- Понятие эксперимента. Классификация видов экспериментальных исследований

Содержание
- 2. МЕТОДЫ ПЛАНИРОВАНИЯ И ОБРАБОТКИ РЕЗУЛЬТАТОВ ИНЖЕНЕРНОГО ЭКСПЕРИМЕНТА Спирин Н.А., Лавров В.В., Зайнуллин Л.А., Бондин А.Р., Бурыкин
- 3. ПОНЯТИЕ ЭКСПЕРИМЕНТА Термину эксперимент устанавливается следующее определение – система операций, воздействий и (или) наблюдений, направленных на
- 4. КЛАССИФИКАЦИЯ ВИДОВ ЭКСПЕРИМЕНТАЛЬНЫХ ИССЛЕДОВАНИЙ Качественный эксперимент устанавливает только сам факт существования какого-либо явления, но при этом
- 5. По тому, какой группой факторов располагает исследователь, количественный эксперимент в свою очередь можно разделить еще на
- 6. Полностью свойства случайной законом ее распределения, под которым понимают связь между возможными значениями случайной величины и
- 7. Плотность распределения f(x) – первая производная функции распределения. 1. Плотность распределения вероятностей является неотрицательной функцией, 2.
- 8. Параметр распределения – постоянная, от которой зависит функция распределения. Математическое ожидание Mx – среднее взвешенное по
- 9. Нормальный закон распределения Центральная предельная теорема математической статистики, «при определенных условиях распределение нормированной суммы n независимых
- 10. Значения нормированной функции нормального распределения (функции и значения плотности нормированного нормального распределения табулированы и приведены в
- 11. Отличие какого-либо из значений случайной величины с нормальным законом распределения от ее математического ожидания не превосходит
- 12. Вычисление параметров эмпирических распределений. Точечное оценивание . Наблюдаемая единица – действительный или условный предмет, над которым
- 13. Оценивание с помощью доверительного интервала Доверительный интервал – интервал, который с заданной вероятностью накроет неизвестное значение
- 14. Оценивание с помощью доверительного интервала (продолжение)
- 15. На практике, как правило, число измерений (например, отбора проб шихты, чугуна, стали и других материалов) конечно
- 16. Построение доверительного интервала для дисперсии доверительный интервал для дисперсии σx2 с доверительной вероятностью P= P2 -
- 17. Статистические гипотезы Статистическая гипотеза – любое предположение, касающееся неизвестного распределения случайной величины. Статистические гипотезы можно разделить
- 18. Проверка любой статистической гипотезы в самом общем случае заключается в следующем: формулирование нулевой гипотезы Н0; выбор
- 19. Отсев грубых погрешностей Результаты наблюдений располагают в возрастающей последовательности x1≤ x2≤ x3 ... ≤ xi …≤xn
- 20. Сравнение двух рядов наблюдений. Сравнение двух дисперсий Требуется установить, являются ли выборочные дисперсии S12 ≠ S22
- 21. Проверка однородности нескольких дисперсий
- 22. Проверка гипотез о числовых значениях математических ожиданий Для двух нормально распределенных генеральных совокупностей с неизвестными параметрами
- 23. Проверка гипотез о числовых значениях математических ожиданий (продолжение)
- 24. Проверка гипотез о виде функции распределения Нулевая гипотеза в данном случае заключается в том, что Н0:-
- 25. Проверка гипотез о виде функции распределения
- 26. Критерий Пирсона
- 27. Критерий Пирсона (продолжение) ХИ2.ОБР.ПХ(α;m) из электронных таблиц Microsoft Excel
- 32. АНАЛИЗ РЕЗУЛЬТАТОВ ПАССИВНОГО ЭКСПЕРИМЕНТА. ЭМПИРИЧЕСКИЕ ЗАВИСИМОСТИ Виды связей: а – функциональная связь, все точки лежат на
- 34. Определение коэффициентов уравнения регрессии В данном случае число независимых уравнений системы равно числу опорных точек, в
- 35. Метод избранных точек Если предполагается, что уравнение регрессии более высокого порядка, то соответственно увеличивают число избранных
- 36. Второй подход – метод наименьших квадратов
- 37. Определение тесноты связи между случайными величинами Тесноту связи между случайными величинами характеризуют корреляционным отношением ρxy. Остаточная
- 38. а – функциональная связь; б – отсутствие связи Разброс экспериментально наблюдаемых точек относительно линии регрессии характеризуется
- 39. Линейная регрессия от одного фактора Система нормальных уравнений в этом случае примет вид Решение этой системы
- 40. Оценку силы линейной связи осуществляют по выборочному (эмпирическому) коэффициенту парной корреляции rxy. Выборочный коэффициент корреляции может
- 41. Отметим еще раз область применимости выборочного коэффициента корреляции для оценки тесноты связи. 1. Коэффициент парной корреляции
- 43. Регрессионный анализ При проведении регрессионного анализа примем следующие допущения: 1) входной параметр x измеряется с пренебрежимо
- 44. Проверка адекватности модели Сформулируем нуль-гипотезу Н0: "Уравнение регрессии адекватно". Альтернативная гипотеза Н1: "Уравнение регрессии неадекватно". Для
- 46. Проверка значимости коэффициентов уравнения регрессии
- 47. МЕТОДЫ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТОВ. ЛОГИЧЕСКИЕ ОСНОВЫ
- 48. Общая последовательность активного эксперимента
- 49. Пример хорошего и плохого эксперимента Традиционное проведение эксперимента*) Когда образец кладется на весы, в таблице ставится
- 50. Методы планирования экспериментов
- 51. Планирование первого порядка Выбор основных факторов В качестве факторов можно выбирать только контролируемые и управляемые переменные,
- 52. Таблица полного факторного эксперимента для трех факторов 1) свойство симметричности: алгебраическая сумма элементов вектор-столбца каждого фактора
- 53. В теории планирования экспериментов показано, что необходимое число уровней факторов на единицу больше порядка уравнения. После
- 54. Определение коэффициентов уравнения регрессии
- 55. Определение коэффициентов уравнения регрессии (продолжение)
- 56. Статистический анализ результатов эксперимента
- 57. Оценки значимости коэффициентов уравнения регрессии
- 58. Адекватность модели
- 59. Дробный факторный эксперимент
- 61. Дробную реплику, в которой Р линейных эффектов приравнены к эффектам взаимодействия, обозначают 2k-P. Таким образом, планы
- 62. Планы второго порядка В этом случае требуется, чтобы каждый фактор варьировался не менее чем на трех
- 63. Так, при двух факторах модель функции отклика y = f(x1,x2) второго порядка представляет собой поверхность в
- 64. Таким образом, в общем случае ядро композиционного плана составляет при k 1) добавить 2⋅k звездных точек,
- 65. Ортогональные планы второго порядка В общем виде план, представленный в табл. неортогонален, так как Приведем его
- 66. В этой таблице Ортогональный план второго порядка для k=2 и n0=1 Представленный на рис. и в
- 67. Ортогональные планы второго порядка (продолжение)
- 68. Исследование причин образования расслоений в горячекатаных листах Известно, что при прокатке листов толщиной более 12 мм
- 69. Ортогональный план второго порядка для двух факторов и с тремя опытами в центре плана
- 70. Матрица ортогонального плана второго порядка в кодированных значениях
- 71. Величина квадратов кодированных значений факторов Таблица произведений кодированных значений факторов на значения отклика
- 72. Расчет коэффициентов модели
- 73. Оценка значимости коэффициентов
- 74. Оценка адекватности модели
- 75. Оценка оптимальных значений параметров
- 76. Ортогональные планы второго порядка (продолжение)
- 77. Ротатабельные планы второго порядка Как мы установили, план второго порядка, представленный в табл., не обладает свойством
- 78. Бокс и Хантер предложили ротатабельные планы 2-го порядка. Для того чтобы композиционный план был ротатабельным, величину
- 79. Ротатабельные планы второго порядка (продолжение) Поясним идею выбора значения звездного плеча α на примере матрицы ротатабельного
- 80. Матрица ротатабельного планирования, оказывается неортогональной, так как Следовательно, если какой-либо из квадратичных эффектов оказался незначимым, то
- 81. Если модель второго порядка оказалась неадекватной, следует: Повторить эксперименты на меньшем интервале варьирования факторов. Перенести центр
- 82. Планирование экспериментов при поиске оптимальных условий Во многих случаях инженерной практики перед исследователем возникает задача не
- 83. На модели шахтной печи с противоточно движущимся плотным продуваемым слоем, схема которой представлена на рис., требуется
- 84. Известный из практики метод "проб" и "ошибок", в котором факторы изменяются на основании опыта, интуиции или
- 85. Метод покоординатной оптимизации По этому методу выбирается произвольная точка М0 и определяются ее координаты. Поиск оптимума
- 86. Метод крутого восхождения Известно, что кратчайший, наиболее короткий путь — это движение по градиенту, т.е. перпендикулярно
- 87. Метод крутого восхождения. Продолжение
- 88. Метод крутого восхождения. Продолжение
- 89. Симплексный метод планирования Метод симплексного планирования позволяет без предварительного изучения влияния факторов найти область оптимума. В
- 90. По итогам проведения опытов 1, 2 и 3 худшим оказался опыт 3. Следующий опыт ставится в
- 91. Выбор размеров симплекса и его начального положения в известной степени произволен. Для построения начального симплекса значения
- 97. Скачать презентацию

