Архитектура параллельных вычислительных систем. Часть 1. История и проблематика. Основы параллельного программирования презентация
- Архитектура параллельных вычислительных систем. Часть 1. История и проблематика. Основы параллельного программирования

Содержание
- 2. Литература Гергель В.П. Теория и практика параллельных вычислений. - М.: Интернет-Университет, БИНОМ. Лаборатория знаний, 2007. Богачев
- 3. Серия книг “Суперкомпьютерное образование” – лауреат национальной премии “Книга года” (номинация “Учебник XXI века”)
- 4. Рост производительности вычислительных систем
- 5. Почему нужны параллельные вычисления… Опережение потребности в вычислениях быстродействия существующих компьютерных систем Оценка необходимой производительности –
- 6. Почему нужны параллельные вычисления… Теоретическая ограниченность роста производительности последовательных компьютеров Резкое снижение стоимости многопроцессорных (параллельных) вычислительных
- 7. Сдерживающие факторы… высокая стоимость параллельных систем – в соответствии с законом Гроша (Grosch), производительность компьютера возрастает
- 8. Сдерживающие факторы… постоянное совершенствование последовательных компьютеров – в соответствии с законом Мура (Moore) мощность последовательных процессоров
- 9. Сдерживающие факторы… зависимость эффективности параллелизма от учета характерных свойств параллельных систем (отсутствие мобильности для параллельных программ)
- 10. Пути достижения параллелизма… Достижение параллелизма возможно только при выполнимости следующих требований: независимость функционирования отдельных устройств ЭВМ
- 11. Пути достижения параллелизма… Возможные режимы выполнения независимых частей программы: многозадачный режим (режим разделения времени), при котором
- 12. Основное внимание будем уделять второму типу организации параллелизма, реализуемому на многопроцессорных вычислительных системах
- 13. Примеры параллельных вычислительных систем… Суперкомпьютеры Существует мировой рейтинг суперкомпьютерных систем: ТОП500. http://www.top500.org Рейтинг содержит 500 лучших
- 14. Исторические примеры Суперкомпьютеры. Программа ASCI (США) (Accelerated Strategic Computing Initiative) 1996, система ASCI Red, построенная Intel,
- 15. Примеры параллельных вычислительных систем… Суперкомпьютеры. Система BlueGene Первый вариант системы представлен в 2004 г. и сразу
- 16. Примеры параллельных вычислительных систем… Кластеры Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и
- 17. Примеры параллельных вычислительных систем… Кластеры. Beowulf В настоящее время под кластером типа “Beowulf” понимается вычислительная система,
- 18. Примеры параллельных вычислительных систем… Кластеры. Beowulf… 1994, научно-космический центр NASA Goddard Space Flight Center, руководители проекта
- 19. Примеры параллельных вычислительных систем… Кластеры. AC3 Velocity Cluster 2000, Корнельский университет (США), результат совместной работы университета
- 20. Кластеры. Thunder 2004, Ливерморская Национальная Лаборатория (США): 1024 сервера, в каждом по 4 процессора Intel Itanium
- 21. Примеры параллельных вычислительных систем… Кластер. Ломоносов-2 (МГУ им. М.В. Ломоносова) 2016, 41 место в рейтинге на
- 22. Задача Метод Алгоритм Технологии программирования Программа Системное ПО Компьютер (миллионы, миллиарды…) Предметная сторона Компьютерная сторона Выполнение
- 23. 1 Pflop/s system… Что мы ожидаем? Суперкомпьютерные центры: ожидания и реальность 1Pflop * 60sec * 60min
- 24. Усредненная производительность одного ядра суперкомпьютера “Чебышев” за 3 дня Эффективность суперкомпьютерных центров (простая оценка)
- 25. Проекты, приложения Очереди заданий Динамика приложения Поток приложений Стек ПО Компоненты компьютера Инж.инфраструктура CPU usage: user,
- 27. Скачать презентацию

Литература
Гергель В.П. Теория и практика параллельных вычислений. - М.: Интернет-Университет, БИНОМ.
Литература
Гергель В.П. Теория и практика параллельных вычислений. - М.: Интернет-Университет, БИНОМ.
Серия книг “Суперкомпьютерное образование” – лауреат национальной премии “Книга года”
(номинация “Учебник
Серия книг “Суперкомпьютерное образование” – лауреат национальной премии “Книга года”
(номинация “Учебник
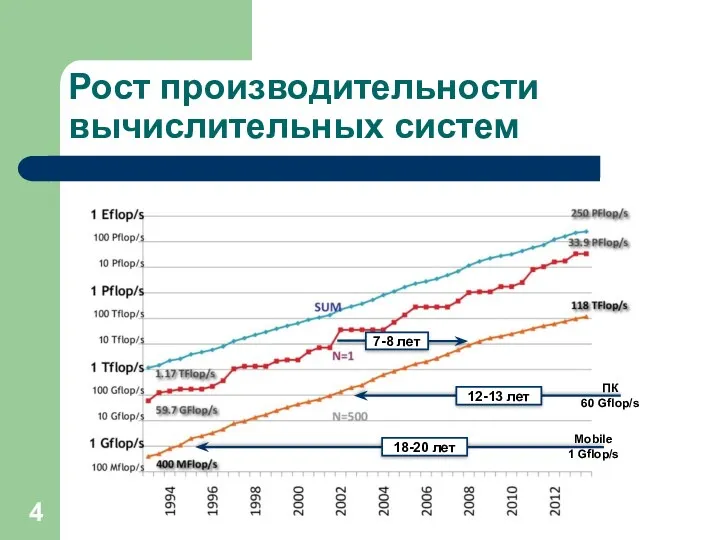
Рост производительности вычислительных систем
Рост производительности вычислительных систем

