- Архитектура параллельных вычислительных систем. Лекция 2

Содержание
- 2. * (С) Л.Б.Соколинский 1. Классификация Флинна (1966) Поток инструкций (команд) Поток данных ОКОД (SISD — Single
- 3. * (С) Л.Б.Соколинский 1.1 ОКОД (SISD) К этому классу относятся, прежде всего, классические последовательные машины, или
- 4. * (С) Л.Б.Соколинский 1.2 ОКМД (SIMD) В архитектурах подобного рода сохраняется один поток команд, включающий, в
- 5. * (С) Л.Б.Соколинский 1.3 МКОД (MISD) Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и
- 6. * (С) Л.Б.Соколинский 1.4 МКМД (MIMD) Этот класс предполагает, что в вычислительной системе есть несколько устройств
- 7. * (С) Л.Б.Соколинский 2.1 Классификация MIMD-систем MIMD Системы с общей оперативной памятью Системы с распределённой оперативной
- 8. * (С) Л.Б.Соколинский Иерархия MIMD-систем Системы делятся по принципу организации работы с ОЗУ В системе с
- 9. * (С) Л.Б.Соколинский UMA и SMP системы UMA: характеристики доступа любого процессорного элемента в любую точку
- 10. * (С) Л.Б.Соколинский SMP-системы Преимущества SMP Простота реализации Недостатки SMP Задержки при доступе к памяти Система
- 11. * (С) Л.Б.Соколинский NUMA-системы NUMA: Процессорные элементы работают на общем адресном пространстве, но характеристики доступа процессора
- 12. * (С) Л.Б.Соколинский NUMA-системы В NUMA-системах остаётся проблема синхронизации кэша. Существует несколько способов её решения: использовать
- 13. * (С) Л.Б.Соколинский NUMA-системы Степень параллелизма выше, чем в SMP Централизация (ограничение ресурсом шины) Использование когерентных
- 14. * (С) Л.Б.Соколинский Иерархия MIMD-систем Системы с распределённой оперативной памятью представляются как объединение компьютерных узлов, каждый
- 15. * (С) Л.Б.Соколинский MPP-системы MPP — Специализированные дорогостоящие ВС. Эти компьютеры могут выстраиваться, процессорные элементы могут
- 16. * (С) Л.Б.Соколинский MPP-системы Преимущества MPP Недостатки MPP Высокая эффективность при решении определённого класса задач Высокая
- 17. * (С) Л.Б.Соколинский COW-системы Кластеры имеют две ориентации на использование: Кластер как вычислительный узел (высокопроизводительная система)
- 18. * (С) Л.Б.Соколинский COW-системы Тепловыделение Топология Преимущества COW Проблемы COW Высокая эффективность при решении широкого круга
- 20. Скачать презентацию

*
(С) Л.Б.Соколинский
1. Классификация Флинна
(1966)
Поток инструкций (команд)
Поток данных
ОКОД (SISD — Single Instruction,
*
(С) Л.Б.Соколинский
1. Классификация Флинна
(1966)
Поток инструкций (команд)
Поток данных
ОКОД (SISD — Single Instruction,

*
(С) Л.Б.Соколинский
1.1 ОКОД (SISD)
К этому классу относятся, прежде всего, классические последовательные
*
(С) Л.Б.Соколинский
1.1 ОКОД (SISD)
К этому классу относятся, прежде всего, классические последовательные

*
(С) Л.Б.Соколинский
1.2 ОКМД (SIMD)
В архитектурах подобного рода сохраняется один поток команд,
*
(С) Л.Б.Соколинский
1.2 ОКМД (SIMD)
В архитектурах подобного рода сохраняется один поток команд,

*
(С) Л.Б.Соколинский
1.3 МКОД (MISD)
Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих
*
(С) Л.Б.Соколинский
1.3 МКОД (MISD)
Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих

*
(С) Л.Б.Соколинский
1.4 МКМД (MIMD)
Этот класс предполагает, что в вычислительной системе есть
*
(С) Л.Б.Соколинский
1.4 МКМД (MIMD)
Этот класс предполагает, что в вычислительной системе есть
*
(С) Л.Б.Соколинский
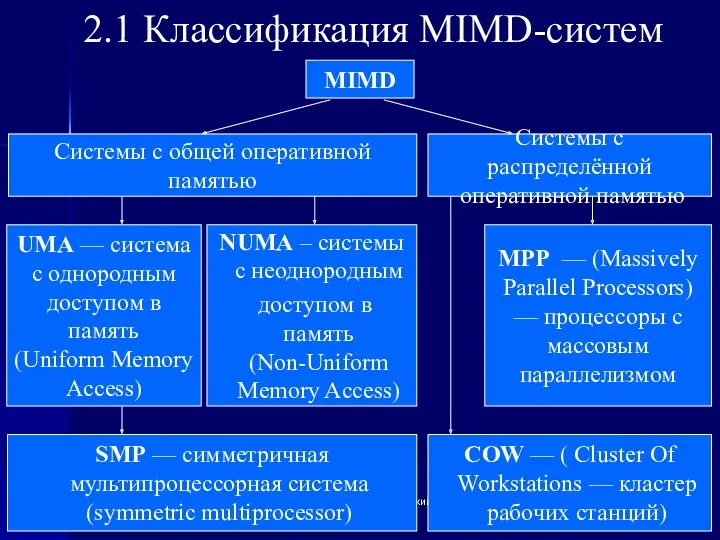
2.1 Классификация MIMD-систем
MIMD
Системы с общей оперативной памятью
Системы с распределённой
*
(С) Л.Б.Соколинский
2.1 Классификация MIMD-систем
MIMD
Системы с общей оперативной памятью
Системы с распределённой

*
(С) Л.Б.Соколинский
Иерархия MIMD-систем
Системы делятся по принципу организации работы с ОЗУ
В
*
(С) Л.Б.Соколинский
Иерархия MIMD-систем
Системы делятся по принципу организации работы с ОЗУ
В
*
(С) Л.Б.Соколинский
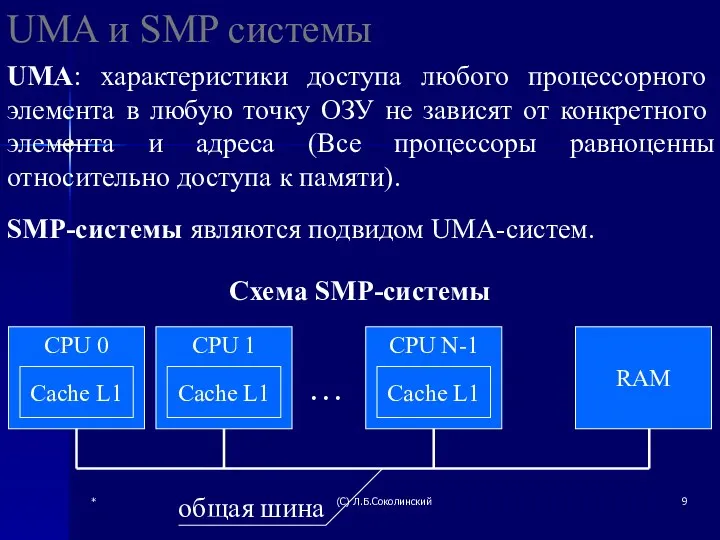
UMA и SMP системы
UMA: характеристики доступа любого процессорного элемента в
*
(С) Л.Б.Соколинский
UMA и SMP системы
UMA: характеристики доступа любого процессорного элемента в

