпретация данных.

Тема 1. Измерение в психологии
Предмет и назначение дисциплины
Измерение в психологии. Взаимоотношение
Тема 1. Измерение в психологии
Предмет и назначение дисциплины
Измерение в психологии. Взаимоотношение

Определение статистики
Термин «статистика» имеет несколько значений:
∙ это совокупность данных и сведений,
Определение статистики
Термин «статистика» имеет несколько значений:
∙ это совокупность данных и сведений,
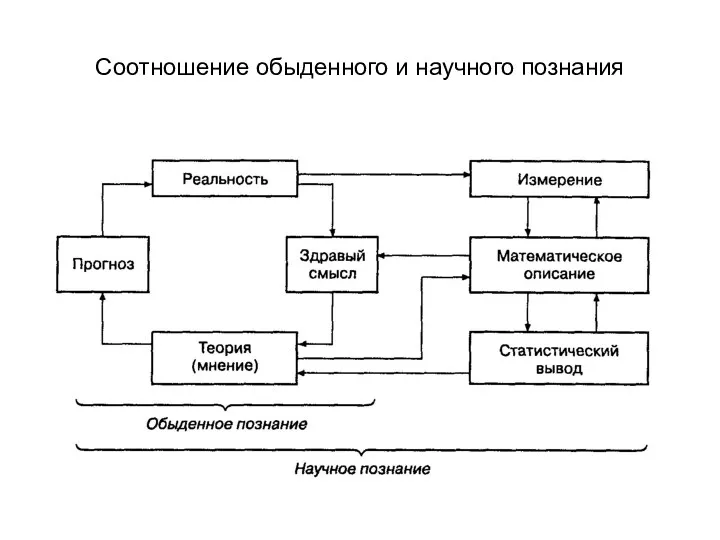
Соотношение обыденного и научного познания
Соотношение обыденного и научного познания
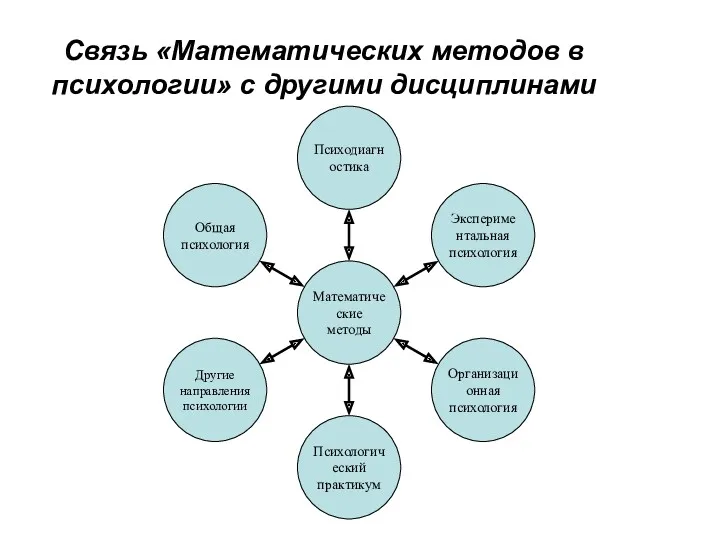
Связь «Математических методов в психологии» с другими дисциплинами
Связь «Математических методов в психологии» с другими дисциплинами
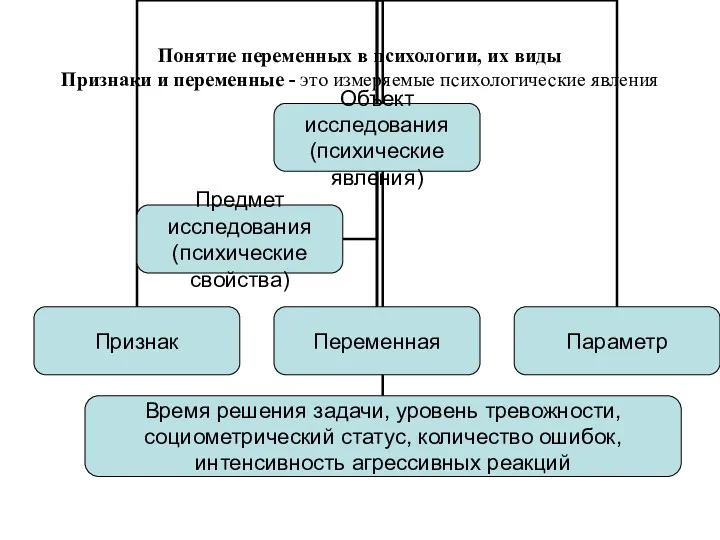
Понятие переменных в психологии, их виды
Признаки и переменные - это
Понятие переменных в психологии, их виды Признаки и переменные - это
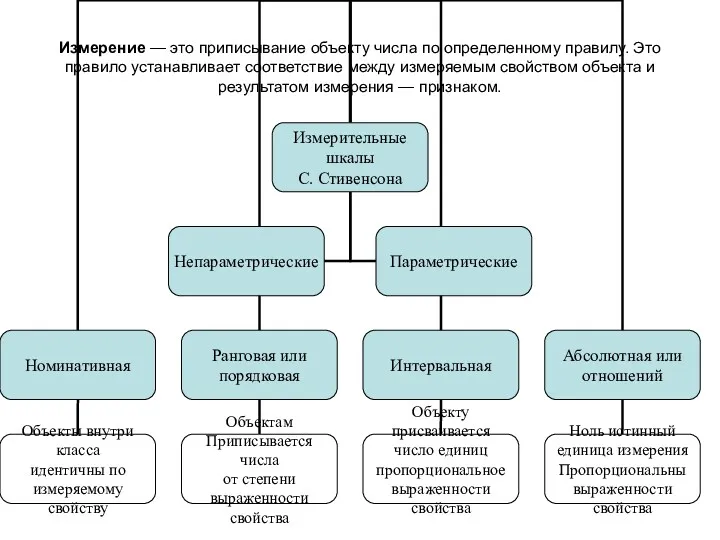
Измерение — это приписывание объекту числа по определенному правилу. Это правило
Измерение — это приписывание объекту числа по определенному правилу. Это правило
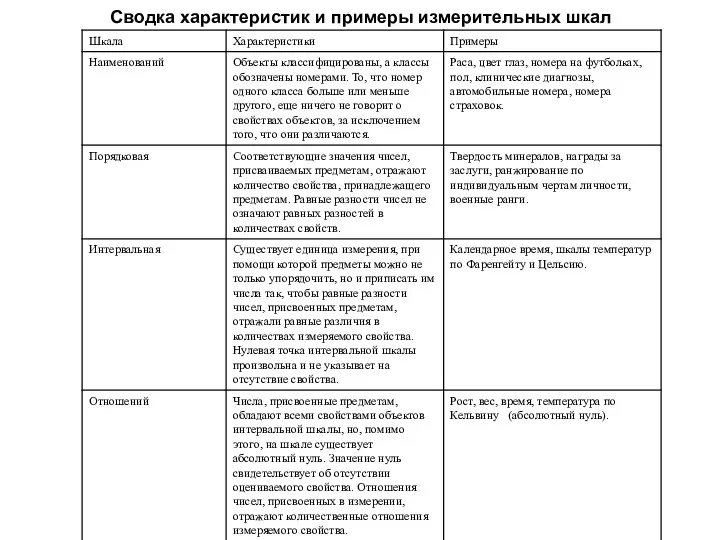
Сводка характеристик и примеры измерительных шкал
Сводка характеристик и примеры измерительных шкал
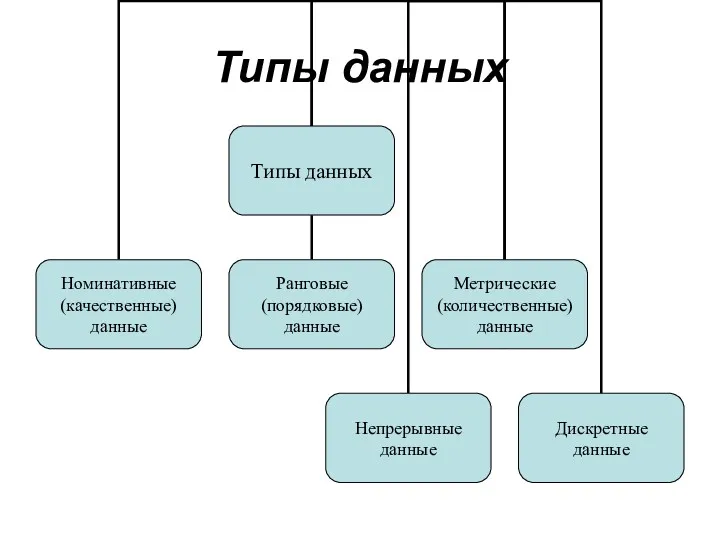
Типы данных
Типы данных
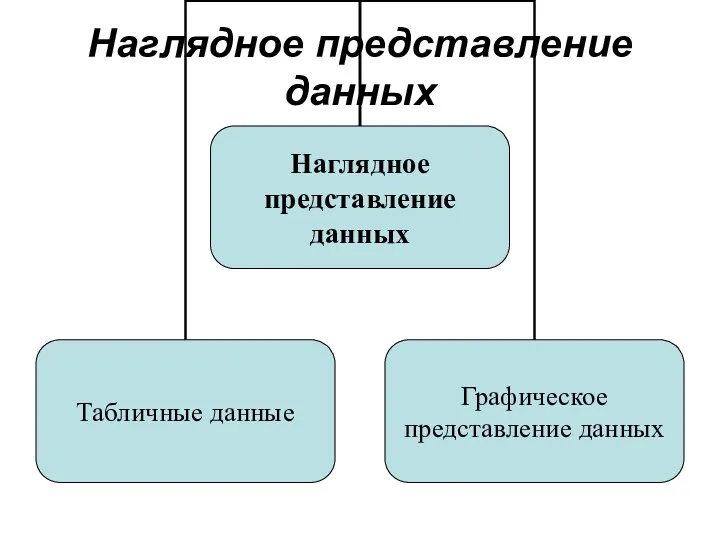
Наглядное представление данных
Наглядное представление данных

Графическое представление данных
В самом общем виде диаграммы делятся на:
1. Столбиковые:
Вертикальные;
Горизонтальные;
2. Линейные
Собственно
Графическое представление данных
В самом общем виде диаграммы делятся на:
1. Столбиковые:
Вертикальные;
Горизонтальные;
2. Линейные
Собственно

Правила графического оформления
Вся структура графика предполагает его чтение слева направо, вертикальные
Правила графического оформления
Вся структура графика предполагает его чтение слева направо, вертикальные

Правила табличного представления первичных данных
Вся структура таблицы предполагает ее чтение слева
Правила табличного представления первичных данных
Вся структура таблицы предполагает ее чтение слева

Тема 3.
Способы представления данных в психологии
Представление данных.
Понятие о квантилях.
Понятие о
Тема 3.
Способы представления данных в психологии
Представление данных.
Понятие о квантилях.
Понятие о

Представление данных в психологии бывает в виде:
Массив данных – первичные результаты
Представление данных в психологии бывает в виде:
Массив данных – первичные результаты
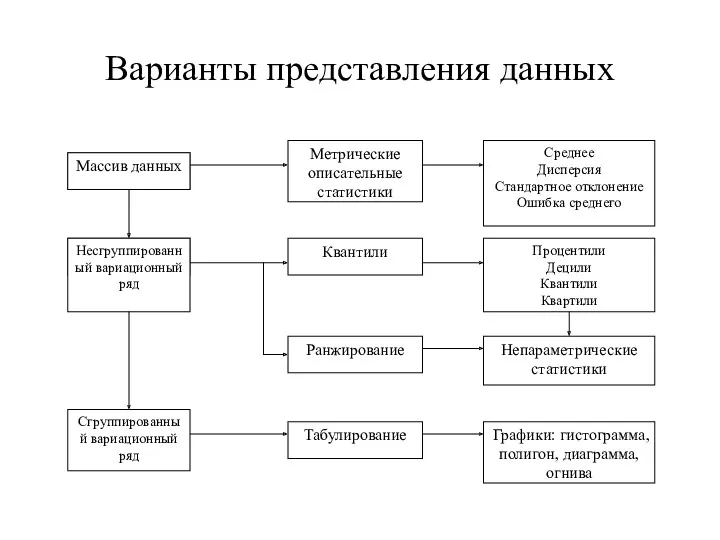
Варианты представления данных
Варианты представления данных

Меры положения – квантили
Квантиль — это точка на числовой оси измеренного
Меры положения – квантили Квантиль — это точка на числовой оси измеренного

Нахождение процентиля
Р-й процентиль представляет собой точку, ниже которой лежит Р %
Нахождение процентиля
Р-й процентиль представляет собой точку, ниже которой лежит Р %

Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов.
Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов.