МЕТОДЫ ПЛАНИРОВАНИЯ И ОБРАБОТКИ РЕЗУЛЬТАТОВ ИНЖЕНЕРНОГО ЭКСПЕРИМЕНТА
Спирин Н.А., Лавров В.В., Зайнуллин
МЕТОДЫ ПЛАНИРОВАНИЯ И ОБРАБОТКИ РЕЗУЛЬТАТОВ ИНЖЕНЕРНОГО ЭКСПЕРИМЕНТА Спирин Н.А., Лавров В.В., Зайнуллин

ПОНЯТИЕ ЭКСПЕРИМЕНТА
Термину эксперимент устанавливается следующее определение – система операций, воздействий и
ПОНЯТИЕ ЭКСПЕРИМЕНТА
Термину эксперимент устанавливается следующее определение – система операций, воздействий и

КЛАССИФИКАЦИЯ ВИДОВ ЭКСПЕРИМЕНТАЛЬНЫХ ИССЛЕДОВАНИЙ
Качественный эксперимент устанавливает только сам факт существования
КЛАССИФИКАЦИЯ ВИДОВ ЭКСПЕРИМЕНТАЛЬНЫХ ИССЛЕДОВАНИЙ
Качественный эксперимент устанавливает только сам факт существования

По тому, какой группой факторов располагает исследователь, количественный эксперимент в свою
По тому, какой группой факторов располагает исследователь, количественный эксперимент в свою
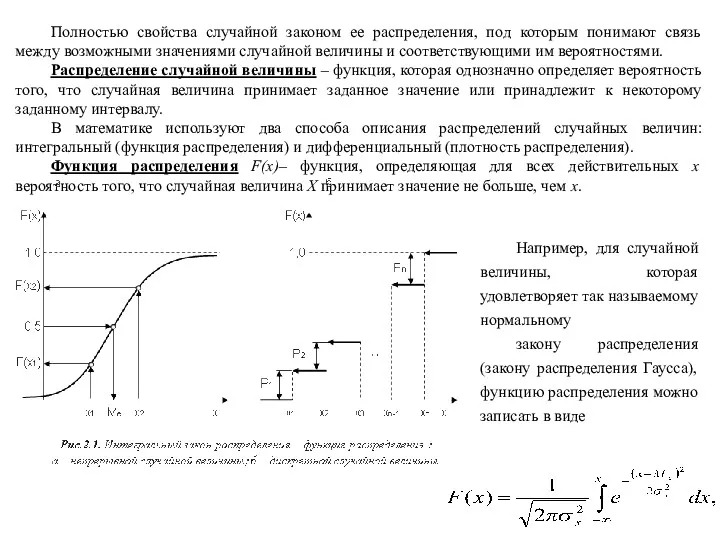
Полностью свойства случайной законом ее распределения, под которым понимают связь между
Полностью свойства случайной законом ее распределения, под которым понимают связь между
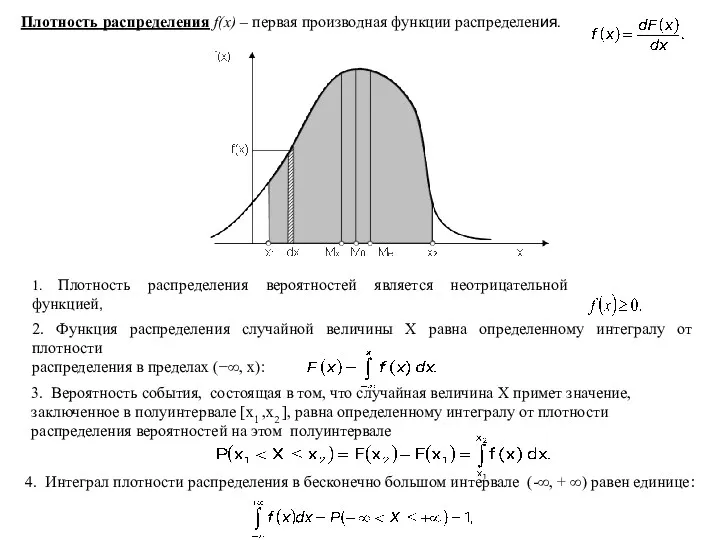
Плотность распределения f(x) – первая производная функции распределения.
1. Плотность распределения вероятностей
Плотность распределения f(x) – первая производная функции распределения.
1. Плотность распределения вероятностей