*
(С) Л.Б.Соколинский
SMP-системы
Преимущества SMP
Простота реализации
Недостатки SMP
Задержки при доступе к памяти
Система с явной
*
(С) Л.Б.Соколинский
SMP-системы
Преимущества SMP
Простота реализации
Недостатки SMP
Задержки при доступе к памяти
Система с явной
*
(С) Л.Б.Соколинский
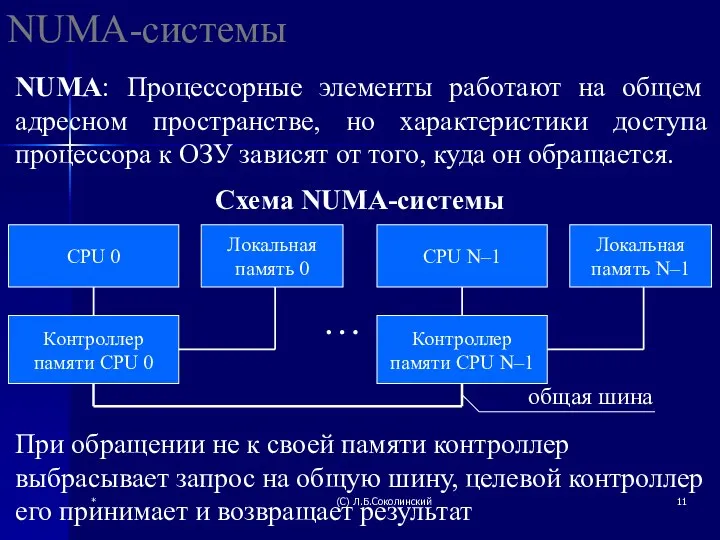
NUMA-системы
NUMA: Процессорные элементы работают на общем адресном пространстве, но характеристики
*
(С) Л.Б.Соколинский
NUMA-системы
NUMA: Процессорные элементы работают на общем адресном пространстве, но характеристики

*
(С) Л.Б.Соколинский
NUMA-системы
В NUMA-системах остаётся проблема синхронизации кэша. Существует несколько способов её
*
(С) Л.Б.Соколинский
NUMA-системы
В NUMA-системах остаётся проблема синхронизации кэша. Существует несколько способов её

*
(С) Л.Б.Соколинский
NUMA-системы
Степень параллелизма выше, чем в SMP
Централизация (ограничение ресурсом шины)
Использование
*
(С) Л.Б.Соколинский
NUMA-системы
Степень параллелизма выше, чем в SMP
Централизация (ограничение ресурсом шины)
Использование

*
(С) Л.Б.Соколинский
Иерархия MIMD-систем
Системы с распределённой оперативной памятью представляются как объединение компьютерных
*
(С) Л.Б.Соколинский
Иерархия MIMD-систем
Системы с распределённой оперативной памятью представляются как объединение компьютерных
*
(С) Л.Б.Соколинский
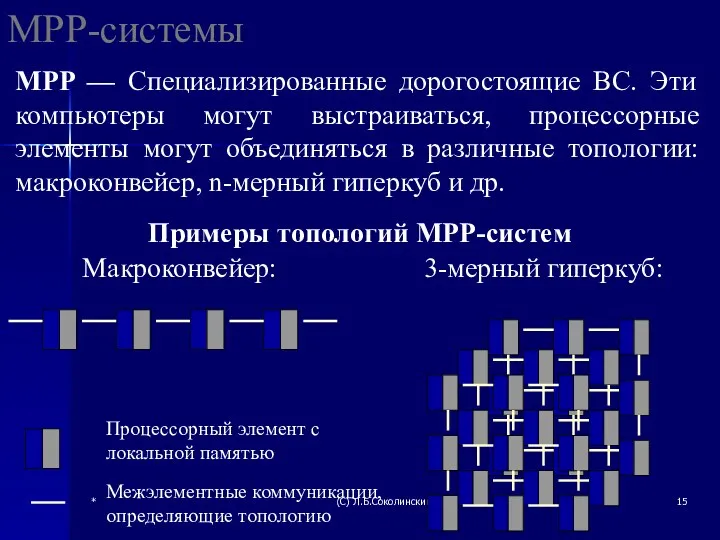
MPP-системы
MPP — Специализированные дорогостоящие ВС. Эти компьютеры могут выстраиваться, процессорные
*
(С) Л.Б.Соколинский
MPP-системы
MPP — Специализированные дорогостоящие ВС. Эти компьютеры могут выстраиваться, процессорные

*
(С) Л.Б.Соколинский
MPP-системы
Преимущества MPP
Недостатки MPP
Высокая эффективность при решении определённого класса задач
Высокая стоимость
Узкая
*
(С) Л.Б.Соколинский
MPP-системы
Преимущества MPP
Недостатки MPP
Высокая эффективность при решении определённого класса задач
Высокая стоимость
Узкая

