- Статистика

Содержание
- 2. ПРИЗНАКИ – это единицы совокупности, обладающие определенными свойствами и качествами. О.Ю. Реброва. Статистический анализ медицинских данных.
- 3. КАЧЕСТВЕННЫЕ ПРИЗНАКИ (НОМИНАЛЬНЫЕ) - это такие признаки, которые не поддаются непосредственному измерению.
- 4. Разновидностью качественных признаков, которые могут быть отнесены только к двум противоположным категориям «да – нет», принимающие
- 5. ПОРЯДКОВЫЕ ПРИЗНАКИ - это признаки, которые можно расположить в естественном порядке (ранжировать), но при этом отсутствует
- 6. КОЛИЧЕСТВЕННЫЕ ПРИЗНАКИ – признаки, количественная мера которых четко определена.
- 8. ВИД РАСПРЕДЕЛЕНИЯ соответствие, устанавливаемое между всеми возможными числовыми значениями случайной величины и вероятностями их появления в
- 9. О.Ю. Реброва. Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA. – М.: МедиаСфера, 2002. –
- 10. ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ Используются для описания событий с недифференцируемыми характеристиками, определёнными в изолированных точках.
- 11. ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ
- 12. БИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ Описывает распределение частоты события, обладающего постоянной вероятностью появления при многократных испытаниях. То есть это
- 13. РАСПРЕДЕЛЕНИЕ ПУАССОНА Описывает события, при которых с возрастанием значения случайной величины, вероятность появления ее в совокупности
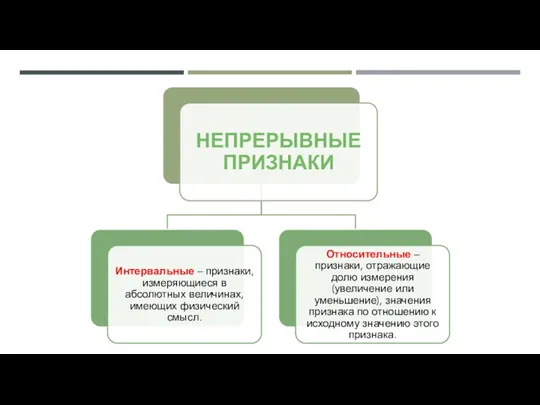
- 14. НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ это распределение случайной вещественной величины, принимающей значения, принадлежащие некоторому промежутку конечной длины, характеризующееся тем,
- 15. НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ
- 16. НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ (ГАУССОВО, СИММЕТРИЧНОЕ, КОЛОКОЛООБРАЗНОЕ) Описывает совместное воздействие на изучаемое явление небольшого числа случайно сочетающихся факторов
- 17. НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
- 19. ВСЕ СТАТИСТИЧЕСКИЕ ПОКАЗАТЕЛИ ДЕЛЯТСЯ НА 3 БОЛЬШИЕ ГРУППЫ: Меры центральной тенденции - показывают расположение среднего, типичного
- 20. Среднее значение (М) - среднее арифметическое Медиана (Ме) - средняя точка распределения Если кол-во значений нечетное,
- 21. МЕРЫ РАССЕЯНИЯ (МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ) Дисперсия - характеризует, насколько частные значения отклоняются от средней величины
- 22. МЕРЫ РАССЕЯНИЯ (МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ) Размах - разность максимального и минимального значения (Недостаток: не характеризует
- 23. ПОНЯТИЕ О КВАНТИЛЯХ Квантили (ед.ч. - Квантиль) - величины, разделяющие ранжированный ряд на равные части. Разновидности
- 24. ПОДРОБНЕЕ О КВАРТИЛЯХ Квартили делят ранжированный ряд на 4 равные части Нижний (первый) квартиль Q1 -
- 25. АНАЛИЗ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ Первый этап - анализ вида распределения От вида распределения зависят: Выбор способа описания