Ранговый порядок
Ранжирование – это приписывание объектам чисел в зависимости от
Ранговый порядок Ранжирование – это приписывание объектам чисел в зависимости от
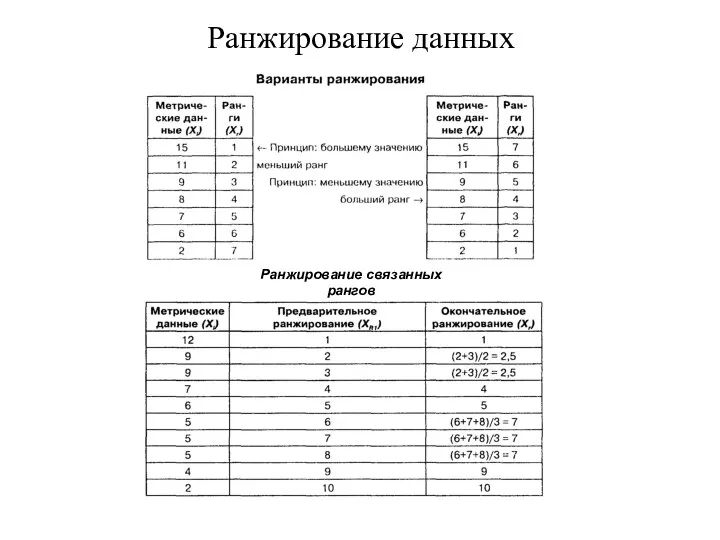
Ранжирование данных
Ранжирование связанных рангов
Ранжирование данных
Ранжирование связанных рангов

Распределение частот
Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько
Распределение частот
Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько
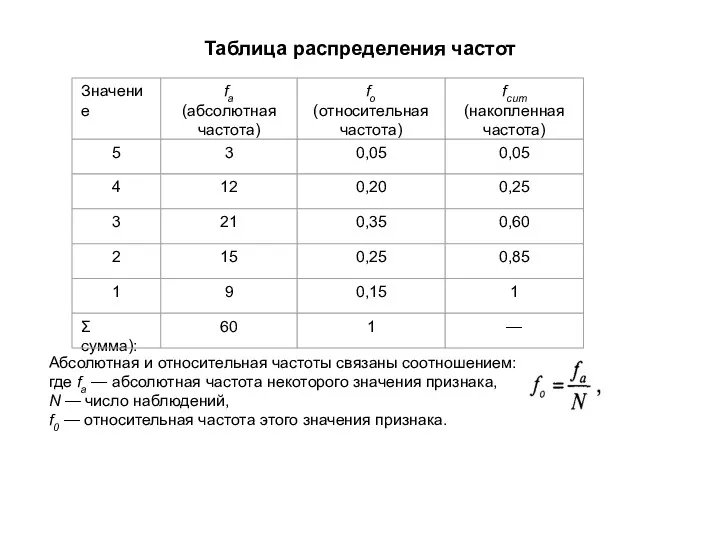
Таблица распределения частот
Абсолютная и относительная частоты связаны соотношением:
где fa — абсолютная
Таблица распределения частот
Абсолютная и относительная частоты связаны соотношением:
где fa — абсолютная
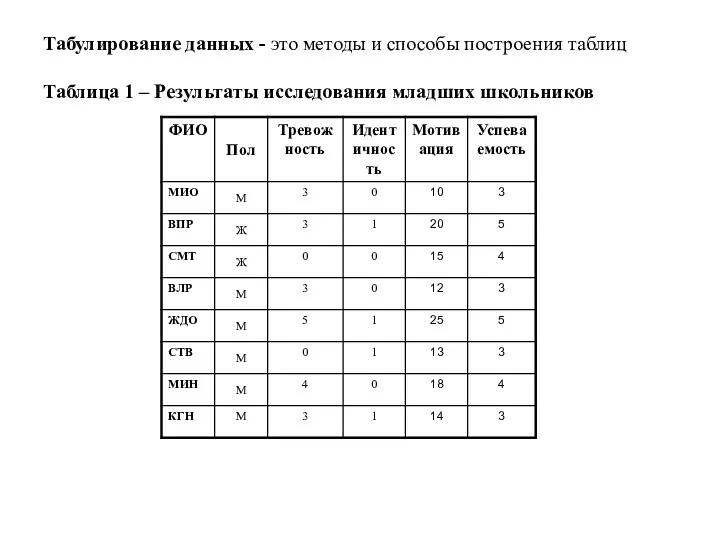
Табулирование данных - это методы и способы построения таблиц
Таблица 1 –
Табулирование данных - это методы и способы построения таблиц Таблица 1 –

Этапы построения распределения сгруппированных частот
Уточнение лимитов (крайних значений интервала) – производится
Этапы построения распределения сгруппированных частот
Уточнение лимитов (крайних значений интервала) – производится

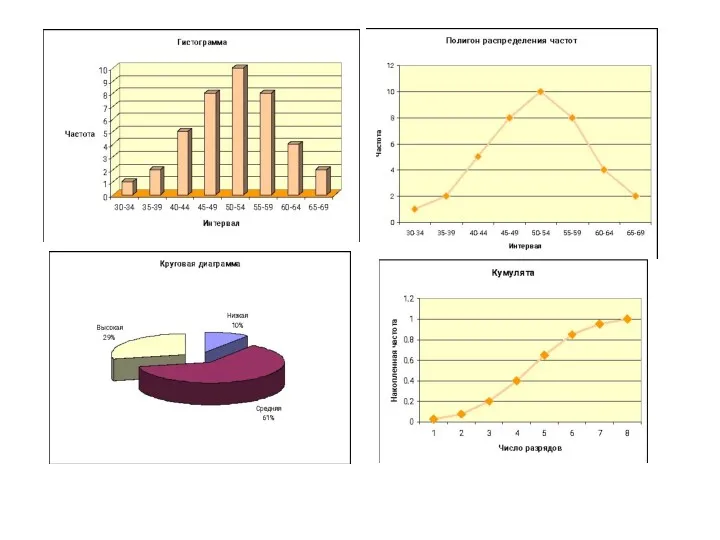
Графическое представление
Гистограмма – это последовательность столбцов, каждый из которых опирается
Графическое представление
Гистограмма – это последовательность столбцов, каждый из которых опирается

Тема 4. Меры центральной тенденции
Определение меры центральной тенденции;
Мода;
Медиана;
Среднее;
Выбор и особенности мер
Тема 4. Меры центральной тенденции
Определение меры центральной тенденции;
Мода;
Медиана;
Среднее;
Выбор и особенности мер
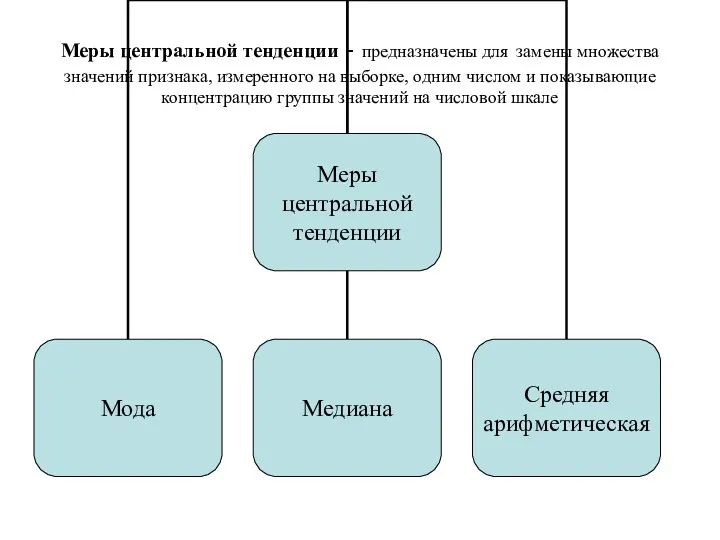
Меры центральной тенденции - предназначены для замены множества значений признака, измеренного
Меры центральной тенденции - предназначены для замены множества значений признака, измеренного

Мода (Mode) — это такое значение из множества измерений, которое встречается
Мода (Mode) — это такое значение из множества измерений, которое встречается

Медиана (Median) — это такое значение признака, которое делит упорядоченное множество
Медиана (Median) — это такое значение признака, которое делит упорядоченное множество

Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как
Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как

Выбор и особенности мер центральной тенденции
Для номинативных данных единственной подходящей мерой
Выбор и особенности мер центральной тенденции
Для номинативных данных единственной подходящей мерой
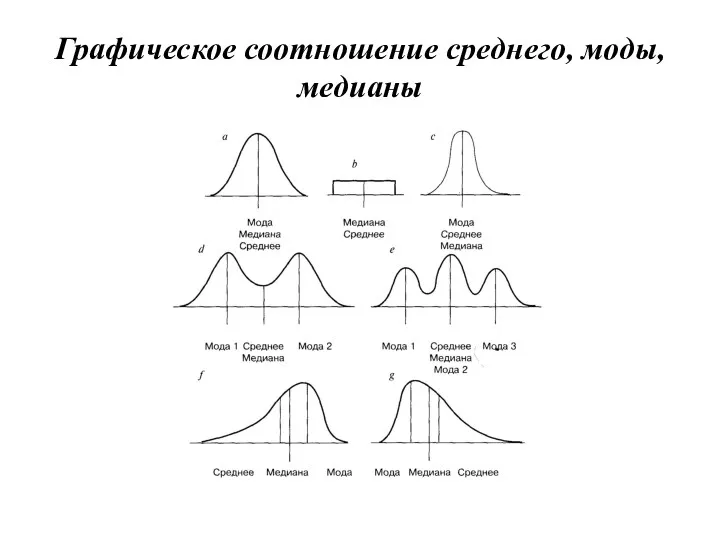
Графическое соотношение среднего, моды, медианы
Графическое соотношение среднего, моды, медианы
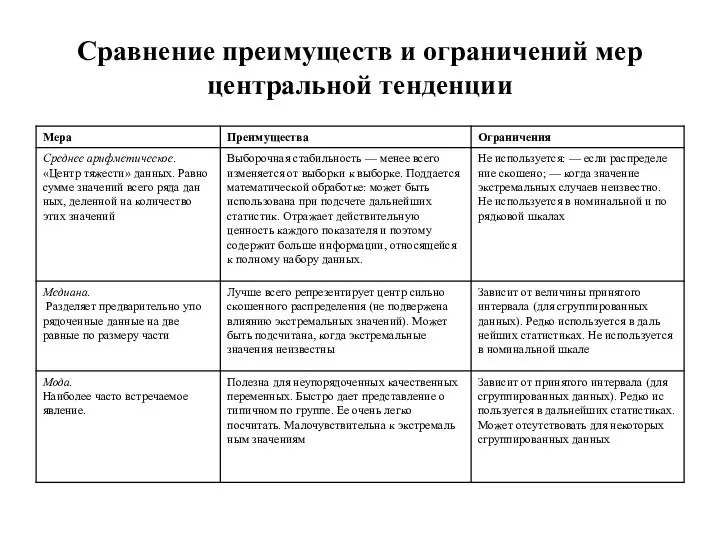
Сравнение преимуществ и ограничений мер центральной тенденции
Сравнение преимуществ и ограничений мер центральной тенденции

