- Статистические методы исследования экспериментальных данных

Содержание
- 2. Проведение исследования При выполнении исследования мы можем использовать два подходами при выполнении экспериментальных работ: Использовать уже
- 3. Пассивный эксперимент Собрав необходимый экспериментальный материал, проводим его анализ с целью выявления возможных связей между выходными
- 4. Дисперсионный анализ С помощью дисперсионного анализа решаются вопросы о влиянии одного (однофакторный дисперсионный анализ) или нескольких
- 5. Равномерный однофакторный дисперсионный анализ При равномерном однофакторном дисперсионном анализе число замеров значений изучаемого признака на разных
- 6. Равномерный однофакторный дисперсионный анализ (расчет) Общая сумма квадратов отклонений наблюдаемых значений признака от общей средней: Факторная
- 7. Результаты решения Исходные данные – таблица с 5 факторами и 10 измерениями по каждому из факторов
- 8. Дисперсионный анализ для различных наборов данных Посмотреть Одинаковые средние и стандартные отклонения Разные средние и одинаковые
- 9. Другие виды дисперсионного однопараметрического анализа Можно реализовывать неравномерные выборки по параметрам ( разное число испытаний для
- 10. Двухфакторный дисперсионный анализ Позволяет оценить влияние двух факторов на выходную функцию, например, несколько катализаторов на выход
- 11. Корреляционный анализ Корреляционный анализ состоит в определении степени связи между двумя случайными величинами X и Y.
- 12. Качественная оценка тесноты связи При получении коэффициента корреляции более 0,5 обычно требуется учета
- 13. Примеры расчетов Исходные данные – таблица с 5 факторами и 10 измерениями по каждому из факторов
- 14. Порядок принятия решения Процедуру установления корреляционной зависимости принято называть проверкой гипотезы. Ее принято проводить в следующей
- 15. Области существования корреляционных зависимостей R=1 R= -1 -1 X Y
- 16. Оценка значимых факторов при анализе работы печи пиролиза Фрагмент таблицы данных ЦЗЛ ОАО «Казань Оргсинтез» по
- 17. Оценка значимых факторов при анализе работы печи пиролиза Фрагмент таблицы коэффициентов корреляции для компонентов при работе
- 18. Регрессионный анализ В практике статистического исследования часто возникает необходимость определить не только корреляционное соотношение между изучаемыми
- 19. Выбор модели Задачей анализа является поиск математической зависимости и оценка на сколько описание с использованием данной
- 20. Математическая реализация решения В основе решения задачи лежит метод наименьших квадратов (МНК), критерием оптимальности которого является
- 21. Решение одномерных задач Требуется провести исследование влияния одного параметра на исследуемую функцию, например как изменяется вязкость
- 22. Реализация решения в MS Excel Готовим таблицу с исходным данными Пользуясь информацией из таблицы исходных данных
- 23. Формируем формулы для нумерации опытов и значений параметра: Первый опыт начинается 1 и далее вычисляется по
- 24. В результате получаем следующую таблицу Посмотреть При заполнении экспериментальных данных сначала выделим весь столбец с этими
- 25. Номер задания заполняется автоматически или может быть выбираем из списка имен «Использовать в формуле » на
- 26. По результатам эксперимента строим график Выделяем таблицу с ячейки, где написано «Температура» до последнего расчетного значения
- 27. Если график нужен для отчета, переносим его на отдельный лист и настраиваем по требованиям ГОСТ или
- 28. Первоначально задаем один шрифт для всего графика «Arial», потом размещаем на нем заголовки, которые не вписываем
- 29. Через контекстное меню ряда (щелчок правой кнопки мышки на точке) выполняем команду – «Добавить линию тренда»
- 30. Создаем таблицу расчетных и экспериментальных данных Готовим таблицу с начальными приближениями по всем коэффициентам Заполняем расчетной
- 31. Вызываем «Поиск решения» Убираем галочку Выбираем центральные производные
- 32. «Поиск решения» в 2007 Выбираем центральные производные
- 34. Реализация решения для произвольного уравнений Имеется задача исследовать процесс получения продукта в химическом реакторе: Входным параметром
- 35. Копируем два листа, которые были создан ранее (рабочий лист и диаграмма): Выделяем рабочий лист и удерживая
- 36. Получаем следующую таблицу и новый график Как видим, все изменения отразились и на графике, остается убрать
- 37. Исправляем формулу: =($J$2+$J$3*E4)/($J$4+$J$5*E4) Выполняем поиск решения и получаем результат, который не совсем отвечает нашим желаниям: Начальная
- 38. Сделаем анализ формулы и используем ограничения: Задание первому коэффициенту нулевого значения (или удаление его из формулы)
- 39. Равно нулю Равняется 45 Но кривая идет не совсем по точкам, это, скорее всего, связано с
- 40. Внесем изменения в модель, добавив степени для параметра: Для этого расширим таблицу коэффициентов, выделим две свободные
- 41. Получена модель процесса с высокой степенью надежности по совпадению экспериментальных и расчётных данных
- 42. Реализация решения для многопараметрических уравнений Однако, чаще приходится решать многопараметрические задачи Y=F(X1, X2) . Первый вопрос
- 43. Строим линейную модель полинома Y= A0 + A1*X1 + A2*X2 Проверяем линейную модель полинома и можем
- 44. Копируем лист, который был создан для первой задачи: Перемещаем его за заголовок левой кнопкой мышки и
- 45. Разберем порядок выполнения команд: Выделяем столбец «С», нажимая левой кнопкой мышки на его заголовок; Выполняем команду
- 46. Вносим изменение в названии – «Среднее значение»; Заполняем данные по следующему параметру – «Давление», 4, 2
- 47. Начинаем заполнять данные таблицы экспериментальных и расчетных данных, чтобы заполнить имя второго параметра надо просто растянуть
- 48. Заполняем формулы в ячейки таблицы: Получаем готовый лист для двухпара- метрической зависимости; Заполняем экспериментальные данные и
- 49. Готовим табличку с коэффициентами для уравнения: Y= A0 + A1*X1 + A2*X2 + А12*Х1*Х2 + А11*Х12
- 50. =$L$2+$L$3*F4+$L$4*G4+$L$5*F4^2+$L$6*F4*G4+$L$7*G4^2 Копируем полученную формулу в остальные опыты и вызываем «Поиск решения» для расчета. Основные настройки в
- 51. Расчеты по «Поиску решения» надо выполнить не менее 2-х раз до тех пор, пока значения в
- 52. Копируем ячейку с расчетной функцией и вставляем её ниже, переходим в режим редактирования, чтобы отметить ячейки
- 53. Повторяем эти операции для давления, только по столбцу вниз. Сначала вводим 2 и потом отсчитываем 10
- 54. Выделяем внутреннюю часть матрицы данных: Строим диаграмму «Вставка» – «Другие» – «Поверхность» и получаем:
- 57. Скачать презентацию

Проведение исследования
При выполнении исследования мы можем использовать два подходами при выполнении
Проведение исследования
При выполнении исследования мы можем использовать два подходами при выполнении

Пассивный эксперимент
Собрав необходимый экспериментальный материал, проводим его анализ с целью выявления
Пассивный эксперимент
Собрав необходимый экспериментальный материал, проводим его анализ с целью выявления

Дисперсионный анализ
С помощью дисперсионного анализа решаются вопросы о влиянии одного (однофакторный
Дисперсионный анализ
С помощью дисперсионного анализа решаются вопросы о влиянии одного (однофакторный