Параметр распределения – постоянная, от которой зависит функция распределения.
Математическое ожидание Mx
Параметр распределения – постоянная, от которой зависит функция распределения.
Математическое ожидание Mx
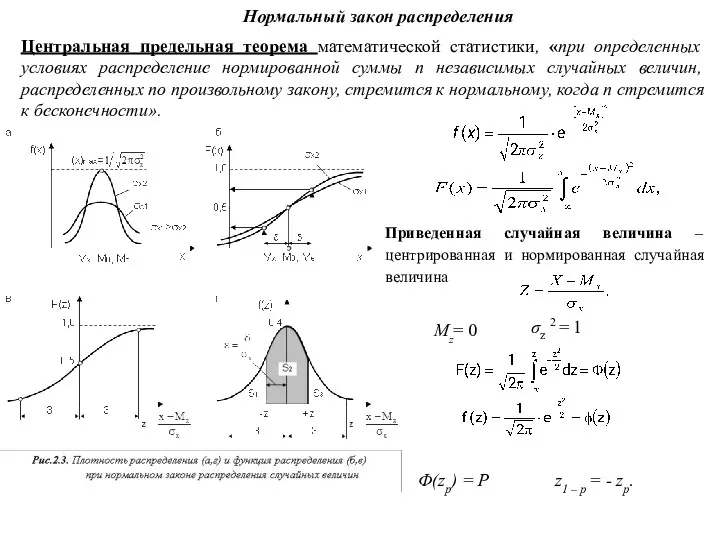
Нормальный закон распределения
Центральная предельная теорема математической статистики, «при определенных условиях распределение
Нормальный закон распределения
Центральная предельная теорема математической статистики, «при определенных условиях распределение

Значения нормированной функции нормального распределения (функции и значения плотности нормированного нормального
Значения нормированной функции нормального распределения (функции и значения плотности нормированного нормального

Отличие какого-либо из значений случайной величины с нормальным законом распределения от
Отличие какого-либо из значений случайной величины с нормальным законом распределения от

Вычисление параметров эмпирических распределений. Точечное оценивание
.
Наблюдаемая единица – действительный или
Вычисление параметров эмпирических распределений. Точечное оценивание
.
Наблюдаемая единица – действительный или

Оценивание с помощью доверительного интервала
Доверительный интервал – интервал, который с заданной
Оценивание с помощью доверительного интервала
Доверительный интервал – интервал, который с заданной

Оценивание с помощью доверительного интервала (продолжение)
Оценивание с помощью доверительного интервала (продолжение)

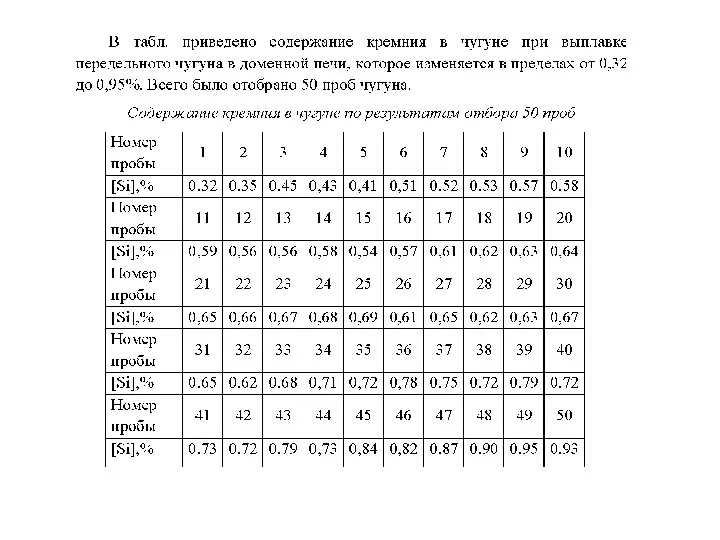
На практике, как правило, число измерений (например, отбора проб шихты, чугуна,
На практике, как правило, число измерений (например, отбора проб шихты, чугуна,

Построение доверительного интервала для дисперсии
доверительный интервал для дисперсии σx2 с доверительной
Построение доверительного интервала для дисперсии
доверительный интервал для дисперсии σx2 с доверительной

Статистические гипотезы
Статистическая гипотеза – любое предположение, касающееся неизвестного распределения случайной величины.
Статистические
Статистические гипотезы
Статистическая гипотеза – любое предположение, касающееся неизвестного распределения случайной величины.
Статистические

Проверка любой статистической гипотезы в самом общем случае заключается в следующем:
формулирование
Проверка любой статистической гипотезы в самом общем случае заключается в следующем:
формулирование

Отсев грубых погрешностей
Результаты наблюдений располагают в возрастающей последовательности
x1≤ x2≤ x3
Отсев грубых погрешностей
Результаты наблюдений располагают в возрастающей последовательности
x1≤ x2≤ x3

Сравнение двух рядов наблюдений. Сравнение двух дисперсий
Требуется установить, являются ли
Сравнение двух рядов наблюдений. Сравнение двух дисперсий
Требуется установить, являются ли

Проверка однородности нескольких дисперсий
Проверка однородности нескольких дисперсий

Проверка гипотез о числовых значениях математических ожиданий
Для двух нормально распределенных генеральных
Проверка гипотез о числовых значениях математических ожиданий
Для двух нормально распределенных генеральных

Проверка гипотез о числовых значениях математических ожиданий (продолжение)
Проверка гипотез о числовых значениях математических ожиданий (продолжение)

Проверка гипотез о виде функции распределения
Нулевая гипотеза в данном случае заключается
Проверка гипотез о виде функции распределения
Нулевая гипотеза в данном случае заключается
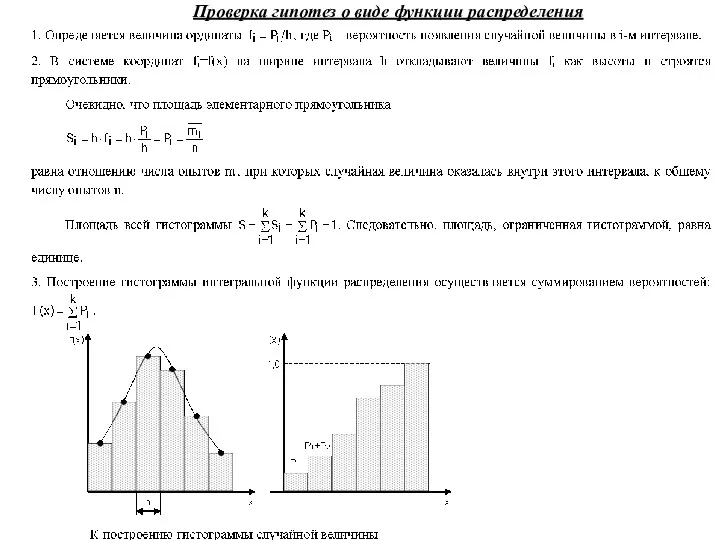
Проверка гипотез о виде функции распределения
Проверка гипотез о виде функции распределения