Тема 5. Меры изменчивости
Понятие меры изменчивости
Лимиты. Размах вариации и его разновидности.
Дисперсия
Тема 5. Меры изменчивости
Понятие меры изменчивости
Лимиты. Размах вариации и его разновидности.
Дисперсия
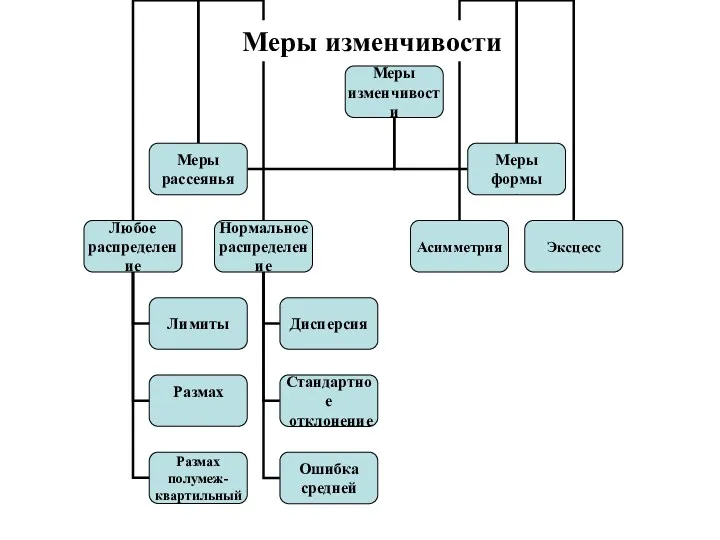
Меры изменчивости
Меры изменчивости

Меры рассеяния
независящие от распределения
Лимиты – это характеристики, определяющие верхнюю (max) и
Меры рассеяния
независящие от распределения
Лимиты – это характеристики, определяющие верхнюю (max) и

Меры рассеяния
характеризующие нормальное распределение
Дисперсия (Variance) — мера изменчивости для метрических данных,
Меры рассеяния
характеризующие нормальное распределение
Дисперсия (Variance) — мера изменчивости для метрических данных,

Расчет дисперсии
Расчет дисперсии

Меры рассеяния
характеризующие нормальное распределение
Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) —
Меры рассеяния
характеризующие нормальное распределение
Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) —
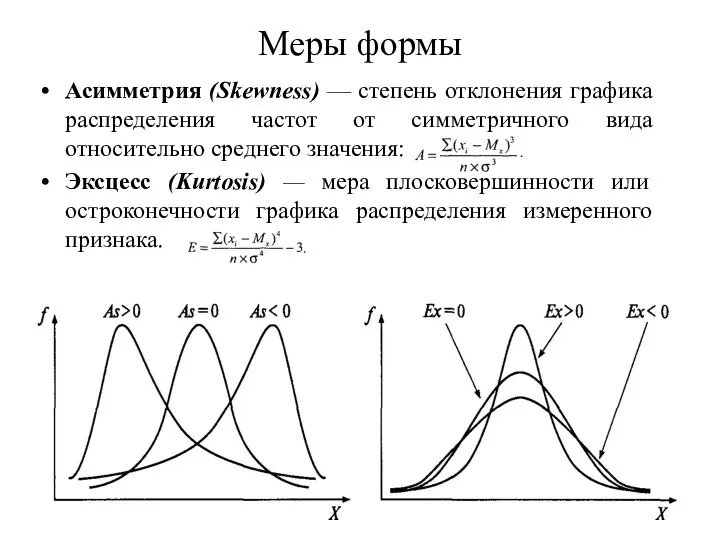
Меры формы
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного
Меры формы
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного

Тема 6. Стандартизация данных
Понятие стандартизации данных.
Основные формы стандартизации.
z-преобразование данных.
Тема 6. Стандартизация данных
Понятие стандартизации данных.
Основные формы стандартизации.
z-преобразование данных.

Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры
Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры

Преобразование первичных оценок в новую шкалу
Центрирование – это линейная трансформация величин
Преобразование первичных оценок в новую шкалу
Центрирование – это линейная трансформация величин
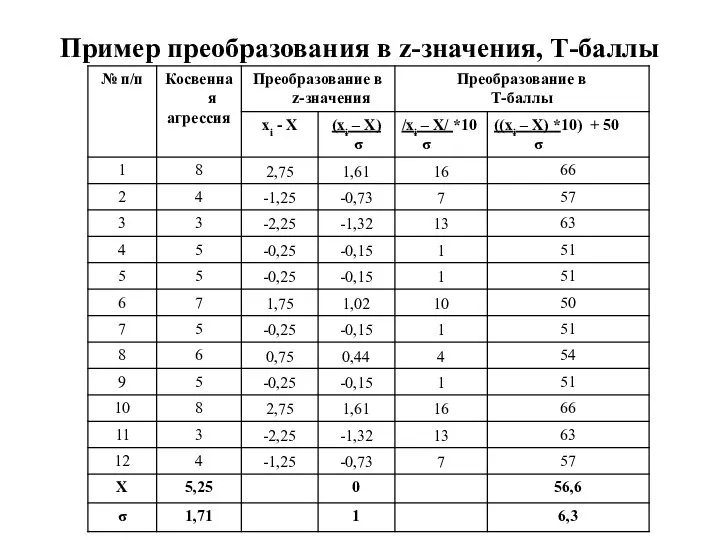
Пример преобразования в z-значения, Т-баллы
Пример преобразования в z-значения, Т-баллы

Тема 7. Теоретические распределения, используемые при статистических выводах
Нормальное распределение
Единичное нормальное
Тема 7. Теоретические распределения, используемые при статистических выводах
Нормальное распределение
Единичное нормальное
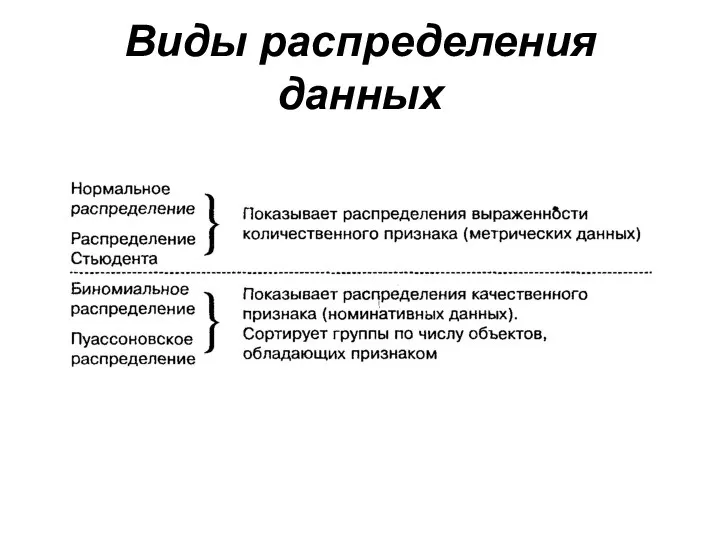
Виды распределения данных
Виды распределения данных
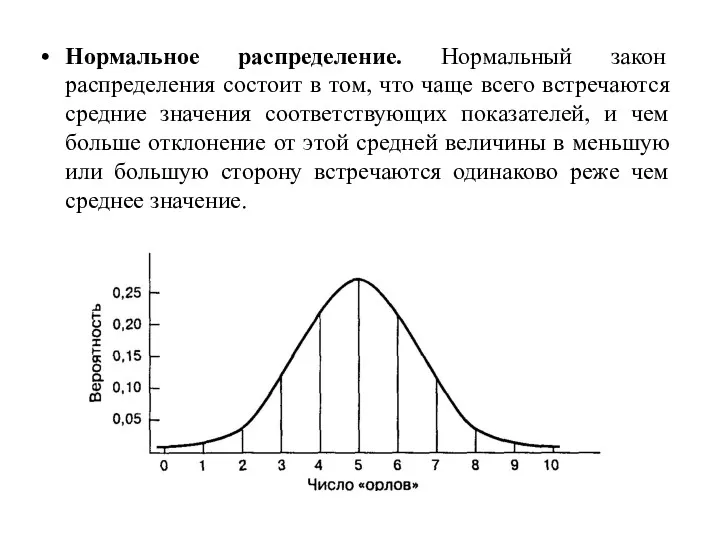
Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего
Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего

Единичное нормальное распределение и его свойства
Если применить z-преобразование ко всем
Единичное нормальное распределение и его свойства
Если применить z-преобразование ко всем
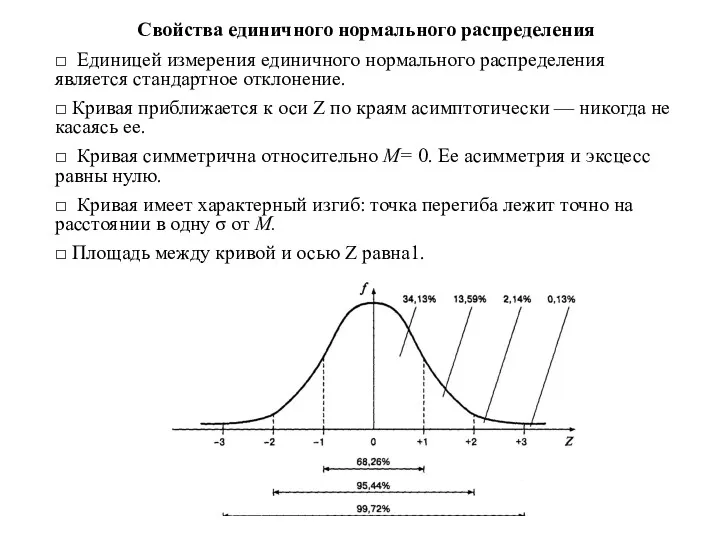
Свойства единичного нормального распределения
□ Единицей измерения единичного нормального распределения является стандартное
Свойства единичного нормального распределения
□ Единицей измерения единичного нормального распределения является стандартное
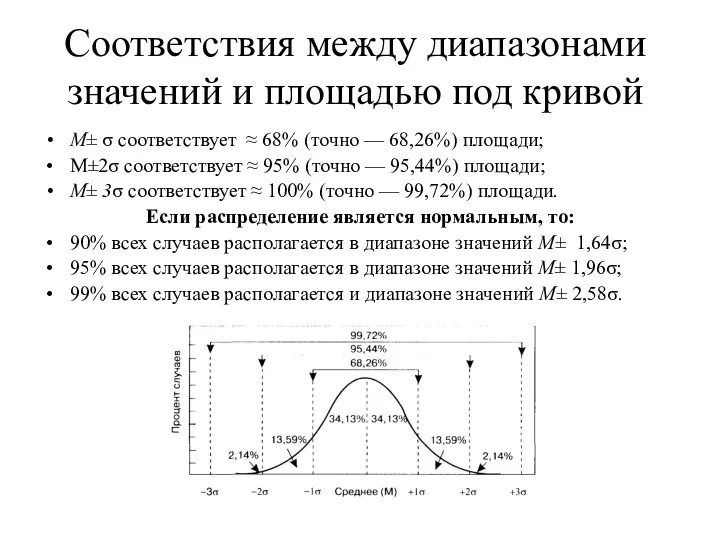
Соответствия между диапазонами значений и площадью под кривой
М± σ соответствует ≈
Соответствия между диапазонами значений и площадью под кривой
М± σ соответствует ≈

Проверка нормальности распределения
1. Нормальность распределения результативного признака можно проверить путем расчета
Проверка нормальности распределения
1. Нормальность распределения результативного признака можно проверить путем расчета

2. Еще одним из критериев проверки на нормальность - является критерий
2. Еще одним из критериев проверки на нормальность - является критерий
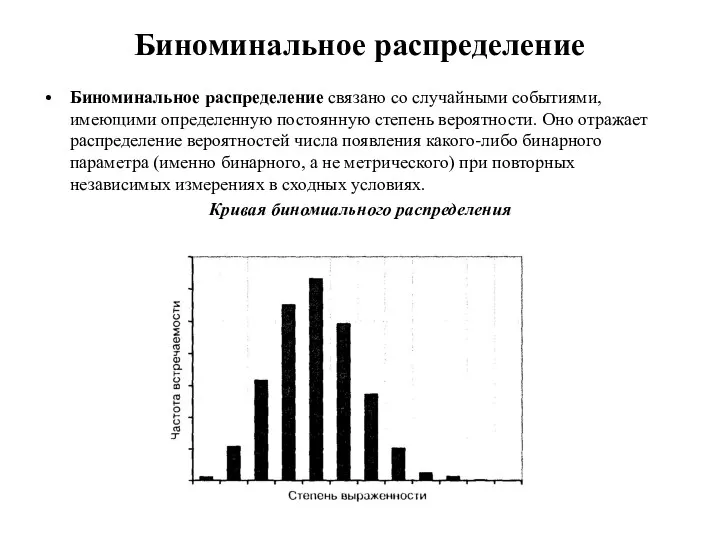
Биноминальное распределение
Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень
Биноминальное распределение
Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень

Распределение Пуассона
Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в
Распределение Пуассона
Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в

Тема 8. Статистическое оценивание и проверка гипотез
Понятие генеральной совокупности и
Тема 8. Статистическое оценивание и проверка гипотез
Понятие генеральной совокупности и
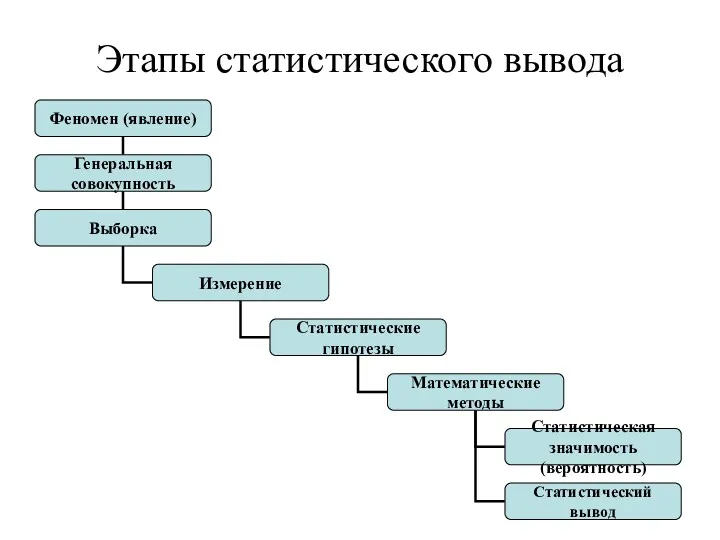
Этапы статистического вывода
Этапы статистического вывода

Понятие генеральной совокупности и выборки
Генеральной совокупностью – называется всякая большая (конечная
Понятие генеральной совокупности и выборки
Генеральной совокупностью – называется всякая большая (конечная
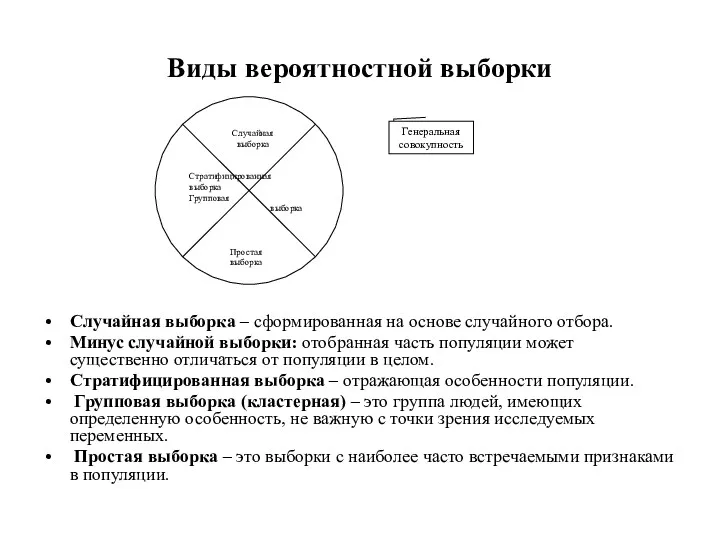
Виды вероятностной выборки
Случайная выборка – сформированная на основе случайного отбора.
Минус случайной
Виды вероятностной выборки
Случайная выборка – сформированная на основе случайного отбора.
Минус случайной
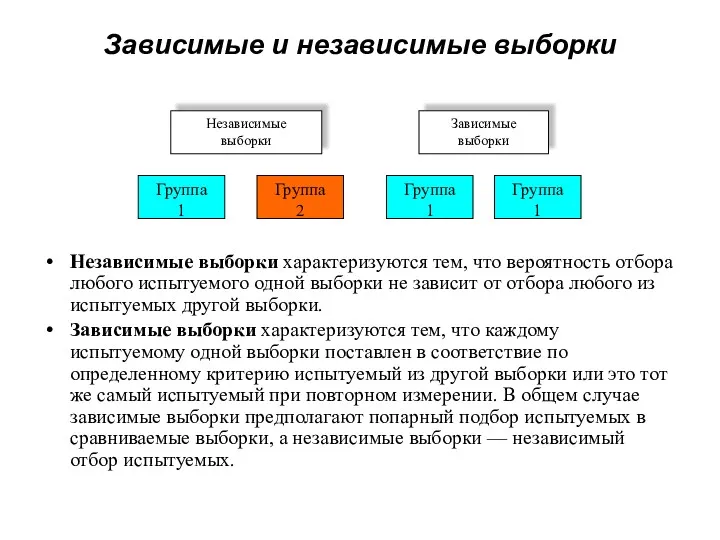
Зависимые и независимые выборки
Независимые выборки характеризуются тем, что вероятность отбора любого
Зависимые и независимые выборки
Независимые выборки характеризуются тем, что вероятность отбора любого

Объем выборки – определяется численностью входящих в нее элементов. Объем выборки
Объем выборки – определяется численностью входящих в нее элементов. Объем выборки

Гипотеза – это утверждение, истинность или ложность которого неизвестны, но могут
Гипотеза – это утверждение, истинность или ложность которого неизвестны, но могут
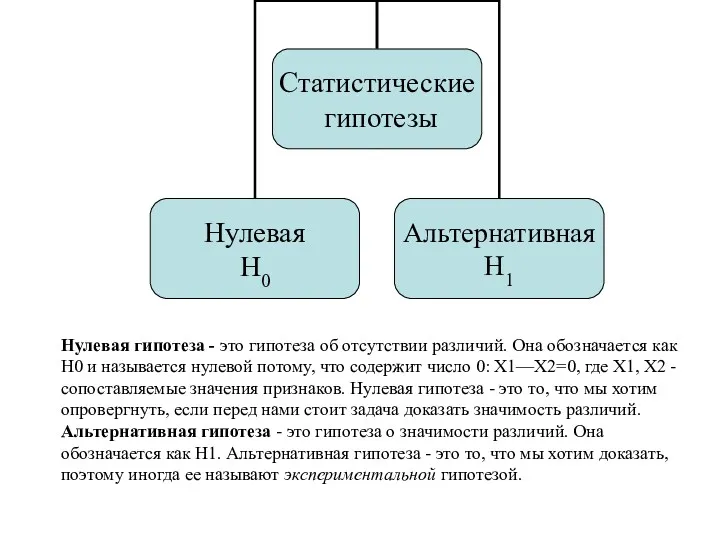
Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как
Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как

Статистический критерий
Статистический критерий – это решающее правило, обеспечивающее надежное поведение,
Статистический критерий
Статистический критерий – это решающее правило, обеспечивающее надежное поведение,

Основание выбора критерия
а) в какой шкале представлены признаки;
б) мощность критерия
в) применимость
Основание выбора критерия
а) в какой шкале представлены признаки;
б) мощность критерия
в) применимость

Степень свободы
Число степеней свободы – это количество возможных направлений изменчивости
Степень свободы
Число степеней свободы – это количество возможных направлений изменчивости

Показатели степеней свободы для зависимых и независимых выборок
Если имеются две независимые
Показатели степеней свободы для зависимых и независимых выборок
Если имеются две независимые

Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level), —
Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level), —
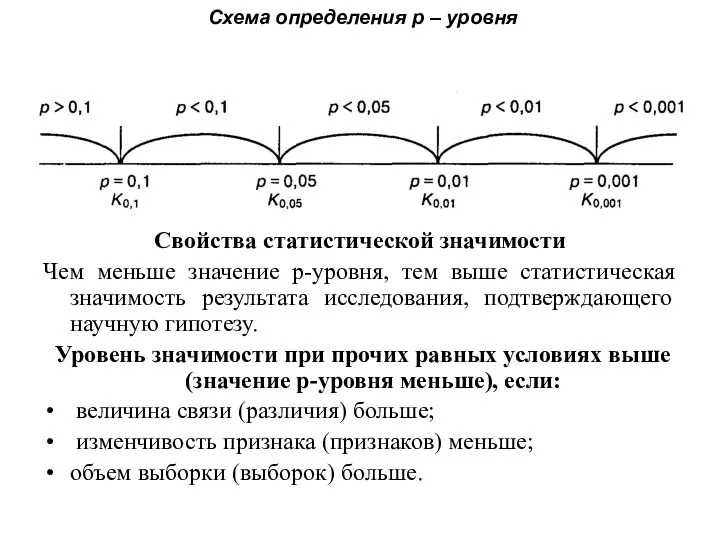
Схема определения р – уровня
Свойства статистической значимости
Чем меньше значение р-уровня, тем
Схема определения р – уровня
Свойства статистической значимости
Чем меньше значение р-уровня, тем

Статистический вывод — это формулирование вывода на основе статистической значимости.
Статистический
Статистический вывод — это формулирование вывода на основе статистической значимости.
Статистический

Ошибки 1 и 2 рода
Ошибка I рода - ошибка, состоящая
Ошибки 1 и 2 рода
Ошибка I рода - ошибка, состоящая

Алгоритм проверки статистических гипотез
Обоснование применения критерия.
Выполнение ограничений (если есть).
Формулирование статистических
Алгоритм проверки статистических гипотез
Обоснование применения критерия.
Выполнение ограничений (если есть).
Формулирование статистических

Тема 9. Меры связи
Понятие корреляции.
Диаграмма рассеяния.
Классификация коэффициентов корреляции.
Корреляционные матрицы.
Интерпретация
Тема 9. Меры связи
Понятие корреляции.
Диаграмма рассеяния.
Классификация коэффициентов корреляции.
Корреляционные матрицы.
Интерпретация

Понятие корреляции и ее основные параметры
Корреляционная связь – это согласованное изменение
Понятие корреляции и ее основные параметры
Корреляционная связь – это согласованное изменение

Сила связи достигает максимума при условии взаимно однозначного соответствия: когда каждому
Сила связи достигает максимума при условии взаимно однозначного соответствия: когда каждому
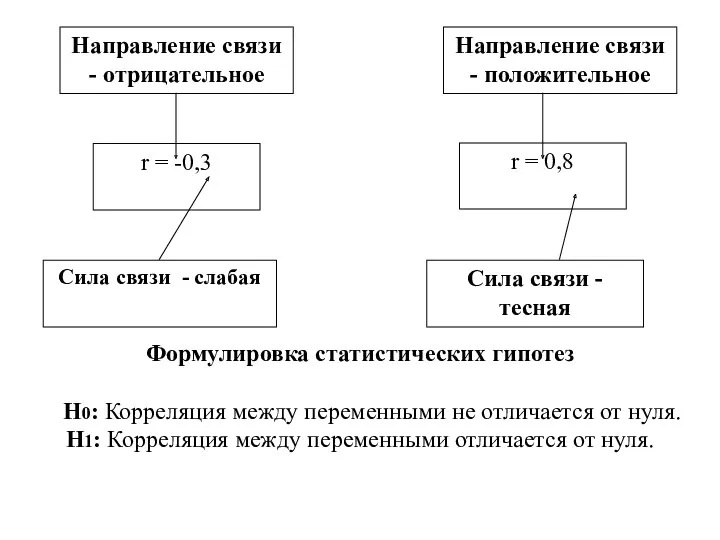
Формулировка статистических гипотез
Н0: Корреляция между переменными не отличается от нуля.
Формулировка статистических гипотез
Н0: Корреляция между переменными не отличается от нуля.