- 26. КАК ОПРЕДЕЛИТЬ ВИД РАСПРЕДЕЛЕНИЯ? 4 способа с помощью программы STATISTICA: Качественные: 1. Построение гистограммы (Graphs =>
- 27. Количественные: 3. Оценка симметричности распределения признаков СКО 4. Проверка статистических гипотез (используется крайне редко): Нулевая гипотеза
- 28. 3 критерия: Колмогорова - Смирнова (λ-критерий): применяется, если среднее значение и среднее квадратическое отклонение известны априори
- 29. ОПРЕДЕЛЕНИЕ КРИТЕРИЕВ В ПРОГРАММЕ STATISTICA Statistics => Basic Statistics/Tables => =>Descriptive statistics => Normality (здесь же,
- 30. ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ После использования программы STATISTICA будут получены результаты анализа распределения каждого признака - р. Если
- 31. КАКИЕ ДАННЫЕ НЕОБХОДИМО УКАЗЫВАТЬ ПРИ ОПИСАНИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ? Число наблюдений (объектов исследования) Среднее значение Среднее квадратическое
- 32. ПРИ ОПИСАНИИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ СЛЕДУЕТ ОБЯЗАТЕЛЬНО УКАЗЫВАТЬ ЧИСЛО НАБЛЮДЕНИЙ (ОБЪЕКТОВ ИССЛЕДОВАНИЯ) - N Пример: Исследуют группу
- 33. Статистические методы делят на: Параметрические (основываются на оценке параметров: среднее значение или стандартное отклонение; применяются для
- 34. СРАВНЕНИЕ ПАРАМЕТРИЧЕСКИХ И НЕПАРАМЕТРИЧЕСКИХ МЕТОДОВ К преимуществам непараметрических методов можно отнести следующие: могут быть использованы, когда
- 35. ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ 1. Непарный t-тест (тест Стьюдента) - с его помощью проводят проверку нулевой гипотезы ("H0")
- 36. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ I. Для непрерывных переменных (данные, полученные на непрерывной шкале: АД, масса, рост) U-тест Манна-Уитни
- 37. U-ТЕСТ МАННА-УИТНИ (MANN-WHITNEY U) ИЛИ ТЕСТ МАННА-УИТНИ-ВИЛКОКСОНА (MWW) U-критерий Манна-Уитни - используется для сравнения двух независимых
- 39. Качественная переменная Количественная переменная ? ДВЕ ПЕРЕМЕННЫЕ
- 40. КАК УЗНАТЬ, БУДУТ ЛИ ЗАВИСИМЫ ДРУГ ОТ ДРУГА ДВЕ ПЕРЕМЕННЫЕ? Две разные переменные зависимы в том
- 44. 1 выборка случайных переменных
- 45. ВЕЛИЧИНА 100 100 Из случайной выборки у каждого мужчины лейкоцитов больше, чем у случайно выбранных женщин
- 46. 2 выборка случайных переменных
- 47. НАДЕЖНОСТЬ (ИСТИННОСТЬ) 100 100 Из случайной выборки у одной женщины лейкоцитов больше, чем у случайно выбранных
- 48. ЧТО ТАКОЕ P-УРОВЕНЬ (ЗНАЧИМОСТЬ) Значимость – оценённая мера уверенности в его «истинности». Р-уровень находится в обратной
- 49. 100 100 ЗНАЧИМОСТЬ Данная зависимость встретилась лишь 5 раз из 100 выборок. Р-уровень = 0,05. Связь
- 51. Скачать презентацию
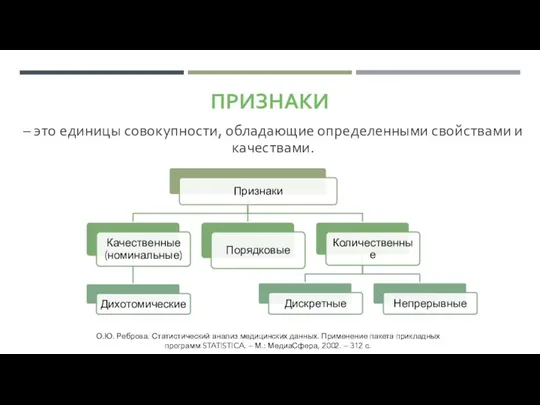
ПРИЗНАКИ
– это единицы совокупности, обладающие определенными свойствами и качествами.
О.Ю. Реброва. Статистический
ПРИЗНАКИ
– это единицы совокупности, обладающие определенными свойствами и качествами.
О.Ю. Реброва. Статистический