Равномерный однофакторный дисперсионный анализ
При равномерном однофакторном дисперсионном анализе число замеров
Равномерный однофакторный дисперсионный анализ
При равномерном однофакторном дисперсионном анализе число замеров

Равномерный однофакторный дисперсионный анализ (расчет)
Общая сумма квадратов отклонений наблюдаемых значений
Равномерный однофакторный дисперсионный анализ (расчет)
Общая сумма квадратов отклонений наблюдаемых значений
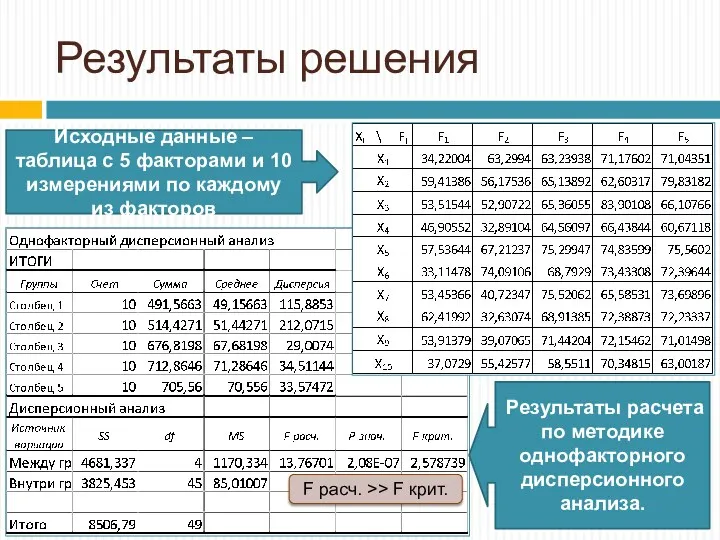
Результаты решения
Исходные данные – таблица с 5 факторами и 10 измерениями
Результаты решения
Исходные данные – таблица с 5 факторами и 10 измерениями
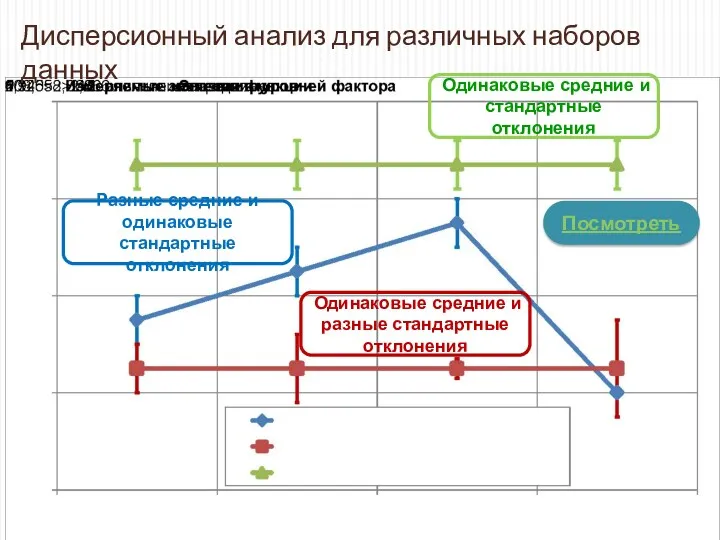
Дисперсионный анализ для различных наборов данных
Посмотреть
Одинаковые средние и стандартные отклонения
Разные
Дисперсионный анализ для различных наборов данных
Посмотреть
Одинаковые средние и стандартные отклонения
Разные

Другие виды дисперсионного однопараметрического анализа
Можно реализовывать неравномерные выборки по параметрам (
Другие виды дисперсионного однопараметрического анализа
Можно реализовывать неравномерные выборки по параметрам (

Двухфакторный дисперсионный анализ
Позволяет оценить влияние двух факторов на выходную функцию,
Двухфакторный дисперсионный анализ
Позволяет оценить влияние двух факторов на выходную функцию,

Корреляционный анализ
Корреляционный анализ состоит в определении степени связи между двумя случайными
Корреляционный анализ
Корреляционный анализ состоит в определении степени связи между двумя случайными

Качественная оценка тесноты связи
При получении коэффициента корреляции более 0,5 обычно требуется
Качественная оценка тесноты связи
При получении коэффициента корреляции более 0,5 обычно требуется
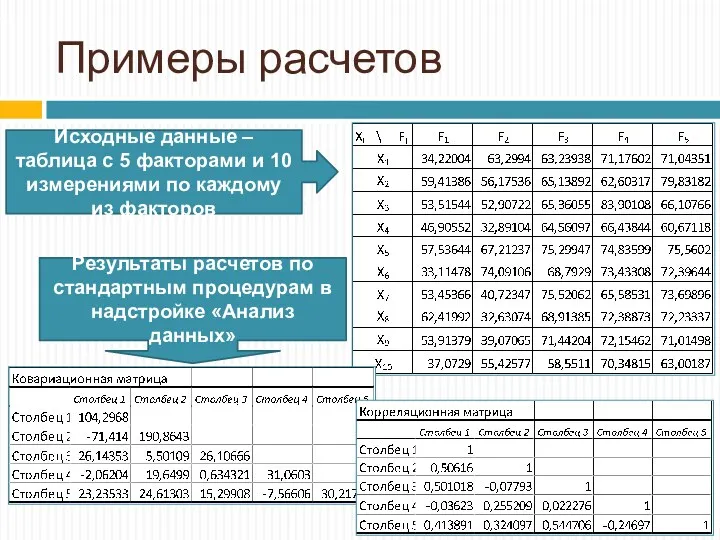
Примеры расчетов
Исходные данные – таблица с 5 факторами и 10 измерениями
Примеры расчетов
Исходные данные – таблица с 5 факторами и 10 измерениями