Виды связей
Взаимосвязи на языке математики обычно описываются при помощи функций, которые
Виды связей
Взаимосвязи на языке математики обычно описываются при помощи функций, которые
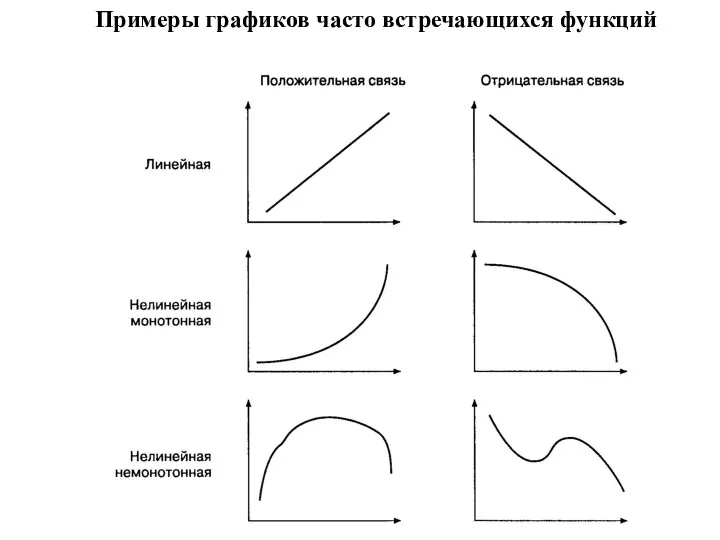
Примеры графиков часто встречающихся функций
Примеры графиков часто встречающихся функций
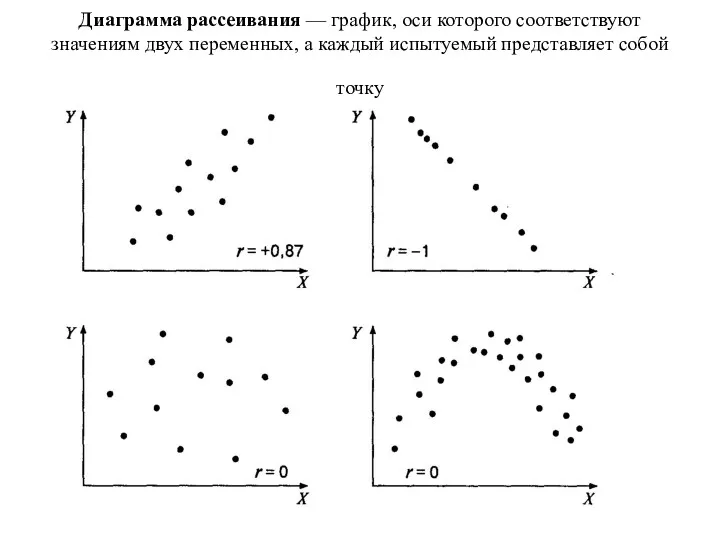
Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а
Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а

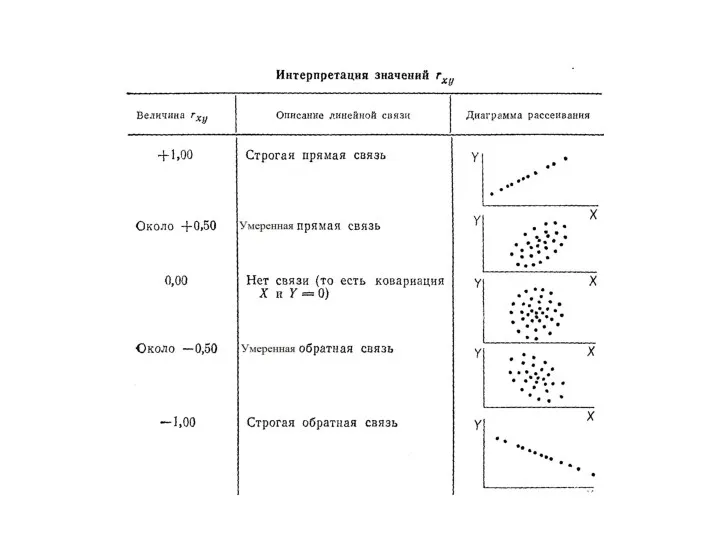
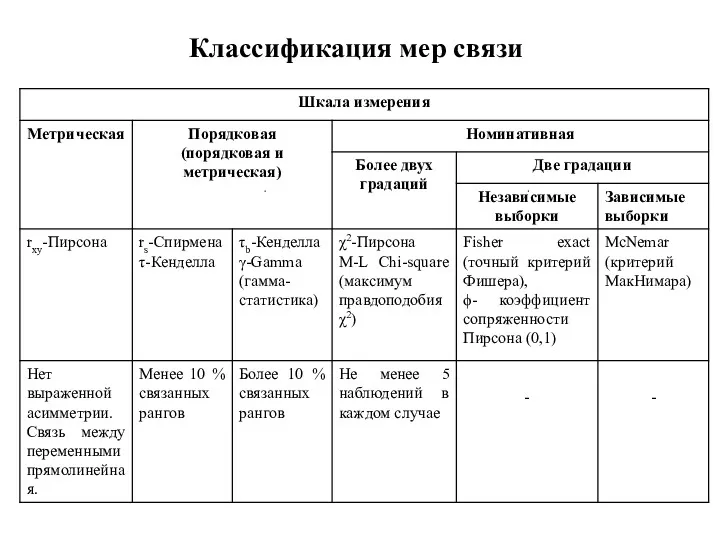
Классификация мер связи
При r ≤ 0.3 (слабая связь), 0,3 < r
Классификация мер связи
При r ≤ 0.3 (слабая связь), 0,3 < r
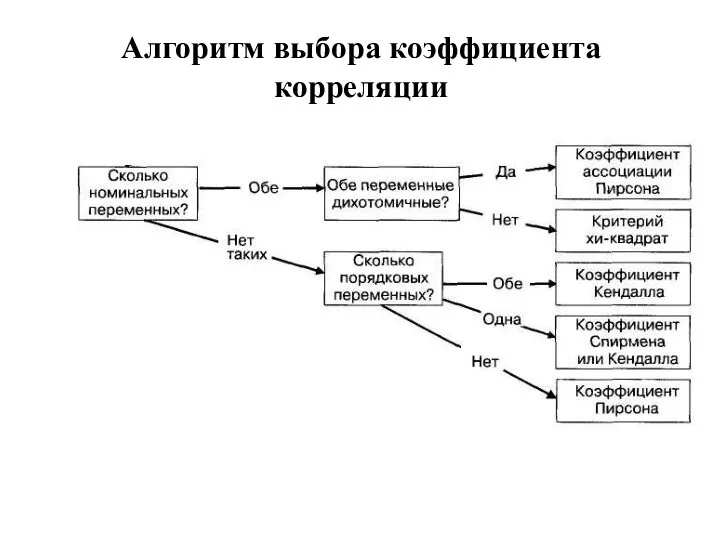
Алгоритм выбора коэффициента корреляции
Алгоритм выбора коэффициента корреляции
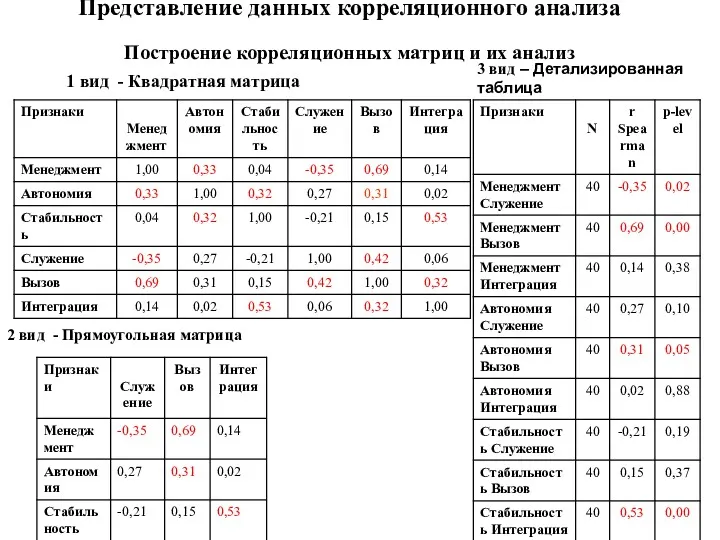
Представление данных корреляционного анализа
Построение корреляционных матриц и их анализ
1
Представление данных корреляционного анализа
Построение корреляционных матриц и их анализ
1
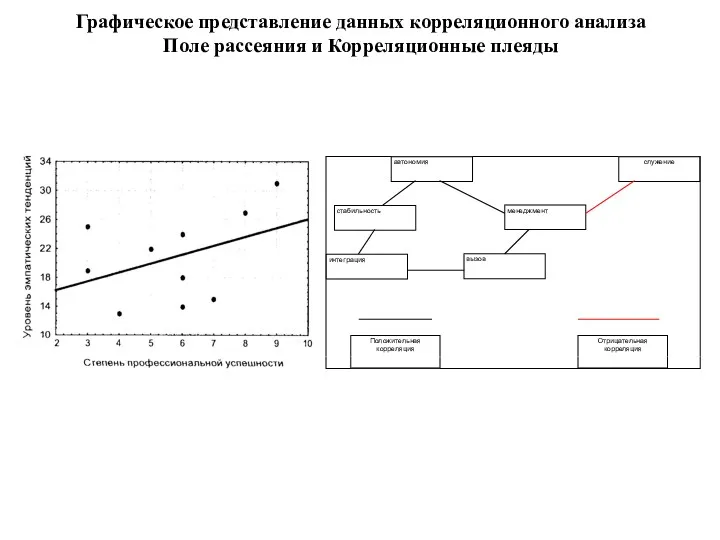
Графическое представление данных корреляционного анализа
Поле рассеяния и Корреляционные плеяды
Графическое представление данных корреляционного анализа
Поле рассеяния и Корреляционные плеяды
Классификация мер связи
Классификация мер связи

Коэффициент корреляции rxy- Пирсона
Коэффициент был создан Карлом (Чарлзом) Пирсоном (англ. Karl
Коэффициент корреляции rxy- Пирсона
Коэффициент был создан Карлом (Чарлзом) Пирсоном (англ. Karl

Основные положения
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических
Основные положения
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических
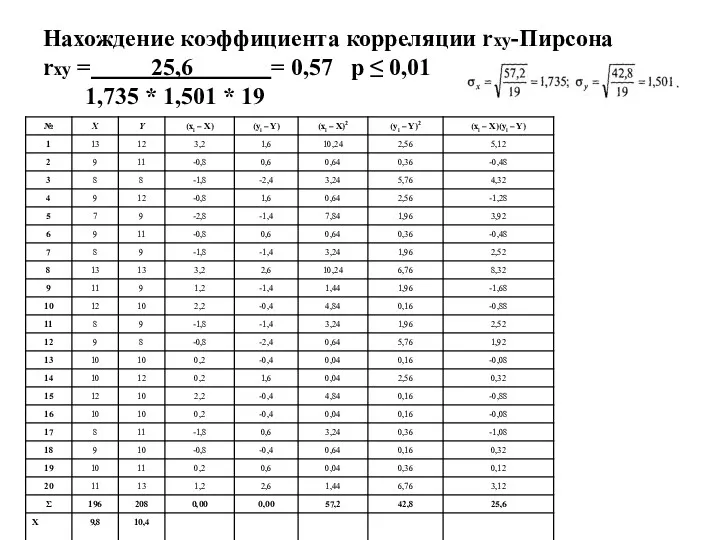
Нахождение коэффициента корреляции rxy-Пирсона
rxy = 25,6 = 0,57 р ≤ 0,01
Нахождение коэффициента корреляции rxy-Пирсона rxy = 25,6 = 0,57 р ≤ 0,01
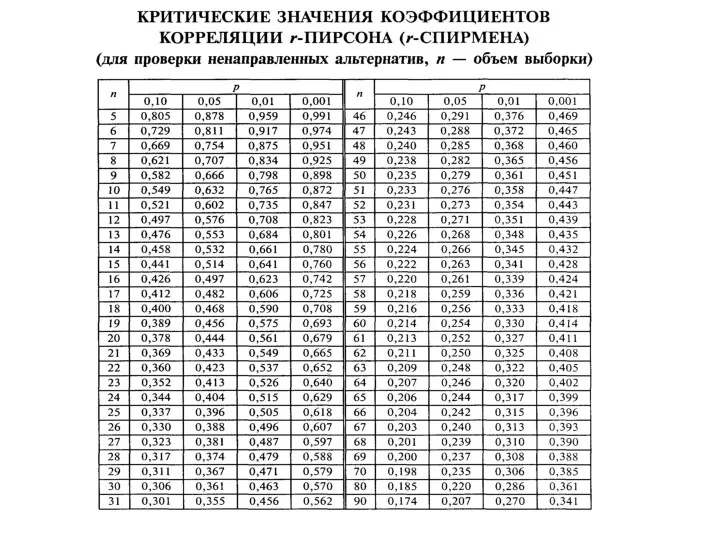