КАЧЕСТВЕННЫЕ ПРИЗНАКИ
(НОМИНАЛЬНЫЕ)
- это такие признаки, которые не поддаются непосредственному измерению.
КАЧЕСТВЕННЫЕ ПРИЗНАКИ
(НОМИНАЛЬНЫЕ)
- это такие признаки, которые не поддаются непосредственному измерению.

Разновидностью качественных признаков, которые могут быть отнесены только к двум противоположным
Разновидностью качественных признаков, которые могут быть отнесены только к двум противоположным
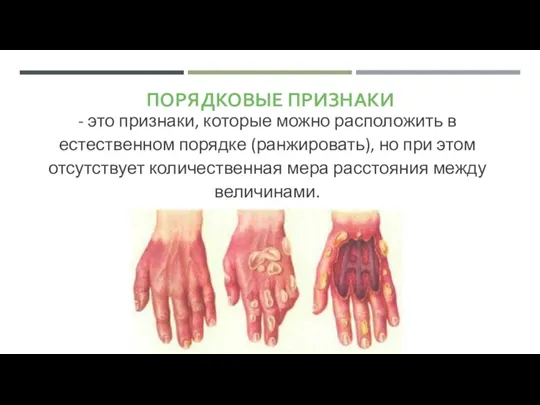
ПОРЯДКОВЫЕ ПРИЗНАКИ
- это признаки, которые можно расположить в естественном порядке (ранжировать),
ПОРЯДКОВЫЕ ПРИЗНАКИ
- это признаки, которые можно расположить в естественном порядке (ранжировать),
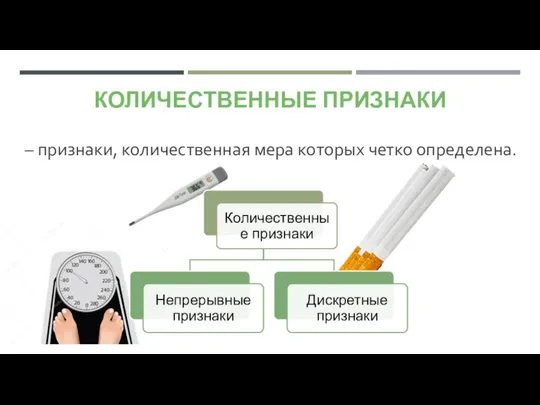
КОЛИЧЕСТВЕННЫЕ ПРИЗНАКИ
– признаки, количественная мера которых четко определена.
КОЛИЧЕСТВЕННЫЕ ПРИЗНАКИ
– признаки, количественная мера которых четко определена.

ВИД РАСПРЕДЕЛЕНИЯ
соответствие, устанавливаемое между всеми возможными числовыми значениями случайной величины и
ВИД РАСПРЕДЕЛЕНИЯ
соответствие, устанавливаемое между всеми возможными числовыми значениями случайной величины и

О.Ю. Реброва. Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA.
О.Ю. Реброва. Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA.

ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ
Используются для описания событий с недифференцируемыми характеристиками, определёнными в изолированных
ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ
Используются для описания событий с недифференцируемыми характеристиками, определёнными в изолированных
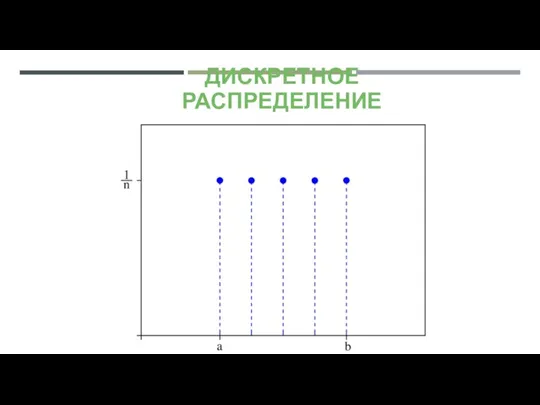
ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ
ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ

БИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Описывает распределение частоты события, обладающего постоянной вероятностью появления при многократных испытаниях.
БИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Описывает распределение частоты события, обладающего постоянной вероятностью появления при многократных испытаниях.

