- Первичные описательные статистики

Содержание
- 2. Меры центральной тенденции Мера центральной тенденции (Central Tendency) - это число, характеризующее выборку по уровню выраженности
- 3. Меры центральной тенденции Мода (Mode) - это такое значение из множества измерений, которое встречается наиболее часто.
- 4. Если выборка содержит две моды, то распределение называется бимодальным. Пример: массив {3, 3, 5, 1, 4,
- 6. Когда все значения в выборке встречаются одинаково часто принято считать что этот выборочный ряд не имеет
- 7. Для интервального ряда распределения мода определяется по формуле: где ХMo - нижняя граница модального интервала; hMo
- 8. Например: Распределение учителей по стажу работы характеризуется следующими данными. Определить моду интервального ряда распределения. Мода интервального
- 9. Графический способ определение моды для интервального ряда (закупка учебников)
- 10. Меры центральной тенденции Медиана (Median, Md или Me) - это такое значение признака, которое делит упорядоченное
- 11. Чтобы определить медиану для сгруппированных данных, необходимо считать накопленные частоты. Например: По имеющимся данным определим медиану
- 12. Среднее (Mean) (Мх или - выборочное среднее, среднее арифметическое) - определяется как сумма всех значений измеренного
- 13. Выбор меры центральной тенденции Для номинативных данных единственной подходящей мерой центральной тенденции является мода. Для порядковых
- 14. Выбор меры центральной тенденции Выборочные средние можно сравнивать, если выполняются следующие условия: группы достаточно большие, чтобы
- 15. Меры изменчивости Используя для описания ряда значений признака, только меру центральной тенденции, можно сильно ошибиться в
- 16. Способы определения выраженности индивидуальных различий: Размах Дисперсия Стандартное отклонение Коэффициент вариации
- 17. Наиболее простой мерой изменчивости является размах, указывающий на диапазон изменчивости значений. Размах (Range) - это разность
- 18. Меры изменчивости Дисперсия (S2, Dx) (Variance) - мера изменчивости для метрических данных относительно среднего значения. Дисперсия
- 19. Пример вычисления дисперсии х = 18/6 = 3 D= 12/(6-1) = 2,4 Если значение измеренного признака
- 20. СТАНДАРТНОЕ ОТКЛОНЕНИЕ (S,σ) - (Std. deviation) (сигма, среднеквадратическое отклонение) Положительное значение квадратного корня из дисперсии: На
- 21. Из всех показателей вариации среднеквадратическое отклонение в наибольшей степени используется для проведения других видов статистического анализа.
- 22. В статистике принято, что, если коэффициент вариации меньше 10%, то степень рассеивания данных считается незначительной, от
- 24. Скачать презентацию

Меры центральной тенденции
Мера центральной тенденции (Central Tendency) - это число, характеризующее
Меры центральной тенденции
Мера центральной тенденции (Central Tendency) - это число, характеризующее

Меры центральной тенденции
Мода (Mode) - это такое значение из множества измерений,
Меры центральной тенденции
Мода (Mode) - это такое значение из множества измерений,

Если выборка содержит две моды, то распределение называется бимодальным.
Пример: массив
Если выборка содержит две моды, то распределение называется бимодальным.
Пример: массив


Когда все значения в выборке встречаются одинаково часто принято считать что
Когда все значения в выборке встречаются одинаково часто принято считать что
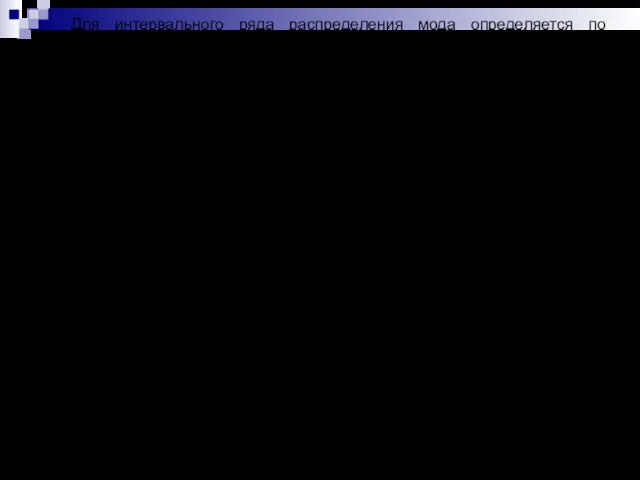
Для интервального ряда распределения мода определяется по формуле:
где ХMo - нижняя
Для интервального ряда распределения мода определяется по формуле:
где ХMo - нижняя