Поле рассеяния
Поле рассеяния

Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла
Чарльз Э́двард Спи́рмен (англ. Charles Edward
Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла
Чарльз Э́двард Спи́рмен (англ. Charles Edward

Основные положения
Коэффициентов корреляции rs-Спирмена и ι-Кендалла
Коэффициенты ранговой корреляции: r-Спирмена или
Основные положения
Коэффициентов корреляции rs-Спирмена и ι-Кендалла
Коэффициенты ранговой корреляции: r-Спирмена или
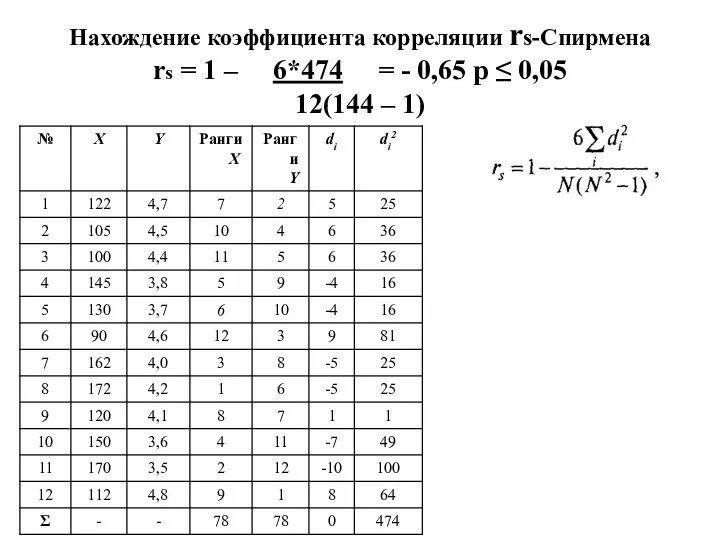
Нахождение коэффициента корреляции rs-Спирмена
rs = 1 – 6*474 = -
Нахождение коэффициента корреляции rs-Спирмена rs = 1 – 6*474 = -

Формула ι-Кенделла :
Пояснения к формуле
Р — общее число совпадений.
Q —
Формула ι-Кенделла :
Пояснения к формуле
Р — общее число совпадений.
Q —
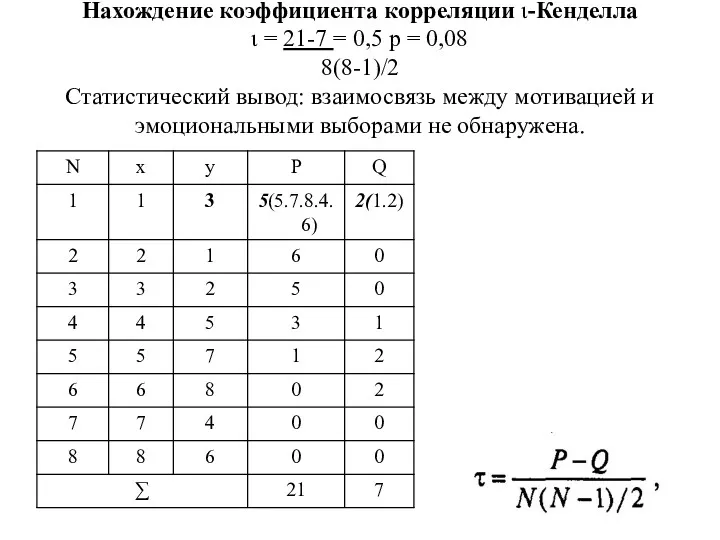
Нахождение коэффициента корреляции ι-Кенделла
ι = 21-7 = 0,5 р =
Нахождение коэффициента корреляции ι-Кенделла ι = 21-7 = 0,5 р =

Тема 10. Анализ качественных признаков (номинативных данных)
Корреляция номинативных данных
критерий χ2-Пирсона
Корреляция бинарных
Тема 10. Анализ качественных признаков (номинативных данных)
Корреляция номинативных данных
критерий χ2-Пирсона
Корреляция бинарных
Анализ качественных признаков (номинативных данных)
Анализ качественных признаков (номинативных данных)

Корреляция номинативных данных
критерий χ2-Пирсона
Критерий χ2-Пирсона применяется если обе переменные представлены в
Корреляция номинативных данных
критерий χ2-Пирсона
Критерий χ2-Пирсона применяется если обе переменные представлены в
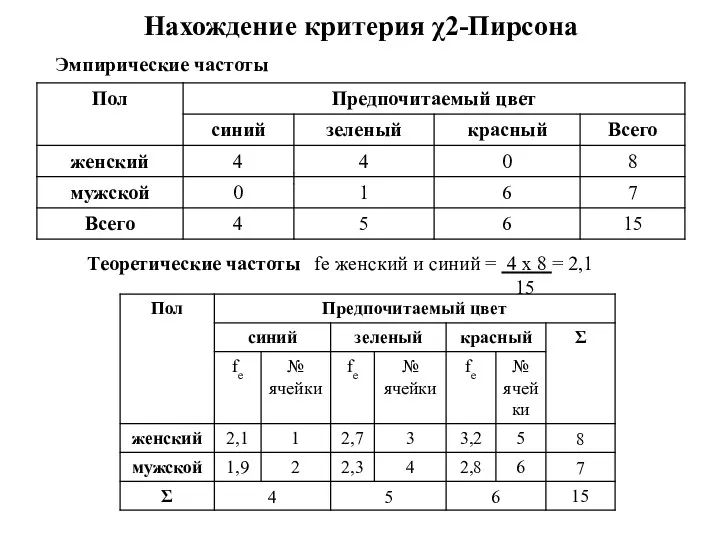
Нахождение критерия χ2-Пирсона
Теоретические частоты fe женский и синий = 4 x
Нахождение критерия χ2-Пирсона
Теоретические частоты fe женский и синий = 4 x

Нахождение критерия χ2-Пирсона
Расчет
χ2= 11,8
k = 3; j = 2; df
Нахождение критерия χ2-Пирсона
Расчет
χ2= 11,8
k = 3; j = 2; df

Корреляция бинарных данных
фи-коэффициент сопряженности Пирсона
Коэффициент сопряженности φ-Пирсона применяется если обе переменные
Корреляция бинарных данных
фи-коэффициент сопряженности Пирсона
Коэффициент сопряженности φ-Пирсона применяется если обе переменные

Нахождение коэффициента сопряженности φ-Пирсона
Нахождение коэффициента сопряженности φ-Пирсона

Тема 11. Анализ различий между 2 группами независимых выборок
Классификация методов сравнения
Представление
Тема 11. Анализ различий между 2 группами независимых выборок
Классификация методов сравнения
Представление

Методы сравнения
В зависимости от решаемых задач методы внутри этой группы классифицируются
Методы сравнения
В зависимости от решаемых задач методы внутри этой группы классифицируются
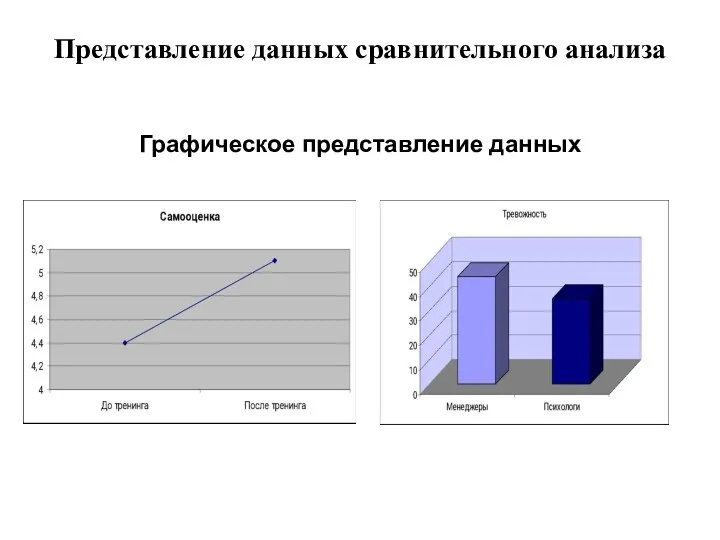
Представление данных сравнительного анализа
Графическое представление данных
Представление данных сравнительного анализа
Графическое представление данных
Построение таблиц
Построение таблиц
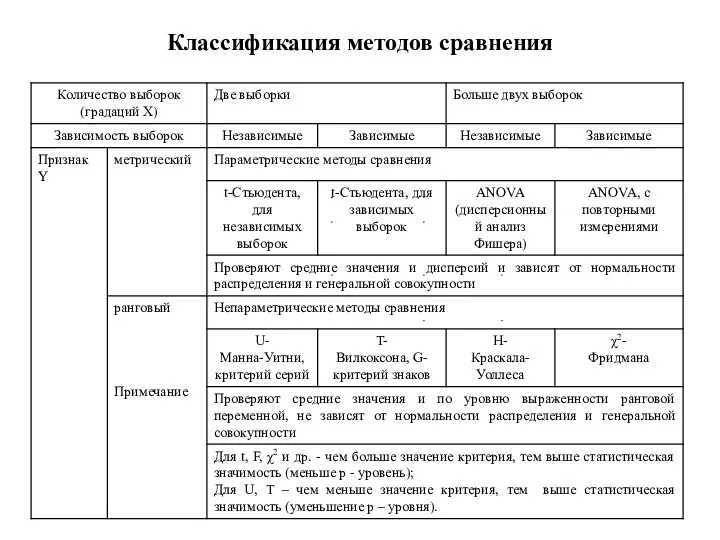
Классификация методов сравнения
Классификация методов сравнения

Критерий t-Стьюдента
Уи́льям Си́ли Го́ссет - известный учёный-статистик.
Родился 13 июня 1876
Критерий t-Стьюдента
Уи́льям Си́ли Го́ссет - известный учёный-статистик.
Родился 13 июня 1876

Параметрический критерий t-Стьюдента для двух независимых выборок
Метод позволяет проверить гипотезу
Параметрический критерий t-Стьюдента для двух независимых выборок
Метод позволяет проверить гипотезу
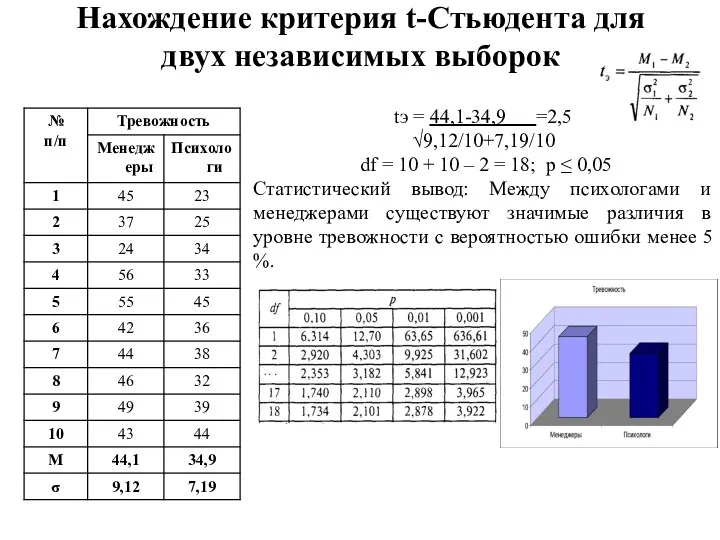
Нахождение критерия t-Стьюдента для двух независимых выборок
tэ = 44,1-34,9 =2,5
√9,12/10+7,19/10
Нахождение критерия t-Стьюдента для двух независимых выборок
tэ = 44,1-34,9 =2,5
√9,12/10+7,19/10

Критерий U-Манна-Уитни
Настоящий статистический метод был предложен Фрэнком Вилкоксоном в 1945 году.
Критерий U-Манна-Уитни
Настоящий статистический метод был предложен Фрэнком Вилкоксоном в 1945 году.