Порядок принятия решения
Процедуру установления корреляционной зависимости принято называть проверкой гипотезы. Ее
Порядок принятия решения
Процедуру установления корреляционной зависимости принято называть проверкой гипотезы. Ее
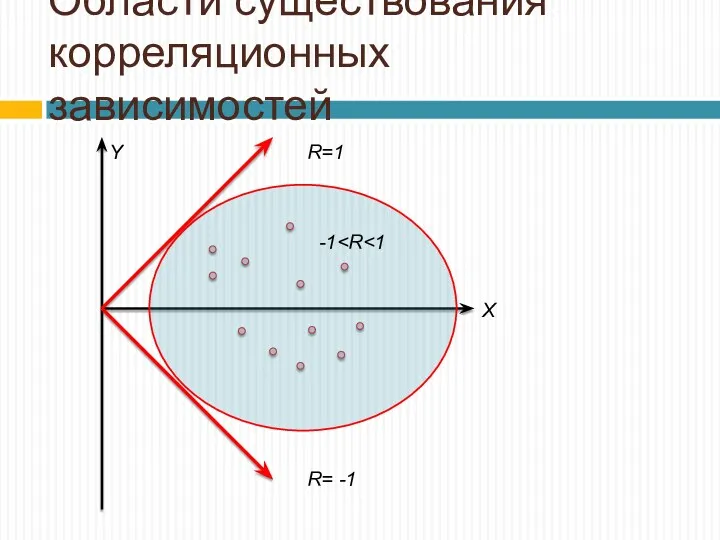
Области существования корреляционных зависимостей
R=1
R= -1
-1X
Y
Области существования корреляционных зависимостей
R=1
R= -1
-1 X Y
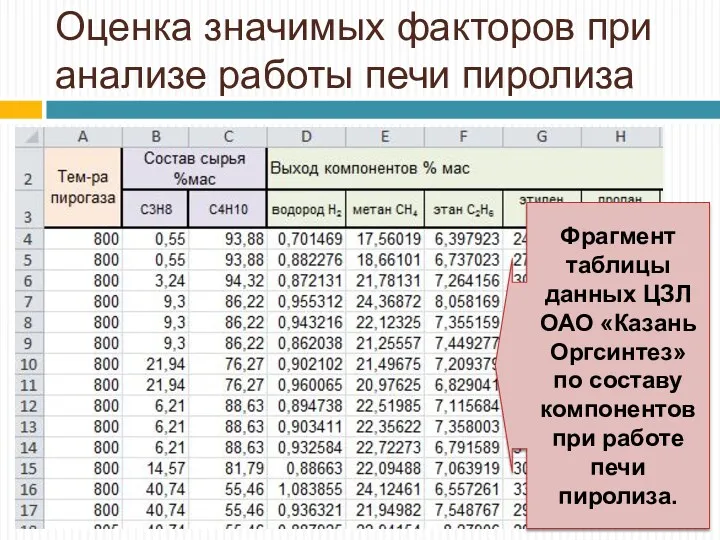
Оценка значимых факторов при анализе работы печи пиролиза
Фрагмент таблицы данных ЦЗЛ
Оценка значимых факторов при анализе работы печи пиролиза
Фрагмент таблицы данных ЦЗЛ
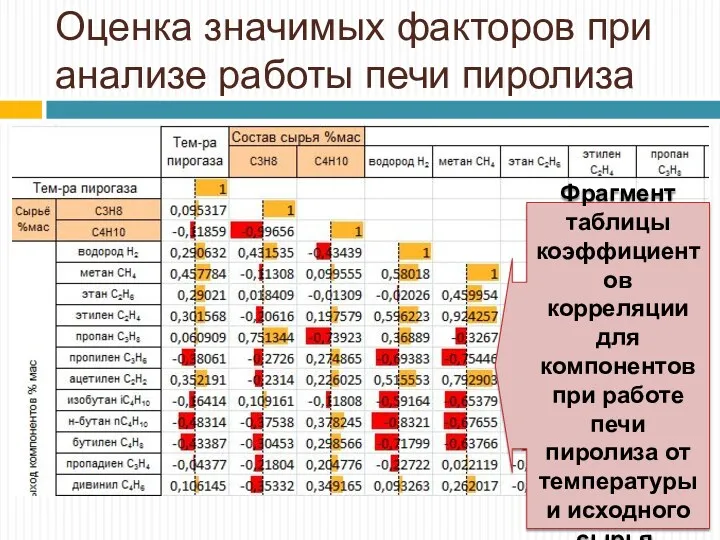
Оценка значимых факторов при анализе работы печи пиролиза
Фрагмент таблицы коэффициентов корреляции
Оценка значимых факторов при анализе работы печи пиролиза
Фрагмент таблицы коэффициентов корреляции

Регрессионный анализ
В практике статистического исследования часто возникает необходимость определить не только
Регрессионный анализ
В практике статистического исследования часто возникает необходимость определить не только

Выбор модели
Задачей анализа является поиск математической зависимости и оценка на сколько
Выбор модели
Задачей анализа является поиск математической зависимости и оценка на сколько

Математическая реализация решения
В основе решения задачи лежит метод наименьших квадратов (МНК),
Математическая реализация решения
В основе решения задачи лежит метод наименьших квадратов (МНК),

Решение одномерных задач
Требуется провести исследование влияния одного параметра на исследуемую функцию,
Решение одномерных задач
Требуется провести исследование влияния одного параметра на исследуемую функцию,
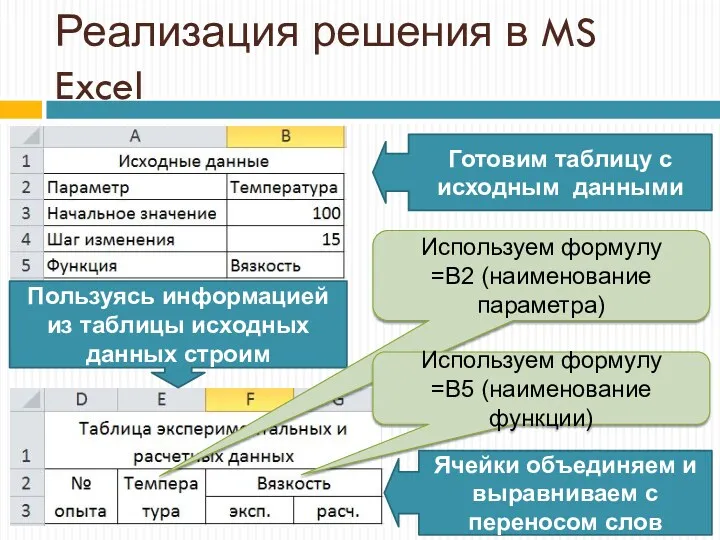
Реализация решения в MS Excel
Готовим таблицу с исходным данными
Пользуясь информацией
Реализация решения в MS Excel
Готовим таблицу с исходным данными
Пользуясь информацией