Например: Распределение учителей по стажу работы характеризуется следующими данными.
Определить моду интервального
Например: Распределение учителей по стажу работы характеризуется следующими данными.
Определить моду интервального
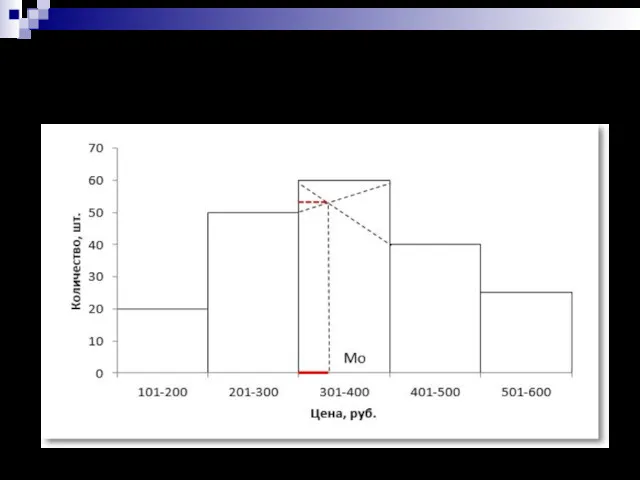
Графический способ определение моды для интервального ряда (закупка учебников)
Графический способ определение моды для интервального ряда (закупка учебников)

Меры центральной тенденции
Медиана (Median, Md или Me) - это такое значение
Меры центральной тенденции
Медиана (Median, Md или Me) - это такое значение

Чтобы определить медиану для сгруппированных данных, необходимо считать накопленные частоты.
Например: По
Чтобы определить медиану для сгруппированных данных, необходимо считать накопленные частоты. Например: По
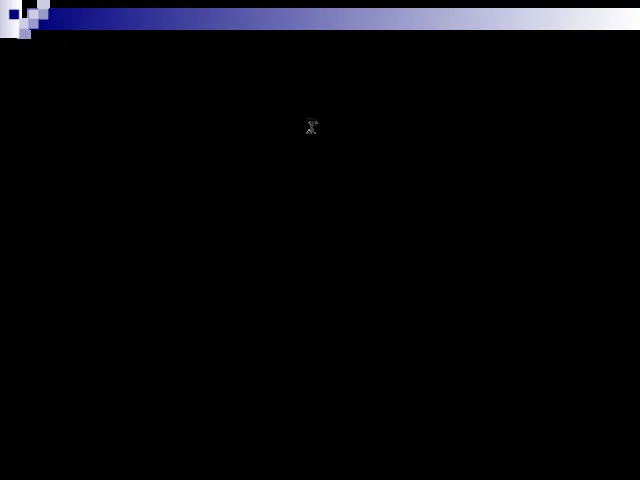
Среднее (Mean) (Мх или - выборочное среднее, среднее арифметическое) - определяется
Среднее (Mean) (Мх или - выборочное среднее, среднее арифметическое) - определяется

Выбор меры центральной тенденции
Для номинативных данных единственной подходящей мерой центральной тенденции
Выбор меры центральной тенденции
Для номинативных данных единственной подходящей мерой центральной тенденции

Выбор меры центральной тенденции
Выборочные средние можно сравнивать, если выполняются следующие условия:
группы
Выбор меры центральной тенденции
Выборочные средние можно сравнивать, если выполняются следующие условия:
группы

Меры изменчивости
Используя для описания ряда значений признака, только меру центральной тенденции,
Меры изменчивости
Используя для описания ряда значений признака, только меру центральной тенденции,

Способы определения выраженности индивидуальных различий:
Размах
Дисперсия
Стандартное отклонение
Коэффициент вариации
Способы определения выраженности индивидуальных различий:
Размах
Дисперсия
Стандартное отклонение
Коэффициент вариации

Наиболее простой мерой изменчивости является размах, указывающий на диапазон изменчивости значений.
Наиболее простой мерой изменчивости является размах, указывающий на диапазон изменчивости значений.