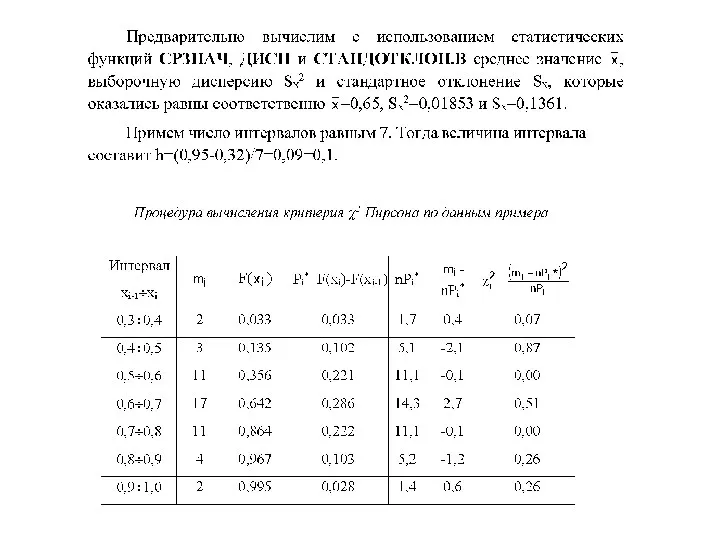
Критерий Пирсона
Критерий Пирсона

Критерий Пирсона (продолжение)
ХИ2.ОБР.ПХ(α;m) из электронных таблиц Microsoft Excel
Критерий Пирсона (продолжение)
ХИ2.ОБР.ПХ(α;m) из электронных таблиц Microsoft Excel



АНАЛИЗ РЕЗУЛЬТАТОВ ПАССИВНОГО ЭКСПЕРИМЕНТА.
ЭМПИРИЧЕСКИЕ ЗАВИСИМОСТИ
Виды связей: а – функциональная связь,
АНАЛИЗ РЕЗУЛЬТАТОВ ПАССИВНОГО ЭКСПЕРИМЕНТА.
ЭМПИРИЧЕСКИЕ ЗАВИСИМОСТИ
Виды связей: а – функциональная связь,


Определение коэффициентов уравнения регрессии
В данном случае число независимых уравнений системы равно
Определение коэффициентов уравнения регрессии
В данном случае число независимых уравнений системы равно
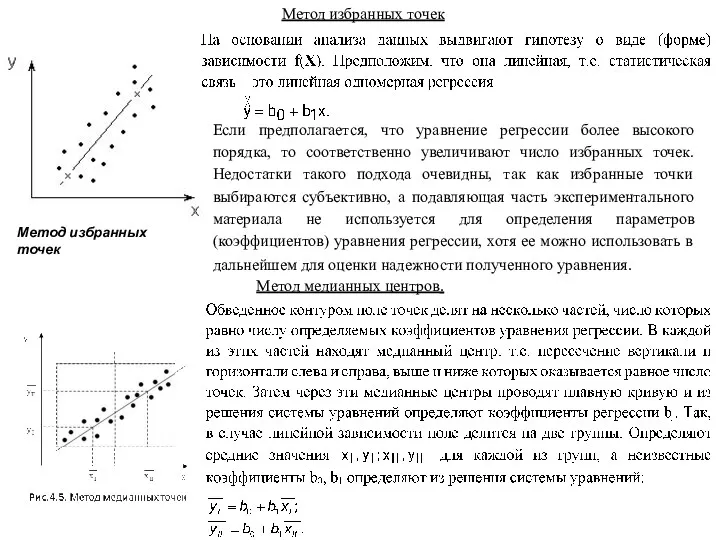
Метод избранных точек
Если предполагается, что уравнение регрессии более высокого порядка,
Метод избранных точек
Если предполагается, что уравнение регрессии более высокого порядка,

Второй подход – метод наименьших квадратов
Второй подход – метод наименьших квадратов

Определение тесноты связи между случайными величинами
Тесноту связи между случайными величинами характеризуют
Определение тесноты связи между случайными величинами
Тесноту связи между случайными величинами характеризуют

а – функциональная связь; б – отсутствие связи
Разброс экспериментально наблюдаемых точек
а – функциональная связь; б – отсутствие связи
Разброс экспериментально наблюдаемых точек

Линейная регрессия от одного фактора
Система нормальных уравнений в этом случае примет
Линейная регрессия от одного фактора
Система нормальных уравнений в этом случае примет

Оценку силы линейной связи осуществляют по выборочному (эмпирическому) коэффициенту парной корреляции
Оценку силы линейной связи осуществляют по выборочному (эмпирическому) коэффициенту парной корреляции

Отметим еще раз область применимости выборочного коэффициента корреляции для оценки тесноты
Отметим еще раз область применимости выборочного коэффициента корреляции для оценки тесноты


Регрессионный анализ
При проведении регрессионного анализа примем следующие допущения:
1) входной параметр
Регрессионный анализ
При проведении регрессионного анализа примем следующие допущения:
1) входной параметр

Проверка адекватности модели
Сформулируем нуль-гипотезу
Н0: "Уравнение регрессии адекватно".
Альтернативная гипотеза Н1:
Проверка адекватности модели
Сформулируем нуль-гипотезу
Н0: "Уравнение регрессии адекватно".
Альтернативная гипотеза Н1:


Проверка значимости коэффициентов уравнения регрессии
Проверка значимости коэффициентов уравнения регрессии

МЕТОДЫ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТОВ.
ЛОГИЧЕСКИЕ ОСНОВЫ
МЕТОДЫ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТОВ.
ЛОГИЧЕСКИЕ ОСНОВЫ

Общая последовательность активного эксперимента
Общая последовательность активного эксперимента

Пример хорошего и плохого эксперимента
Традиционное проведение эксперимента*) Когда образец кладется
Пример хорошего и плохого эксперимента
Традиционное проведение эксперимента*) Когда образец кладется