Почему нужны параллельные вычисления…
Опережение потребности в вычислениях быстродействия существующих компьютерных систем
Почему нужны параллельные вычисления…
Опережение потребности в вычислениях быстродействия существующих компьютерных систем

Почему нужны параллельные вычисления…
Теоретическая ограниченность роста производительности последовательных компьютеров
Резкое снижение стоимости
Почему нужны параллельные вычисления…
Теоретическая ограниченность роста производительности последовательных компьютеров
Резкое снижение стоимости

Сдерживающие факторы…
высокая стоимость параллельных систем –
в соответствии с законом Гроша
Сдерживающие факторы…
высокая стоимость параллельных систем – в соответствии с законом Гроша

Сдерживающие факторы…
постоянное совершенствование последовательных компьютеров – в соответствии с законом Мура
Сдерживающие факторы…
постоянное совершенствование последовательных компьютеров – в соответствии с законом Мура

Сдерживающие факторы…
зависимость эффективности параллелизма от учета характерных свойств параллельных систем (отсутствие
Сдерживающие факторы…
зависимость эффективности параллелизма от учета характерных свойств параллельных систем (отсутствие

Пути достижения параллелизма…
Достижение параллелизма возможно только при выполнимости следующих требований:
независимость функционирования
Пути достижения параллелизма…
Достижение параллелизма возможно только при выполнимости следующих требований:
независимость функционирования

Пути достижения параллелизма…
Возможные режимы выполнения независимых частей программы:
многозадачный режим (режим разделения
Пути достижения параллелизма…
Возможные режимы выполнения независимых частей программы:
многозадачный режим (режим разделения

Основное внимание будем уделять второму типу организации параллелизма, реализуемому на многопроцессорных

Примеры параллельных вычислительных систем…
Суперкомпьютеры
Существует мировой рейтинг суперкомпьютерных систем: ТОП500.
http://www.top500.org
Рейтинг содержит 500
Примеры параллельных вычислительных систем…
Суперкомпьютеры
Существует мировой рейтинг суперкомпьютерных систем: ТОП500.
http://www.top500.org
Рейтинг содержит 500

Исторические примеры
Суперкомпьютеры. Программа ASCI (США)
(Accelerated Strategic Computing Initiative)
1996, система ASCI Red,
Исторические примеры
Суперкомпьютеры. Программа ASCI (США)
(Accelerated Strategic Computing Initiative)
1996, система ASCI Red,

Примеры параллельных вычислительных систем…
Суперкомпьютеры. Система BlueGene
Первый вариант системы представлен в 2004
Примеры параллельных вычислительных систем…
Суперкомпьютеры. Система BlueGene
Первый вариант системы представлен в 2004

Примеры параллельных вычислительных систем…
Кластеры
Кластер – группа компьютеров, объединенных в локальную вычислительную
Примеры параллельных вычислительных систем…
Кластеры
Кластер – группа компьютеров, объединенных в локальную вычислительную

Примеры параллельных вычислительных систем…
Кластеры. Beowulf
В настоящее время под кластером типа “Beowulf”
Примеры параллельных вычислительных систем…
Кластеры. Beowulf
В настоящее время под кластером типа “Beowulf”

Примеры параллельных вычислительных систем…
Кластеры. Beowulf…
1994, научно-космический центр NASA Goddard Space Flight
Примеры параллельных вычислительных систем…
Кластеры. Beowulf…
1994, научно-космический центр NASA Goddard Space Flight

Примеры параллельных вычислительных систем…
Кластеры. AC3 Velocity Cluster
2000, Корнельский университет (США),
Примеры параллельных вычислительных систем…
Кластеры. AC3 Velocity Cluster
2000, Корнельский университет (США),

Кластеры. Thunder
2004, Ливерморская Национальная Лаборатория (США):
1024 сервера, в каждом
Кластеры. Thunder
2004, Ливерморская Национальная Лаборатория (США):
1024 сервера, в каждом