РАСПРЕДЕЛЕНИЕ ПУАССОНА
Описывает события, при которых с возрастанием значения случайной величины, вероятность
РАСПРЕДЕЛЕНИЕ ПУАССОНА
Описывает события, при которых с возрастанием значения случайной величины, вероятность

НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ
это распределение случайной вещественной величины, принимающей значения, принадлежащие некоторому промежутку конечной длины, характеризующееся
НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ
это распределение случайной вещественной величины, принимающей значения, принадлежащие некоторому промежутку конечной длины, характеризующееся

НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ
НЕПРЕРЫВНОЕ РАСПРЕДЕЛЕНИЕ

НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
(ГАУССОВО, СИММЕТРИЧНОЕ, КОЛОКОЛООБРАЗНОЕ)
Описывает совместное воздействие на изучаемое явление небольшого
НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
(ГАУССОВО, СИММЕТРИЧНОЕ, КОЛОКОЛООБРАЗНОЕ)
Описывает совместное воздействие на изучаемое явление небольшого
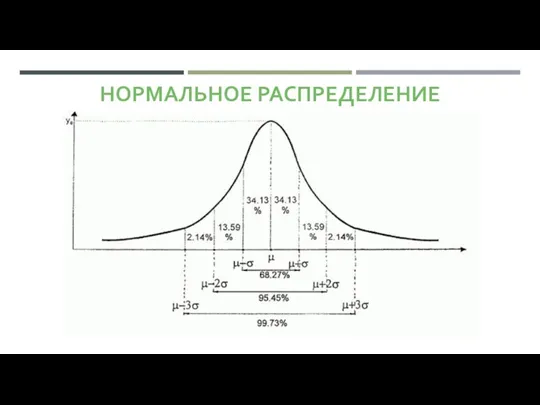
НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ

ВСЕ СТАТИСТИЧЕСКИЕ ПОКАЗАТЕЛИ ДЕЛЯТСЯ НА 3 БОЛЬШИЕ ГРУППЫ:
Меры центральной тенденции -
ВСЕ СТАТИСТИЧЕСКИЕ ПОКАЗАТЕЛИ ДЕЛЯТСЯ НА 3 БОЛЬШИЕ ГРУППЫ:
Меры центральной тенденции -

Среднее значение (М) - среднее арифметическое
Медиана (Ме) - средняя точка распределения
Если
Среднее значение (М) - среднее арифметическое
Медиана (Ме) - средняя точка распределения
Если

МЕРЫ РАССЕЯНИЯ
(МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ)
Дисперсия - характеризует, насколько частные значения отклоняются
МЕРЫ РАССЕЯНИЯ
(МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ)
Дисперсия - характеризует, насколько частные значения отклоняются

МЕРЫ РАССЕЯНИЯ
(МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ)
Размах - разность максимального и минимального
МЕРЫ РАССЕЯНИЯ
(МЕРЫ ИЗМЕНЧИВОСТИ, ПОКАЗАТЕЛИ ВАРИАЦИИ)
Размах - разность максимального и минимального

ПОНЯТИЕ О КВАНТИЛЯХ
Квантили (ед.ч. - Квантиль) - величины, разделяющие
ранжированный
ПОНЯТИЕ О КВАНТИЛЯХ
Квантили (ед.ч. - Квантиль) - величины, разделяющие ранжированный

ПОДРОБНЕЕ О КВАРТИЛЯХ
Квартили делят ранжированный ряд на 4 равные части
Нижний (первый)
ПОДРОБНЕЕ О КВАРТИЛЯХ
Квартили делят ранжированный ряд на 4 равные части
Нижний (первый)