Методы планирования экспериментов
Методы планирования экспериментов

Планирование первого порядка
Выбор основных факторов
В качестве факторов можно выбирать только
Планирование первого порядка
Выбор основных факторов
В качестве факторов можно выбирать только
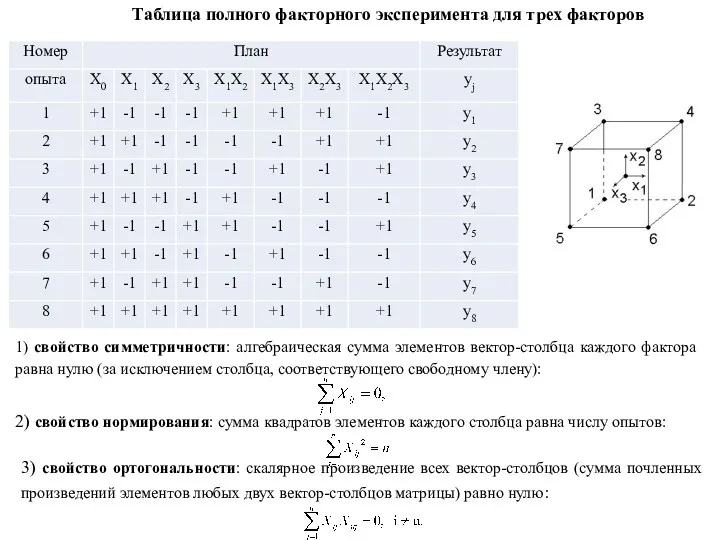
Таблица полного факторного эксперимента для трех факторов
1) свойство симметричности: алгебраическая сумма
Таблица полного факторного эксперимента для трех факторов
1) свойство симметричности: алгебраическая сумма

В теории планирования экспериментов показано, что необходимое число уровней факторов на
В теории планирования экспериментов показано, что необходимое число уровней факторов на

Определение коэффициентов уравнения регрессии
Определение коэффициентов уравнения регрессии

Определение коэффициентов уравнения регрессии (продолжение)
Определение коэффициентов уравнения регрессии (продолжение)

Статистический анализ результатов эксперимента
Статистический анализ результатов эксперимента

Оценки значимости коэффициентов уравнения регрессии
Оценки значимости коэффициентов уравнения регрессии

Адекватность модели
Адекватность модели

Дробный факторный эксперимент
Дробный факторный эксперимент
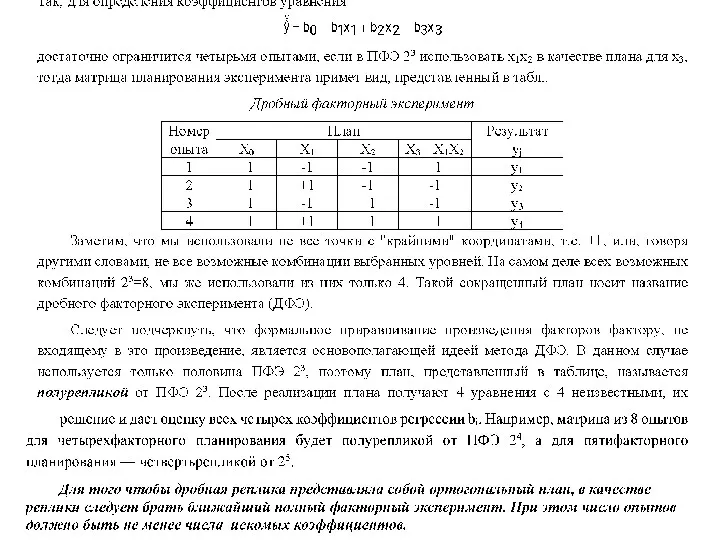

Дробную реплику, в которой Р линейных эффектов приравнены к эффектам взаимодействия,
Дробную реплику, в которой Р линейных эффектов приравнены к эффектам взаимодействия,

Планы второго порядка
В этом случае требуется, чтобы каждый фактор варьировался
Планы второго порядка
В этом случае требуется, чтобы каждый фактор варьировался

Так, при двух факторах модель функции отклика y = f(x1,x2) второго
Так, при двух факторах модель функции отклика y = f(x1,x2) второго
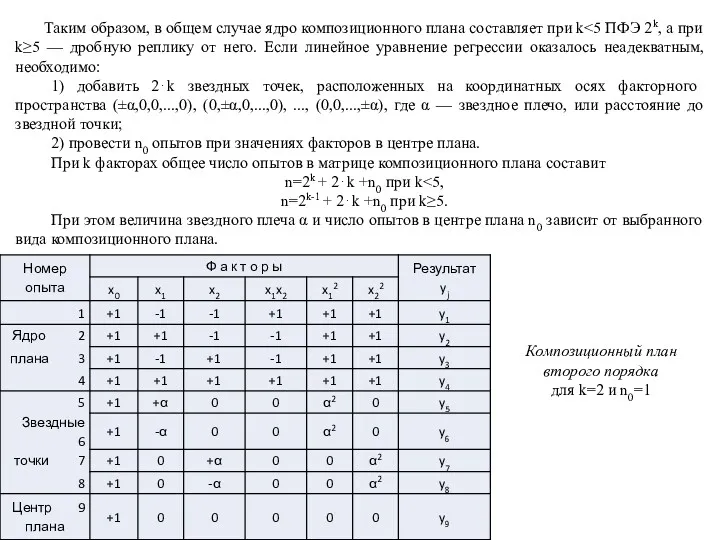
Таким образом, в общем случае ядро композиционного плана составляет при k<5
Таким образом, в общем случае ядро композиционного плана составляет при k<5

Ортогональные планы второго порядка
В общем виде план, представленный в табл. неортогонален,
Ортогональные планы второго порядка
В общем виде план, представленный в табл. неортогонален,
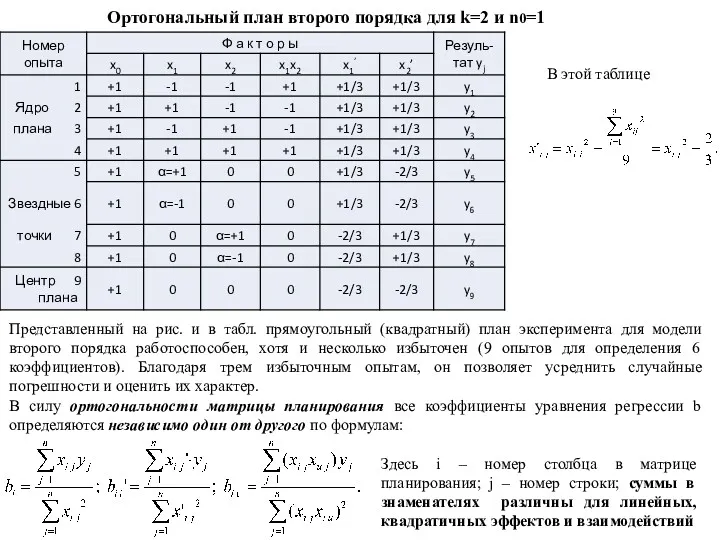
В этой таблице
Ортогональный план второго порядка для k=2 и n0=1
В этой таблице
Ортогональный план второго порядка для k=2 и n0=1