Формируем формулы для нумерации опытов и значений параметра:
Первый опыт начинается 1
Формируем формулы для нумерации опытов и значений параметра:
Первый опыт начинается 1
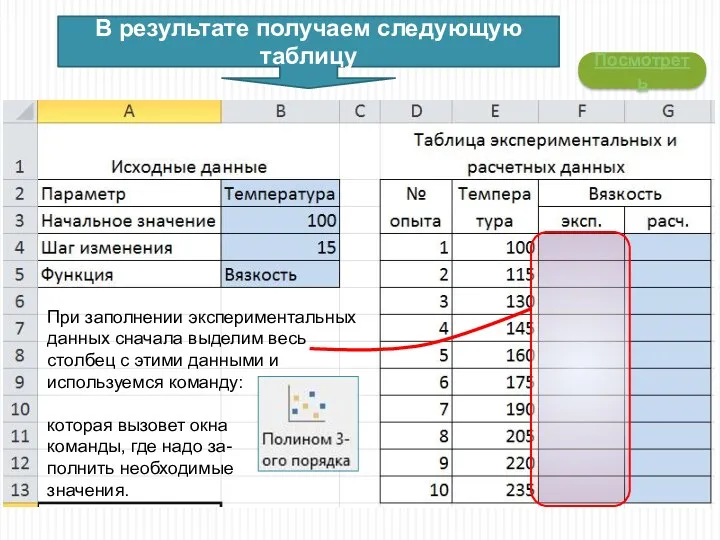
В результате получаем следующую таблицу
Посмотреть
При заполнении экспериментальных данных сначала выделим весь
В результате получаем следующую таблицу
Посмотреть
При заполнении экспериментальных данных сначала выделим весь
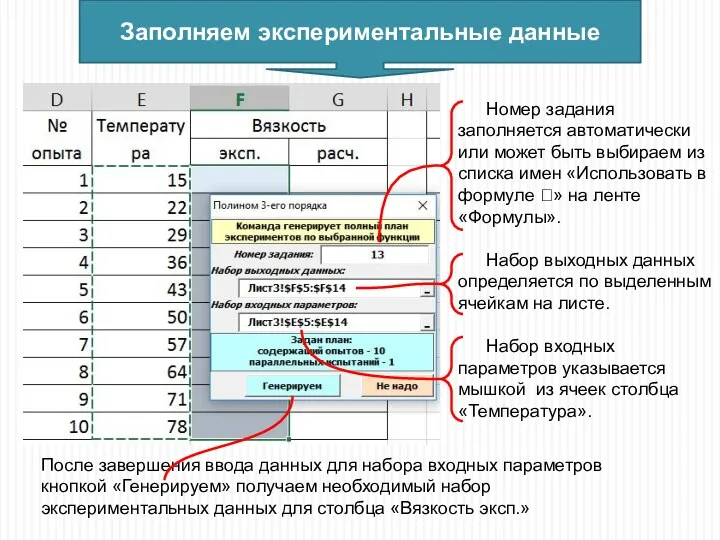
Номер задания заполняется автоматически или может быть выбираем из списка имен
Номер задания заполняется автоматически или может быть выбираем из списка имен
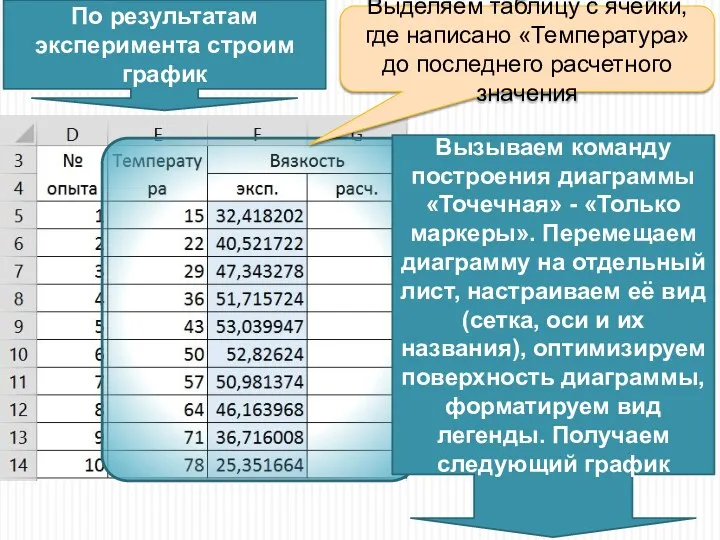
По результатам эксперимента строим график
Выделяем таблицу с ячейки, где написано «Температура»
По результатам эксперимента строим график
Выделяем таблицу с ячейки, где написано «Температура»
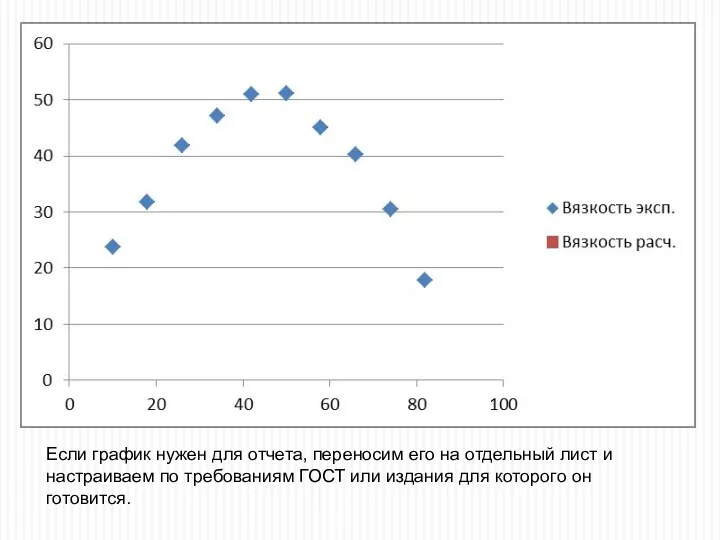
Если график нужен для отчета, переносим его на отдельный лист и
Если график нужен для отчета, переносим его на отдельный лист и