Меры изменчивости
Дисперсия (S2, Dx) (Variance) - мера изменчивости для метрических данных
Меры изменчивости
Дисперсия (S2, Dx) (Variance) - мера изменчивости для метрических данных
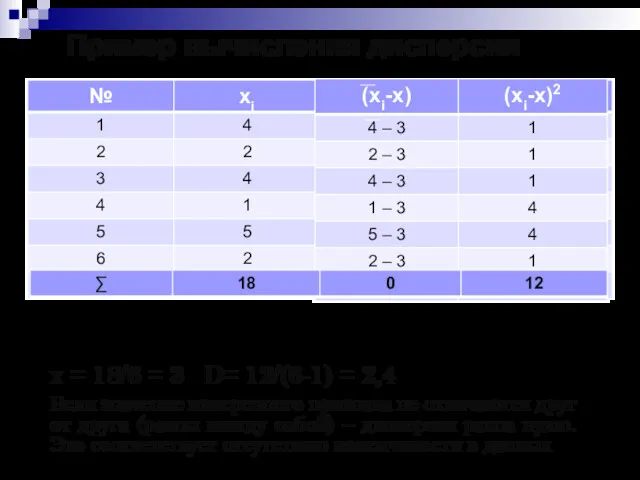
Пример вычисления дисперсии
х = 18/6 = 3 D= 12/(6-1) = 2,4
Пример вычисления дисперсии
х = 18/6 = 3 D= 12/(6-1) = 2,4

СТАНДАРТНОЕ ОТКЛОНЕНИЕ (S,σ) - (Std. deviation) (сигма, среднеквадратическое отклонение)
Положительное значение квадратного
СТАНДАРТНОЕ ОТКЛОНЕНИЕ (S,σ) - (Std. deviation) (сигма, среднеквадратическое отклонение)
Положительное значение квадратного

Из всех показателей вариации среднеквадратическое отклонение в наибольшей степени используется для
Из всех показателей вариации среднеквадратическое отклонение в наибольшей степени используется для

В статистике принято, что, если коэффициент вариации меньше 10%, то степень
В статистике принято, что, если коэффициент вариации меньше 10%, то степень
 Жизнь Пифагора
Жизнь Пифагора Конкретный смысл действия деления
Конкретный смысл действия деления Задачи на кратное сравнение
Задачи на кратное сравнение Урок математики Нахождение дроби от числа 6 класс
Урок математики Нахождение дроби от числа 6 класс Прямая и плоскость
Прямая и плоскость Деление обыкновенных дробей
Деление обыкновенных дробей Урок математики Закрепление изученного материала. Зимняя олимпиада в Сочи.
Урок математики Закрепление изученного материала. Зимняя олимпиада в Сочи. Линейная функция y = k∙x + b и её график
Линейная функция y = k∙x + b и её график Ромб и его свойства (8 класс)
Ромб и его свойства (8 класс) Задачи и методы оптимального планирования
Задачи и методы оптимального планирования История возникновения и развития геометрии
История возникновения и развития геометрии Числовые выражения. Буквенные выражения
Числовые выражения. Буквенные выражения Формулы сокращённого умножения. Урок обобщения знаний
Формулы сокращённого умножения. Урок обобщения знаний Деление двузначного числа на двузначное. Математика. 3 класс.
Деление двузначного числа на двузначное. Математика. 3 класс. Комбинаторика. Перестановки. Дискретный анализ. Лекция 3
Комбинаторика. Перестановки. Дискретный анализ. Лекция 3 Составная задача на нахождение неизвестного вычитаемого
Составная задача на нахождение неизвестного вычитаемого Презентация к уроку математика.3 класс.УМК Перспектива.
Презентация к уроку математика.3 класс.УМК Перспектива. Игра-тренажер Собери букет
Игра-тренажер Собери букет Арифметический корень
Арифметический корень Второй признак равенства треугольников. Решение задач
Второй признак равенства треугольников. Решение задач Умножение положительных и отрицательных чисел
Умножение положительных и отрицательных чисел Конспект урока математики 3 класс Закрепление темы: Таблица умножения на 2,3,4,5,6. Решение задач
Конспект урока математики 3 класс Закрепление темы: Таблица умножения на 2,3,4,5,6. Решение задач Теорема Пифагора
Теорема Пифагора Решение уравнений
Решение уравнений Планирование эксперимента в научных исследованиях. Цели, задачи, основные понятия статистики. (Лекция 4)
Планирование эксперимента в научных исследованиях. Цели, задачи, основные понятия статистики. (Лекция 4) Презентация к уроку математики 3 класс на тему Умножение трехзначного числа на однозначное
Презентация к уроку математики 3 класс на тему Умножение трехзначного числа на однозначное Особенности подготовки учащихся по математике к ОГЭ
Особенности подготовки учащихся по математике к ОГЭ Тест по теме: Скалярное произведение векторов. Теоремы треугольника
Тест по теме: Скалярное произведение векторов. Теоремы треугольника