Ортогональные планы второго порядка (продолжение)
Ортогональные планы второго порядка (продолжение)
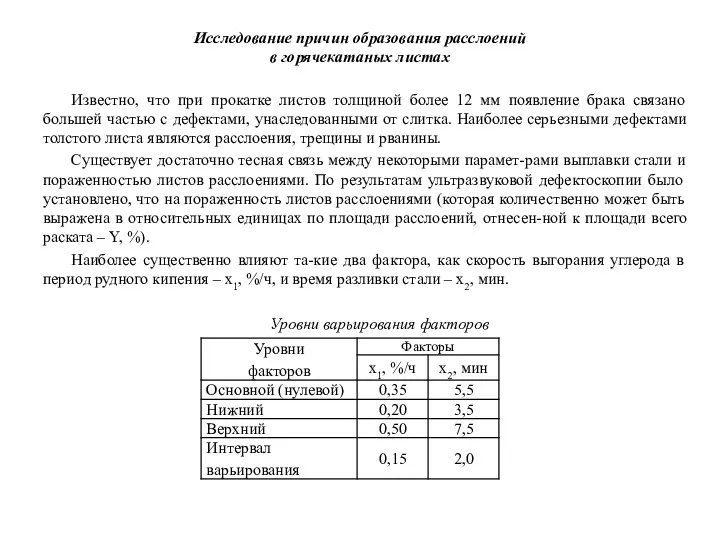
Исследование причин образования расслоений
в горячекатаных листах
Известно, что при прокатке листов
Исследование причин образования расслоений
в горячекатаных листах
Известно, что при прокатке листов
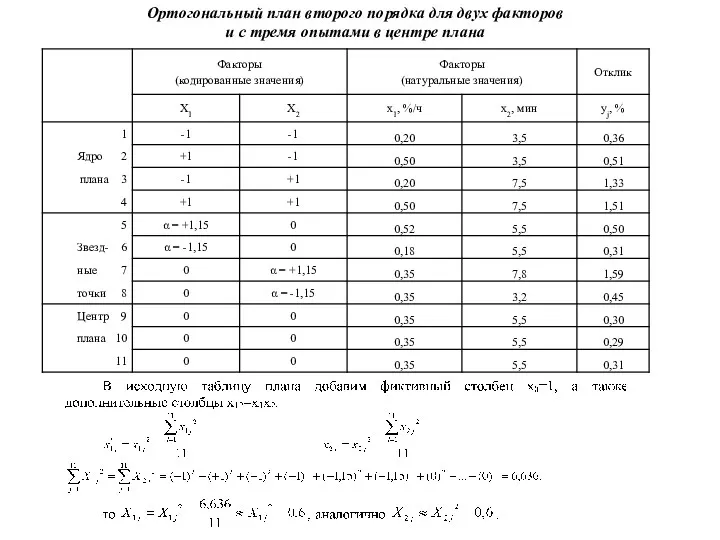
Ортогональный план второго порядка для двух факторов
и с тремя опытами
Ортогональный план второго порядка для двух факторов и с тремя опытами
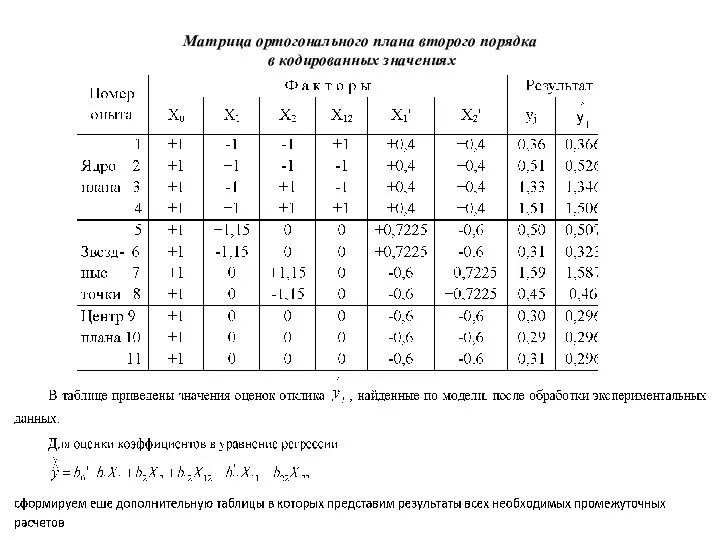
Матрица ортогонального плана второго порядка
в кодированных значениях
Матрица ортогонального плана второго порядка
в кодированных значениях
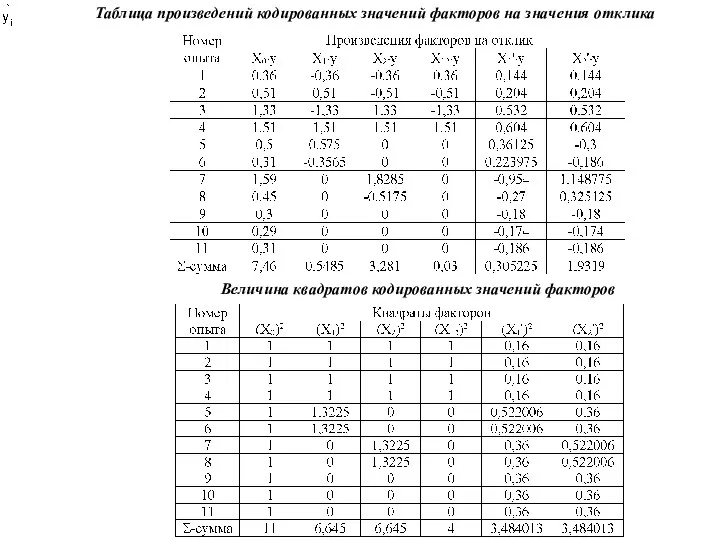
Величина квадратов кодированных значений факторов
Таблица произведений кодированных значений факторов на значения
Величина квадратов кодированных значений факторов
Таблица произведений кодированных значений факторов на значения