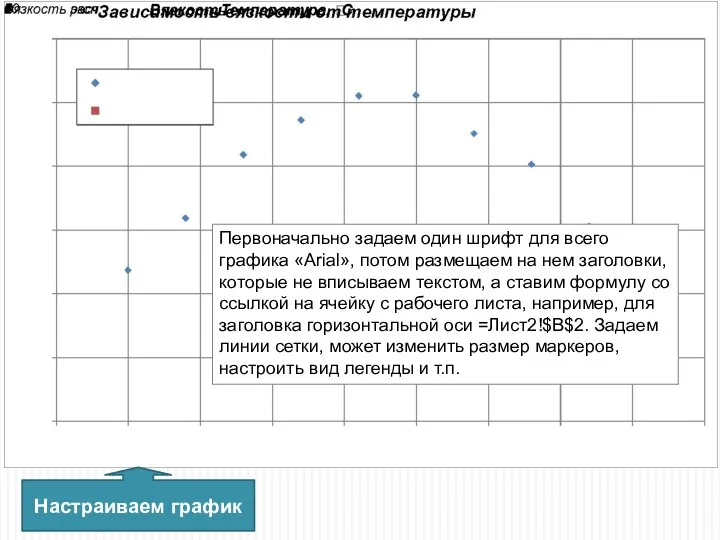
Первоначально задаем один шрифт для всего графика «Arial», потом размещаем на
Первоначально задаем один шрифт для всего графика «Arial», потом размещаем на
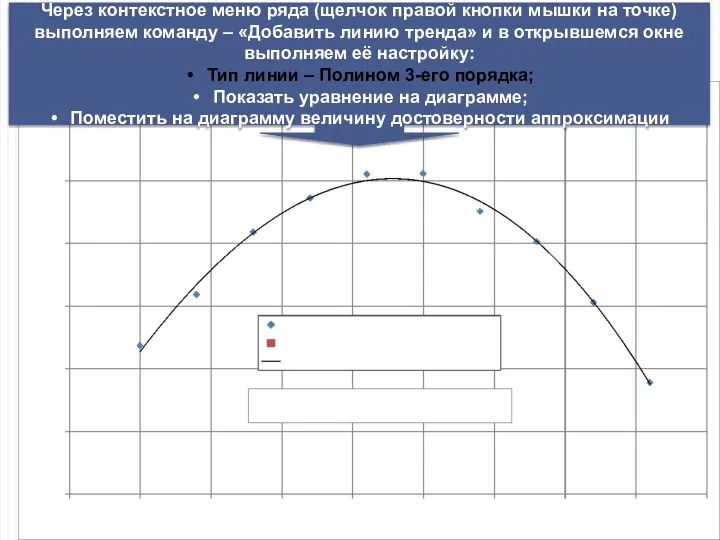
Через контекстное меню ряда (щелчок правой кнопки мышки на точке) выполняем
Через контекстное меню ряда (щелчок правой кнопки мышки на точке) выполняем
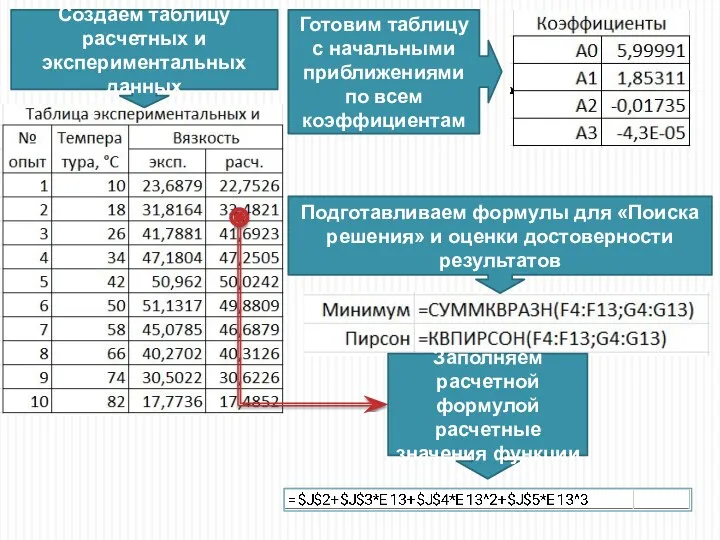
Создаем таблицу расчетных и экспериментальных данных
Готовим таблицу с начальными приближениями по
Создаем таблицу расчетных и экспериментальных данных
Готовим таблицу с начальными приближениями по
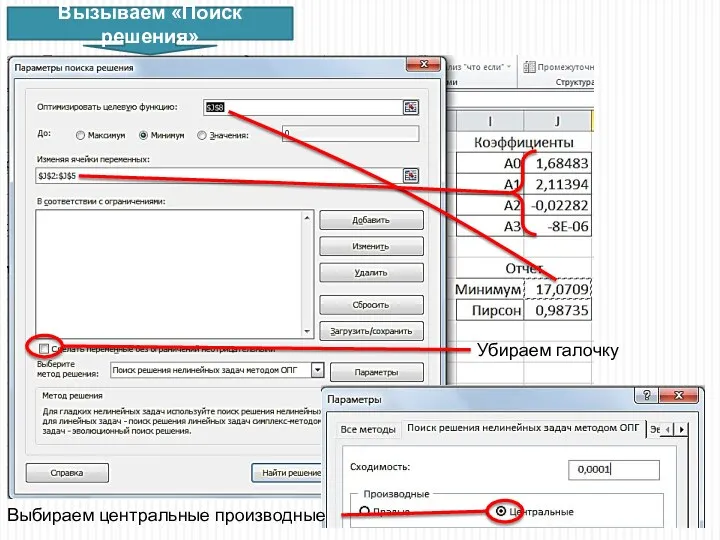
Вызываем «Поиск решения»
Убираем галочку
Выбираем центральные производные
Вызываем «Поиск решения»
Убираем галочку
Выбираем центральные производные
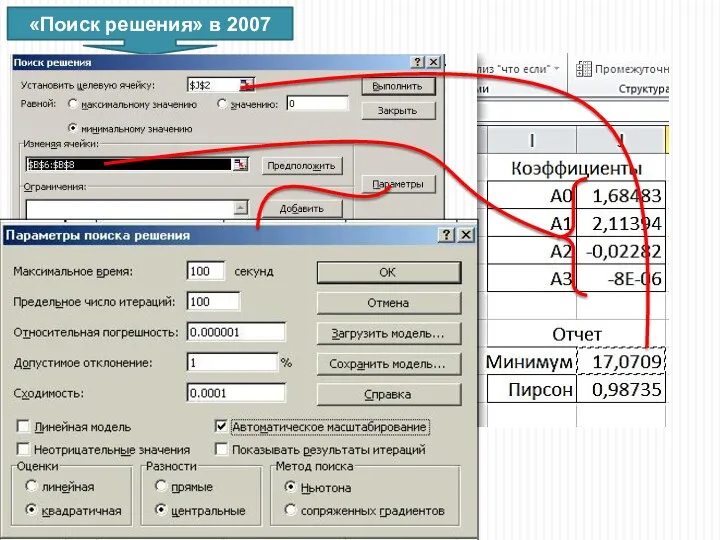
«Поиск решения» в 2007
Выбираем центральные производные
«Поиск решения» в 2007
Выбираем центральные производные
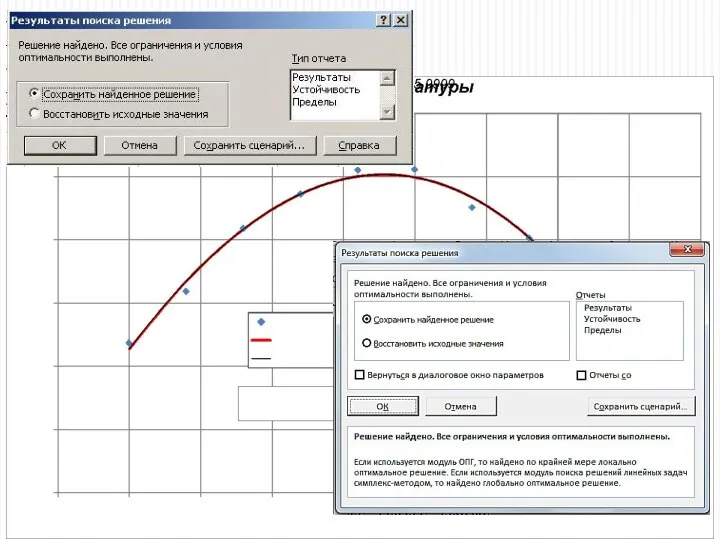