Примеры параллельных вычислительных систем…
Кластер. Ломоносов-2
(МГУ им. М.В. Ломоносова)
2016, 41 место
Примеры параллельных вычислительных систем…
Кластер. Ломоносов-2
(МГУ им. М.В. Ломоносова)
2016, 41 место
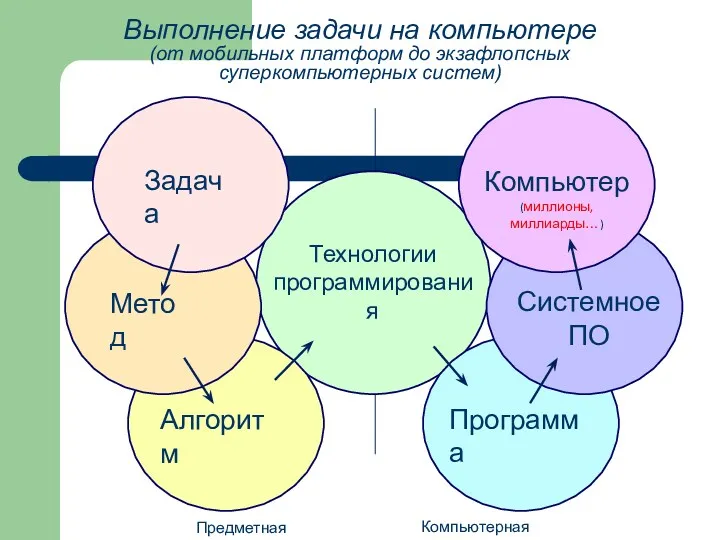
Задача
Метод
Алгоритм
Технологии
программирования
Программа
Системное ПО
Компьютер
(миллионы, миллиарды…)
Предметная сторона
Компьютерная сторона
Выполнение задачи на компьютере
(от мобильных платформ до
Задача
Метод
Алгоритм
Технологии
программирования
Программа
Системное ПО
Компьютер
(миллионы, миллиарды…)
Предметная сторона
Компьютерная сторона
Выполнение задачи на компьютере
(от мобильных платформ до

1 Pflop/s system… Что мы ожидаем?
Суперкомпьютерные центры:
ожидания и реальность
1Pflop
1 Pflop/s system… Что мы ожидаем?
Суперкомпьютерные центры:
ожидания и реальность
1Pflop

Усредненная производительность одного ядра
суперкомпьютера “Чебышев” за 3 дня
Эффективность суперкомпьютерных центров
(простая
Усредненная производительность одного ядра
суперкомпьютера “Чебышев” за 3 дня
Эффективность суперкомпьютерных центров
(простая

Проекты, приложения
Очереди заданий
Динамика приложения
Поток приложений
Стек ПО
Компоненты компьютера
Инж.инфраструктура
CPU usage:
user, system, irq,
Проекты, приложения
Очереди заданий
Динамика приложения
Поток приложений
Стек ПО
Компоненты компьютера
Инж.инфраструктура
CPU usage:
user, system, irq,
 Социальное партнёрство с родителями, как условие развития творческих способностей обучающихся
Социальное партнёрство с родителями, как условие развития творческих способностей обучающихся  149512
149512 Artificial intelligence
Artificial intelligence Предварительное обогащение
Предварительное обогащение Кратко о форсайте
Кратко о форсайте презентация мастер-класс Фоторамка - подготовительная группа
презентация мастер-класс Фоторамка - подготовительная группа Презентация Адаптация детей к школе.
Презентация Адаптация детей к школе. Государство Турция
Государство Турция Достопримечательности Европы
Достопримечательности Европы Welcome to Apple
Welcome to Apple Иммобилайзеры SHINCHANG
Иммобилайзеры SHINCHANG Антуан де Сент Экзюпери
Антуан де Сент Экзюпери Косарева Н.Н., Отставнова В.В. Использование информационно - коммуникационных технологий на уроках русского языка и литературы для активизации познавательной деятельности обучающихся.
Косарева Н.Н., Отставнова В.В. Использование информационно - коммуникационных технологий на уроках русского языка и литературы для активизации познавательной деятельности обучающихся. Налог на имущество физических лиц
Налог на имущество физических лиц Классификация и архитектура Windows Server
Классификация и архитектура Windows Server Вклад М.В.Ломоносова в развитие химии.
Вклад М.В.Ломоносова в развитие химии. Выделение существенных признаков
Выделение существенных признаков Совместный проект детей, воспитателя и родителей в старшей группе Промыслы нижегородкой области
Совместный проект детей, воспитателя и родителей в старшей группе Промыслы нижегородкой области Другу
Другу Традиционная народная кукла
Традиционная народная кукла Проверочная работа по теме Климат России
Проверочная работа по теме Климат России История одной фотографии
История одной фотографии Библиология. Перевод священного писания
Библиология. Перевод священного писания Сварка жаропрочных сталей и сплавов
Сварка жаропрочных сталей и сплавов Свайные фундаменты
Свайные фундаменты Cтроительные машины для уплотнения строительных смесей
Cтроительные машины для уплотнения строительных смесей Высшие растения
Высшие растения Портфоліо Кратік Надії Вікторівни
Портфоліо Кратік Надії Вікторівни