Расчет коэффициентов модели
Расчет коэффициентов модели

Оценка значимости коэффициентов
Оценка значимости коэффициентов

Оценка адекватности модели
Оценка адекватности модели

Оценка оптимальных значений параметров
Оценка оптимальных значений параметров

Ортогональные планы второго порядка (продолжение)
Ортогональные планы второго порядка (продолжение)
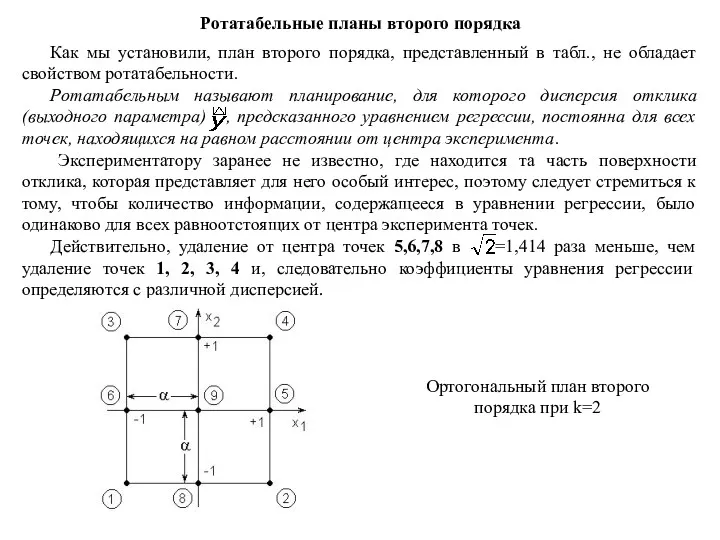
Ротатабельные планы второго порядка
Как мы установили, план второго порядка, представленный
Ротатабельные планы второго порядка
Как мы установили, план второго порядка, представленный
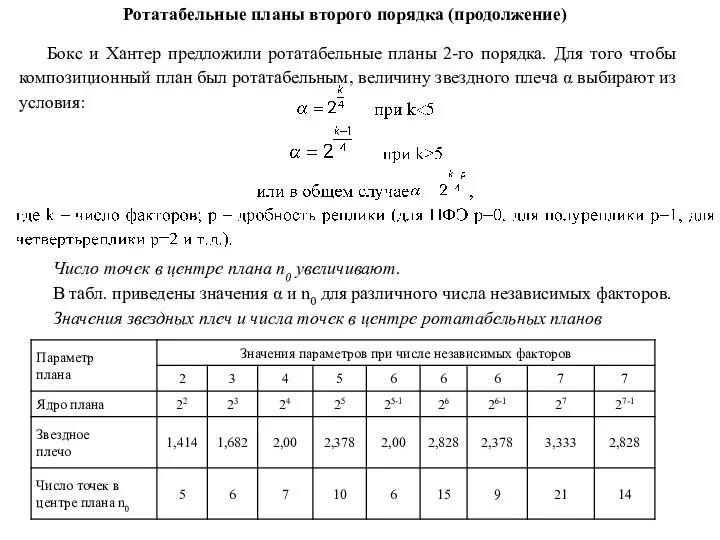
Бокс и Хантер предложили ротатабельные планы 2-го порядка. Для того чтобы
Бокс и Хантер предложили ротатабельные планы 2-го порядка. Для того чтобы
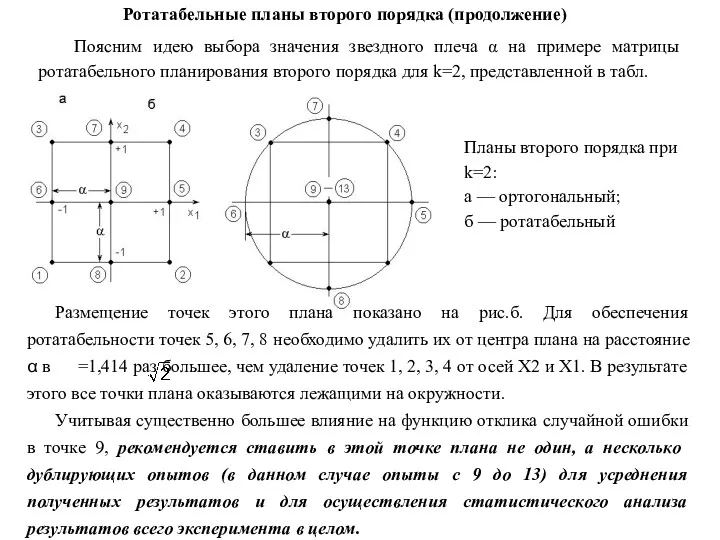
Ротатабельные планы второго порядка (продолжение)
Поясним идею выбора значения звездного плеча α
Ротатабельные планы второго порядка (продолжение)
Поясним идею выбора значения звездного плеча α
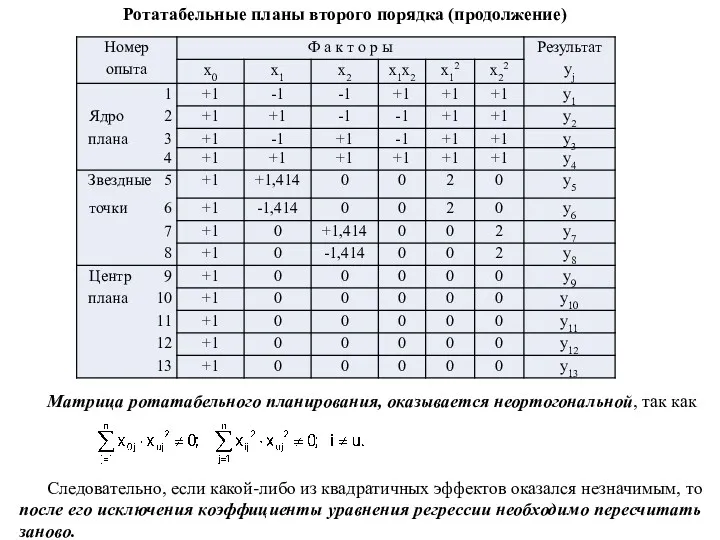
Матрица ротатабельного планирования, оказывается неортогональной, так как
Следовательно, если какой-либо из квадратичных
Матрица ротатабельного планирования, оказывается неортогональной, так как
Следовательно, если какой-либо из квадратичных