Реализация решения для произвольного уравнений
Имеется задача исследовать процесс получения продукта в
Реализация решения для произвольного уравнений
Имеется задача исследовать процесс получения продукта в

Копируем два листа, которые были создан ранее (рабочий лист и диаграмма):
Выделяем
Копируем два листа, которые были создан ранее (рабочий лист и диаграмма):
Выделяем

Получаем следующую таблицу и новый график
Как видим, все изменения отразились и
Получаем следующую таблицу и новый график
Как видим, все изменения отразились и
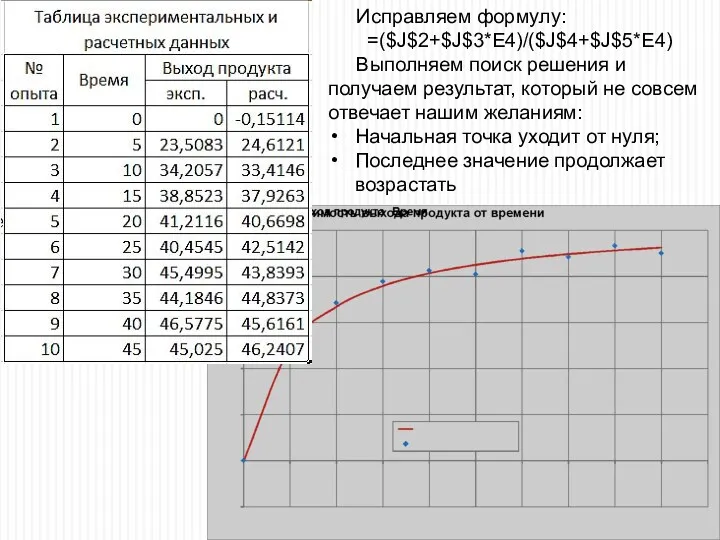
Исправляем формулу:
=($J$2+$J$3*E4)/($J$4+$J$5*E4)
Выполняем поиск решения и получаем результат, который не совсем отвечает
Исправляем формулу:
=($J$2+$J$3*E4)/($J$4+$J$5*E4)
Выполняем поиск решения и получаем результат, который не совсем отвечает
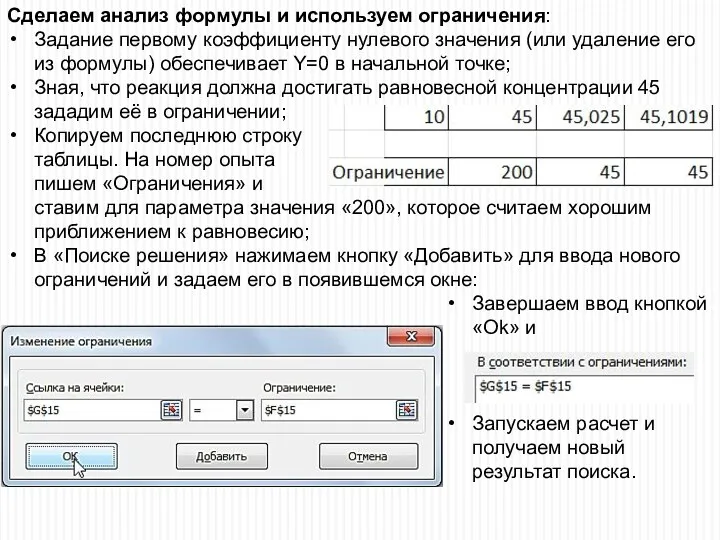
Сделаем анализ формулы и используем ограничения:
Задание первому коэффициенту нулевого значения (или
Сделаем анализ формулы и используем ограничения:
Задание первому коэффициенту нулевого значения (или
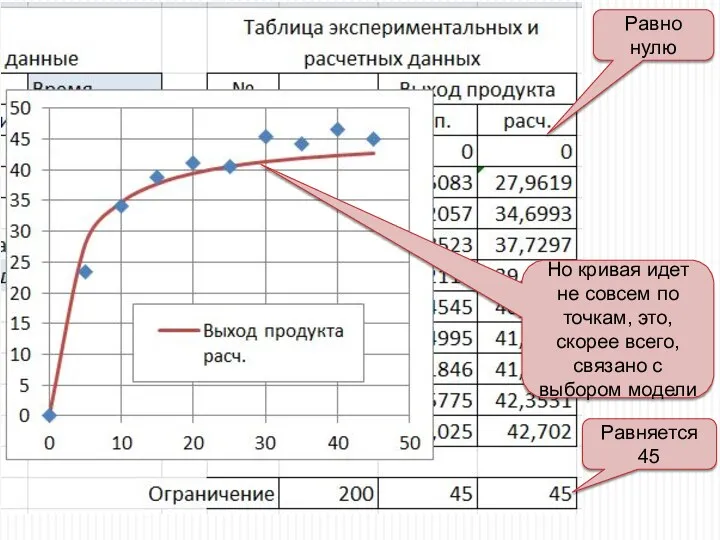
Равно нулю
Равняется 45
Но кривая идет не совсем по точкам, это, скорее
Равно нулю
Равняется 45
Но кривая идет не совсем по точкам, это, скорее

Внесем изменения в модель, добавив
степени для параметра:
Для этого расширим таблицу
коэффициентов, выделим
Внесем изменения в модель, добавив
степени для параметра:
Для этого расширим таблицу
коэффициентов, выделим
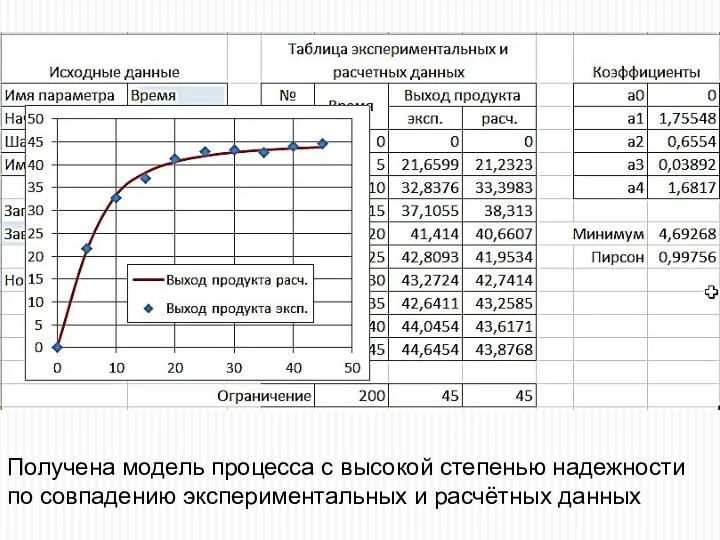
Получена модель процесса с высокой степенью надежности по совпадению экспериментальных и
Получена модель процесса с высокой степенью надежности по совпадению экспериментальных и

Реализация решения для многопараметрических уравнений
Однако, чаще приходится решать многопараметрические задачи Y=F(X1,
Реализация решения для многопараметрических уравнений
Однако, чаще приходится решать многопараметрические задачи Y=F(X1,
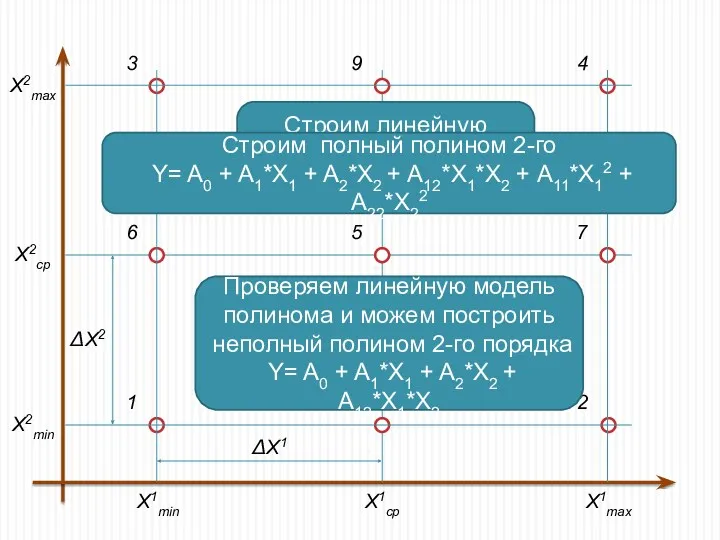
Строим линейную модель полинома
Y= A0 + A1*X1 + A2*X2
Проверяем линейную
Строим линейную модель полинома
Y= A0 + A1*X1 + A2*X2
Проверяем линейную
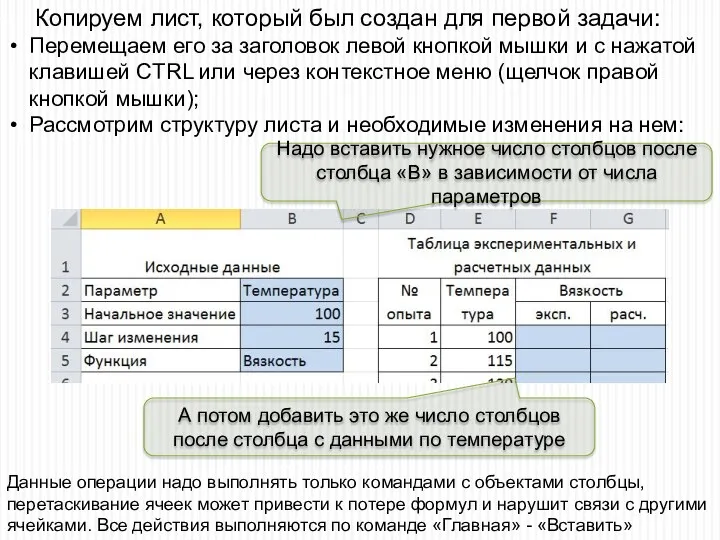
Копируем лист, который был создан для первой задачи:
Перемещаем его за заголовок
Копируем лист, который был создан для первой задачи:
Перемещаем его за заголовок
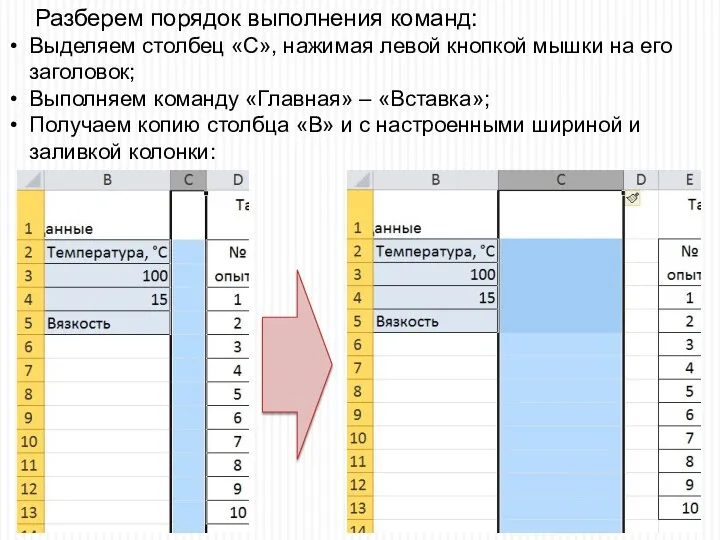
Разберем порядок выполнения команд:
Выделяем столбец «С», нажимая левой кнопкой мышки на
Разберем порядок выполнения команд:
Выделяем столбец «С», нажимая левой кнопкой мышки на
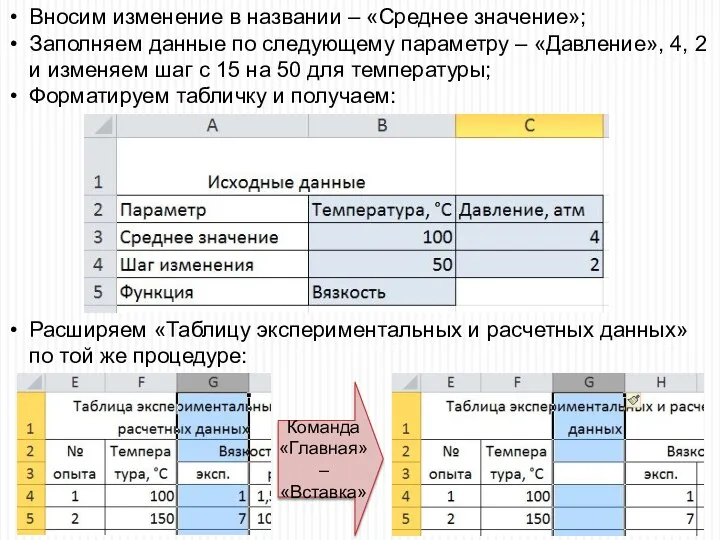
Вносим изменение в названии – «Среднее значение»;
Заполняем данные по следующему параметру
Вносим изменение в названии – «Среднее значение»;
Заполняем данные по следующему параметру