*
(С) Л.Б.Соколинский
COW-системы
Кластеры имеют две ориентации на использование:
Кластер как вычислительный узел (высокопроизводительная
*
(С) Л.Б.Соколинский
COW-системы
Кластеры имеют две ориентации на использование:
Кластер как вычислительный узел (высокопроизводительная

*
(С) Л.Б.Соколинский
COW-системы
Тепловыделение
Топология
Преимущества COW
Проблемы COW
Высокая эффективность при решении широкого круга задач
*
(С) Л.Б.Соколинский
COW-системы
Тепловыделение
Топология
Преимущества COW
Проблемы COW
Высокая эффективность при решении широкого круга задач
 Дизайн и архитектура моего сада. 7 класс
Дизайн и архитектура моего сада. 7 класс Разработка и экономическое обоснование экскурсионного маршрута
Разработка и экономическое обоснование экскурсионного маршрута Профессия - полицейский.
Профессия - полицейский. Кафе быстрого обслуживания Dio Cafe
Кафе быстрого обслуживания Dio Cafe Строение атома
Строение атома Общие особенности античной философии
Общие особенности античной философии Урок технологии швейного дела
Урок технологии швейного дела Что такое учебный проект
Что такое учебный проект Биохимические методы исследования,используемые в эндокринологии,в норме и в патологии,иетерпретация результатов
Биохимические методы исследования,используемые в эндокринологии,в норме и в патологии,иетерпретация результатов День профессий 2022
День профессий 2022 Пасха. Светлое Христово Воскресение
Пасха. Светлое Христово Воскресение Четыре замечательные точки треугольника
Четыре замечательные точки треугольника Портфолио Андрея Джеджулы
Портфолио Андрея Джеджулы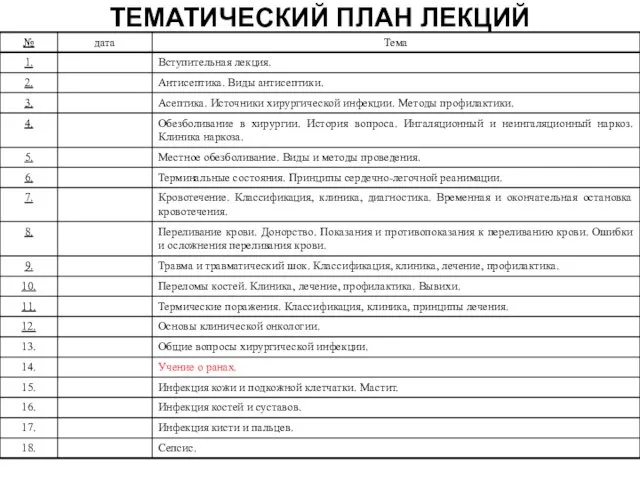 Раны. Раневой процесс
Раны. Раневой процесс Component Enabler for .NET
Component Enabler for .NET Организационные формы обучения
Организационные формы обучения Успехи в освоении технологии за 6 класс
Успехи в освоении технологии за 6 класс ПОУ СКУИТ Северодвинский колледж управления и информационных технологий
ПОУ СКУИТ Северодвинский колледж управления и информационных технологий Мастер-класс для родителей Артикуляционная гимнастика
Мастер-класс для родителей Артикуляционная гимнастика сценарий и презентация праздника ко дню Победы. Я еще не хочу умирать
сценарий и презентация праздника ко дню Победы. Я еще не хочу умирать праздник Осени во 2 классе
праздник Осени во 2 классе презентация к занятию Земля - наш общий дом!
презентация к занятию Земля - наш общий дом! Шахта лифта в панельных зданиях. Опирание перекрытий на шахту лифта. (Тест 3.1)
Шахта лифта в панельных зданиях. Опирание перекрытий на шахту лифта. (Тест 3.1) Презентация Индийский океан
Презентация Индийский океан Русская Православная церковь. Страницы истории. Обзор
Русская Православная церковь. Страницы истории. Обзор Знатоки правил дорожного движения
Знатоки правил дорожного движения Международный валютный рынок
Международный валютный рынок Натюрморт в технике гризайль
Натюрморт в технике гризайль