Если модель второго порядка оказалась неадекватной, следует:
Повторить эксперименты на меньшем интервале
Если модель второго порядка оказалась неадекватной, следует:
Повторить эксперименты на меньшем интервале
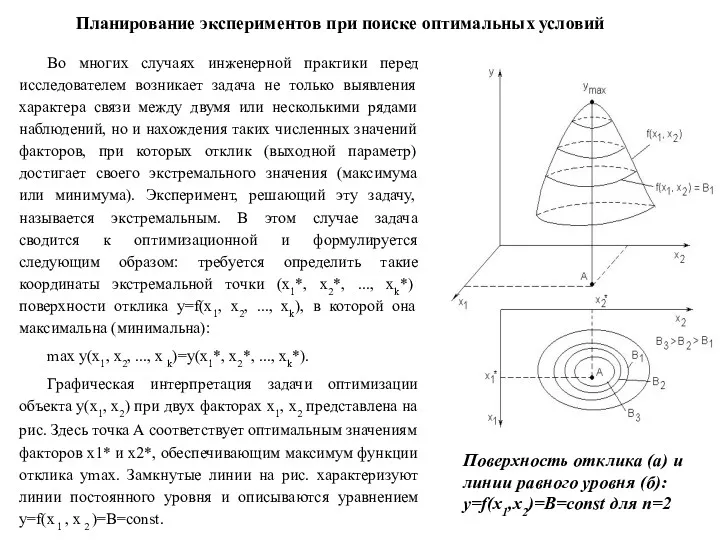
Планирование экспериментов при поиске оптимальных условий
Во многих случаях инженерной практики
Планирование экспериментов при поиске оптимальных условий
Во многих случаях инженерной практики
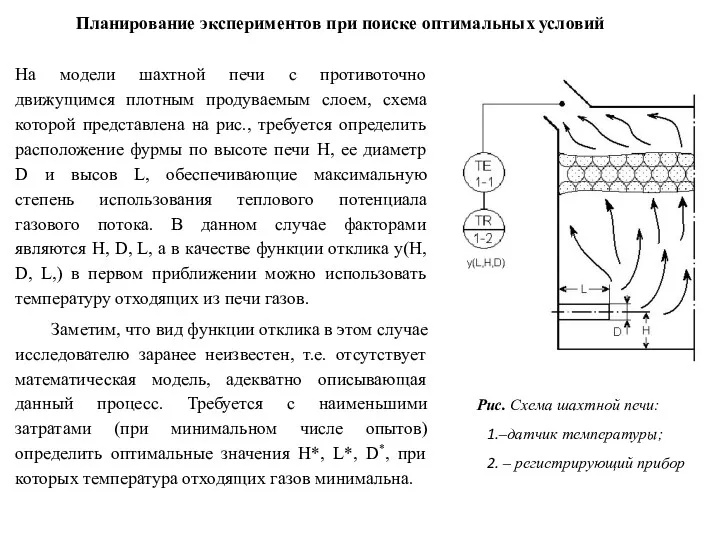
На модели шахтной печи с противоточно движущимся плотным продуваемым слоем, схема
На модели шахтной печи с противоточно движущимся плотным продуваемым слоем, схема

Известный из практики метод "проб" и "ошибок", в котором факторы изменяются
Известный из практики метод "проб" и "ошибок", в котором факторы изменяются
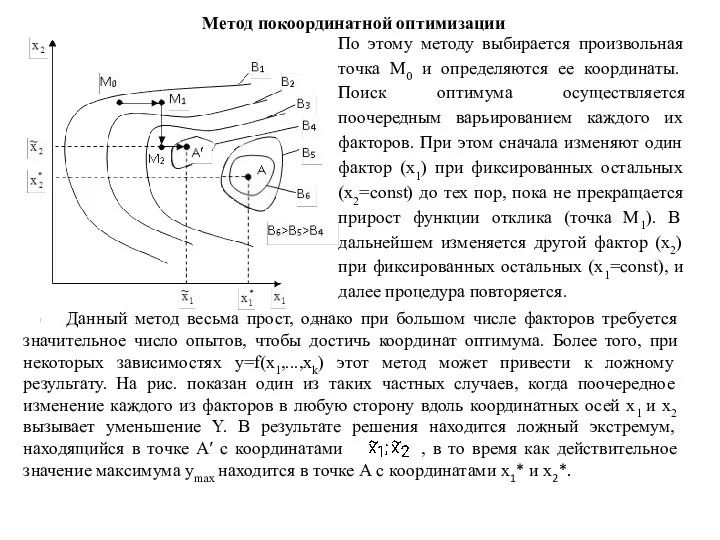
Метод покоординатной оптимизации
По этому методу выбирается произвольная точка М0 и
Метод покоординатной оптимизации
По этому методу выбирается произвольная точка М0 и

Метод крутого восхождения
Известно, что кратчайший, наиболее короткий путь — это движение
Метод крутого восхождения
Известно, что кратчайший, наиболее короткий путь — это движение

Метод крутого восхождения.
Продолжение
Метод крутого восхождения.
Продолжение

Метод крутого восхождения.
Продолжение
Метод крутого восхождения.
Продолжение

Симплексный метод планирования
Метод симплексного планирования позволяет без предварительного изучения влияния факторов
Симплексный метод планирования
Метод симплексного планирования позволяет без предварительного изучения влияния факторов

По итогам проведения опытов 1, 2 и 3 худшим оказался опыт
По итогам проведения опытов 1, 2 и 3 худшим оказался опыт

Выбор размеров симплекса и его начального положения в известной степени произволен.
Выбор размеров симплекса и его начального положения в известной степени произволен.




 Обыкновенные дроби. Выполните действия
Обыкновенные дроби. Выполните действия Таблица вариантов и правило произведения
Таблица вариантов и правило произведения Алғашқы интеграл
Алғашқы интеграл Булева алгебра. Основные понятия булевой алгебры
Булева алгебра. Основные понятия булевой алгебры Задачи на деление.
Задачи на деление. Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення
Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення Геометрия. Повторение из курса математики 5 класса
Геометрия. Повторение из курса математики 5 класса Применение интегралов в решении задач
Применение интегралов в решении задач Способы нахождения корней многочлена. Теорема Безу
Способы нахождения корней многочлена. Теорема Безу Великие математики. Звездный час. Правила игры
Великие математики. Звездный час. Правила игры Отношение. Урок математики в 6 классе
Отношение. Урок математики в 6 классе Опыты с равновозможными элементарными событиями. Решение задач
Опыты с равновозможными элементарными событиями. Решение задач Линейное уравнение с двумя переменными и его график
Линейное уравнение с двумя переменными и его график Разложение на простые множители
Разложение на простые множители Однополостный гиперболоид
Однополостный гиперболоид Оптимизационные задачи. Задачи линейного программирования
Оптимизационные задачи. Задачи линейного программирования Кубизм в архитектуре. Оригами
Кубизм в архитектуре. Оригами Развёрнутый конспект урока математики в 1 классе по программе Л.Г. Петерсон Равные фигуры
Развёрнутый конспект урока математики в 1 классе по программе Л.Г. Петерсон Равные фигуры Конус. Объём усечённого конуса
Конус. Объём усечённого конуса Равнобедренный треугольник
Равнобедренный треугольник Нахождение числа по заданному значению его дроби
Нахождение числа по заданному значению его дроби Треугольник. Параллелограмм. Центральные и вписанные углы
Треугольник. Параллелограмм. Центральные и вписанные углы Вычисление площади сложной фигуры, состоящей из прямоугольников (квадратов)
Вычисление площади сложной фигуры, состоящей из прямоугольников (квадратов) Число π (Пи)
Число π (Пи) Ожившие задачи и теоремы
Ожившие задачи и теоремы Интегрированный урок по теме Внетабличное умножение и деление. Экологическая безопасность. 3 класс
Интегрированный урок по теме Внетабличное умножение и деление. Экологическая безопасность. 3 класс Задачи на работу. 9 класс
Задачи на работу. 9 класс Письменная нумерация чисел в пределах 1000
Письменная нумерация чисел в пределах 1000