Непараметрический критерий U-Манна-Уитни для двух независимых выборок
Критерий предназначен для оценки различий
Непараметрический критерий U-Манна-Уитни для двух независимых выборок
Критерий предназначен для оценки различий

Нахождение критерия U-Манна-Уитни
Ш а г 1. Значения двух выборок объединяются в
Нахождение критерия U-Манна-Уитни
Ш а г 1. Значения двух выборок объединяются в

Тема 12. Анализ различий между 2 группами зависимых выборок
Параметрический критерий t-Стьюдента
Тема 12. Анализ различий между 2 группами зависимых выборок
Параметрический критерий t-Стьюдента

Параметрический критерий t-Стьюдента для двух зависимых выборок
Метод позволяет проверить гипотезу о
Параметрический критерий t-Стьюдента для двух зависимых выборок
Метод позволяет проверить гипотезу о
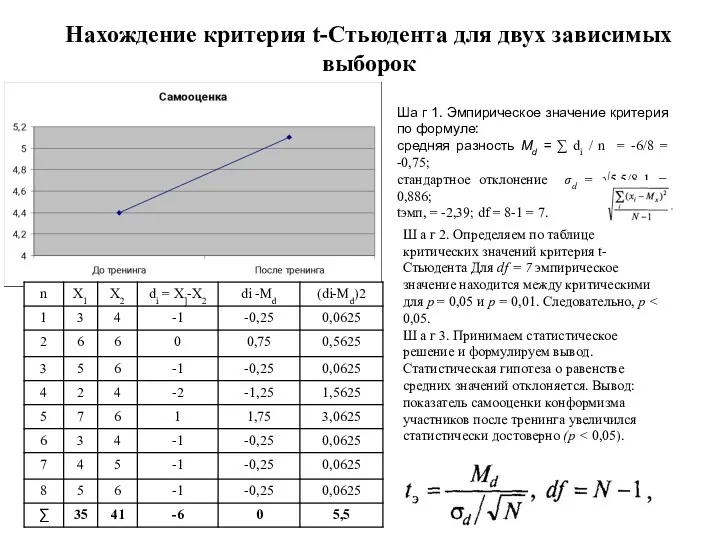
Нахождение критерия t-Стьюдента для двух зависимых выборок
Ша г 1. Эмпирическое значение
Нахождение критерия t-Стьюдента для двух зависимых выборок
Ша г 1. Эмпирическое значение

Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп
Критерий предназначен для оценки
Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп
Критерий предназначен для оценки
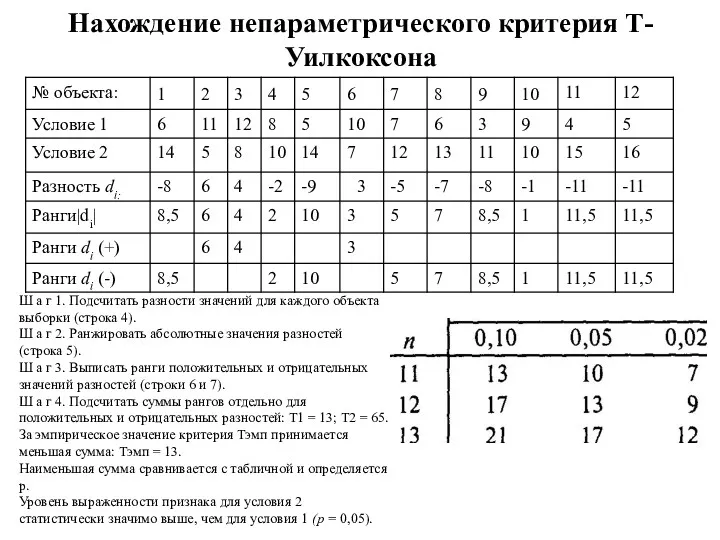
Нахождение непараметрического критерия Т-Уилкоксона
Ш а г 1. Подсчитать разности значений для
Нахождение непараметрического критерия Т-Уилкоксона
Ш а г 1. Подсчитать разности значений для

Тема 13. Анализ различий между 3 и более группами независимых выборок
Непараметрический
Тема 13. Анализ различий между 3 и более группами независимых выборок
Непараметрический

Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп
Критерий Краскала —
Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп
Критерий Краскала —

Основные положения
Критерий Н-Краскала-Уоллеса позволяет проверять гипотезы о различии более двух выборок
Основные положения
Критерий Н-Краскала-Уоллеса позволяет проверять гипотезы о различии более двух выборок

Нахождение Н-Краскала-Уоллеса
Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность
Нахождение Н-Краскала-Уоллеса
Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность

Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок
Критерий χ2-Фридмана
Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок
Критерий χ2-Фридмана

Нахождение критерия χ2-Фридмана
Шаг 1. Для каждого объекта условия ранжируются (по
Нахождение критерия χ2-Фридмана
Шаг 1. Для каждого объекта условия ранжируются (по

Тема 14. Дисперсионный анализ (ANOVA)
Однофакторный дисперсионный анализ ANOVA
Методы множественного сравнения
Тема 14. Дисперсионный анализ (ANOVA)
Однофакторный дисперсионный анализ ANOVA
Методы множественного сравнения

Дисперсионный анализ ANOVA
(от англоязычного ANalysis Of VАriance)
Анализ предназначен для
Дисперсионный анализ ANOVA
(от англоязычного ANalysis Of VАriance)
Анализ предназначен для

Последовательность вычислений для ANOVA
В общей изменчивости зависимой переменной выделяются основные
Последовательность вычислений для ANOVA
В общей изменчивости зависимой переменной выделяются основные
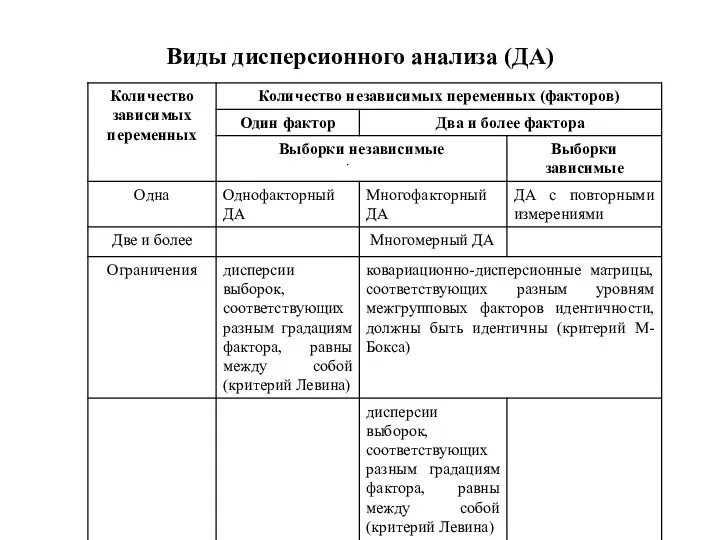
Виды дисперсионного анализа (ДА)
Виды дисперсионного анализа (ДА)
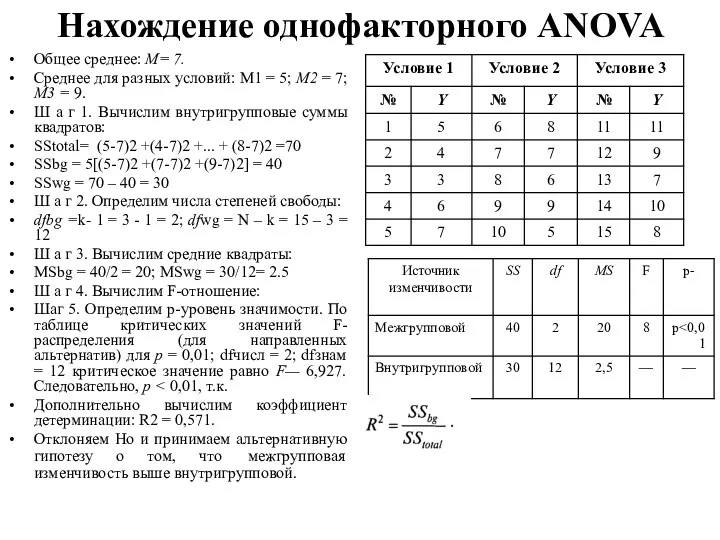
Нахождение однофакторного ANOVA
Общее среднее: М= 7.
Среднее для разных условий: М1 =
Нахождение однофакторного ANOVA
Общее среднее: М= 7.
Среднее для разных условий: М1 =
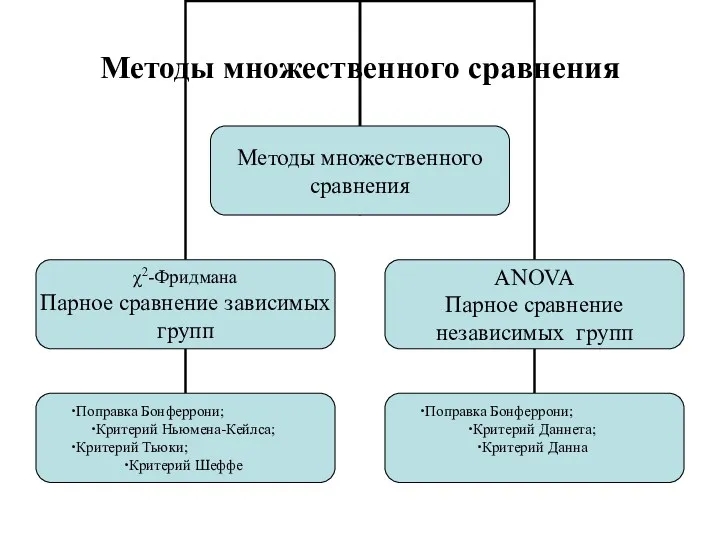
Методы множественного сравнения
Методы множественного сравнения

Тема 15. Многомерные методы
Определение и классификация многомерных методов
Регрессионный анализ (частный случай
Тема 15. Многомерные методы
Определение и классификация многомерных методов
Регрессионный анализ (частный случай

Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания
Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания
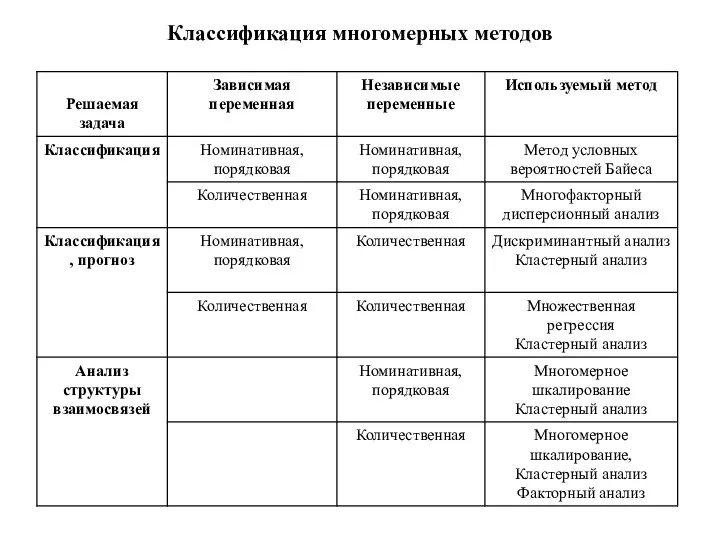
Классификация многомерных методов
Классификация многомерных методов

Регрессионный анализ (частный случай множественного регрессионного анализа)
Регрессионный анализ — основан на
Регрессионный анализ (частный случай множественного регрессионного анализа)
Регрессионный анализ — основан на

Уравнение линейной регрессии
Если переменные пропорциональны друг другу, то графически связь
Уравнение линейной регрессии
Если переменные пропорциональны друг другу, то графически связь
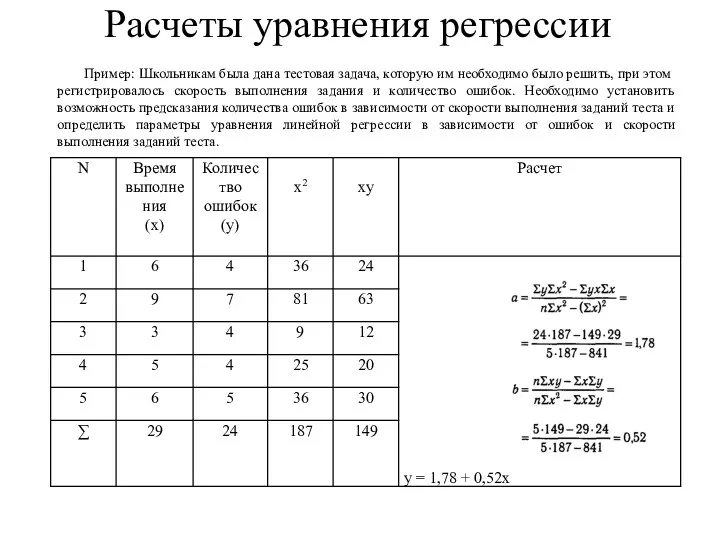
Расчеты уравнения регрессии
Пример: Школьникам была дана тестовая задача, которую им необходимо
Расчеты уравнения регрессии
Пример: Школьникам была дана тестовая задача, которую им необходимо

Множественный регрессионный анализ
Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной
Множественный регрессионный анализ
Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной

Основными целями МРА являются
Определение того, в какой мере «зависимая» переменная связана
Основными целями МРА являются
Определение того, в какой мере «зависимая» переменная связана

Дискриминантный анализ
Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у)
Дискриминантный анализ
Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у)

Основные результаты дискриминантного анализа
Определение статистической значимости различения классов при помощи
Основные результаты дискриминантного анализа
Определение статистической значимости различения классов при помощи

Факторный анализ
Главная цель факторного анализа — уменьшение размерности исходных данных.
Факторный анализ
Главная цель факторного анализа — уменьшение размерности исходных данных.

