- Абстрактные структуры данных

Содержание
- 2. Абстрактные структуры данных Базовые структуры Базовыми структуры данных называют также примитивными или простыми структурами. Эти структуры
- 3. Абстрактные структуры данных Статические структуры Статические структуры относятся к разряду непримитивных структур, которые, фактически, представляют собой
- 4. Абстрактные структуры данных Полустатические структуры Полустатические структуры данных характеризуются следующими признаками: (1) они имеют переменную длину
- 5. Абстрактные структуры данных Динамические структуры Динамические структуры характерны отсутствием физической смежности элементов структуры в памяти и
- 6. Линейные связанные списки – упорядоченное множество, состоящее из переменного числа элементов, отражающий отношения соседства между элементами.
- 7. Абстрактные структуры данных Файловые структуры Файловые структуры данных – это сами файлы, их внутренняя организация и
- 8. Структуры данных Стек (stack) Стеки – последовательный список переменной длины, включение и исключение элементов из которого
- 9. Структуры данных C / С++ Стек (stack) int stack [MAX]; int tos=0; // вершина стека void
- 10. Классы и объекты #include #define SIZE 100 // Определение класса stack class stack { int stck[SIZE];
- 11. #include struct stek // Описание элемента стека { int value; struct stek *next; /* значение, следующий
- 12. Структуры данных Очереди (queue) Очереди – последовательный (линейный) список переменной длины, в котором добавление элементов выполняется
- 14. Скачать презентацию

Абстрактные структуры данных
Базовые структуры
Базовыми структуры данных называют также примитивными или
Абстрактные структуры данных
Базовые структуры
Базовыми структуры данных называют также примитивными или

Абстрактные структуры данных
Статические структуры
Статические структуры относятся к разряду непримитивных структур,
Абстрактные структуры данных
Статические структуры
Статические структуры относятся к разряду непримитивных структур,

Абстрактные структуры данных
Полустатические структуры
Полустатические структуры данных характеризуются следующими признаками: (1)
Абстрактные структуры данных
Полустатические структуры
Полустатические структуры данных характеризуются следующими признаками: (1)

Абстрактные структуры данных
Динамические структуры
Динамические структуры характерны отсутствием физической смежности элементов
Абстрактные структуры данных
Динамические структуры
Динамические структуры характерны отсутствием физической смежности элементов

Линейные связанные списки – упорядоченное множество, состоящее из переменного числа
Линейные связанные списки – упорядоченное множество, состоящее из переменного числа

Абстрактные структуры данных
Файловые структуры
Файловые структуры данных – это сами файлы,
Абстрактные структуры данных
Файловые структуры
Файловые структуры данных – это сами файлы,

Структуры данных
Стек (stack)
Стеки – последовательный список переменной длины, включение и
Структуры данных
Стек (stack)
Стеки – последовательный список переменной длины, включение и
![Структуры данных C / С++ Стек (stack) int stack [MAX];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/53743/slide-8.jpg)
Структуры данных
C / С++
Стек (stack)
int stack [MAX];
int tos=0; //
Структуры данных
C / С++
Стек (stack)
int stack [MAX];
int tos=0; //

Классы и объекты
#include
#define SIZE 100
// Определение класса stack
class stack
{
int
Классы и объекты
#include
#define SIZE 100
// Определение класса stack
class stack
{
int

#include
struct stek // Описание элемента стека
{ int value; struct stek
#include
struct stek // Описание элемента стека
{ int value; struct stek

Структуры данных
Очереди (queue)
Очереди – последовательный (линейный) список переменной длины, в
Структуры данных
Очереди (queue)
Очереди – последовательный (линейный) список переменной длины, в
 Предприятие – основное звено экономики
Предприятие – основное звено экономики Химиялық композиттер
Химиялық композиттер Транспортная задача
Транспортная задача Информационно-практический проект Спасибо Бэмби!
Информационно-практический проект Спасибо Бэмби! Расчет дуговой электросталеплавильной печи емкостью 5т
Расчет дуговой электросталеплавильной печи емкостью 5т Лексикология и ее разделы
Лексикология и ее разделы Страшный суд
Страшный суд Исполнение районного бюджета Амурского района по налоговым, неналоговым доходам за 2016 год
Исполнение районного бюджета Амурского района по налоговым, неналоговым доходам за 2016 год Презентация Мир оригами
Презентация Мир оригами Конкурс МЕТОДСЕМИНАР
Конкурс МЕТОДСЕМИНАР Элементы системы вентиляции. Конструкции
Элементы системы вентиляции. Конструкции Программа Поток. Расчёт систем отопления
Программа Поток. Расчёт систем отопления Кроссворд о воде
Кроссворд о воде Путешествие в царство живой природы
Путешествие в царство живой природы Системы компьютерной математики
Системы компьютерной математики Транспортная Логистика
Транспортная Логистика Сложение и вычитание чисел в пределах 1000 с переходом через разряд
Сложение и вычитание чисел в пределах 1000 с переходом через разряд Пикорнавирустар. Полиомиелит вирусы. Коксаки. Есно
Пикорнавирустар. Полиомиелит вирусы. Коксаки. Есно Прямоугольная система координат в пространстве. 11 класс
Прямоугольная система координат в пространстве. 11 класс Қималарды салу
Қималарды салу Основы логики
Основы логики классный час по пдд для 1-2 классов
классный час по пдд для 1-2 классов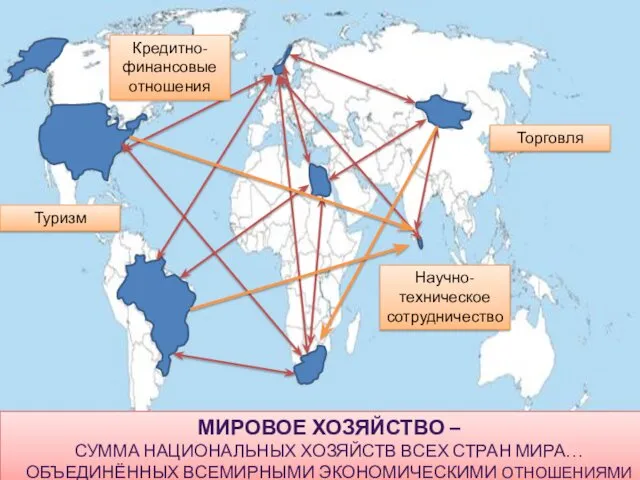 Мировая глобализация
Мировая глобализация Телереклама стиральных машин
Телереклама стиральных машин Рестриктивная кардиомиопатия
Рестриктивная кардиомиопатия Утка мандаринка
Утка мандаринка Amphitheater towards the sun
Amphitheater towards the sun Джеффри Престон Безос. Основатель сервиса Amazon.com
Джеффри Престон Безос. Основатель сервиса Amazon.com