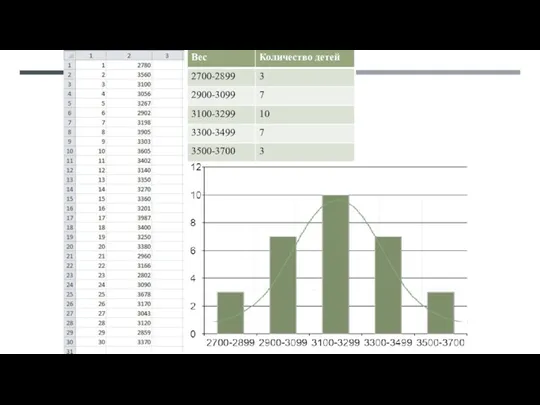
АНАЛИЗ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ
Первый этап - анализ вида распределения
От вида распределения зависят:
Выбор способа
АНАЛИЗ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ
Первый этап - анализ вида распределения
От вида распределения зависят:
Выбор способа

КАК ОПРЕДЕЛИТЬ ВИД РАСПРЕДЕЛЕНИЯ?
4 способа с помощью программы STATISTICA:
Качественные:
1. Построение гистограммы
КАК ОПРЕДЕЛИТЬ ВИД РАСПРЕДЕЛЕНИЯ?
4 способа с помощью программы STATISTICA:
Качественные:
1. Построение гистограммы

Количественные:
3. Оценка симметричности распределения признаков
СКО<(M/2)
(Среднее квадратическое отклонение должно быть
Количественные:
3. Оценка симметричности распределения признаков
СКО<(M/2)
(Среднее квадратическое отклонение должно быть

3 критерия:
Колмогорова - Смирнова (λ-критерий): применяется, если среднее значение и среднее квадратическое
3 критерия:
Колмогорова - Смирнова (λ-критерий): применяется, если среднее значение и среднее квадратическое

ОПРЕДЕЛЕНИЕ КРИТЕРИЕВ В ПРОГРАММЕ STATISTICA
Statistics => Basic Statistics/Tables =>
=>Descriptive statistics
ОПРЕДЕЛЕНИЕ КРИТЕРИЕВ В ПРОГРАММЕ STATISTICA
Statistics => Basic Statistics/Tables => =>Descriptive statistics

ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ
После использования программы STATISTICA будут получены результаты анализа распределения каждого
ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ
После использования программы STATISTICA будут получены результаты анализа распределения каждого

КАКИЕ ДАННЫЕ НЕОБХОДИМО УКАЗЫВАТЬ ПРИ ОПИСАНИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ?
Число наблюдений (объектов исследования)
Среднее
КАКИЕ ДАННЫЕ НЕОБХОДИМО УКАЗЫВАТЬ ПРИ ОПИСАНИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ?
Число наблюдений (объектов исследования)
Среднее

ПРИ ОПИСАНИИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ СЛЕДУЕТ ОБЯЗАТЕЛЬНО УКАЗЫВАТЬ ЧИСЛО НАБЛЮДЕНИЙ
(ОБЪЕКТОВ ИССЛЕДОВАНИЯ)
ПРИ ОПИСАНИИИ КОЛИЧЕСТВЕННЫХ ПРИЗНАКОВ СЛЕДУЕТ ОБЯЗАТЕЛЬНО УКАЗЫВАТЬ ЧИСЛО НАБЛЮДЕНИЙ (ОБЪЕКТОВ ИССЛЕДОВАНИЯ)

Статистические методы делят на:
Параметрические (основываются на оценке параметров: среднее значение или стандартное отклонение; применяются для количественных
Статистические методы делят на:
Параметрические (основываются на оценке параметров: среднее значение или стандартное отклонение; применяются для количественных

СРАВНЕНИЕ ПАРАМЕТРИЧЕСКИХ И НЕПАРАМЕТРИЧЕСКИХ МЕТОДОВ
К преимуществам непараметрических методов можно отнести
СРАВНЕНИЕ ПАРАМЕТРИЧЕСКИХ И НЕПАРАМЕТРИЧЕСКИХ МЕТОДОВ
К преимуществам непараметрических методов можно отнести

ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ
1. Непарный t-тест (тест Стьюдента) - с его помощью проводят
ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ
1. Непарный t-тест (тест Стьюдента) - с его помощью проводят

НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ
I. Для непрерывных переменных (данные, полученные на непрерывной шкале: АД,
НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ
I. Для непрерывных переменных (данные, полученные на непрерывной шкале: АД,

U-ТЕСТ МАННА-УИТНИ (MANN-WHITNEY U)
ИЛИ ТЕСТ МАННА-УИТНИ-ВИЛКОКСОНА (MWW)
U-критерий Манна-Уитни - используется
U-ТЕСТ МАННА-УИТНИ (MANN-WHITNEY U)
ИЛИ ТЕСТ МАННА-УИТНИ-ВИЛКОКСОНА (MWW)
U-критерий Манна-Уитни - используется


Качественная переменная
Количественная переменная
?
ДВЕ ПЕРЕМЕННЫЕ
Качественная переменная
Количественная переменная
?
ДВЕ ПЕРЕМЕННЫЕ

КАК УЗНАТЬ, БУДУТ ЛИ ЗАВИСИМЫ ДРУГ ОТ ДРУГА ДВЕ ПЕРЕМЕННЫЕ?
Две разные
КАК УЗНАТЬ, БУДУТ ЛИ ЗАВИСИМЫ ДРУГ ОТ ДРУГА ДВЕ ПЕРЕМЕННЫЕ?
Две разные
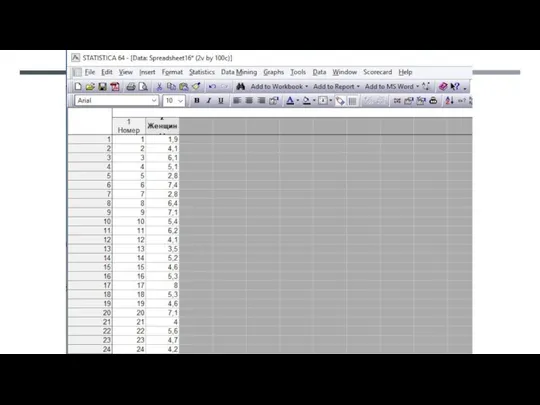
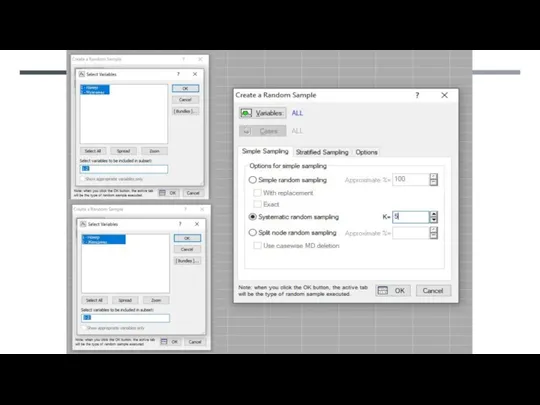
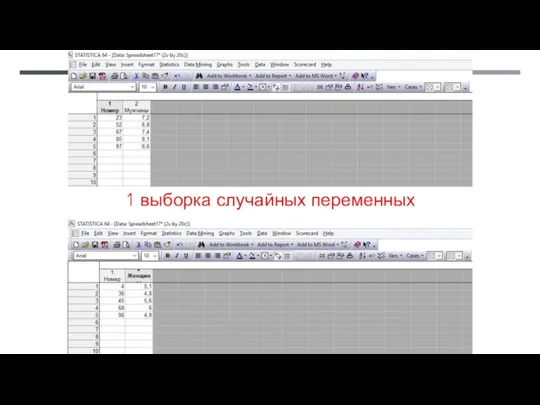
1 выборка случайных переменных
1 выборка случайных переменных