Начинаем заполнять данные таблицы экспериментальных и расчетных данных, чтобы заполнить имя
второго
Начинаем заполнять данные таблицы экспериментальных и расчетных данных, чтобы заполнить имя второго
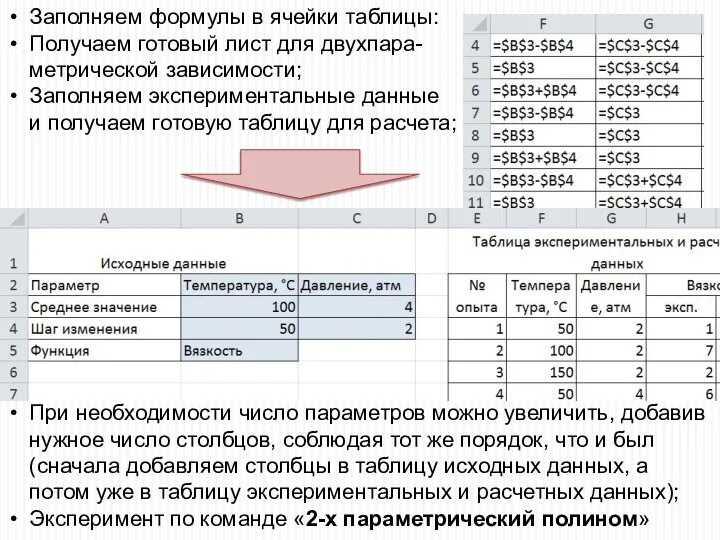
Заполняем формулы в ячейки таблицы:
Получаем готовый лист для двухпара-
метрической зависимости;
Заполняем экспериментальные
Заполняем формулы в ячейки таблицы:
Получаем готовый лист для двухпара-
метрической зависимости;
Заполняем экспериментальные
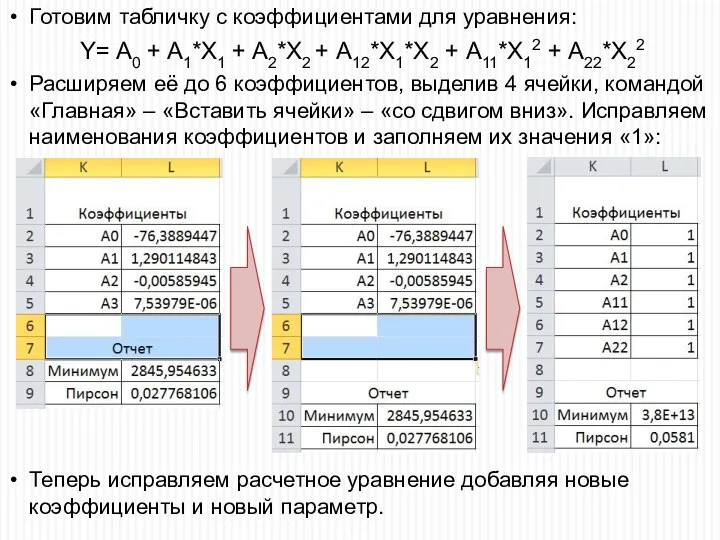
Готовим табличку с коэффициентами для уравнения:
Y= A0 + A1*X1 +
Готовим табличку с коэффициентами для уравнения:
Y= A0 + A1*X1 +
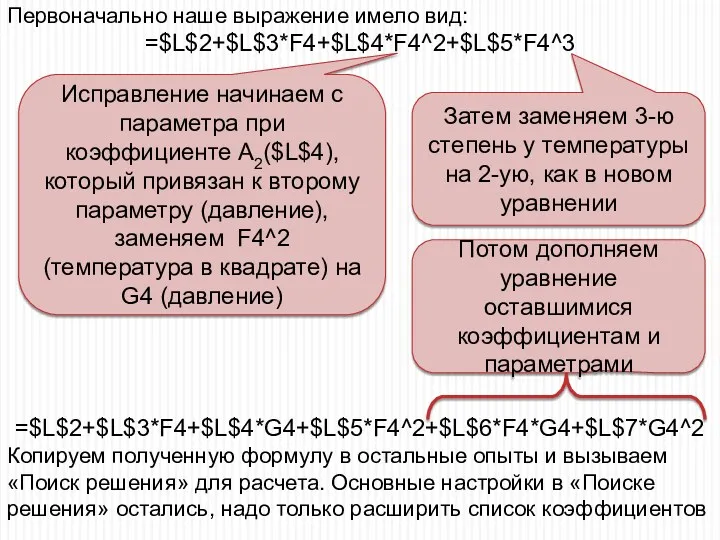
=$L$2+$L$3*F4+$L$4*G4+$L$5*F4^2+$L$6*F4*G4+$L$7*G4^2
Копируем полученную формулу в остальные опыты и вызываем «Поиск решения» для
=$L$2+$L$3*F4+$L$4*G4+$L$5*F4^2+$L$6*F4*G4+$L$7*G4^2
Копируем полученную формулу в остальные опыты и вызываем «Поиск решения» для
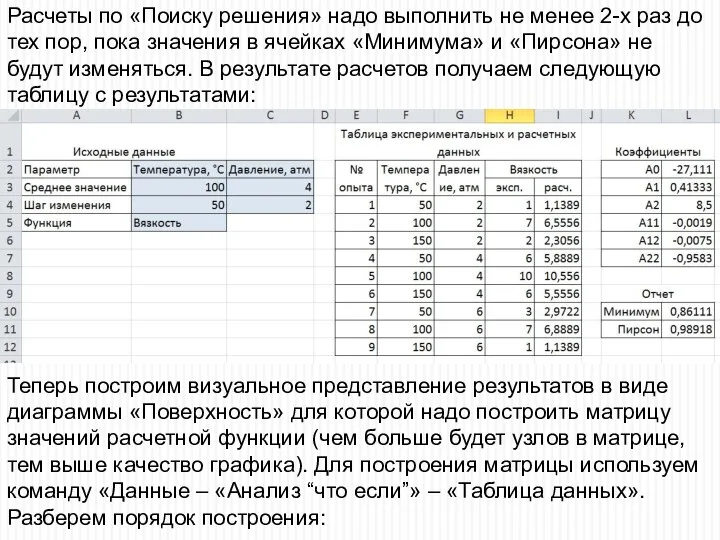
Расчеты по «Поиску решения» надо выполнить не менее 2-х раз до
Расчеты по «Поиску решения» надо выполнить не менее 2-х раз до
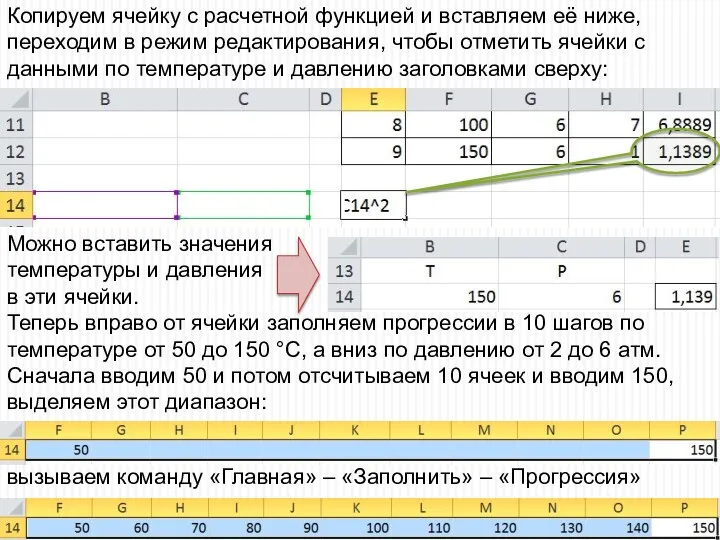
Копируем ячейку с расчетной функцией и вставляем её ниже, переходим в
Копируем ячейку с расчетной функцией и вставляем её ниже, переходим в