Основные этапы факторного анализа
Выбор исходных данных.
Предварительное решение проблемы числа факторов:
Основные этапы факторного анализа
Выбор исходных данных.
Предварительное решение проблемы числа факторов:

Кластерный анализ
Кластерный анализ — это процедура упорядочивания объектов в сравнительно
Кластерный анализ
Кластерный анализ — это процедура упорядочивания объектов в сравнительно

Этапы кластерного анализа
1. Отбор объектов для кластеризации. Объектами могут быть, в
Этапы кластерного анализа
1. Отбор объектов для кластеризации. Объектами могут быть, в

Многомерное шкалирование
Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества
Многомерное шкалирование
Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества

Основные этапы многомерного шкалирования
Определение величины стресса (φ-Stress), который является показателем точности
Основные этапы многомерного шкалирования
Определение величины стресса (φ-Stress), который является показателем точности

Тема 16. Математическое моделирование в психологии
Системные подходы.
Теория функциональных систем.
Становление
Тема 16. Математическое моделирование в психологии
Системные подходы.
Теория функциональных систем.
Становление

Система - множество элементов, находящихся в отношениях и связях друг с
Система - множество элементов, находящихся в отношениях и связях друг с
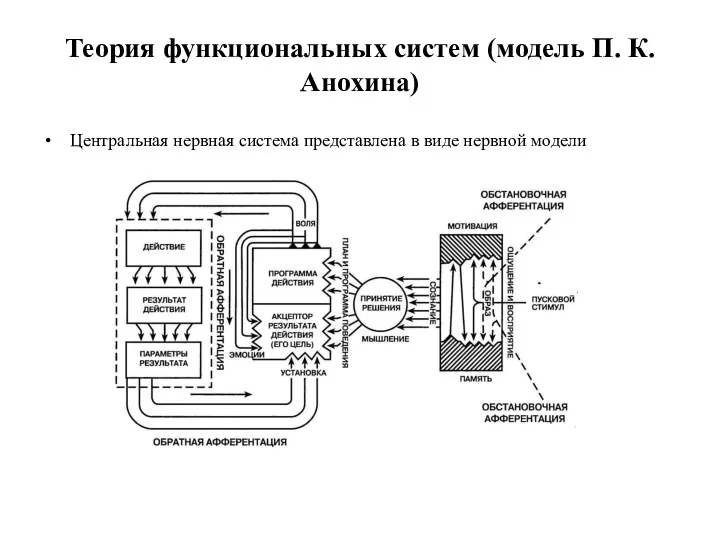
Теория функциональных систем (модель П. К. Анохина)
Центральная нервная система представлена в
Теория функциональных систем (модель П. К. Анохина)
Центральная нервная система представлена в

Кибернетика Н. Винера
Человек, один из самых сложных объектов реального мира, известных
Кибернетика Н. Винера
Человек, один из самых сложных объектов реального мира, известных

Синергетика (Г. Хакена)
По Хакену, синергетика занимается изучением систем, состоящих из большого
Синергетика (Г. Хакена)
По Хакену, синергетика занимается изучением систем, состоящих из большого

Общая теория систем Л. Фон Берталанфи
Общая теория систем Л. Фон Берталанфи
Общая теория систем Л. Фон Берталанфи
Общая теория систем Л. Фон Берталанфи

Теория развития И.Р. Пригожина
Теория развития И.Р. Пригожина гласит, что если отток
Теория развития И.Р. Пригожина
Теория развития И.Р. Пригожина гласит, что если отток
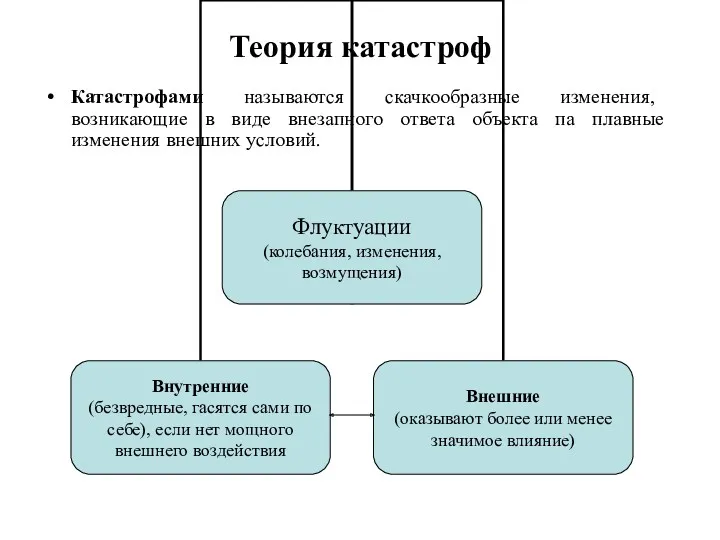
Теория катастроф
Катастрофами называются скачкообразные изменения, возникающие в виде внезапного ответа объекта
Теория катастроф
Катастрофами называются скачкообразные изменения, возникающие в виде внезапного ответа объекта

Системный анализ
Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных
Системный анализ
Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных

Моделирование сложных систем
Этапы моделирования сложных процессов и явлений:
Формулировка цели моделирования.
Анализ объекта
Моделирование сложных систем
Этапы моделирования сложных процессов и явлений:
Формулировка цели моделирования.
Анализ объекта
Метод моделирования в психодиагностике
Метод моделирования в психодиагностике

Тема 17. Анализ данных на компьютере.
Использование MS Excel
Статистические пакеты:
Тема 17. Анализ данных на компьютере.
Использование MS Excel
Статистические пакеты:
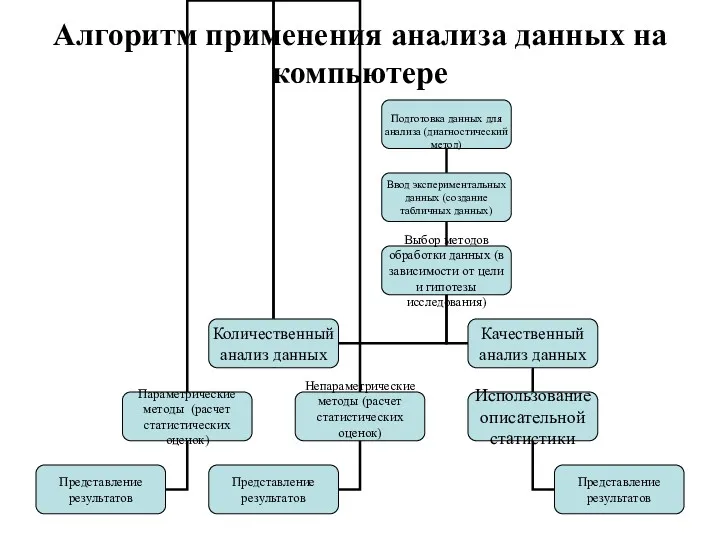
Алгоритм применения анализа данных на компьютере
Алгоритм применения анализа данных на компьютере
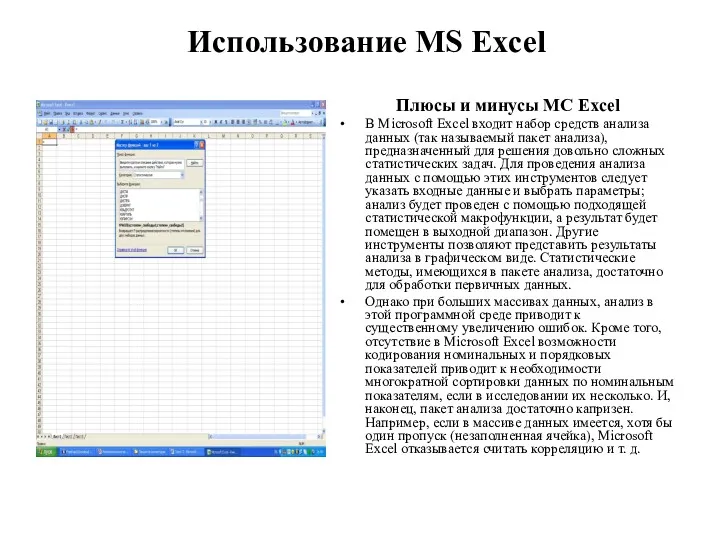
Использование MS Excel
Плюсы и минусы MC Excel
В Microsoft Excel входит
Использование MS Excel
Плюсы и минусы MC Excel
В Microsoft Excel входит

Статистические пакеты: SPSS, STATISTICA
STATISTICA for Windows представляет собой интегрированную систему
Статистические пакеты: SPSS, STATISTICA
STATISTICA for Windows представляет собой интегрированную систему
 Матрицы и действия над ними
Матрицы и действия над ними Производная. Устные упражнения
Производная. Устные упражнения Памятка по оформлению краткой записи к задачам
Памятка по оформлению краткой записи к задачам Закрепление пройденного материала. Математика урок-игра 3 класс
Закрепление пройденного материала. Математика урок-игра 3 класс Деление двузначного числа на двузначное. Математика. 3 класс.
Деление двузначного числа на двузначное. Математика. 3 класс. Презентация к уроку математики Сложение и вычитание в пределах 20
Презентация к уроку математики Сложение и вычитание в пределах 20 Метод замены множителей
Метод замены множителей Компланарные векторы. Правило параллелепипеда
Компланарные векторы. Правило параллелепипеда Умножение многозначных чисел на двузначные
Умножение многозначных чисел на двузначные Кривые второго порядка
Кривые второго порядка Методы исследования математических моделей
Методы исследования математических моделей Признак перпендикулярности прямой и плоскости. (10 класс)
Признак перпендикулярности прямой и плоскости. (10 класс) Развитие интереса у детей к математике (проектная деятельность на уроке математики и вне его)
Развитие интереса у детей к математике (проектная деятельность на уроке математики и вне его) Турнир знатоков математики
Турнир знатоков математики Десятичные дроби. 5 класс
Десятичные дроби. 5 класс Основное свойство дроби. Сокращение дробей
Основное свойство дроби. Сокращение дробей Функции y = tgx и y = ctgx, их свойства и графики
Функции y = tgx и y = ctgx, их свойства и графики Герои сказок на уроке.
Герои сказок на уроке. Сравнение, сложение и вычитание десятичных дробей
Сравнение, сложение и вычитание десятичных дробей Тренажёр В гости к Мудрой сове (Математика, 1 класс)
Тренажёр В гости к Мудрой сове (Математика, 1 класс) презентация к уроку по теме Магия числа 7
презентация к уроку по теме Магия числа 7 урок математики в 3 классе Умножение многозначного на однозначное число по программе Начальная школа 21 век
урок математики в 3 классе Умножение многозначного на однозначное число по программе Начальная школа 21 век Системы рациональных неравенств. 9 класс
Системы рациональных неравенств. 9 класс Раскрытие скобок и приведение подобных слагаемых
Раскрытие скобок и приведение подобных слагаемых Выборочный метод
Выборочный метод Магические квадраты
Магические квадраты Прямая.Отрезок.Луч
Прямая.Отрезок.Луч Цена, количество, стоимость. Решение задач
Цена, количество, стоимость. Решение задач