ВЕЛИЧИНА
100
100
Из случайной выборки у каждого мужчины лейкоцитов больше, чем у случайно
ВЕЛИЧИНА
100
100
Из случайной выборки у каждого мужчины лейкоцитов больше, чем у случайно
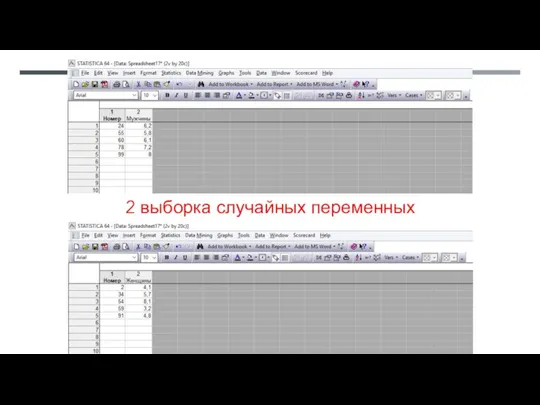
2 выборка случайных переменных
2 выборка случайных переменных

НАДЕЖНОСТЬ (ИСТИННОСТЬ)
100
100
Из случайной выборки у одной женщины лейкоцитов больше, чем у
НАДЕЖНОСТЬ (ИСТИННОСТЬ)
100
100
Из случайной выборки у одной женщины лейкоцитов больше, чем у

ЧТО ТАКОЕ P-УРОВЕНЬ (ЗНАЧИМОСТЬ)
Значимость – оценённая мера уверенности в его «истинности».
ЧТО ТАКОЕ P-УРОВЕНЬ (ЗНАЧИМОСТЬ)
Значимость – оценённая мера уверенности в его «истинности».

100
100
ЗНАЧИМОСТЬ
Данная зависимость встретилась лишь 5 раз из 100 выборок.
Р-уровень =
100
100
ЗНАЧИМОСТЬ
Данная зависимость встретилась лишь 5 раз из 100 выборок. Р-уровень =
 Пакет материалов и рекомендаций для самостоятельной работы гимназистов
Пакет материалов и рекомендаций для самостоятельной работы гимназистов Формулы для радиусов вписанной и описанной окружности треугольника
Формулы для радиусов вписанной и описанной окружности треугольника Урок математики
Урок математики Действия с дробями. Сложение и вычитание
Действия с дробями. Сложение и вычитание Решение задач на тему Сумма углов треугольника
Решение задач на тему Сумма углов треугольника Разложение на множители. 7 класс
Разложение на множители. 7 класс Дифференцированный подход в обучении на занятиях по математике с учётом развития речи
Дифференцированный подход в обучении на занятиях по математике с учётом развития речи Умножение числа 3 и на 3
Умножение числа 3 и на 3 Комбинаторные задачи
Комбинаторные задачи Анаграммы. Квадратные уравнения
Анаграммы. Квадратные уравнения Урок-сказка
Урок-сказка Исследование устойчивости рынка ВРП методами Ляпунова. Лекция 6
Исследование устойчивости рынка ВРП методами Ляпунова. Лекция 6 Конкретный смысл действия умножения. Устный счёт
Конкретный смысл действия умножения. Устный счёт Устный счет
Устный счет Лекция по медицинской статистике
Лекция по медицинской статистике Двойное неравенство
Двойное неравенство Решение уравнений. Урок-обобщение
Решение уравнений. Урок-обобщение Занимательные задачи
Занимательные задачи Дисперсия дискретной случайной величины
Дисперсия дискретной случайной величины Понятие одночлена. Стандартный вид одночлена
Понятие одночлена. Стандартный вид одночлена Геодезия. Определение площадей
Геодезия. Определение площадей ЕГЭ - профиль №15. 2018 год
ЕГЭ - профиль №15. 2018 год Сложение вида +4
Сложение вида +4 Способы решения логарифмических уравнений
Способы решения логарифмических уравнений Аксиома параллельных прямых. Доказательство от противного
Аксиома параллельных прямых. Доказательство от противного Применение распределительного свойства умножения
Применение распределительного свойства умножения Преобразование подобия. Гомотетия
Преобразование подобия. Гомотетия Второй замечательный предел. Лекция 7
Второй замечательный предел. Лекция 7