Повторяем эти операции для давления, только
по столбцу вниз. Сначала вводим
Повторяем эти операции для давления, только по столбцу вниз. Сначала вводим
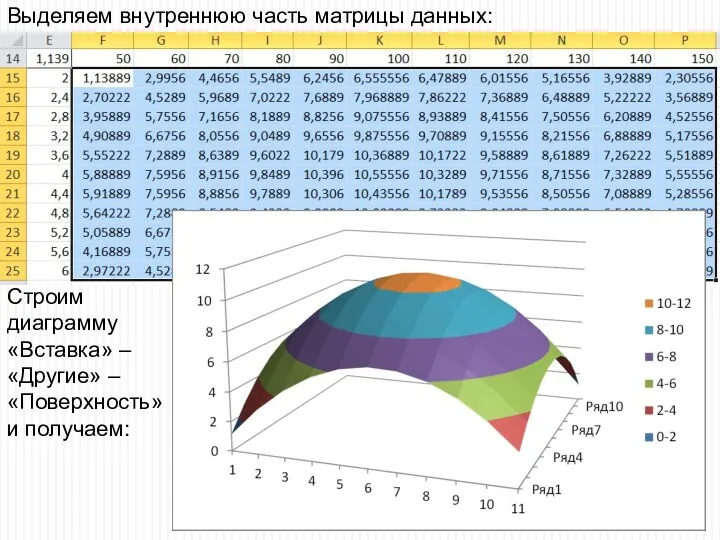
Выделяем внутреннюю часть матрицы данных:
Строим
диаграмму
«Вставка» –
«Другие» –
«Поверхность»
и
Выделяем внутреннюю часть матрицы данных:
Строим
диаграмму
«Вставка» –
«Другие» –
«Поверхность»
и

 Понятие, задачи корреляционно-регрессионного анализа и моделирования
Понятие, задачи корреляционно-регрессионного анализа и моделирования Сложение и вычитание положительных и отрицательных чисел
Сложение и вычитание положительных и отрицательных чисел Тригонометрические формулы. 10 класс
Тригонометрические формулы. 10 класс Модуль числа
Модуль числа Плоскость. Задание плоскости на чертеже. Точка и прямая в плоскости
Плоскость. Задание плоскости на чертеже. Точка и прямая в плоскости Сложение натуральных чисел и его свойства
Сложение натуральных чисел и его свойства Угол между скрещивающимися прямыми
Угол между скрещивающимися прямыми Урок алгебры в 7 классе Разложение многочленов на множители
Урок алгебры в 7 классе Разложение многочленов на множители Алгебраические выражения
Алгебраические выражения В стране занимательной математики
В стране занимательной математики Закрепление по теме : Нумерация чисел больше 1000.в 4 классе
Закрепление по теме : Нумерация чисел больше 1000.в 4 классе Презентация игры Собери неделю для старшей группы
Презентация игры Собери неделю для старшей группы Арифметикалық және геометриялық прогрессияларды есептер шығаруда қолдану
Арифметикалық және геометриялық прогрессияларды есептер шығаруда қолдану Сравнение по модулю m
Сравнение по модулю m Проверка сложения во 2 классе
Проверка сложения во 2 классе Применение ЭОР и ИКТ на уроках математики в рамках реализации ФГОС (презентация материалов из опыта работы)
Применение ЭОР и ИКТ на уроках математики в рамках реализации ФГОС (презентация материалов из опыта работы) Вычитание вида 14- ,15-
Вычитание вида 14- ,15- Это загадочное число Пи
Это загадочное число Пи Виды треугольников
Виды треугольников Презентация Времена года
Презентация Времена года Свойства действий с рациональными числами
Свойства действий с рациональными числами Методическая разработка - технологическая карта урока математики в 3 классе по теме Проверка умножения. ФГОС
Методическая разработка - технологическая карта урока математики в 3 классе по теме Проверка умножения. ФГОС Окружность, вписанная в правильный многоугольник
Окружность, вписанная в правильный многоугольник Статистические гипотезы
Статистические гипотезы Логарифмические уравнения
Логарифмические уравнения Сравнение десятичных дробей
Сравнение десятичных дробей Геометрические задачи С2, по материалам ЕГЭ
Геометрические задачи С2, по материалам ЕГЭ Решение задач в два действия
Решение задач в два действия